Explicaré el título del artículo de inmediato. Inicialmente, se planeó dar consejos buenos y confiables sobre la aceleración del uso de la reflexión usando un ejemplo simple pero realista, pero durante la evaluación comparativa resultó que la reflexión no funciona tan lentamente como pensaba, LINQ funciona más lento de lo que se había soñado en las pesadillas. Pero al final resultó que también cometí un error en las mediciones ... Detalles de esta historia de vida debajo del corte y en los comentarios. Dado que el ejemplo es bastante cotidiano y se implementa en principio, como se suele hacer en la empresa, resultó ser bastante interesante, como me parece, una demostración de la vida: no hubo un efecto notable en la velocidad del tema principal del artículo debido a la lógica externa: Moq, Autofac, EF Core, etc. "Fornido".Comencé mi trabajo bajo la impresión de este artículo: ¿Por qué la reflexión es lenta?Como puede ver, el autor sugiere utilizar delegados compilados en lugar de invocar directamente los métodos de tipo reflexión como una excelente manera de acelerar la aplicación. Hay, por supuesto, emisión de IL, pero me gustaría evitarla, ya que esta es la forma más laboriosa de completar la tarea, que está llena de errores.Teniendo en cuenta que siempre me adherí a una opinión similar sobre la velocidad de la reflexión, no tenía la intención de arrojar dudas particulares sobre las conclusiones del autor.A menudo encuentro el uso ingenuo de la reflexión en una empresa. Se toma el tipo. Se toma la información de la propiedad. Se llama al método SetValue y todos están contentos. El valor voló al campo de destino, todos están felices. Las personas que son muy inteligentes, siniors y líderes de equipo, escriben sus extensiones en el objeto, basándose en una implementación tan ingenua de los mapeadores "universales" de un tipo en otro. La esencia de esto suele ser: tomamos todos los campos, tomamos todas las propiedades, iteramos sobre ellas: si los nombres de los miembros de tipo coinciden, ejecutamos SetValue. Periódicamente, detectamos excepciones en casos en los que uno de los tipos no encontró alguna propiedad, pero también hay una salida que logra el rendimiento. Trata de atraparlo.Vi personas reinventando analizadores y mapeadores sin estar completamente armados con información sobre cómo las bicicletas inventaron antes de que funcionaran. Vi a la gente esconder sus implementaciones ingenuas detrás de estrategias, detrás de interfaces, detrás de inyecciones, como si esto excusara la bacanal posterior. De tales implementaciones volví la nariz. De hecho, no medí la pérdida de rendimiento real y, si es posible, simplemente cambié la implementación a una más "óptima", si mis manos llegaban. Debido a las primeras mediciones, que se analizan a continuación, me sentí muy avergonzado.Creo que muchos de ustedes, al leer a Richter u otros ideólogos, han llegado a la afirmación bastante justa de que la reflexión en el código es un fenómeno que tiene un efecto extremadamente negativo en el rendimiento de la aplicación.La llamada de reflexión obliga al CLR a recorrer el ensamblaje en busca del correcto, extraer sus metadatos, analizarlo, etc. Además, la reflexión durante el recorrido de la secuencia conduce a la asignación de una gran cantidad de memoria. Gastamos memoria, el CLR descubre el HZ y se congela a toda velocidad. Debería ser notablemente lento, créeme. Las enormes cantidades de memoria de los servidores de producción modernos o las máquinas en la nube no ahorran los altos retrasos de procesamiento. De hecho, cuanto más memoria, mayor es la probabilidad de que AVISARÁ cómo funciona el HZ. La reflexión es, en teoría, un trapo rojo extra para él.Sin embargo, todos usamos contenedores IoC y mapeadores de fechas, cuyo principio también se basa en la reflexión, sin embargo, las preguntas sobre su rendimiento generalmente no surgen. No, no porque la introducción de dependencias y la abstracción de modelos de contexto externo limitado sean cosas tan necesarias que tenemos que sacrificar el rendimiento en cualquier caso. Todo es más simple: realmente no afecta en gran medida el rendimiento.El hecho es que los marcos más comunes que se basan en la tecnología de reflexión utilizan todo tipo de trucos para trabajar de manera más óptima. Esto suele ser un caché. Por lo general, estas son expresiones y delegados compilados del árbol de expresiones. El mismo mapeador automático mantiene un diccionario competitivo debajo, comparando tipos con funciones que pueden convertir entre sí sin llamar a la reflexión.¿Cómo se logra esto? De hecho, esto no es diferente de la lógica que la plataforma misma usa para generar código JIT. Cuando se llama por primera vez a un método, se compila (y, sí, este proceso no es rápido), con llamadas posteriores, el control se transfiere al método ya compilado y no habrá reducciones de rendimiento especiales.En nuestro caso, también puede usar la compilación JIT y luego usar el comportamiento compilado con el mismo rendimiento que sus contrapartes AOT. En este caso, las expresiones vendrán en nuestra ayuda.Brevemente, podemos formular el principio en cuestión de la siguiente manera: elresultado final de la reflexión debe almacenarse en caché en forma de un delegado que contiene una función compilada. También tiene sentido almacenar en caché todos los objetos necesarios con información sobre los tipos en los campos de su tipo que se almacenan fuera de los objetos: el trabajador.Hay lógica en esto. El sentido común nos dice que si algo puede compilarse y almacenarse en caché, entonces esto debería hacerse.Mirando hacia el futuro, debe decirse que la memoria caché al trabajar con la reflexión tiene sus ventajas, incluso si no utiliza el método propuesto para compilar expresiones. En realidad, aquí simplemente estoy repitiendo las tesis del autor del artículo al que me refiero anteriormente.Ahora sobre el código. Veamos un ejemplo que se basa en mi dolor reciente que tuve que enfrentar en la producción seria de una organización crediticia seria. Todas las entidades son ficticias para que nadie lo adivine.Hay una cierta entidad. Deja que sea contacto. Hay letras con un cuerpo estandarizado, desde el cual el analizador y el hidratador crean estos mismos contactos. Llegó una carta, la leímos, desarmamos los pares clave-valor, creamos un contacto y lo guardamos en la base de datos.Esto es elemental. Suponga que un contacto tiene el nombre, la edad y el número de contacto de la propiedad. Estos datos se transmiten en una carta. Además, la empresa quiere soporte para poder agregar rápidamente nuevas claves para asignar propiedades de entidad a pares en el cuerpo de la carta. En caso de que alguien se imprima en la plantilla o si antes del lanzamiento sería necesario comenzar a mapear con urgencia desde un nuevo socio, ajustándose al nuevo formato. Entonces podemos agregar una nueva correlación de mapeo como un arreglo de datos barato. Es decir, un ejemplo de vida.Implementamos, creamos pruebas. Trabajos.No daré el código: había muchas fuentes, y están disponibles en GitHub en el enlace al final del artículo. Puede descargarlos, torturarlos más allá del reconocimiento y medirlos, ya que afectaría su caso. Solo daré el código de dos métodos de plantilla que distinguen el hidratador, que debería haber sido rápido del hidratador, que debería haber sido lento.La lógica es la siguiente: el método de plantilla recibe los pares formados por la lógica del analizador base. El nivel LINQ es el analizador y la lógica básica del hidratador, haciendo una solicitud al contexto db y haciendo coincidir las teclas con pares del analizador (para estas funciones, hay un código sin LINQ para comparar). A continuación, los pares se transfieren al método de hidratación principal y los valores de los pares se establecen en las propiedades correspondientes de la entidad."Rápido" (prefijo rápido en los puntos de referencia): protected override Contact GetContact(PropertyToValueCorrelation[] correlations)
{
var contact = new Contact();
foreach (var setterMapItem in _proprtySettersMap)
{
var correlation = correlations.FirstOrDefault(x => x.PropertyName == setterMapItem.Key);
setterMapItem.Value(contact, correlation?.Value);
}
return contact;
}
Como podemos ver, se utiliza una colección estática con establecedores de propiedades: lambdas compiladas que llaman a la entidad establecedora. Generado por el siguiente código: static FastContactHydrator()
{
var type = typeof(Contact);
foreach (var property in type.GetProperties())
{
_proprtySettersMap[property.Name] = GetSetterAction(property);
}
}
private static Action<Contact, string> GetSetterAction(PropertyInfo property)
{
var setterInfo = property.GetSetMethod();
var paramValueOriginal = Expression.Parameter(property.PropertyType, "value");
var paramEntity = Expression.Parameter(typeof(Contact), "entity");
var setterExp = Expression.Call(paramEntity, setterInfo, paramValueOriginal).Reduce();
var lambda = (Expression<Action<Contact, string>>)Expression.Lambda(setterExp, paramEntity, paramValueOriginal);
return lambda.Compile();
}
En general, está claro. Recorrimos las propiedades, creamos delegados para ellos que llaman a los establecedores y los guardamos. Luego llamamos cuando es necesario."Lento" (prefijo lento en los puntos de referencia): protected override Contact GetContact(PropertyToValueCorrelation[] correlations)
{
var contact = new Contact();
foreach (var property in _properties)
{
var correlation = correlations.FirstOrDefault(x => x.PropertyName == property.Name);
if (correlation?.Value == null)
continue;
property.SetValue(contact, correlation.Value);
}
return contact;
}
Aquí vamos inmediatamente a las propiedades y llamamos a SetValue directamente.Para mayor claridad y como referencia, implementé un método ingenuo que escribe los valores de sus pares de correlación directamente en los campos de la entidad. El prefijo es Manual.Ahora tomamos BenchmarkDotNet y estudiamos la productividad. Y de repente ... (el spoiler no es el resultado correcto, los detalles están a continuación)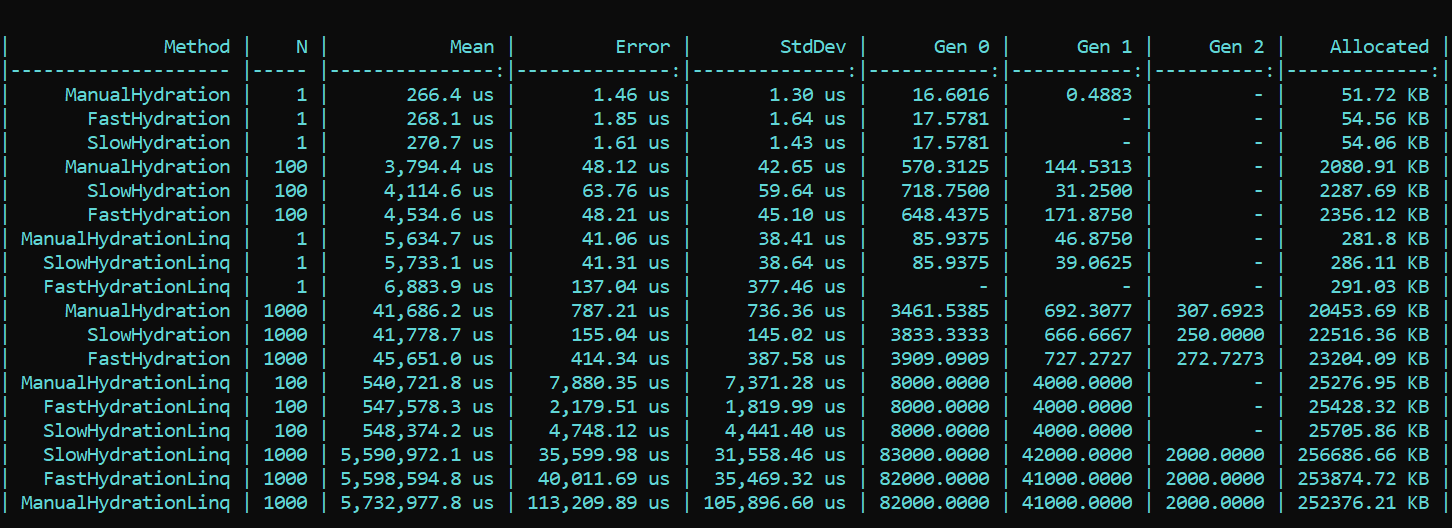 ¿Qué vemos aquí? Los métodos que usan triunfalmente el prefijo Fast resultan ser más lentos en casi todos los pases que los métodos con el prefijo Slow. Esto es cierto para la asignación y para la velocidad. Por otro lado, la implementación hermosa y elegante del mapeo utilizando métodos LINQ diseñados para este propósito, por el contrario, consume mucho rendimiento. La diferencia en los pedidos. La tendencia no cambia con un número diferente de pases. La diferencia es solo en escala. Con LINQ 4 a 200 veces más lento, hay más escombros aproximadamente a la misma escala.ACTUALIZADONo podía creer lo que veía, pero lo que es más importante, ni nuestros ojos ni mi código eran creídos por nuestro colega, Dmitry Tikhonov 0x1000000. Después de volver a verificar mi solución, descubrió brillantemente y señaló un error que no pude debido a una serie de cambios en la implementación. Después de corregir el error encontrado en la configuración de Moq, todos los resultados cayeron en su lugar. Según los resultados de la nueva prueba, la tendencia principal no cambia: LINQ afecta que el rendimiento sea aún más fuerte que la reflexión. Sin embargo, es bueno que el trabajo con la compilación de expresiones no sea en vano, y el resultado sea visible tanto en la asignación como en el tiempo de ejecución. La primera ejecución, cuando se inicializan los campos estáticos, es naturalmente más lenta en el método "rápido", pero la situación cambia aún más.Aquí está el resultado de la nueva prueba:
¿Qué vemos aquí? Los métodos que usan triunfalmente el prefijo Fast resultan ser más lentos en casi todos los pases que los métodos con el prefijo Slow. Esto es cierto para la asignación y para la velocidad. Por otro lado, la implementación hermosa y elegante del mapeo utilizando métodos LINQ diseñados para este propósito, por el contrario, consume mucho rendimiento. La diferencia en los pedidos. La tendencia no cambia con un número diferente de pases. La diferencia es solo en escala. Con LINQ 4 a 200 veces más lento, hay más escombros aproximadamente a la misma escala.ACTUALIZADONo podía creer lo que veía, pero lo que es más importante, ni nuestros ojos ni mi código eran creídos por nuestro colega, Dmitry Tikhonov 0x1000000. Después de volver a verificar mi solución, descubrió brillantemente y señaló un error que no pude debido a una serie de cambios en la implementación. Después de corregir el error encontrado en la configuración de Moq, todos los resultados cayeron en su lugar. Según los resultados de la nueva prueba, la tendencia principal no cambia: LINQ afecta que el rendimiento sea aún más fuerte que la reflexión. Sin embargo, es bueno que el trabajo con la compilación de expresiones no sea en vano, y el resultado sea visible tanto en la asignación como en el tiempo de ejecución. La primera ejecución, cuando se inicializan los campos estáticos, es naturalmente más lenta en el método "rápido", pero la situación cambia aún más.Aquí está el resultado de la nueva prueba: Conclusión: cuando se usa la reflexión en una empresa, no es particularmente necesario recurrir a trucos: LINQ engullerá el rendimiento con mayor fuerza. Sin embargo, en los métodos altamente cargados que requieren optimización, uno puede preservar la reflexión en forma de inicializadores y compiladores delegados, que luego proporcionarán una lógica "rápida". Para que pueda mantener la flexibilidad de la reflexión y la velocidad de la aplicación.Un código con un punto de referencia está disponible aquí. Todos pueden verificar mis palabras:HabraReflectionTestsPD: el código usa IoC en las pruebas y el diseño explícito en los puntos de referencia. El hecho es que en la implementación final, comparto todos los factores que pueden afectar el rendimiento y hacer que el resultado sea ruidoso.PPS: Gracias a Dmitry Tikhonov @ 0x1000000para detectar mi error en la configuración de Moq, que afectó las primeras mediciones. Si alguno de los lectores tiene suficiente karma, me gusta, por favor. El hombre se detuvo, el hombre leyó, el hombre verificó dos veces e indicó un error. Creo que esto es digno de respeto y simpatía.PPPS: gracias a ese lector meticuloso que llegó al fondo del estilo y el diseño. Estoy por la uniformidad y conveniencia. La diplomacia de la presentación deja mucho que desear, pero tomé en cuenta las críticas. Pido la concha.
Conclusión: cuando se usa la reflexión en una empresa, no es particularmente necesario recurrir a trucos: LINQ engullerá el rendimiento con mayor fuerza. Sin embargo, en los métodos altamente cargados que requieren optimización, uno puede preservar la reflexión en forma de inicializadores y compiladores delegados, que luego proporcionarán una lógica "rápida". Para que pueda mantener la flexibilidad de la reflexión y la velocidad de la aplicación.Un código con un punto de referencia está disponible aquí. Todos pueden verificar mis palabras:HabraReflectionTestsPD: el código usa IoC en las pruebas y el diseño explícito en los puntos de referencia. El hecho es que en la implementación final, comparto todos los factores que pueden afectar el rendimiento y hacer que el resultado sea ruidoso.PPS: Gracias a Dmitry Tikhonov @ 0x1000000para detectar mi error en la configuración de Moq, que afectó las primeras mediciones. Si alguno de los lectores tiene suficiente karma, me gusta, por favor. El hombre se detuvo, el hombre leyó, el hombre verificó dos veces e indicó un error. Creo que esto es digno de respeto y simpatía.PPPS: gracias a ese lector meticuloso que llegó al fondo del estilo y el diseño. Estoy por la uniformidad y conveniencia. La diplomacia de la presentación deja mucho que desear, pero tomé en cuenta las críticas. Pido la concha.