Antecedentes
Recientemente, en el marco de las actividades educativas, necesitaba usar el viejo algoritmo genético para encontrar las funciones mínimas y máximas de dos variables. Sin embargo, para mi sorpresa, no hubo una implementación similar en Python en Internet, y esta sección no fue cubierta en el artículo sobre el algoritmo genético en Wikipedia. Entonces decidí escribir mi pequeño paquete en Python con una visualización del algoritmo, según el cual sería conveniente configurar este algoritmo y buscar las sutilezas del modelo seleccionado.En este breve artículo, me gustaría compartir el proceso, las observaciones y los resultados.
Entonces decidí escribir mi pequeño paquete en Python con una visualización del algoritmo, según el cual sería conveniente configurar este algoritmo y buscar las sutilezas del modelo seleccionado.En este breve artículo, me gustaría compartir el proceso, las observaciones y los resultados.El principio del algoritmo.
No hablaré sobre el principio global del trabajo de los algoritmos genéticos, pero si no ha escuchado sobre esto, entonces puede familiarizarse con él en Wikipedia .Por el momento, el paquete implementa solo un GA, que se parametriza por los datos de entrada a través de un simple guiche. Te contaré brevemente sobre las funciones genéticas seleccionadas y las soluciones algorítmicas básicas.El individuo monocromosómico lleva en cada uno de sus genes información sobre la coordenada x o y correspondiente. Una población está determinada por muchos individuos, pero la población está segmentada en 4 individuos. Esta solución, por supuesto, se debe a un intento de evitar la convergencia a un óptimo local, ya que la tarea es encontrar un extremo global. Tal partición, como la práctica ha demostrado, en muchos casos no permite que un genotipo domine en toda la población, sino que, por el contrario, le da a la "evolución" una mayor dinámica. Para cada parte de la población, se aplica el siguiente algoritmo:- La selección se lleva a cabo de manera similar al método de clasificación. Se seleccionan 3 individuos con los mejores indicadores de función de condición física (es decir, los individuos se ordenan en orden ascendente / descendente de la función establecida por el usuario, que actúa como la función de adaptación).
- Luego, la función de cruce se aplica de tal manera que la nueva generación (o más bien un nuevo segmento de la población de 4 individuos) recibe 2 pares de genes no silenciados del individuo con la mejor indicación de la función de aptitud y un par de genes mutados de otros dos individuos. En la siguiente sección se escribirá más sobre la compilación de la función de mutación.
El principio de operación de selección, cruzamiento y mutación claramente se ve así (en la generación N, los cromosomas de los individuos ya están ordenados en el orden correcto, y un pequeño cuadrado negro significa mutación):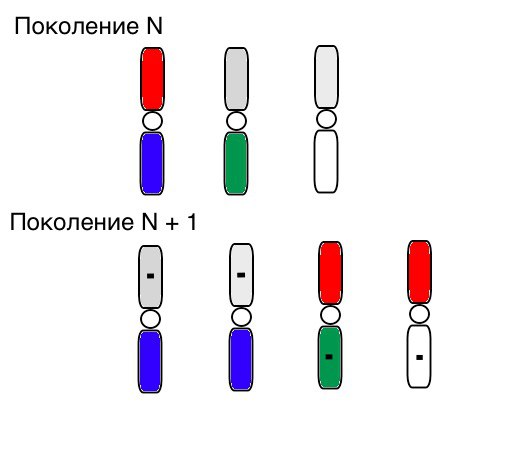
Pruebas primarias y observaciones
Entonces, probamos este algoritmo en dos ejemplos simples:Prueba 1
 Prueba 2
Prueba 2

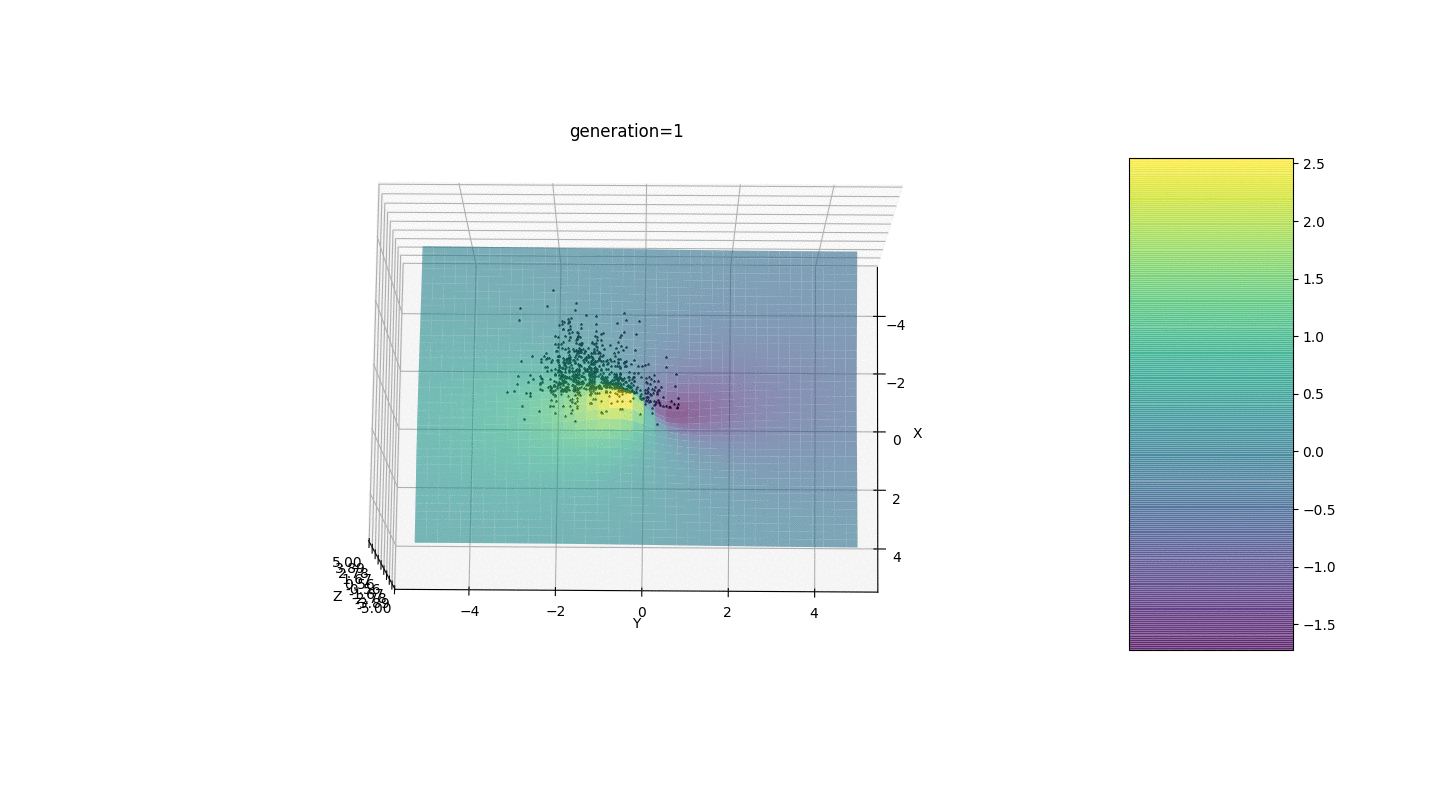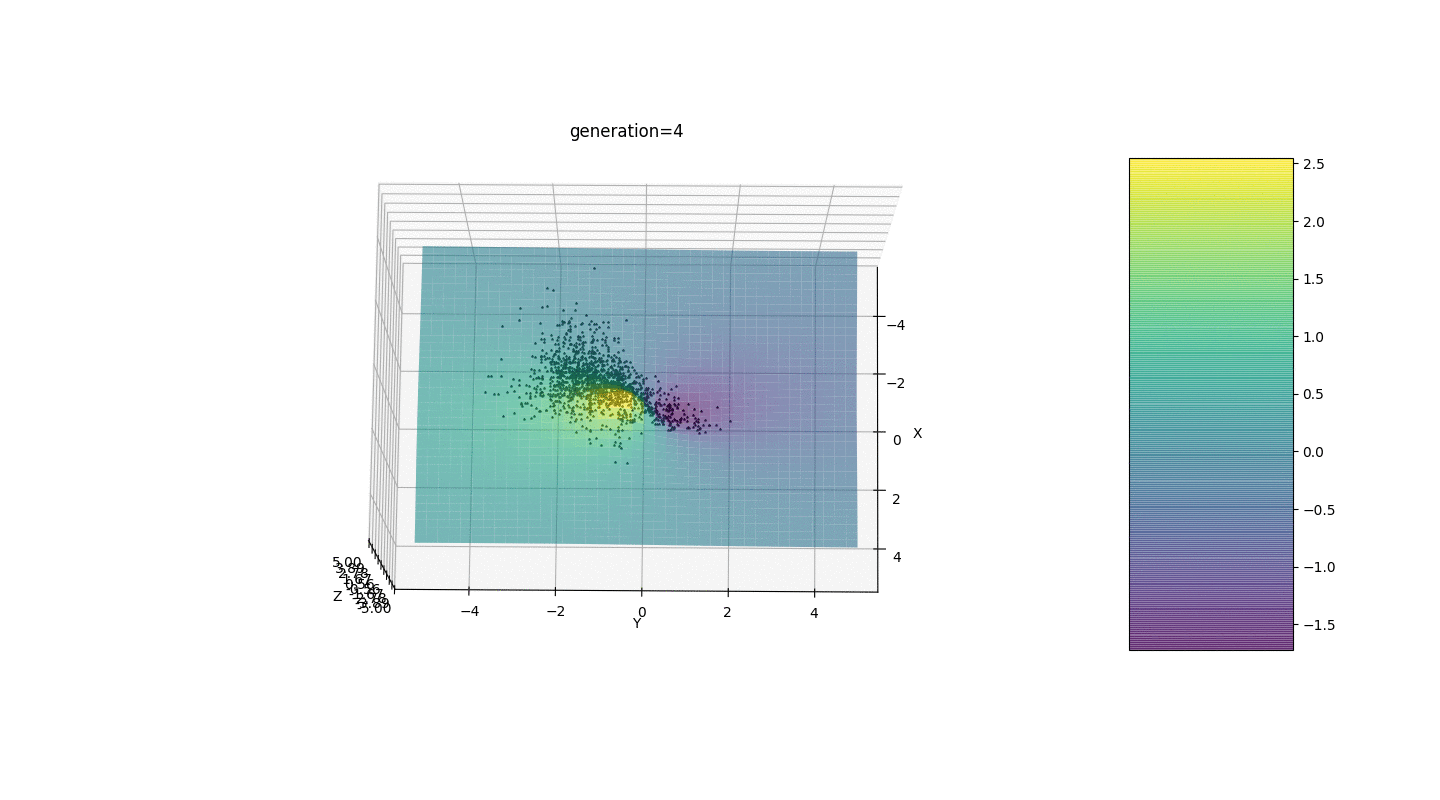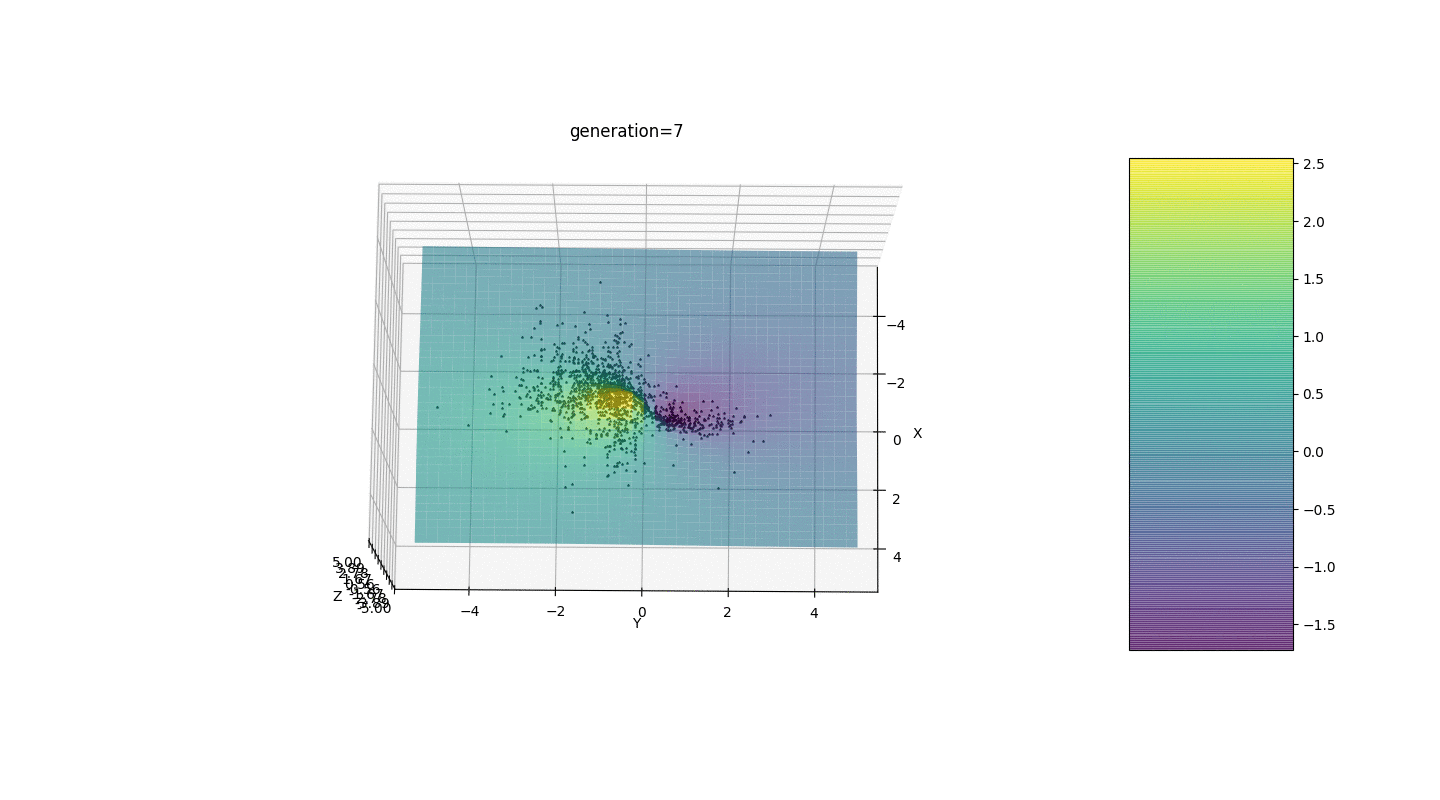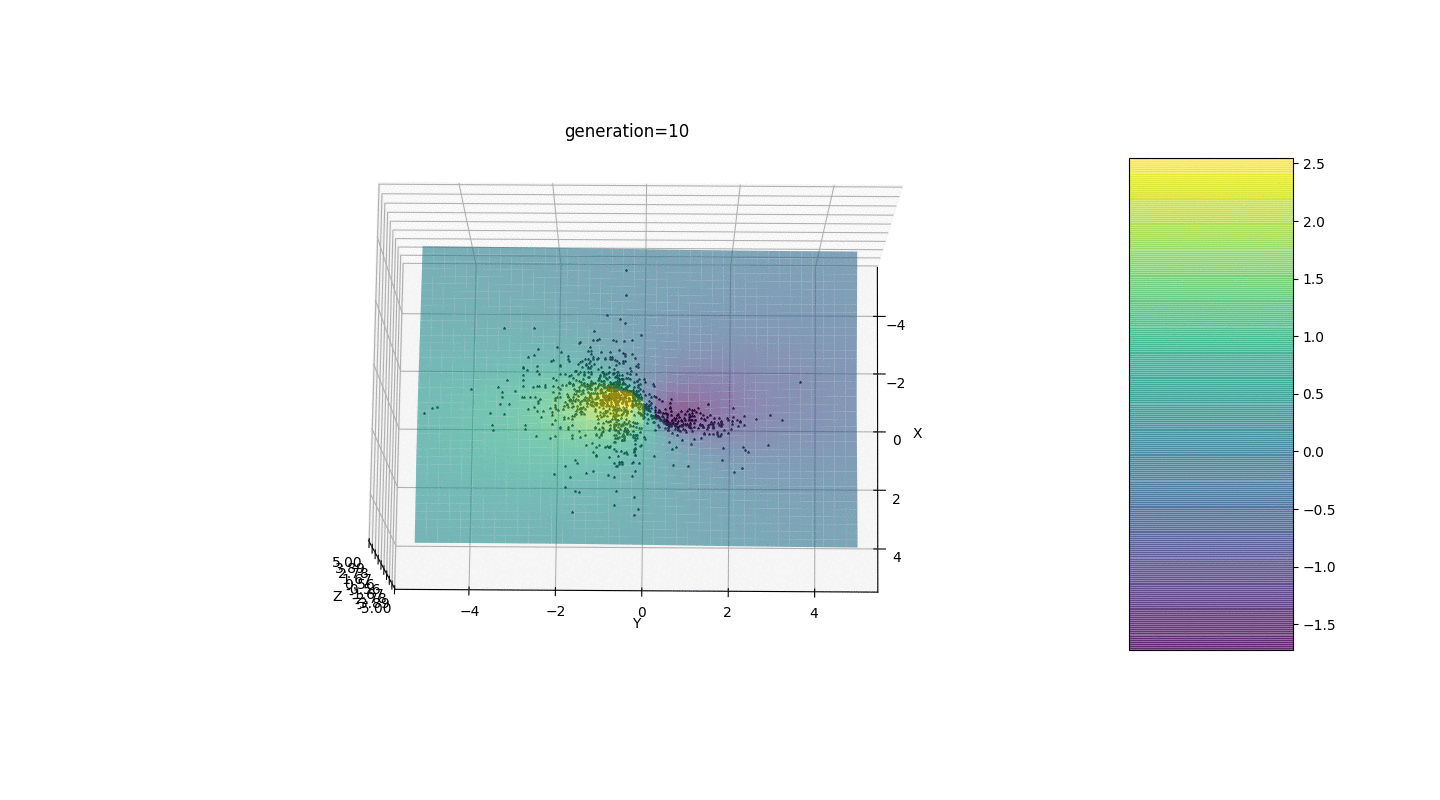
 Después de probar y estudiar el funcionamiento del algoritmo mediante el método de la mirada y la búsqueda aleatoria, se revelaron varios patrones de hipótesis:
Después de probar y estudiar el funcionamiento del algoritmo mediante el método de la mirada y la búsqueda aleatoria, se revelaron varios patrones de hipótesis:- El error del algoritmo es directamente proporcional al número de individuos, pero en promedio el error se calcula en centésimas, aunque con parámetros fallidos el error puede llegar a décimas.
- En este momento, una mutación ocurre al agregar un número aleatorio del medio intervalo al gendebido a que los individuos no pueden permanecer en la vecindad del extremo y se produce una fluctuación relativamente fuerte en la distancia entre individuos de diferentes generaciones. En algunos casos, tales oscilaciones pueden ser útiles para salir de un extremo local, por ejemplo, una función periódica, pero los extremos pueden estar a una gran distancia entre sí (distancia en el sentido euclidiano)
- En muchos casos, los individuos alcanzan el punto extremo en 5 a 15 generaciones, y las generaciones restantes "saltan" inútilmente en las proximidades de este extremo.
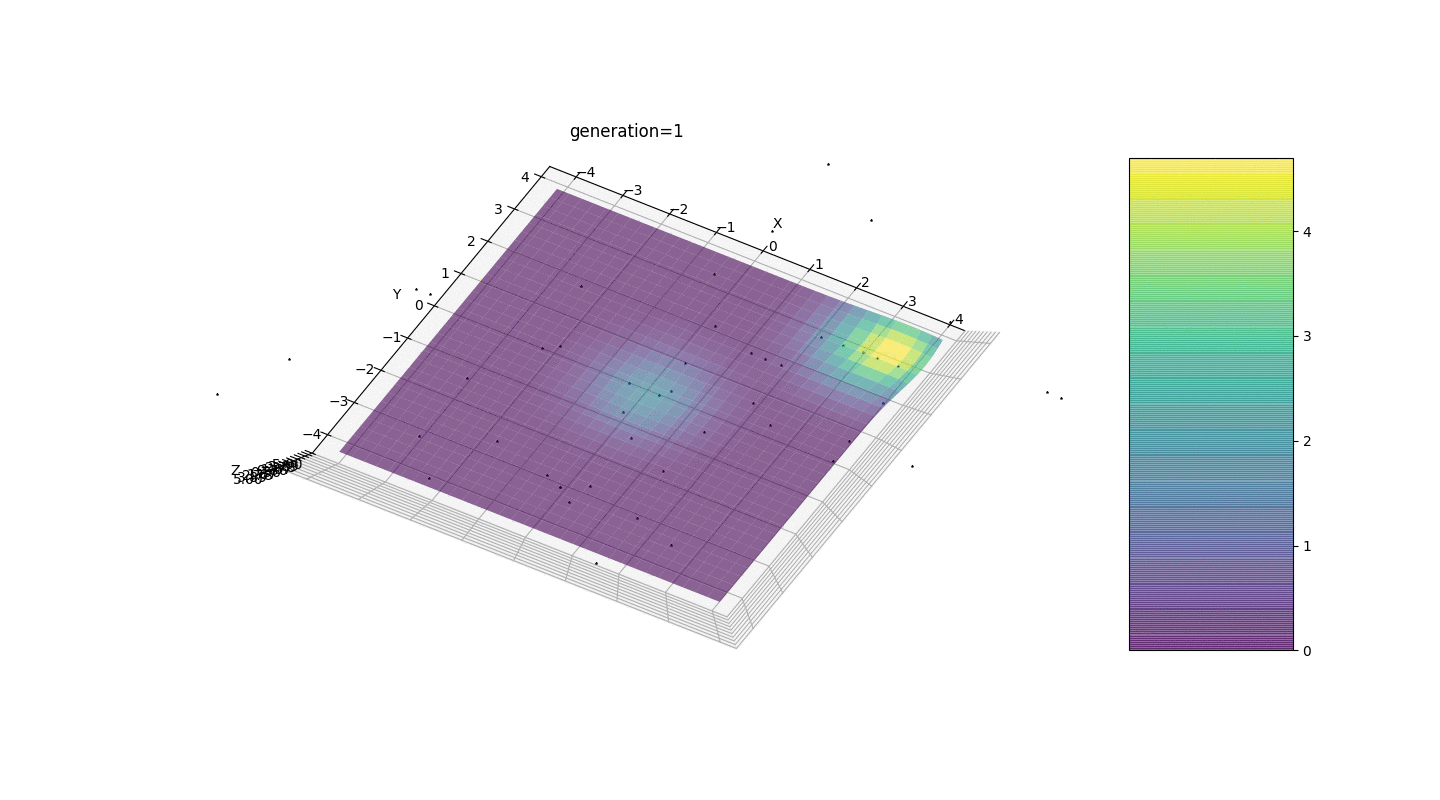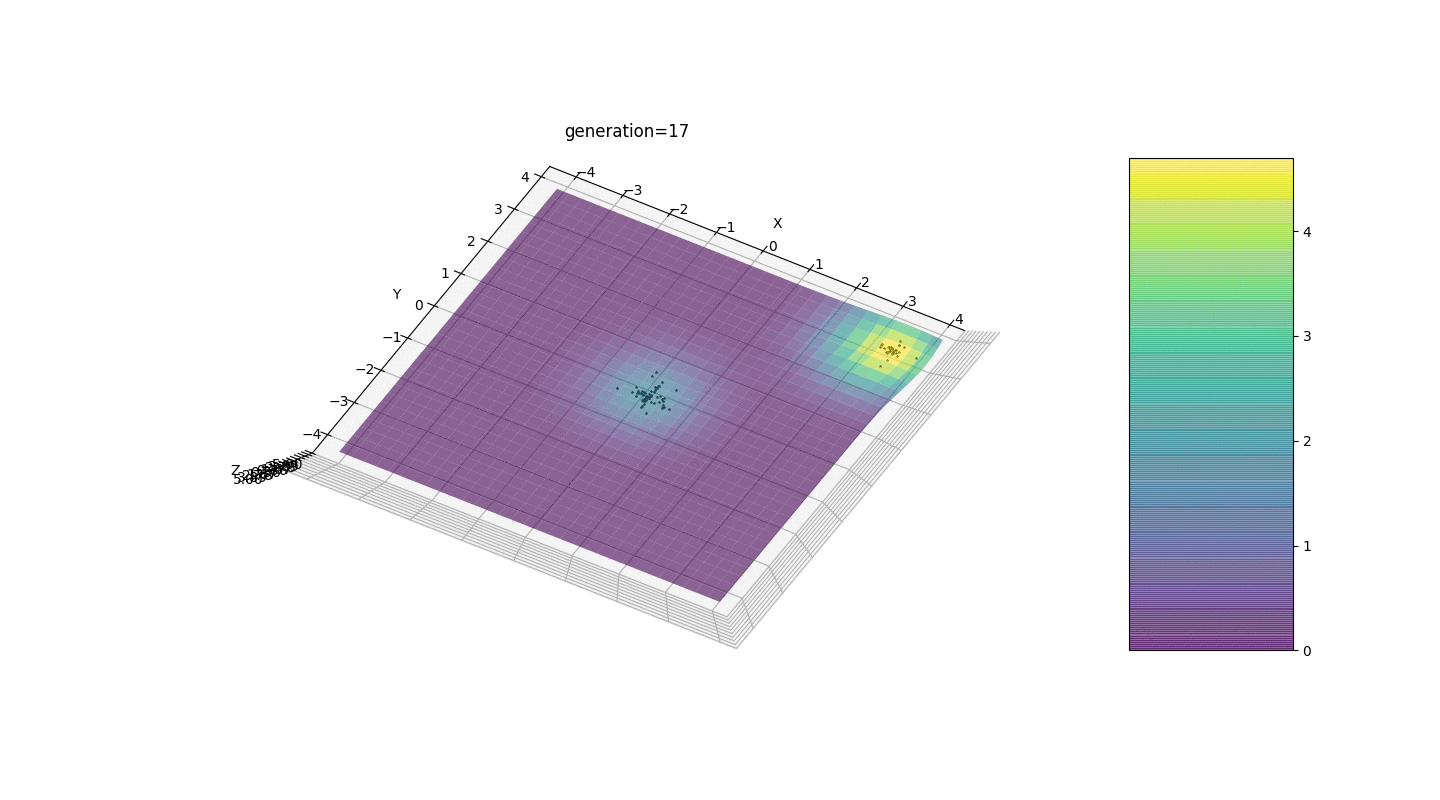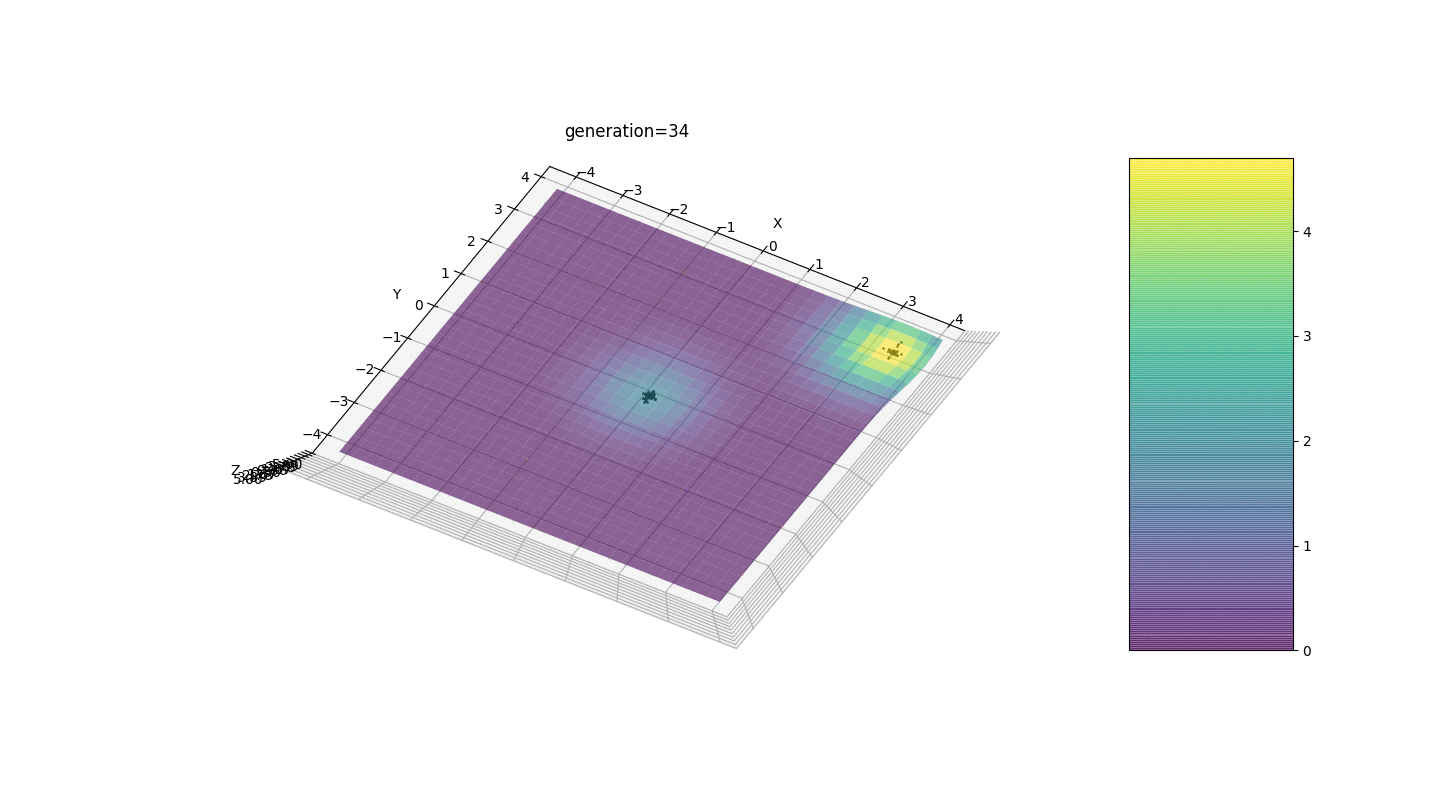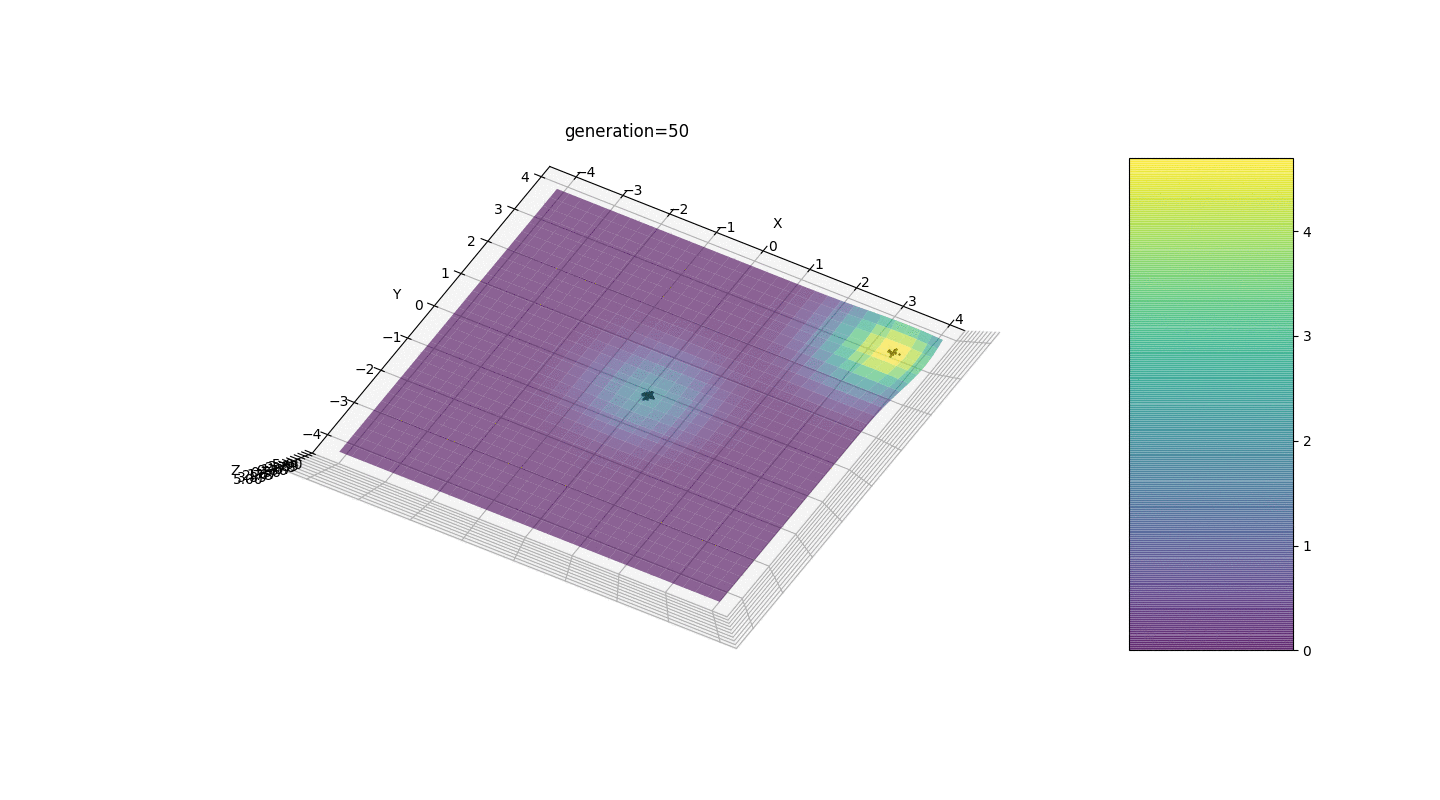
- La generación cero se llena con números aleatorios solo en un cuadrado
y puede haber casos en que este cuadrado cubra un extremo local, lo que no nos conviene
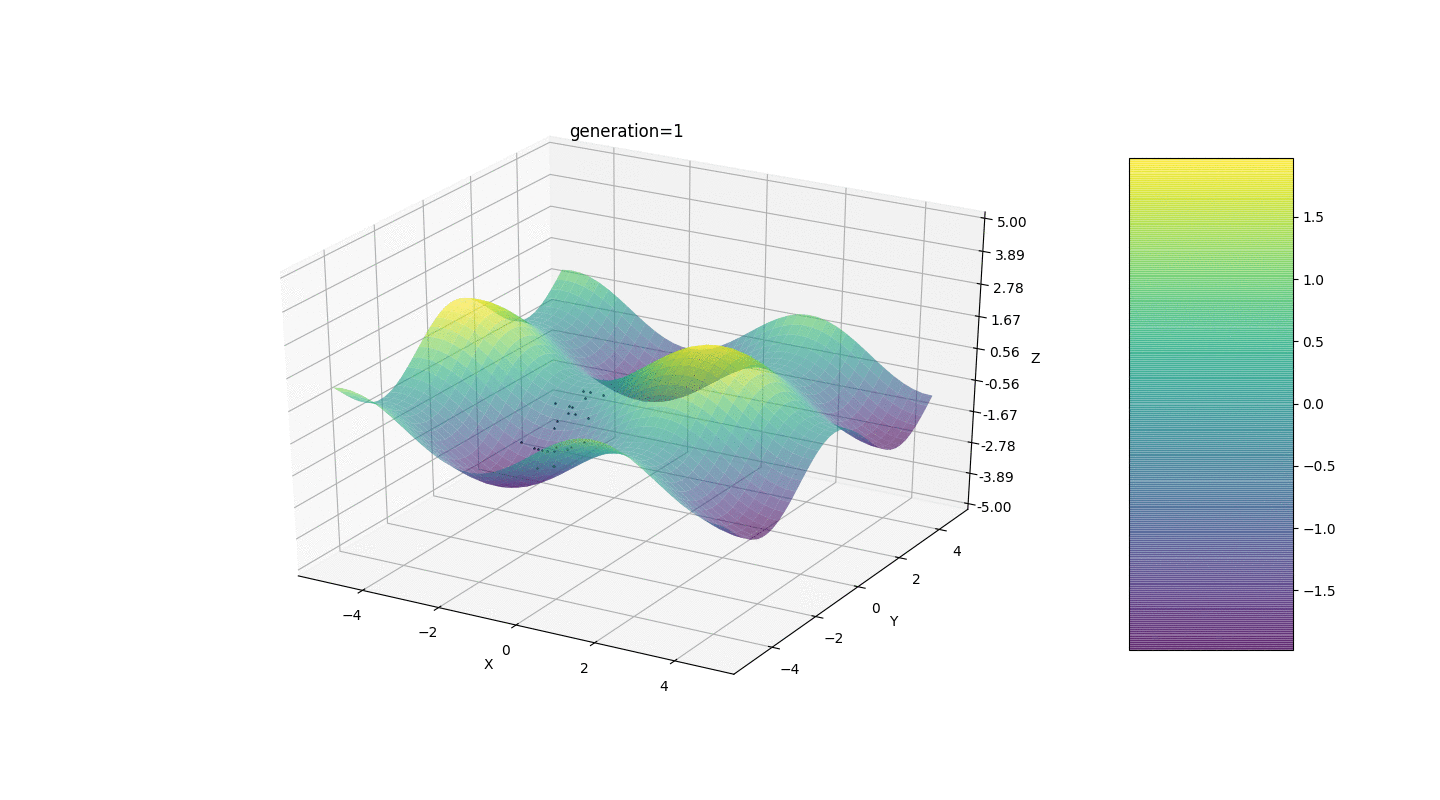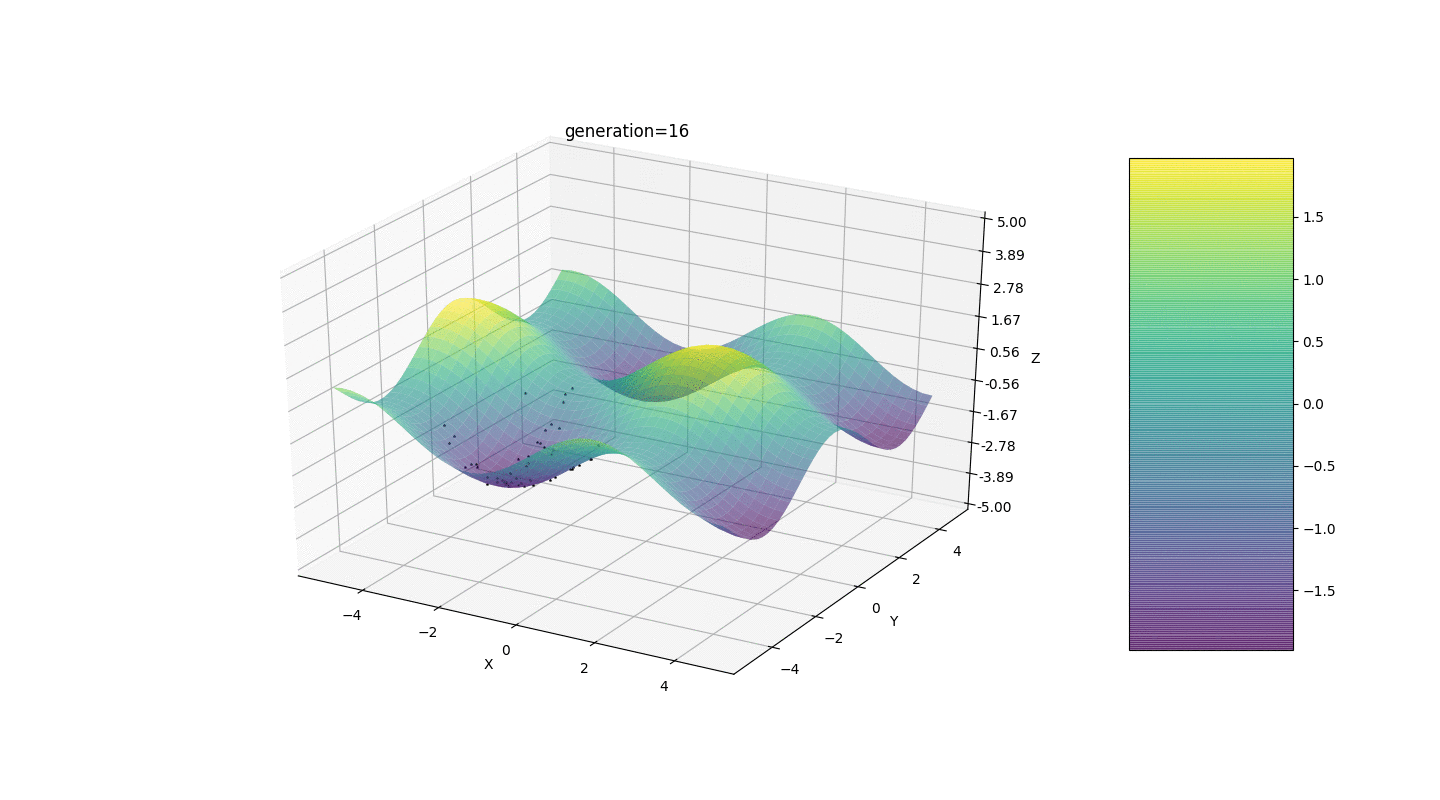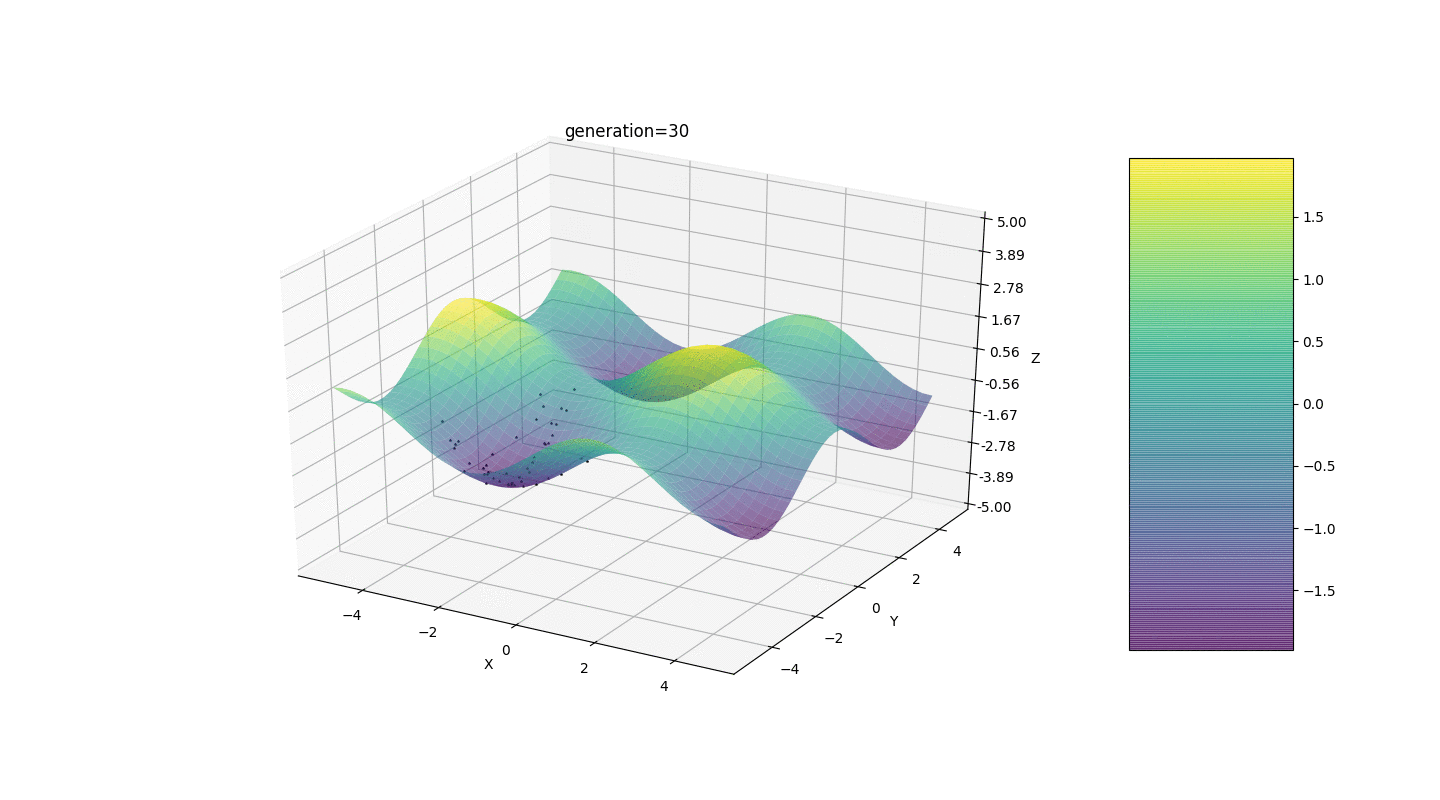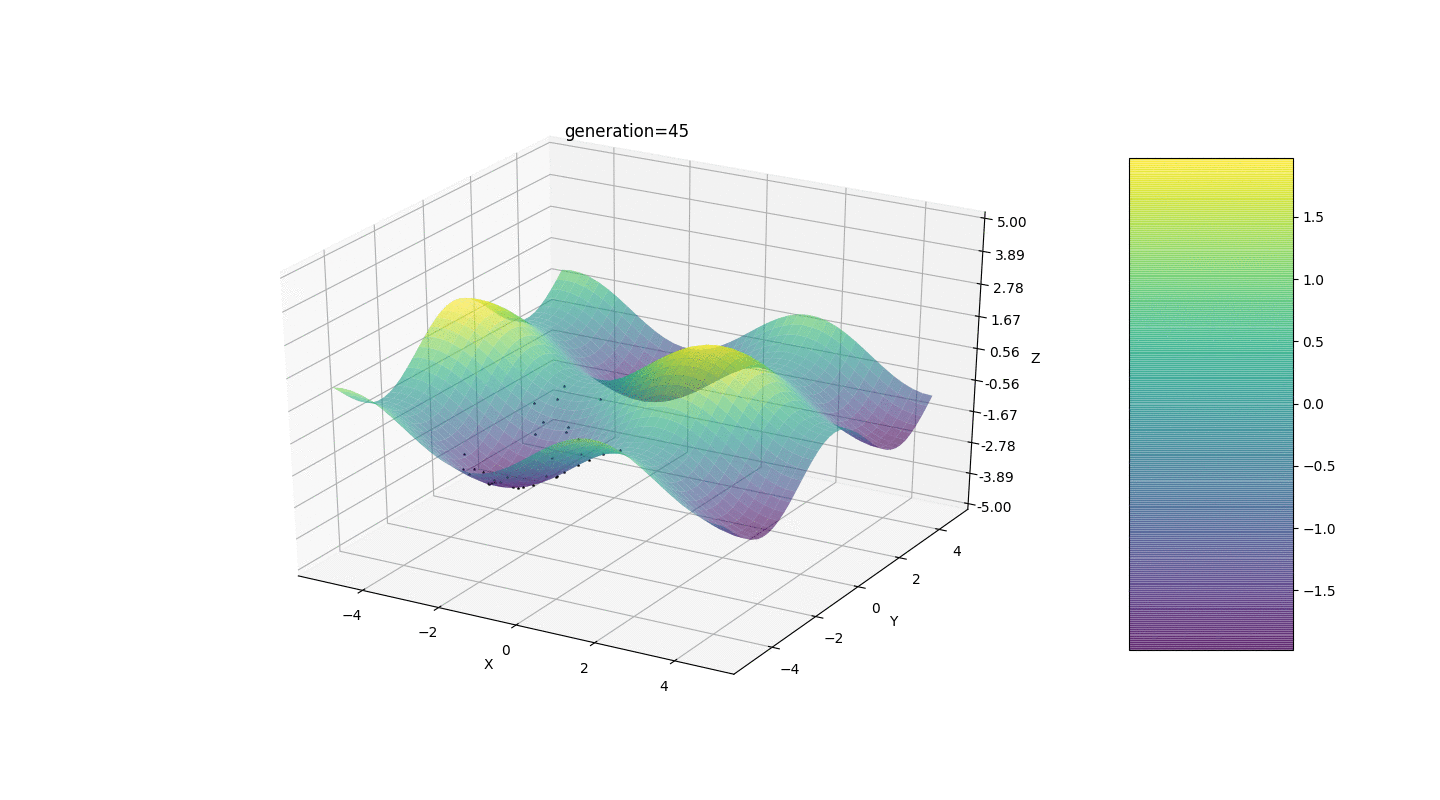
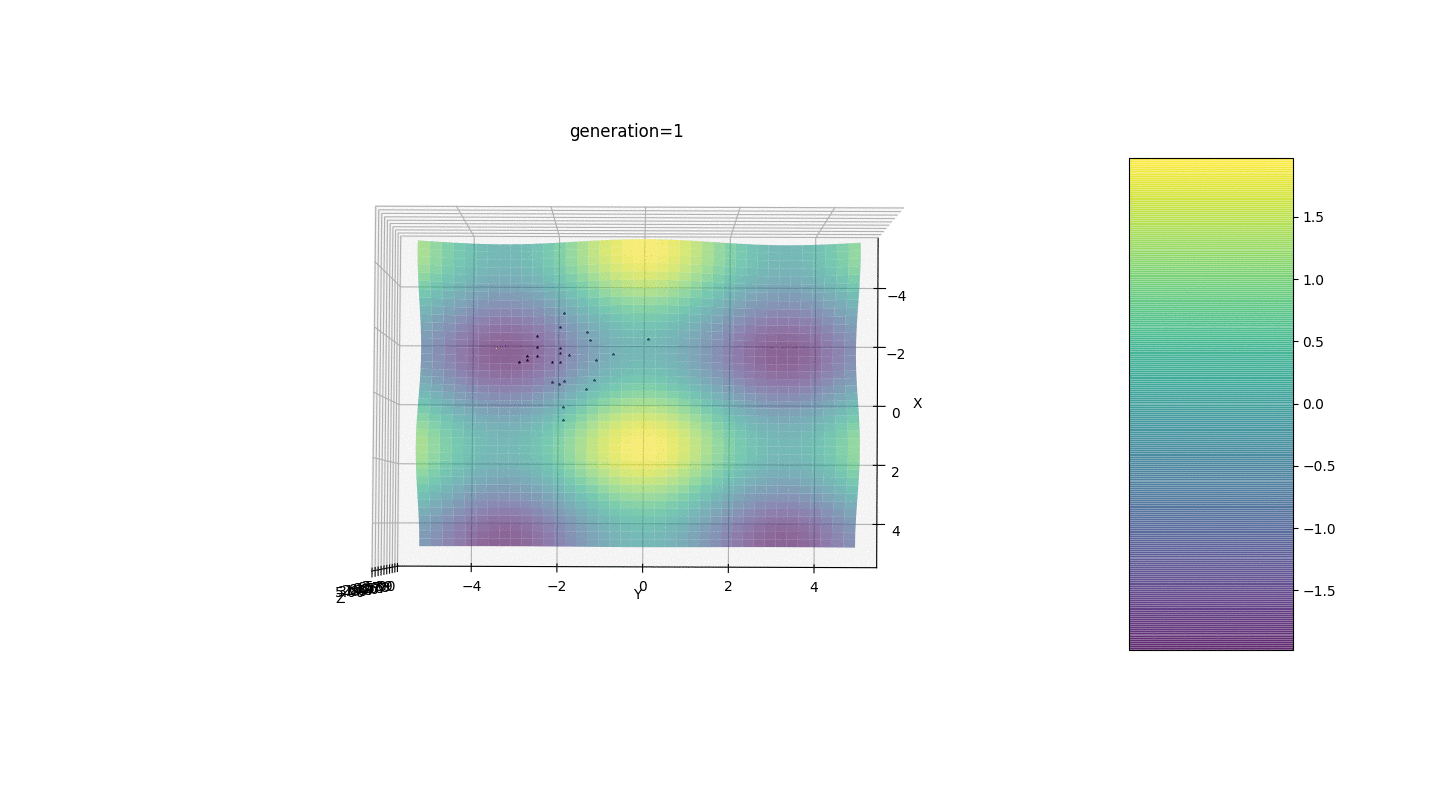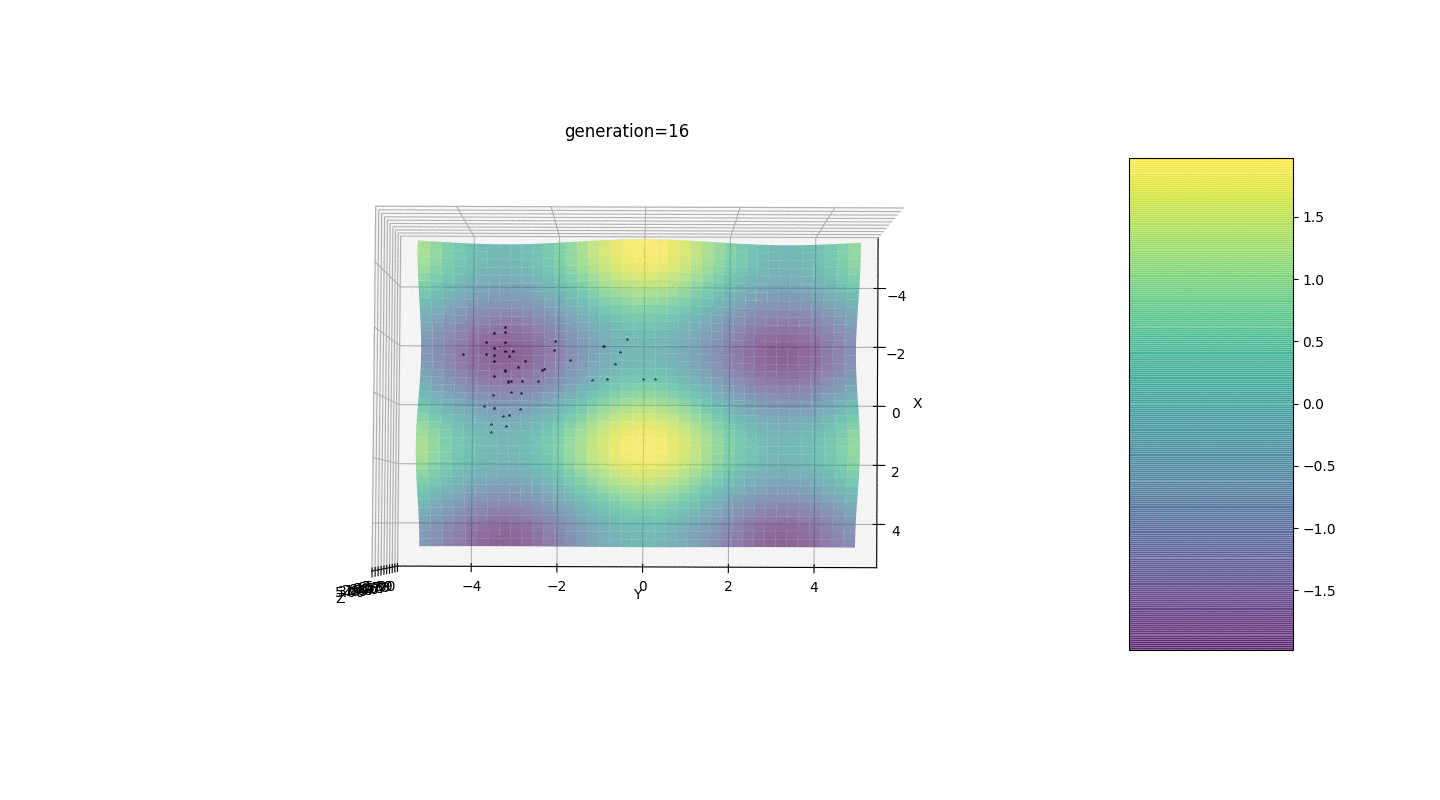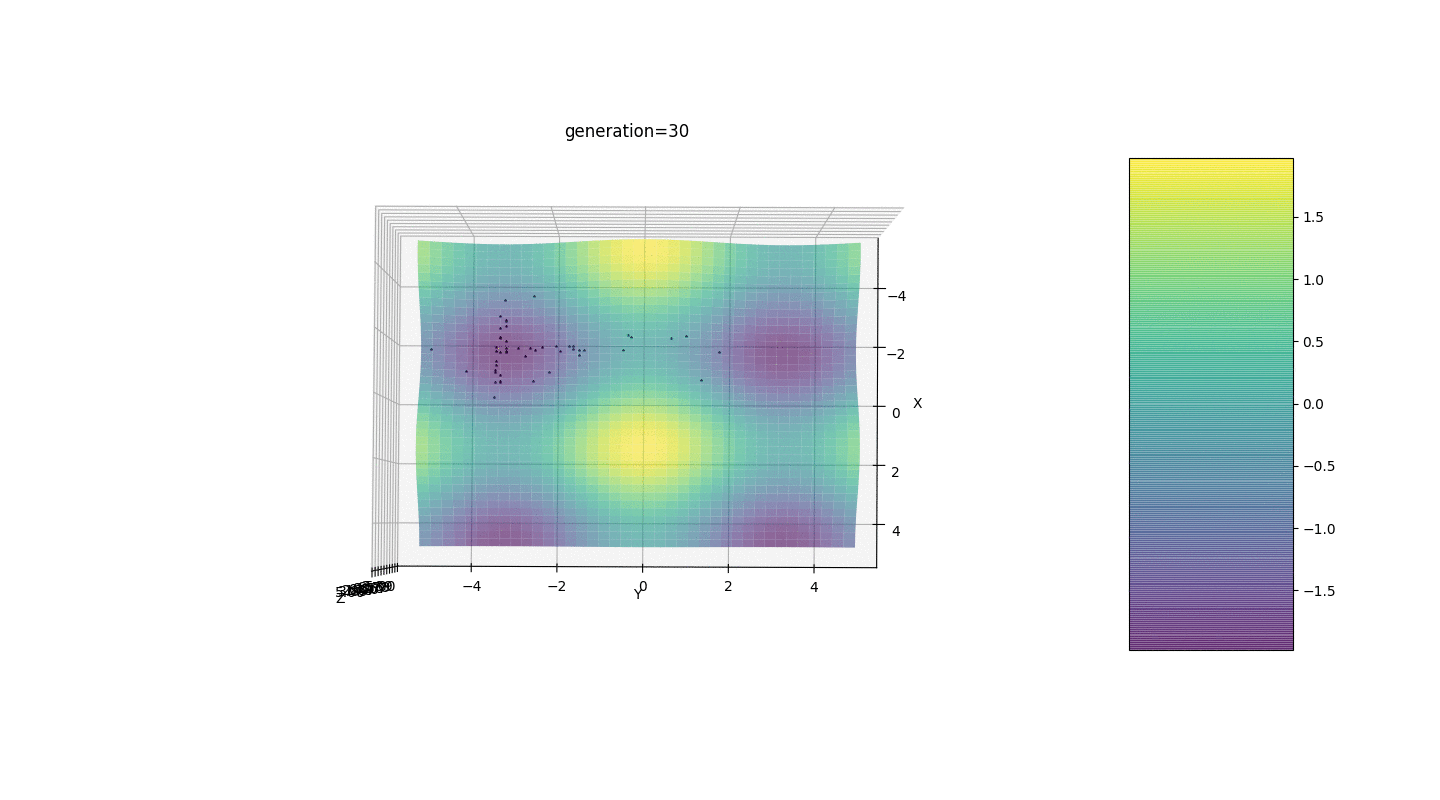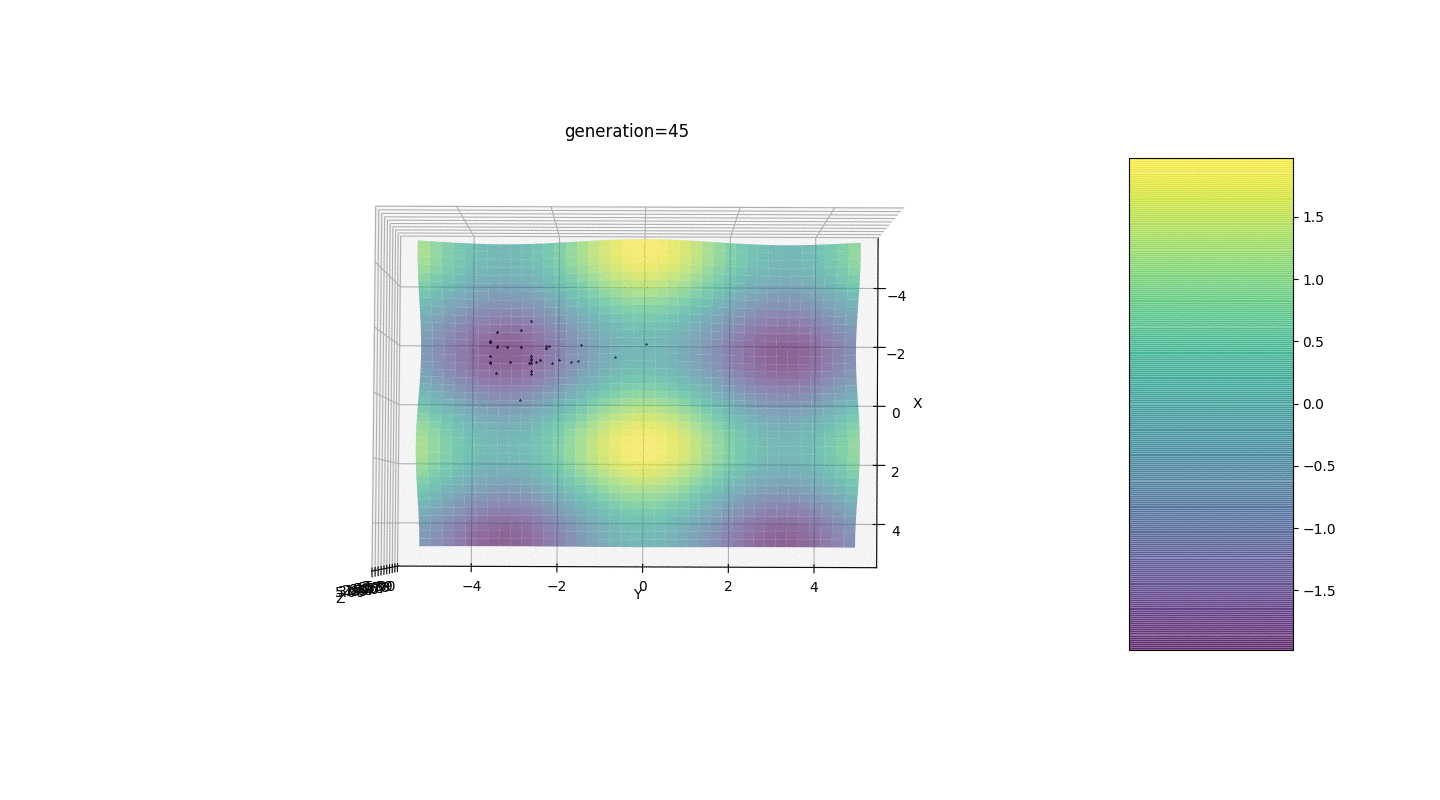
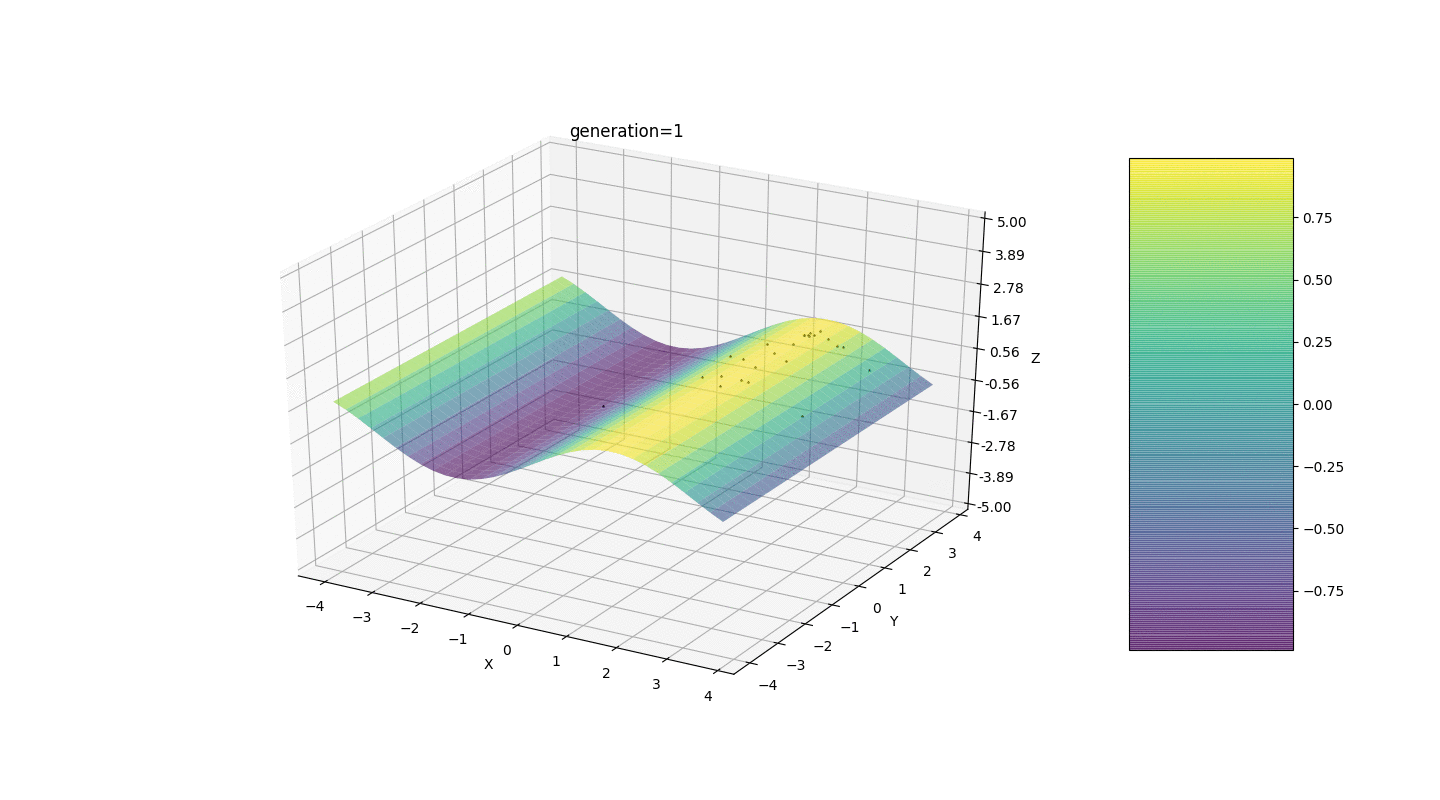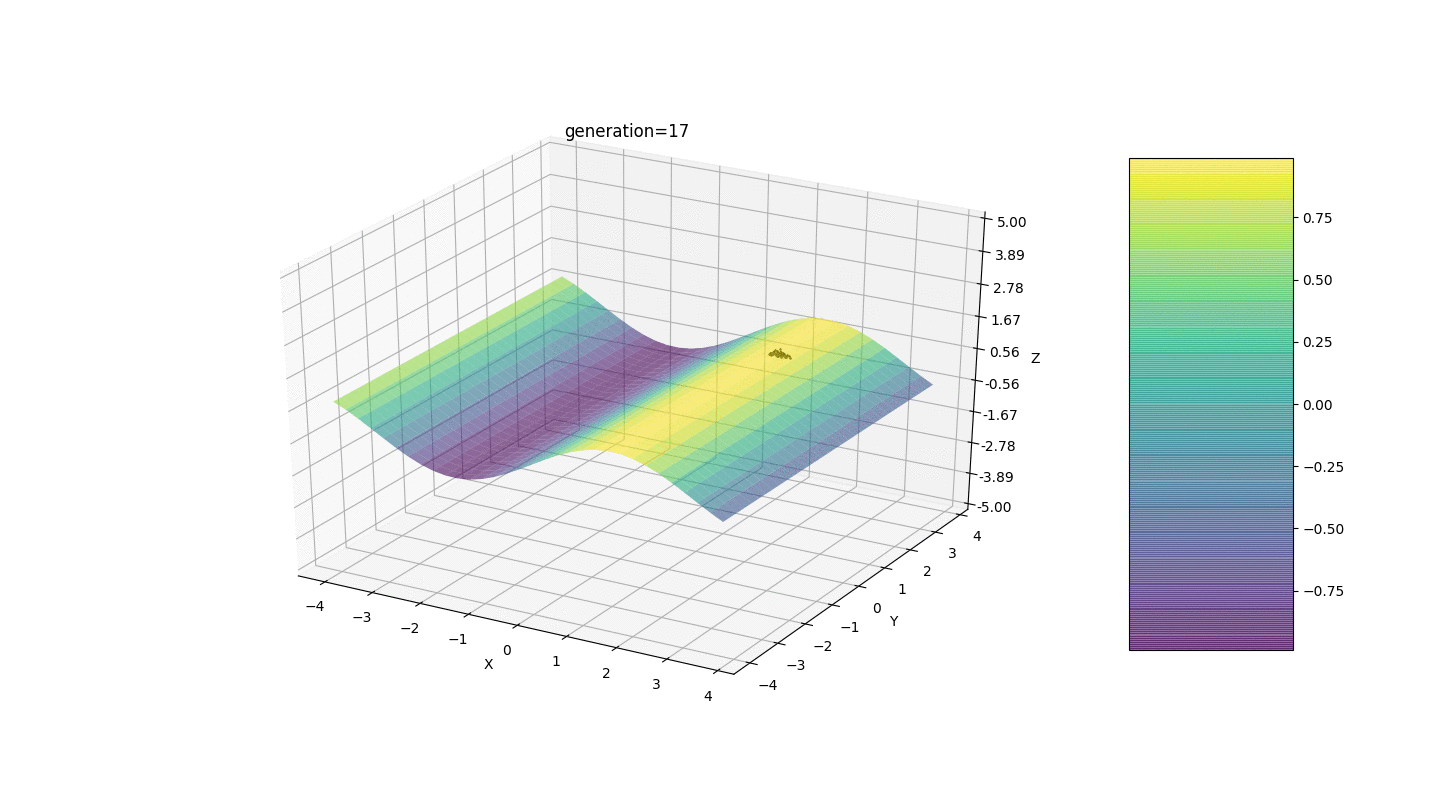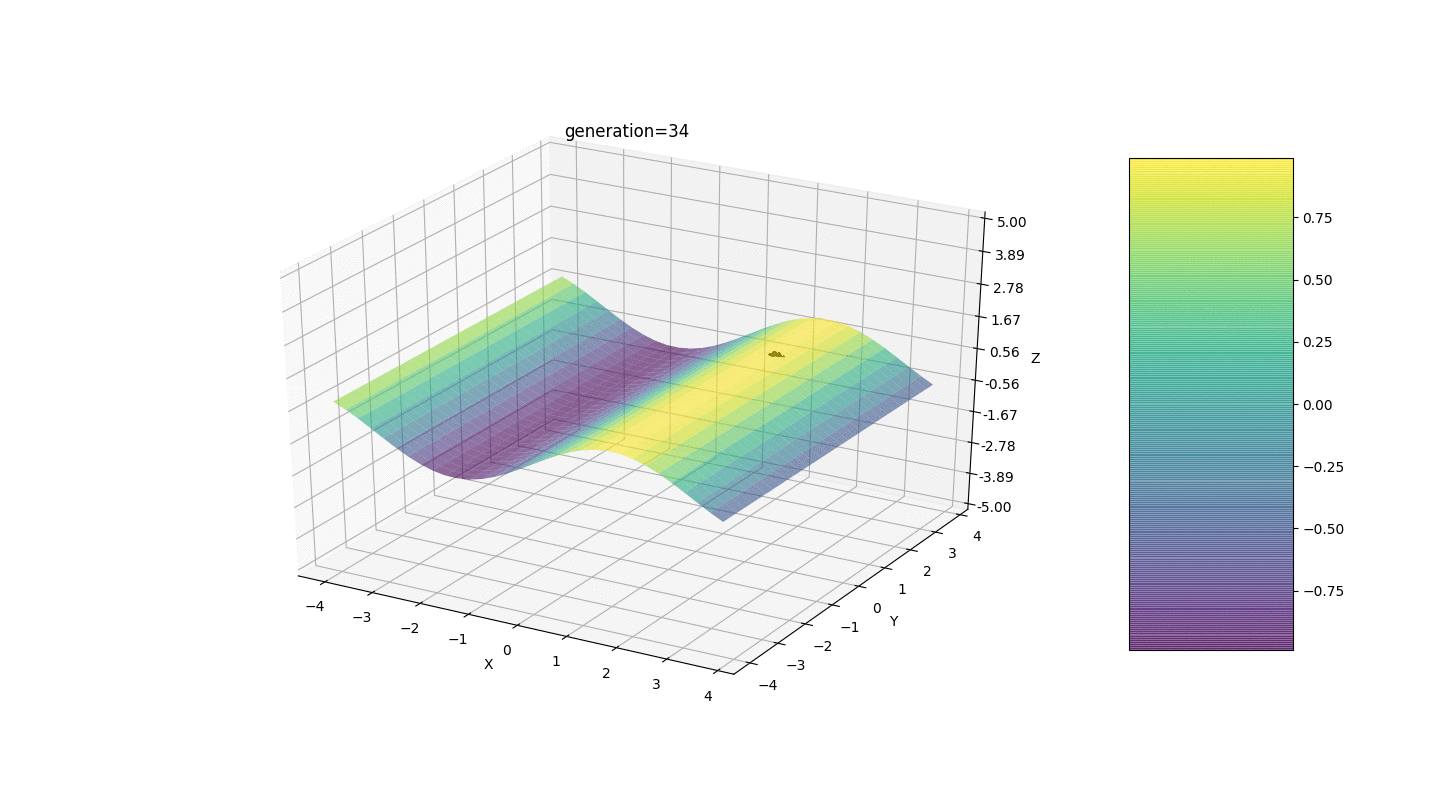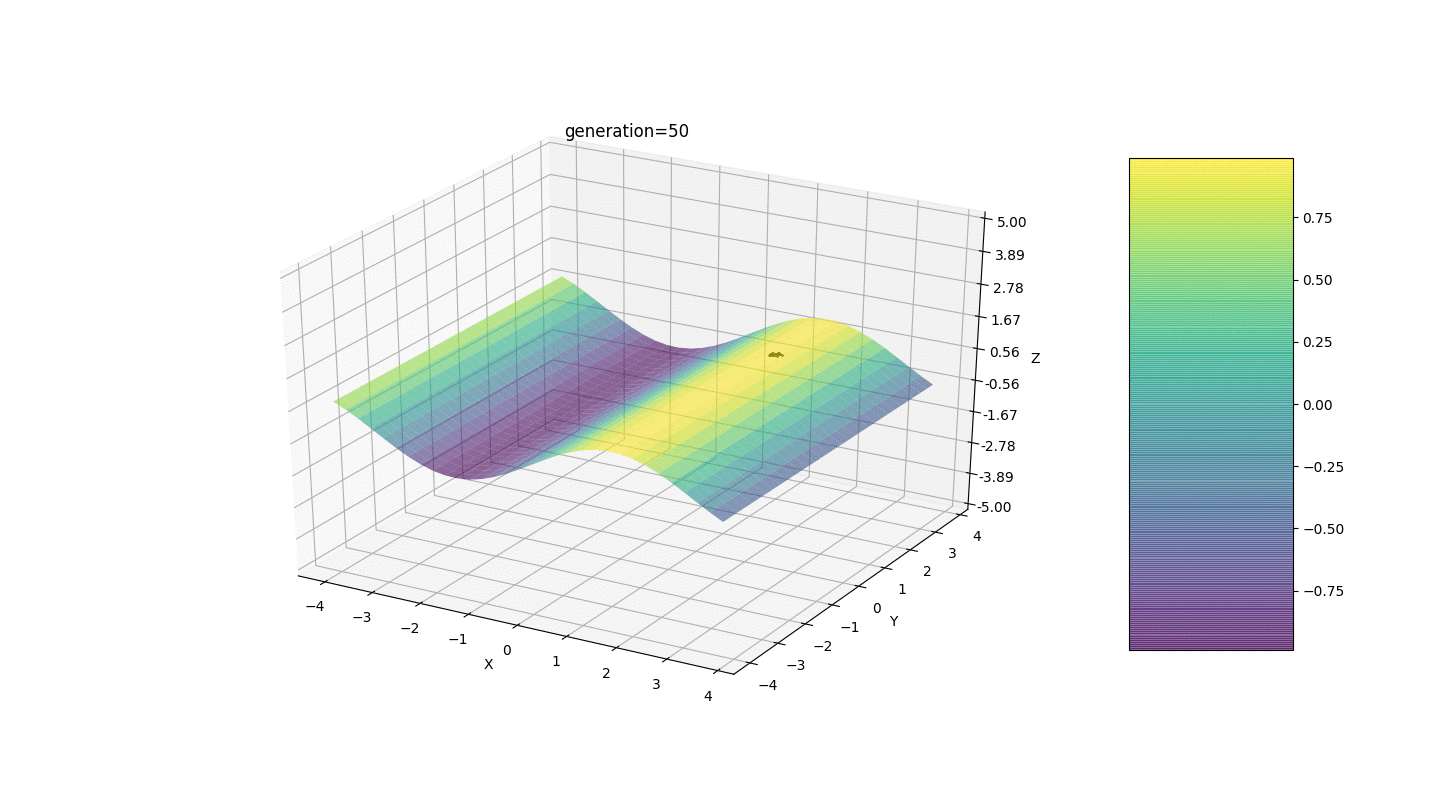
Considere una superficie con muchos extremos de la forma:Los extremos de la función g estarán en puntos.Prueba 3 Este ejemplo confirma e ilustra todas las observaciones anteriores.
Este ejemplo confirma e ilustra todas las observaciones anteriores.Actualización del algoritmo genético
Entonces, en este momento, la función de mutación está compuesta de manera muy primitiva: agrega valores aleatorios del medio intervaloal gen mutado. Tal invariancia de mutación a veces interfiere con el funcionamiento correcto del algoritmo, pero hay una manera efectiva de corregir este defecto.Introducimos un nuevo parámetro, que llamaremos el "rango de mutación" y que mostrará en qué medio intervalo muta el gen. Hagamos que este coeficiente de mutación sea inversamente proporcional al número de generación. Aquellos. cuanto mayor es el número de generación, más débiles mutan los genes. Esta solución le permite personalizar el área de inicio y mejorar la precisión de los cálculos si es necesario.Prueba 1
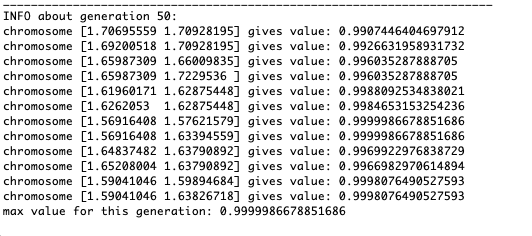 Como muestra el ejemplo, ahora, con cada generación, la población converge cada vez más hasta el punto extremo y calcula los valores más precisos debido a fluctuaciones débiles.Pero, ¿qué pasa con el problema de los extremos locales? Considere un ejemplo familiar.Prueba 2
Como muestra el ejemplo, ahora, con cada generación, la población converge cada vez más hasta el punto extremo y calcula los valores más precisos debido a fluctuaciones débiles.Pero, ¿qué pasa con el problema de los extremos locales? Considere un ejemplo familiar.Prueba 2

 Vemos que ahora la idea de dividir a la población en partes funciona según lo previsto. Sin esta segmentación, los individuos de las primeras generaciones podrían revelar un genotipo falso dominante en un extremo local, lo que conduciría a una respuesta incorrecta en la tarea. También es notable una mejora cualitativa en la precisión de la respuesta debido a la dependencia introducida de la mutación en el número de generación.
Vemos que ahora la idea de dividir a la población en partes funciona según lo previsto. Sin esta segmentación, los individuos de las primeras generaciones podrían revelar un genotipo falso dominante en un extremo local, lo que conduciría a una respuesta incorrecta en la tarea. También es notable una mejora cualitativa en la precisión de la respuesta debido a la dependencia introducida de la mutación en el número de generación.Resumen
Resumo el resultado:...
- , . , , aka
- Comparación en tiempo y eficiencia de algoritmos similares con métodos de optimización estándar, por ejemplo, descenso de gradiente
- Nuevas características del paquete (probable)