Hola a todos. Antes del comienzo del curso de Python Neural Networks, hemos preparado para usted una traducción de otro material interesante.
Nos complace presentar PyCaret , una biblioteca de aprendizaje automático de Python de código abierto para aprender y desplegar modelos con y sin un maestro en un entorno de código bajo. PyCaret le permite pasar de la preparación de datos a la implementación del modelo en unos pocos segundos en el entorno de notebook que elija.En comparación con otras bibliotecas de aprendizaje automático abiertas, PyCaret es una alternativa de bajo código que puede reemplazar cientos de líneas de código con solo unas pocas palabras. La velocidad de los experimentos más eficientes aumentará exponencialmente. PyCaret es esencialmente un shell de Python sobre varias bibliotecas de aprendizaje automático como scikit-learn , XGBoost , Microsoft LightGBM , spaCyy muchos otros.PyCaret es simple y fácil de usar. Todas las operaciones realizadas por PyCaret se almacenan secuencialmente en una tubería totalmente lista para su implementación. Ya sea que esté agregando valores faltantes, convirtiendo datos categóricos, características de ingeniería u optimizando hiperparámetros, PyCaret puede automatizar todo esto. Para aprender un poco más sobre PyCaret, mira este breve video .Comenzando con PyCaret
La primera versión estable de PyCaret versión 1.0.0 se puede instalar usando pip. Use la interfaz de línea de comandos o el entorno del cuaderno y ejecute el siguiente comando para instalar PyCaret.pip install pycaret
Si usa Azure Notebooks o Google Colab , ejecute el siguiente comando:!pip install pycaret
Cuando instala PyCaret, todas las dependencias se instalarán automáticamente. Puede ver la lista de dependencias aquí .No podría ser más fácil
Tutorial
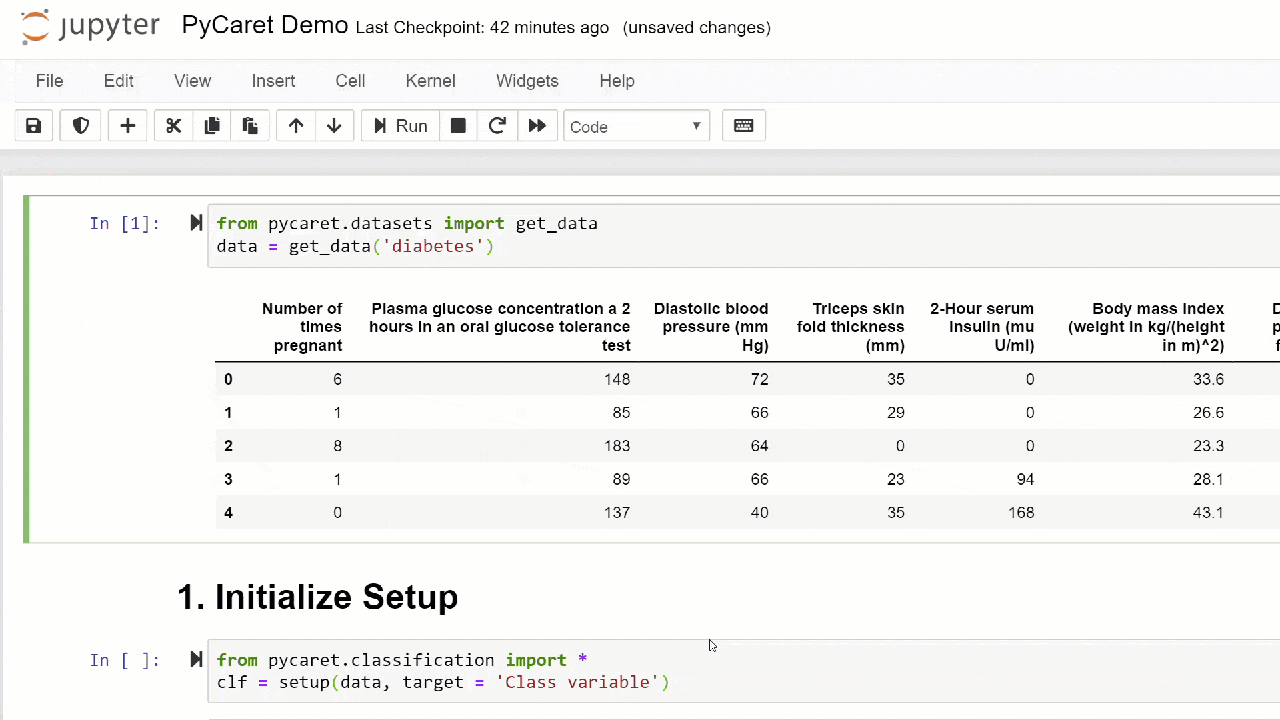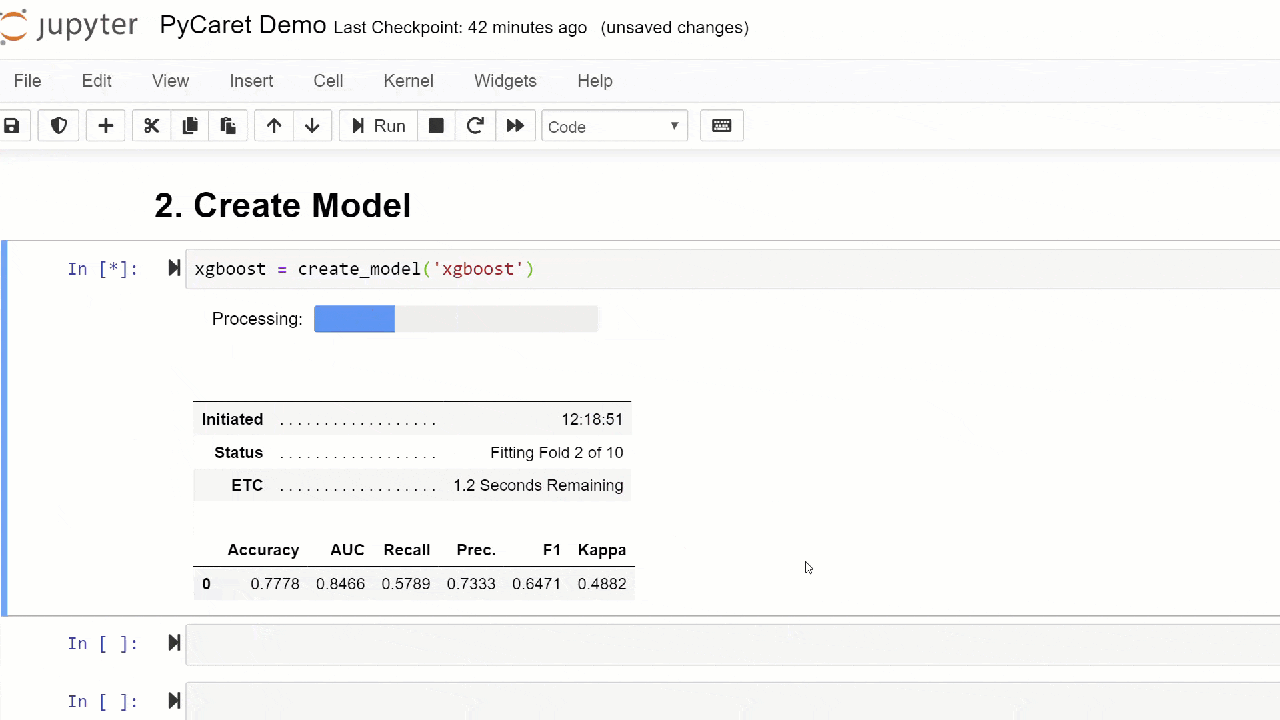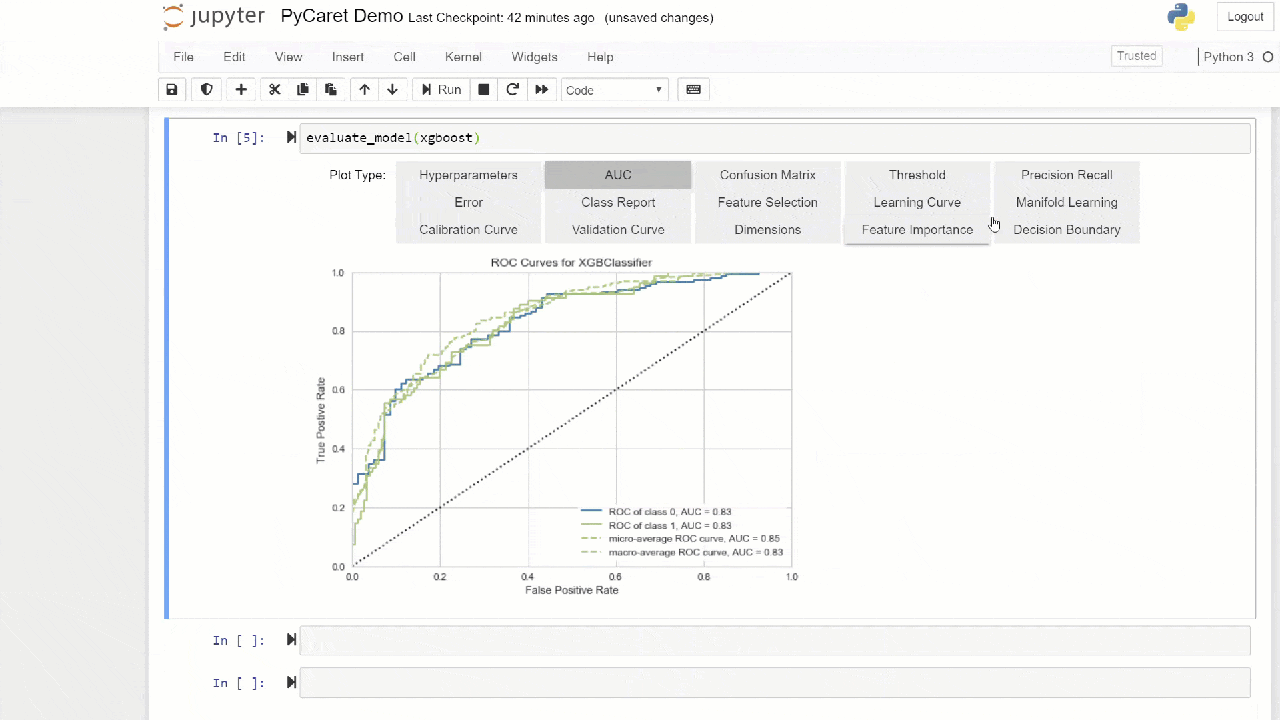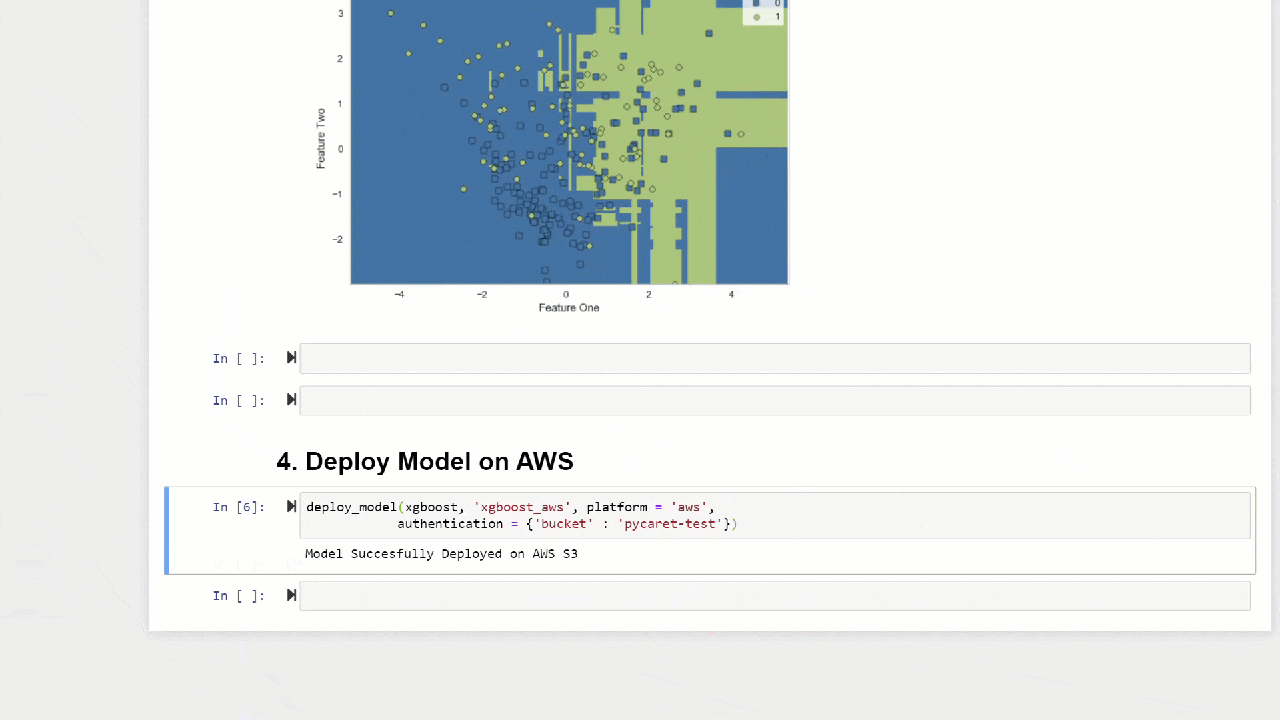
1. Adquisición de datosEn este tutorial, utilizaremos un conjunto de datos para diabéticos, nuestro objetivo es predecir el resultado del paciente (binario 0 o 1) en función de varios factores, como la presión, el nivel de insulina en la sangre, la edad, etc. . Este conjunto de datos está disponible en el repositorio PyCaret GitHub . La forma más fácil de importar el conjunto de datos directamente desde el repositorio es usar la función get_datade los módulos pycaret.datasets.from pycaret.datasets import get_data
diabetes = get_data('diabetes')
 PyCaret puede trabajar directamente con marcos de datos de pandas2. Configuración del entornoCualquier experimento de aprendizaje automático en PyCaret comienza con la configuración del entorno mediante la importación del módulo necesario y la inicialización
PyCaret puede trabajar directamente con marcos de datos de pandas2. Configuración del entornoCualquier experimento de aprendizaje automático en PyCaret comienza con la configuración del entorno mediante la importación del módulo necesario y la inicialización setup(). El módulo que se utilizará en este ejemplo es pycaret.classification .Después de importar el módulo, se setup()inicializa definiendo un marco de datos ( 'diabetes' ) y una variable objetivo ( 'variable de clase' ).from pycaret.classification import *
exp1 = setup(diabetes, target = 'Class variable')
 Todo el preprocesamiento tiene lugar en
Todo el preprocesamiento tiene lugar en setup(). Utilizando más de 20 funciones para preparar los datos antes del aprendizaje automático, PyCaret crea una tubería de transformaciones basadas en los parámetros definidos en la función setup(). Construye automáticamente todas las dependencias en la tubería, por lo que no necesita controlar manualmente la ejecución secuencial de transformaciones en una prueba o un nuevo conjunto de datos (invisible).La tubería de PyCaret puede transferirse fácilmente de un entorno a otro o implementarse en producción. A continuación, puede familiarizarse con las funciones de preprocesamiento que han estado disponibles en PyCaret desde el primer lanzamiento.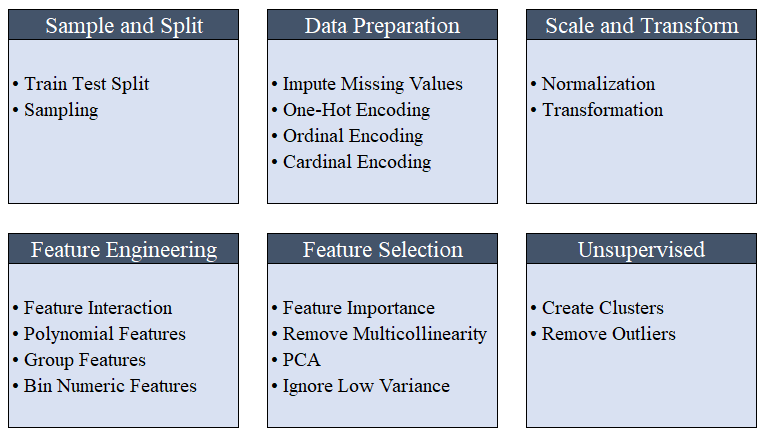 Los pasos de preprocesamiento de datos son obligatorios para el aprendizaje automático, como agregar valores faltantes, codificar variables de calidad, codificar etiquetas (sí o no a 1 o 0) y dividir prueba de tren, se realizan automáticamente durante la inicialización
Los pasos de preprocesamiento de datos son obligatorios para el aprendizaje automático, como agregar valores faltantes, codificar variables de calidad, codificar etiquetas (sí o no a 1 o 0) y dividir prueba de tren, se realizan automáticamente durante la inicialización setup(). Puede obtener más información sobre las funciones de preprocesamiento en PyCaret aquí .3. Comparación de modelosEste es el primer paso que se recomienda realizar cuando se trabaja con capacitación de maestros ( clasificación o regresión ). Esta función entrena a todos los modelos en la biblioteca de modelos y compara el indicador estimado entre sí mediante validación cruzada para bloques K (10 bloques por defecto). Los indicadores estimados se utilizan de la siguiente manera:- Para clasificación: Precisión, AUC, Retirada, Precisión, F1, Kappa
- Para regresión: MAE, MSE, RMSE, R2, RMSLE, MAPE
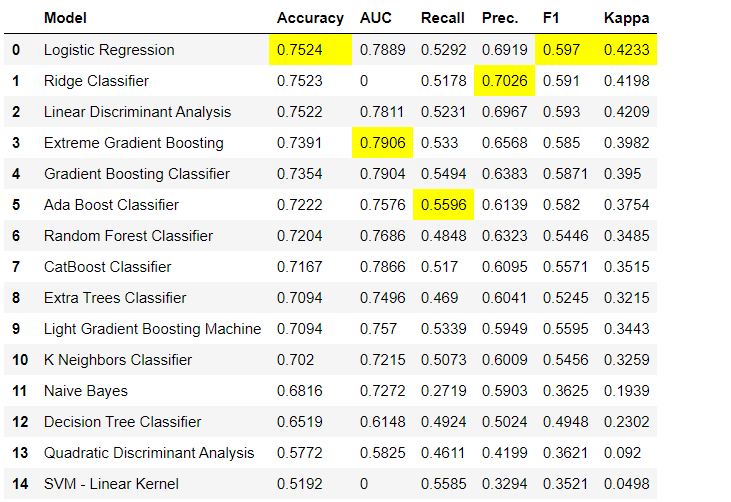 Por defecto, las métricas se evalúan mediante validación cruzada en 10 bloques. El número de bloques se puede cambiar cambiando el valor del parámetro
Por defecto, las métricas se evalúan mediante validación cruzada en 10 bloques. El número de bloques se puede cambiar cambiando el valor del parámetro fold.La tabla predeterminada se ordena por "Precisión" del valor más alto al más bajo. Forma de ordenación también se puede cambiar usando la opción sort.4. Crear un modeloCrear un modelo en cualquier módulo PyCaret es tan simple que solo necesita escribirlo create_model. La función toma un parámetro en la entrada, es decir nombre del modelo pasado como una cadena. Esta función devuelve una tabla con puntajes con validación cruzada y un objeto modelo entrenado.adaboost = create_model('ada')
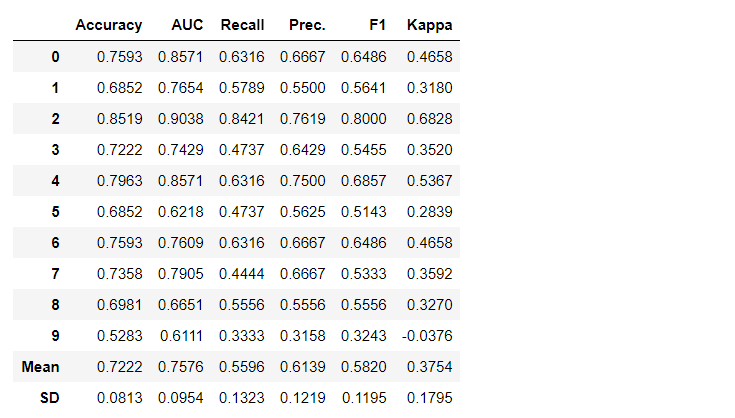 La variable "adaboost" almacena el objeto del modelo entrenado, que devuelve una función
La variable "adaboost" almacena el objeto del modelo entrenado, que devuelve una función create_modelque, bajo el capó, es un evaluador scikit-learn. El acceso a los atributos de origen del objeto entrenado se puede obtener utilizando la función period ( . )después de la variable. Puede encontrar un ejemplo de uso a continuación. PyCaret tiene más de 60 algoritmos de código abierto listos para usar. Puede encontrar una lista completa de evaluadores / modelos disponibles en PyCaret aquí .5. Configuración del modeloLa función se
PyCaret tiene más de 60 algoritmos de código abierto listos para usar. Puede encontrar una lista completa de evaluadores / modelos disponibles en PyCaret aquí .5. Configuración del modeloLa función se tune_modelutiliza para configurar automáticamente los hiperparámetros del modelo de aprendizaje automático. PyCaret utilizarandom grid searchen un espacio de búsqueda específico La función devuelve una tabla con estimaciones con validación cruzada y un objeto de un modelo entrenado.tuned_adaboost = tune_model('ada')
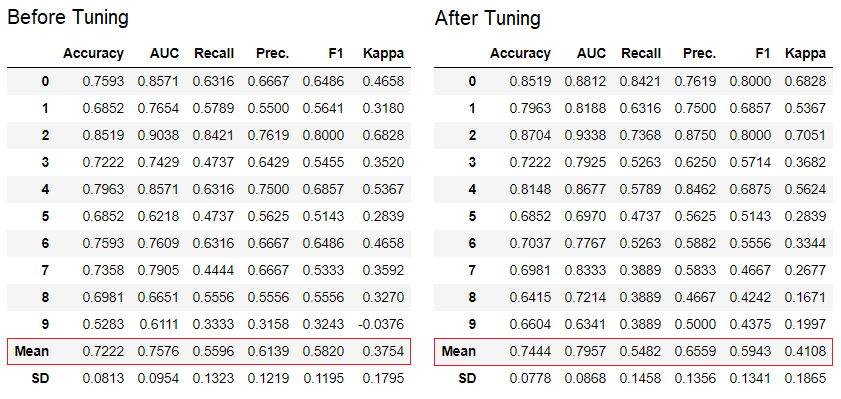 La función
La función tune_modelen módulos de aprendizaje no docentes como pycaret.nlp , pycaret.clustering y pycaret.anomaly se puede usar junto con los módulos de aprendizaje docente. Por ejemplo, el módulo NLP en PyCaret se puede usar para ajustar un parámetro number of topicsevaluando una función objetivo o función de pérdida de un modelo con un maestro, como "Precisión" o "R2".6. Conjunto de modelosLa función se ensemble_modelutiliza para crear un conjunto de modelos entrenados. En la entrada, se necesita un parámetro: el objeto del modelo entrenado. La función devuelve una tabla con estimaciones con validación cruzada y un objeto de un modelo entrenado.
dt = create_model('dt')
dt_bagged = ensemble_model(dt)
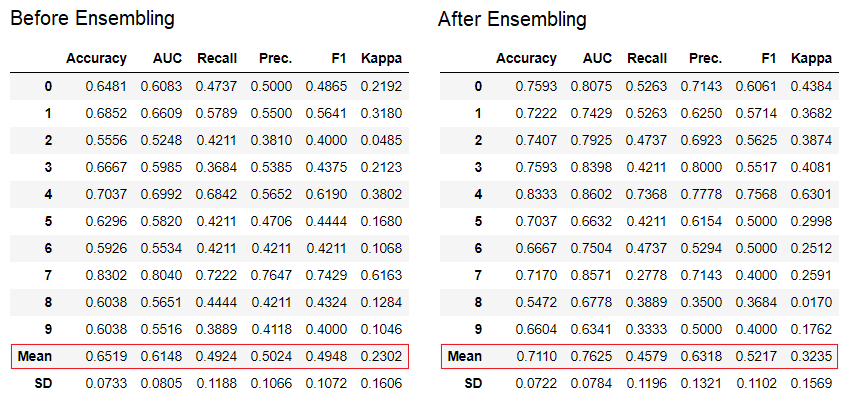 El método de "ensacado" se usa cuando se crea el conjunto por defecto, se puede cambiar a "refuerzo" usando el parámetro
El método de "ensacado" se usa cuando se crea el conjunto por defecto, se puede cambiar a "refuerzo" usando el parámetro methoden la función ensemble_model.PyCaret también proporciona funciones blend_modelsy modelos de pila para combinar varios modelos entrenados.7. Visualización del modelo: puede evaluar el rendimiento y diagnosticar un modelo de aprendizaje automático capacitado utilizando la función plot_model. Toma el objeto del modelo entrenado y el tipo de gráfico en forma de cadena.
adaboost = create_model('ada')
plot_model(adaboost, plot = 'auc')
plot_model(adaboost, plot = 'boundary')
plot_model(adaboost, plot = 'pr')
plot_model(adaboost, plot = 'vc')
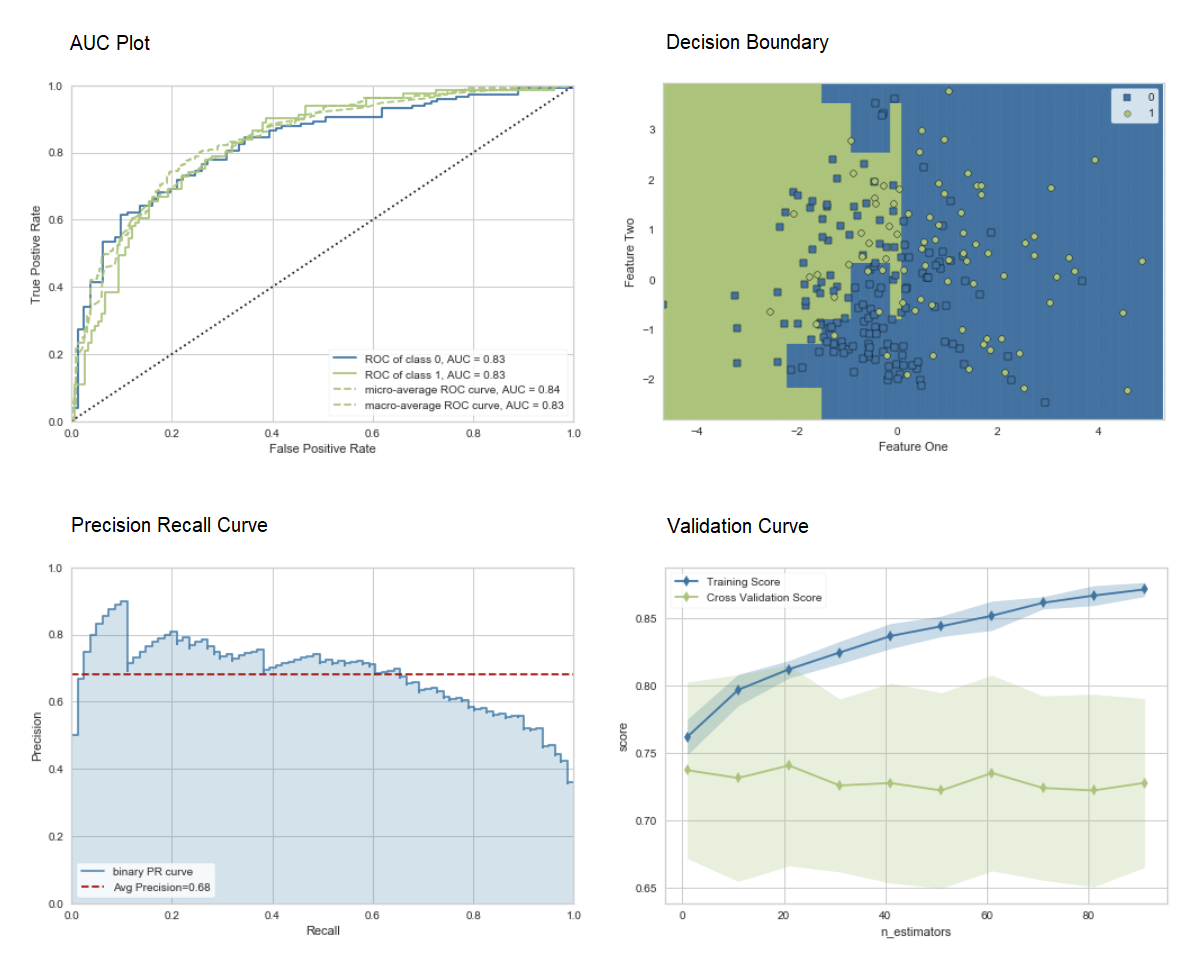 Aquí puede obtener más información sobre la visualización en PyCaret.También puede usar la función
Aquí puede obtener más información sobre la visualización en PyCaret.También puede usar la función evaluate_modelpara ver gráficos usando la interfaz de usuario de la notebook. La función
La función plot_modelen el módulo pycaret.nlpse puede utilizar para visualizar el cuerpo de textos y modelos temáticos semánticos. Aquí puedes aprender más sobre ellos.8. Interpretación del modeloCuando los datos no son lineales, lo que sucede con frecuencia en la vida real, invariablemente vemos que los modelos en forma de árbol funcionan mucho mejor que los modelos gaussianos simples. Sin embargo, esto se debe a una pérdida de interpretabilidad, ya que los modelos de árbol no proporcionan coeficientes simples, como los modelos lineales. PyCaret implementa SHAP (Explicaciones de aditivo SHapley ) usando una función interpret_model.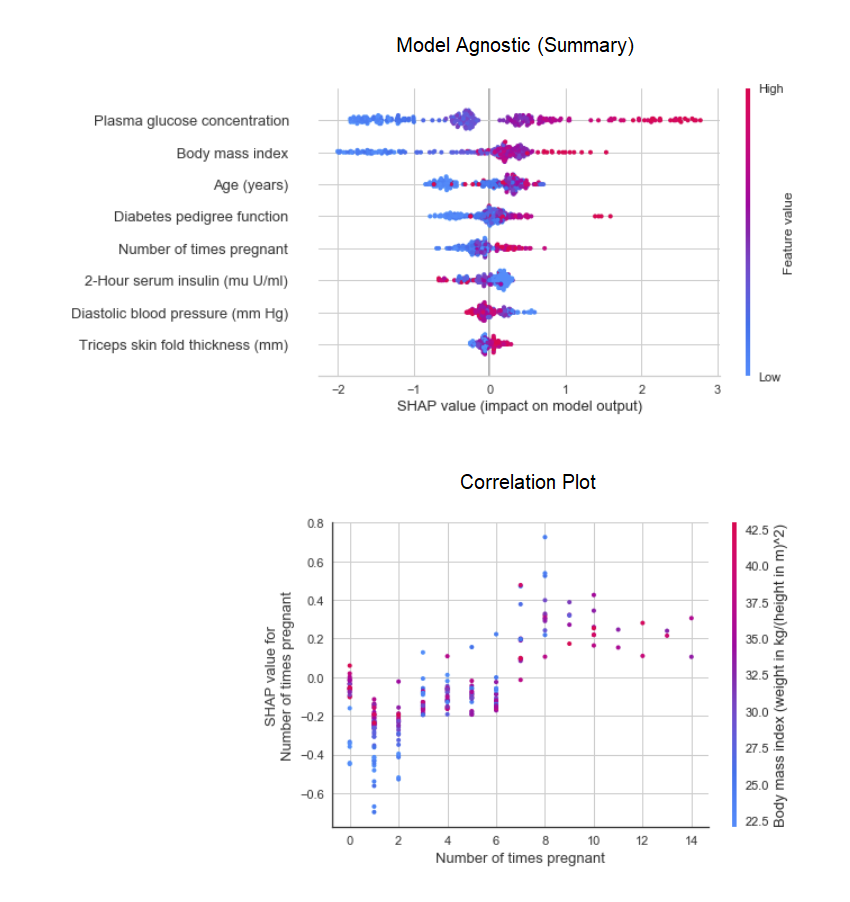 La interpretación de un punto de datos particular en un conjunto de datos de prueba se puede estimar utilizando el gráfico de "razón". En el siguiente ejemplo, probamos la primera instancia en el conjunto de datos de prueba.
La interpretación de un punto de datos particular en un conjunto de datos de prueba se puede estimar utilizando el gráfico de "razón". En el siguiente ejemplo, probamos la primera instancia en el conjunto de datos de prueba. 9. Modelo predictivoHasta este punto, los resultados que obtuvimos se basaron en la validación cruzada por bloques K en un conjunto de datos de entrenamiento (70% por defecto). Para ver los pronósticos y el rendimiento del modelo en el conjunto de datos de prueba / espera, se utiliza una función
9. Modelo predictivoHasta este punto, los resultados que obtuvimos se basaron en la validación cruzada por bloques K en un conjunto de datos de entrenamiento (70% por defecto). Para ver los pronósticos y el rendimiento del modelo en el conjunto de datos de prueba / espera, se utiliza una función predict_model.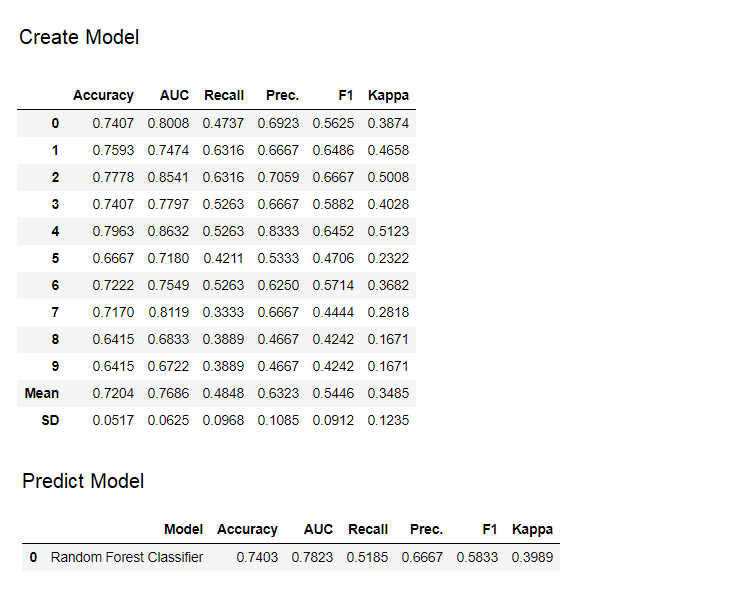 La función se
La función se predict_modelusa para pronosticar un conjunto de datos invisible. Ahora usaremos el mismo conjunto de datos que usamos para el entrenamiento, como un proxy para el nuevo conjunto de datos invisible. En la práctica, la funciónpredict_modelse utilizará de forma iterativa, cada vez en un nuevo conjunto de datos invisible. La función
La función predict_modeltambién puede hacer predicciones para una cadena secuencial de modelos que se pueden crear utilizando las funciones stack_models y create_stacknet .La función predict_modeltambién puede hacer predicciones directamente para los modelos alojados en AWS S3 utilizando la función deploy_model .10. Implementación de un modeloUna de las formas de usar modelos entrenados para crear pronósticos para un nuevo conjunto de datos es usar la funciónpredict_modelen el mismo cuaderno / IDE donde se formó el modelo. Sin embargo, generar un pronóstico para un nuevo conjunto de datos (invisible) es un proceso iterativo. Dependiendo del caso de uso, la frecuencia de los pronósticos puede variar desde pronósticos en tiempo real hasta pronósticos por lotes. La función deploy_modelen PyCaret le permite implementar toda la tubería, incluido el modelo entrenado en la nube desde el entorno de la notebook.deploy_model(model = rf, model_name = 'rf_aws', platform = 'aws',
authentication = {'bucket' : 'pycaret-test'})
11. Guarde el modelo / guarde el experimento
Después del entrenamiento, toda la tubería que contiene todas las transformaciones de preprocesamiento y el objeto del modelo entrenado se puede guardar en un archivo binario de pepinillos.
adaboost = create_model('ada')
save_model(adaboost, model_name = 'ada_for_deployment')
 También puede guardar todo el experimento, que contiene toda la salida intermedia, como un solo archivo binario.save_experiment (experiment_name = 'my_first_experiment')
También puede guardar todo el experimento, que contiene toda la salida intermedia, como un solo archivo binario.save_experiment (experiment_name = 'my_first_experiment') Puede cargar modelos y experimentos guardados utilizando las funciones
Puede cargar modelos y experimentos guardados utilizando las funciones load_modely load_experimentdisponibles en todos los módulos de PyCaret.12. Siguiente guíaEn la siguiente guía, mostraremos cómo usar el modelo de aprendizaje automático capacitado en Power BI para generar predicciones por lotes en un entorno de producción real.También puede leer blocs de notas para principiantes en los siguientes módulos:¿Qué es una tubería de desarrollo?
Estamos trabajando activamente para mejorar PyCaret. Nuestra próxima línea de desarrollo incluye un nuevo módulo de pronóstico de series temporales, integración de TensorFlow y mejoras importantes de escalabilidad de PyCaret. Si desea compartir sus comentarios y ayudarnos a mejorar, puede completar un formulario en el sitio o dejar un comentario en nuestra página en GitHub o LinkedIn .¿Quieres saber más sobre un módulo en particular?
A partir de la primera versión, PyCaret 1.0.0 tiene los siguientes módulos disponibles para su uso. Siga los enlaces a continuación para familiarizarse con la documentación y ejemplos de trabajo.ClasificaciónRegresiónAgrupación deanomalías BúsquedaProcesamiento de texto natural (PNL)Reglas asociativas CapacitaciónLinks importantes
Si te gustó PyCaret, ponnos ️ en GitHub.Para saber más sobre PyCaret, puede seguirnos en LinkedIn y Youtube .
Aprende más sobre el curso.