 Internet está lleno de artículos sobre modelos de lenguaje basados en N-gram. Al mismo tiempo, hay muy pocas bibliotecas listas para trabajar.Hay KenLM , SriLM e IRSTLM . Son populares y se usan en muchos proyectos grandes. Pero hay problemas:
Internet está lleno de artículos sobre modelos de lenguaje basados en N-gram. Al mismo tiempo, hay muy pocas bibliotecas listas para trabajar.Hay KenLM , SriLM e IRSTLM . Son populares y se usan en muchos proyectos grandes. Pero hay problemas:- Las bibliotecas son viejas, no se están desarrollando.
- Mal soporte para el idioma ruso.
- Solo trabaje con texto limpio y especialmente preparado
- Mal soporte para UTF-8. Por ejemplo, SriLM con el indicador de tolower rompe la codificación.
KenLM se
destaca un poco de la lista . Es compatible regularmente y no tiene problemas con UTF-8, pero también exige la calidad del texto.Una vez que necesitaba una biblioteca para construir un modelo de lenguaje. Después de muchas pruebas y errores, llegué a la conclusión de que preparar un conjunto de datos para enseñar un modelo de lenguaje es demasiado complicado y un proceso largo. ¡Especialmente si es ruso ! Pero de alguna manera quería automatizar todo.En su investigación, comenzó en la biblioteca SriLM . Notaré de inmediato que esto no es un préstamo de código o una bifurcación SriLM . Todo el código está escrito completamente desde cero.Un pequeño ejemplo de texto:
! .
La falta de espacio entre oraciones es un error tipográfico bastante común. Tal error es difícil de encontrar en una gran cantidad de datos, mientras que rompe el tokenizer.Después del procesamiento, aparecerá el siguiente N-gram en el modelo de idioma:
-0.3009452 !
Por supuesto, hay muchos otros problemas, errores tipográficos, caracteres especiales, abreviaturas, varias fórmulas matemáticas ... Todo esto debe manejarse correctamente.ANYKS LM ( ALM )
La biblioteca solo es compatible con los sistemas operativos Linux , MacOS X y FreeBSD . No tengo Windows y no tengo planeado soporte.Breve descripción de la funcionalidad.
- Soporte para UTF-8 sin dependencias de terceros.
- Soporte para formatos de datos: Arpa, Vocab, Secuencia de mapas, N-gramos, Diccionario binario alm.
- : Kneser-Nay, Modified Kneser-Nay, Witten-Bell, Additive, Good-Turing, Absolute discounting.
- , , , .
- , N-, N- , N-.
- — N-, .
- : , -.
- N- — N-, backoff .
- N- backoff-.
- , : , , , , Python3.
- « », .
- 〈unk〉 .
- N- Python3.
- , .
- . : , , .
- A diferencia de otros modelos de idiomas, ALM está garantizado para recopilar todos los N-gramos del texto, independientemente de su longitud (a excepción de Kneser-Nay modificado). También existe la posibilidad de registro obligatorio de todos los N-gramos raros, incluso si se reunieron solo 1 vez.
De los formatos de modelo de idioma estándar, solo se admite el formato ARPA . Honestamente, no veo ninguna razón para apoyar todo el zoológico en todo tipo de formatos.El formato ARPA distingue entre mayúsculas y minúsculas y también es un problema definido.A veces es útil saber solo la presencia de datos específicos en el N-gram. Por ejemplo, debe comprender la presencia de números en el N-gramo, y su significado no es tan importante.Ejemplo:
, 2
Como resultado, el N-gram entra en el modelo de lenguaje:
-0.09521468 2
El número específico, en este caso, no importa. La venta en la tienda puede durar 1 y 3 y tantos días como desee.Para resolver este problema, ALM usa tokenización de clase.Fichas Soportadas
Estándar:〈s〉 - Señal del comienzo de la oración〈/s〉 - Señal del final de la oración〈unk〉 - Señal de una palabra desconocidaNo estándar:〈url〉 - Señal de la dirección URL〈num〉 - Señal de números (árabe o romano)Arabicdate〉 - Fecha token (18 de julio de 2004 | 18/07/2004)〈time〉 - Token de tiempo (15:44:56)〈abbr〉 - Token de abreviatura (1st | 2nd | 20th)〉 anum〉 - Pseudo -Token números (T34 | 895-M-86 | 39km)〈math〉 - Token de operaciones matemáticas (+ | - | = | / | * | ^)〈range〉 - Token del rango de números (1-2 | 100-200 | 300- 400)proaprox〉- Una ficha numérica aproximada (~ 93 | ~ 95.86 | 10 ~ 20)〈puntuación〉 - Una ficha de cuenta numérica (4: 3 | 01:04)〈dimen〉 - Señal general (200x300 | 1920x1080)〈fract〉 - Una ficha fracción fraccional (5/20 | 192/864)〈punct〉 - Token de caracteres de puntuación (. | ... |, |! |? |: |;)〈Specl〉 - Token de caracteres especiales (~ | @ | # | No. |% | & | $ | § | ±)〈isolat〉 - Token de símbolo de aislamiento ("| '|" | "|„ | “|` | (|) | [|] | {|})Por supuesto, el soporte para cada uno de los tokens se puede deshabilitar si tales N-gramos son necesarios.Si necesita procesar otras etiquetas (por ejemplo, necesita encontrar nombres de países en el texto), ALM admite la conexión de scripts externos en Python3.Un ejemplo de un script de detección de token:
def init():
"""
:
"""
def run(token, word):
"""
:
@token
@word
"""
if token and (token == "<usa>"):
if word and (word.lower() == ""): return "ok"
elif token and (token == "<russia>"):
if word and (word.lower() == ""): return "ok"
return "no"
Tal script agrega dos etiquetas más a la lista de etiquetas estándar: 〈usa〉 y 〈russia〉 .Además del script para detectar tokens, hay soporte para un script para el preprocesamiento de palabras procesadas. Este script puede cambiar la palabra antes de agregarla al modelo de idioma.Un ejemplo de un script de procesamiento de texto:
def init():
"""
:
"""
def run(word, context):
"""
:
@word
@context
"""
return word
Tal enfoque puede ser útil si es necesario montar un modelo de lenguaje que consiste en lemas o stemms .Lenguaje Modelo Formatos de texto compatibles con ALM
ARPA:
\data\
ngram 1=52
ngram 2=68
ngram 3=15
\1-grams:
-1.807052 1- -0.30103
-1.807052 2 -0.30103
-1.807052 3~4 -0.30103
-2.332414 -0.394770
-3.185530 -0.311249
-3.055896 -0.441649
-1.150508 </s>
-99 <s> -0.3309932
-2.112406 <unk>
-1.807052 T358 -0.30103
-1.807052 VII -0.30103
-1.503878 -0.39794
-1.807052 -0.30103
-1.62953 -0.30103
...
\2-grams:
-0.29431 1-
-0.29431 2
-0.29431 3~4
-0.8407791 <s>
-1.328447 -0.477121
...
\3-grams:
-0.09521468
-0.166590
...
\end\
ARPA es el formato de texto estándar para el modelo de lenguaje de lenguaje natural utilizado por Sphinx / CMU y Kaldi .NGRAMAS:
\data\
ad=1
cw=23832
unq=9390
ngram 1=9905
ngram 2=21907
ngram 3=306
\1-grams:
<s> 2022 | 1
<num> 117 | 1
<unk> 19 | 1
<abbr> 16 | 1
<range> 7 | 1
</s> 2022 | 1
244 | 1
244 | 1
11 | 1
762 | 1
112 | 1
224 | 1
1 | 1
86 | 1
978 | 1
396 | 1
108 | 1
77 | 1
32 | 1
...
\2-grams:
<s> <num> 7 | 1
<s> <unk> 1 | 1
<s> 84 | 1
<s> 83 | 1
<s> 57 | 1
82 | 1
11 | 1
24 | 1
18 | 1
31 | 1
45 | 1
97 | 1
71 | 1
...
\3-grams:
<s> <num> </s> 3 | 1
<s> 6 | 1
<s> 4 | 1
<s> 2 | 1
<s> 3 | 1
2 | 1
</s> 2 | 1
2 | 1
2 | 1
2 | 1
2 | 1
2 | 1
</s> 2 | 1
</s> 3 | 1
2 | 1
...
\end\
Ngrams : el formato de texto no estándar del modelo de idioma es una modificación del formato ARPA .Descripción:- ad - Número de documentos en el gabinete
- cw - El número de palabras en todos los documentos en el corpus
- unq : número de palabras únicas recopiladas
VOCAB:
\data\
ad=1
cw=23832
unq=9390
\words:
33 244 | 1 | 0.010238 | 0.000000 | -3.581616
34 11 | 1 | 0.000462 | 0.000000 | -6.680889
35 762 | 1 | 0.031974 | 0.000000 | -2.442838
40 12 | 1 | 0.000504 | 0.000000 | -6.593878
330344 47 | 1 | 0.001972 | 0.000000 | -5.228637
335190 17 | 1 | 0.000713 | 0.000000 | -6.245571
335192 1 | 1 | 0.000042 | 0.000000 | -9.078785
335202 22 | 1 | 0.000923 | 0.000000 | -5.987742
335206 7 | 1 | 0.000294 | 0.000000 | -7.132874
335207 29 | 1 | 0.001217 | 0.000000 | -5.711489
2282019644 1 | 1 | 0.000042 | 0.000000 | -9.078785
2282345502 10 | 1 | 0.000420 | 0.000000 | -6.776199
2282416889 2 | 1 | 0.000084 | 0.000000 | -8.385637
3009239976 1 | 1 | 0.000042 | 0.000000 | -9.078785
3009763109 1 | 1 | 0.000042 | 0.000000 | -9.078785
3013240091 1 | 1 | 0.000042 | 0.000000 | -9.078785
3014009989 1 | 1 | 0.000042 | 0.000000 | -9.078785
3015727462 2 | 1 | 0.000084 | 0.000000 | -8.385637
3025113549 1 | 1 | 0.000042 | 0.000000 | -9.078785
3049820849 1 | 1 | 0.000042 | 0.000000 | -9.078785
3061388599 1 | 1 | 0.000042 | 0.000000 | -9.078785
3063804798 1 | 1 | 0.000042 | 0.000000 | -9.078785
3071212736 1 | 1 | 0.000042 | 0.000000 | -9.078785
3074971025 1 | 1 | 0.000042 | 0.000000 | -9.078785
3075044360 1 | 1 | 0.000042 | 0.000000 | -9.078785
3123271427 1 | 1 | 0.000042 | 0.000000 | -9.078785
3123322362 1 | 1 | 0.000042 | 0.000000 | -9.078785
3126399411 1 | 1 | 0.000042 | 0.000000 | -9.078785
…
Vocab es un formato de diccionario de texto no estándar en el modelo de idioma.Descripción:- oc - ocurrencia de caso
- dc - ocurrencia en documentos
- tf - (term frequency — ) — . , , : [tf = oc / cw]
- idf - (inverse document frequency — ) — , , : [idf = log(ad / dc)]
- tf-idf - : [tf-idf = tf * idf]
- wltf - , : [wltf = 1 + log(tf * dc)]
MAP:
1:{2022,1,0}|42:{57,1,0}|279603:{2,1,0}
1:{2022,1,0}|42:{57,1,0}|320749:{2,1,0}
1:{2022,1,0}|42:{57,1,0}|351283:{2,1,0}
1:{2022,1,0}|42:{57,1,0}|379815:{3,1,0}
1:{2022,1,0}|42:{57,1,0}|26122748:{3,1,0}
1:{2022,1,0}|44:{6,1,0}
1:{2022,1,0}|48:{1,1,0}
1:{2022,1,0}|51:{11,1,0}|335967:{3,1,0}
1:{2022,1,0}|53:{14,1,0}|371327:{3,1,0}
1:{2022,1,0}|53:{14,1,0}|40260976:{7,1,0}
1:{2022,1,0}|65:{68,1,0}|34:{2,1,0}
1:{2022,1,0}|65:{68,1,0}|3277:{3,1,0}
1:{2022,1,0}|65:{68,1,0}|278003:{2,1,0}
1:{2022,1,0}|65:{68,1,0}|320749:{2,1,0}
1:{2022,1,0}|65:{68,1,0}|11353430797:{2,1,0}
1:{2022,1,0}|65:{68,1,0}|34270133320:{2,1,0}
1:{2022,1,0}|65:{68,1,0}|51652356484:{2,1,0}
1:{2022,1,0}|65:{68,1,0}|66967237546:{2,1,0}
1:{2022,1,0}|2842:{11,1,0}|42:{7,1,0}
…
Mapa : el contenido del archivo tiene un significado puramente técnico. Utilizado junto con el archivo de vocabulario , puede combinar varios modelos de idiomas, modificar, almacenar, distribuir y exportar a cualquier formato ( arpa , ngrams , binary alm ).Formatos de archivo de texto auxiliar admitidos por ALM
A menudo, al ensamblar un modelo de lenguaje, se encuentran errores tipográficos en el texto, que son sustituciones de letras (con letras visualmente similares de otro alfabeto).ALM resuelve este problema con un archivo con letras de aspecto similar.p
c
o
t
k
e
a
h
x
b
m
Si, al enseñar un modelo de lenguaje, transfiere archivos con una lista de dominios y abreviaturas de primer nivel, ALM puede ayudarlo a detectar con mayor precisión las etiquetas de clase 〈url〉 y 〈abbr〉 .Archivo de lista de abreviaturas:
…
Archivo de lista de zonas de dominio:
ru
su
cc
net
com
org
info
…
Para una detección más precisa del token 〈url〉 , debe agregar sus zonas de dominio de primer nivel (todas las zonas de dominio del ejemplo ya están preinstaladas) .Contenedor binario del modelo de lenguaje ALM
Para crear un contenedor binario para el modelo de idioma, debe crear un archivo JSON con una descripción de sus parámetros.Opciones de JSON:
{
"aes": 128,
"name": "Name dictionary",
"author": "Name author",
"lictype": "License type",
"lictext": "License text",
"contacts": "Contacts data",
"password": "Password if needed",
"copyright": "Copyright author"
}
Descripción:- aes : tamaño de cifrado AES (128, 192, 256) bits
- nombre - Nombre del diccionario
- autor - Autor del diccionario
- lictype - Tipo de licencia
- lictext - Texto de licencia
- contactos - Datos de contacto del autor
- contraseña : contraseña de cifrado (si es necesario), el cifrado se realiza solo cuando se configura una contraseña
- copyright - Copyright del propietario del diccionario
Todos los parámetros son opcionales excepto el nombre del contenedor.Ejemplos de bibliotecas ALM
Operación Tokenizer
El tokenizer recibe texto en la entrada y genera JSON en la salida.$ echo 'Hello World?' | ./alm -alphabet "abcdefghijklmnopqrstuvwxyz" -method tokens
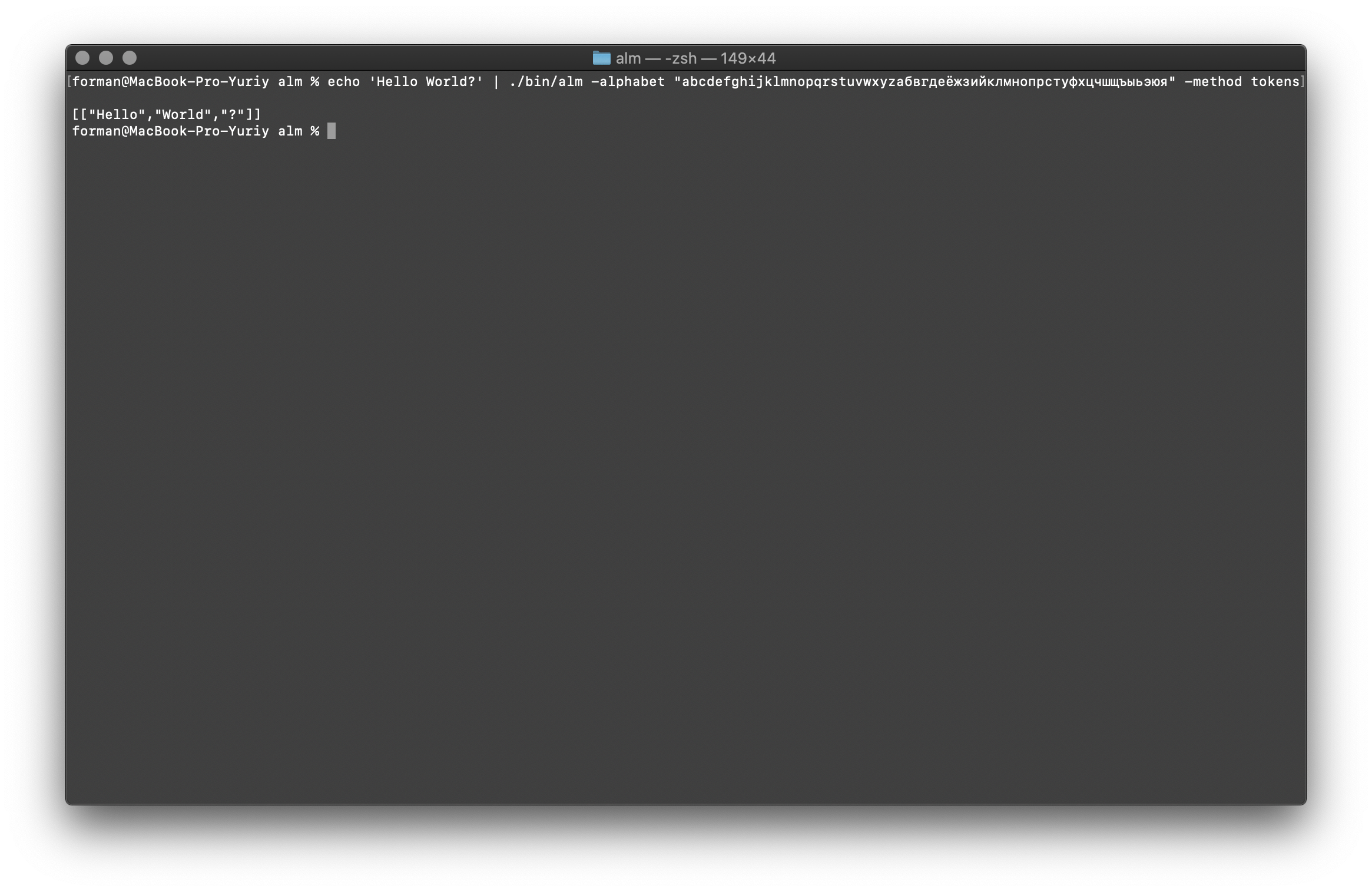 Prueba:
Prueba:Hello World?
Resultado:[
["Hello","World","?"]
]
Probemos algo más duro ...$ echo ' ??? ....' | ./alm -alphabet "abcdefghijklmnopqrstuvwxyz" -method tokens
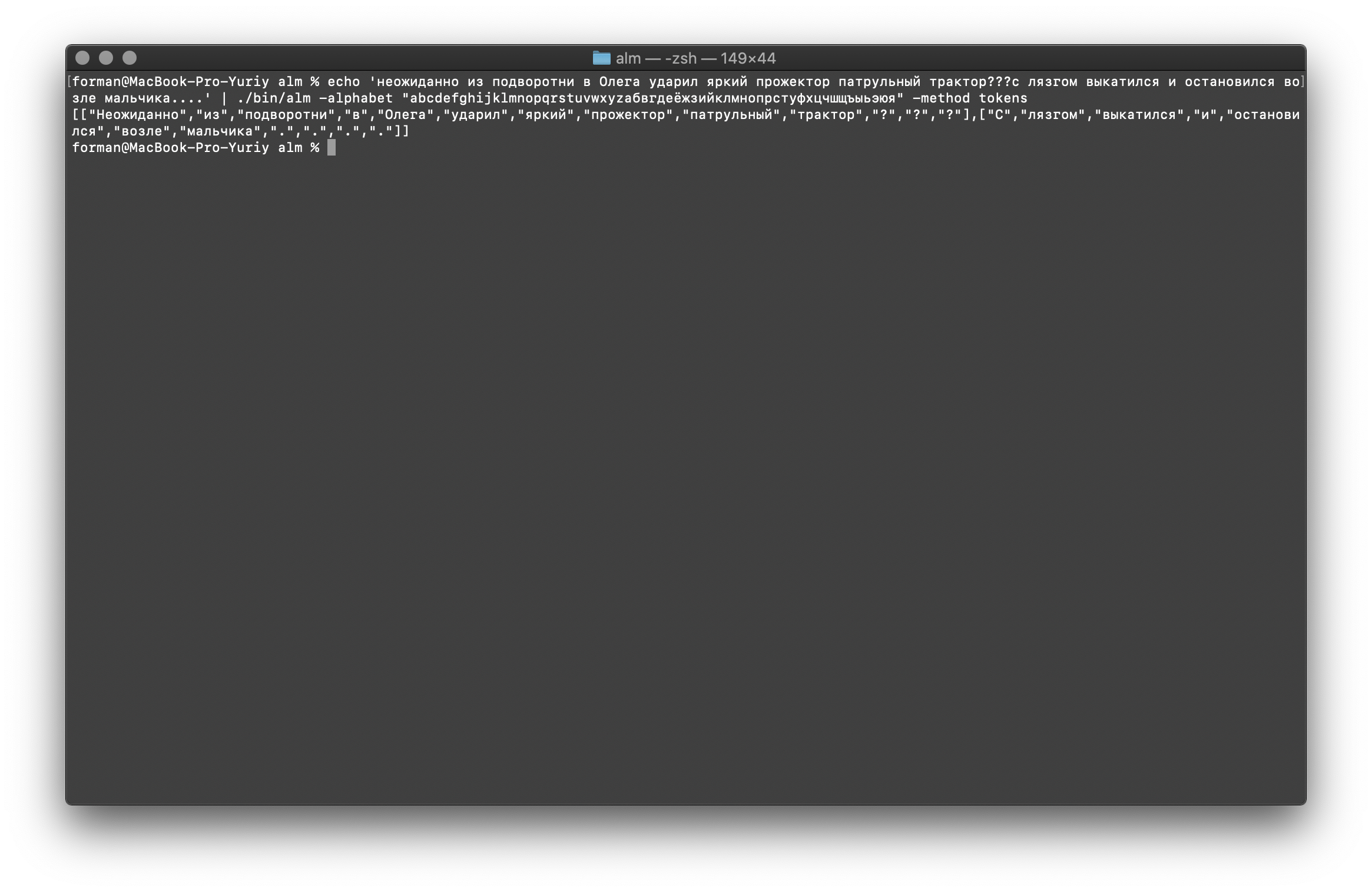 Prueba:
Prueba: ??? ....
Resultado:[
[
"",
"",
"",
"",
"",
"",
"",
"",
"",
"",
"?",
"?",
"?"
],[
"",
"",
"",
"",
"",
"",
"",
".",
".",
".",
"."
]
]
Como puede ver, el tokenizer funcionó correctamente y solucionó los errores básicos.Cambia un poco el texto y mira el resultado.$ echo ' ... .' | ./alm -alphabet "abcdefghijklmnopqrstuvwxyz" -method tokens
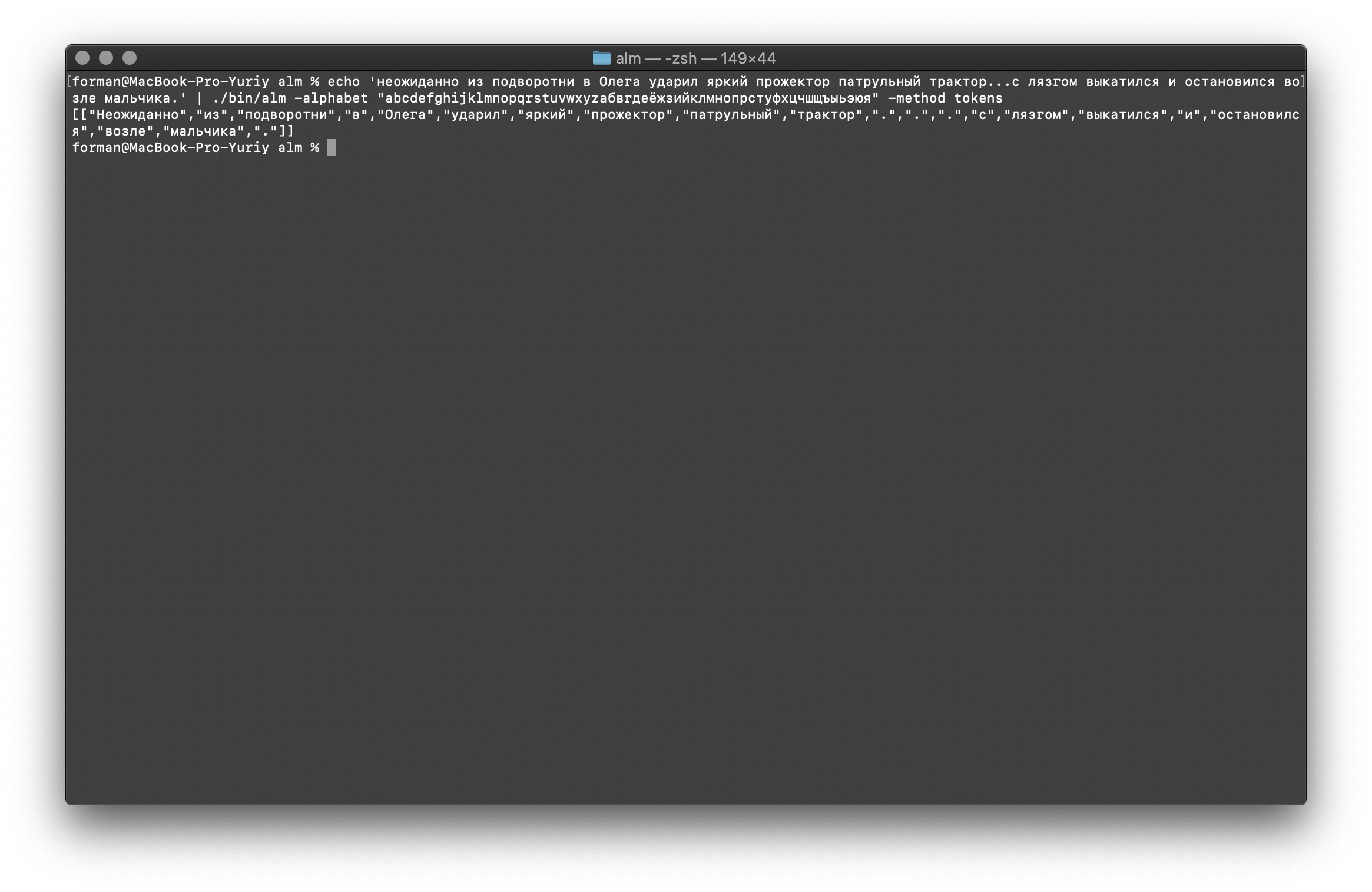 Prueba:
Prueba: ... .
Resultado:[
[
"",
"",
"",
"",
"",
"",
"",
"",
"",
"",
".",
".",
".",
"",
"",
"",
"",
"",
"",
"",
"."
]
]
Como puede ver, el resultado ha cambiado. Ahora intenta otra cosa.$ echo ' 5–7 . : 1 . ( +37–38°), 5–10 . – ( +12–15°) ..»| |()' | ./alm -alphabet "abcdefghijklmnopqrstuvwxyz" -method tokens
 Prueba:
Prueba: 5–7 . : 1 . ( +37–38°), 5–10 . – ( +12–15°) ..»| |()
Resultado:[
[
"",
"",
"",
"",
"5–7",
".",
"",
"",
"",
"",
"",
"",
"",
"",
"",
"",
"",
"",
"",
":",
"1",
".",
"",
"",
"(",
"+37–38°",
")",
",",
"",
"5–10",
".",
"–",
"",
"",
"(",
"+12–15°",
")",
"",
"..",
"»",
"|",
"|",
"(",
")"
]
]
Combina todo de nuevo en texto
Primero, restaure la primera prueba.$ echo '[["Hello","World","?"]]' | ./alm -alphabet "abcdefghijklmnopqrstuvwxyz" -method tokens
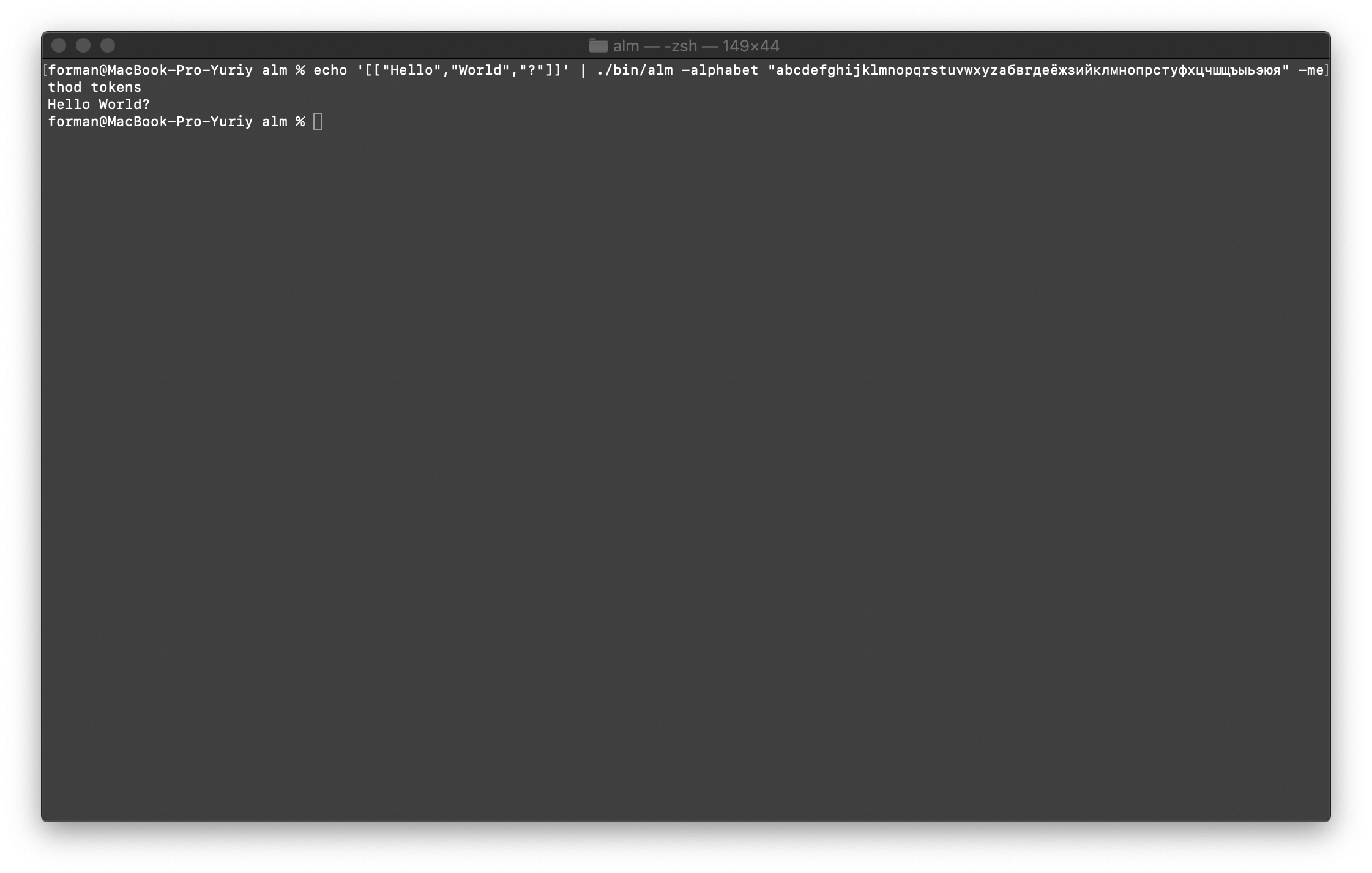 Prueba:
Prueba:[["Hello","World","?"]]
Resultado:Hello World?
Ahora restauraremos la prueba más compleja.$ echo '[["","","","","","","","","","","?","?","?"],["","","","","","","",".",".",".","."]]' | ./alm -alphabet "abcdefghijklmnopqrstuvwxyz" -method tokens
 Prueba:
Prueba:[["","","","","","","","","","","?","?","?"],["","","","","","","",".",".",".","."]]
Resultado: ???
….
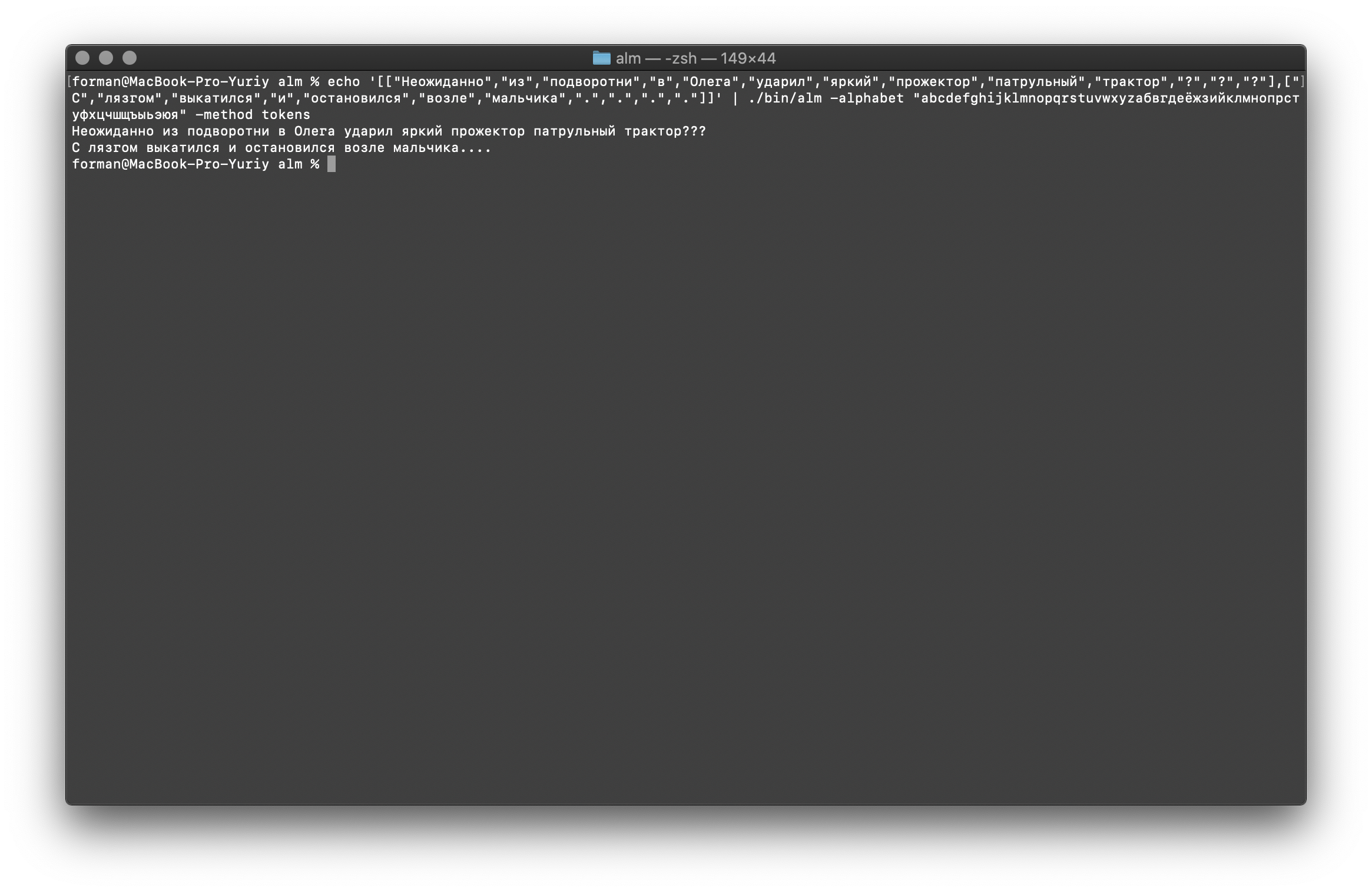
Como puede ver, el tokenizer pudo restaurar el texto inicialmente roto.Continúa en.$ echo '[["","","","","","","","","","",".",".",".","","","","","","","","."]]' | ./alm -alphabet "abcdefghijklmnopqrstuvwxyz" -method tokens
 Prueba:
Prueba:[["","","","","","","","","","",".",".",".","","","","","","","","."]]
Resultado: ... .
Y finalmente, marque la opción más difícil.$ echo '[["","","","","5–7",".","","","","","","","","","","","","","",":","1",".","","","(","+37–38°",")",",","","5–10",".","–","","","(","+12–15°",")","","..","»","|","|","(",")"]]' | ./alm -alphabet "abcdefghijklmnopqrstuvwxyz" -method tokens
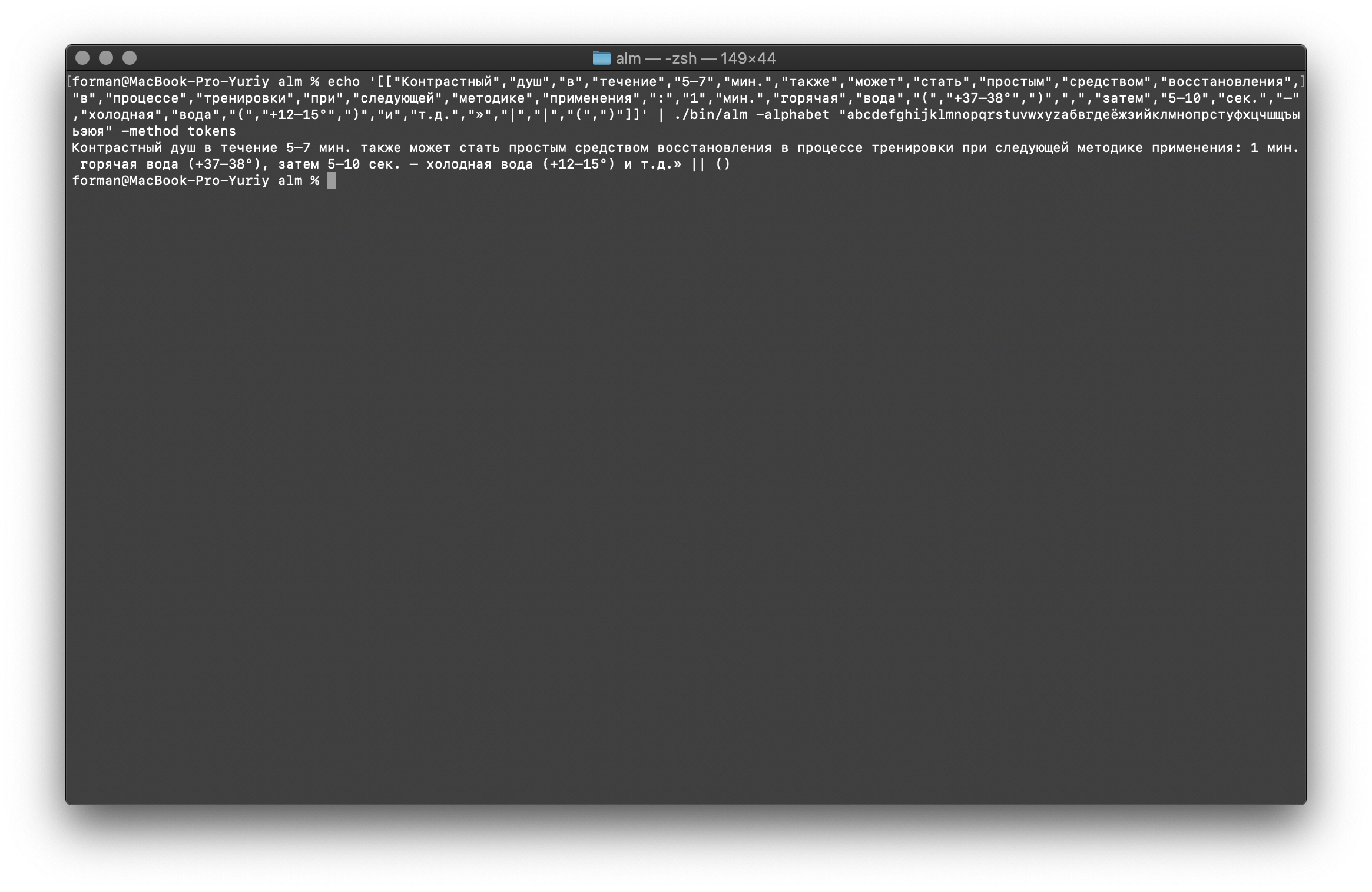 Prueba:
Prueba:[["","","","","5–7",".","","","","","","","","","","","","","",":","1",".","","","(","+37–38°",")",",","","5–10",".","–","","","(","+12–15°",")","","..","»","|","|","(",")"]]
Resultado: 5–7 . : 1 . (+37–38°), 5–10 . – (+12–15°) ..» || ()
Como se puede ver en los resultados, el tokenizer puede corregir la mayoría de los errores en el diseño del texto.Entrenamiento de modelo de lenguaje
$ ./alm -alphabet "abcdefghijklmnopqrstuvwxyz" -size 3 -smoothing wittenbell -method train -debug 1 -w-arpa ./lm.arpa -w-map ./lm.map -w-vocab ./lm.vocab -w-ngram ./lm.ngrams -allow-unk -interpolate -corpus ./text.txt -threads 0 -train-segments
Describiré los parámetros de ensamblaje con más detalle.- tamaño : el tamaño de la longitud de N-gramos (el tamaño se establece en 3 gramos )
- suavizado : algoritmo de suavizado (algoritmo seleccionado por Witten-Bell )
- Método : método de trabajo (método de capacitación especificado )
- debug - Modo de depuración (el indicador de estado de aprendizaje está configurado)
- w-arpa — ARPA
- w-map — MAP
- w-vocab — VOCAB
- w-ngram — NGRAM
- allow-unk — 〈unk〉
- interpolate —
- corpus — . ,
- subprocesos : utilice subprocesos múltiples para la capacitación (0: para la capacitación, se proporcionarán todos los núcleos de procesador disponibles,> 0 el número de núcleos que participan en la capacitación)
- segmentos de trenes : el edificio de capacitación se segmentará de manera uniforme en todos los núcleos
Se puede obtener más información usando la bandera [-help] .
Cálculo de perplejidad
$ echo " ??? ...." | ./alm -alphabet "abcdefghijklmnopqrstuvwxyz" -method ppl -debug 2 -r-arpa ./lm.arpa -confidence -threads 0
 Prueba:
Prueba: ??? ….
Resultado:info: <s> <punct> <punct> <punct> </s>
info: p( | <s> ) = [2gram] 0.00209192 [ -2.67945500 ] / 0.99999999
info: p( | ...) = [3gram] 0.91439744 [ -0.03886500 ] / 1.00000035
info: p( | ...) = [3gram] 0.86302624 [ -0.06397600 ] / 0.99999998
info: p( | ...) = [3gram] 0.98003368 [ -0.00875900 ] / 1.00000088
info: p( | ...) = [3gram] 0.85783547 [ -0.06659600 ] / 0.99999955
info: p( | ...) = [3gram] 0.95238819 [ -0.02118600 ] / 0.99999897
info: p( | ...) = [3gram] 0.97959599 [ -0.00895300 ] / 1.00000090
info: p( | ...) = [3gram] 0.97959599 [ -0.00895300 ] / 1.00000090
info: p( | ...) = [3gram] 0.97959599 [ -0.00895300 ] / 1.00000090
info: p( | ...) = [3gram] 0.97959599 [ -0.00895300 ] / 1.00000090
info: p( <punct> | ...) = [3gram] 0.78127873 [ -0.10719400 ] / 1.00000031
info: p( <punct> | <punct> ...) = [2gram] 0.29417110 [ -0.53140000 ] / 0.99999998
info: p( <punct> | <punct> ...) = [3gram] 0.51262054 [ -0.29020400 ] / 0.99999998
info: p( </s> | <punct> ...) = [3gram] 0.45569787 [ -0.34132300 ] / 0.99999998
info: 1 sentences, 13 words, 0 OOVs
info: 0 zeroprobs, logprob= -4.18477000 ppl= 1.99027067 ppl1= 2.09848266
info: <s> <punct> <punct> <punct> <punct> </s>
info: p( | <s> ) = [2gram] 0.00809597 [ -2.09173100 ] / 0.99999999
info: p( | ...) = [3gram] 0.19675329 [ -0.70607800 ] / 0.99999972
info: p( | ...) = [3gram] 0.97959599 [ -0.00895300 ] / 1.00000090
info: p( | ...) = [3gram] 0.98007204 [ -0.00874200 ] / 0.99999931
info: p( | ...) = [3gram] 0.85785325 [ -0.06658700 ] / 1.00000018
info: p( | ...) = [3gram] 0.81482810 [ -0.08893400 ] / 1.00000027
info: p( | ...) = [3gram] 0.93507404 [ -0.02915400 ] / 1.00000058
info: p( <punct> | ...) = [3gram] 0.76391493 [ -0.11695500 ] / 0.99999971
info: p( <punct> | <punct> ...) = [2gram] 0.29417110 [ -0.53140000 ] / 0.99999998
info: p( <punct> | <punct> ...) = [3gram] 0.51262054 [ -0.29020400 ] / 0.99999998
info: p( <punct> | <punct> ...) = [3gram] 0.51262054 [ -0.29020400 ] / 0.99999998
info: p( </s> | <punct> ...) = [3gram] 0.45569787 [ -0.34132300 ] / 0.99999998
info: 1 sentences, 11 words, 0 OOVs
info: 0 zeroprobs, logprob= -4.57026500 ppl= 2.40356248 ppl1= 2.60302678
info: 2 sentences, 24 words, 0 OOVs
info: 0 zeroprobs, logprob= -8.75503500 ppl= 2.23975957 ppl1= 2.31629103
info: work time shifting: 0 seconds
Creo que no hay nada especial que comentar, por lo que continuaremos más allá.Verificación de existencia de contexto
$ echo "<s> </s>" | ./alm -alphabet "abcdefghijklmnopqrstuvwxyz" -method checktext -debug 1 -r-arpa ./lm.arpa -confidence
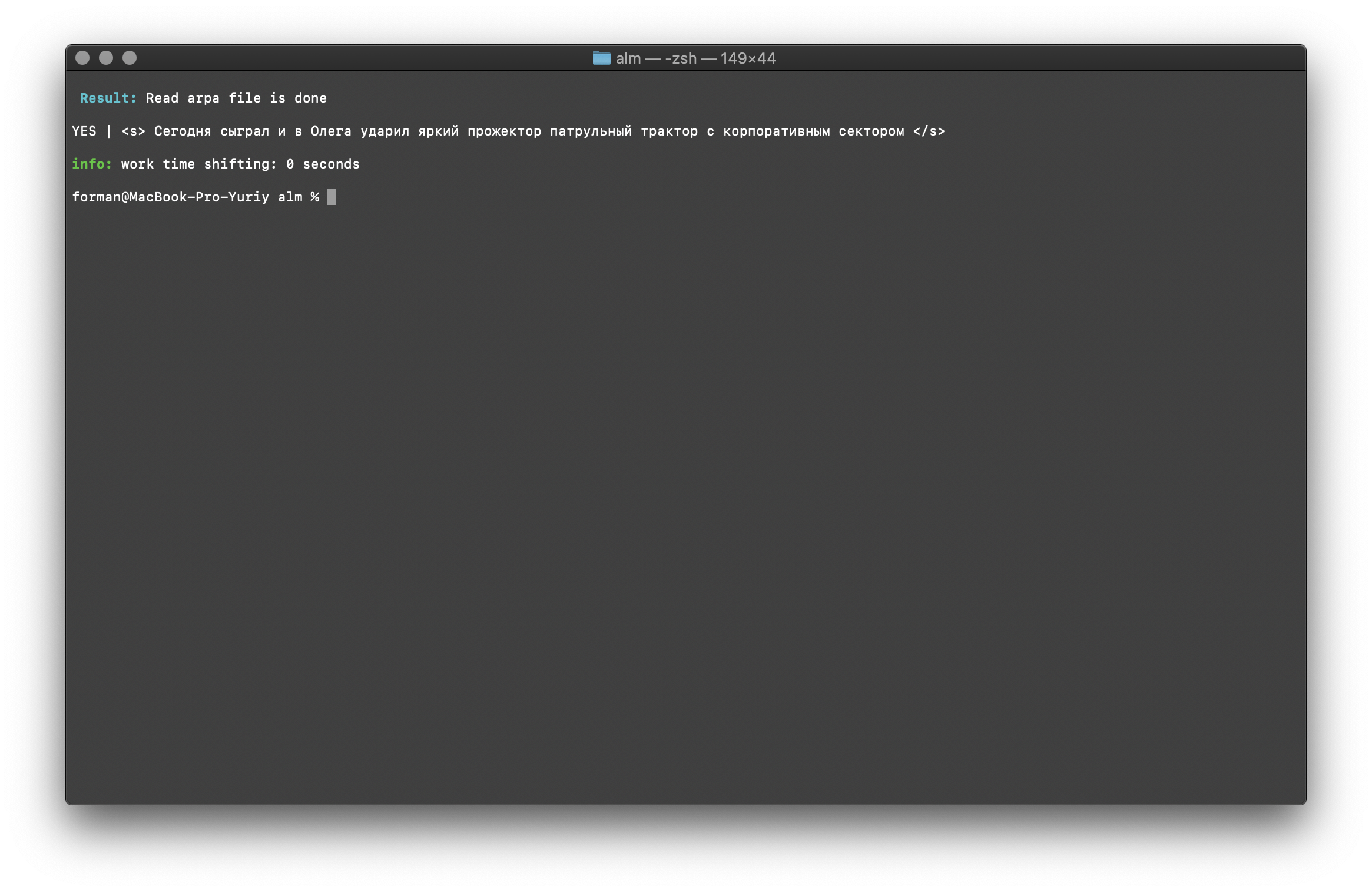 Prueba:
Prueba:<s> </s>
Resultado:YES | <s> </s>
El resultado muestra que el texto que se verifica tiene el contexto correcto en términos del modelo de lenguaje ensamblado.Indicador [ -confianza ]: significa que el modelo de idioma se cargará tal como se creó, sin sobreobservación.Corrección de mayúsculas y minúsculas
$ echo " ??? ...." | ./alm -alphabet "abcdefghijklmnopqrstuvwxyz" -method fixcase -debug 1 -r-arpa ./lm.arpa -confidence
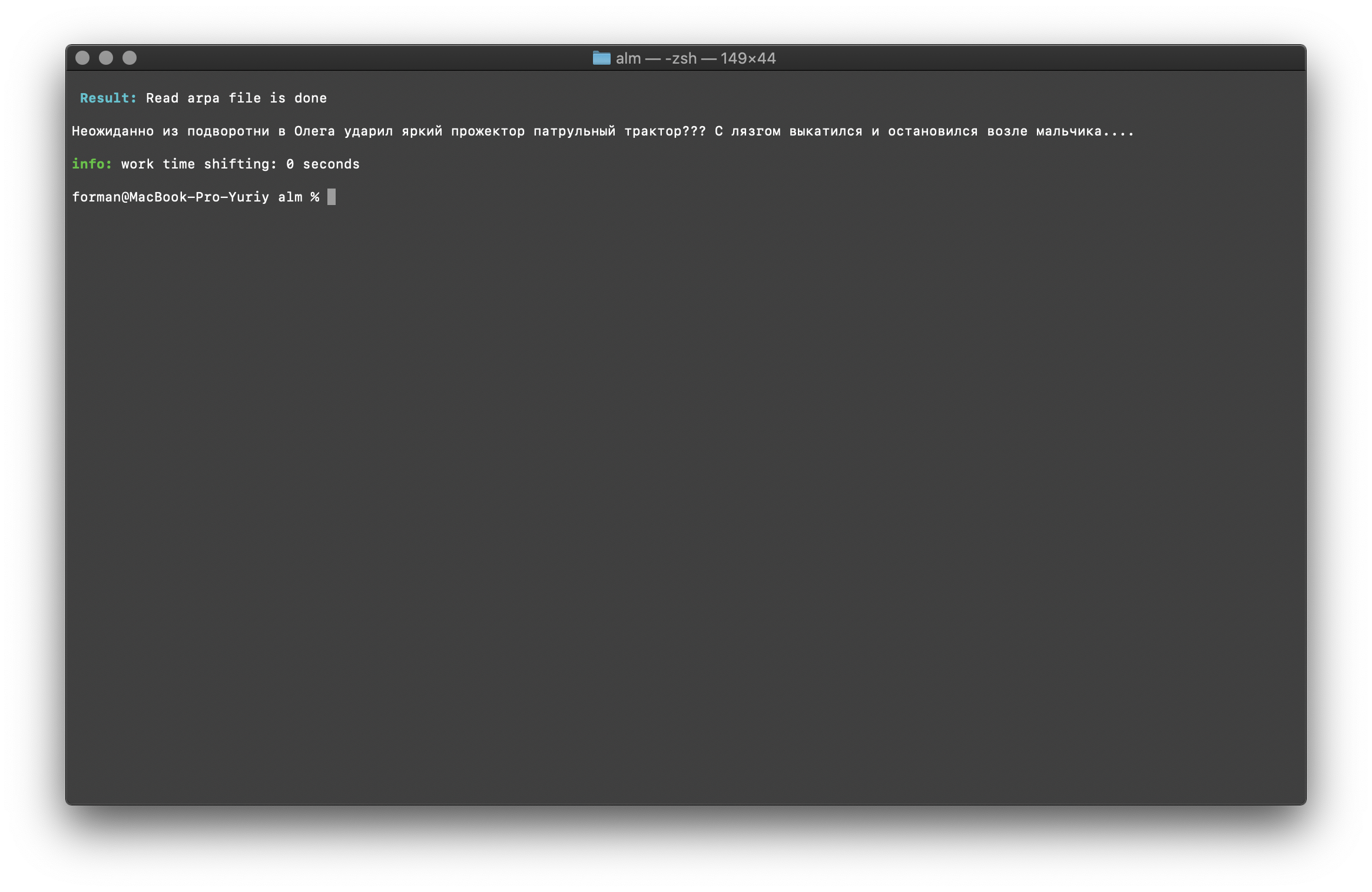 Prueba:
Prueba: ??? ....
Resultado: ??? ....
Los registros en el texto se restauran teniendo en cuenta el contexto del modelo de lenguaje.Las bibliotecas descritas anteriormente para trabajar con modelos de lenguaje estadístico distinguen entre mayúsculas y minúsculas. Por ejemplo, el N-gramo " en Moscú lloverá mañana " no es lo mismo que el N-gramo " en Moscú lloverá mañana ", estos son N-gramos completamente diferentes. Pero, ¿qué sucede si se requiere que el caso distinga entre mayúsculas y minúsculas y, al mismo tiempo, duplicar los mismos N-gramos es irracional? ALM representa todos los N-gramos en minúsculas. Esto elimina la posibilidad de duplicación de N-gramos. ALM también mantiene su clasificación de registros de palabras en cada N-gramo. Al exportar al formato de texto de un modelo de idioma, los registros se restauran según su clasificación.Comprobación de la cantidad de N-gramos
$ echo " ??? ...." | ./alm -alphabet "abcdefghijklmnopqrstuvwxyz" -method counts -debug 1 -r-arpa ./lm.arpa -confidence
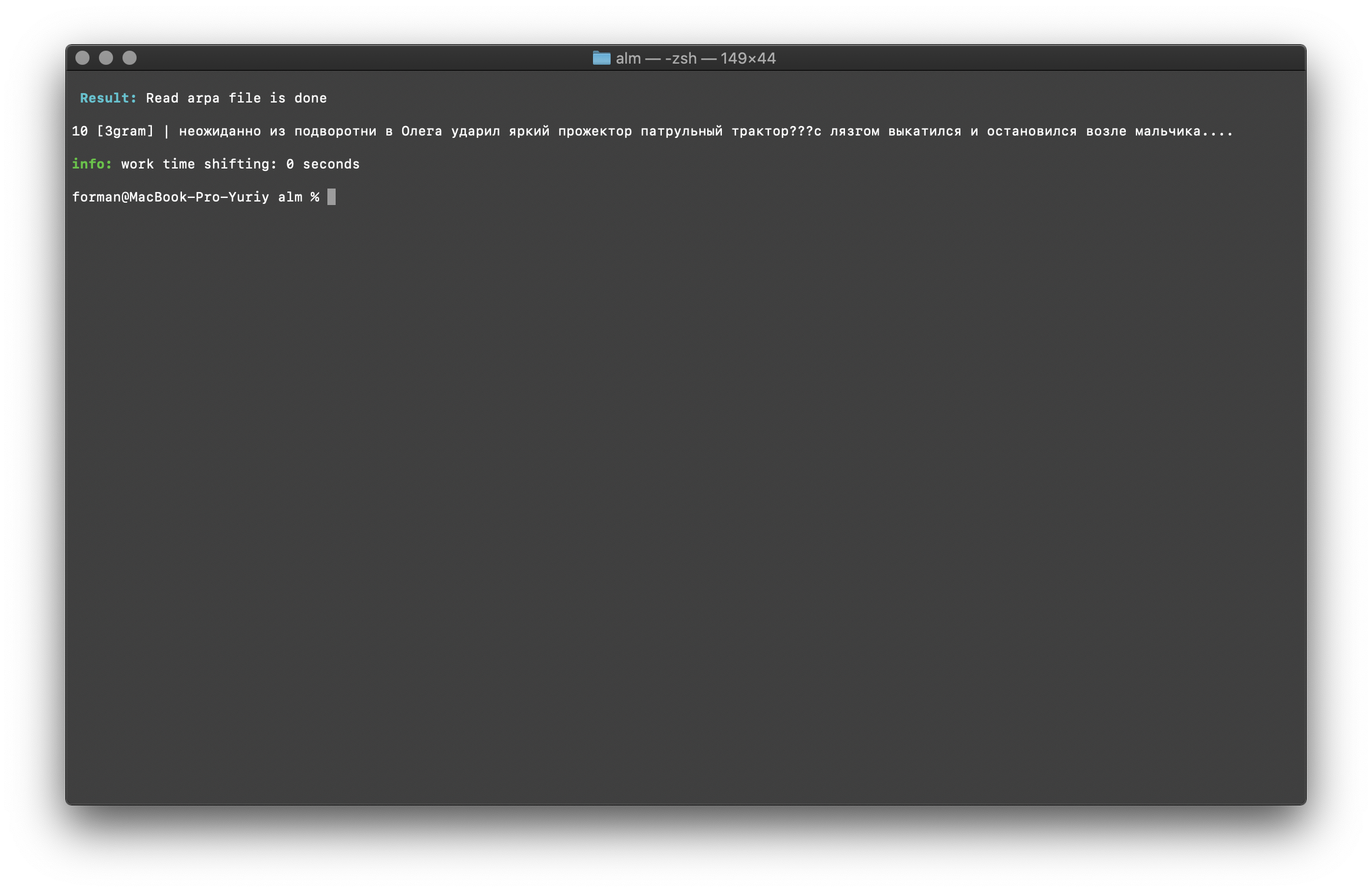 Prueba:
Prueba: ??? ....
Resultado:10 [3gram] |
N- , .
La comprobación del número de N-gramos se realiza por el tamaño del N-gramo en el modelo de lenguaje. También existe la oportunidad de verificar bigrams y trigrams .Bigram Check
$ echo " ??? ...." | ./alm -alphabet "abcdefghijklmnopqrstuvwxyz" -method counts -ngrams bigram -debug 1 -r-arpa ./lm.arpa -confidence
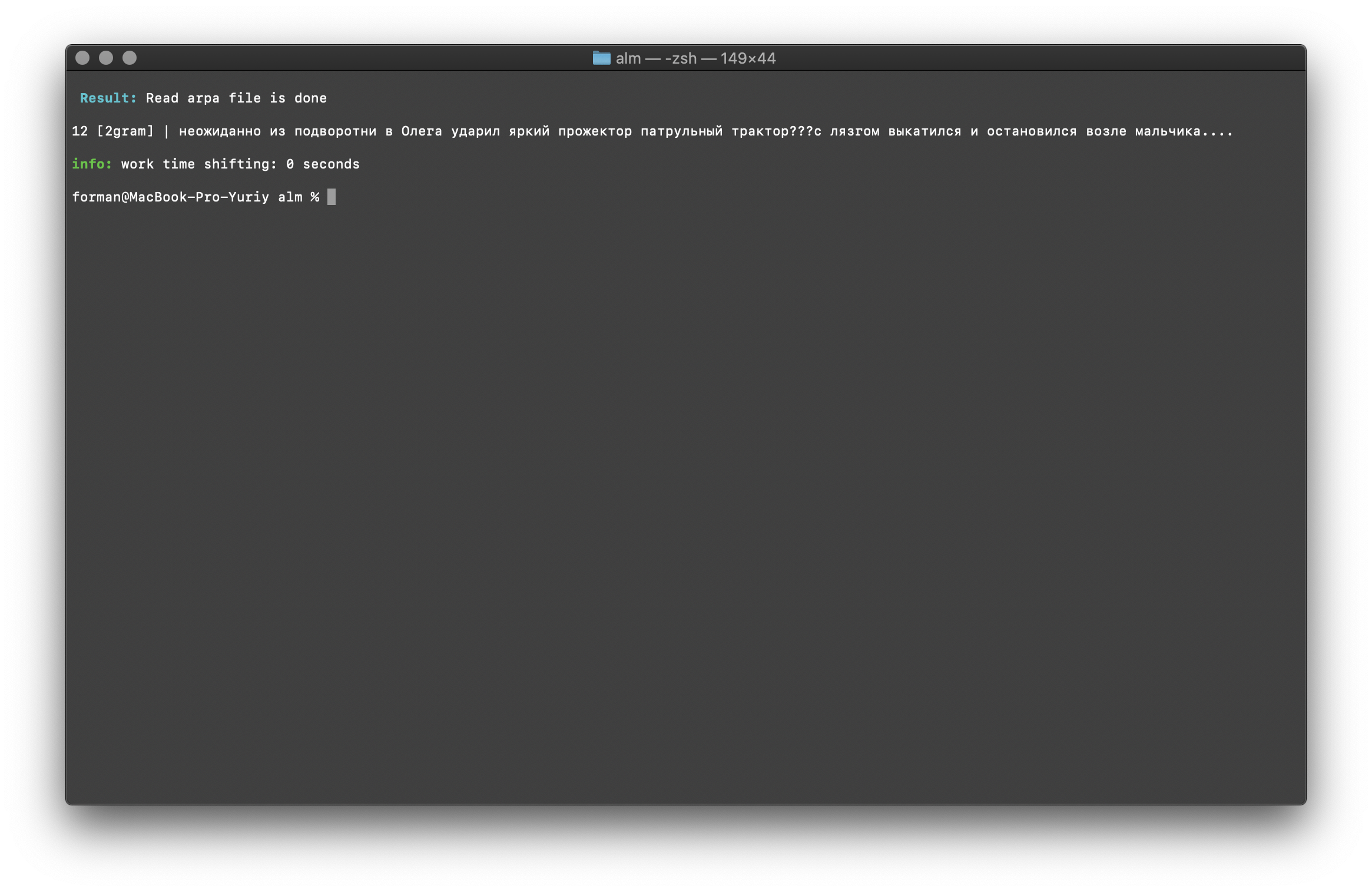 Prueba:
Prueba: ??? ....
Resultado:12 [2gram] | ??? ….
Trigram Check
$ echo " ??? ...." | ./alm -alphabet "abcdefghijklmnopqrstuvwxyz" -method counts -ngrams trigram -debug 1 -r-arpa ./lm.arpa -confidence
Prueba: ??? ....
Resultado:10 [3gram] | ??? ….
Buscar N-gramos en el texto
$ echo " " | ./alm -alphabet "abcdefghijklmnopqrstuvwxyz" -method find -debug 1 -r-arpa ./lm.arpa -confidence
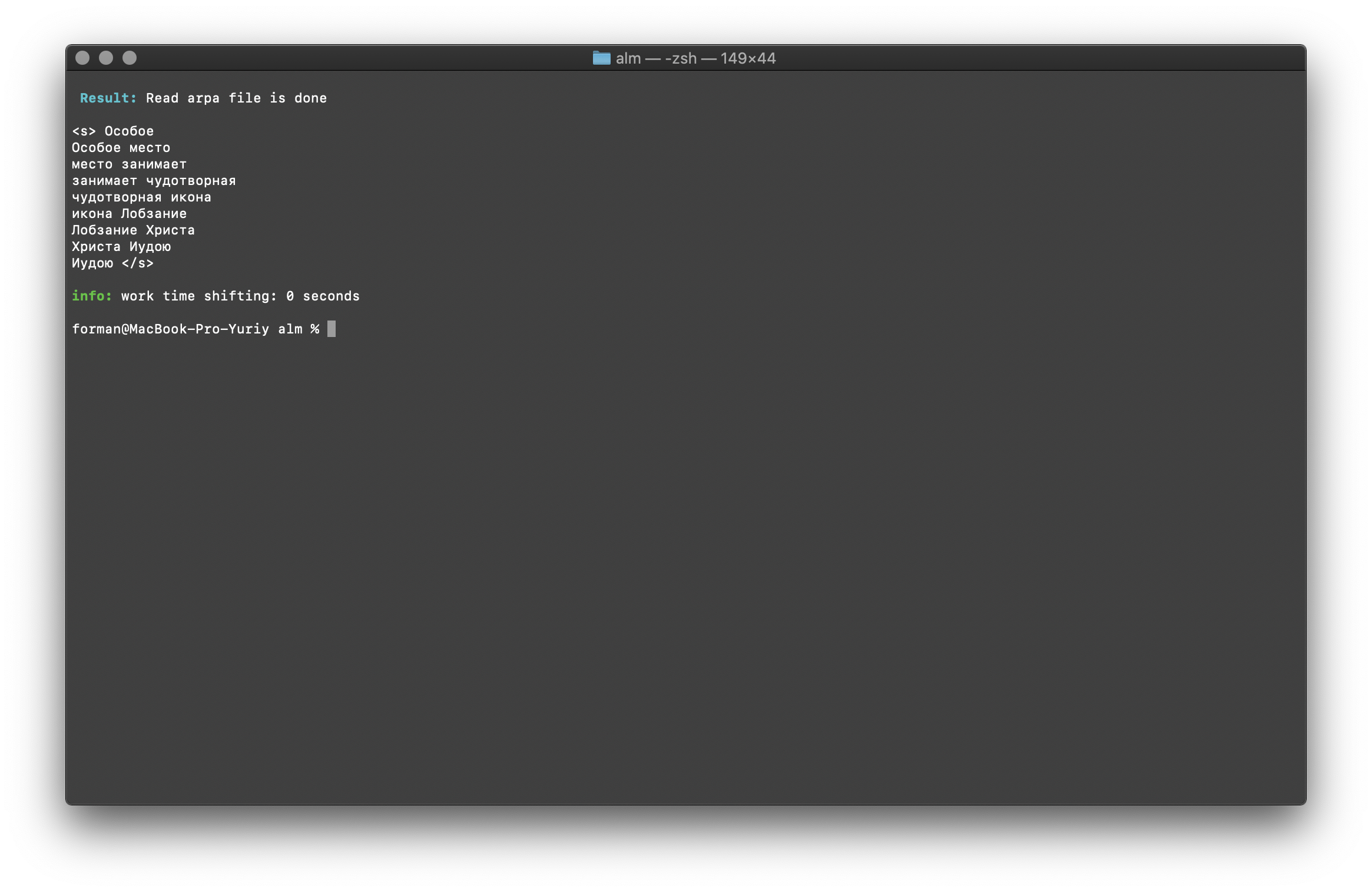 Prueba:
Prueba:
Resultado:<s>
</s>
Una lista de N-gramos que se encuentran en el texto. No hay nada especial que explicar aquí.Variables de entorno
Todos los parámetros se pueden pasar a través de variables de entorno. Las variables comienzan con el prefijo ALM_ y deben escribirse en mayúsculas. De lo contrario, los nombres de las variables corresponden a los parámetros de la aplicación.Si se especifican los parámetros de la aplicación y las variables de entorno, los parámetros de la aplicación tienen prioridad.$ export $ALM_SMOOTHING=wittenbell
$ export $ALM_W-ARPA=./lm.arpa
Por lo tanto, el proceso de ensamblaje puede ser automatizado. Por ejemplo, a través de scripts BASH.Conclusión
Entiendo que hay tecnologías más prometedoras como RnnLM o Bert . Pero estoy seguro de que los modelos estadísticos de N-gram serán relevantes durante mucho tiempo.Este trabajo tomó mucho tiempo y esfuerzo. Estaba ocupado en la biblioteca en su tiempo libre del trabajo básico, por la noche y los fines de semana. El código no cubrió las pruebas, son posibles errores y errores. Estaré agradecido por las pruebas. También estoy abierto a sugerencias de mejora y nueva funcionalidad de biblioteca. ALM se distribuye bajo la licencia MIT , que le permite usarlo casi sin restricciones.Espero recibir comentarios, críticas, sugerencias.Sitio del proyecto Depósito del proyecto