Conozcamos uno de los ataques a la red neuronal, que conduce a errores de clasificación con mínimas influencias externas. Imagine por un momento que la red neuronal es usted. Y en este momento, mientras bebe una taza de café aromático, clasifica las imágenes de los gatos con una precisión de más del 90 por ciento sin siquiera sospechar que el "ataque de un píxel" convirtió a todos sus "gatos" en camiones.Y ahora haremos una pausa, apartaremos el café, importaremos todas las bibliotecas que necesitamos y analizaremos cómo funcionan esos ataques de píxeles.El propósito de este ataque es hacer que el algoritmo (red neuronal) dé una respuesta incorrecta. A continuación veremos esto con varios modelos diferentes de redes neuronales convolucionales. Usando uno de los métodos de optimización matemática multidimensional: evolución diferencial, encontramos un píxel especial que puede cambiar la imagen para que la red neuronal comience a clasificar incorrectamente esta imagen (a pesar de que anteriormente el algoritmo "reconoció" la misma imagen correctamente y con alta precisión).Importar las bibliotecas:
%matplotlib inline
import pickle
import numpy as np
import pandas as pd
import matplotlib
from keras.datasets import cifar10
from keras import backend as K
from networks.lenet import LeNet
from networks.pure_cnn import PureCnn
from networks.network_in_network import NetworkInNetwork
from networks.resnet import ResNet
from networks.densenet import DenseNet
from networks.wide_resnet import WideResNet
from networks.capsnet import CapsNet
from differential_evolution import differential_evolution
import helper
matplotlib.style.use('ggplot')
Para nuestro experimento, cargaremos el conjunto de datos CIFAR-10 que contiene imágenes del mundo real divididas en 10 clases.(x_train, y_train), (x_test, y_test) = cifar10.load_data()
class_names = ['airplane', 'automobile', 'bird', 'cat', 'deer', 'dog', 'frog', 'horse', 'ship', 'truck']
Veamos cualquier imagen por su índice. Por ejemplo, aquí en este caballo.image_id = 99
helper.plot_image(x_test[image_id])
 Tendremos que buscar el píxel muy poderoso que puede cambiar la respuesta de la red neuronal, lo que significa que es hora de escribir una función para cambiar uno o más píxeles de la imagen.
Tendremos que buscar el píxel muy poderoso que puede cambiar la respuesta de la red neuronal, lo que significa que es hora de escribir una función para cambiar uno o más píxeles de la imagen.def perturb_image(xs, img):
if xs.ndim < 2:
xs = np.array([xs])
tile = [len(xs)] + [1]*(xs.ndim+1)
imgs = np.tile(img, tile)
xs = xs.astype(int)
for x,img in zip(xs, imgs):
pixels = np.split(x, len(x) // 5)
for pixel in pixels:
x_pos, y_pos, *rgb = pixel
img[x_pos, y_pos] = rgb
return imgs
Echale un vistazo ?! Cambia un píxel de nuestro caballo con coordenadas (16, 16) a amarillo.image_id = 99
pixel = np.array([16, 16, 255, 255, 0])
image_perturbed = perturb_image(pixel, x_test[image_id])[0]
helper.plot_image(image_perturbed)
 Para demostrar el ataque, debe descargar modelos pre entrenados de redes neuronales en nuestro conjunto de datos CIFAR-10. Usaremos dos modelos lenet y resnet, pero puede usar otros para sus experimentos al descomentar las líneas de código correspondientes.
Para demostrar el ataque, debe descargar modelos pre entrenados de redes neuronales en nuestro conjunto de datos CIFAR-10. Usaremos dos modelos lenet y resnet, pero puede usar otros para sus experimentos al descomentar las líneas de código correspondientes.lenet = LeNet()
resnet = ResNet()
models = [lenet, resnet]
Después de cargar los modelos, es necesario evaluar las imágenes de prueba de cada modelo para asegurarse de que atacamos solo las imágenes que están clasificadas correctamente. El siguiente código muestra la precisión y el número de parámetros para cada modelo.network_stats, correct_imgs = helper.evaluate_models(models, x_test, y_test)
correct_imgs = pd.DataFrame(correct_imgs, columns=['name', 'img', 'label', 'confidence', 'pred'])
network_stats = pd.DataFrame(network_stats, columns=['name', 'accuracy', 'param_count'])
network_stats
Evaluating lenet
Evaluating resnet
Out[11]:
name accuracy param_count
0 lenet 0.748 62006
1 resnet 0.9231 470218
Todos estos ataques se pueden dividir en dos clases: WhiteBox y BlackBox. La diferencia entre ellos es que, en el primer caso, todos conocemos de manera confiable el algoritmo, el modelo con el que estamos tratando. En el caso de BlackBox, todo lo que necesitamos es entrada (imagen) y salida (probabilidades de ser asignado a una de las clases). Un ataque de píxel se refiere al BlackBox.En este artículo, consideramos dos opciones para atacar un solo píxel: sin objetivo y dirigido. En el primer caso, no importará en absoluto a qué clase pertenecerá la red neuronal de nuestro gato, lo más importante, no a la clase de gatos. El ataque dirigido es aplicable cuando queremos que nuestro gato se convierta en un camión y solo en un camión.¿Pero cómo encontrar los mismos píxeles cuyo cambio conducirá a un cambio en la clase de la imagen? ¿Cómo encontrar un píxel cambiando cuál ataque de píxel se vuelve posible y exitoso? Intentemos formular este problema como un problema de optimización, pero solo en palabras muy simples: con un ataque no dirigido, debemos minimizar la confianza en la clase deseada y, con el objetivo, maximizar la confianza en la clase objetivo.Al llevar a cabo tales ataques, es difícil optimizar la función utilizando un gradiente. Se debe utilizar un algoritmo de optimización que no dependa de la suavidad de la función.Recuerde que para nuestro experimento usamos el conjunto de datos CIFAR-10, que contiene imágenes del mundo real, de 32 x 32 píxeles de tamaño, divididas en 10 clases. Y esto significa que tenemos valores discretos enteros de 0 a 31 e intensidades de color de 0 a 255, y no se espera que la función sea suave, sino irregular, como se muestra a continuación: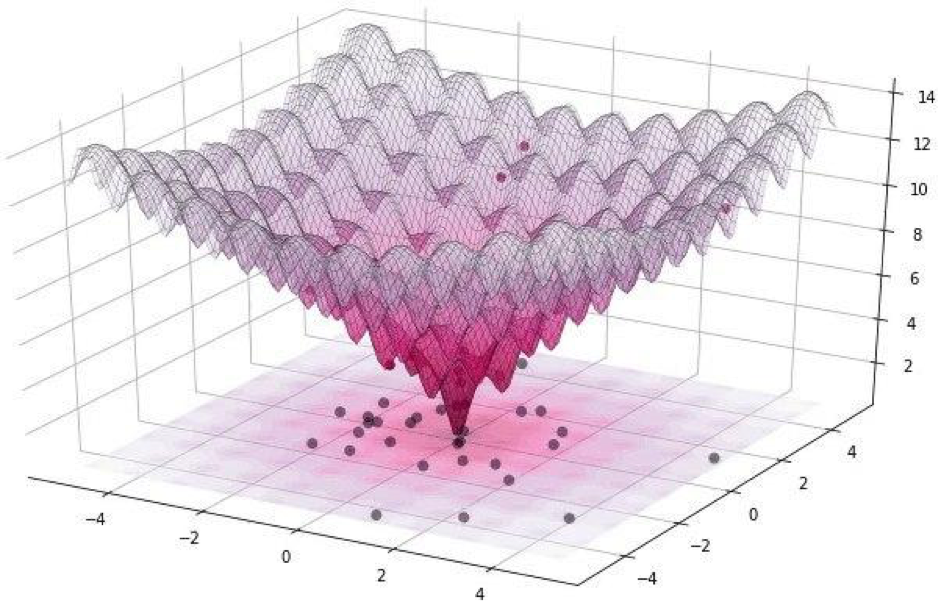 Es por eso que usamos el algoritmo de evolución diferencial.Pero regrese al código y escriba una función que devuelva la probabilidad de la confiabilidad del modelo. Si la clase de destino es correcta, entonces queremos minimizar esta función para que el modelo esté seguro de otra clase (lo cual no es cierto).
Es por eso que usamos el algoritmo de evolución diferencial.Pero regrese al código y escriba una función que devuelva la probabilidad de la confiabilidad del modelo. Si la clase de destino es correcta, entonces queremos minimizar esta función para que el modelo esté seguro de otra clase (lo cual no es cierto).def predict_classes(xs, img, target_class, model, minimize=True):
imgs_perturbed = perturb_image(xs, img)
predictions = model.predict(imgs_perturbed)[:,target_class]
return predictions if minimize else 1 - predictions
image_id = 384
pixel = np.array([16, 13, 25, 48, 156])
model = resnet
true_class = y_test[image_id, 0]
prior_confidence = model.predict_one(x_test[image_id])[true_class]
confidence = predict_classes(pixel, x_test[image_id], true_class, model)[0]
print('Confidence in true class', class_names[true_class], 'is', confidence)
print('Prior confidence was', prior_confidence)
helper.plot_image(perturb_image(pixel, x_test[image_id])[0])
Confidence in true class bird is 0.00018887444
Prior confidence was 0.70661753
 Necesitaremos la siguiente función para confirmar el criterio para el éxito del ataque, devolverá True cuando el cambio fue suficiente para engañar al modelo.
Necesitaremos la siguiente función para confirmar el criterio para el éxito del ataque, devolverá True cuando el cambio fue suficiente para engañar al modelo.def attack_success(x, img, target_class, model, targeted_attack=False, verbose=False):
attack_image = perturb_image(x, img)
confidence = model.predict(attack_image)[0]
predicted_class = np.argmax(confidence)
if verbose:
print('Confidence:', confidence[target_class])
if ((targeted_attack and predicted_class == target_class) or
(not targeted_attack and predicted_class != target_class)):
return True
Veamos el trabajo de la función de criterio de éxito. Para demostrar, asumimos un ataque no objetivo.image_id = 541
pixel = np.array([17, 18, 185, 36, 215])
model = resnet
true_class = y_test[image_id, 0]
prior_confidence = model.predict_one(x_test[image_id])[true_class]
success = attack_success(pixel, x_test[image_id], true_class, model, verbose=True)
print('Prior confidence', prior_confidence)
print('Attack success:', success == True)
helper.plot_image(perturb_image(pixel, x_test[image_id])[0])
Confidence: 0.07460087
Prior confidence 0.50054216
Attack success: True
 Es hora de reunir todos los rompecabezas en una sola imagen. Utilizaremos una pequeña modificación de la implementación de la evolución diferencial en Scipy.
Es hora de reunir todos los rompecabezas en una sola imagen. Utilizaremos una pequeña modificación de la implementación de la evolución diferencial en Scipy.def attack(img_id, model, target=None, pixel_count=1,
maxiter=75, popsize=400, verbose=False):
targeted_attack = target is not None
target_class = target if targeted_attack else y_test[img_id, 0]
bounds = [(0,32), (0,32), (0,256), (0,256), (0,256)] * pixel_count
popmul = max(1, popsize // len(bounds))
def predict_fn(xs):
return predict_classes(xs, x_test[img_id], target_class,
model, target is None)
def callback_fn(x, convergence):
return attack_success(x, x_test[img_id], target_class,
model, targeted_attack, verbose)
attack_result = differential_evolution(
predict_fn, bounds, maxiter=maxiter, popsize=popmul,
recombination=1, atol=-1, callback=callback_fn, polish=False)
attack_image = perturb_image(attack_result.x, x_test[img_id])[0]
prior_probs = model.predict_one(x_test[img_id])
predicted_probs = model.predict_one(attack_image)
predicted_class = np.argmax(predicted_probs)
actual_class = y_test[img_id, 0]
success = predicted_class != actual_class
cdiff = prior_probs[actual_class] - predicted_probs[actual_class]
helper.plot_image(attack_image, actual_class, class_names, predicted_class)
return [model.name, pixel_count, img_id, actual_class, predicted_class, success, cdiff, prior_probs, predicted_probs, attack_result.x]
Es hora de compartir los resultados del estudio (el ataque) y ver cómo cambiar solo un píxel convertirá una rana en un perro, un gato en una rana y un automóvil en un avión. Pero mientras más puntos de imagen se puedan cambiar, mayor será la probabilidad de un ataque exitoso sobre cualquier imagen.

 Demuestre un ataque exitoso a una imagen de rana usando el modelo de rediseño. Deberíamos ver confianza en la verdadera disminución de la clase después de varias iteraciones.
Demuestre un ataque exitoso a una imagen de rana usando el modelo de rediseño. Deberíamos ver confianza en la verdadera disminución de la clase después de varias iteraciones.image_id = 102
pixels = 1
model = resnet
_ = attack(image_id, model, pixel_count=pixels, verbose=True)
Confidence: 0.9938618
Confidence: 0.77454716
Confidence: 0.77454716
Confidence: 0.77454716
Confidence: 0.77454716
Confidence: 0.77454716
Confidence: 0.53226393
Confidence: 0.53226393
Confidence: 0.53226393
Confidence: 0.53226393
Confidence: 0.4211318
 Estos fueron ejemplos de un ataque no dirigido, y ahora realizaremos un ataque dirigido y elegiremos a qué clase nos gustaría que el modelo clasifique la imagen. La tarea es mucho más complicada que la anterior, porque haremos que la red neuronal clasifique la imagen de un barco como un automóvil y un caballo como un gato.
Estos fueron ejemplos de un ataque no dirigido, y ahora realizaremos un ataque dirigido y elegiremos a qué clase nos gustaría que el modelo clasifique la imagen. La tarea es mucho más complicada que la anterior, porque haremos que la red neuronal clasifique la imagen de un barco como un automóvil y un caballo como un gato.
 A continuación trataremos de obtener Lenet para clasificar la imagen del barco como un automóvil.
A continuación trataremos de obtener Lenet para clasificar la imagen del barco como un automóvil.image_id = 108
target_class = 1
pixels = 3
model = lenet
print('Attacking with target', class_names[target_class])
_ = attack(image_id, model, target_class, pixel_count=pixels, verbose=True)
Attacking with target automobile
Confidence: 0.044409167
Confidence: 0.044409167
Confidence: 0.044409167
Confidence: 0.054611664
Confidence: 0.054611664
Confidence: 0.054611664
Confidence: 0.054611664
Confidence: 0.054611664
Confidence: 0.054611664
Confidence: 0.054611664
Confidence: 0.054611664
Confidence: 0.054611664
Confidence: 0.054611664
Confidence: 0.054611664
Confidence: 0.054611664
Confidence: 0.081972085
Confidence: 0.081972085
Confidence: 0.081972085
Confidence: 0.081972085
Confidence: 0.1537778
Confidence: 0.1537778
Confidence: 0.1537778
Confidence: 0.22246778
Confidence: 0.23916133
Confidence: 0.25238588
Confidence: 0.25238588
Confidence: 0.25238588
Confidence: 0.44560355
Confidence: 0.44560355
Confidence: 0.44560355
Confidence: 0.5711696
 Después de tratar casos únicos de ataques, recopilaremos estadísticas utilizando la arquitectura de redes neuronales convolucionales ResNet, revisando cada modelo, cambiando 1, 3 o 5 píxeles de cada imagen. En este artículo, mostramos las conclusiones finales sin molestar al lector a familiarizarse con cada iteración, ya que requiere mucho tiempo y recursos computacionales.
Después de tratar casos únicos de ataques, recopilaremos estadísticas utilizando la arquitectura de redes neuronales convolucionales ResNet, revisando cada modelo, cambiando 1, 3 o 5 píxeles de cada imagen. En este artículo, mostramos las conclusiones finales sin molestar al lector a familiarizarse con cada iteración, ya que requiere mucho tiempo y recursos computacionales.def attack_all(models, samples=500, pixels=(1,3,5), targeted=False,
maxiter=75, popsize=400, verbose=False):
results = []
for model in models:
model_results = []
valid_imgs = correct_imgs[correct_imgs.name == model.name].img
img_samples = np.random.choice(valid_imgs, samples, replace=False)
for pixel_count in pixels:
for i, img_id in enumerate(img_samples):
print('\n', model.name, '- image', img_id, '-', i+1, '/', len(img_samples))
targets = [None] if not targeted else range(10)
for target in targets:
if targeted:
print('Attacking with target', class_names[target])
if target == y_test[img, 0]:
continue
result = attack(img_id, model, target, pixel_count,
maxiter=maxiter, popsize=popsize,
verbose=verbose)
model_results.append(result)
results += model_results
helper.checkpoint(results, targeted)
return results
untargeted = attack_all(models, samples=100, targeted=False)
targeted = attack_all(models, samples=10, targeted=False)
Para probar la posibilidad de desacreditar la red, se desarrolló un algoritmo y se midió su efecto sobre la calidad del pronóstico de la solución de reconocimiento de patrones.Veamos los resultados finales.untargeted, targeted = helper.load_results()
columns = ['model', 'pixels', 'image', 'true', 'predicted', 'success', 'cdiff', 'prior_probs', 'predicted_probs', 'perturbation']
untargeted_results = pd.DataFrame(untargeted, columns=columns)
targeted_results = pd.DataFrame(targeted, columns=columns)
La siguiente tabla muestra que al usar la red neuronal ResNet con una precisión de 0.9231, cambiando varios píxeles de la imagen, obtuvimos un muy buen porcentaje de imágenes atacadas con éxito (tasa de éxito de ataque).helper.attack_stats(targeted_results, models, network_stats)
Out[26]:
model accuracy pixels attack_success_rate
0 resnet 0.9231 1 0.144444
1 resnet 0.9231 3 0.211111
2 resnet 0.9231 5 0.222222
helper.attack_stats(untargeted_results, models, network_stats)
Out[27]:
model accuracy pixels attack_success_rate
0 resnet 0.9231 1 0.34
1 resnet 0.9231 3 0.79
2 resnet 0.9231 5 0.79
En sus experimentos, es libre de usar otras arquitecturas de redes neuronales artificiales, ya que actualmente hay muchas de ellas. Las redes neuronales han envuelto el mundo moderno con hilos invisibles. Los servicios se han inventado durante mucho tiempo donde, usando inteligencia artificial (IA), los usuarios obtienen fotos procesadas estilísticamente similares al trabajo de grandes artistas, y hoy los algoritmos ya pueden dibujar imágenes ellos mismos, crear obras maestras musicales, escribir libros e incluso guiones para películas.Áreas como la visión por computadora, el reconocimiento facial, los vehículos no tripulados, el diagnóstico de enfermedades: toman decisiones importantes y no tienen derecho a cometer errores, y la interferencia con el funcionamiento de los algoritmos tendrá consecuencias desastrosas.Un ataque de píxeles es una forma de falsificar ataques. Para probar la posibilidad de desacreditar la red, se desarrolló un algoritmo y se midió su efecto sobre la calidad del pronóstico de la solución de reconocimiento de patrones. El resultado mostró que las arquitecturas de redes neuronales convolucionales utilizadas son vulnerables al algoritmo de ataque de un píxel especialmente entrenado, que reemplaza a un píxel, para desacreditar el algoritmo de reconocimiento.El artículo fue preparado por Alexander Andronic y Adrey Cherny-Tkach como parte de una pasantía en Data4 .
Las redes neuronales han envuelto el mundo moderno con hilos invisibles. Los servicios se han inventado durante mucho tiempo donde, usando inteligencia artificial (IA), los usuarios obtienen fotos procesadas estilísticamente similares al trabajo de grandes artistas, y hoy los algoritmos ya pueden dibujar imágenes ellos mismos, crear obras maestras musicales, escribir libros e incluso guiones para películas.Áreas como la visión por computadora, el reconocimiento facial, los vehículos no tripulados, el diagnóstico de enfermedades: toman decisiones importantes y no tienen derecho a cometer errores, y la interferencia con el funcionamiento de los algoritmos tendrá consecuencias desastrosas.Un ataque de píxeles es una forma de falsificar ataques. Para probar la posibilidad de desacreditar la red, se desarrolló un algoritmo y se midió su efecto sobre la calidad del pronóstico de la solución de reconocimiento de patrones. El resultado mostró que las arquitecturas de redes neuronales convolucionales utilizadas son vulnerables al algoritmo de ataque de un píxel especialmente entrenado, que reemplaza a un píxel, para desacreditar el algoritmo de reconocimiento.El artículo fue preparado por Alexander Andronic y Adrey Cherny-Tkach como parte de una pasantía en Data4 .