 (imagen tomada de aquí )
(imagen tomada de aquí )
Hoy nos gustaría informarle sobre la tarea de postprocesar los resultados del reconocimiento de campos de texto basados en el conocimiento a priori del campo. Anteriormente, ya escribimos sobre el método de corrección de campo basado en trigramas , que le permite corregir algunos errores de reconocimiento de palabras escritas en lenguajes naturales. Sin embargo, una parte importante de los documentos importantes, incluidos los documentos de identificación, son campos de diferente naturaleza: fechas, números, códigos VIN de automóviles, números TIN y SNILS, zonas legibles por máquinacon sus sumas de comprobación y más. Aunque no pueden atribuirse a los campos de un lenguaje natural, sin embargo, tales campos a menudo tienen algún modelo de lenguaje, a veces implícito, lo que significa que también se les pueden aplicar algunos algoritmos de corrección. En esta publicación, analizaremos dos mecanismos para los resultados del reconocimiento posterior al procesamiento que se pueden utilizar para una gran cantidad de documentos y tipos de campo.El modelo de lenguaje del campo se puede dividir condicionalmente en tres componentes:- Sintaxis : reglas que gobiernan la estructura de una representación de campo de texto. Ejemplo: el campo "fecha de vencimiento del documento" en una zona legible por máquina se representa con siete dígitos "DDDDDDD".
- : , . : “ ” - – , 3- 4- – , 5- 6- – , 7- – .
- : , . : “ ” , , “ ”.
Al tener información sobre la estructura semántica y sintáctica del documento y el campo reconocido, puede crear un algoritmo especializado para el procesamiento posterior del resultado del reconocimiento. Sin embargo, teniendo en cuenta la necesidad de soportar y desarrollar sistemas de reconocimiento y la complejidad de su desarrollo, es interesante considerar métodos y herramientas "universales" que permitan, con un mínimo esfuerzo (de los desarrolladores), construir un algoritmo de posprocesamiento bastante bueno que funcione con una clase extensa. documentos y campos. La metodología para configurar y soportar dicho algoritmo estaría unificada, y solo el modelo de lenguaje sería un componente variable de la estructura del algoritmo.Vale la pena señalar que el procesamiento posterior de los resultados del reconocimiento de campos de texto no siempre es útil, y a veces incluso perjudicial: si tiene un módulo de reconocimiento de línea bastante bueno y trabaja en sistemas críticos con documentos de identificación, entonces algún tipo de procesamiento posterior es mejor minimizar y producir resultados "tal cual", o monitorear claramente cualquier cambio e informarlo al cliente. Sin embargo, en muchos casos, cuando se sabe que el documento es válido y que el modelo de lenguaje del campo es confiable, el uso de algoritmos de procesamiento posterior puede aumentar significativamente la calidad del reconocimiento final.Entonces, el artículo discutirá dos métodos de procesamiento posterior que dicen ser universales. El primero se basa en convertidores finitos ponderados, requiere una descripción del modelo de lenguaje en forma de máquina de estados finitos, no es muy fácil de usar, pero es más universal. El segundo es más fácil de usar, más eficiente, solo requiere escribir una función para verificar la validez del valor del campo, pero también tiene una serie de desventajas.Método de transmisor de extremo ponderado
En este trabajo se describe un modelo hermoso y bastante general que le permite construir un algoritmo universal para los resultados del reconocimiento posterior al procesamiento . El modelo se basa en la estructura de datos de los Transductores de estado finito ponderados (WFST).Los WFST son una generalización de máquinas de estados finitos ponderados: si una máquina de estados finitos ponderados codifica algún idioma ponderado  (es decir, un conjunto ponderado de líneas sobre un cierto alfabeto
(es decir, un conjunto ponderado de líneas sobre un cierto alfabeto  ), entonces WFST codifica un mapa ponderado de un idioma
), entonces WFST codifica un mapa ponderado de un idioma  sobre el alfabeto
sobre el alfabeto  en un idioma
en un idioma  sobre el alfabeto
sobre el alfabeto  . Una máquina de estados finitos ponderada, que toma una cadena
. Una máquina de estados finitos ponderada, que toma una cadena  sobre el alfabeto , le asigna algo de peso
sobre el alfabeto , le asigna algo de peso  , mientras que WFST, toma una cadena
, mientras que WFST, toma una cadena sobre el alfabeto , asocia con él un conjunto de pares (posiblemente infinitos)
sobre el alfabeto , asocia con él un conjunto de pares (posiblemente infinitos)  , donde
, donde  está la línea sobre el alfabeto en la que se convierte la línea , y
está la línea sobre el alfabeto en la que se convierte la línea , y  es el peso de tal conversión. Cada transición del convertidor se caracteriza por dos estados (entre los cuales se realiza la transición), los caracteres de entrada (del alfabeto ), los caracteres de salida (del alfabeto ) y el peso de la transición. Un carácter vacío (cadena vacía) se considera un elemento de ambos alfabetos. El peso de la conversión de
es el peso de tal conversión. Cada transición del convertidor se caracteriza por dos estados (entre los cuales se realiza la transición), los caracteres de entrada (del alfabeto ), los caracteres de salida (del alfabeto ) y el peso de la transición. Un carácter vacío (cadena vacía) se considera un elemento de ambos alfabetos. El peso de la conversión de  cadena a cadena
cadena a cadena  es la suma de los productos de los pesos de transición a lo largo de todas las rutas en las que la concatenación de los caracteres de entrada forma la cadena , y la concatenación de los caracteres de salida forma la cadena, y que transfieren el convertidor del estado inicial a uno de los terminales.La operación de composición se determina a través de WFST, en la que se basa el método de procesamiento posterior. Dése dos transformadores
es la suma de los productos de los pesos de transición a lo largo de todas las rutas en las que la concatenación de los caracteres de entrada forma la cadena , y la concatenación de los caracteres de salida forma la cadena, y que transfieren el convertidor del estado inicial a uno de los terminales.La operación de composición se determina a través de WFST, en la que se basa el método de procesamiento posterior. Dése dos transformadores  y
y  , y convertir la línea por encima
, y convertir la línea por encima  de la línea anterior
de la línea anterior  con el peso
con el peso  , y se convierten más a la línea
, y se convierten más a la línea  anterior
anterior  con el peso
con el peso  . Luego, el convertidor
. Luego, el convertidor  , llamado la composición de los convertidores, convierte la cadena en una cadena con un peso
, llamado la composición de los convertidores, convierte la cadena en una cadena con un peso . La composición de los transductores es una operación computacionalmente costosa, pero se puede calcular perezosamente: los estados y las transiciones del transductor resultante se pueden construir en el momento en que se necesita acceder.El algoritmo para el procesamiento posterior del resultado del reconocimiento basado en WFST se basa en tres fuentes principales de información: el
. La composición de los transductores es una operación computacionalmente costosa, pero se puede calcular perezosamente: los estados y las transiciones del transductor resultante se pueden construir en el momento en que se necesita acceder.El algoritmo para el procesamiento posterior del resultado del reconocimiento basado en WFST se basa en tres fuentes principales de información: el  modelo de hipótesis , el modelo de error
modelo de hipótesis , el modelo de error  y el modelo de lenguaje
y el modelo de lenguaje  . Los tres modelos se presentan en forma de transductores finales ponderados:
. Los tres modelos se presentan en forma de transductores finales ponderados:- ( WFST – , ), , . ,
 , ():
, ():  ,
,  –
–  - ,
- ,  – () .
– () .  - , :
- , :  - ,
- ,  - – ,
- – ,  -
-  -
-  . - , . , .
. - , . , .
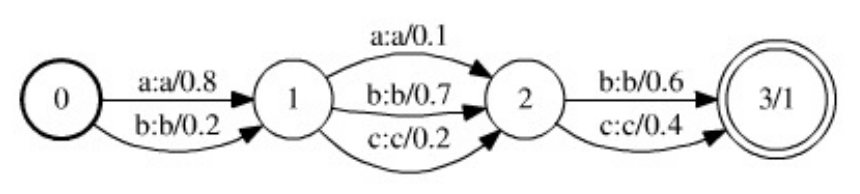
. 1. , WFST ( ). .
- , , . WFST ( ). . , .
- . .. , ( ).
Después de definir un modelo de hipótesis, errores y un modelo de lenguaje, la tarea de los resultados del reconocimiento posterior al procesamiento ahora se puede plantear de la siguiente manera: considere la composición de los tres modelos  (en términos de composición WFST). El convertidor
(en términos de composición WFST). El convertidor  codifica todas las conversiones posibles de cadenas del modelo de hipótesis en cadenas del modelo de lenguaje , aplicando transformaciones codificadas en el modelo de error a cadenas . Además, el peso de tal transformación incluye el peso de la hipótesis original, el peso de la transformación y el peso de la cadena resultante (en el caso de un modelo de lenguaje ponderado). En consecuencia, en dicho modelo, el posprocesamiento óptimo del resultado del reconocimiento corresponderá a la ruta óptima (en términos de peso) en el convertidortraduciéndolo de la inicial a uno de los estados terminales. La línea de entrada a lo largo de esta ruta corresponderá a la hipótesis inicial seleccionada, y la línea de salida al resultado de reconocimiento corregido. Se puede buscar la ruta óptima utilizando algoritmos para encontrar las rutas más cortas en gráficos dirigidos.Las ventajas de este enfoque son su generalidad y flexibilidad. El modelo de error, por ejemplo, puede expandirse fácilmente de tal manera que tenga en cuenta la eliminación y la adición de caracteres (para esto, solo vale la pena agregar transiciones con un símbolo de salida o entrada vacío, respectivamente, al modelo de error). Sin embargo, este modelo tiene desventajas significativas. Primero, el modelo de lenguaje aquí debe presentarse como un transformador finito ponderado finito. Para lenguajes complejos, dicho autómata puede resultar bastante engorroso, y en caso de un cambio o refinamiento del modelo de lenguaje, será necesario reconstruirlo. También se debe tener en cuenta que la composición de los tres transductores como resultado tiene, por regla general, un transductor aún más voluminoso,y esta composición se calcula cada vez que inicia el procesamiento posterior de un resultado de reconocimiento. Debido al volumen de la composición, la búsqueda del camino óptimo en la práctica debe realizarse con métodos heurísticos, como la búsqueda A *.Utilizando el modelo de verificación de gramáticas, es posible construir un modelo más simple de la tarea de los resultados del reconocimiento posterior al procesamiento, que no será tan general como el modelo basado en WFST, pero será fácilmente extensible y fácil de implementar.Una gramática de verificación es un par
codifica todas las conversiones posibles de cadenas del modelo de hipótesis en cadenas del modelo de lenguaje , aplicando transformaciones codificadas en el modelo de error a cadenas . Además, el peso de tal transformación incluye el peso de la hipótesis original, el peso de la transformación y el peso de la cadena resultante (en el caso de un modelo de lenguaje ponderado). En consecuencia, en dicho modelo, el posprocesamiento óptimo del resultado del reconocimiento corresponderá a la ruta óptima (en términos de peso) en el convertidortraduciéndolo de la inicial a uno de los estados terminales. La línea de entrada a lo largo de esta ruta corresponderá a la hipótesis inicial seleccionada, y la línea de salida al resultado de reconocimiento corregido. Se puede buscar la ruta óptima utilizando algoritmos para encontrar las rutas más cortas en gráficos dirigidos.Las ventajas de este enfoque son su generalidad y flexibilidad. El modelo de error, por ejemplo, puede expandirse fácilmente de tal manera que tenga en cuenta la eliminación y la adición de caracteres (para esto, solo vale la pena agregar transiciones con un símbolo de salida o entrada vacío, respectivamente, al modelo de error). Sin embargo, este modelo tiene desventajas significativas. Primero, el modelo de lenguaje aquí debe presentarse como un transformador finito ponderado finito. Para lenguajes complejos, dicho autómata puede resultar bastante engorroso, y en caso de un cambio o refinamiento del modelo de lenguaje, será necesario reconstruirlo. También se debe tener en cuenta que la composición de los tres transductores como resultado tiene, por regla general, un transductor aún más voluminoso,y esta composición se calcula cada vez que inicia el procesamiento posterior de un resultado de reconocimiento. Debido al volumen de la composición, la búsqueda del camino óptimo en la práctica debe realizarse con métodos heurísticos, como la búsqueda A *.Utilizando el modelo de verificación de gramáticas, es posible construir un modelo más simple de la tarea de los resultados del reconocimiento posterior al procesamiento, que no será tan general como el modelo basado en WFST, pero será fácilmente extensible y fácil de implementar.Una gramática de verificación es un par  , donde está el alfabeto, y
, donde está el alfabeto, y  es el predicado de la admisibilidad de una cadena sobre el alfabeto , es decir.
es el predicado de la admisibilidad de una cadena sobre el alfabeto , es decir.  . Una gramática de verificación codifica un determinado idioma sobre el alfabeto de la siguiente manera: una línea
. Una gramática de verificación codifica un determinado idioma sobre el alfabeto de la siguiente manera: una línea  pertenece al idioma si el predicado toma un valor verdadero en esta línea. Vale la pena señalar que verificar la gramática es una forma más general de representar un modelo de lenguaje que una máquina de estados. De hecho, cualquier lenguaje representado como una máquina de estados finitos, puede representarse en forma de una gramática de verificación (con un predicado
pertenece al idioma si el predicado toma un valor verdadero en esta línea. Vale la pena señalar que verificar la gramática es una forma más general de representar un modelo de lenguaje que una máquina de estados. De hecho, cualquier lenguaje representado como una máquina de estados finitos, puede representarse en forma de una gramática de verificación (con un predicado  , donde
, donde  es el conjunto de líneas aceptadas por el autómata . Sin embargo, no todos los idiomas que pueden representarse como una gramática de verificación son representables como un autómata finito en el caso general (por ejemplo, un lenguaje de palabras de longitud ilimitada sobre alfabeto
es el conjunto de líneas aceptadas por el autómata . Sin embargo, no todos los idiomas que pueden representarse como una gramática de verificación son representables como un autómata finito en el caso general (por ejemplo, un lenguaje de palabras de longitud ilimitada sobre alfabeto  , en el que el número de caracteres es
, en el que el número de caracteres es  mayor que el número de caracteres
mayor que el número de caracteres  .)Deje que el resultado del reconocimiento (modelo de hipótesis) se dé como una secuencia de celdas(igual que en la sección anterior). Por conveniencia, suponemos que cada celda contiene K alternativas y todas las estimaciones alternativas toman un valor positivo. La evaluación (peso) de la cadena se considerará el producto de las calificaciones de cada uno de los caracteres de esta cadena. Si el modelo de lenguaje se da en forma de una gramática de verificación , entonces el problema de posprocesamiento se puede formular como un problema de optimización discreta (maximización) en el conjunto de controles
.)Deje que el resultado del reconocimiento (modelo de hipótesis) se dé como una secuencia de celdas(igual que en la sección anterior). Por conveniencia, suponemos que cada celda contiene K alternativas y todas las estimaciones alternativas toman un valor positivo. La evaluación (peso) de la cadena se considerará el producto de las calificaciones de cada uno de los caracteres de esta cadena. Si el modelo de lenguaje se da en forma de una gramática de verificación , entonces el problema de posprocesamiento se puede formular como un problema de optimización discreta (maximización) en el conjunto de controles  (el conjunto de todas las líneas de longitud sobre el alfabeto ) con el predicado de admisibilidad y funcional
(el conjunto de todas las líneas de longitud sobre el alfabeto ) con el predicado de admisibilidad y funcional  , donde
, donde  es la estimación del símbolo
es la estimación del símbolo  en la celda i-ésima .Cualquier problema de optimización discreta (es decir, con un conjunto finito de controles) se puede resolver utilizando una enumeración completa de controles. El algoritmo descrito itera eficientemente sobre los controles (filas) en orden decreciente del valor funcional hasta que el predicado de validez acepte el valor verdadero. Establecemos como el
en la celda i-ésima .Cualquier problema de optimización discreta (es decir, con un conjunto finito de controles) se puede resolver utilizando una enumeración completa de controles. El algoritmo descrito itera eficientemente sobre los controles (filas) en orden decreciente del valor funcional hasta que el predicado de validez acepte el valor verdadero. Establecemos como el  número máximo de iteraciones del algoritmo, es decir El número máximo de filas con la estimación máxima sobre la cual se calculará el predicado.En primer lugar, ordenar las alternativas en orden descendente de las estimaciones, y suponemos además que para cualquier celda de la desigualdad
número máximo de iteraciones del algoritmo, es decir El número máximo de filas con la estimación máxima sobre la cual se calculará el predicado.En primer lugar, ordenar las alternativas en orden descendente de las estimaciones, y suponemos además que para cualquier celda de la desigualdad  de que es cierto
de que es cierto  . La posición será la secuencia de índices
. La posición será la secuencia de índices  correspondientes a la fila.
correspondientes a la fila. . Evaluación de posición, es decir valor funcional en esa posición, tenga en cuenta las evaluaciones de alternativas de productos que corresponden a los índices incluidos en la posición:
. Evaluación de posición, es decir valor funcional en esa posición, tenga en cuenta las evaluaciones de alternativas de productos que corresponden a los índices incluidos en la posición:  . Para almacenar posiciones, necesita la estructura de datos de PositionBase , que le permite agregar nuevas posiciones (obteniendo sus direcciones), obtener la posición en la dirección y verificar si la posición especificada se agrega a la base de datos.En el proceso de enumerar posiciones, seleccionaremos una posición no vista con una calificación máxima, y luego agregaremos a la cola para consideración PositionQueue todas las posiciones que se pueden obtener de la actual agregando uno a uno de los índices incluidos en la posición. La cola para consideración PositionQueue contendrá triples
. Para almacenar posiciones, necesita la estructura de datos de PositionBase , que le permite agregar nuevas posiciones (obteniendo sus direcciones), obtener la posición en la dirección y verificar si la posición especificada se agrega a la base de datos.En el proceso de enumerar posiciones, seleccionaremos una posición no vista con una calificación máxima, y luego agregaremos a la cola para consideración PositionQueue todas las posiciones que se pueden obtener de la actual agregando uno a uno de los índices incluidos en la posición. La cola para consideración PositionQueue contendrá triples  , donde
, donde - evaluación de la posición no
- evaluación de la posición no  revisada , - dirección de la posición vista en PositionBase desde la cual se obtuvo esta posición,
revisada , - dirección de la posición vista en PositionBase desde la cual se obtuvo esta posición,  - índice del elemento de posición con la dirección que se incrementó en uno para obtener esta posición. Posicionar una cola PositionQueue requerirá una estructura de datos que le permita agregar otro triple , así como recuperar un triple con la calificación máxima .En la primera iteración del algoritmo, es necesario considerar la posición
- índice del elemento de posición con la dirección que se incrementó en uno para obtener esta posición. Posicionar una cola PositionQueue requerirá una estructura de datos que le permita agregar otro triple , así como recuperar un triple con la calificación máxima .En la primera iteración del algoritmo, es necesario considerar la posición  con la estimación máxima. Si el predicado toma el valor verdadero en la línea correspondiente a esta posición, entonces el algoritmo termina. De lo contrario, la posición se agrega a PositionBase y enPositionQueue agrega todos los triples de la vista
con la estimación máxima. Si el predicado toma el valor verdadero en la línea correspondiente a esta posición, entonces el algoritmo termina. De lo contrario, la posición se agrega a PositionBase y enPositionQueue agrega todos los triples de la vista  , para todos
, para todos  , dónde
, dónde  está la dirección de la posición inicial en PositionBase . En cada iteración posterior del algoritmo, el triple con el valor máximo de la estimación se extrae de PositionQueue , la posición en cuestión se restaura a la dirección de la posición inicial y el índice . Si la posición ya se ha agregado a la base de datos de las posiciones consideradas de PositionBase , se omite y las tres siguientes con el valor máximo de la estimación se extraen de PositionQueue . De lo contrario, el valor del predicado se verifica en la línea correspondiente a la posición . Si el predicadotoma el valor verdadero en esta línea, luego termina el algoritmo. Si el predicado no acepta el valor verdadero en esta línea, entonces la línea se agrega a PositionBase (con la dirección asignada
está la dirección de la posición inicial en PositionBase . En cada iteración posterior del algoritmo, el triple con el valor máximo de la estimación se extrae de PositionQueue , la posición en cuestión se restaura a la dirección de la posición inicial y el índice . Si la posición ya se ha agregado a la base de datos de las posiciones consideradas de PositionBase , se omite y las tres siguientes con el valor máximo de la estimación se extraen de PositionQueue . De lo contrario, el valor del predicado se verifica en la línea correspondiente a la posición . Si el predicadotoma el valor verdadero en esta línea, luego termina el algoritmo. Si el predicado no acepta el valor verdadero en esta línea, entonces la línea se agrega a PositionBase (con la dirección asignada  ), todas las posiciones derivadas se agregan a la cola PositionQueue y continúa la siguiente iteración.
), todas las posiciones derivadas se agregan a la cola PositionQueue y continúa la siguiente iteración.FindSuitableString(M, N, K, P, C[1], ..., C[N]):
i : 1 ... N:
C[i]
( )
PositionBase PositionQueue
S_1 = {1, 1, 1, ..., 1}
P(S_1):
: S_1,
( )
S_1 PositionBase R(S_1)
i : 1 ... N:
K > 1, :
<Q * q[i][2] / q[i][1], R(S_1), i> PositionQueue
( )
( )
PositionBase M:
PositionQueue:
PositionQueue <Q, R, I> Q
S_from = PositionBase R
S_curr = {S_from[1], S_from[2], ..., S_from[I] + 1, ..., S_from[N]}
S_curr PositionBase:
:
S_curr PositionBase R(S_curr)
( )
P(S_curr):
: S_curr,
( )
i : 1 ... N:
K > S_curr[i]:
<Q * q[i][S_curr[i] + 1] / q[i][S_curr[i]],
R(S_curr),
i> PositionQueue
( )
( )
( )
( )
M
Tenga en cuenta que durante las iteraciones, el predicado se verificará no más de una vez, no habrá más adiciones a PositionBase , y además de PositionQueue , la extracción de PositionQueue , así como una búsqueda en PositionBase , no ocurrirá más de  una vez. Si la implementación PositionQueue usó "grupo" de estructura de datos, y para la organización PositionBase que usó la estructura de datos "Bor", la complejidad del algoritmo es
una vez. Si la implementación PositionQueue usó "grupo" de estructura de datos, y para la organización PositionBase que usó la estructura de datos "Bor", la complejidad del algoritmo es  , donde
, donde  - el predicado de prueba más extremo en la longitud de la línea .Quizás el inconveniente más importante del algoritmo basado en el control de las gramáticas es que no puede procesar hipótesis de diferentes longitudes (que pueden surgir debido a errores de segmentación : pérdida u ocurrencia de caracteres adicionales, pegado y corte de caracteres, etc.), mientras que Los cambios en hipótesis tales como “eliminar un carácter”, “agregar un carácter” o incluso “reemplazar un carácter con un par” pueden codificarse en el modelo de error del algoritmo basado en WFST.Sin embargo, la velocidad y la facilidad de uso (cuando se trabaja con un nuevo tipo de campo, solo necesita dar acceso al algoritmo a la función de validación de valor) hacen que el método basado en las gramáticas de verificación sea una herramienta muy poderosa en el arsenal del desarrollador de sistemas de reconocimiento de documentos. Utilizamos este enfoque para una gran cantidad de diversos campos, como varias fechas, número de tarjeta bancaria (predicado: verificar el código lunar ), campos de áreas de documentos legibles por máquina con sumas de verificación y muchos otros.
- el predicado de prueba más extremo en la longitud de la línea .Quizás el inconveniente más importante del algoritmo basado en el control de las gramáticas es que no puede procesar hipótesis de diferentes longitudes (que pueden surgir debido a errores de segmentación : pérdida u ocurrencia de caracteres adicionales, pegado y corte de caracteres, etc.), mientras que Los cambios en hipótesis tales como “eliminar un carácter”, “agregar un carácter” o incluso “reemplazar un carácter con un par” pueden codificarse en el modelo de error del algoritmo basado en WFST.Sin embargo, la velocidad y la facilidad de uso (cuando se trabaja con un nuevo tipo de campo, solo necesita dar acceso al algoritmo a la función de validación de valor) hacen que el método basado en las gramáticas de verificación sea una herramienta muy poderosa en el arsenal del desarrollador de sistemas de reconocimiento de documentos. Utilizamos este enfoque para una gran cantidad de diversos campos, como varias fechas, número de tarjeta bancaria (predicado: verificar el código lunar ), campos de áreas de documentos legibles por máquina con sumas de verificación y muchos otros.
La publicación se preparó sobre la base del artículo : Un algoritmo universal para los resultados del reconocimiento posterior al procesamiento basado en la validación de gramáticas. K.B. Bulatov, D.P. Nikolaev, V.V. Postnikov. Actas de ISA RAS, Vol. 65, No. 4, 2015, pp. 68-73.