Hola queridos suscriptores! Probablemente ya sepa que hemos lanzado un nuevo curso "Computer Vision" , clases en las que comenzará en los próximos días. En previsión del comienzo de las clases, preparamos otra traducción interesante para la inmersión en el mundo de CV.
Mi pasatiempo es jugar juegos de mesa, y como estoy un poco familiarizado con las redes neuronales convolucionales, decidí crear una aplicación que pueda vencer a una persona en un juego de cartas. Quería construir un modelo desde cero usando mi propio conjunto de datos y ver qué tan bien funciona con un pequeño conjunto de datos. Decidí comenzar con el simple juego Dobble (también conocido como Spot it!).Si no sabes qué es Dobble, recordaré brevemente las reglas del juego: Dobble es un simple juego de reconocimiento de patrones en el que los jugadores intentan encontrar una imagen representada simultáneamente en dos cartas. Cada carta en el juego Dobble original contiene ocho personajes diferentes, y en diferentes cartas son de diferentes tamaños. Dos cartas tienen solo un símbolo común. Si encuentra el símbolo primero, luego tome una tarjeta. Cuando termina la baraja de 55 cartas, gana la que tenga más cartas. Pruébelo usted mismo: ¿qué símbolo es común para estas dos cartas?
Pruébelo usted mismo: ¿qué símbolo es común para estas dos cartas?¿Dónde empezar?
El primer paso para resolver cualquier tarea de análisis de datos es recopilar datos. Tomé seis fotos de cada tarjeta en el teléfono. En total resultaron 330 fotos. Cuatro de ellos se ven a continuación. Puede preguntar, ¿es esto suficiente para crear una buena red neuronal convolucional? ¡Volveremos a esto!
Procesamiento de imágenes
OK, los datos que tenemos, ¿qué sigue? Probablemente la parte más importante en el camino hacia el éxito: el procesamiento de imágenes. Necesitamos obtener personajes de cada imagen. Algunas dificultades nos esperan aquí. En las fotos de arriba, es notable que algunos personajes son más difíciles de distinguir que otros: el muñeco de nieve y el fantasma (en la tercera foto) y la aguja (en la cuarta) de colores claros, y las manchas (en la segunda foto) y el signo de exclamación (en la cuarta foto) consisten en varias partes . Para procesar caracteres claros agregaremos contraste. Después de eso, cambiaremos el tamaño y guardaremos la imagen.Añadir contraste
Para agregar contraste, utilizamos el espacio de color Lab. L es ligereza, a es el componente cromático en el rango de verde a magenta, y b es el componente cromático en el rango de azul a amarillo. Podemos extraer fácilmente estos componentes usando OpenCV :import cv2
import imutils
imgname = 'picture1'
image = cv2.imread(f’{imgname}.jpg’)
lab = cv2.cvtColor(image, cv2.COLOR_BGR2LAB)
l, a, b = cv2.split(lab)
 De izquierda a derecha: la imagen original, el componente de claridad, el componente a y el componente bAhora agregamos contraste al componente de claridad, combinamos todos los componentes nuevamente y los convertimos en una imagen normal:
De izquierda a derecha: la imagen original, el componente de claridad, el componente a y el componente bAhora agregamos contraste al componente de claridad, combinamos todos los componentes nuevamente y los convertimos en una imagen normal:clahe = cv2.createCLAHE(clipLimit=3.0, tileGridSize=(8,8))
cl = clahe.apply(l)
limg = cv2.merge((cl,a,b))
final = cv2.cvtColor(limg, cv2.COLOR_LAB2BGR)
 De izquierda a derecha: la imagen original, el componente de claridad, la imagen con alto contraste y la imagen convertida de nuevo a RGB
De izquierda a derecha: la imagen original, el componente de claridad, la imagen con alto contraste y la imagen convertida de nuevo a RGBCambio de talla
Ahora cambie el tamaño y guarde la imagen:resized = cv2.resize(final, (800, 800))
# save the image
cv2.imwrite(f'{imgname}processed.jpg', blurred)
¡Hecho!Reconocimiento de cartas y personajes
Ahora que se procesa la imagen, podemos detectar una tarjeta en la imagen. Usando OpenCV, estamos buscando contornos externos. Luego convertimos la imagen en medios tonos, seleccionamos el valor umbral (en nuestro caso, 190) para crear una imagen en blanco y negro y buscamos una ruta. El código:image = cv2.imread(f’{imgname}processed.jpg’)
gray = cv2.cvtColor(image, cv2.COLOR_RGB2GRAY)
thresh = cv2.threshold(gray, 190, 255, cv2.THRESH_BINARY)[1]
# find contours
cnts = cv2.findContours(thresh.copy(), cv2.RETR_EXTERNAL, cv2.CHAIN_APPROX_SIMPLE)
cnts = imutils.grab_contours(cnts)
output = image.copy()
# draw contours on image
for c in cnts:
cv2.drawContours(output, [c], -1, (255, 0, 0), 3)
 Imagen procesada convertida en medios tonos usando el umbral y seleccionando contornos externosSi clasificamos los contornos externos por área, encontraremos el contorno con el área más grande: esta será nuestra carta. Para extraer los personajes podemos crear un fondo blanco.
Imagen procesada convertida en medios tonos usando el umbral y seleccionando contornos externosSi clasificamos los contornos externos por área, encontraremos el contorno con el área más grande: esta será nuestra carta. Para extraer los personajes podemos crear un fondo blanco.# sort by area, grab the biggest one
cnts = sorted(cnts, key=cv2.contourArea, reverse=True)[0]
# create mask with the biggest contour
mask = np.zeros(gray.shape,np.uint8)
mask = cv2.drawContours(mask, [cnts], -1, 255, cv2.FILLED)
# card in foreground
fg_masked = cv2.bitwise_and(image, image, mask=mask)
# white background (use inverted mask)
mask = cv2.bitwise_not(mask)
bk = np.full(image.shape, 255, dtype=np.uint8)
bk_masked = cv2.bitwise_and(bk, bk, mask=mask)
# combine back- and foreground
final = cv2.bitwise_or(fg_masked, bk_masked)
 Máscara, fondo, imagen de primer plano, imagen final ¡Ahora es el momento del reconocimiento de los personajes! Podemos usar la imagen resultante para detectar contornos externos nuevamente, estos contornos serán símbolos. Si creamos un cuadrado alrededor de cada símbolo, podemos extraer esta área. Aquí el código es un poco más largo:
Máscara, fondo, imagen de primer plano, imagen final ¡Ahora es el momento del reconocimiento de los personajes! Podemos usar la imagen resultante para detectar contornos externos nuevamente, estos contornos serán símbolos. Si creamos un cuadrado alrededor de cada símbolo, podemos extraer esta área. Aquí el código es un poco más largo:
gray = cv2.cvtColor(final, cv2.COLOR_RGB2GRAY)
thresh = cv2.threshold(gray, 195, 255, cv2.THRESH_BINARY)[1]
thresh = cv2.bitwise_not(thresh)
cnts = cv2.findContours(thresh.copy(), cv2.RETR_EXTERNAL, cv2.CHAIN_APPROX_SIMPLE)
cnts = imutils.grab_contours(cnts)
cnts = sorted(cnts, key=cv2.contourArea, reverse=True)[:10]
i = 0
for c in cnts:
if cv2.contourArea(c) > 1000:
mask = np.zeros(gray.shape, np.uint8)
mask = cv2.drawContours(mask, [c], -1, 255, cv2.FILLED)
fg_masked = cv2.bitwise_and(image, image, mask=mask)
mask = cv2.bitwise_not(mask)
bk = np.full(image.shape, 255, dtype=np.uint8)
bk_masked = cv2.bitwise_and(bk, bk, mask=mask)
finalcont = cv2.bitwise_or(fg_masked, bk_masked)
output = finalcont.copy()
x,y,w,h = cv2.boundingRect(c)
if w < h:
x += int((w-h)/2)
w = h
else:
y += int((h-w)/2)
h = w
roi = finalcont[y:y+h, x:x+w]
roi = cv2.resize(roi, (400,400))
cv2.imwrite(f"{imgname}_icon{i}.jpg", roi)
i += 1
 Imagen en blanco y negro (con umbral), contornos detectados, un símbolo de fantasma y un símbolo de corazón (caracteres extraídos con máscaras)
Imagen en blanco y negro (con umbral), contornos detectados, un símbolo de fantasma y un símbolo de corazón (caracteres extraídos con máscaras)Tipo de personaje
¡Y ahora lo más aburrido! Necesitas ordenar los personajes. Necesitará los directorios de tren, prueba y validación, 57 directorios cada uno (tenemos 57 caracteres diferentes en total). La estructura de carpetas es la siguiente:symbols
├── test
│ ├── anchor
│ ├── apple
│ │ ...
│ └── zebra
├── train
│ ├── anchor
│ ├── apple
│ │ ...
│ └── zebra
└── validation
├── anchor
├── apple
│ ...
└── zebra
¡Llevará algún tiempo colocar los caracteres extraídos (más de 2500 piezas) en los directorios necesarios! Tengo código para crear subcarpetas, un conjunto de pruebas y un kit de validación en GitHub . Tal vez la próxima vez sea mejor ordenar según el algoritmo de agrupamiento ...Entrenamiento de redes neuronales convolucionales
Después de la parte aburrida, ¡la diversión vuelve! Es hora de crear y entrenar una red neuronal convolucional. Puede encontrar información sobre redes neuronales convolucionales aquí .Arquitectura modelo
Tenemos la tarea de clasificación multi-clase con una etiqueta. Para cada personaje necesitamos una etiqueta. Es por eso que necesitaremos una función para activar la capa softmax de salida con 57 nodos y una entropía cruzada categórica como función de pérdida.La arquitectura del modelo final es la siguiente:
from keras import layers
from keras import models
from keras import optimizers
from keras.preprocessing.image import ImageDataGenerator
import matplotlib.pyplot as plt
model = models.Sequential()
model.add(layers.Conv2D(32, (3, 3), activation='relu', input_shape=(400, 400, 3)))
model.add(layers.MaxPooling2D((2, 2)))
model.add(layers.Conv2D(64, (3, 3), activation='relu'))
model.add(layers.MaxPooling2D((2, 2)))
model.add(layers.Conv2D(128, (3, 3), activation='relu'))
model.add(layers.MaxPooling2D((2, 2)))
model.add(layers.Conv2D(256, (3, 3), activation='relu'))
model.add(layers.MaxPooling2D((2, 2)))
model.add(layers.Conv2D(256, (3, 3), activation='relu'))
model.add(layers.MaxPooling2D((2, 2)))
model.add(layers.Conv2D(128, (3, 3), activation='relu'))
model.add(layers.Flatten())
model.add(layers.Dropout(0.5))
model.add(layers.Dense(512, activation='relu'))
model.add(layers.Dense(57, activation='softmax'))
model.compile(loss='categorical_crossentropy', optimizer=optimizers.RMSprop(lr=1e-4), metrics=['acc'])
Aumento de datos
Para mejorar el rendimiento, utilicé el aumento de datos. El aumento de datos es el proceso de aumentar el volumen y la variedad de datos de entrada. Esto se puede hacer girando, cambiando, escalando, recortando y volteando las imágenes existentes. Keras puede aumentar fácilmente los datos:
train_dir = 'symbols/train'
validation_dir = 'symbols/validation'
test_dir = 'symbols/test'
train_datagen = ImageDataGenerator(rescale=1./255, rotation_range=40, width_shift_range=0.1, height_shift_range=0.1, shear_range=0.1, zoom_range=0.1, horizontal_flip=True, vertical_flip=True)
test_datagen = ImageDataGenerator(rescale=1./255)
train_generator = train_datagen.flow_from_directory(train_dir, target_size=(400,400), batch_size=20, class_mode='categorical')
validation_generator = test_datagen.flow_from_directory(validation_dir, target_size=(400,400), batch_size=20, class_mode='categorical')
Si estaba interesado, el fantasma aumentado se ve así: la imagen original del fantasma a la izquierda, fantasmas aumentados en todas las otras imágenes
la imagen original del fantasma a la izquierda, fantasmas aumentados en todas las otras imágenesEntrenamiento modelo
Vamos a entrenar el modelo, guardarlo para usarlo en predicciones y verificar los resultados.history = model.fit_generator(train_generator, steps_per_epoch=100, epochs=100, validation_data=validation_generator, validation_steps=50)
model.save('models/model.h5')
 Predicciones perfectas!
Predicciones perfectas!resultados
El modelo básico que entrené sin aumento de datos, abandonos y con menos capas. Este modelo dio los siguientes resultados: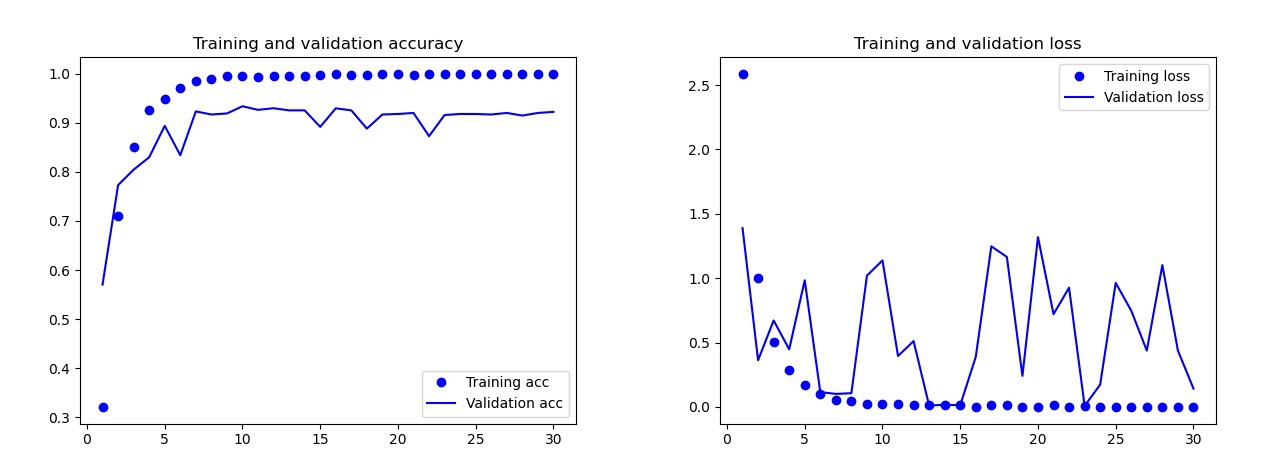 Los resultados del modelo básicoA simple vista, está claro que este modelo está reentrenado. Los resultados de la versión final del modelo (su código se presenta en las secciones anteriores) son mucho mejores. En el gráfico a continuación puede ver la precisión y las pérdidas durante el entrenamiento y en el conjunto de validación.
Los resultados del modelo básicoA simple vista, está claro que este modelo está reentrenado. Los resultados de la versión final del modelo (su código se presenta en las secciones anteriores) son mucho mejores. En el gráfico a continuación puede ver la precisión y las pérdidas durante el entrenamiento y en el conjunto de validación. Resultados del modelo final:en el conjunto de prueba, este modelo cometió un solo error: reconoció la bomba como una gota. Decidí quedarme en este modelo, la precisión en el conjunto de prueba fue de 0.995.
Resultados del modelo final:en el conjunto de prueba, este modelo cometió un solo error: reconoció la bomba como una gota. Decidí quedarme en este modelo, la precisión en el conjunto de prueba fue de 0.995.Reconocimiento de un símbolo común en dos cartas.
Ahora puede comenzar a buscar símbolos comunes en dos tarjetas. Usamos dos fotografías, haremos predicciones para cada imagen por separado y usaremos la intersección de conjuntos para descubrir qué símbolo está en ambas tarjetas. Tenemos 3 opciones de trabajo:- Algo salió mal durante la predicción: no se encontraron caracteres comunes.
- Hay un símbolo en la intersección (la predicción puede ser verdadera o falsa).
- Hay más de un personaje en la intersección. En este caso, elijo el símbolo con la mayor probabilidad (el promedio de ambas predicciones).
El código para predecir toda la combinación en las dos imágenes en el catálogo se encuentra con GitHub 's main.py.Y aquí están los resultados:
Conclusión
¿No es ese el modelo perfecto? Lamentablemente no. Cuando tomé nuevas fotos de las tarjetas y les di los modelos para la predicción, hubo algunos problemas con el muñeco de nieve. ¡A veces reconoció el ojo o la cebra como un muñeco de nieve! Como resultado, a veces los resultados eran extraños: Bueno, ¿dónde está el muñeco de nieve aquí?¿Es este modelo mejor que el hombre? Dependiendo de lo que necesitemos: la gente reconoce perfectamente, ¡pero el modelo lo hace más rápido! Noté el tiempo por el cual la computadora está lidiando: di una baraja de 55 cartas y tuve que obtener un símbolo común para cada combinación de dos cartas. En total, estas son 1485 combinaciones. La computadora lo hizo en menos de 140 segundos. Cometió algunos errores, ¡pero definitivamente derrotará a cualquier persona cuando se trata de velocidad!
Bueno, ¿dónde está el muñeco de nieve aquí?¿Es este modelo mejor que el hombre? Dependiendo de lo que necesitemos: la gente reconoce perfectamente, ¡pero el modelo lo hace más rápido! Noté el tiempo por el cual la computadora está lidiando: di una baraja de 55 cartas y tuve que obtener un símbolo común para cada combinación de dos cartas. En total, estas son 1485 combinaciones. La computadora lo hizo en menos de 140 segundos. Cometió algunos errores, ¡pero definitivamente derrotará a cualquier persona cuando se trata de velocidad! No creo que crear un modelo 100% funcional sea difícil. Esto se puede lograr a través de la capacitación de transferencia. Para comprender lo que hace el modelo, podríamos visualizar capas para la imagen de prueba. ¡Puedes hacerlo la próxima vez!
No creo que crear un modelo 100% funcional sea difícil. Esto se puede lograr a través de la capacitación de transferencia. Para comprender lo que hace el modelo, podríamos visualizar capas para la imagen de prueba. ¡Puedes hacerlo la próxima vez!
Aprende más sobre el curso y pasa el examen de ingreso