Quizás haya enfrentado la tarea de computación paralela en marcos de datos de pandas. Este problema puede resolverse tanto con Python nativo como con la ayuda de una biblioteca maravillosa: pandarallel. En este artículo, mostraré cómo esta biblioteca le permite procesar sus datos utilizando todas las capacidades disponibles.
La biblioteca le permite no pensar en la cantidad de hilos, crear procesos y proporciona una interfaz interactiva para monitorear el progreso.
Instalación
pip install pandas jupyter pandarallel requests tqdm
Como puede ver, también instalo tqdm. Con él, demostraré claramente la diferencia en la velocidad de ejecución del código en un enfoque secuencial y paralelo.
Personalización
import pandas as pd
import requests
from tqdm import tqdm
tqdm.pandas()
from pandarallel import pandarallel
pandarallel.initialize(progress_bar=True)
Puede encontrar la lista completa de configuraciones en la documentación pandarallel.
Crear un marco de datos
Para los experimentos, cree un marco de datos simple: 100 filas, 1 columna.
df = pd.DataFrame(
[i for i in range(100)],
columns=["sample_column"]
)

Ejemplo de una tarea adecuada para la paralelización.
Como sabemos, la solución de no todos los problemas puede ser paralela. Un ejemplo simple de una tarea adecuada es llamar a una fuente externa, como una API o una base de datos. En la función a continuación, llamo a una API que me devuelve una palabra al azar. Mi objetivo es agregar una columna con palabras derivadas de esta API al marco de datos.
def function_to_apply(i):
r = requests.get(f'https://random-word-api.herokuapp.com/word').json()
return r[0]
df["sample-word"] = df.sample_column.progress_apply(function_to_apply)
, tqdm, — progress_apply apply. , , progress bar.

"" 35 .
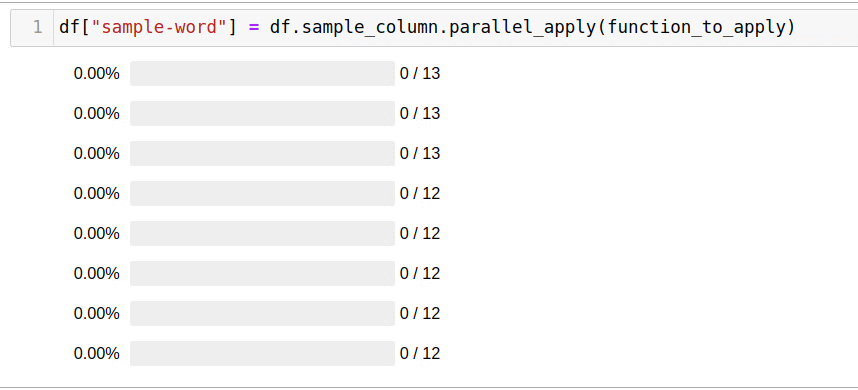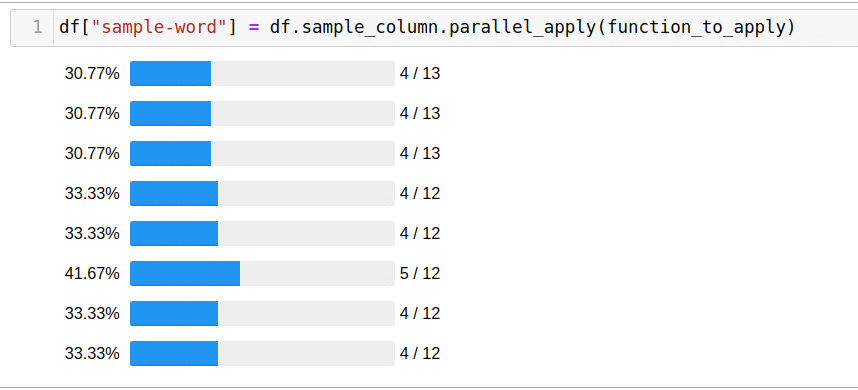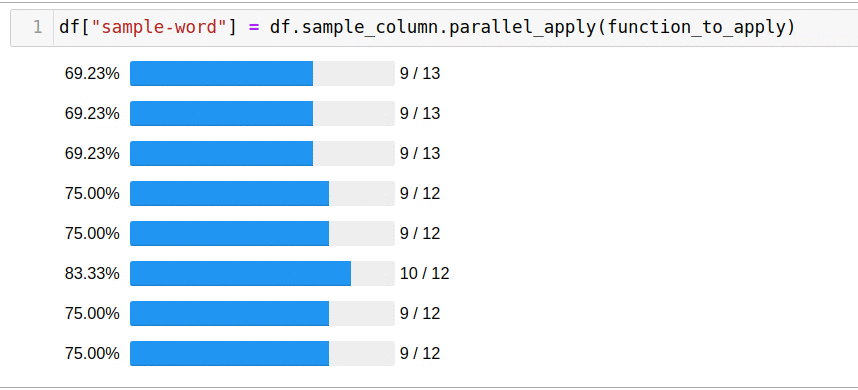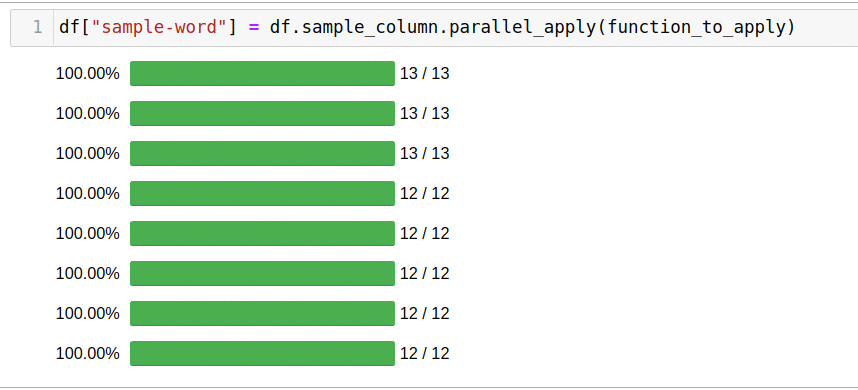
, parallel_apply:
df["sample-word"] = df.sample_column.parallel_apply(function_to_apply)
5 .
pandas , pandarallel, Github .

! — .