¿Qué debo hacer si quiero escribir muchos "hechos" en la base de datos de un volumen mucho mayor de lo que puede soportar? Primero, por supuesto, llevamos los datos a una forma normal más económica y obtenemos "diccionarios", que escribiremos una vez . Pero, ¿cómo hacerlo de manera más efectiva?Esta es exactamente la pregunta que enfrentamos al desarrollar la supervisión y el análisis de los registros del servidor PostgreSQL , cuando se agotaron otros métodos para optimizar el registro en la base de datos .Haremos una reserva de inmediato para que nuestros recolectores estén ejecutando Node.js , por lo que no interactuamos con registros de procesador y cachés de ninguna manera. Y la opción de utilizar "cientos" o servicios / bases de datos de almacenamiento en caché externo da demasiado retraso para las transmisiones entrantes de varios cientos de Mbps .Por lo tanto, tratamos de almacenar en caché todo en RAM , específicamente en la memoria del proceso de JavaScript. Sobre cómo organizar esto de manera más eficiente, e iremos más allá.Caché de disponibilidad
Nuestra tarea principal es asegurarnos de que la única instancia de cualquier objeto ingrese a la base de datos. Estos son los textos originales repetidamente repetidos de consultas SQL, plantillas de planes para su implementación , nodos de estos planes, en resumen, algunos bloques de texto .Históricamente, como identificador, utilizamos un UUIDvalor -valor, que se obtuvo como resultado del cálculo directo del hash MD5 a partir del texto del objeto. Después de eso, verificamos la disponibilidad de dicho hash en el "diccionario" local en la memoria del proceso , y si no está allí, solo entonces escribimos en la base de datos en la tabla "diccionario".Es decir, no necesitamos almacenar el valor del texto original en sí (y a veces toma decenas de kilobytes), solo el hecho de la presencia del hash correspondiente en el diccionario es suficiente .Diccionario clave
Dicho diccionario se puede guardar Arrayy usar Array.includes()para verificar la disponibilidad, pero esto es bastante redundante: la búsqueda se degrada (al menos en versiones anteriores de V8) linealmente desde el tamaño de la matriz, O (N). Y en las implementaciones modernas, a pesar de todas las optimizaciones, pierde a una velocidad del 2-3%.Por lo tanto, en la era anterior a ES6, el almacenamiento era la solución tradicional Object, con valores almacenados como claves. Pero todos asignaron los valores de las teclas a lo que él quería, por ejemplo Boolean:var dict = {};
function has(key) {
return dict[key] !== undefined;
}
function add(key) {
dict[key] = true;
}
Pero es bastante obvio que claramente estamos almacenando el exceso aquí: el valor de la clave que nadie necesita. Pero, ¿y si no se almacena en absoluto? Entonces apareció el objeto Set .Las pruebas muestran que la búsqueda con ayuda es Set.has()aproximadamente un 20-25% más rápida que la verificación clave c Object. Pero esta no es su única ventaja. Dado que almacenamos menos, deberíamos necesitar menos memoria , y esto afecta directamente el rendimiento cuando se trata de cientos de miles de tales claves.Entonces, Objecten el que hay 100 claves UUID en una representación de texto, ocupa 6.216 bytes en memoria :
Setcon el mismo contenido - 2.632 bytes :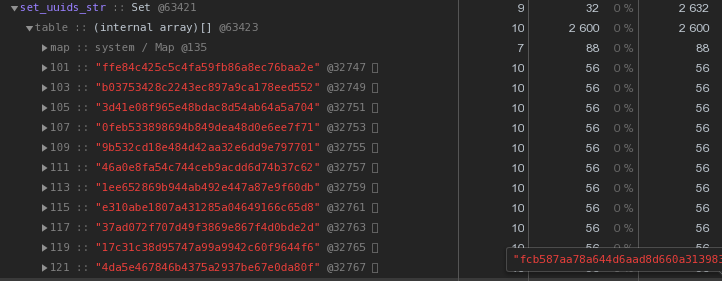 es decir,
es decir, Setfunciona más rápido y al mismo tiempo toma2.5 veces menos memoria : el ganador es obvio.Optimizamos el almacenamiento de claves UUID
En general, en la naturaleza de los sistemas distribuidos, las claves UUID son bastante comunes: en nuestro VLSI , como mínimo, se utilizan para identificar documentos y regulaciones en la gestión de documentos electrónicos , personas en mensajería , ...Ahora echemos un vistazo más de cerca a la imagen de arriba: cada UUID es la clave almacenada en la representación hexadecimal "nos cuesta" 56 bytes de memoria . Pero tenemos cientos de miles de ellos, por lo que es razonable preguntar: "¿Es posible tener menos?"Primero, recuerde que el UUID es un identificador de 16 bytes. Esencialmente una pieza de datos binarios. Y para la transmisión por correo electrónico, por ejemplo, los datos binarios están codificados en base64 ; intente aplicarlos:let str = Buffer.from(uuidstr, 'hex').toString('base64');
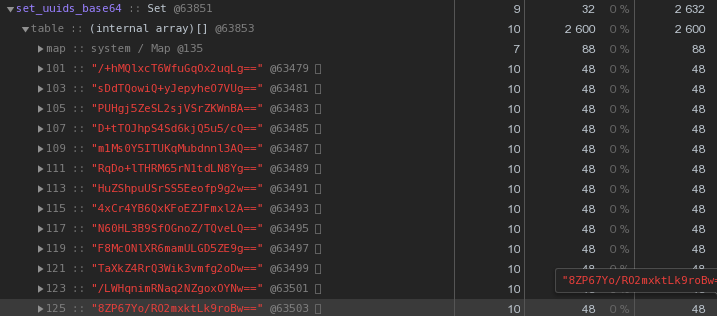 Ya 48 bytes cada uno es mejor, pero imperfecto. Intentemos traducir la representación hexadecimal directamente en una cadena:
Ya 48 bytes cada uno es mejor, pero imperfecto. Intentemos traducir la representación hexadecimal directamente en una cadena:let str = Buffer.from(uuidstr, 'hex').toString('binary');
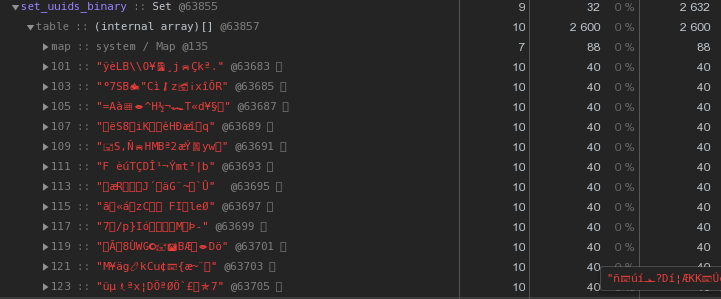 En lugar de 56 bytes por clave, ¡40 bytes, ahorrando casi un 30% !
En lugar de 56 bytes por clave, ¡40 bytes, ahorrando casi un 30% !Maestro, trabajador: ¿dónde almacenar los diccionarios?
Teniendo en cuenta que los datos de vocabulario de los trabajadores se cruzan con bastante fuerza, hicimos el almacenamiento de diccionarios y los escribimos en la base de datos en el proceso maestro, y la transmisión de datos de los trabajadores a través del mecanismo de mensajes IPC .Sin embargo, una parte importante del tiempo del maestro se gastó en channel.onread, es decir, procesar la recepción de paquetes con información de "diccionario" de procesos secundarios: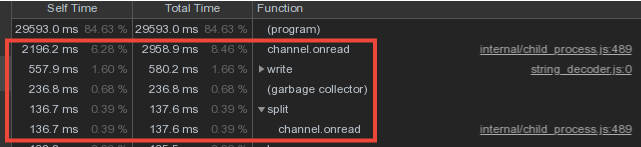
Conjunto doble barrera de escritura
Ahora pensemos por un segundo: los trabajadores envían y envían al maestro los mismos datos de vocabulario (básicamente estas son las plantillas de plan y los cuerpos de solicitud repetitivos), los analiza con sudor y ... no hace nada, porque ya se han enviado a la base de datos antes !Entonces, si Set"protegimos" la base de datos de la grabación del maestro con un diccionario, ¿por qué no usar el mismo enfoque para "proteger" al maestro de ser transferido del trabajador? ...En realidad, eso se hizo y redujo los costos directos de servicio del canal de intercambio tres veces :
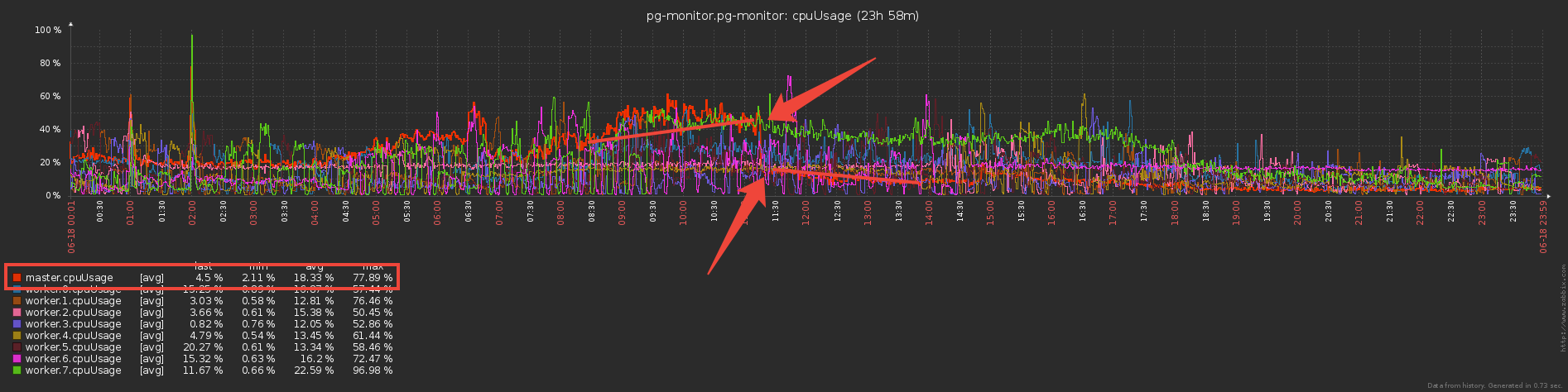 Pero ahora los trabajadores parecen hacer más trabajo: ¿almacenar diccionarios y filtrar por ellos? ¿O no? De hecho, comenzaron a funcionar significativamente menos, ya que la transferencia de grandes volúmenes (¡incluso a través de IPC!) No es barata.
Pero ahora los trabajadores parecen hacer más trabajo: ¿almacenar diccionarios y filtrar por ellos? ¿O no? De hecho, comenzaron a funcionar significativamente menos, ya que la transferencia de grandes volúmenes (¡incluso a través de IPC!) No es barata.Bonito bono
Dado que el asistente ahora comenzó a recibir una cantidad mucho menor de información, comenzó a asignar mucha menos memoria para estos contenedores, lo que significa que el tiempo dedicado al trabajo del recolector de basura disminuyó significativamente, lo que afectó positivamente la latencia del sistema en su conjunto.Tal esquema proporciona protección contra entradas repetidas a nivel de coleccionista, pero ¿qué pasa si tenemos varios coleccionistas? Solo el gatillo con ayudará aquí INSERT ... ON CONFLICT DO NOTHING.Acelerar el cálculo de hash
En nuestra arquitectura, todo el flujo de registro de un servidor PostgreSQL es procesado por un trabajador.Es decir, un servidor es una tarea para el trabajador. Al mismo tiempo, la carga de trabajadores se equilibra con el propósito de las tareas del servidor, de modo que el consumo de CPU por parte de los trabajadores de todos los recolectores es aproximadamente el mismo. Este es un despachador de servicios por separado."En promedio", cada trabajador maneja docenas de tareas que producen aproximadamente la misma carga total. Sin embargo, hay servidores que superan significativamente el resto en la cantidad de entradas de registro. E incluso si el despachador deja esta tarea como la única en el trabajador, su descarga es mucho mayor que las demás:Eliminamos el perfil de CPU de este trabajador: en las líneas superiores, el cálculo de los hash MD5. Y realmente se calculan una gran cantidad, para todo el flujo de objetos entrantes.
en las líneas superiores, el cálculo de los hash MD5. Y realmente se calculan una gran cantidad, para todo el flujo de objetos entrantes.xxHash
¿Cómo optimizar esta parte, a excepción de estos hash, no podemos?Decidimos probar otra función hash: xxHash , que implementa un algoritmo hash no criptográfico extremadamente rápido . Y el módulo para Node.js es xxhash-addon , que utiliza la última versión de la biblioteca xxHash 0.7.3 con el nuevo algoritmo XXH3.Verifique ejecutando cada opción en un conjunto de filas de diferentes longitudes:const crypto = require('crypto');
const { XXHash3, XXHash64 } = require('xxhash-addon');
const hasher3 = new XXHash3(0xDEADBEAF);
const hasher64 = new XXHash64(0xDEADBEAF);
const buf = Buffer.allocUnsafe(16);
const getBinFromHash = (hash) => buf.fill(hash, 'hex').toString('binary');
const funcs = {
xxhash64 : (str) => hasher64.hash(Buffer.from(str)).toString('binary')
, xxhash3 : (str) => hasher3.hash(Buffer.from(str)).toString('binary')
, md5 : (str) => getBinFromHash(crypto.createHash('md5').update(str).digest('hex'))
};
const check = (hash) => {
let log = [];
let cnt = 10000;
while (cnt--) log.push(crypto.randomBytes(cnt).toString('hex'));
console.time(hash);
log.forEach(funcs[hash]);
console.timeEnd(hash);
};
Object.keys(funcs).forEach(check);
Resultados:xxhash64 : 148.268ms
xxhash3 : 108.337ms
md5 : 317.584ms
Como se esperaba , ¡xxhash3 fue mucho más rápido que MD5 !Queda por comprobar la resistencia a las colisiones. Se crean secciones de tablas de diccionarios para nosotros todos los días, por lo que fuera de los límites del día podemos permitir la intersección de hashes de forma segura.Pero por si acaso, lo verificamos con un margen en el intervalo de tres días, ni un solo conflicto que nos convenga más que suficiente.Reemplazo de hash
Pero simplemente no podemos tomar y cambiar los antiguos campos de UUID en el nuevo hash en las tablas del diccionario, porque tanto la base de datos como la interfaz existente esperan que los objetos continúen siendo identificados por UUID.Por lo tanto, agregaremos una caché más al recopilador , para MD5 ya calculado. Ahora será un Mapa , en el que las claves son xxhash3, los valores son MD5. Para líneas idénticas, no volvemos a contar el MD5 "caro", sino que lo tomamos del caché:const getHashFromBin = (bin) => Buffer.from(bin, 'binary').toString('hex');
const dictmd5 = new Map();
const getmd5 = (data) => {
const hash = xxhash(data);
let md5hash = dictmd5.get(hash);
if (!md5hash) {
md5hash = md5(data);
dictmd5.set(hash, getBinFromHash(md5hash));
return md5hash;
}
return getHashFromBin(md5hash);
};
Eliminamos el perfil: la fracción del tiempo para calcular hashes ha disminuido notablemente, ¡salud! Entonces ahora contamos xxhash3, luego verificamos el caché MD5 y obtenemos el MD5 deseado, y luego verificamos el caché del diccionario; si este md5 no está allí, envíelo a la base de datos para su escritura.Algo que demasiadas comprobaciones ... ¿Por qué comprobar la memoria caché del diccionario si ya ha verificado la memoria caché MD5? Resulta que todos los cachés de diccionario ya no son necesarios y es suficiente tener solo un caché, para MD5, con el que se realizarán todas las operaciones básicas:
Entonces ahora contamos xxhash3, luego verificamos el caché MD5 y obtenemos el MD5 deseado, y luego verificamos el caché del diccionario; si este md5 no está allí, envíelo a la base de datos para su escritura.Algo que demasiadas comprobaciones ... ¿Por qué comprobar la memoria caché del diccionario si ya ha verificado la memoria caché MD5? Resulta que todos los cachés de diccionario ya no son necesarios y es suficiente tener solo un caché, para MD5, con el que se realizarán todas las operaciones básicas: Como resultado, reemplazamos la verificación en varios diccionarios de "objetos" con un caché MD5, y la operación de cálculo intensivo de recursos MD5 es intensiva El hash se realiza solo para nuevas entradas, utilizando el xxhash mucho más eficiente para la transmisión entrante.graciasKilor por ayuda en la preparación del artículo.
Como resultado, reemplazamos la verificación en varios diccionarios de "objetos" con un caché MD5, y la operación de cálculo intensivo de recursos MD5 es intensiva El hash se realiza solo para nuevas entradas, utilizando el xxhash mucho más eficiente para la transmisión entrante.graciasKilor por ayuda en la preparación del artículo.