 El efecto de tablas e índices de hinchazón (hinchazón) es ampliamente conocido y está presente no solo en Postgres. Hay formas de tratarlo "fuera de la caja" como VACUUM FULL o CLUSTER, pero bloquean las tablas durante la operación y, por lo tanto, no siempre se pueden usar.El artículo tendrá un poco de teoría sobre cómo se produce la hinchazón, cómo lidiar con ella, sobre las restricciones diferidas y sobre los problemas que traen al uso de la extensión pg_repack.Este artículo se basa en mi presentación en PgConf.Russia 2020.
El efecto de tablas e índices de hinchazón (hinchazón) es ampliamente conocido y está presente no solo en Postgres. Hay formas de tratarlo "fuera de la caja" como VACUUM FULL o CLUSTER, pero bloquean las tablas durante la operación y, por lo tanto, no siempre se pueden usar.El artículo tendrá un poco de teoría sobre cómo se produce la hinchazón, cómo lidiar con ella, sobre las restricciones diferidas y sobre los problemas que traen al uso de la extensión pg_repack.Este artículo se basa en mi presentación en PgConf.Russia 2020.Por qué ocurre la hinchazón
Postgres se basa en el modelo de múltiples versiones ( MVCC ). Su esencia es que cada fila de la tabla puede tener varias versiones, mientras que las transacciones no ven más de una de estas versiones, pero no necesariamente la misma. Esto permite que varias transacciones funcionen simultáneamente y prácticamente no tengan efecto entre ellas.Obviamente, todas estas versiones necesitan ser almacenadas. Postgres funciona con memoria página por página y la página es la cantidad mínima de datos que se pueden leer desde el disco o escribir. Veamos un pequeño ejemplo para entender cómo sucede esto.Supongamos que tenemos una tabla en la que hemos agregado varios registros. En la primera página del archivo donde se almacena la tabla, han aparecido nuevos datos. Estas son versiones en vivo de cadenas que están disponibles para otras transacciones después de una confirmación (por simplicidad, asumiremos que el nivel de aislamiento de Confirmación de lectura).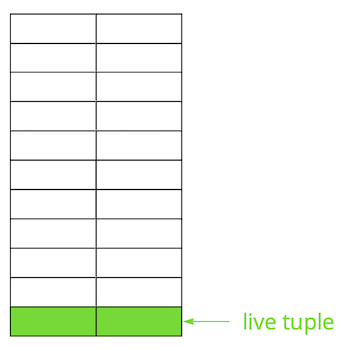 Luego, actualizamos una de las entradas y, por lo tanto, marcamos la versión anterior como irrelevante.
Luego, actualizamos una de las entradas y, por lo tanto, marcamos la versión anterior como irrelevante.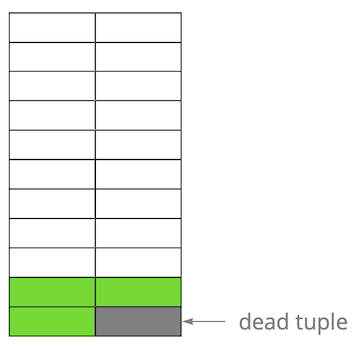 Paso a paso, actualizando y eliminando la versión de las líneas, obtuvimos una página en la que aproximadamente la mitad de los datos son "basura". Estos datos no son visibles para ninguna transacción.
Paso a paso, actualizando y eliminando la versión de las líneas, obtuvimos una página en la que aproximadamente la mitad de los datos son "basura". Estos datos no son visibles para ninguna transacción.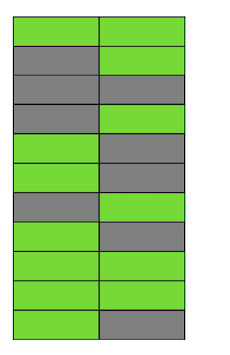 Postgres tiene un mecanismo de VACÍO, que limpia versiones irrelevantes y libera espacio para nuevos datos. Pero si no está configurado de manera suficientemente agresiva o está ocupado trabajando en otras tablas, entonces los "datos basura" permanecen, y tenemos que usar páginas adicionales para obtener nuevos datos.Entonces, en nuestro ejemplo, en algún momento, la tabla constará de cuatro páginas, pero solo tendrá la mitad de los datos en vivo. Como resultado, al acceder a la tabla, leeremos muchos más datos de los necesarios.
Postgres tiene un mecanismo de VACÍO, que limpia versiones irrelevantes y libera espacio para nuevos datos. Pero si no está configurado de manera suficientemente agresiva o está ocupado trabajando en otras tablas, entonces los "datos basura" permanecen, y tenemos que usar páginas adicionales para obtener nuevos datos.Entonces, en nuestro ejemplo, en algún momento, la tabla constará de cuatro páginas, pero solo tendrá la mitad de los datos en vivo. Como resultado, al acceder a la tabla, leeremos muchos más datos de los necesarios.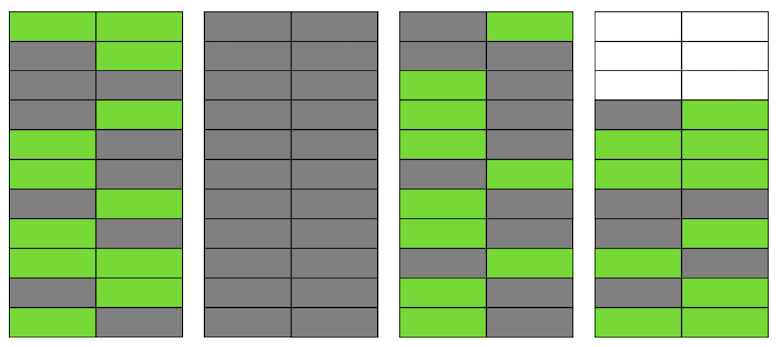 Incluso si VACUUM ahora elimina todas las versiones irrelevantes de cadenas, la situación no mejorará dramáticamente. Tendremos espacio libre en las páginas o incluso en páginas enteras para nuevas líneas, pero continuaremos leyendo más datos de los necesarios.Por cierto, si una página completamente en blanco (la segunda en nuestro ejemplo) estuviera al final del archivo, VACUUM podría recortarla. Pero ahora ella está en el medio, así que no se puede hacer nada con ella.
Incluso si VACUUM ahora elimina todas las versiones irrelevantes de cadenas, la situación no mejorará dramáticamente. Tendremos espacio libre en las páginas o incluso en páginas enteras para nuevas líneas, pero continuaremos leyendo más datos de los necesarios.Por cierto, si una página completamente en blanco (la segunda en nuestro ejemplo) estuviera al final del archivo, VACUUM podría recortarla. Pero ahora ella está en el medio, así que no se puede hacer nada con ella.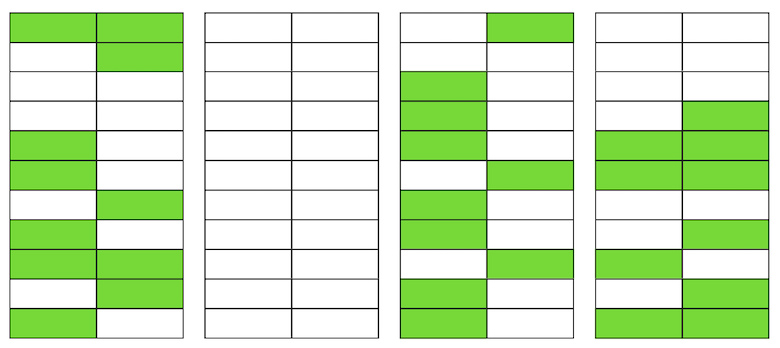 Cuando el número de páginas en blanco o muy planas aumenta, lo que se llama hinchazón, comienza a afectar el rendimiento.Todo lo descrito anteriormente es la mecánica de la aparición de hinchazón en las tablas. En los índices, esto sucede aproximadamente igual.
Cuando el número de páginas en blanco o muy planas aumenta, lo que se llama hinchazón, comienza a afectar el rendimiento.Todo lo descrito anteriormente es la mecánica de la aparición de hinchazón en las tablas. En los índices, esto sucede aproximadamente igual.¿Tengo una hinchazón?
Hay varias formas de determinar si tiene una hinchazón. La idea del primero es utilizar estadísticas internas de Postgres, que contienen información aproximada sobre el número de filas en las tablas, el número de filas "en vivo", etc. En Internet, puede encontrar muchas variaciones de secuencias de comandos listas para usar. Tomamos como base una secuencia de comandos de los expertos de PostgreSQL, que puede evaluar las tablas de relleno junto con los índices de btree de pan tostado e hinchado. En nuestra experiencia, su error es del 10-20%.Otra forma es usar la extensión pgstattuple , que le permite mirar dentro de las páginas y obtener valores de hinchamiento estimados y precisos. Pero en el segundo caso, debe escanear toda la tabla.Un valor de hinchazón pequeño, hasta 20%, lo consideramos aceptable. Se puede considerar como un análogo del factor de relleno para tablas e índices . Al 50% o más, pueden comenzar problemas de rendimiento.Formas de lidiar con la hinchazón
Hay varias formas de lidiar con la hinchazón fuera de la caja en Postgres, pero están lejos de ser siempre adecuadas para todos.Establezca AUTOVACUUM para que no se produzca hinchazón . Y más precisamente, para mantenerlo en un nivel aceptable para usted. Este parece ser el consejo del "capitán", pero en realidad esto no siempre es fácil de lograr. Por ejemplo, está desarrollando activamente con cambios regulares en el esquema de datos o se está produciendo algún tipo de migración de datos. Como resultado, su perfil de carga puede cambiar con frecuencia y, como regla, puede ser diferente para diferentes tablas. Esto significa que debe trabajar constantemente un poco por delante de la curva y ajustar AUTOVACUUM al perfil cambiante de cada tabla. Pero es obvio que esto no es fácil.Otra razón común por la que AUTOVACUUM no tiene tiempo para procesar tablas es la presencia de transacciones largas que evitan que se borren datos debido al hecho de que están disponibles para estas transacciones. La recomendación aquí también es obvia: deshacerse de las transacciones pendientes y minimizar el tiempo de las transacciones activas. Pero si la carga en su aplicación es un híbrido de OLAP y OLTP, al mismo tiempo puede tener muchas actualizaciones frecuentes y solicitudes cortas, así como operaciones largas, por ejemplo, la creación de un informe. En tal situación, vale la pena pensar en distribuir la carga a diferentes bases, lo que permitirá un ajuste más fino de cada una de ellas.Otro ejemplo: incluso si el perfil es uniforme, pero la base de datos está bajo una carga muy alta, incluso el AUTOVACUUM más agresivo puede no hacer frente, y se producirá una hinchazón. La escala (vertical u horizontal) es la única solución.Pero, ¿qué pasa con la situación cuando configuró AUTOVACUUM, pero la hinchazón continúa creciendo?Comando VACÍO COMPLETOreconstruye el contenido de tablas e índices y deja solo datos relevantes en ellos. Para eliminar la hinchazón, funciona perfectamente, pero durante su ejecución, se captura un bloqueo exclusivo en la tabla (AccessExclusiveLock), que no permitirá consultas a esta tabla, incluso las selecciona. Si puede permitirse detener su servicio o parte de él por un tiempo (de decenas de minutos a varias horas, dependiendo del tamaño de la base de datos y su hardware), entonces esta opción es la mejor. Desafortunadamente, no tenemos tiempo para ejecutar VACUUM FULL durante el mantenimiento programado, por lo que este método no nos conviene.Comando CLUSTERtambién reconstruye el contenido de las tablas, al igual que VACUUM FULL, al mismo tiempo que le permite especificar el índice según el cual los datos se ordenarán físicamente en el disco (pero en el futuro el pedido no está garantizado). En ciertas situaciones, esta es una buena optimización para varias consultas, con la lectura de varios registros por índice. La desventaja del comando es la misma que la de VACUUM FULL: bloquea la tabla durante la operación.El comando REINDEX es similar a los dos anteriores, pero reconstruye un índice específico o todos los índices de la tabla. Los bloqueos son ligeramente más débiles: ShareLock en la tabla (evita modificaciones, pero le permite seleccionar) y AccessExclusiveLock en un índice ajustable (bloquea las solicitudes que utilizan este índice). Sin embargo, en la versión 12 de Postgres, el parámetro CONCURRENTEMENTE, que le permite reconstruir el índice sin bloquear la adición, modificación o eliminación paralela de registros.En versiones anteriores de Postgres, puede lograr un resultado similar a REINDEX CONCURRENTEMENTE con CREATE INDEX CONCURRENTLY . Le permite crear un índice sin un bloqueo estricto (ShareUpdateExclusiveLock, que no interfiere con las consultas paralelas), luego reemplazar el índice antiguo por uno nuevo y eliminar el índice anterior. Esto elimina los índices de hinchazón sin interferir con su aplicación. Es importante tener en cuenta que al reconstruir índices habrá una carga adicional en el subsistema de disco.Por lo tanto, si hay formas para que los índices eliminen la hinchazón "en caliente", entonces para las tablas no hay ninguna. Aquí entran en juego varias extensiones externas: pg_repack(anteriormente pg_reorg), pgcompact , pgcompacttable y otros. En el marco de este artículo, no los compararé y solo hablaré sobre pg_repack, que, después de algunos ajustes, usamos en casa.Cómo funciona pg_repack
Supongamos que tenemos una tabla muy normal para nosotros, con índices, restricciones y, desafortunadamente, con hinchazón. El primer paso es pg_repack crea una tabla de registro para almacenar datos sobre todos los cambios durante la operación. El activador replicará estos cambios en cada inserción, actualización y eliminación. Luego se crea una tabla que es similar a la estructura original, pero sin índices y restricciones, para no ralentizar el proceso de inserción de datos.A continuación, pg_repack transfiere datos de la tabla anterior a la nueva, filtrando automáticamente todas las filas irrelevantes y luego crea índices para la nueva tabla. Durante la ejecución de todas estas operaciones, los cambios se acumulan en la tabla de registro.El siguiente paso es transferir los cambios a la nueva tabla. La migración se realiza en varias iteraciones, y cuando quedan menos de 20 entradas en la tabla de registro, pg_repack captura un bloqueo estricto, transfiere los últimos datos y reemplaza la tabla anterior por la nueva en las tablas del sistema Postgres. Este es el único y muy corto momento en el que no puede trabajar con la tabla. Después de eso, la tabla anterior y la tabla con los registros se eliminan y se libera espacio en el sistema de archivos. El proceso está completo.En teoría, todo se ve muy bien, ¿qué pasa en la práctica? Probamos pg_repack sin carga y bajo carga, verificamos su funcionamiento en caso de una parada prematura (en otras palabras, Ctrl + C). Todas las pruebas fueron positivas.Fuimos a la producción y luego todo salió mal como esperábamos.El primer panqueque en prod
En el primer clúster, recibimos un error sobre la violación de una restricción única:$ ./pg_repack -t tablename -o id
INFO: repacking table "tablename"
ERROR: query failed:
ERROR: duplicate key value violates unique constraint "index_16508"
DETAIL: Key (id, index)=(100500, 42) already exists.
Esta restricción tenía el nombre autogenerado index_16508: fue creado por pg_repack. Por los atributos incluidos en su composición, determinamos "nuestra" restricción, que le corresponde. El problema resultó ser que no se trata de una restricción ordinaria, sino de una restricción diferida , es decir, su verificación se realiza más tarde que el comando sql, lo que lleva a consecuencias inesperadas.Restricciones diferidas: por qué son necesarias y cómo funcionan
Un poco de teoría sobre las restricciones diferidas.Considere un ejemplo simple: tenemos una tabla de referencia de automóviles con dos atributos: el nombre y el orden del automóvil en el directorio.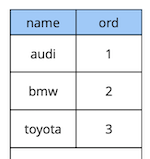
create table cars
(
name text constraint pk_cars primary key,
ord integer not null constraint uk_cars unique
);
Digamos que necesitábamos cambiar el primer y el segundo auto. La solución "en la frente" es actualizar el primer valor al segundo y el segundo al primero:begin;
update cars set ord = 2 where name = 'audi';
update cars set ord = 1 where name = 'bmw';
commit;
Pero al ejecutar este código, esperamos obtener una violación de la restricción, porque el orden de los valores en la tabla es único:[23305] ERROR: duplicate key value violates unique constraint “uk_cars”
Detail: Key (ord)=(2) already exists.
¿Cómo hacerlo de manera diferente? Opción uno: agregue un reemplazo adicional del valor por un pedido que se garantiza que no existe en la tabla, por ejemplo, "-1". En programación, esto se llama "intercambiar los valores de dos variables a través de la tercera". El único inconveniente de este método es la actualización adicional.Opción dos: rediseñar la tabla para usar un tipo de datos de punto flotante para el valor del pedido en lugar de enteros. Luego, al actualizar el valor de 1, por ejemplo, a 2.5, el primer registro se “levantará” automáticamente entre el segundo y el tercero. Esta solución funciona, pero hay dos limitaciones. En primer lugar, no funcionará si el valor se usa en algún lugar de la interfaz. En segundo lugar, dependiendo de la precisión del tipo de datos, tendrá un número limitado de inserciones posibles antes de volver a calcular los valores de todos los registros.Opción tres: diferir la restricción para que se verifique solo en el momento de la confirmación:create table cars
(
name text constraint pk_cars primary key,
ord integer not null constraint uk_cars unique deferrable initially deferred
);
Dado que la lógica de nuestra solicitud inicial garantiza que todos los valores sean únicos en el momento de la confirmación, tendrá éxito.El ejemplo anterior es, por supuesto, muy sintético, pero revela la idea. En nuestra aplicación, utilizamos restricciones diferidas para implementar una lógica responsable de resolver conflictos mientras trabajamos simultáneamente con objetos de widget comunes en el tablero. El uso de tales restricciones nos permite hacer que el código de la aplicación sea un poco más fácil.En general, dependiendo del tipo de restricción en Postgres, existen tres niveles de granularidad para verificarlos: nivel de fila, transacción y expresión.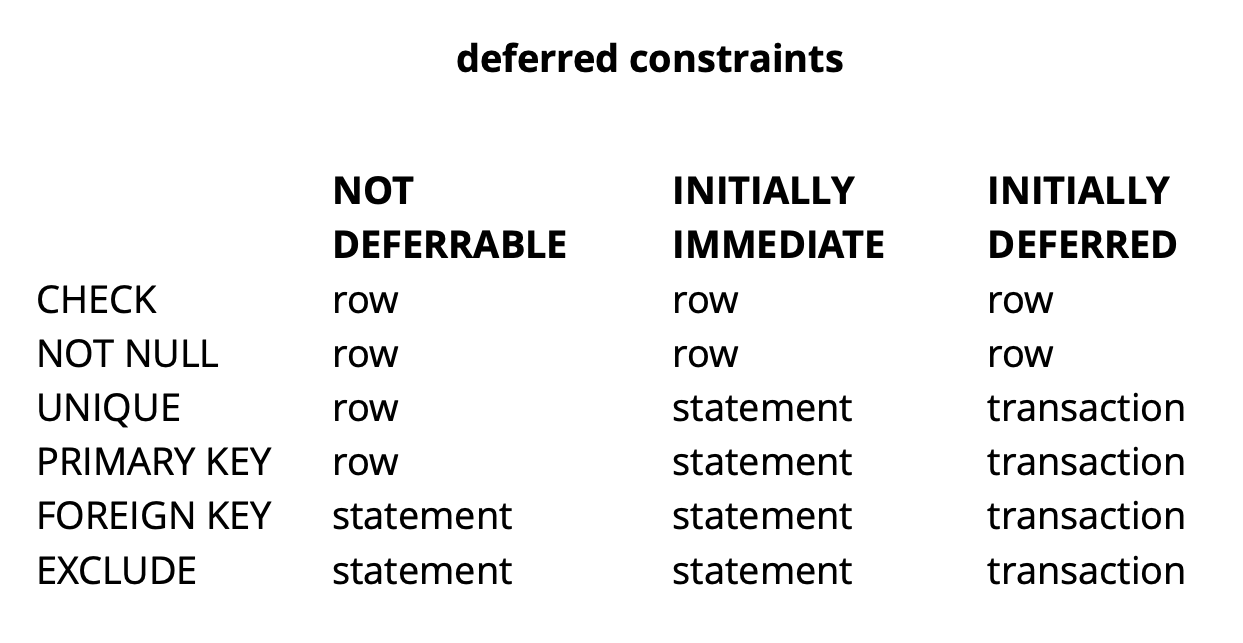 Fuente: begriffsCHECK y NOT NULL siempre se verifican a nivel de fila, para otras restricciones, como se puede ver en la tabla, hay diferentes opciones. Lee más aquí .Para resumir brevemente, las restricciones pendientes en algunas situaciones dan un código más legible y menos comandos. Sin embargo, debe pagar esto complicando el proceso de depuración, desde el momento en que se produjo el error y el momento en que se entera de que se separan en el tiempo. Otro posible problema es que el planificador no siempre puede construir el plan óptimo si hay una restricción retrasada en la solicitud.
Fuente: begriffsCHECK y NOT NULL siempre se verifican a nivel de fila, para otras restricciones, como se puede ver en la tabla, hay diferentes opciones. Lee más aquí .Para resumir brevemente, las restricciones pendientes en algunas situaciones dan un código más legible y menos comandos. Sin embargo, debe pagar esto complicando el proceso de depuración, desde el momento en que se produjo el error y el momento en que se entera de que se separan en el tiempo. Otro posible problema es que el planificador no siempre puede construir el plan óptimo si hay una restricción retrasada en la solicitud.Refinamiento pg_repack
Descubrimos cuáles son las restricciones pendientes, pero ¿cómo se relacionan con nuestro problema? Recordemos el error que recibimos anteriormente:$ ./pg_repack -t tablename -o id
INFO: repacking table "tablename"
ERROR: query failed:
ERROR: duplicate key value violates unique constraint "index_16508"
DETAIL: Key (id, index)=(100500, 42) already exists.
Ocurre al momento de copiar datos de la tabla de registro a la nueva tabla. Se ve raro porque los datos en la tabla de registro se confirman junto con los datos en la tabla original. Si satisfacen las restricciones de la tabla original, ¿cómo pueden violar las mismas restricciones en la nueva?Resultó que la raíz del problema radica en el paso anterior de pg_repack, en el que solo se crean índices, pero no restricciones: la tabla anterior tenía una restricción única, y la nueva creó un índice único. Es importante señalar aquí que si la restricción es normal y no diferida, entonces el índice único creado en su lugar es equivalente a esta restricción, porque Las restricciones únicas de Postgres se implementan creando un índice único. Pero en el caso de una restricción diferida, el comportamiento no es el mismo, porque el índice no puede diferirse y siempre se verifica en el momento en que se ejecuta el comando sql.Por lo tanto, la esencia del problema radica en el "aplazamiento" de la verificación: en la tabla original se produce en el momento de la confirmación, y en la nueva, en el momento de la ejecución del comando sql. Por lo tanto, debemos asegurarnos de que las comprobaciones se realicen de la misma manera en ambos casos: siempre diferidas o siempre de forma inmediata.Entonces, ¿qué ideas tuvimos?
Es importante señalar aquí que si la restricción es normal y no diferida, entonces el índice único creado en su lugar es equivalente a esta restricción, porque Las restricciones únicas de Postgres se implementan creando un índice único. Pero en el caso de una restricción diferida, el comportamiento no es el mismo, porque el índice no puede diferirse y siempre se verifica en el momento en que se ejecuta el comando sql.Por lo tanto, la esencia del problema radica en el "aplazamiento" de la verificación: en la tabla original se produce en el momento de la confirmación, y en la nueva, en el momento de la ejecución del comando sql. Por lo tanto, debemos asegurarnos de que las comprobaciones se realicen de la misma manera en ambos casos: siempre diferidas o siempre de forma inmediata.Entonces, ¿qué ideas tuvimos?Crear un índice similar al diferido
La primera idea es realizar ambas comprobaciones en modo inmediato. Esto puede dar lugar a varios desencadenantes falsos positivos de la restricción, pero si hay pocos, entonces esto no debería afectar el trabajo de los usuarios, ya que para ellos estos conflictos son una situación normal. Ocurren, por ejemplo, cuando dos usuarios comienzan a editar simultáneamente el mismo widget, y el cliente del segundo usuario no tiene tiempo para obtener información de que el primer usuario ya ha bloqueado el widget para editarlo. En esta situación, el servidor rechaza al segundo usuario y su cliente revierte los cambios y bloquea el widget. Un poco más tarde, cuando el primer usuario termine de editar, el segundo recibirá información de que el widget ya no está bloqueado y podrá repetir su acción.Para garantizar que las comprobaciones estén siempre en modo de emergencia, creamos un nuevo índice similar a la restricción diferida original:CREATE UNIQUE INDEX CONCURRENTLY uk_tablename__immediate ON tablename (id, index);
DROP INDEX CONCURRENTLY uk_tablename__immediate;
En el entorno de prueba, recibimos solo algunos errores esperados. ¡Éxito! Nuevamente lanzamos pg_repack en el producto y obtuvimos 5 errores en el primer clúster en una hora de trabajo. Este es un resultado aceptable. Sin embargo, ya en el segundo clúster, el número de errores aumentó muchas veces y tuvimos que detener pg_repack.¿Por qué sucedió? La probabilidad de un error depende de cuántos usuarios trabajen simultáneamente con los mismos widgets. Aparentemente, en ese momento con los datos almacenados en el primer grupo, hubo muchos menos cambios competitivos que en el resto, es decir. solo fuimos "afortunados".La idea no funcionó. En ese momento, vimos otras dos opciones de solución: reescribir nuestro código de aplicación para abandonar las restricciones pendientes, o "enseñar" a pg_repack para trabajar con ellas. Hemos elegido el segundo.Reemplazar índices en una nueva tabla con restricciones diferidas de la tabla fuente
El propósito de la revisión era obvio: si la tabla original tiene una restricción diferida, entonces para la nueva debe crear dicha restricción, no un índice.Para probar nuestros cambios, escribimos una prueba simple:- tabla con restricción diferida y un registro;
- inserte datos en el bucle que entren en conflicto con el registro existente;
- hacer actualización: los datos ya no entran en conflicto;
- comprometer el cambio
create table test_table
(
id serial,
val int,
constraint uk_test_table__val unique (val) deferrable initially deferred
);
INSERT INTO test_table (val) VALUES (0);
FOR i IN 1..10000 LOOP
BEGIN
INSERT INTO test_table VALUES (0) RETURNING id INTO v_id;
UPDATE test_table set val = i where id = v_id;
COMMIT;
END;
END LOOP;
La versión original de pg_repack siempre fallaba en la primera inserción, la versión revisada funcionaba sin errores. Multa.Vamos al producto y nuevamente tenemos un error en la misma fase de copiar datos de la tabla de registro a la nueva:$ ./pg_repack -t tablename -o id
INFO: repacking table "tablename"
ERROR: query failed:
ERROR: duplicate key value violates unique constraint "index_16508"
DETAIL: Key (id, index)=(100500, 42) already exists.
Situación clásica: ¿todo funciona en entornos de prueba, pero no en productos?APPLY_COUNT y la unión de dos lotes
Comenzamos a analizar el código literalmente línea por línea y encontramos un punto importante: los datos se transfieren de la tabla de registro a la nueva con lotes, la constante APPLY_COUNT indica el tamaño de los lotes:for (;;)
{
num = apply_log(connection, table, APPLY_COUNT);
if (num > MIN_TUPLES_BEFORE_SWITCH)
continue;
...
}
El problema es que los datos de la transacción original, en la que varias operaciones pueden violar potencialmente la restricción, se pueden transferir a la unión de dos lotes durante la transferencia: la mitad de los equipos se comprometerán en el primer partido y la otra mitad en el segundo. Y aquí está la suerte: si los equipos en el primer lote no violan nada, entonces todo está bien, pero si violan, se produce un error.APPLY_COUNT es igual a 1000 entradas, lo que explica por qué nuestras pruebas tuvieron éxito: no cubrieron el caso de "unión de lotes". Utilizamos dos comandos: insertar y actualizar, por lo que exactamente 500 transacciones de dos equipos siempre se colocaron en el lote y no tuvimos problemas. Después de agregar la segunda actualización, nuestra edición dejó de funcionar:FOR i IN 1..10000 LOOP
BEGIN
INSERT INTO test_table VALUES (1) RETURNING id INTO v_id;
UPDATE test_table set val = i where id = v_id;
UPDATE test_table set val = i where id = v_id;
COMMIT;
END;
END LOOP;
Por lo tanto, la siguiente tarea es asegurarse de que los datos de la tabla de origen que cambiaron en una transacción caigan en la nueva tabla también dentro de la misma transacción.Rechazo de carnicería
Y nuevamente tuvimos dos soluciones. Primero: abandonemos por completo el procesamiento por lotes y realicemos la transferencia de datos en una transacción. A favor de esta solución fue su simplicidad: los cambios de código requeridos fueron mínimos (por cierto, en versiones anteriores, pg_reorg funcionaba de esa manera). Pero hay un problema: estamos creando una transacción larga, y esto, como se dijo anteriormente, es una amenaza para la aparición de una nueva hinchazón.La segunda solución es más complicada, pero probablemente más correcta: cree una columna en la tabla de registro con el identificador de la transacción que agregó los datos a la tabla. Luego, al copiar datos, podremos agruparlos por este atributo y asegurarnos de que los cambios relacionados se transfieran juntos. Se formará un lote a partir de varias transacciones (o una grande) y su tamaño variará según la cantidad de datos que hayan cambiado en estas transacciones. Es importante tener en cuenta que dado que los datos de diferentes transacciones caen en la tabla de registro en orden aleatorio, no será posible leerlos secuencialmente, como era antes. seqscan para cada solicitud filtrada por tx_id es demasiado costoso, necesita un índice, pero ralentizará el método debido a la sobrecarga de actualizarlo. En general, como siempre, debes sacrificar algo.Entonces, decidimos comenzar con la primera opción, como una más simple. Primero, era necesario comprender si una transacción larga sería un problema real. Dado que la transferencia de datos principal de la tabla anterior a la nueva también se produce en una transacción larga, la pregunta se ha transformado en "¿cuánto aumentaremos esta transacción?" La duración de la primera transacción depende principalmente del tamaño de la tabla. La duración del nuevo depende de cuántos cambios se acumulen en la tabla durante la transferencia de datos, es decir. de la intensidad de la carga. La ejecución de pg_repack se produjo durante la carga mínima en el servicio, y la cantidad de cambio fue incomparablemente pequeña en comparación con el tamaño de la tabla original. Decidimos que podemos descuidar el tiempo de la nueva transacción (en comparación, esto es un promedio de 1 hora y 2-3 minutos).Los experimentos fueron positivos. Corriendo en prod también. Para mayor claridad, una imagen con el tamaño de una de las bases después de la ejecución: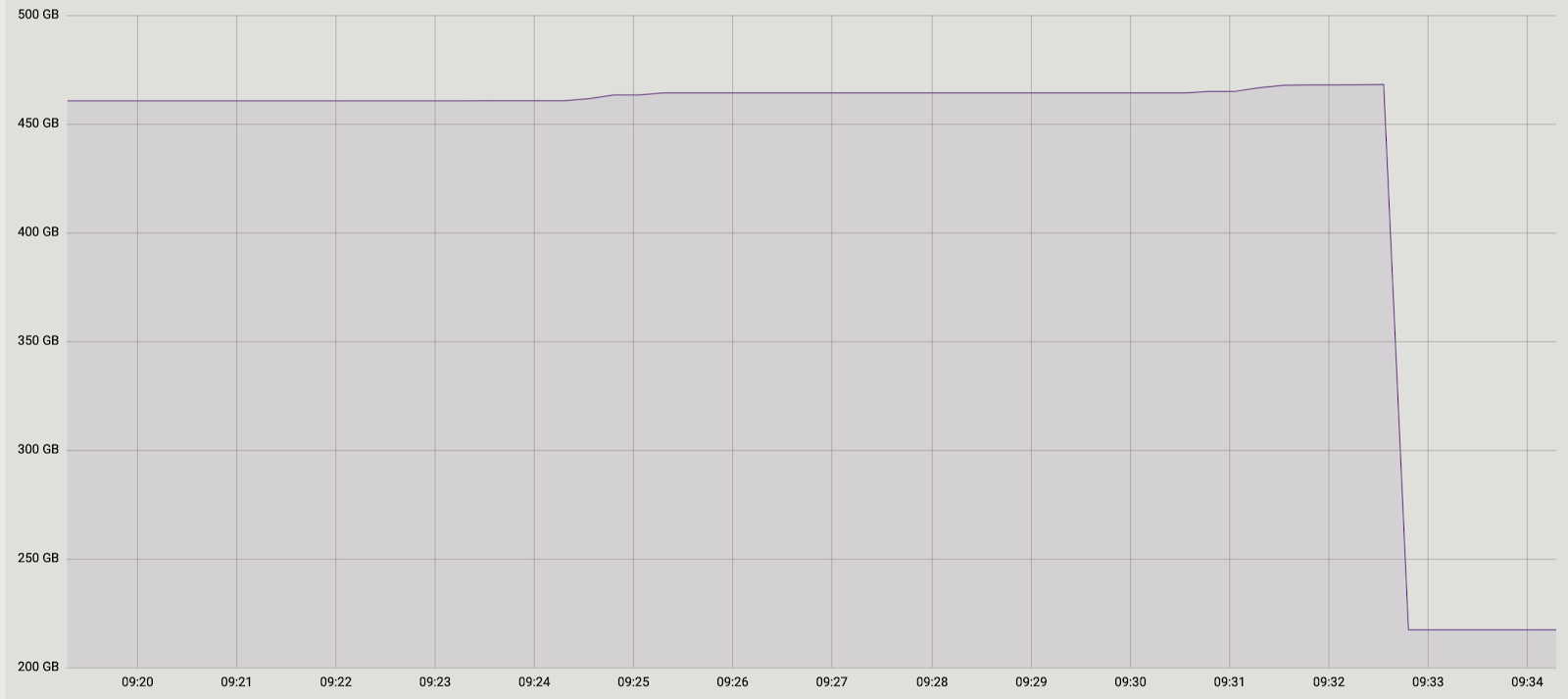 dado que esta solución nos convenía completamente, no intentamos implementar la segunda, pero estamos considerando discutirla con los desarrolladores de la extensión. Desafortunadamente, nuestra revisión actual aún no está lista para su publicación, ya que hemos resuelto el problema solo con restricciones pendientes únicas, y para un parche completo es necesario hacer soporte de otros tipos. Esperamos poder hacer esto en el futuro.Quizás tenga una pregunta, ¿por qué nos involucramos en esta historia con la finalización de pg_repack, y no utilizamos, por ejemplo, sus análogos? En algún momento, también pensamos en esto, pero la experiencia positiva de usarlo antes, en tablas sin restricciones pendientes, nos motivó a tratar de comprender la esencia del problema y solucionarlo. Además, para usar otras soluciones, también lleva tiempo realizar pruebas, por lo que decidimos que primero trataríamos de solucionar el problema, y si nos dimos cuenta de que no podíamos hacerlo en un período de tiempo razonable, entonces comenzaríamos a considerar los análogos.
dado que esta solución nos convenía completamente, no intentamos implementar la segunda, pero estamos considerando discutirla con los desarrolladores de la extensión. Desafortunadamente, nuestra revisión actual aún no está lista para su publicación, ya que hemos resuelto el problema solo con restricciones pendientes únicas, y para un parche completo es necesario hacer soporte de otros tipos. Esperamos poder hacer esto en el futuro.Quizás tenga una pregunta, ¿por qué nos involucramos en esta historia con la finalización de pg_repack, y no utilizamos, por ejemplo, sus análogos? En algún momento, también pensamos en esto, pero la experiencia positiva de usarlo antes, en tablas sin restricciones pendientes, nos motivó a tratar de comprender la esencia del problema y solucionarlo. Además, para usar otras soluciones, también lleva tiempo realizar pruebas, por lo que decidimos que primero trataríamos de solucionar el problema, y si nos dimos cuenta de que no podíamos hacerlo en un período de tiempo razonable, entonces comenzaríamos a considerar los análogos.recomendaciones
Lo que podemos recomendar en base a nuestra propia experiencia:- Controla tu hinchazón. Según los datos de monitoreo, puede comprender qué tan bien está configurado el vacío automático.
- Establezca AUTOVACUUM para mantener la hinchazón a un nivel razonable.
- bloat “ ”, . – .
- – , .