Una vez, un colega compartió sus pensamientos sobre la API para los clústeres de computación distribuida, y yo respondí en tono de broma: "Obviamente, una API ideal sería una simple llamada telefork()para que su proceso se active en cada máquina de clúster, devolviendo el valor de la ID de la instancia". Pero al final, esta idea se apoderó de mí. No podía entender por qué es tan estúpido y simple, mucho más simple que cualquier API para trabajo remoto, y por qué los sistemas informáticos no parecen ser capaces de hacerlo. También parecía entender cómo se puede implementar esto, y ya tenía un buen nombre, que es la parte más difícil de cualquier proyecto. Entonces me puse a trabajar.Durante el primer fin de semana, hizo un prototipo básico, y el segundo fin de semana trajo una demostración que podríaCómo se ve
Implementé el código como una biblioteca Rust, pero teóricamente puedes envolver el programa en la API C y luego ejecutar los enlaces FFI para teletransportar incluso el proceso de Python. La implementación es de solo 500 líneas de código (más 200 líneas de comentarios):use telefork::{telefork, TeleforkLocation};
fn main() {
let args: Vec<String> = std::env::args().collect();
let destination = args.get(1).expect("expected arg: address of teleserver");
let mut stream = std::net::TcpStream::connect(destination).unwrap();
match telefork(&mut stream).unwrap() {
TeleforkLocation::Child(val) => {
println!("I teleported to another computer and was passed {}!", val);
}
TeleforkLocation::Parent => println!("Done sending!"),
};
}
También escribí un ayudante llamado yoyoteleforks para el servidor, realiza el cierre transmitido y luego teleforks de regreso. Esto crea la ilusión de que puede ejecutar fácilmente un fragmento de código en un servidor remoto, por ejemplo, con una potencia de procesamiento mucho mayor.
let scene = create_scene();
let mut backbuffer = vec![Vec3::new(0.0, 0.0, 0.0); width * height];
telefork::yoyo(destination, || {
render_scene(&scene, width, height, &mut backbuffer);
});
save_png_file(width, height, &backbuffer);
Anatomía del proceso de Linux
Veamos cómo se ve el proceso en Linux (en el que se ejecuta el sistema operativo host de la madre telefork):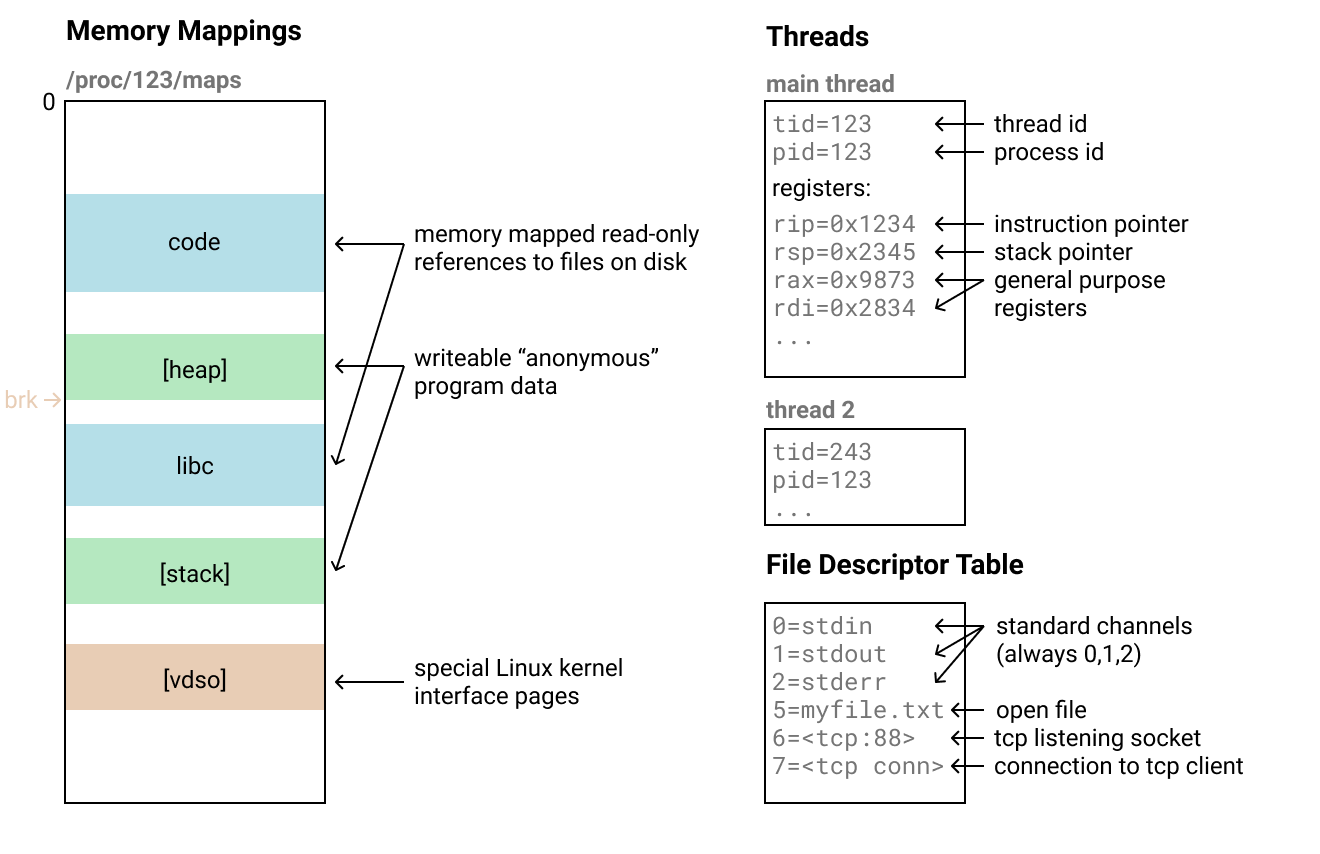
- (memory mappings): , . «» 4 .
/proc/<pid>/maps. , , .
- : , . , , - , , , . , .
- : , . - , . , , , TCP-, .
- . stdin/stdout/stderr, 0, 1 2.
- , , , .
- Varios : hay otras partes del estado del proceso que varían en complejidad de replicación. Pero en la mayoría de los casos no importan, por ejemplo, brk (puntero de montón). Algunos de ellos solo se pueden restaurar con la ayuda de trucos extraños o llamadas especiales del sistema como PR_SET_MM_MAP , lo que complica la recuperación.
Por lo tanto, la implementación básica teleforkse puede hacer con un mapeo simple de memoria y registros de los hilos principales. Esto debería ser suficiente para programas simples que principalmente realizan cálculos sin interactuar con los recursos del sistema operativo, como los archivos (en principio, para teletransportarse es suficiente para abrir el archivo en el sistema y cerrarlo antes de llamar telefork).Cómo teletransportar un proceso
No fui el primero en pensar en recrear procesos en otra máquina. Entonces, el depurador rr y el depurador de grabación hacen cosas muy similares . Envié algunas preguntas al autor de este programa @rocallahan , y me contó sobre el sistema CRIU para la migración "en caliente" de contenedores entre hosts. CRIU puede transferir el proceso de Linux a otro sistema, admite la recuperación de todo tipo de descriptores de archivos y otros estados, sin embargo, el código es realmente complejo y utiliza muchas llamadas al sistema que requieren ensamblados especiales del núcleo y permisos de raíz. Usando el enlace de la página wiki de CRIU, encontré DMTCP creado para instantáneas de tareas distribuidas en supercomputadoras para que puedan reiniciarse más tarde, y este programaEl código resultó ser más simple .Estos ejemplos no me obligaron a abandonar los intentos de implementar mi propio sistema, ya que estos son programas extremadamente complejos que requieren corredores e infraestructura especiales, y quería implementar la teletransportación de procesos más simple posible como una llamada a la biblioteca. Así que estudié los fragmentos del código fuente rr, CRIU, DMTCP y algunos ejemplos ptrace, y armé mi propio procedimiento telefork. Mi método funciona a su manera, es una mezcla de varias técnicas.Para teletransportar un proceso, debe hacer un trabajo en el proceso original que llama telefork, y otro trabajo en el lado de la llamada a la función, que recibe el proceso de transmisión en el servidor y lo recrea desde la transmisión (funcióntelepad) Pueden ocurrir al mismo tiempo, pero toda la serialización también se puede hacer antes de descargar, por ejemplo, soltarlo en un archivo y luego descargarlo.La siguiente es una descripción simplificada de ambos procesos. Si desea comprender en detalle, le sugiero leer el código fuente . Está contenido en un archivo y está fuertemente comentado para leer en orden y comprender cómo funciona todo.Enviar un proceso usando telefork
La función teleforkrecibe una secuencia con capacidad de escritura, mediante la cual transfiere todo el estado de su proceso.- «» . , , . fork .
- .
/proc/<pid>/maps , . proc_maps crate.
- . DMTCP, , , . ,
[vdso], , , .
- . , , process_vm_readv , .
- Transferencia de registros . Yo uso la opción
PTRACE_GETREGSpara la llamada al sistema ptrace . Le permite obtener todos los valores del registro del proceso secundario. Luego solo los escribo en un mensaje en el canal.
Ejecutar llamadas del sistema en un proceso secundario
Para convertir el proceso de destino en una copia del proceso entrante, deberá forzar el proceso para ejecutar un montón de llamadas del sistema en sí mismo, sin acceso a ningún código, porque eliminamos todo. Hacemos llamadas al sistema remoto utilizando ptrace , una llamada al sistema universal para manipular y verificar otros procesos:- syscall. syscall , . ,
process_vm_readv [vdso] , , , syscall Linux, . , [vdso].
- ,
PTRACE_SETREGS. syscall, rax Linux, rdi, rsi, rdx, r10, r8, r9.
PTRACE_SINGLESTEPDé un paso usando el parámetro para ejecutar el comando syscall.
- Lea los registros con
PTRACE_GETREGSpara restaurar el valor de retorno de syscall y vea si tuvo éxito.
Proceso de aceptación en telepad
Usando esto y las primitivas ya descritas, podemos recrear el proceso:- Bifurca un proceso de niño congelado . Similar al envío, pero esta vez necesitamos un proceso hijo que podamos manipular para convertirlo en un clon del proceso transferido.
- Verifique las tarjetas de asignación de memoria . Esta vez necesitamos conocer todas las tarjetas de asignación de memoria existentes para eliminarlas y dejar espacio para el proceso entrante.
- . ,
munmap.
- .
mremap, .
- .
mmap , process_vm_writev .
- .
PTRACE_SETREGS , , rax. raise(SIGSTOP), . , telepad.
- Se utiliza un valor arbitrario para que el servidor de Telefork pueda transferir el descriptor de archivo de la conexión TCP que ingresó el proceso, y puede enviar datos de vuelta o, en caso de
yoyoteletransportarse, a la misma conexión.
- Reinicie el proceso con el nuevo contenido usando
PTRACE_DETACH.
Implementación más competente
Algunas partes de mi implementación de telefork no están perfectamente diseñadas. Sé cómo solucionarlos, pero en la forma actual me gusta el sistema, y a veces son realmente difíciles de solucionar. Aquí hay algunos ejemplos interesantes:- (vDSO).
mremap vDSO , DMTCP, , . vDSO, . - , CPU glibc vDSO . , vDSO, syscall, rr, vDSO vDSO .
brk . DMTCP, , brk , brk . , , — PR_SET_MM_MAP, .
- . Rust « », , FS GS, , , -
glibc pid tid, . CRIU, PID TID .
- . , , , / , / FUSE. , TCP-, DMTCP CRIU ,
perf_event_open.
- .
fork() Unix , , .
Creo que ya entendiste que con las interfaces de bajo nivel adecuadas, puedes implementar algunas cosas locas que parecían imposibles para alguien. Aquí hay algunas ideas sobre cómo desarrollar las ideas básicas de Telefork. Aunque gran parte de lo anterior probablemente se pueda implementar completamente solo en un núcleo completamente nuevo o fijo:- Telefork en racimo . La fuente inicial de inspiración para Telefork fue la idea de transmitir un proceso a todas las máquinas en un clúster informático. Incluso puede resultar que implemente métodos de multidifusión UDP o de igual a igual para acelerar la distribución en todo el clúster. Probablemente también desee tener primitivas de comunicación.
- . CRIU , -
userfaultfd. , SIGSEGV mmap. , , — .
- ! , .
userfaultfd userfaultfd, , , MESI, . , , . — , . , , , . : syscall, -, syscall, . , . , , , . , , . , , ( , ) , .
Realmente me gusta porque aquí hay un ejemplo de una de mis técnicas favoritas: sumergirme en una capa de abstracción menos conocida, que cumple con relativa facilidad lo que pensamos que era casi imposible. Los cálculos de teletransportación pueden parecer imposibles o muy difíciles. Puede pensar que requeriría métodos como serializar todo el estado, copiar el ejecutable binario en la máquina remota e iniciarlo allí con banderas de línea de comando especiales para recargar el estado. Pero no, todo es mucho más simple. Bajo su lenguaje de programación favorito hay una capa de abstracción donde puede elegir un subconjunto de funciones bastante simple, y durante el fin de semana implementar la teletransportación de la mayoría de los cálculos puros en cualquier lenguaje de programación en 500 líneas de código. Yo creo queque tal salto a otro nivel de abstracción a menudo conduce a soluciones más simples y más universales. Otro de mis proyectos como este esNumderline .A primera vista, tales proyectos parecen ser hacks extremos, y en gran medida lo son. Hacen cosas como nadie espera, y cuando se rompen, lo hacen al nivel de abstracción, en el que programas similares no deberían funcionar, por ejemplo, los descriptores de sus archivos desaparecen misteriosamente. Pero a veces puede establecer correctamente el nivel de abstracción y codificar cualquier situación posible, de modo que al final todo funcione sin problemas y mágicamente. Creo que los buenos ejemplos aquí son rr (aunque Telefork logró saquearlo) y la migración a la nube de máquinas virtuales en tiempo real (de hecho, Telefork a nivel de hipervisor).También me gusta presentar estas cosas como ideas para formas alternativas de trabajar con sistemas informáticos. ¿Por qué nuestras API de computación en clúster son mucho más complicadas que un simple programa que traduce funciones en un clúster? ¿Por qué la programación del sistema de red es mucho más complicada que la multiproceso? Por supuesto, puede dar todo tipo de buenas razones, pero generalmente se basan en lo difícil que es hacer un ejemplo de los sistemas existentes. ¿O tal vez con la abstracción correcta o con el esfuerzo suficiente, todo funcionará fácilmente y sin problemas? Fundamentalmente, no hay nada imposible.
