Hola, mi nombre es Alexander Vasin, soy desarrollador de backend en Edadil. La idea de este material comenzó con el hecho de que quería analizar la tarea introductoria ( Ya.Disk ) en la Yandex Backend Development School. Comencé a describir todas las sutilezas de la elección de ciertas tecnologías, la metodología de prueba ... Resultó no ser un análisis en absoluto, sino una guía muy detallada sobre cómo escribir backends en Python. Desde la idea inicial solo había requisitos para el servicio, en cuyo ejemplo es conveniente desmontar herramientas y tecnologías. Como resultado, me desperté con cien mil personajes. Se requería exactamente tanto para considerar todo con gran detalle. Entonces, el programa para los próximos 100 kilobytes: cómo construir un backend de servicio, desde la elección de herramientas hasta la implementación. TL; DR: Aquí hay un representante de GitHub con aplicación, y quién ama los hilos largos (reales) - por favor, bajo cat.Desarrollaremos y probaremos el servicio API REST en Python, lo empacaremos en un contenedor Docker liviano y lo implementaremos usando Ansible.
TL; DR: Aquí hay un representante de GitHub con aplicación, y quién ama los hilos largos (reales) - por favor, bajo cat.Desarrollaremos y probaremos el servicio API REST en Python, lo empacaremos en un contenedor Docker liviano y lo implementaremos usando Ansible.Puede implementar el servicio REST API de diferentes maneras utilizando diferentes herramientas. La solución descrita no es la única correcta, elegí la implementación y las herramientas basadas en mi experiencia personal y preferencias.
qué hacemos?
Imagine que una tienda de regalos en línea planea lanzar una acción en diferentes regiones. Para que una estrategia de ventas sea efectiva, se necesita un análisis de mercado. La tienda tiene un proveedor que envía regularmente (por ejemplo, por correo) la descarga de datos con información sobre los residentes.Desarrollemos un servicio API REST de Python que analizará los datos proporcionados e identificará la demanda de obsequios de residentes de diferentes grupos de edad en diferentes ciudades por mes.Implementamos los siguientes controladores en el servicio:POST /imports
Agrega una nueva carga con datos;
GET /imports/$import_id/citizens
Devuelve a los residentes de la descarga especificada;
PATCH /imports/$import_id/citizens/$citizen_id
Cambia la información sobre el residente (y sus familiares) en la descarga especificada;
GET /imports/$import_id/citizens/birthdays
, ( ), ;
GET /imports/$import_id/towns/stat/percentile/age
50-, 75- 99- ( ) .
?
Entonces, estamos escribiendo un servicio en Python usando marcos familiares, bibliotecas y DBMS.En 4 conferencias del video curso, se describen varios DBMS y sus características. Para mi implementación, elegí el DBMS PostgreSQL , que se ha establecido como una solución confiable con excelente documentación en ruso , una fuerte comunidad rusa (siempre puede encontrar la respuesta a una pregunta en ruso) e incluso cursos gratuitos . El modelo relacional es bastante versátil y bien entendido por muchos desarrolladores. Aunque se podría hacer lo mismo en cualquier DBMS NoSQL, en este artículo consideraremos PostgreSQL.El objetivo principal del servicio, la transmisión de datos a través de la red entre la base de datos y los clientes, no implica una gran carga en el procesador, sino que requiere la capacidad de procesar múltiples solicitudes al mismo tiempo. En 10 conferencias consideró enfoque asincrónico. Le permite servir de manera eficiente a varios clientes dentro del mismo proceso del sistema operativo (a diferencia, por ejemplo, del modelo previo a la bifurcación utilizado en Flask / Django, que crea varios procesos para procesar las solicitudes de los usuarios, cada uno de ellos consume memoria, pero está inactivo la mayor parte del tiempo ) Por lo tanto, como biblioteca para escribir el servicio, elegí el aiohttp asíncrono . La quinta conferencia del video curso dice que SQLAlchemy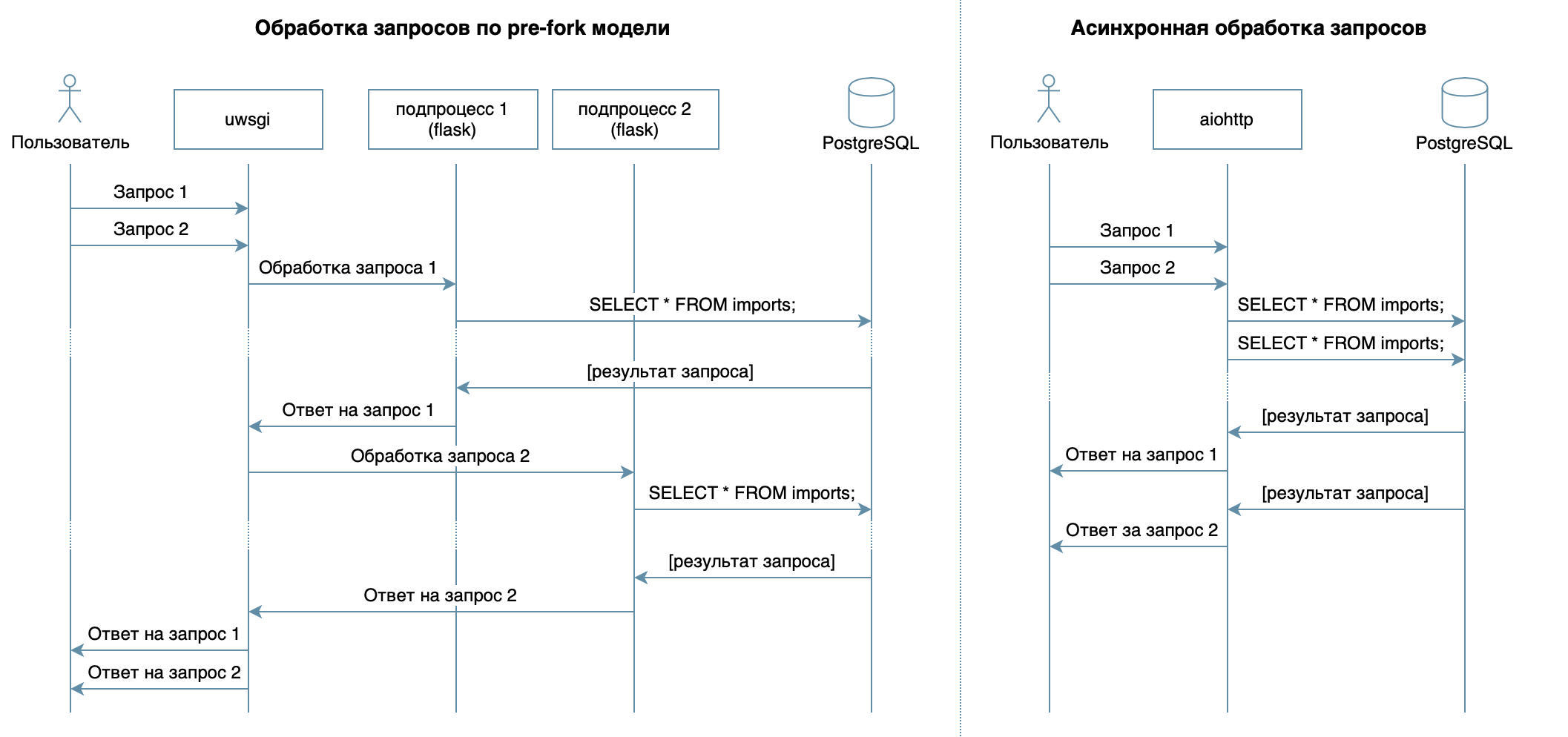 le permite descomponer consultas complejas en partes, reutilizarlas, generar consultas con un conjunto dinámico de campos (por ejemplo, el procesador PATCH permite la actualización parcial de un residente con campos arbitrarios) y centrarse directamente en la lógica empresarial. El controlador asyncpg puede manejar estas solicitudes y transferir los datos más rápido , y asyncpgsa los ayudará a hacer amigos .Mi herramienta favorita para administrar el estado de la base de datos y trabajar con migraciones es Alembic . Por cierto, recientemente hablé sobre eso en Moscow Python .La lógica de validación fue descrita sucintamente por los esquemas de Marshmallow (incluidas las comprobaciones de los lazos familiares). Usando el módulo aiohttp-specVinculaba aiohttp-handlers y esquemas para la validación de datos, y la ventaja era generar documentación en formato Swagger y mostrarla en una interfaz gráfica .Para escribir pruebas, elegí
le permite descomponer consultas complejas en partes, reutilizarlas, generar consultas con un conjunto dinámico de campos (por ejemplo, el procesador PATCH permite la actualización parcial de un residente con campos arbitrarios) y centrarse directamente en la lógica empresarial. El controlador asyncpg puede manejar estas solicitudes y transferir los datos más rápido , y asyncpgsa los ayudará a hacer amigos .Mi herramienta favorita para administrar el estado de la base de datos y trabajar con migraciones es Alembic . Por cierto, recientemente hablé sobre eso en Moscow Python .La lógica de validación fue descrita sucintamente por los esquemas de Marshmallow (incluidas las comprobaciones de los lazos familiares). Usando el módulo aiohttp-specVinculaba aiohttp-handlers y esquemas para la validación de datos, y la ventaja era generar documentación en formato Swagger y mostrarla en una interfaz gráfica .Para escribir pruebas, elegí pytest, más sobre esto en 3 conferencias .Para depurar y perfilar este proyecto, utilicé el depurador PyCharm ( clase 9 ).En la conferencia 7 se describe cómo cualquier computadora Docker (o incluso en un sistema operativo diferente) puede ejecutarse empaquetado sin tener que ajustar el entorno de la aplicación para iniciar y fácil de instalar / actualizar / eliminar la aplicación en el servidor.Para la implementación, elegí Ansible. Le permite describir declarativamente el estado deseado del servidor y sus servicios, funciona a través de ssh y no requiere un software especial.Desarrollo
Decidí darle un nombre al paquete Python analyzery usar la siguiente estructura: en el archivo publiqué
en el archivo publiquéanalyzer/__init__.py información general sobre el paquete: descripción ( cadena de documentación ), versión, licencia, contactos de desarrollador.Se puede ver con la ayuda incorporada$ python
>>> import analyzer
>>> help(analyzer)
Help on package analyzer:
NAME
analyzer
DESCRIPTION
REST API, .
PACKAGE CONTENTS
api (package)
db (package)
utils (package)
DATA
__all__ = ('__author__', '__email__', '__license__', '__maintainer__',...
__email__ = 'alvassin@yandex.ru'
__license__ = 'MIT'
__maintainer__ = 'Alexander Vasin'
VERSION
0.0.1
AUTHOR
Alexander Vasin
FILE
/Users/alvassin/Work/backendschool2019/analyzer/__init__.py
El paquete tiene dos puntos de entrada: el servicio REST API ( analyzer/api/__main__.py) y la utilidad de administración de estado de la base de datos ( analyzer/db/__main__.py). Los archivos se llaman __main__.pypor una razón: en primer lugar, dicho nombre llama la atención, deja en claro que el archivo es un punto de entrada.En segundo lugar, gracias a este enfoque de los puntos de entrada python -m:
$ python -m analyzer.api --help
$ python -m analyzer.db --help
¿Por qué necesitas comenzar con setup.py?
Mirando hacia el futuro, pensaremos en cómo distribuir la aplicación: puede empaquetarse en un archivo zip (así como en wheel / egg-), un paquete rpm, un archivo pkg para macOS e instalarse en una computadora remota, una máquina virtual, MacBook o Docker- envase.El objetivo principal del archivo setup.pyes describir el paquete con la aplicación . El archivo debe contener información general sobre el paquete (nombre, versión, autor, etc.), pero también puede especificar los módulos necesarios para el trabajo, dependencias "adicionales" (por ejemplo, para pruebas), puntos de entrada (por ejemplo, comandos ejecutables ) y requisitos para el intérprete. Los complementos de Setuptools le permiten recopilar artefactos del paquete descrito. Hay complementos integrados: zip, egg, rpm, macOS pkg. Los complementos restantes se distribuyen a través de PyPI: rueda ,distutils/setuptoolsxar , pex .En la línea inferior, describiendo un archivo, tenemos grandes oportunidades. Es por eso que el desarrollo de un nuevo proyecto debe comenzar con setup.py.En la función, setup()los módulos dependientes se indican mediante una lista:setup(..., install_requires=["aiohttp", "SQLAlchemy"])
Pero describí las dependencias en archivos separados requirements.txty requirements.dev.txtcuyos contenidos se utilizan setup.py. Me parece más flexible, además hay un secreto: más adelante te permitirá construir una imagen Docker más rápido. Las dependencias se establecerán como un paso separado antes de instalar la aplicación en sí, y al reconstruir el contenedor Docker, está en la memoria caché.Para setup.pypoder leer las dependencias de los archivos requirements.txty requirements.dev.txt, la función está escrita:def load_requirements(fname: str) -> list:
requirements = []
with open(fname, 'r') as fp:
for req in parse_requirements(fp.read()):
extras = '[{}]'.format(','.join(req.extras)) if req.extras else ''
requirements.append(
'{}{}{}'.format(req.name, extras, req.specifier)
)
return requirements
Vale la pena señalar que setuptoolscuando la distribución de la fuente por defecto de montaje incluye sólo los archivos de ensamblaje .py, .c, .cppy .h. Para un archivo de dependencia requirements.txty requirements.dev.txtgolpear la bolsa, deben especificarse claramente en el archivo MANIFEST.in.setup.py por completoimport os
from importlib.machinery import SourceFileLoader
from pkg_resources import parse_requirements
from setuptools import find_packages, setup
module_name = 'analyzer'
module = SourceFileLoader(
module_name, os.path.join(module_name, '__init__.py')
).load_module()
def load_requirements(fname: str) -> list:
requirements = []
with open(fname, 'r') as fp:
for req in parse_requirements(fp.read()):
extras = '[{}]'.format(','.join(req.extras)) if req.extras else ''
requirements.append(
'{}{}{}'.format(req.name, extras, req.specifier)
)
return requirements
setup(
name=module_name,
version=module.__version__,
author=module.__author__,
author_email=module.__email__,
license=module.__license__,
description=module.__doc__,
long_description=open('README.rst').read(),
url='https://github.com/alvassin/backendschool2019',
platforms='all',
classifiers=[
'Intended Audience :: Developers',
'Natural Language :: Russian',
'Operating System :: MacOS',
'Operating System :: POSIX',
'Programming Language :: Python',
'Programming Language :: Python :: 3',
'Programming Language :: Python :: 3.8',
'Programming Language :: Python :: Implementation :: CPython'
],
python_requires='>=3.8',
packages=find_packages(exclude=['tests']),
install_requires=load_requirements('requirements.txt'),
extras_require={'dev': load_requirements('requirements.dev.txt')},
entry_points={
'console_scripts': [
'{0}-api = {0}.api.__main__:main'.format(module_name),
'{0}-db = {0}.db.__main__:main'.format(module_name)
]
},
include_package_data=True
)
Puede instalar un proyecto en modo de desarrollo utilizando el siguiente comando (en modo editable, Python no instalará el paquete completo en una carpeta site-packages, sino que solo creará enlaces, por lo que cualquier cambio realizado en los archivos del paquete será visible de inmediato):
pip install -e '.[dev]'
pip install -e .
¿Cómo especificar versiones de dependencia?
Es genial cuando los desarrolladores trabajan activamente en sus paquetes: los errores se corrigen activamente en ellos, aparece una nueva funcionalidad y se pueden obtener comentarios más rápidamente. Pero a veces los cambios en las bibliotecas dependientes no son compatibles con versiones anteriores y pueden provocar errores en su aplicación si no lo piensa de antemano.Para cada paquete dependiente, puede especificar una versión específica, por ejemplo aiohttp==3.6.2. Luego, se garantizará que la aplicación se construirá específicamente con esas versiones de las bibliotecas dependientes con las que se probó. Pero este enfoque tiene un inconveniente: si los desarrolladores corrigen un error crítico en un paquete dependiente que no afecta la compatibilidad con versiones anteriores, esta solución no entrará en la aplicación.Hay un enfoque para el versionado de versiones semánticas, que sugiere enviar la versión en el formato MAJOR.MINOR.PATCH:MAJOR - aumenta cuando se agregan cambios incompatibles hacia atrás;MINOR - Aumenta cuando se agrega nueva funcionalidad con soporte para compatibilidad con versiones anteriores;PATCH - aumenta al agregar correcciones de errores con soporte de compatibilidad con versiones anteriores.
Si un paquete dependiente sigue este enfoque (de los cuales los autores se presentan por lo general en los archivos README y los Cambios), es suficiente para fijar el valor de MAJOR, MINORy para limitar el valor mínimo para el parche versión: >= MAJOR.MINOR.PATCH, == MAJOR.MINOR.*.Tal requisito se puede implementar utilizando el operador ~ = . Por ejemplo, aiohttp~=3.6.2permitirá que PIP se instale para la aiohttpversión 3.6.3, pero no 3.7.Si especifica el intervalo de versiones de dependencia, esto le dará una ventaja más: no habrá conflictos de versión entre las bibliotecas dependientes.Si está desarrollando una biblioteca que requiere un paquete de dependencia diferente, no permita una versión específica, sino un intervalo. Entonces será mucho más fácil para los usuarios de su biblioteca usarlo (de repente, su aplicación requiere el mismo paquete de dependencia, pero de una versión diferente).El control de versiones semántico es solo un acuerdo entre autores y consumidores de paquetes. No garantiza que los autores escriban código sin errores y no pueden cometer un error en la nueva versión de su paquete.Base de datos
Diseñamos el esquema
La descripción del manejador POST / importaciones proporciona un ejemplo de descarga con información sobre los residentes:Ejemplo de carga{
"citizens": [
{
"citizen_id": 1,
"town": "",
"street": " ",
"building": "1675",
"apartment": 7,
"name": " ",
"birth_date": "26.12.1986",
"gender": "male",
"relatives": [2]
},
{
"citizen_id": 2,
"town": "",
"street": " ",
"building": "1675",
"apartment": 7,
"name": " ",
"birth_date": "01.04.1997",
"gender": "male",
"relatives": [1]
},
{
"citizen_id": 3,
"town": "",
"street": " ",
"building": "2",
"apartment": 11,
"name": " ",
"birth_date": "23.11.1986",
"gender": "female",
"relatives": []
},
...
]
}
El primer pensamiento fue almacenar toda la información sobre el residente en una tabla citizens, donde la relación estaría representada por un campo relativesen forma de una lista de enteros .Pero este método tiene varias desventajas.GET /imports/$import_id/citizens/birthdays , , citizens . relatives UNNEST.
, 10- :
SELECT
relations.citizen_id,
relations.relative_id,
date_part('month', relatives.birth_date) as relative_birth_month
FROM (
SELECT
citizens.import_id,
citizens.citizen_id,
UNNEST(citizens.relatives) as relative_id
FROM citizens
WHERE import_id = 1
) as relations
INNER JOIN citizens as relatives ON
relations.import_id = relatives.import_id AND
relations.relative_id = relatives.citizen_id
relatives PostgreSQL, : relatives , . ( ) .
Además, decidí llevar todos los datos necesarios para trabajar a una tercera forma normal , y se obtuvo la siguiente estructura:
- La tabla de importaciones consta de una columna que se incrementa automáticamente
import_id. Es necesario para crear una verificación de clave externa en la tabla citizens.
- La tabla de ciudadanos almacena datos escalares sobre el residente (todos los campos excepto la información sobre las relaciones familiares).
Se utiliza un par ( import_id, citizen_id) como clave principal , garantizando la unicidad de los residentes citizen_iddentro del marco import_id.
Una clave foránea citizens.import_id -> imports.import_idasegura que el campo citizens.import_idcontenga solo descargas existentes.
- relations .
( ): citizens relations .
(import_id, citizen_id, relative_id) , import_id citizen_id c relative_id.
: (relations.import_id, relations.citizen_id) -> (citizens.import_id, citizens.citizen_id) (relations.import_id, relations.relative_id) -> (citizens.import_id, citizens.citizen_id), , citizen_id relative_id .
Esta estructura garantiza la integridad de los datos utilizando las herramientas de PostgreSQL , le permite obtener de manera eficiente a los residentes con parientes de la base de datos, pero está sujeto a una condición de carrera al actualizar la información sobre los residentes con consultas competitivas (analizaremos más de cerca la implementación del controlador PATCH).Describir el esquema en SQLAlchemy.
En el Capítulo 5, hablé sobre cómo crear consultas usando SQLAlchemy, necesita describir el esquema de la base de datos usando objetos especiales: las tablas se describen usando sqlalchemy.Tabley vinculadas a un registro sqlalchemy.MetaDataque almacena toda la metainformación sobre la base de datos. Por cierto, el registro MetaDatano solo puede almacenar la metainformación descrita en Python, sino que también representa el estado real de la base de datos en forma de objetos SQLAlchemy.Esta característica también permite que Alembic compare condiciones y genere un código de migración automáticamente.Por cierto, cada base de datos tiene su propio esquema de nombres de restricciones predeterminado. Para no perder el tiempo nombrando nuevas restricciones o buscando / recordando qué restricción está a punto de eliminar, SQLAlchemy sugiere usar convenciones de nomenclatura para los patrones de nomenclatura . Se pueden definir en el registro MetaData.Cree un registro de MetaData y pásele patrones de nombres
from sqlalchemy import MetaData
convention = {
'all_column_names': lambda constraint, table: '_'.join([
column.name for column in constraint.columns.values()
]),
'ix': 'ix__%(table_name)s__%(all_column_names)s',
'uq': 'uq__%(table_name)s__%(all_column_names)s',
'ck': 'ck__%(table_name)s__%(constraint_name)s',
'fk': 'fk__%(table_name)s__%(all_column_names)s__%(referred_table_name)s',
'pk': 'pk__%(table_name)s'
}
metadata = MetaData(naming_convention=convention)
Si especifica patrones de nomenclatura, Alembic los usará durante la generación automática de migraciones y nombrará todas las restricciones de acuerdo con ellos. En el futuro, el registro creado MetaDatadeberá describir las tablas:Describimos el esquema de la base de datos con objetos SQLAlchemy
from enum import Enum, unique
from sqlalchemy import (
Column, Date, Enum as PgEnum, ForeignKey, ForeignKeyConstraint, Integer,
String, Table
)
@unique
class Gender(Enum):
female = 'female'
male = 'male'
imports_table = Table(
'imports',
metadata,
Column('import_id', Integer, primary_key=True)
)
citizens_table = Table(
'citizens',
metadata,
Column('import_id', Integer, ForeignKey('imports.import_id'),
primary_key=True),
Column('citizen_id', Integer, primary_key=True),
Column('town', String, nullable=False, index=True),
Column('street', String, nullable=False),
Column('building', String, nullable=False),
Column('apartment', Integer, nullable=False),
Column('name', String, nullable=False),
Column('birth_date', Date, nullable=False),
Column('gender', PgEnum(Gender, name='gender'), nullable=False),
)
relations_table = Table(
'relations',
metadata,
Column('import_id', Integer, primary_key=True),
Column('citizen_id', Integer, primary_key=True),
Column('relative_id', Integer, primary_key=True),
ForeignKeyConstraint(
('import_id', 'citizen_id'),
('citizens.import_id', 'citizens.citizen_id')
),
ForeignKeyConstraint(
('import_id', 'relative_id'),
('citizens.import_id', 'citizens.citizen_id')
),
)
Personalizar alambique
Cuando se describe el esquema de la base de datos, es necesario generar migraciones, pero para esto primero debe configurar Alembic, que también se trata en el Capítulo 5 .Para usar el comando alembic, debe realizar los siguientes pasos:- Paquete de instalación:
pip install alembic - Inicializar Alambique:
cd analyzer && alembic init db/alembic.
Este comando creará un archivo de configuración analyzer/alembic.iniy una carpeta analyzer/db/alembiccon el siguiente contenido:
env.py- Llamado cada vez que inicias Alembic. Se conecta al registro de Alembic sqlalchemy.MetaDatacon una descripción del estado deseado de la base de datos y contiene instrucciones para iniciar las migraciones.
script.py.mako - la plantilla en función de la cual se generan las migraciones.versions - la carpeta en la que Alembic buscará (y generará) migraciones.
- Especifique la dirección de la base de datos en el archivo alembic.ini:
; analyzer/alembic.ini
[alembic]
sqlalchemy.url = postgresql://user:hackme@localhost/analyzer
- Especifique una descripción del estado deseado de la base de datos (registro
sqlalchemy.MetaData) para que Alembic pueda generar migraciones automáticamente:
from analyzer.db import schema
target_metadata = schema.metadata
Alembic está configurado y ya se puede usar, pero en nuestro caso esta configuración tiene varias desventajas:- La utilidad
alembicbusca alembic.inien el directorio de trabajo actual. Puede alembic.iniespecificar la ruta al argumento de la línea de comando, pero esto es inconveniente: quiero poder llamar al comando desde cualquier carpeta sin parámetros adicionales. - Para configurar Alembic para que funcione con una base de datos específica, debe cambiar el archivo
alembic.ini. Sería mucho más conveniente especificar la configuración de la base de datos para la variable de entorno y / o un argumento de línea de comando, por ejemplo --pg-url. - El nombre de la utilidad
alembicno se correlaciona muy bien con el nombre de nuestro servicio (y el usuario puede no tener Python y no saber nada sobre Alembic). Sería mucho más conveniente para el usuario final si todos los comandos ejecutables del servicio tuvieran un prefijo común, por ejemplo analyzer-*.
Estos problemas se resuelven con una pequeña envoltura. analyzer/db/__main__.py:- Alembic utiliza un módulo estándar para procesar argumentos de línea de comando
argparse. Le permite agregar un argumento opcional --pg-urlcon un valor predeterminado de una variable de entorno ANALYZER_PG_URL.
El códigoimport os
from alembic.config import CommandLine, Config
from analyzer.utils.pg import DEFAULT_PG_URL
def main():
alembic = CommandLine()
alembic.parser.add_argument(
'--pg-url', default=os.getenv('ANALYZER_PG_URL', DEFAULT_PG_URL),
help='Database URL [env var: ANALYZER_PG_URL]'
)
options = alembic.parser.parse_args()
config = Config(file_=options.config, ini_section=options.name,
cmd_opts=options)
config.set_main_option('sqlalchemy.url', options.pg_url)
exit(alembic.run_cmd(config, options))
if __name__ == '__main__':
main()
- La ruta al archivo
alembic.inise puede calcular en relación con la ubicación del archivo ejecutable y no con el directorio de trabajo actual del usuario.
El códigoimport os
from alembic.config import CommandLine, Config
from pathlib import Path
PROJECT_PATH = Path(__file__).parent.parent.resolve()
def main():
alembic = CommandLine()
options = alembic.parser.parse_args()
if not os.path.isabs(options.config):
options.config = os.path.join(PROJECT_PATH, options.config)
config = Config(file_=options.config, ini_section=options.name,
cmd_opts=options)
alembic_location = config.get_main_option('script_location')
if not os.path.isabs(alembic_location):
config.set_main_option('script_location',
os.path.join(PROJECT_PATH, alembic_location))
exit(alembic.run_cmd(config, options))
if __name__ == '__main__':
main()
Cuando la utilidad para administrar el estado de la base de datos está lista, puede registrarse setup.pycomo un comando ejecutable con un nombre que sea comprensible para el usuario final, por ejemplo analyzer-db:Registre un comando ejecutable en setup.pyfrom setuptools import setup
setup(..., entry_points={
'console_scripts': [
'analyzer-db = analyzer.db.__main__:main'
]
})
Después de reinstalar el módulo, se generará un archivo env/bin/analyzer-dby el comando analyzer-dbestará disponible:$ pip install -e '.[dev]'
Generamos migraciones
Para generar migraciones, se requieren dos estados: el estado deseado (que describimos con los objetos SQLAlchemy) y el estado real (la base de datos, en nuestro caso, está vacía).Decidí que la forma más fácil de aumentar Postgres con Docker era agregar un comando make postgresque ejecutara un contenedor con PostgreSQL en el puerto 5432 en segundo plano:Eleve PostgreSQL y genere migración$ make postgres
...
$ analyzer-db revision --message="Initial" --autogenerate
INFO [alembic.runtime.migration] Context impl PostgresqlImpl.
INFO [alembic.runtime.migration] Will assume transactional DDL.
INFO [alembic.autogenerate.compare] Detected added table 'imports'
INFO [alembic.autogenerate.compare] Detected added table 'citizens'
INFO [alembic.autogenerate.compare] Detected added index 'ix__citizens__town' on '['town']'
INFO [alembic.autogenerate.compare] Detected added table 'relations'
Generating /Users/alvassin/Work/backendschool2019/analyzer/db/alembic/versions/d5f704ed4610_initial.py ... done
En general, Alembic hace un buen trabajo en el trabajo de rutina de generar migraciones, pero me gustaría llamar la atención sobre lo siguiente:- Los tipos de datos de usuario especificados en las tablas creadas se crean automáticamente (en nuestro caso -
gender), pero downgradeno se genera el código para eliminarlos . Si aplica, revierte y luego aplica la migración nuevamente, esto causará un error porque el tipo de datos especificado ya existe.
Eliminar el tipo de datos de género en el método de degradaciónfrom alembic import op
from sqlalchemy import Column, Enum
GenderType = Enum('female', 'male', name='gender')
def upgrade():
...
op.create_table('citizens', ...,
Column('gender', GenderType, nullable=False))
...
def downgrade():
op.drop_table('citizens')
GenderType.drop(op.get_bind())
- En el método,
downgradealgunas acciones a veces se pueden eliminar (si eliminamos toda la tabla, no puede eliminar sus índices por separado):
por ejemplodef downgrade():
op.drop_table('relations')
op.drop_index(op.f('ix__citizens__town'), table_name='citizens')
op.drop_table('citizens')
op.drop_table('imports')
Cuando la migración está arreglada y lista, la aplicamos:$ analyzer-db upgrade head
INFO [alembic.runtime.migration] Context impl PostgresqlImpl.
INFO [alembic.runtime.migration] Will assume transactional DDL.
INFO [alembic.runtime.migration] Running upgrade -> d5f704ed4610, Initial
solicitud
Antes de comenzar a crear controladores, debe configurar la aplicación aiohttp.Si observa el inicio rápido de aiohttp, puede escribir algo como estoimport logging
from aiohttp import web
def main():
logging.basicConfig(level=logging.DEBUG)
app = web.Application()
app.router.add_route(...)
web.run_app(app)
Este código plantea una serie de preguntas y tiene una serie de desventajas:- ¿Cómo configurar la aplicación? Como mínimo, debe especificar el host y el puerto para conectar clientes, así como la información para conectarse a la base de datos.
Realmente me gusta resolver este problema con la ayuda del módulo ConfigArgParse: extiende el estándar argparsey permite usar argumentos de línea de comando, variables de entorno (indispensables para configurar contenedores Docker) e incluso archivos de configuración (así como combinar estos métodos) para la configuración. Al ConfigArgParseusarlo, también puede validar los valores de los parámetros de configuración de la aplicación.
Un ejemplo de procesamiento de parámetros usando ConfigArgParsefrom aiohttp import web
from configargparse import ArgumentParser, ArgumentDefaultsHelpFormatter
from analyzer.utils.argparse import positive_int
parser = ArgumentParser(
auto_env_var_prefix='ANALYZER_',
formatter_class=ArgumentDefaultsHelpFormatter
)
parser.add_argument('--api-address', default='0.0.0.0',
help='IPv4/IPv6 address API server would listen on')
parser.add_argument('--api-port', type=positive_int, default=8081,
help='TCP port API server would listen on')
def main():
args = parser.parse_args()
app = web.Application()
web.run_app(app, host=args.api_address, port=args.api_port)
if __name__ == '__main__':
main()
, ConfigArgParse, argparse, ( -h --help). :
$ python __main__.py --help
usage: __main__.py [-h] [--api-address API_ADDRESS] [--api-port API_PORT]
If an arg is specified in more than one place, then commandline values override environment variables which override defaults.
optional arguments:
-h, --help show this help message and exit
--api-address API_ADDRESS
IPv4/IPv6 address API server would listen on [env var: ANALYZER_API_ADDRESS] (default: 0.0.0.0)
--api-port API_PORT TCP port API server would listen on [env var: ANALYZER_API_PORT] (default: 8081)
- — , «» . , .
os.environ.clear(), Python (, asyncio?), , ConfigArgParser.
import os
from typing import Callable
from configargparse import ArgumentParser
from yarl import URL
from analyzer.api.app import create_app
from analyzer.utils.pg import DEFAULT_PG_URL
ENV_VAR_PREFIX = 'ANALYZER_'
parser = ArgumentParser(auto_env_var_prefix=ENV_VAR_PREFIX)
parser.add_argument('--pg-url', type=URL, default=URL(DEFAULT_PG_URL),
help='URL to use to connect to the database')
def clear_environ(rule: Callable):
"""
,
rule
"""
for name in filter(rule, tuple(os.environ)):
os.environ.pop(name)
def main():
args = parser.parse_args()
clear_environ(lambda i: i.startswith(ENV_VAR_PREFIX))
app = create_app(args)
...
if __name__ == '__main__':
main()
- stderr/ .
9 , logging.basicConfig() stderr.
, . aiomisc.
aiomiscimport logging
from aiomisc.log import basic_config
basic_config(logging.DEBUG, buffered=True)
- , ? ,
fork , (, Windows ).
import os
from sys import argv
import forklib
from aiohttp.web import Application, run_app
from aiomisc import bind_socket
from setproctitle import setproctitle
def main():
sock = bind_socket(address='0.0.0.0', port=8081, proto_name='http')
setproctitle(f'[Master] {os.path.basename(argv[0])}')
def worker():
setproctitle(f'[Worker] {os.path.basename(argv[0])}')
app = Application()
run_app(app, sock=sock)
forklib.fork(os.cpu_count(), worker, auto_restart=True)
if __name__ == '__main__':
main()
- - ? , ( — ) ,
nobody. — .
import os
import pwd
from aiohttp.web import run_app
from aiomisc import bind_socket
from analyzer.api.app import create_app
def main():
sock = bind_socket(address='0.0.0.0', port=8085, proto_name='http')
user = pwd.getpwnam('nobody')
os.setgid(user.pw_gid)
os.setuid(user.pw_uid)
app = create_app(...)
run_app(app, sock=sock)
if __name__ == '__main__':
main()
create_app, .
Todas las respuestas exitosas del manejador serán devueltas en formato JSON. También sería conveniente para los clientes recibir información sobre errores en forma serializada (por ejemplo, para ver qué campos no pasaron la validación).La documentación aiohttpofrece un método json_responseque toma un objeto, lo serializa en JSON y devuelve un nuevo objeto aiohttp.web.Responsecon un encabezado Content-Type: application/jsony datos serializados dentro.Cómo serializar datos usando json_responsefrom aiohttp.web import Application, View, run_app
from aiohttp.web_response import json_response
class SomeView(View):
async def get(self):
return json_response({'hello': 'world'})
app = Application()
app.router.add_route('*', '/hello', SomeView)
run_app(app)
Pero hay otra forma: aiohttp le permite registrar un serializador arbitrario para un tipo específico de datos de respuesta en el registro aiohttp.PAYLOAD_REGISTRY. Por ejemplo, puede especificar un serializador aiohttp.JsonPayloadpara objetos de tipo Mapping .En este caso, será suficiente para que el controlador devuelva un objeto Responsecon los datos de respuesta en el parámetro body. aiohttp encontrará un serializador que coincida con el tipo de datos y serializará la respuesta.Además del hecho de que la serialización de objetos se describe en un solo lugar, este enfoque también es más flexible: le permite implementar soluciones muy interesantes (consideraremos uno de los casos de uso en el controlador GET /imports/$import_id/citizens).Cómo serializar datos usando aiohttp.PAYLOAD_REGISTRYfrom types import MappingProxyType
from typing import Mapping
from aiohttp import PAYLOAD_REGISTRY, JsonPayload
from aiohttp.web import run_app, Application, Response, View
PAYLOAD_REGISTRY.register(JsonPayload, (Mapping, MappingProxyType))
class SomeView(View):
async def get(self):
return Response(body={'hello': 'world'})
app = Application()
app.router.add_route('*', '/hello', SomeView)
run_app(app)
Es importante comprender que json_response, por ejemplo aiohttp.JsonPayload, utilizan un método estándar json.dumpsque no puede serializar tipos de datos complejos, por ejemplo, datetime.dateo asyncpg.Record( asyncpgdevuelve registros de la base de datos como instancias de esta clase). Además, algunos objetos complejos pueden contener otros: en un registro de la base de datos puede haber un campo de tipo datetime.date.Los desarrolladores de Python han abordado este problema: el método le json.dumpspermite usar el argumento defaultpara especificar una función que se llama cuando es necesario serializar un objeto desconocido. Se espera que la función arroje un objeto desconocido a un tipo que pueda serializar el módulo json.Cómo extender JsonPayload para serializar objetos arbitrariosimport json
from datetime import date
from functools import partial, singledispatch
from typing import Any
from aiohttp.payload import JsonPayload as BaseJsonPayload
from aiohttp.typedefs import JSONEncoder
@singledispatch
def convert(value):
raise NotImplementedError(f'Unserializable value: {value!r}')
@convert.register(Record)
def convert_asyncpg_record(value: Record):
"""
,
asyncpg
"""
return dict(value)
@convert.register(date)
def convert_date(value: date):
"""
date —
.
..
"""
return value.strftime('%d.%m.%Y')
dumps = partial(json.dumps, default=convert)
class JsonPayload(BaseJsonPayload):
def __init__(self,
value: Any,
encoding: str = 'utf-8',
content_type: str = 'application/json',
dumps: JSONEncoder = dumps,
*args: Any,
**kwargs: Any) -> None:
super().__init__(value, encoding, content_type, dumps, *args, **kwargs)
Manipuladores
aiohttp le permite implementar controladores con funciones y clases asincrónicas. Las clases son más extensibles: en primer lugar, el código que pertenece a un controlador puede colocarse en un lugar y, en segundo lugar, las clases le permiten usar la herencia para deshacerse de la duplicación de código (por ejemplo, cada controlador requiere una conexión a la base de datos).Clase base de manejadorfrom aiohttp.web_urldispatcher import View
from asyncpgsa import PG
class BaseView(View):
URL_PATH: str
@property
def pg(self) -> PG:
return self.request.app['pg']
Como es difícil leer un archivo grande, decidí dividir los controladores en archivos. Los archivos pequeños fomentan la conectividad débil, y si, por ejemplo, hay importaciones de anillo dentro de los controladores, significa que algo puede estar mal con la composición de las entidades.POST / importaciones
El manejador de entrada recibe json con datos sobre los residentes. El tamaño de solicitud máximo permitido en aiohttp está controlado por la opción client_max_sizey es de 2 MB de forma predeterminada . Si se excede el límite, aiohttp devolverá una respuesta HTTP con un estado de 413: Error de entidad de solicitud demasiado grande.Al mismo tiempo, el json correcto con las líneas y números más largos pesará ~ 63 megabytes, por lo que las restricciones sobre el tamaño de la solicitud deben ampliarse.A continuación, debe verificar y deserializar los datos . Si son incorrectos, debe devolver una respuesta HTTP 400: Bad Request.Necesitaba dos esquemas Marhsmallow. El primero CitizenSchema, verifica los datos de cada residente individual y también deserializa la cadena de feliz cumpleaños en el objeto datetime.date:- Tipo de datos, formato y disponibilidad de todos los campos obligatorios;
- Falta de campos desconocidos;
- La fecha de nacimiento debe indicarse en el formato
DD.MM.YYYYy no puede tener ninguna importancia en el futuro; - La lista de familiares de cada residente debe contener identificadores únicos de residentes existentes en esta carga.
El segundo esquema ImportSchema, comprueba la descarga en su conjunto:citizen_id cada residente dentro de la descarga debe ser único;- Los lazos familiares deben ser bidireccionales (si el residente # 1 tiene un residente # 2 en la lista de parientes, entonces el residente # 2 también debe tener un pariente # 1).
Si los datos son correctos, deben agregarse a la base de datos con uno nuevo y único import_id.Para agregar datos, deberá realizar varias consultas en diferentes tablas. Para evitar datos agregados parcialmente en la base de datos en caso de error o excepción (por ejemplo, al desconectar un cliente que no recibió una respuesta completa, aiohttp lanzará una excepción CancelledError ), debe usar una transacción .Es necesario agregar datos a las tablas en partes , ya que en una consulta a PostgreSQL no puede haber más de 32,767 argumentos. Hay citizens9 campos en la tabla . En consecuencia, para 1 consulta, solo se pueden insertar 32.767 / 9 = 3.640 filas en esta tabla, y en una carga puede haber hasta 10.000 habitantes.GET / imports / $ import_id / ciudadanos
El controlador devuelve a todos los residentes para descargar con el especificado import_id. Si la carga especificada no existe , debe devolver la respuesta 404: No encontrado HTTP. Este comportamiento parece ser común para los controladores que necesitan una descarga existente, por lo que extraje el código de verificación en una clase separada.Clase base para manipuladores con descargasfrom aiohttp.web_exceptions import HTTPNotFound
from sqlalchemy import select, exists
from analyzer.db.schema import imports_table
class BaseImportView(BaseView):
@property
def import_id(self):
return int(self.request.match_info.get('import_id'))
async def check_import_exists(self):
query = select([
exists().where(imports_table.c.import_id == self.import_id)
])
if not await self.pg.fetchval(query):
raise HTTPNotFound()
Para obtener una lista de parientes para cada residente, deberá realizar una LEFT JOINtabla citizensa otra relations, agregando el campo relations.relative_idagrupado por import_idy citizen_id.Si el residente no tiene parientes, LEFT JOINle devolverá el relations.relative_idvalor en el campo NULLy, como resultado de la agregación, se verá la lista de parientes [NULL].Para corregir este valor incorrecto, utilicé la función array_remove .La base de datos almacena la fecha en un formato YYYY-MM-DD, pero necesitamos un formato DD.MM.YYYY.Técnicamente, puede formatear la fecha con una consulta SQL o en el lado de Python al momento de serializar la respuesta con json.dumps(asyncpg devuelve el valor del campo birth_datecomo una instancia de la clasedatetime.date)Elegí la serialización en el lado de Python, dado que birth_datees el único objeto datetime.dateen el proyecto con un solo formato (consulte la sección "Serialización de datos" ).A pesar de que el procesador ejecuta dos solicitudes (comprobando la existencia de una descarga y una solicitud de una lista de residentes), no es necesario utilizar una transacción . De manera predeterminada, PostgreSQL usa el nivel de aislamiento, READ COMMITTEDe incluso dentro de una transacción todos los cambios a otras transacciones completadas con éxito serán visibles (agregando nuevas filas, cambiando las existentes).La carga más grande en una vista de texto puede tomar ~ 63 megabytes, esto es bastante, especialmente teniendo en cuenta que varias solicitudes para recibir datos pueden llegar al mismo tiempo. Hay una forma bastante interesante de obtener datos de la base de datos utilizando el cursor y enviarlos al cliente por partes .Para hacer esto, necesitamos implementar dos objetos:- Un objeto de
SelectQuerytipo AsyncIterableque devuelve registros de la base de datos. En la primera llamada, se conecta a la base de datos, abre una transacción y crea un cursor; durante la iteración posterior, devuelve registros de la base de datos. Es devuelto por el manejador.
Seleccionar código de consultafrom collections import AsyncIterable
from asyncpgsa.transactionmanager import ConnectionTransactionContextManager
from sqlalchemy.sql import Select
class SelectQuery(AsyncIterable):
"""
, PostgreSQL
, ,
"""
PREFETCH = 500
__slots__ = (
'query', 'transaction_ctx', 'prefetch', 'timeout'
)
def __init__(self, query: Select,
transaction_ctx: ConnectionTransactionContextManager,
prefetch: int = None,
timeout: float = None):
self.query = query
self.transaction_ctx = transaction_ctx
self.prefetch = prefetch or self.PREFETCH
self.timeout = timeout
async def __aiter__(self):
async with self.transaction_ctx as conn:
cursor = conn.cursor(self.query, prefetch=self.prefetch,
timeout=self.timeout)
async for row in cursor:
yield row
- Un serializador
AsyncGenJSONListPayloadque puede iterar sobre generadores asincrónicos, serializar datos de un generador asincrónico a JSON y enviar datos a clientes en partes. Está registrado aiohttp.PAYLOAD_REGISTRYcomo un serializador de objetos AsyncIterable.
AsyncGenJSONListPayload Codeimport json
from functools import partial
from aiohttp import Payload
dumps = partial(json.dumps, default=convert, ensure_ascii=False)
class AsyncGenJSONListPayload(Payload):
"""
AsyncIterable,
JSON
"""
def __init__(self, value, encoding: str = 'utf-8',
content_type: str = 'application/json',
root_object: str = 'data',
*args, **kwargs):
self.root_object = root_object
super().__init__(value, content_type=content_type, encoding=encoding,
*args, **kwargs)
async def write(self, writer):
await writer.write(
('{"%s":[' % self.root_object).encode(self._encoding)
)
first = True
async for row in self._value:
if not first:
await writer.write(b',')
else:
first = False
await writer.write(dumps(row).encode(self._encoding))
await writer.write(b']}')
Además, en el controlador será posible crear un objeto SelectQuery, pasarle una consulta SQL y una función para abrir la transacción y devolverlo a Response body:Código de controlador
from aiohttp.web_response import Response
from aiohttp_apispec import docs, response_schema
from analyzer.api.schema import CitizensResponseSchema
from analyzer.db.schema import citizens_table as citizens_t
from analyzer.utils.pg import SelectQuery
from .query import CITIZENS_QUERY
from .base import BaseImportView
class CitizensView(BaseImportView):
URL_PATH = r'/imports/{import_id:\d+}/citizens'
@docs(summary=' ')
@response_schema(CitizensResponseSchema())
async def get(self):
await self.check_import_exists()
query = CITIZENS_QUERY.where(
citizens_t.c.import_id == self.import_id
)
body = SelectQuery(query, self.pg.transaction())
return Response(body=body)
aiohttpdetecta un aiohttp.PAYLOAD_REGISTRYserializador registrado AsyncGenJSONListPayloadpara objetos de tipo en el registro AsyncIterable. Luego, el serializador iterará sobre el objeto SelectQueryy enviará datos al cliente. En la primera llamada, el objeto SelectQueryrecibe una conexión a la base de datos, abre una transacción y crea un cursor; durante la iteración adicional, recibirá datos de la base de datos con el cursor y los devolverá línea por línea.Este enfoque permite no asignar memoria para la cantidad total de datos con cada solicitud, pero tiene una peculiaridad: la aplicación no podrá devolver el estado HTTP correspondiente al cliente si se produce un error (después de todo, el estado HTTP, los encabezados ya se han enviado al cliente y se están escribiendo datos).Cuando ocurre una excepción, no queda nada más que desconectarse. Por supuesto, se puede asegurar una excepción, pero el cliente no podrá entender exactamente qué error ocurrió.Por otro lado, puede surgir una situación similar incluso si el procesador recibe todos los datos de la base de datos, pero la red parpadea mientras transmite datos al cliente; nadie está a salvo de esto.PARCHE / importaciones / $ import_id / ciudadanos / $ citizen_id
El controlador recibe el identificador de la descarga import_id, el residente citizen_id, así como json con los nuevos datos sobre el residente. En el caso de una descarga inexistente o de un residente , se debe devolver una respuesta HTTP 404: Not Found.Los datos transmitidos por el cliente deben ser verificados y deserializados . Si son incorrectos, debe devolver una respuesta HTTP 400: Bad Request. Implementé un esquema Marshmallow PatchCitizenSchemaque verifica:- El tipo y el formato de los datos para los campos especificados.
- Fecha de nacimiento. Debe especificarse en un formato
DD.MM.YYYYy no puede tener importancia en el futuro. - Una lista de familiares de cada residente. Debe tener identificadores únicos para los residentes.
La existencia de los parientes indicados en el campo relativesno se puede verificar por separado: si relationsse agrega un residente inexistente a la tabla, PostgreSQL devolverá un error ForeignKeyViolationErrorque se puede procesar y se puede devolver el estado HTTP 400: Bad Request.¿Qué estado debería devolverse si el cliente envió datos incorrectos para un residente o descarga inexistente ? Es semánticamente más correcto verificar primero la existencia de una descarga y un residente (si no hay ninguno, regresar 404: Not Found) y solo luego si el cliente ha enviado los datos correctos (si no, regresar 400: Bad Request). En la práctica, a menudo es más barato verificar los datos primero, y solo si son correctos, acceder a la base de datos.Ambas opciones son aceptables, pero decidí elegir una segunda opción más barata, ya que en cualquier caso el resultado de la operación es un error que no afecta nada (el cliente corregirá los datos y luego descubrirá que el residente no existe).Si los datos son correctos, es necesario actualizar la información sobre el residente en la base de datos . En el controlador, deberá realizar varias consultas a diferentes tablas. Si se produce un error o una excepción, los cambios en la base de datos deben deshacerse, por lo que las consultas deben realizarse en una transacción .El método le PATCH permite transferir solo algunos campos para un residente.El controlador debe estar escrito de tal manera que no se bloquee al acceder a datos que el cliente no especificó, y tampoco ejecuta consultas en tablas en las que los datos no han cambiado.Si el cliente especificó el campo relatives, es necesario obtener una lista de parientes existentes. Si ha cambiado, determine qué registros de la tabla relativesdeben eliminarse y cuáles agregar para alinear la base de datos con la solicitud del cliente. Por defecto, PostgreSQL usa aislamiento de transacciones READ COMMITTED. Esto significa que, como parte de la transacción actual, los cambios serán visibles para los registros existentes (así como los nuevos) de otras transacciones completadas. Esto puede conducir a una condición de carrera entre solicitudes competitivas .Supongamos que hay una descarga con los residentes.#1. #2, #3sin parentesco. El servicio recibe dos solicitudes simultáneas para cambiar el residente # 1: {"relatives": [2]}y {"relatives": [3]}. aiohttp creará dos controladores que recibirán simultáneamente el estado actual del residente de PostgreSQL.Cada controlador no detectará una sola relación relacionada y decidirá agregar una nueva relación con el pariente especificado. Como resultado, el residente # 1 tiene el mismo campo que los parientes [2,3]. Este comportamiento no puede llamarse obvio. Se esperan dos opciones para decidir el resultado de la carrera: completar solo la primera solicitud y que la segunda devuelva una respuesta HTTP
Este comportamiento no puede llamarse obvio. Se esperan dos opciones para decidir el resultado de la carrera: completar solo la primera solicitud y que la segunda devuelva una respuesta HTTP409: Conflict(para que el cliente repita la solicitud), o ejecutar solicitudes por turno (la segunda solicitud se procesará solo después de que se complete la primera).La primera opción se puede implementar activando el modo de aislamientoSERIALIZABLE. Si durante el procesamiento de la solicitud alguien ya logró cambiar y confirmar los datos, se generará una excepción, que se puede procesar y devolver el estado HTTP correspondiente.La desventaja de esta solución: una gran cantidad de bloqueos en PostgreSQL SERIALIZABLEarrojará una excepción, incluso si las consultas competitivas cambian los registros de los residentes de diferentes descargas.También puede usar el mecanismo de bloqueo de recomendación . Si obtiene este bloqueo activado import_id, las solicitudes competitivas para diferentes descargas podrán ejecutarse en paralelo.Para procesar solicitudes competitivas en una carga, puede implementar el comportamiento de cualquiera de las opciones: la función pg_try_advisory_xact_lockintenta obtener un bloqueo ydevuelve el resultado booleano inmediatamente (si no fue posible obtener el bloqueo, se puede lanzar una excepción) y pg_advisory_xact_lockespera hasta que elrecurso esté disponible para el bloqueo (en este caso, las solicitudes se ejecutarán secuencialmente, me decidí por esta opción).Como resultado, el controlador debe devolver la información actual sobre el residente actualizado . Fue posible limitarnos a devolver datos de su solicitud al cliente (dado que estamos devolviendo una respuesta al cliente, significa que no hubo excepciones y que todas las solicitudes se completaron con éxito). O bien, use la palabra clave RETURNING en consultas que modifiquen la base de datos y generen una respuesta a partir de los resultados. Pero ambos enfoques no nos permitirían ver y probar el caso con la raza de los estados.No hubo requisitos de alta carga para el servicio, así que decidí solicitar nuevamente todos los datos sobre el residente y devolver al cliente un resultado honesto de la base de datos.GET / importaciones / $ import_id / ciudadanos / cumpleaños
El controlador calcula la cantidad de regalos que cada residente de la descarga recibirá a sus familiares (primer pedido). El número se agrupa por mes para cargar con el especificado import_id. En el caso de una carga inexistente , se debe devolver una respuesta HTTP 404: Not Found.Hay dos opciones de implementación:- Obtenga datos para residentes con parientes de la base de datos y, en el lado de Python, agregue datos por mes y genere listas para aquellos meses para los que no hay datos en la base de datos.
- Compile una solicitud json en la base de datos y agregue talones para los meses que faltan.
Me decidí por la primera opción: visualmente parece más comprensible y compatible. El número de cumpleaños en un mes determinado puede obtenerse JOINde la tabla con lazos familiares ( relations.citizen_id- el residente para quien consideramos los cumpleaños de familiares) en la tabla citizens(que contiene la fecha de nacimiento de la que desea obtener el mes).Los valores del mes no deben contener ceros a la izquierda. El mes obtenido del campo birth_dateusando la función date_partpuede contener un cero a la izquierda. Para quitarlo, he realizado casta integeren la consulta SQL.A pesar de que el controlador necesita cumplir dos solicitudes (verificar la existencia de descarga y obtener información sobre cumpleaños y regalos), no se requiere una transacción .De manera predeterminada, PostgreSQL usa el modo LEER COMPROMETIDO, en el que todos los registros nuevos (agregados por otras transacciones) y existentes (modificados por otras transacciones) son visibles en la transacción actual después de que se completen con éxito.Por ejemplo, si se agrega una nueva carga al momento de recibir los datos, no afectará a los existentes. Si al momento de recibir los datos se ejecuta una solicitud para cambiar el residente, los datos aún no estarán visibles (si la transacción que cambió los datos no se ha completado) o la transacción se completará por completo y todos los cambios serán visibles de inmediato. La integridad obtenida de la base de datos no será violada.GET / imports / $ import_id / towns / stat / percentil / age
El controlador calcula los percentiles 50, 75 y 99 de las edades (años completos) de los residentes por ciudad en la muestra con el import_id especificado. En el caso de una carga inexistente , se debe devolver una respuesta HTTP 404: Not Found.A pesar de que el procesador ejecuta dos solicitudes (comprobando la existencia de descarga y obteniendo una lista de residentes), no es necesario utilizar una transacción .Hay dos opciones de implementación:- Obtenga la edad de los residentes de la base de datos, agrupada por ciudad, y luego, en el lado de Python, calcule los percentiles usando numpy (que se especifica como referencia en la tarea) y redondee hasta dos decimales.
- PostgreSQL: percentile_cont , SQL-, numpy .
La segunda opción requiere transferir menos datos entre la aplicación y PostgreSQL, pero no tiene una trampa muy obvia: en PostgreSQL, el redondeo es matemático, ( SELECT ROUND(2.5)devuelve 3), y en Python - contabilidad, al entero más cercano ( round(2.5)devuelve 2).Para probar el controlador, la implementación debe ser la misma tanto en PostgreSQL como en Python (implementar una función con redondeo matemático en Python parece más fácil). Vale la pena señalar que al calcular los percentiles, numpy y PostgreSQL pueden devolver números ligeramente diferentes, pero dado el redondeo, esta diferencia no será notable.Pruebas
¿Qué se debe verificar en esta aplicación? En primer lugar, que los manejadores cumplan con los requisitos y realicen el trabajo requerido en un entorno lo más cercano posible al entorno de combate. En segundo lugar, las migraciones que cambian el estado de la base de datos funcionan sin errores. En tercer lugar, hay una serie de funciones auxiliares que también podrían cubrirse correctamente mediante pruebas.Decidí usar el marco pytest debido a su flexibilidad y facilidad de uso. Ofrece un poderoso mecanismo para preparar el entorno para las pruebas: accesorios , es decir, funciones con un decoradorpytest.mark.fixturecuyos nombres pueden especificarse por el parámetro en la prueba. Si pytest detecta un parámetro con un nombre de dispositivo en la anotación de prueba, ejecutará este dispositivo y pasará el resultado en el valor de este parámetro. Y si el dispositivo es un generador, entonces el parámetro de prueba tomará el valor devuelto yield, y después de que finalice la prueba, se ejecutará la segunda parte del dispositivo , que puede borrar recursos o cerrar conexiones.Para la mayoría de las pruebas, necesitamos una base de datos PostgreSQL. Para aislar las pruebas entre sí, puede crear una base de datos separada antes de cada prueba y eliminarla después de la ejecución.Crear una base de datos de dispositivos para cada pruebaimport os
import uuid
import pytest
from sqlalchemy import create_engine
from sqlalchemy_utils import create_database, drop_database
from yarl import URL
from analyzer.utils.pg import DEFAULT_PG_URL
PG_URL = os.getenv('CI_ANALYZER_PG_URL', DEFAULT_PG_URL)
@pytest.fixture
def postgres():
tmp_name = '.'.join([uuid.uuid4().hex, 'pytest'])
tmp_url = str(URL(PG_URL).with_path(tmp_name))
create_database(tmp_url)
try:
yield tmp_url
finally:
drop_database(tmp_url)
def test_db(postgres):
"""
, PostgreSQL
"""
engine = create_engine(postgres)
assert engine.execute('SELECT 1').scalar() == 1
engine.dispose()
El módulo sqlalchemy_utils hizo un gran trabajo de esta tarea , teniendo en cuenta las características de diferentes bases de datos y controladores. Por ejemplo, PostgreSQL no permite la ejecución CREATE DATABASEen un bloque de transacciones. Al crear una base de datos, se sqlalchemy_utilstraduce psycopg2(que generalmente ejecuta todas las solicitudes en una transacción) al modo de confirmación automática.Otra característica importante: si al menos un cliente está conectado a PostgreSQL, la base de datos no se puede eliminar, pero sqlalchemy_utilsdesconecta a todos los clientes antes de eliminar la base de datos. La base de datos se eliminará con éxito incluso si se bloquea alguna prueba con conexiones activas.Necesitamos PostgreSQL en diferentes estados: para probar las migraciones, necesitamos una base de datos limpia, mientras que los controladores requieren que se apliquen todas las migraciones. Puede cambiar programáticamente el estado de una base de datos utilizando comandos Alembic; requieren el objeto de configuración Alembic para llamarlos.Crear un objeto de configuración Alembic de dispositivofrom types import SimpleNamespace
import pytest
from analyzer.utils.pg import make_alembic_config
@pytest.fixture()
def alembic_config(postgres):
cmd_options = SimpleNamespace(config='alembic.ini', name='alembic',
pg_url=postgres, raiseerr=False, x=None)
return make_alembic_config(cmd_options)
Tenga en cuenta que los dispositivos alembic_configtienen un parámetro postgres: pytestpermite no solo indicar la dependencia de la prueba en los dispositivos, sino también las dependencias entre ellos.Este mecanismo le permite separar de manera flexible la lógica y escribir código muy conciso y reutilizable.Manipuladores
Las pruebas de controladores requieren una base de datos con tablas y tipos de datos creados. Para aplicar migraciones, debe llamar mediante programación al comando Alembic de actualización. Para llamarlo, necesita un objeto con la configuración Alembic, que ya hemos definido con los accesorios alembic_config. La base de datos con migraciones parece una entidad completamente independiente y se puede representar como un elemento fijo:from alembic.command import upgrade
@pytest.fixture
async def migrated_postgres(alembic_config, postgres):
upgrade(alembic_config, 'head')
return postgres
Cuando hay muchas migraciones en el proyecto, su aplicación para cada prueba puede llevar demasiado tiempo. Para acelerar el proceso, puede crear una base de datos con migraciones una vez y luego usarla como plantilla .Además de la base de datos para probar controladores, necesitará una aplicación en ejecución, así como un cliente configurado para trabajar con esta aplicación. Para hacer que la aplicación sea fácil de probar, puse su creación en una función create_appque toma parámetros para ejecutarse: una base de datos, un puerto para la API REST y otros.Los argumentos para iniciar la aplicación también se pueden representar como un elemento separado. Para crearlos, deberá determinar el puerto libre para ejecutar la aplicación de prueba y la dirección a la base de datos temporal migrada.Para determinar el puerto libre, utilicé el dispositivo aiomisc_unused_portdel paquete aiomisc.Un dispositivo estándar aiohttp_unused_porttambién estaría bien, pero devuelve una función para determinar los puertos libres, mientras que aiomisc_unused_portinmediatamente devuelve el número de puerto. Para nuestra aplicación, necesitamos determinar solo un puerto libre, así que decidí no escribir una línea de código adicional con una llamada aiohttp_unused_port.@pytest.fixture
def arguments(aiomisc_unused_port, migrated_postgres):
return parser.parse_args(
[
'--log-level=debug',
'--api-address=127.0.0.1',
f'--api-port={aiomisc_unused_port}',
f'--pg-url={migrated_postgres}'
]
)
Todas las pruebas con controladores implican solicitudes a la API REST; aiohttpno es necesario trabajar directamente con la aplicación . Por lo tanto, hice un accesorio que inicia la aplicación y el uso de fábrica aiohttp_clientcrea y devuelve un cliente de prueba estándar conectado a la aplicación aiohttp.test_utils.TestClient.from analyzer.api.app import create_app
@pytest.fixture
async def api_client(aiohttp_client, arguments):
app = create_app(arguments)
client = await aiohttp_client(app, server_kwargs={
'port': arguments.api_port
})
try:
yield client
finally:
await client.close()
Ahora, si especifica la fijación en los parámetros de prueba api_client, sucederá lo siguiente:postgres ( migrated_postgres).alembic_config Alembic, ( migrated_postgres).migrated_postgres ( arguments).aiomisc_unused_port ( arguments).arguments ( api_client).api_client .- .
api_client .postgres .
Los accesorios le permiten evitar la duplicación de código, pero además de preparar el entorno en las pruebas, hay otro lugar potencial en el que habrá una gran cantidad del mismo código: solicitudes de solicitud.Primero, al hacer una solicitud, esperamos obtener un cierto estado HTTP. En segundo lugar, si el estado coincide con el esperado, antes de trabajar con los datos, debe asegurarse de que tengan el formato correcto. Aquí es fácil cometer un error y escribir un controlador que haga los cálculos correctos y devuelva el resultado correcto, pero no pase la validación automática debido al formato de respuesta incorrecto (por ejemplo, olvide envolver la respuesta en un diccionario con una clave data). Todos estos controles podrían hacerse en un solo lugar.En el moduloanalyzer.testing He preparado para cada controlador una función auxiliar que verifica el estado de HTTP, así como el formato de respuesta usando Marshmallow.GET / imports / $ import_id / ciudadanos
Decidí comenzar con un controlador que devuelva residentes, porque es muy útil para verificar los resultados de otros controladores que cambian el estado de la base de datos.Intencionalmente no utilicé código que agrega datos a la base de datos desde el controlador POST /imports, aunque no es difícil convertirlo en una función separada. El código del controlador tiene la propiedad de cambiar, y si hay algún error en el código que se agrega a la base de datos, existe la posibilidad de que la prueba deje de funcionar según lo previsto e implícitamente para los desarrolladores dejarán de mostrar errores.Para esta prueba, definí los siguientes conjuntos de datos de prueba:- Descarga con varios familiares. Comprueba que para cada residente se formará correctamente una lista con identificadores de familiares.
- Descarga con un residente sin parientes. Comprueba que el campo
relativeses una lista vacía (debido LEFT JOINa la consulta SQL, la lista de parientes puede ser igual [None]). - Descarga con un residente que es un pariente suyo.
- Descarga vacía. Comprueba que el controlador permite agregar descargas vacías y no se bloquea con un error.
Para ejecutar la misma prueba por separado en cada carga, utilicé otro mecanismo pytest muy poderoso: la parametrización . Este mecanismo le permite ajustar la función de prueba en el decorador pytest.mark.parametrizey describir en ella qué parámetros debe tomar la función de prueba para cada caso de prueba individual.Cómo parametrizar una pruebaimport pytest
from analyzer.utils.testing import generate_citizen
datasets = [
[
generate_citizen(citizen_id=1, relatives=[2, 3]),
generate_citizen(citizen_id=2, relatives=[1]),
generate_citizen(citizen_id=3, relatives=[1])
],
[
generate_citizen(relatives=[])
],
[
generate_citizen(citizen_id=1, name='', gender='male',
birth_date='17.02.2020', relatives=[1])
],
[],
]
@pytest.mark.parametrize('dataset', datasets)
async def test_get_citizens(api_client, dataset):
"""
4 ,
"""
Por lo tanto, la prueba agregará la carga a la base de datos, luego, mediante una solicitud al controlador, recibirá información sobre los residentes y comparará la carga de referencia con la recibida. Pero, ¿cómo se compara a los residentes?Cada residente consta de campos escalares y un campo relatives, una lista de identificadores de parientes. Una lista en Python es un tipo ordenado, y al comparar el orden de los elementos de cada lista sí importa, pero al comparar listas con hermanos, el orden no debería importar.Si lleva relativesal conjunto antes de la comparación, al compararlo no funciona para encontrar una situación en la que uno de los habitantes del campo relativestenga duplicados. Si ordena la lista con los identificadores de parientes, esto evitará el problema del diferente orden de los identificadores de parientes, pero al mismo tiempo detectará duplicados.Al comparar dos listas con residentes, uno puede encontrar un problema similar: técnicamente, el orden de los residentes en la descarga no es importante, pero es importante detectar si hay dos residentes con los mismos identificadores en una descarga y no en la otra. Entonces, además de organizar la lista con parientes, los parientes de cada residente deben organizar a los residentes en cada descarga.Como la tarea de comparar residentes surgirá más de una vez, implementé dos funciones: una para comparar dos residentes y la segunda para comparar dos listas con residentes:Compara residentesfrom typing import Iterable, Mapping
def normalize_citizen(citizen):
"""
"""
return {**citizen, 'relatives': sorted(citizen['relatives'])}
def compare_citizens(left: Mapping, right: Mapping) -> bool:
"""
"""
return normalize_citizen(left) == normalize_citizen(right)
def compare_citizen_groups(left: Iterable, right: Iterable) -> bool:
"""
,
"""
left = [normalize_citizen(citizen) for citizen in left]
left.sort(key=lambda citizen: citizen['citizen_id'])
right = [normalize_citizen(citizen) for citizen in right]
right.sort(key=lambda citizen: citizen['citizen_id'])
return left == right
Para asegurarme de que este controlador no regrese a los residentes de otras descargas, decidí agregar una descarga adicional con un habitante antes de cada prueba.POST / importaciones
Definí los siguientes conjuntos de datos para probar el controlador:- Datos correctos, que se espera agregar con éxito a la base de datos.
- ( ).
. , , insert , . - ( , ).
, .
- .
, . :)
, aiohttp PostgreSQL 32 767 ( ).
- Descarga vacía
El controlador debe tener en cuenta este caso y no caerse, intentando realizar una inserción vacía en la tabla con los habitantes.
- Datos con errores, espere una respuesta HTTP de 400: Solicitud incorrecta.
- La fecha de nacimiento es incorrecta (tiempo futuro).
- citizen_id no es único dentro de la carga.
- Un parentesco se indica incorrectamente (solo hay de un residente a otro, pero no hay comentarios).
- El residente tiene un pariente inexistente en la descarga.
- Los lazos familiares no son únicos.
Si el procesador funcionó correctamente y se agregaron los datos, debe agregar los residentes a la base de datos y compararlos con la descarga estándar. Para conseguir residentes, utilicé el controlador ya probado GET /imports/$import_id/citizensy, para comparar, una función compare_citizen_groups.PARCHE / importaciones / $ import_id / ciudadanos / $ citizen_id
La validación de los datos es similar en muchos aspectos a la descrita en el controlador POST /importscon algunas excepciones: solo hay un residente y el cliente solo puede pasar los campos que desee .Decidí usar los siguientes conjuntos con datos incorrectos para verificar que el controlador devolverá una respuesta HTTP 400: Bad request:- El campo está especificado, pero tiene un tipo o formato de datos incorrecto
- La fecha de nacimiento es incorrecta (hora futura).
- El campo
relativescontiene un pariente que no existe en la descarga.
También es necesario verificar que el controlador actualice correctamente la información sobre el residente y sus familiares.Para hacer esto, cree una carga con tres habitantes, dos de los cuales son parientes, y envíe una solicitud con nuevos valores para todos los campos escalares y un nuevo identificador relativo en el campo relatives.Para asegurarme de que el controlador distinga entre los residentes de diferentes descargas antes de la prueba (y, por ejemplo, no cambia a los residentes con los mismos identificadores de otra descarga), creé una descarga adicional con tres residentes que tienen los mismos identificadores.El controlador debe guardar los nuevos valores de los campos escalares, agregar un nuevo pariente especificado y eliminar la relación con un pariente antiguo no especificado. Todos los cambios en el parentesco deben ser bilaterales. No debe haber cambios en otras descargas.Dado que dicho controlador puede estar sujeto a condiciones de carrera (esto se discutió en la sección Desarrollo), agregué dos pruebas adicionales . Uno reproduce el problema con el estado de la carrera (extiende la clase de controlador y elimina el bloqueo), el segundo prueba que el problema con el estado de la carrera no se reproduce.GET / importaciones / $ import_id / ciudadanos / cumpleaños
Para probar este controlador, seleccioné los siguientes conjuntos de datos:- Una descarga en la que un residente tiene un pariente en un mes y dos parientes en otro.
- Descarga con un residente sin parientes. Comprueba que el controlador no lo tenga en cuenta en los cálculos.
- Descarga vacía. Comprueba que el controlador no fallará y devolverá el diccionario correcto con 12 meses en la respuesta.
- Descarga con un residente que es un pariente suyo. Comprueba que un residente comprará un regalo para el mes de su nacimiento.
El controlador debe devolver todos los meses en la respuesta, incluso si no hay cumpleaños en estos meses. Para evitar la duplicación, hice una función a la que puedes pasar el diccionario para que lo complemente con valores para los meses que faltan.Para asegurarme de que el controlador distinga entre residentes de diferentes descargas, agregué una descarga adicional con dos parientes. Si el controlador los usa por error en los cálculos, los resultados serán incorrectos y el controlador caerá con un error.GET / imports / $ import_id / towns / stat / percentil / age
La peculiaridad de esta prueba es que los resultados de su trabajo dependen de la hora actual: la edad de los habitantes se calcula en función de la fecha actual. Para garantizar que los resultados de la prueba no cambien con el tiempo, se debe registrar la fecha actual, las fechas de nacimiento de los residentes y los resultados esperados. Esto facilitará la reproducción de cualquier caso, incluso borde.¿Cuál es la mejor fecha de reparación? El controlador utiliza la función PostgreSQL para calcular la edad de los residentes AGE, que toma el primer parámetro como la fecha para la que es necesario calcular la edad y el segundo como la fecha base (definida por una constante TownAgeStatView.CURRENT_DATE).Reemplazamos la fecha base en el controlador con el tiempo de pruebafrom unittest.mock import patch
import pytz
CURRENT_DATE = datetime(2020, 2, 17, tzinfo=pytz.utc)
@patch('analyzer.api.handlers.TownAgeStatView.CURRENT_DATE', new=CURRENT_DATE)
async def test_get_ages(...):
...
Para probar el controlador, seleccioné los siguientes conjuntos de datos (para todos los residentes indiqué una ciudad, porque el controlador agrega los resultados por ciudad):- Descarga con varios residentes cuyo cumpleaños es mañana (edad - varios años y 364 días). Comprueba que el procesador usa solo la cantidad de años completos en los cálculos.
- Descargar con un residente cuyo cumpleaños es hoy (edad, exactamente unos pocos años). Comprueba el caso regional: la edad de un residente cuyo cumpleaños es hoy no debe calcularse como reducida en 1 año.
- Descarga vacía. El controlador no debe caer sobre él.
El numpypunto de referencia para calcular percentiles, con interpolación lineal, y los resultados de referencia para las pruebas que calculé para ellos.También debe redondear los valores de percentiles fraccionarios a dos decimales. Si usó PostgreSQL para redondear en el controlador y Python para calcular los datos de referencia, puede notar que el redondeo en Python 3 y PostgreSQL puede dar resultados diferentes .por ejemplo# Python 3
round(2.5)
> 2
-- PostgreSQL
SELECT ROUND(2.5)
> 3
El hecho es que Python usa redondeo bancario al par más cercano , y PostgreSQL usa matemático (medio arriba). En caso de que los cálculos y el redondeo se realicen en PostgreSQL, también sería correcto usar el redondeo matemático en las pruebas.Al principio describí conjuntos de datos con fechas de nacimiento en formato de texto, pero fue inconveniente leer una prueba en este formato: cada vez que tenía que calcular la edad de cada habitante en mi mente para recordar lo que estaba comprobando un conjunto de datos en particular. Por supuesto, podría pasar con los comentarios en el código, pero decidí ir un poco más allá y escribí una función age2dateque le permite describir la fecha de nacimiento en forma de edad: la cantidad de años y días.Por ejemplo, asíimport pytz
from analyzer.utils.testing import generate_citizen
CURRENT_DATE = datetime(2020, 2, 17, tzinfo=pytz.utc)
def age2date(years: int, days: int = 0, base_date=CURRENT_DATE) -> str:
birth_date = copy(base_date).replace(year=base_date.year - years)
birth_date -= timedelta(days=days)
return birth_date.strftime(BIRTH_DATE_FORMAT)
generate_citizen(birth_date='17.02.2009')
generate_citizen(birth_date=age2date(years=11))
Para asegurarme de que el controlador distinga entre residentes de diferentes descargas, agregué una descarga adicional con un residente de otra ciudad: si el controlador lo usa por error, aparecerá una ciudad adicional en los resultados y la prueba se interrumpirá.Un hecho interesante: cuando escribí esta prueba el 29 de febrero de 2020, de repente dejé de generar descargas con los residentes debido a un error en Faker (2020 es un año bisiesto, y otros años que Faker eligió no siempre fueron años bisiestos en ellos también no fue el 29 de febrero). ¡Recuerde registrar fechas y probar casos límite!
Migraciones
El código de migración a primera vista parece obvio y menos propenso a errores, ¿por qué probarlo? Este es un error muy peligroso: los errores más insidiosos de las migraciones pueden manifestarse en el momento más inoportuno. Incluso si no estropean los datos, pueden causar tiempos de inactividad innecesarios.La migración inicial existente en el proyecto cambia la estructura de la base de datos, pero no cambia los datos. ¿Qué errores comunes pueden protegerse de tales migraciones?downgrade ( , , ).
, (--): , — .
- C .
- ( ).
La mayoría de estos errores serán detectados por la prueba de la escalera . Su idea - para usar una sola migración, realizando constantemente los métodos upgrade, downgrade, upgradepara cada migración. Tal prueba es suficiente para agregarse al proyecto una vez, no requiere soporte y servirá fielmente.Pero si la migración, además de la estructura, cambiara los datos, entonces sería necesario escribir al menos una prueba separada, verificando que los datos cambien correctamente en el método upgradey vuelvan al estado inicial downgrade. Por las dudas: un proyecto con ejemplos de pruebas de diferentes migraciones , que preparé para un informe sobre Alembic en Moscú Python.Montaje
El artefacto final que vamos a implementar y que queremos obtener como resultado del ensamblaje es una imagen de Docker. Para construir, debe seleccionar la imagen base con Python. La imagen oficial python:latestpesa ~ 1 GB y, si se usa como imagen base, la imagen con la aplicación será enorme. Hay imágenes basadas en el sistema operativo Alpine , cuyo tamaño es mucho más pequeño. Pero con el creciente número de paquetes instalados, el tamaño de la imagen final crecerá y, como resultado, incluso la imagen recopilada en base a Alpine no será tan pequeña. Elegí snakepacker / python como imagen base : pesa un poco más que las imágenes Alpine, pero se basa en Ubuntu, que ofrece una gran selección de paquetes y bibliotecas.De otra manerareduzca el tamaño de la imagen con la aplicación : no incluya en la imagen final el compilador, las bibliotecas y los archivos con encabezados para el ensamblaje, que no son necesarios para que la aplicación funcione.Para hacer esto, puede usar el ensamblaje de varias etapas de Docker:- Usando una imagen "pesada"
snakepacker/python:all(~ 1 GB, ~ 500 MB comprimidos), cree un entorno virtual, instale todas las dependencias y el paquete de la aplicación. Esta imagen se necesita exclusivamente para el ensamblaje, puede contener un compilador, todas las bibliotecas y archivos necesarios con encabezados.
FROM snakepacker/python:all as builder
RUN python3.8 -m venv /usr/share/python3/app
COPY dist/ /mnt/dist/
RUN /usr/share/python3/app/bin/pip install /mnt/dist/*
- Copiamos el entorno virtual terminado en una imagen "ligera"
snakepacker/python:3.8(~ 100 MB, comprimida ~ 50 MB), que contiene solo el intérprete de la versión requerida de Python.
Importante: en un entorno virtual, se utilizan rutas absolutas, por lo que debe copiarse en la misma dirección en la que se ensambló en el contenedor del recopilador.
FROM snakepacker/python:3.8 as api
COPY --from=builder /usr/share/python3/app /usr/share/python3/app
RUN ln -snf /usr/share/python3/app/bin/analyzer-* /usr/local/bin/
CMD ["analyzer-api"]
Para reducir el tiempo que lleva construir la imagen , los módulos dependientes de la aplicación pueden instalarse antes de instalarse en el entorno virtual. Luego, Docker los almacenará en caché y no se reinstalará si no han cambiado.Dockerfile por completo
FROM snakepacker/python:all as builder
RUN python3.8 -m venv /usr/share/python3/app
RUN /usr/share/python3/app/bin/pip install -U pip
COPY requirements.txt /mnt/
RUN /usr/share/python3/app/bin/pip install -Ur /mnt/requirements.txt
COPY dist/ /mnt/dist/
RUN /usr/share/python3/app/bin/pip install /mnt/dist/* \
&& /usr/share/python3/app/bin/pip check
FROM snakepacker/python:3.8 as api
COPY --from=builder /usr/share/python3/app /usr/share/python3/app
RUN ln -snf /usr/share/python3/app/bin/analyzer-* /usr/local/bin/
CMD ["analyzer-api"]
Para facilitar el montaje, agregué un comando make uploadque recopila la imagen de Docker y la carga en hub.docker.com.Ci
Ahora que el código está cubierto con pruebas y podemos construir una imagen de Docker, es hora de automatizar estos procesos. Lo primero que viene a la mente: ejecute pruebas para crear solicitudes de grupo y, cuando agregue cambios a la rama maestra, recopile una nueva imagen de Docker y cárguela en Docker Hub (o paquetes de GitHub , si no va a distribuir la imagen públicamente).Resolví este problema con las acciones de GitHub . Para hacer esto, era necesario crear un archivo YAML en una carpeta .github/workflowsy describir en él un flujo de trabajo (con dos tareas: testy publish), que nombré CI.La tarea testse ejecuta cada vez que se inicia el flujo de trabajo CI, utilizando serviciosrecoge un contenedor con PostgreSQL, espera a que esté disponible y se inicia pytesten el contenedor snakepacker/python:all.La tarea publishse realiza solo si los cambios se han agregado a la rama mastery si la tarea testfue exitosa. Ella recopila la distribución de origen por el contenedor snakepacker/python:all, luego recopila y carga la imagen de Docker docker/build-push-action@v1.Descripción completa del flujo de trabajo.name: CI
# Workflow
# - master
on:
push:
branches: [ master ]
pull_request:
branches: [ master ]
jobs:
# workflow
test:
runs-on: ubuntu-latest
services:
postgres:
image: docker://postgres
ports:
- 5432:5432
env:
POSTGRES_USER: user
POSTGRES_PASSWORD: hackme
POSTGRES_DB: analyzer
steps:
- uses: actions/checkout@v2
- name: test
uses: docker://snakepacker/python:all
env:
CI_ANALYZER_PG_URL: postgresql://user:hackme@postgres/analyzer
with:
args: /bin/bash -c "pip install -U '.[dev]' && pylama && wait-for-port postgres:5432 && pytest -vv --cov=analyzer --cov-report=term-missing tests"
# Docker-
publish:
# master
if: github.event_name == 'push' && github.ref == 'refs/heads/master'
# , test
needs: test
runs-on: ubuntu-latest
steps:
- uses: actions/checkout@v2
- name: sdist
uses: docker://snakepacker/python:all
with:
args: make sdist
- name: build-push
uses: docker/build-push-action@v1
with:
username: ${{ secrets.REGISTRY_LOGIN }}
password: ${{ secrets.REGISTRY_TOKEN }}
repository: alvassin/backendschool2019
target: api
tags: 0.0.1, latest
Ahora, al agregar cambios al maestro en la pestaña Acciones en GitHub, puede ver el inicio de las pruebas, el ensamblaje y la carga de la imagen de Docker: y al crear una solicitud de grupo en la rama maestra, los resultados de la tarea también se mostrarán en ella
y al crear una solicitud de grupo en la rama maestra, los resultados de la tarea también se mostrarán en ella test:
Desplegar
Para implementar la aplicación en el servidor proporcionado, debe instalar Docker, Docker Compose, iniciar los contenedores con la aplicación y PostgreSQL y aplicar las migraciones.Estos pasos pueden automatizarse utilizando el sistema de gestión de configuración de Ansible. Está escrito en Python, no requiere agentes especiales (se conecta directamente a través de ssh), utiliza plantillas jinja y permite describir declarativamente el estado deseado en los archivos YAML. El enfoque declarativo le permite no pensar en el estado actual del sistema y las acciones necesarias para llevar el sistema al estado deseado. Todo este trabajo descansa sobre los hombros de los módulos Ansible.Ansible le permite agrupar tareas relacionadas lógicamente en roles y luego reutilizarlas. Necesitaremos dos roles:docker(instala y configura Docker) y analyzer(instala y configura la aplicación).El roldocker agrega un repositorio con Docker al sistema, instala y configura paquetes docker-cey docker-compose.Opcionalmente, puede configurar la API REST para que se reanude automáticamente después de reiniciar el servidor. Ubuntu le permite resolver este problema con la ayuda de un sistema de inicialización systemd. Controla unidades que representan varios recursos (demonios, sockets, puntos de montaje y otros). Para agregar una nueva unidad a systemd, debe describir su configuración en un archivo .service separado y colocar este archivo en una de las carpetas especiales, por ejemplo, en /etc/systemd/system. Luego se puede iniciar la unidad, así como habilitar la carga automática para ella.Paquetedocker-cedurante la instalación, creará automáticamente un archivo con la configuración de la unidad; solo necesita asegurarse de que se está ejecutando y se enciende cuando se inicia el sistema. Para Docker Compose docker-compose@.serviceserá creado por Ansible. El símbolo @en el nombre indica a systemd que la unidad es una plantilla. Esto le permite iniciar el servicio docker-composecon un parámetro, por ejemplo, con el nombre de nuestro servicio, que se sustituirá %ien el archivo de configuración de la unidad:[Unit]
Description=%i service with docker compose
Requires=docker.service
After=docker.service
[Service]
Type=oneshot
RemainAfterExit=true
WorkingDirectory=/etc/docker/compose/%i
ExecStart=/usr/local/bin/docker-compose up -d --remove-orphans
ExecStop=/usr/local/bin/docker-compose down
[Install]
WantedBy=multi-user.target
El rolanalyzer generará un archivo desde la plantilla docker-compose.ymlen la dirección /etc/docker/compose/analyzer, registrará la aplicación como un servicio lanzado automáticamente systemdy aplicará la migración. Cuando los roles estén listos, debe describir el libro de jugadas.---
- name: Gathering facts
hosts: all
become: yes
gather_facts: yes
- name: Install docker
hosts: docker
become: yes
gather_facts: no
roles:
- docker
- name: Install analyzer
hosts: api
become: yes
gather_facts: no
roles:
- analyzer
La lista de hosts, así como las variables utilizadas en los roles, se pueden especificar en el archivo de inventario hosts.ini.[api]
130.193.51.154
[docker:children]
api
[api:vars]
analyzer_image = alvassin/backendschool2019
analyzer_pg_user = user
analyzer_pg_password = hackme
analyzer_pg_dbname = analyzer
Después de que todos los archivos Ansible estén listos, ejecútelos:$ ansible-playbook -i hosts.ini deploy.yml
Sobre pruebas de estrés, , . , -
. : , — , 10 . , (, , CI-): .
, , , 10 . ? , , . , , .
RPS, : . , ,
import_id,
POST /imports . .
, Python 3,
Locust.
,
locustfile.py locust. - .
Locust . , .
self.round .
locustfile.py
import logging
from http import HTTPStatus
from locust import HttpLocust, constant, task, TaskSet
from locust.exception import RescheduleTask
from analyzer.api.handlers import (
CitizenBirthdaysView, CitizensView, CitizenView, TownAgeStatView
)
from analyzer.utils.testing import generate_citizen, generate_citizens, url_for
class AnalyzerTaskSet(TaskSet):
def __init__(self, *args, **kwargs):
super().__init__(*args, **kwargs)
self.round = 0
def make_dataset(self):
citizens = [
generate_citizen(citizen_id=1, relatives=[2]),
generate_citizen(citizen_id=2, relatives=[1]),
*generate_citizens(citizens_num=9998, relations_num=1000,
start_citizen_id=3)
]
return {citizen['citizen_id']: citizen for citizen in citizens}
def request(self, method, path, expected_status, **kwargs):
with self.client.request(
method, path, catch_response=True, **kwargs
) as resp:
if resp.status_code != expected_status:
resp.failure(f'expected status {expected_status}, '
f'got {resp.status_code}')
logging.info(
'round %r: %s %s, http status %d (expected %d), took %rs',
self.round, method, path, resp.status_code, expected_status,
resp.elapsed.total_seconds()
)
return resp
def create_import(self, dataset):
resp = self.request('POST', '/imports', HTTPStatus.CREATED,
json={'citizens': list(dataset.values())})
if resp.status_code != HTTPStatus.CREATED:
raise RescheduleTask
return resp.json()['data']['import_id']
def get_citizens(self, import_id):
url = url_for(CitizensView.URL_PATH, import_id=import_id)
self.request('GET', url, HTTPStatus.OK,
name='/imports/{import_id}/citizens')
def update_citizen(self, import_id):
url = url_for(CitizenView.URL_PATH, import_id=import_id, citizen_id=1)
self.request('PATCH', url, HTTPStatus.OK,
name='/imports/{import_id}/citizens/{citizen_id}',
json={'relatives': [i for i in range(3, 10)]})
def get_birthdays(self, import_id):
url = url_for(CitizenBirthdaysView.URL_PATH, import_id=import_id)
self.request('GET', url, HTTPStatus.OK,
name='/imports/{import_id}/citizens/birthdays')
def get_town_stats(self, import_id):
url = url_for(TownAgeStatView.URL_PATH, import_id=import_id)
self.request('GET', url, HTTPStatus.OK,
name='/imports/{import_id}/towns/stat/percentile/age')
@task
def workflow(self):
self.round += 1
dataset = self.make_dataset()
import_id = self.create_import(dataset)
self.get_citizens(import_id)
self.update_citizen(import_id)
self.get_birthdays(import_id)
self.get_town_stats(import_id)
class WebsiteUser(HttpLocust):
task_set = AnalyzerTaskSet
wait_time = constant(1)
100 c , , :

, ( — 95 , — ). .

— Ansible ~20.15 ~20.30 Locust.

Qué más se puede hacer?
La creación de perfiles de la aplicación mostró que aproximadamente una cuarta parte del tiempo total de ejecución de la consulta se gasta en serializar y deserializar JSON: hay muchos datos enviados y recibidos del servicio. Estos procesos pueden acelerarse significativamente usando la biblioteca orjson , pero el servicio tendrá que estar preparado un poco, orjsonno es un reemplazo jsondirecto para el módulo estándar. Por lo general, la producción requiere varias copias del servicio para garantizar la tolerancia a fallas y hacer frente a la carga. Para administrar un grupo de servicios, necesita una herramienta que muestre si una copia del servicio está "viva". Este problema puede resolverse mediante un controlador /healthque sondee todos los recursos necesarios para el trabajo, en nuestro caso, una base de datos. SiSELECT 1ejecutado en menos de un segundo, entonces el servicio está vivo. Si no, debes prestarle atención.Cuando una aplicación trabaja de manera muy intensiva con una red, uvloop puede aumentar el rendimiento de manera genial .Un factor importante es la legibilidad del código. Uno de mis colegas, Yuri Shikanov, escribió un módulo gris que combina varias herramientas para la verificación automática y la ejecución de código, que es fácil de agregar a un pre-commitenlace Git, configurado con un solo archivo de configuración o variables de entorno. Gray le permite ordenar las importaciones ( isort ), optimiza las expresiones de python según las nuevas versiones del lenguaje ( pyupgrade ), agrega comas al final de las llamadas a funciones, importaciones, listas, etc. (add-trailing-comma ), y también cita a un solo formulario ( unificar ).* * *
Eso es todo para mí: desarrollamos, cubrimos con pruebas, ensamblamos e implementamos el servicio, y también realizamos pruebas de carga.Expresiones de gratitud
Me gustaría expresar mi profunda gratitud a los muchachos que se tomaron el tiempo para participar en la redacción de este artículo, para revisar el código, para presentar mis ideas y comentarios: a Maria Zelenova zelmaVladimir Solomatin leenrAnastasia Semenova morkovYuri Shikanov dizballanzeMikhail Shushpanov mishushPavel Mosein Pavkazzz y especialmente a Dmitry Orlov orlovdl.