Preludio
Este es el segundo de cuatro artículos de una serie que proporcionará información sobre la mecánica y el diseño de punteros, pilas, montones, análisis de escape y semántica Go / Value. Esta publicación trata sobre montones y análisis de escape.Tabla de contenido:- Mecánica del lenguaje en pilas y punteros ( traducción )
- Mecánica del lenguaje en el análisis de escape
- Mecánica del lenguaje en perfiles de memoria
- Filosofía de diseño sobre datos y semántica
Introducción
En la primera publicación de esta serie, hablé sobre los conceptos básicos de la mecánica del puntero utilizando un ejemplo en el que el valor se distribuye en la pila entre goroutines. No te mostré lo que sucede cuando divides el valor en la pila. Para comprender esto, debe averiguar sobre otra área de la memoria donde pueden estar los valores: sobre el "montón". Con este conocimiento, puede comenzar a estudiar el "análisis de escape".El análisis de escape es un proceso que el compilador utiliza para determinar la ubicación de los valores creados por su programa. En particular, el compilador realiza un análisis de código estático para determinar si el valor se puede colocar en el marco de la pila para la función que lo construye, o si el valor debe "escaparse" al montón. No hay una sola palabra clave o función en Go que pueda usar para decirle al compilador qué decisión tomar. Solo la forma en que escribe su código condicionalmente le permite influir en esta decisión.Muchísimo
Un montón es una segunda área de memoria, además de la pila, utilizada para almacenar valores. El montón no es autolimpiante como las pilas, por lo que usar esta memoria es más costoso. En primer lugar, los costos están asociados con el recolector de basura (GC), que debe mantener limpia esta área. Cuando se inicia el GC, utilizará el 25% de la potencia disponible de su procesador. Además, potencialmente puede crear microsegundos de demoras para "detener el mundo". La ventaja de tener un GC es que no tiene que preocuparse por administrar la memoria de almacenamiento dinámico que históricamente ha sido compleja y propensa a errores.Los valores en el montón provocan asignaciones de memoria en Go. Estas asignaciones ejercen presión sobre el GC porque cada valor en el montón al que el puntero ya no hace referencia debe eliminarse. Cuantos más valores necesite verificar y eliminar, más trabajo debe realizar el GC en cada inicio. Por lo tanto, el algoritmo de estimulación trabaja constantemente para equilibrar el tamaño del montón y la velocidad de ejecución.Compartir pila
En el lenguaje Go, ni una sola goroutina puede tener un puntero apuntando a un recuerdo en la pila de otra goroutine. Esto se debe al hecho de que la memoria de la pila para goroutines se puede reemplazar con un nuevo bloque de memoria, cuando la pila debe aumentar o disminuir. Si en el tiempo de ejecución tuvieras que rastrear los punteros de la pila en otra rutina, tendrías que manejar demasiado, y el retraso de "detener el mundo" al actualizar los punteros a estas pilas sería asombroso.Aquí hay un ejemplo de una pila que se reemplaza varias veces debido al crecimiento. Mire la salida en las líneas 2 y 6. Verá dos veces los cambios de dirección del valor de la cadena dentro del marco de la pila principal.play.golang.org/p/pxn5u4EBSIMecánica de escape
Cada vez que se comparte un valor fuera de la región del marco de la pila de una función, se coloca (o asigna) en un montón. La tarea de los algoritmos de análisis de escape es encontrar tales situaciones y mantener el nivel de integridad en el programa. La integridad es garantizar que el acceso a cualquier valor sea siempre preciso, consistente y eficiente.Eche un vistazo a este ejemplo para conocer los mecanismos básicos del análisis de escape.play.golang.org/p/Y_VZxYteKOListado 101 package main
02
03 type user struct {
04 name string
05 email string
06 }
07
08 func main() {
09 u1 := createUserV1()
10 u2 := createUserV2()
11
12 println("u1", &u1, "u2", &u2)
13 }
14
15
16 func createUserV1() user {
17 u := user{
18 name: "Bill",
19 email: "bill@ardanlabs.com",
20 }
21
22 println("V1", &u)
23 return u
24 }
25
26
27 func createUserV2() *user {
28 u := user{
29 name: "Bill",
30 email: "bill@ardanlabs.com",
31 }
32
33 println("V2", &u)
34 return &u
35 }
Uso la directiva go: noinline para que el compilador no incruste código para estas funciones directamente en main. La incrustación eliminará las llamadas a funciones y complicará este ejemplo. Hablaré sobre los efectos secundarios de incrustar en la próxima publicación.El Listado 1 muestra un programa con dos funciones diferentes que crean un valor de tipo usuario y lo devuelven a la persona que llama. La primera versión de la función usa la semántica del valor cuando regresa.Listado 216 func createUserV1() user {
17 u := user{
18 name: "Bill",
19 email: "bill@ardanlabs.com",
20 }
21
22 println("V1", &u)
23 return u
24 }
Dije que la función usa la semántica de los valores cuando regresa, porque un valor de tipo usuario creado por esta función se copia y se pasa a la pila de llamadas. Esto significa que la función de llamada recibe una copia del valor en sí.Puede ver la creación de un valor de tipo usuario, ejecutado en las líneas 17 a 20. Luego, en la línea 23, se pasa una copia del valor a la pila de llamadas y se devuelve al llamante. Después de devolver la función, la pila tiene el siguiente aspecto.Imagen 1 En la Figura 1, puede ver que existe un valor de tipo usuario en ambos marcos después de llamar a createUserV1. En la segunda versión de la función, la semántica del puntero se usa para regresar.Listado 3
En la Figura 1, puede ver que existe un valor de tipo usuario en ambos marcos después de llamar a createUserV1. En la segunda versión de la función, la semántica del puntero se usa para regresar.Listado 327 func createUserV2() *user {
28 u := user{
29 name: "Bill",
30 email: "bill@ardanlabs.com",
31 }
32
33 println("V2", &u)
34 return &u
35 }
Dije que una función usa semántica de puntero cuando regresa, porque la pila de llamadas comparte un valor de tipo usuario creado por esta función. Esto significa que la función de llamada recibe una copia de la dirección donde se encuentran los valores.Puede ver el mismo literal estructural que se usa en las líneas 28 a 31 para crear un valor de tipo usuario, pero en la línea 34 el retorno de la función es diferente. En lugar de pasar una copia del valor a la pila de llamadas, se pasa una copia de la dirección del valor. Basado en esto, puede pensar que después de la llamada, la pila se ve así.Imagen 2 Si lo que ve en la Figura 2 realmente está sucediendo, tendrá un problema de integridad. Un puntero apunta a una pila de llamadas a la memoria que ya no es válida. La próxima vez que se llame a la función, la memoria indicada será reformateada y reinicializada.Aquí es donde el análisis de escape comienza a mantener la integridad. En este caso, el compilador determinará que no es seguro crear un valor de tipo usuario dentro del marco de la pila createUserV2, por lo que creará un valor en el montón. Esto sucederá inmediatamente durante la construcción en la línea 28.
Si lo que ve en la Figura 2 realmente está sucediendo, tendrá un problema de integridad. Un puntero apunta a una pila de llamadas a la memoria que ya no es válida. La próxima vez que se llame a la función, la memoria indicada será reformateada y reinicializada.Aquí es donde el análisis de escape comienza a mantener la integridad. En este caso, el compilador determinará que no es seguro crear un valor de tipo usuario dentro del marco de la pila createUserV2, por lo que creará un valor en el montón. Esto sucederá inmediatamente durante la construcción en la línea 28.Legibilidad
Como aprendió en una publicación anterior, una función tiene acceso directo a la memoria dentro de su marco a través del puntero del marco, pero el acceso a la memoria fuera del marco requiere acceso indirecto. Esto significa que el acceso a los valores que caen en el montón también debe hacerse indirectamente a través de un puntero.Recuerde cómo se ve el código createUserV2.Listado 427 func createUserV2() *user {
28 u := user{
29 name: "Bill",
30 email: "bill@ardanlabs.com",
31 }
32
33 println("V2", &u)
34 return &u
35 }
La sintaxis oculta lo que realmente sucede en este código. La variable u declarada en la línea 28 representa un valor de tipo usuario. La construcción en Go no le dice exactamente dónde se almacena el valor en la memoria, por lo que antes de la declaración de retorno en la línea 34 no sabe que el valor se acumulará. Esto significa que aunque u representa un valor de tipo usuario, el acceso a este valor debe ser a través de un puntero.Puede visualizar una pila que se ve así después de una llamada a la función.Imagen 3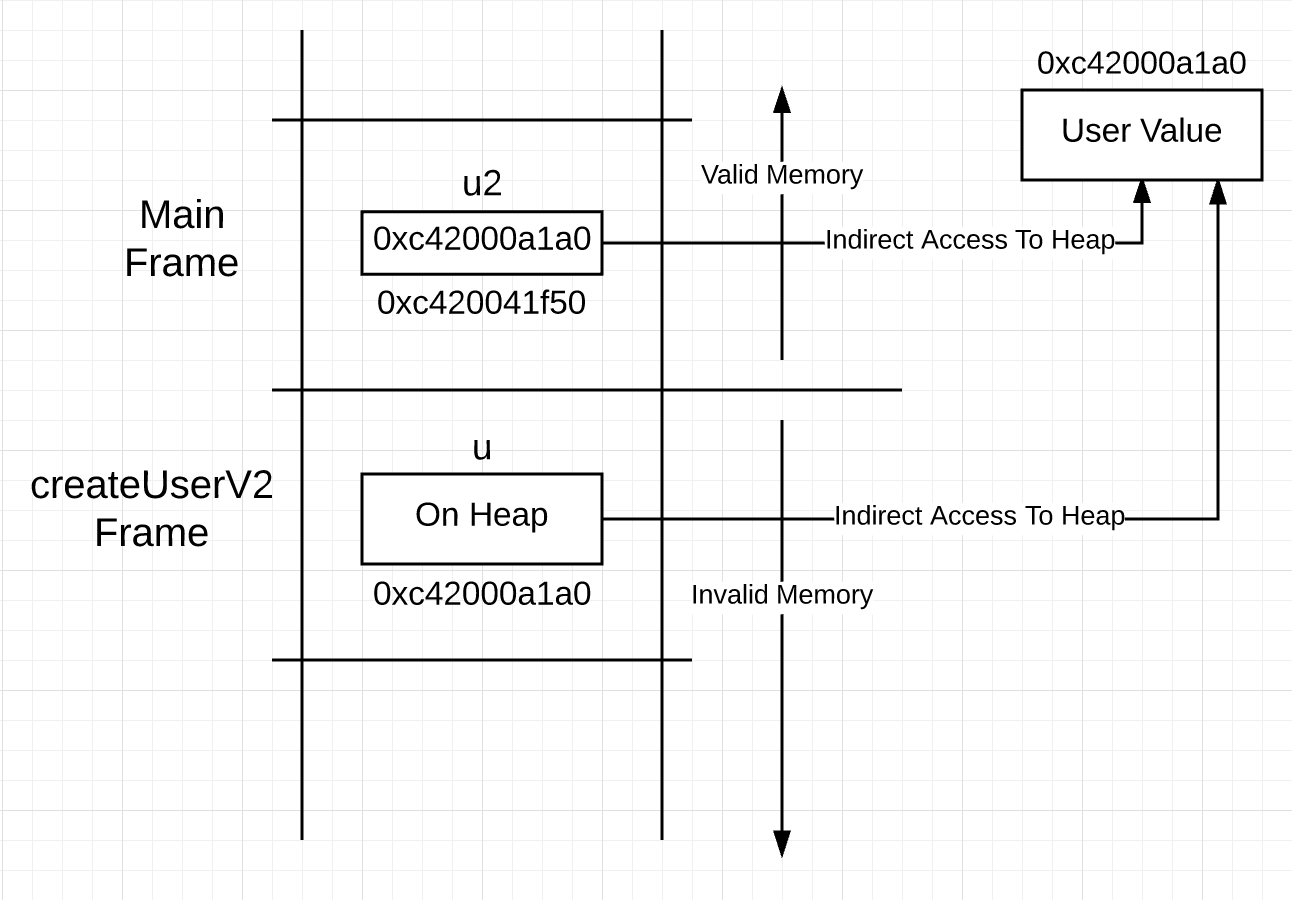 La variable u en el marco de la pila para createUserV2 representa el valor en el montón, no en la pila. Esto significa que usar u para acceder a un valor requiere acceso a un puntero, no el acceso directo sugerido por la sintaxis. Puede pensar, ¿por qué no hacer un puntero inmediatamente, ya que para acceder al valor que representa todavía se requiere el uso de un puntero?Listado 5
La variable u en el marco de la pila para createUserV2 representa el valor en el montón, no en la pila. Esto significa que usar u para acceder a un valor requiere acceso a un puntero, no el acceso directo sugerido por la sintaxis. Puede pensar, ¿por qué no hacer un puntero inmediatamente, ya que para acceder al valor que representa todavía se requiere el uso de un puntero?Listado 527 func createUserV2() *user {
28 u := &user{
29 name: "Bill",
30 email: "bill@ardanlabs.com",
31 }
32
33 println("V2", u)
34 return u
35 }
Si lo hace, perderá legibilidad, que no podría perder en su código. Aléjese del cuerpo de la función por un segundo y concéntrese en el retorno.Listado 634 return u
35 }
¿De qué está hablando este regreso? Todo lo que dice es que una copia de u se inserta en la pila de llamadas. Mientras tanto, ¿qué le dice return cuando usa el operador &?Listado 734 return &u
35 }
Gracias al operador & return, ahora le dice que está compartiendo la pila de llamadas y, por lo tanto, sale al montón. Recuerde que los punteros están destinados a usarse juntos y, mientras leen el código, reemplazan el operador & con la frase "compartir". Es muy poderoso en términos de legibilidad. Esto es algo que no me gustaría perder.Aquí hay otro ejemplo donde la construcción de valores usando semántica de puntero degrada la legibilidad.Listado 801 var u *user
02 err := json.Unmarshal([]byte(r), &u)
03 return u, err
Para que este código funcione, cuando llame a json.Unmarshal en la línea 02, debe pasar un puntero a una variable de puntero. Una llamada json.Unmarshal creará un valor de tipo usuario y asignará su dirección a una variable de puntero. play.golang.org/p/koI8EjpeIxLo que dice este código:01: Cree un puntero de tipo usuario con un valor nulo.02: Comparte la variable u con json. Función Unmarshal.03: Devuelva una copia de la variable u a la persona que llama.No es del todo obvio que un valor de tipo usuario creado por la función json.Unmarshal se pasa al llamador.¿Cómo cambia la legibilidad cuando se usa la semántica de valores durante la declaración de variables?Listado 901 var u user
02 err := json.Unmarshal([]byte(r), &u)
03 return &u, err
Lo que dice este código:01: Cree un valor de tipo usuario con un valor nulo.02: Comparte la variable u con json. Función Unmarshal.03: Comparta la variable u con la persona que llama.Todo esta muy claro. La línea 02 divide el valor de tipo de usuario en la pila de llamadas en json.Unmarshal, y la línea 03 divide el valor de la pila de llamadas de nuevo al llamante. Este recurso compartido hará que el valor se mueva al montón.Utilice la semántica de los valores al crear valores y aproveche la legibilidad del operador & para aclarar cómo se separan los valores.Informes del compilador
Para ver las decisiones tomadas por el compilador, puede pedirle que proporcione un informe. Todo lo que tiene que hacer es usar el modificador -gcflags con la opción -m cuando llame a go build.De hecho, puede usar 4 niveles de -m, pero después de 2 niveles de información se vuelve demasiado. Usaré 2 niveles -m.Listado 10$ go build -gcflags "-m -m"
./main.go:16: cannot inline createUserV1: marked go:noinline
./main.go:27: cannot inline createUserV2: marked go:noinline
./main.go:8: cannot inline main: non-leaf function
./main.go:22: createUserV1 &u does not escape
./main.go:34: &u escapes to heap
./main.go:34: from ~r0 (return) at ./main.go:34
./main.go:31: moved to heap: u
./main.go:33: createUserV2 &u does not escape
./main.go:12: main &u1 does not escape
./main.go:12: main &u2 does not escape
Puede ver que el compilador informa decisiones para volcar el valor en el montón. ¿Qué dice el compilador? Primero, mire nuevamente las funciones createUserV1 y createUserV2 para actualizarlas en la memoria.Listado 1316 func createUserV1() user {
17 u := user{
18 name: "Bill",
19 email: "bill@ardanlabs.com",
20 }
21
22 println("V1", &u)
23 return u
24 }
27 func createUserV2() *user {
28 u := user{
29 name: "Bill",
30 email: "bill@ardanlabs.com",
31 }
32
33 println("V2", &u)
34 return &u
35 }
Comencemos con esta línea en el informe.Listado 14./main.go:22: createUserV1 &u does not escape
Esto sugiere que la llamada a la función println dentro de la función createUserV1 no hace que el tipo de usuario sea volcado en el montón. Este caso tuvo que verificarse porque se usa junto con la función println.Luego, mire estas líneas en el informe.Listado 15./main.go:34: &u escapes to heap
./main.go:34: from ~r0 (return) at ./main.go:34
./main.go:31: moved to heap: u
./main.go:33: createUserV2 &u does not escape
Estas líneas dicen que el valor del tipo de usuario asociado con la variable u, que tiene el tipo de usuario nombrado y se crea en la línea 31, se vierte en el montón debido al retorno en la línea 34. La última línea dice lo mismo que antes, println call en la línea 33 no restablece el tipo de usuario.La lectura de estos informes puede ser confusa y puede variar ligeramente dependiendo de si el tipo de la variable en cuestión se basa en un tipo con nombre o literal.Modifique la variable u para que sea el usuario de tipo literal * en lugar del usuario de tipo con nombre, como era antes.Listado 1627 func createUserV2() *user {
28 u := &user{
29 name: "Bill",
30 email: "bill@ardanlabs.com",
31 }
32
33 println("V2", u)
34 return u
35 }
Ejecute el informe nuevamente.Listado 17./main.go:30: &user literal escapes to heap
./main.go:30: from u (assigned) at ./main.go:28
./main.go:30: from ~r0 (return) at ./main.go:34
Ahora el informe dice que el valor del tipo de usuario al que hace referencia la variable u, que tiene el tipo literal * usuario y se creó en la línea 28, se volca en el montón debido al retorno en la línea 34.Conclusión
Crear un valor no determina dónde está ubicado. Solo cómo se divide el valor determinará qué hará el compilador con este valor. Cada vez que comparte un valor en la pila de llamadas, se descarga en el montón. Hay otras razones por las cuales un valor puede escapar de la pila. Hablaré de ellos en la próxima publicación.El propósito de estas publicaciones es proporcionar una guía para elegir usar semántica de valor o semántica de puntero para cualquier tipo dado. Cada semántica se combina con ganancias y valor. La semántica de los valores almacena los valores en la pila, lo que reduce la carga en el GC. Sin embargo, hay diferentes copias del mismo valor que deben almacenarse, rastrearse y mantenerse. La semántica de puntero pone los valores en un montón, lo que puede ejercer presión sobre el GC. Sin embargo, son efectivos porque solo hay un valor que debe almacenarse, rastrearse y mantenerse. El punto clave es el uso de cada semántica de manera correcta, consistente y equilibrada.