Introducción
Si no ha dormido demasiado en los últimos años, entonces, por supuesto, ha escuchado de los transformadores: la arquitectura de la atención canónica es todo lo que necesita . ¿Por qué los transformadores son tan buenos? Por ejemplo, evitan la recurrencia, lo que les permite crear de manera eficiente una presentación de datos en la que se puede insertar una gran cantidad de información contextual, lo que afecta positivamente la capacidad de generar textos y la capacidad sin igual de transferir el aprendizaje.
Transformers lanzó una avalancha de trabajo sobre modelado de lenguaje, una tarea en la que el modelo selecciona la siguiente palabra, teniendo en cuenta las probabilidades de las palabras anteriores, es decir, aprender p(x)dónde está el xtoken actual. Como puede suponer, esta tarea no requiere marcado en absoluto y, por lo tanto, puede usar enormes matrices de texto sin anotar. Un modelo de lenguaje ya entrenado puede generar texto, tan bien que los autores a veces se niegan a diseñar modelos entrenados .
Pero, ¿qué pasa si queremos agregar algunos "bolígrafos" a la generación de texto? Por ejemplo, haga una generación condicional estableciendo un tema o controlando otros atributos. Tal forma ya requiere probabilidad condicional p(x|a), donde aestá el atributo deseado. ¿Interesante? ¡Vamos debajo del corte!
Los autores del artículo ofrecen un enfoque simple (y, por lo tanto, Plug and Play) y elegante para la generación condicional, utilizando un modelo de lenguaje pesado previamente entrenado (en adelante LM) y varios clasificadores simples, por lo tanto, el muestreo de una distribución de vista p(x|a) ∝ p(a|x)p(x). Cabe señalar que el LM original no se modifica de ninguna manera. Los autores proponen dos formas de clasificadores, llamados modelos de atributos en el artículo: BoW para control de temas y un clasificador lineal para control de tonalidad. Los autores hacen un análisis bastante detallado de sus contribuciones clave, comparando las ideas y enfoques de su método con otros artículos. Uno de los puntos más importantes es la facilidad de enfoque, y aquí, tal vez, solo mire esta placa:
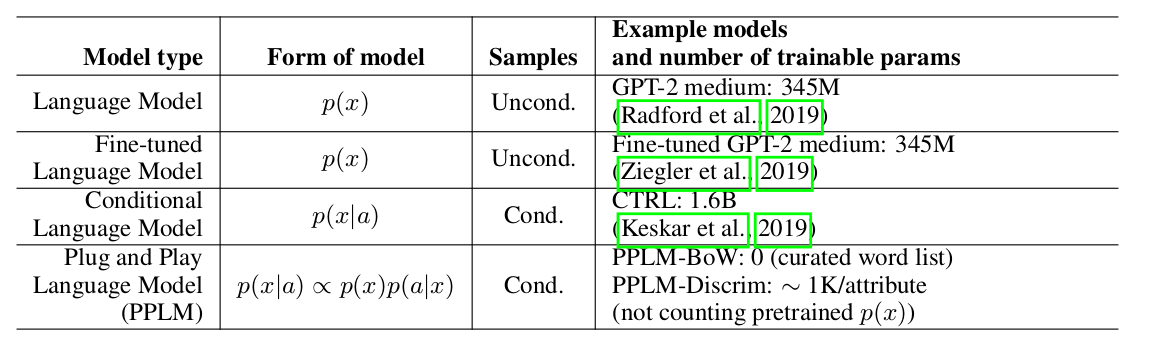
se puede ver que PPLM supera a todos los competidores en la cantidad de parámetros.
Decodificación ponderada 2.0
Uber weighted decoding: , . , , . , . , , , .
Uber : , LM, . , , , ( , ) . ( perturb_past — , .
? log-likelihood: p(x) a attribute model p(a|x). , backward pass .
log-likelihood? , :
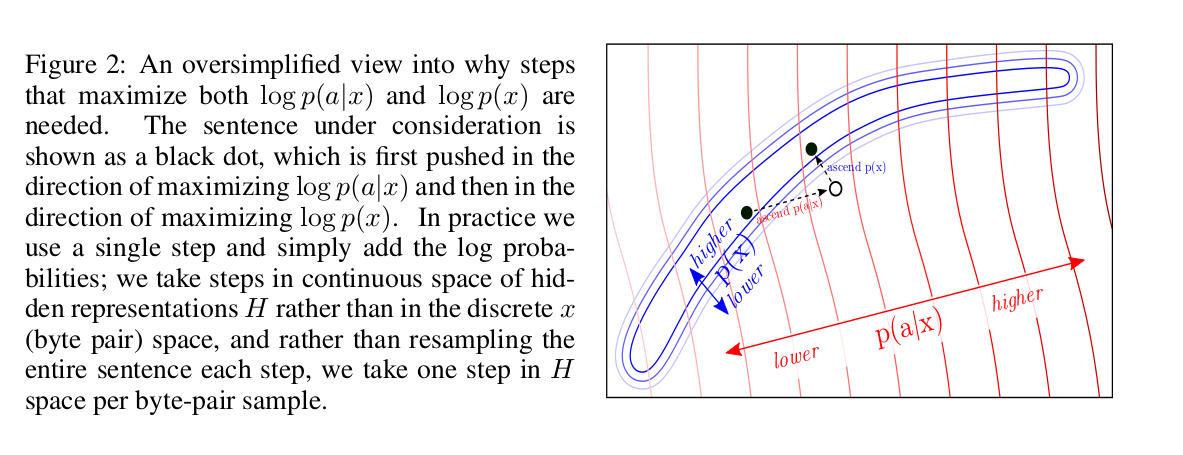
, , LM. , fluency LM.
, :

forward pass LM, p(a|x) — attribute model. backward pass, , attribute model, , . , .
, : “” k k forward backward pass’, n. LM forward pass. , : ( num of iterations=3 gen length=5, ).
, ( colab , ) , , , “the kitten” “military” :
- The kitten is a creature with no real personality, it is just a pet. You can use it as a combat item.
- The kitten that is now being called the "suspected killer" of a woman in a San Diego apartment complex was shot by another person who then shot him, according to authorities.
combat, shot, killer — , military. LM :
- The kitten that escaped a cage has been rescued from a cat sanctuary in Texas.
- The cat, named "Lucky," was found wandering in the back yard of the Humane Society at the time of the incident on Friday.
attribute models
, BoW discriminator. :
p_t+1 — LM, w_i — i- .
Discriminator model , BoW, , , , . , .
, LM, LM weighted decoding CTRL (conditional LM). fluency , , perplexity . PPLM :
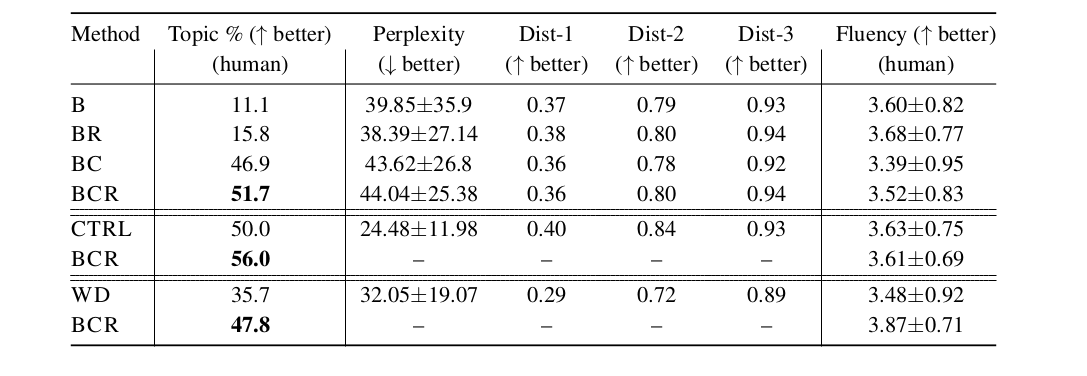
:
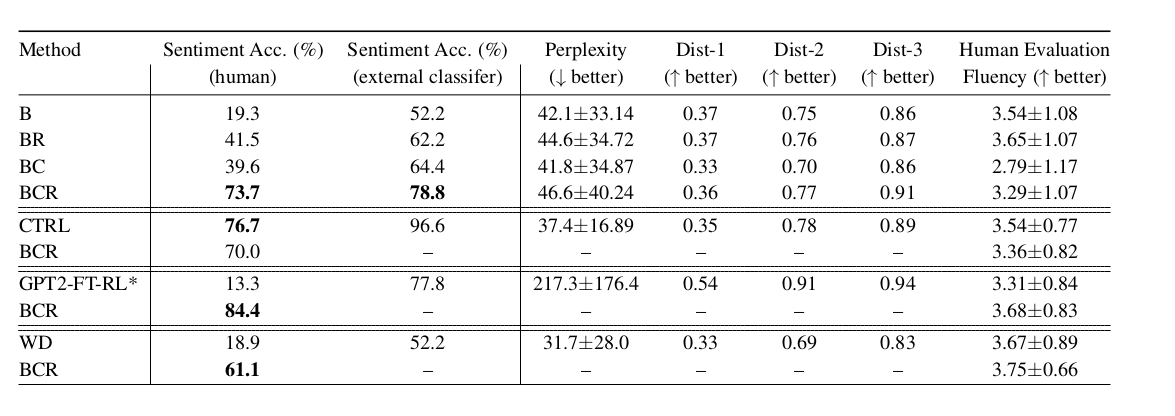
- B — baseline, GPT-2 LM;
- BR — , B,
r , log-likelihood ; - BC — , ;
- BCR — , BC,
r , log-likelihood ; - CTRL — Keskar et al, 2019;
- GPT2-FT-RL — GPT2, fine-tuned RL ;
- WD — weighted decoding,
p(a|x);
— , LM, . , , - :)