La computación paralela fascina con lo inesperado de su comportamiento. Pero el comportamiento conjunto de los procesos no puede ser impredecible. Solo en este caso puede ser estudiado y entendido en sus peculiaridades. La concurrencia moderna de subprocesos múltiples es única. En un sentido literal. Y esta es toda su mala esencia. La esencia que puede y debe ser influenciada. La esencia, que debería, en el buen sentido, hace mucho tiempo que ha cambiado ...Aunque hay otra opción. No hay necesidad de cambiar nada y / o influir en algo. Que haya múltiples subprocesos y corutinas, que sea ... y programación automática paralela (AP). Dejen que compitan y, cuando sea necesario y posible, se complementen entre sí. En este sentido, el paralelismo moderno tiene al menos un plus: le permite hacer esto.Bueno, vamos a competir!1. De serie a paralelo
Considere programar la ecuación aritmética más simple:C2 = A + B + A1 + B1; (1)Que haya bloques que implementen operaciones aritméticas simples. En este caso, los bloques de suma son suficientes. Una idea clara y precisa del número de bloques, su estructura y las relaciones entre ellos da arroz. 1. Y en la Fig. 2. La configuración del medio VKP (a) se da para resolver la ecuación (1).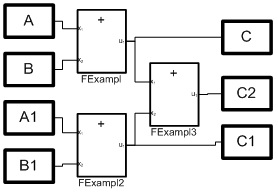 Figura 1. Modelo estructural de procesosPero el diagrama estructural de la Fig. 1 corresponde a un sistema de tres ecuaciones:= A + B;C1 = A1 + B; (2)C2 = C + C1;Al mismo tiempo (2), esta es una implementación paralela de la ecuación (1), que es un algoritmo para sumar una matriz de números, también conocido como algoritmo de duplicación. Aquí la matriz está representada por cuatro números A, B, A1, B1, las variables C y C1 son resultados intermedios, y C2 es la suma de la matriz.
Figura 1. Modelo estructural de procesosPero el diagrama estructural de la Fig. 1 corresponde a un sistema de tres ecuaciones:= A + B;C1 = A1 + B; (2)C2 = C + C1;Al mismo tiempo (2), esta es una implementación paralela de la ecuación (1), que es un algoritmo para sumar una matriz de números, también conocido como algoritmo de duplicación. Aquí la matriz está representada por cuatro números A, B, A1, B1, las variables C y C1 son resultados intermedios, y C2 es la suma de la matriz.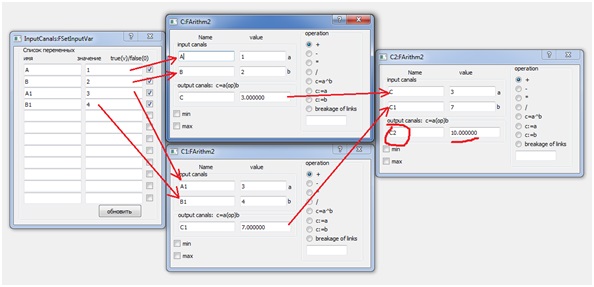 Figura 2. Tipo de diálogos para la configuración de tres procesos paralelos
Figura 2. Tipo de diálogos para la configuración de tres procesos paralelos
Las características de implementación incluyen la continuidad de su operación, cuando cualquier cambio en los datos de entrada conduce a un recuento del resultado. Después de cambiar los datos de entrada, tomará dos ciclos de reloj, y cuando los bloques estén conectados en serie, se logrará el mismo efecto en tres ciclos de reloj. Y cuanto mayor sea la matriz, mayor será la ganancia de velocidad.2. La concurrencia como problema
No se sorprenda si se le llamarán muchos argumentos a favor de una solución paralela particular, pero no mencionarán los posibles problemas que están completamente ausentes en la programación secuencial ordinaria. La razón principal de la interpretación similar del problema de la correcta implementación del paralelismo. Dicen lo menos sobre ella. Si acaso dicen. Lo tocaremos en la parte relacionada con el acceso paralelo a los datos.Cualquier proceso puede representarse como muchos pasos consecutivos indivisibles. Para muchos procesos, en cada uno de estos pasos, las acciones que pertenecen a todos los procesos se ejecutan simultáneamente. Y aquí bien podemos encontrar un problema que se manifiesta en el siguiente ejemplo elemental.Supongamos que hay dos procesos paralelos que corresponden al siguiente sistema de ecuaciones:c = a + b; (3)a = b + c;Suponga que a las variables a, b, c se les asignan los valores iniciales 1, 1, 0. Podemos esperar que el protocolo de cálculo para los cinco pasos sea el siguiente:a b c
1.000 1.000 0.000
1.000 1.000 2.000
3.000 1.000 2.000
3.000 1.000 4.000
5.000 1.000 4.000
5.000 1.000 6.000
Al formarlo, procedimos del hecho de que los operadores se ejecutan en paralelo (simultáneamente) y dentro de una medida discreta (paso). Para las declaraciones en bucle, será una iteración del bucle. También podemos suponer que en el proceso de cálculo las variables tienen valores fijos al comienzo de una medida discreta, y su cambio ocurre al final. Esto es bastante consistente con la situación real, cuando lleva un tiempo completar la operación. A menudo se asocia con un retraso inherente a un bloque dado.Pero, muy probablemente, obtendrá algo como este protocolo: a b c
1.000 1.000 0.000
3.000 1.000 2.000
5.000 1.000 4.000
7.000 1.000 6.000
9.000 1.000 8.000
11.000 1.000 10.000
Es equivalente al trabajo de un proceso que ejecuta dos declaraciones consecutivas en un ciclo:c = a + b; a = b + c; (4)Pero puede suceder que la ejecución de las declaraciones sea exactamente lo contrario, y luego el protocolo será el siguiente: a b c
1.000 1.000 0.000
1.000 1.000 2.000
3.000 1.000 4.000
5.000 1.000 6.000
7.000 1.000 8.000
9.000 1.000 10.000
En la programación multiproceso, la situación es aún peor. En ausencia de sincronización de procesos, no solo es difícil predecir la secuencia de lanzamiento de los operadores, sino que su trabajo también se verá interrumpido en cualquier lugar. Todo esto no puede sino afectar los resultados del trabajo conjunto de los operadores.Dentro del marco de la tecnología AP, se permite trabajar con variables de proceso comunes de manera simple y correcta. Aquí, con mayor frecuencia, no se requieren esfuerzos especiales para sincronizar procesos y trabajar con datos. Pero será necesario señalar acciones que se considerarán condicionalmente instantáneas e indivisibles, así como crear modelos de procesos automáticos. En nuestro caso, las acciones serán operadores de suma y los autómatas con transiciones cíclicas serán responsables de su lanzamiento.El Listado 1 muestra el código para un proceso que implementa la operación de suma. Su modelo es una máquina de estados finitos (ver Fig. 3) con un estado y una transición de bucle incondicional, para la cual la única acción y1, después de haber realizado la operación de sumar dos variables, coloca el resultado en el tercero. Fig. 3. Modelo automatizado de la operación de suma.
Fig. 3. Modelo automatizado de la operación de suma.Listado 1. Implementación de un proceso de autómata para una operación de suma#include "lfsaappl.h"
class FSumABC :
public LFsaAppl
{
public:
LFsaAppl* Create(CVarFSA *pCVF) { Q_UNUSED(pCVF)return new FSumABC(nameFsa); }
bool FCreationOfLinksForVariables();
FSumABC(string strNam);
CVar *pVarA;
CVar *pVarB;
CVar *pVarC;
CVar *pVarStrNameA;
CVar *pVarStrNameB;
CVar *pVarStrNameC;
protected:
void y1();
};
#include "stdafx.h"
#include "FSumABC.h"
static LArc TBL_SumABC[] = {
LArc("s1", "s1","--", "y1"),
LArc()
};
FSumABC::FSumABC(string strNam):
LFsaAppl(TBL_SumABC, strNam, nullptr, nullptr)
{ }
bool FSumABC::FCreationOfLinksForVariables() {
pVarA = CreateLocVar("a", CLocVar::vtBool, "variable a");
pVarB = CreateLocVar("b", CLocVar::vtBool, "variable c");
pVarC = CreateLocVar("c", CLocVar::vtBool, "variable c");
pVarStrNameA = CreateLocVar("strNameA", CLocVar::vtString, "");
string str = pVarStrNameA->strGetDataSrc();
if (str != "") { pVarA = pTAppCore->GetAddressVar(pVarStrNameA->strGetDataSrc().c_str(), this); }
pVarStrNameB = CreateLocVar("strNameB", CLocVar::vtString, "");
str = pVarStrNameB->strGetDataSrc();
if (str != "") { pVarB = pTAppCore->GetAddressVar(pVarStrNameB->strGetDataSrc().c_str(), this); }
pVarStrNameC = CreateLocVar("strNameC", CLocVar::vtString, "");
str = pVarStrNameC->strGetDataSrc();
if (str != "") { pVarC = pTAppCore->GetAddressVar(pVarStrNameC->strGetDataSrc().c_str(), this); }
return true;
}
void FSumABC::y1() {
pVarC->SetDataSrc(this, pVarA->GetDataSrc() + pVarB->GetDataSrc());
}
Importante, o más bien, incluso necesario, aquí es el uso de las variables de entorno del PCUS. Sus "propiedades de sombra" aseguran la correcta interacción de los procesos. Además, el entorno le permite cambiar el modo de operación, excluyendo el registro de variables en la memoria intermedia de sombra. Un análisis de los protocolos obtenidos en este modo nos permite verificar la necesidad de utilizar variables de sombra.3. ¿Y las corutinas? ...
Sería bueno saber cómo las corutinas representadas por el lenguaje Kotlin harán frente a la tarea. Tomemos como plantilla de solución el programa considerado en la discusión de [1]. Tiene una estructura que se reduce fácilmente al aspecto requerido. Para hacer esto, reemplace las variables lógicas con un tipo numérico y agregue otra variable, y en lugar de operaciones lógicas usaremos la operación de suma. El código correspondiente se muestra en el listado 2.Listado 2. Programa de suma paralela de Kotlinimport kotlinx.coroutines.*
suspend fun main() =
coroutineScope {
var a = 1
var b = 1
var c = 0;
withContext(Dispatchers.Default) {
for (i in 0..4) {
var res = listOf(async { a+b }, async{ b+c }).map { it.await() }
c = res[0]
a = res[1]
println("$a, $b, $c")
}
}
}
No hay preguntas sobre el resultado de este programa, ya que coincide exactamente con el primero de los protocolos anteriores.Sin embargo, la conversión del código fuente no fue tan obvia como podría parecer, porque Parecía natural usar el siguiente fragmento de código:listOf(async { = a+b }, async{ = b+c })
Como lo demuestran las pruebas (esto se puede hacer en línea en el sitio web de Kotlin, kotlinlang.org/#try-kotlin ), su uso conduce a un resultado completamente impredecible, que también cambia de un lanzamiento a otro. Y solo un análisis más cuidadoso del programa fuente condujo al código correcto.El código que contiene un error desde el punto de vista del funcionamiento del programa, pero es legítimo desde el punto de vista del lenguaje, nos hace temer por la confiabilidad de los programas en él. Esta opinión, probablemente, puede ser cuestionada por los expertos de Kotlin. Sin embargo, la facilidad de cometer un error, que no puede explicarse solo por la falta de comprensión de la "programación de rutina", sin embargo, está presionando persistentemente para llegar a tales conclusiones.4. Máquinas de eventos en Qt
Anteriormente, establecimos que un autómata de eventos no es un autómata en su definición clásica. Es bueno o malo, pero hasta cierto punto, la máquina de eventos sigue siendo un pariente de las máquinas clásicas. Es distante, cercano, pero debemos hablar de ello directamente para que no haya conceptos erróneos sobre esto. Comenzamos a hablar de esto en [2], pero todo por continuar. Ahora haremos esto examinando otros ejemplos del uso de máquinas de eventos en Qt.Por supuesto, un autómata de eventos puede considerarse como un caso degenerado de un autómata clásico con una duración de ciclo indefinida y / o variable asociada con un evento. La posibilidad de tal interpretación se mostró en un artículo anterior al resolver solo uno y, además, un ejemplo bastante específico (ver detalles [2]). A continuación, intentaremos eliminar esta brecha.La biblioteca Qt solo asocia transiciones de máquina con eventos, lo cual es una limitación seria. Por ejemplo, en el mismo lenguaje UML, una transición está asociada no solo con un evento llamado evento iniciador, sino también con una condición protectora, una expresión lógica calculada después de que se recibe el evento [3]. En MATLAB, la situación se mitiga más y suena así: "si no se especifica el nombre del evento, la transición ocurrirá cuando ocurra cualquier evento" [4]. Pero aquí y allá, la causa raíz de la transición es el evento / s. Pero, ¿y si no hay eventos?Si no hay eventos, entonces ... puedes intentar crearlos. Listado 3 y Figura 4 demuestre cómo hacer esto, utilizando el descendiente de la clase de autómata LFsaAppl del entorno VKPa como un "contenedor" del evento Qt-class. Aquí, la acción y2 con una periodicidad del tiempo discreto del espacio del autómata envía una señal que inicia el inicio de la transición del autómata Qt. Este último, utilizando el método s0Exited, inicia la acción y1, que implementa la operación de suma. Tenga en cuenta que la máquina de eventos es creada por la acción y3 estrictamente después de verificar la inicialización de las variables locales de la clase LFsaAppl. Fig.4. Combinación de máquinas clásicas y de eventos.
Fig.4. Combinación de máquinas clásicas y de eventos.
Listado 3. Implementación de un modelo de suma con un autómata de eventos#include "lfsaappl.h"
class QStateMachine;
class QState;
class FSumABC :
public QObject,
public LFsaAppl
{
Q_OBJECT
...
protected:
int x1();
void y1(); void y2(); void y3(); void y12();
signals:
void GoState();
private slots:
void s0Exited();
private:
QStateMachine * machine;
QState * s0;
};
#include "stdafx.h"
#include "FSumABC.h"
#include <QStateMachine>
#include <QState>
static LArc TBL_SumABC[] = {
LArc("st", "st","^x1", "y12"),
LArc("st", "s1","x1", "y3"),
LArc("s1", "s1","--", "y2"),
LArc()
};
FSumABC::FSumABC(string strNam):
QObject(),
LFsaAppl(TBL_SumABC, strNam, nullptr, nullptr)
{ }
...
int FSumABC::x1() { return pVarA&&pVarB&&pVarC; }
void FSumABC::y1() {
pVarC->SetDataSrc(this, pVarA->GetDataSrc() + pVarB->GetDataSrc());
}
void FSumABC::y2() { emit GoState(); }
void FSumABC::y3() {
s0 = new QState();
QSignalTransition *ps = s0->addTransition(this, SIGNAL(GoState()), s0);
connect (s0, SIGNAL(entered()), this, SLOT(s0Exited()));
machine = new QStateMachine(nullptr);
machine->addState(s0);
machine->setInitialState(s0);
machine->start();
}
void FSumABC::y12() { FInit(); }
void FSumABC::s0Exited() { y1(); }
Arriba, implementamos una máquina muy simple. O, más precisamente, una combinación de autómatas clásicos y de eventos. Si la implementación anterior de la clase FSumABC se reemplaza por la creada, entonces simplemente no habrá diferencias en la aplicación. Pero para modelos más complejos, las propiedades limitadas de los autómatas controlados por eventos comienzan a manifestarse por completo. Como mínimo, ya en proceso de crear un modelo. El Listado 4 muestra la implementación del modelo del elemento AND-NOT en forma de un autómata de evento (para más detalles sobre el modelo de autómata utilizado del elemento AND-NOT, consulte [2]).Listado 4. Implementando un modelo de elemento Y NO por una máquina de eventos#include <QObject>
class QStateMachine;
class QState;
class MainWindow;
class ine : public QObject
{
Q_OBJECT
public:
explicit ine(MainWindow *parent = nullptr);
bool bX1, bX2, bY;
signals:
void GoS0();
void GoS1();
private slots:
void s1Exited();
void s0Exited();
private:
QStateMachine * machine;
QState * s0;
QState * s1;
MainWindow *pMain{nullptr};
friend class MainWindow;
};
#include "ine.h"
#include <QStateMachine>
#include <QState>
#include "mainwindow.h"
#include "ui_mainwindow.h"
ine::ine(MainWindow *parent) :
QObject(parent)
{
pMain = parent;
s0 = new QState();
s1 = new QState();
s0->addTransition(this, SIGNAL(GoS1()), s1);
s1->addTransition(this, SIGNAL(GoS0()), s0);
connect (s0, SIGNAL(entered()), this, SLOT(s0Exited()));
connect (s1, SIGNAL(entered()), this, SLOT(s1Exited()));
machine = new QStateMachine(nullptr);
machine->addState(s0);
machine->addState(s1);
machine->setInitialState(s1);
machine->start();
}
void ine::s1Exited() {
bY = !(bX1&&bX2);
pMain->ui->checkBoxY->setChecked(bY);
}
void ine::s0Exited() {
bY = !(bX1&&bX2);
pMain->ui->checkBoxY->setChecked(bY);
}
Queda claro que los autómatas de eventos en Qt se basan estrictamente en los autómatas de Moore. Esto limita las capacidades y la flexibilidad del modelo, ya que las acciones están asociadas solo con estados. Como resultado, por ejemplo, es imposible distinguir entre dos transiciones del estado 0 a 1 para el autómata que se muestra en la Fig. 4 en [2].Por supuesto, para implementar las millas, puede utilizar el procedimiento bien conocido para cambiar a máquinas Moore. Pero esto conduce a un aumento en el número de estados y elimina la asociación simple, visual y útil de los estados modelo con el resultado de sus acciones. Por ejemplo, después de tales transformaciones, los dos estados del autómata Moore deben coincidir con el estado único de la salida del modelo 1 de [2].En un modelo más complejo, los problemas con las condiciones de transición comienzan a aparecer con obviedad. Para sortearlos para la implementación de software del elemento AND-NOT en consideración, se incorporó un análisis del estado de los canales de entrada en el diálogo de control del modelo, como se muestra en el Listado 5.Listado 5. Diálogo de control del elemento NAND#include "mainwindow.h"
#include "ui_mainwindow.h"
#include "ine.h"
MainWindow::MainWindow(QWidget *parent)
: QMainWindow(parent)
, ui(new Ui::MainWindow)
{
ui->setupUi(this);
pine = new ine(this);
connect(this, SIGNAL(GoState0()), pine, SIGNAL(GoS0()));
connect(this, SIGNAL(GoState1()), pine, SIGNAL(GoS1()));
}
MainWindow::~MainWindow()
{
delete ui;
}
void MainWindow::on_checkBoxX1_clicked(bool checked)
{
bX1 = checked;
pine->bX1 = bX1;
bY = !(bX1&&bX2);
if (!(bX1&&bX2)) emit GoState0();
else emit GoState1();
}
void MainWindow::on_checkBoxX2_clicked(bool checked)
{
bX2 = checked;
pine->bX2 = bX2;
bY = !(bX1&&bX2);
if (!(bX1&&bX2)) emit GoState0();
else emit GoState1();
}
En resumen, todo lo anterior complica claramente el modelo y crea problemas para comprender su trabajo. Además, tales soluciones locales pueden no funcionar cuando se consideran composiciones de ellas. Un buen ejemplo en este caso sería un intento de crear un modelo de disparador RS (para más detalles sobre un modelo de autómata de dos componentes de un disparador RS ver [5]). Sin embargo, el placer del resultado logrado se entregará a los fanáticos de las máquinas de eventos. Si ... a menos que, por supuesto, tengan éxito;)5. Función cuadrática y ... ¿mariposa?
Es conveniente representar los datos de entrada como un proceso paralelo externo. Encima de esto estaba el diálogo para administrar el modelo de un elemento AND-NOT. Además, la tasa de cambio de datos puede afectar significativamente el resultado. Para confirmar esto, consideramos el cálculo de la función cuadrática y = ax² + bx + c, que implementamos en forma de un conjunto de bloques interactivos y de funcionamiento paralelo.Se sabe que el gráfico de una función cuadrática tiene la forma de una parábola. Pero la parábola representada por el matemático y la parábola que mostrará el osciloscopio, por ejemplo, estrictamente hablando, nunca coincidirán. La razón de esto es que el matemático a menudo piensa en categorías instantáneas, creyendo que un cambio en la cantidad de entrada conduce inmediatamente al cálculo de la función. Pero en la vida real esto no es del todo cierto. La apariencia del gráfico de función dependerá de la velocidad de la calculadora, de la velocidad de cambio de los datos de entrada, etc. etc. Sí, y los propios programas de velocidad pueden diferir entre sí. Estos factores afectarán la forma de la función, en la forma en que en cierta situación será difícil adivinar la parábola. Estaremos más convencidos de esto.Entonces, agregamos al bloque sumador los bloques de multiplicación, división y exponenciación. Con tal conjunto, podemos "recopilar" expresiones matemáticas de cualquier complejidad. Pero también podemos tener "cubos" que implementan funciones más complejas. Fig.5. La implementación de una función cuadrática se muestra en dos versiones: bloque múltiple (ver flecha con una etiqueta - 1, y también Fig. 6) y una variante de un bloque (en la figura 5 flecha con una etiqueta 2). Fig.5. Dos opciones para implementar la función cuadrática
Fig.5. Dos opciones para implementar la función cuadrática Fig. 6. Modelo estructural para calcular una función cuadráticaQue en la figura 5. parece "borroso" (ver flecha marcada 3), cuando se amplía adecuadamente (ver gráficos (tendencias), marcado 4), está convencido de que el asunto no está en las propiedades gráficas. Este es el resultado de la influencia del tiempo en el cálculo de las variables: la variable y1 es el valor de salida de la variante multibloque (color rojo del gráfico) y la variable y2 es el valor de salida de la variante de bloque único (color negro). Pero ambos gráficos son diferentes de los "gráficos abstractos" [y2 (t), x (t-1)] (verde). Este último se construye para el valor de la variable y2 y el valor de la variable de entrada retrasado en un ciclo de reloj (vea la variable con el nombre x [t-1]).Por lo tanto, cuanto mayor sea la tasa de cambio de la función de entrada x (t), más fuerte será el "efecto de desenfoque" y más lejos estarán los gráficos y1, y2 del gráfico [y2 (t), x (t-1)]. El "defecto" detectado puede usarse para sus propios fines. Por ejemplo, nada nos impide aplicar una señal sinusoidal a la entrada. Consideraremos una opción aún más complicada, cuando el primer coeficiente de la ecuación también cambie de manera similar. El resultado del experimento demuestra una pantalla del medio VKPa, que se muestra en la Fig. 7.
Fig. 6. Modelo estructural para calcular una función cuadráticaQue en la figura 5. parece "borroso" (ver flecha marcada 3), cuando se amplía adecuadamente (ver gráficos (tendencias), marcado 4), está convencido de que el asunto no está en las propiedades gráficas. Este es el resultado de la influencia del tiempo en el cálculo de las variables: la variable y1 es el valor de salida de la variante multibloque (color rojo del gráfico) y la variable y2 es el valor de salida de la variante de bloque único (color negro). Pero ambos gráficos son diferentes de los "gráficos abstractos" [y2 (t), x (t-1)] (verde). Este último se construye para el valor de la variable y2 y el valor de la variable de entrada retrasado en un ciclo de reloj (vea la variable con el nombre x [t-1]).Por lo tanto, cuanto mayor sea la tasa de cambio de la función de entrada x (t), más fuerte será el "efecto de desenfoque" y más lejos estarán los gráficos y1, y2 del gráfico [y2 (t), x (t-1)]. El "defecto" detectado puede usarse para sus propios fines. Por ejemplo, nada nos impide aplicar una señal sinusoidal a la entrada. Consideraremos una opción aún más complicada, cuando el primer coeficiente de la ecuación también cambie de manera similar. El resultado del experimento demuestra una pantalla del medio VKPa, que se muestra en la Fig. 7. Fig. 7. Resultados de simulación con una señal de entrada sinusoidalLa pantalla en la parte inferior izquierda muestra la señal suministrada a las entradas de las realizaciones de una función cuadrática. Arriba están las gráficas de los valores de salida y1 e y2. Los gráficos en forma de "alas" son valores trazados en dos coordenadas. Entonces, con la ayuda de varias realizaciones de la función cuadrática, dibujamos la mitad de la "mariposa". Dibujar un todo es una cuestión de tecnología ...Pero las paradojas del paralelismo no terminan ahí. En la Fig. La Figura 8 muestra las tendencias en el cambio "inverso" de la variable independiente x. Ya pasan a la izquierda del gráfico "abstracto" (este último, notamos, ¡no ha cambiado su posición!).
Fig. 7. Resultados de simulación con una señal de entrada sinusoidalLa pantalla en la parte inferior izquierda muestra la señal suministrada a las entradas de las realizaciones de una función cuadrática. Arriba están las gráficas de los valores de salida y1 e y2. Los gráficos en forma de "alas" son valores trazados en dos coordenadas. Entonces, con la ayuda de varias realizaciones de la función cuadrática, dibujamos la mitad de la "mariposa". Dibujar un todo es una cuestión de tecnología ...Pero las paradojas del paralelismo no terminan ahí. En la Fig. La Figura 8 muestra las tendencias en el cambio "inverso" de la variable independiente x. Ya pasan a la izquierda del gráfico "abstracto" (este último, notamos, ¡no ha cambiado su posición!). Higo. 8. El tipo de gráficos con cambio lineal directo e inverso de la señal de entradaEn este ejemplo, el error "doble" de la señal de salida con respecto a su valor "instantáneo" se hace evidente. Y cuanto más lento es el sistema informático o mayor es la frecuencia de la señal, mayor es el error. Una onda sinusoidal es un ejemplo de un cambio directo e inverso de una señal de entrada. Debido a esto, las "alas" en la Fig. 4 tomaron esta forma. Sin el efecto de "error hacia atrás", serían dos veces más estrechos.
Higo. 8. El tipo de gráficos con cambio lineal directo e inverso de la señal de entradaEn este ejemplo, el error "doble" de la señal de salida con respecto a su valor "instantáneo" se hace evidente. Y cuanto más lento es el sistema informático o mayor es la frecuencia de la señal, mayor es el error. Una onda sinusoidal es un ejemplo de un cambio directo e inverso de una señal de entrada. Debido a esto, las "alas" en la Fig. 4 tomaron esta forma. Sin el efecto de "error hacia atrás", serían dos veces más estrechos.6. Controlador PID adaptativo
Consideremos un ejemplo más en el que se muestran los problemas considerados. En la Fig. La Figura 9 muestra la configuración del medio VKP (a) al modelar un controlador PID adaptativo. También se muestra un diagrama de bloques en el que el controlador PID está representado por una unidad llamada PID. En el nivel de recuadro negro, es similar a la implementación de un solo bloque previamente considerada de una función cuadrática.El resultado de comparar los resultados del cálculo del modelo de controlador PID dentro de un determinado paquete matemático y el protocolo obtenido de los resultados de la simulación en el entorno VKP (a) se muestra en la figura 10, donde el gráfico rojo son los valores calculados, y el gráfico azul es el protocolo. La razón de su falta de coincidencia es que el cálculo dentro del marco del paquete matemático, como se muestra en un análisis posterior, corresponde a la operación secuencial de los objetos cuando primero resuelven el controlador PID y se detienen, y luego el modelo del objeto, etc. en el lazo. El entorno VKPa implementa / modela la operación paralela de objetos de acuerdo con la situación real, cuando el modelo y el objeto trabajan en paralelo. Fig.9. Implementación del controlador PID
Fig.9. Implementación del controlador PID Fig. 10. Comparación de valores calculados con resultados de simulación del controlador PIDDado que, como ya anunciamos, VKP (a) tiene un modo para simular la operación secuencial de bloques estructurales, no es difícil verificar la hipótesis de un modo de cálculo secuencial del controlador PID. Cambiando el modo de funcionamiento del medio a serial, obtenemos la coincidencia de los gráficos, como se muestra en la figura 11.
Fig. 10. Comparación de valores calculados con resultados de simulación del controlador PIDDado que, como ya anunciamos, VKP (a) tiene un modo para simular la operación secuencial de bloques estructurales, no es difícil verificar la hipótesis de un modo de cálculo secuencial del controlador PID. Cambiando el modo de funcionamiento del medio a serial, obtenemos la coincidencia de los gráficos, como se muestra en la figura 11. Fig.11. Operación secuencial del controlador PID y el objeto de control
Fig.11. Operación secuencial del controlador PID y el objeto de control
7. Conclusiones
Dentro del marco de la CPSU (a), el modelo computacional dota a los programas de propiedades que son características de los objetos "vivos" reales. De ahí la asociación figurativa con las "matemáticas vivas". Como muestra la práctica, en los modelos simplemente estamos obligados a tener en cuenta lo que no se puede ignorar en la vida real. En computación paralela, este es principalmente el tiempo y la finitud de los cálculos. Por supuesto, sin olvidar la adecuación del modelo matemático [automático] a uno u otro objeto "vivo".Es imposible luchar contra lo que no puede ser derrotado. Ya es hora. Esto solo es posible en un cuento de hadas. Pero tiene sentido tenerlo en cuenta y / o incluso usarlo para sus propios fines. En la programación paralela moderna, ignorar el tiempo conduce a muchos problemas difíciles de controlar y detectar: carrera de señal, procesos de punto muerto, problemas con la sincronización, etc. etc. La tecnología VKP (a) está en gran parte libre de tales problemas simplemente porque incluye un modelo en tiempo real y tiene en cuenta la finitud de los procesos informáticos. Contiene lo que la mayoría de sus análogos son simplemente ignorados.En conclusión. Las mariposas son mariposas, pero puede, por ejemplo, considerar un sistema de ecuaciones de funciones cuadráticas y lineales. Para hacer esto, es suficiente agregar al modelo ya creado un modelo de función lineal y un proceso que controla su coincidencia. Entonces la solución se encontrará modelando. Lo más probable es que no sea tan preciso como analítico, pero se obtendrá de manera más simple y rápida. Y en muchos casos esto es más que suficiente. Y encontrar una solución analítica es, por regla general, a menudo una pregunta abierta.En relación con este último, se retiraron los AVM. Para aquellos que no están actualizados o han olvidado, - computadoras analógicas. Los principios estructurales son en general, y el enfoque para encontrar una solución.solicitud
1) Video : youtu.be/vf9gNBAmOWQ2) Archivo de ejemplos : github.com/lvs628/FsaHabr/blob/master/FsaHabr.zip .3) Archivo de las bibliotecas Qt dll necesarias versión 5.11.2 : github.com/lvs628/FsaHabr/blob/master/QtDLLs.zip Losejemplos se desarrollan en el entorno de Windows 7. Para instalarlos, abra el archivo de ejemplos y si no tiene Qt instalado o la versión actual de Qt es diferente de la versión 5.11.2, luego, adicionalmente, abra el archivo Qt y escriba la ruta a las bibliotecas en la variable de entorno Path. A continuación, ejecute \ FsaHabr \ VCPaMain \ release \ FsaHabr.exe y use el cuadro de diálogo para seleccionar el directorio de configuración de un ejemplo, por ejemplo, \ FsaHabr \ 9.ParallelOperators \ Heading1 \ Pict1.C2 = A + B + A1 + B1 \ (consulte también video).Comentario. Al principio, en lugar del diálogo de selección de directorio, puede aparecer un diálogo de selección de archivo. También seleccionamos el directorio de configuración y algún archivo en él, por ejemplo, vSetting.txt. Si el cuadro de diálogo de selección de configuración no aparece, antes de comenzar, elimine el archivo ConfigFsaHabr.txt en el directorio donde se encuentra el archivo FsaHabr.exe.
Para no repetir la selección de configuración en el cuadro de diálogo "kernel: espacios automáticos" (se puede abrir utilizando el elemento de menú: FSA-tools / Space Management / Management), haga clic en el botón "recordar ruta del directorio" y desmarque "mostrar el cuadro de diálogo de selección de configuración al inicio ". En el futuro, para seleccionar una configuración diferente, esta opción deberá configurarse nuevamente.Literatura
1. NPS, transportador, computación automática y nuevamente ... corutinas. [Recurso electrónico], Modo de acceso: habr.com/en/post/488808 gratis. Yaz ruso (fecha de tratamiento 02.22.2020).2. ¿Son las máquinas automáticas un evento? [Recurso electrónico], Modo de acceso: habr.com/en/post/483610 gratis. Yaz ruso (fecha de tratamiento 02.22.2020).3. BUCH G., RAMBO J., JACOBSON I. UML. Manual de usuario. Segunda edicion. Academia IT: Moscú, 2007 .-- 493 p.4. Rogachev G.N. Stateflow V5. Manual de usuario. [Recurso electrónico], Modo de acceso: bourabai.kz/cm/stateflow.htm gratis. Yaz ruso (fecha de circulación 10.04.2020).5)Modelo de computación paralela [Recurso electrónico], Modo de acceso: habr.com/en/post/486622 gratis. Yaz ruso (fecha de circulación 11/04/2020).