La traducción del artículo fue preparada especialmente para los estudiantes del curso "Bases de datos" .
Lo que quizás no haya sabido sobre la generación de números aleatorios de SysbenchSysbench es una herramienta de prueba de rendimiento popular. Originalmente fue escrito por Peter Zaitsev a principios de la década de 2000 y se convirtió en el estándar de facto para pruebas y evaluación comparativa. Actualmente es compatible con Alexei Kopytov y está publicado en Github en .Sin embargo, noté que, a pesar de su amplia distribución, hay momentos desconocidos para muchos en sysbench. Por ejemplo, la capacidad de modificar fácilmente las pruebas de MySQL usando Lua o configurar los parámetros del generador de números aleatorios incorporado.¿De qué se trata este artículo?
Escribí este artículo para mostrar lo fácil que es personalizar sysbench según sus requisitos. Hay muchas formas de ampliar la funcionalidad de sysbench, y una de ellas es configurar la generación de identificadores aleatorios (ID).Por defecto, sysbench viene con cinco opciones diferentes para generar números aleatorios. Pero muy a menudo (de hecho, casi nunca), ninguno de ellos se indica explícitamente, y aún menos a menudo se pueden ver los parámetros de generación (para las opciones donde están disponibles).Si tiene una pregunta: “¿Y por qué debería interesarme esto? Después de todo, los valores predeterminados son bastante adecuados ", entonces esta publicación está diseñada para ayudarlo a comprender por qué no siempre es así.Empecemos
¿Cuáles son las formas de generar números aleatorios en sysbench? Actualmente se implementan los siguientes (puede verlos fácilmente a través de la opción --help):- Especial (distribución especial)
- Gaussiano (distribución gaussiana)
- Pareto (distribución de Pareto)
- Zipfian (distribución Zipf)
- Uniforme (distribución uniforme)
Por defecto, Special se usa con los siguientes parámetros:rand-spec-iter = 12 - número de iteraciones para una distribución especialrand-spec-pct = 1 - porcentaje del rango completo en el que los valores "especiales" caen con una distribución especialrand-spec-res = 75 - porcentaje de valores "especiales" para su uso en una distribución especial
Como me gustan las pruebas y los scripts simples y fáciles de reproducir, todos los datos posteriores se recopilarán utilizando los siguientes comandos de sysbench:- sysbench ./src/lua/oltp_read.lua -mysql_storage_engine = innodb –db-driver = mysql –tables = 10 –table_size = 100 prepare
- sysbench ./src/lua/oltp_read_write.lua –db-driver=mysql –tables=10 –table_size=100 –skip_trx=off –report-interval=1 –mysql-ignore-errors=all –mysql_storage_engine=innodb –auto_inc=on –histogram –stats_format=csv –db-ps-mode=disable –threads=10 –time=60 –rand-type=XXX run
Siéntase libre de experimentar usted mismo. La descripción del script y los datos se pueden encontrar aquí .¿Por qué sysbench usa un generador de números aleatorios? Uno de los propósitos es generar ID que se utilizarán en las consultas. Entonces, en nuestro ejemplo, se generarán números entre 1 y 100, teniendo en cuenta la creación de 10 tablas con 100 filas en cada una.¿Qué sucede si ejecuta sysbench como se describe anteriormente y cambia solo -y-type?Ejecuté este script y utilicé el registro general para recopilar y analizar la frecuencia de los valores de ID generados. Aquí está el resultado: Uniformeespecial Zipfian Pareto Gaussian
Se puede ver que este parámetro es importante, ¿verdad? Después de todo, sysbench hace exactamente lo que esperábamos de él.



 Echemos un vistazo más de cerca a cada una de las distribuciones.
Echemos un vistazo más de cerca a cada una de las distribuciones.Especial
Especial se usa por defecto, por lo que si NO especifica el tipo rand, entonces sysbench usará especial. Special utiliza un número muy limitado de valores de ID. En nuestro ejemplo, podemos ver que los valores 50-51 se usan principalmente, los valores restantes entre 44-56 son extremadamente raros, mientras que otros prácticamente no se usan. Tenga en cuenta que los valores seleccionados están en el medio del rango disponible de 1-100.En este caso, el pico es de aproximadamente dos ID que representan el 2% de la muestra. Si aumento el número de registros a un millón, el pico se mantendrá, pero estará en 7493, que es el 0,74% de la muestra. Como esto será más restrictivo, es probable que el número de páginas sea más de una.Uniforme (distribución uniforme)
Como su nombre lo indica, si usamos Uniform, todos los valores se usarán para la ID y la distribución será ... uniforme.Zipfian (distribución Zipf)
La distribución Zipf, a veces llamada distribución zeta, es una distribución discreta comúnmente utilizada en lingüística, seguros y modelos de eventos raros. En este caso, sysbench usará números que comienzan con el más pequeño (1) y reducirá muy rápidamente la frecuencia de uso, pasando a números más grandes.Pareto (Pareto)
Pareto aplica la regla "80-20" . En este caso, las ID generadas se untarán aún menos y se concentrarán más en un segmento pequeño. En nuestro ejemplo, el 52% de todas las ID tenía un valor de 1, y el 73% de los valores estaban en los primeros 10 números.Gaussiano (distribución gaussiana)
La distribución gaussiana (distribución normal) es bien conocida y familiar . Se utiliza principalmente en estadísticas y pronósticos en torno a un factor central. En este caso, los ID utilizados se distribuyen a lo largo de la curva en forma de campana, comenzando con el valor promedio y disminuyendo lentamente hasta los bordes.¿Cuál es el punto de esto?
Cada una de las opciones anteriores tiene su propio uso y se puede agrupar por propósito. Pareto y enfoque especial en puntos calientes. En este caso, la aplicación usa la misma página / datos una y otra vez. Esto puede ser lo que necesitamos, pero debemos entender lo que estamos haciendo y no cometer errores aquí.Por ejemplo, si probamos el rendimiento de la compresión de la página InnoDB mientras leemos, deberíamos evitar usar el valor predeterminado de Special o Pareto. Si tenemos un conjunto de datos de 1 TB y una agrupación de almacenamiento intermedio de 30 GB, y solicitamos la misma página muchas veces, esta página ya se leerá desde el disco y estará disponible sin comprimir en la memoria.En resumen, tal prueba es una pérdida de tiempo y esfuerzo.Lo mismo si necesitamos verificar el rendimiento de la grabación. Escribir la misma página una y otra vez no es la mejor opción.¿Qué hay de las pruebas de rendimiento?Nuevamente, queremos probar el rendimiento, pero ¿para qué caso? Es importante comprender que el método de generar números aleatorios afecta en gran medida los resultados de la prueba. Y sus "valores predeterminados suficientemente buenos" pueden llevar a conclusiones erróneas.Los siguientes gráficos muestran diferentes latencias según el tipo de rand (el tipo de prueba, el tiempo, los parámetros adicionales y el número de subprocesos son los mismos en todas partes).De un tipo a otro, los retrasos son significativamente diferentes: aquí estaba leyendo y escribiendo, y los datos se tomaron del Esquema de rendimiento (
aquí estaba leyendo y escribiendo, y los datos se tomaron del Esquema de rendimiento (sys.schema_table_statistics) Como se esperaba, Pareto y Special tardan mucho más que otros, lo que hace que el sistema (MySQL-InnoDB) sufra artificialmente de competencia en un "punto caliente".Cambiar el tipo de rand afecta no solo el retraso, sino también el número de filas procesadas, como lo indica el esquema de rendimiento.
 Dado todo lo anterior, es importante comprender lo que estamos tratando de evaluar y probar.Si mi objetivo es probar el rendimiento del sistema en todos los niveles, preferiría usar Uniform, que cargará igualmente el conjunto de datos / servidor de base de datos / sistema y es más probable que distribuya lectura / carga / escritura de manera uniforme.Si mi trabajo es trabajar con puntos calientes, entonces Pareto y Special son probablemente la opción correcta.Pero no use los valores predeterminados a ciegas. Pueden ser adecuados para usted, pero a menudo están destinados a casos extremos. En mi experiencia, a menudo puede ajustar la configuración para obtener el resultado que necesita.Por ejemplo, desea utilizar los valores en el medio ampliando el intervalo para que no haya un pico agudo (especial por defecto) o campana (gaussiano).Puede configurar Especial para obtener algo como esto:
Dado todo lo anterior, es importante comprender lo que estamos tratando de evaluar y probar.Si mi objetivo es probar el rendimiento del sistema en todos los niveles, preferiría usar Uniform, que cargará igualmente el conjunto de datos / servidor de base de datos / sistema y es más probable que distribuya lectura / carga / escritura de manera uniforme.Si mi trabajo es trabajar con puntos calientes, entonces Pareto y Special son probablemente la opción correcta.Pero no use los valores predeterminados a ciegas. Pueden ser adecuados para usted, pero a menudo están destinados a casos extremos. En mi experiencia, a menudo puede ajustar la configuración para obtener el resultado que necesita.Por ejemplo, desea utilizar los valores en el medio ampliando el intervalo para que no haya un pico agudo (especial por defecto) o campana (gaussiano).Puede configurar Especial para obtener algo como esto: en este caso, los ID todavía están cerca y hay competencia. Pero la influencia de un "punto caliente" es menor, por lo tanto, los posibles conflictos ahora estarán con varias ID, que, dependiendo del número de registros en una página, pueden estar en varias páginas.Otro ejemplo es la partición. Por ejemplo, ¿cómo verificar cómo funciona su sistema con particiones, centrándose en los datos más recientes y archivando los antiguos?¡Fácil! ¿Recuerdas el cuadro de distribución de Pareto? Puede cambiarlo según sus necesidades.
en este caso, los ID todavía están cerca y hay competencia. Pero la influencia de un "punto caliente" es menor, por lo tanto, los posibles conflictos ahora estarán con varias ID, que, dependiendo del número de registros en una página, pueden estar en varias páginas.Otro ejemplo es la partición. Por ejemplo, ¿cómo verificar cómo funciona su sistema con particiones, centrándose en los datos más recientes y archivando los antiguos?¡Fácil! ¿Recuerdas el cuadro de distribución de Pareto? Puede cambiarlo según sus necesidades. Al especificar el valor -rand-pareto, puede obtener exactamente lo que desea al obligar a sysbench a centrarse en valores de ID grandes.Zipfian también se puede configurar y, aunque no puede obtener una inversión, como es el caso de Pareto, puede cambiar fácilmente de un pico en un valor a una distribución más uniforme. Un buen ejemplo es el siguiente:
Al especificar el valor -rand-pareto, puede obtener exactamente lo que desea al obligar a sysbench a centrarse en valores de ID grandes.Zipfian también se puede configurar y, aunque no puede obtener una inversión, como es el caso de Pareto, puede cambiar fácilmente de un pico en un valor a una distribución más uniforme. Un buen ejemplo es el siguiente: Lo último a tener en cuenta, y me parece que son cosas obvias, pero es mejor decir que no decir que al cambiar los parámetros de generación de números aleatorios, el rendimiento cambiará.Comparar latencia:
Lo último a tener en cuenta, y me parece que son cosas obvias, pero es mejor decir que no decir que al cambiar los parámetros de generación de números aleatorios, el rendimiento cambiará.Comparar latencia: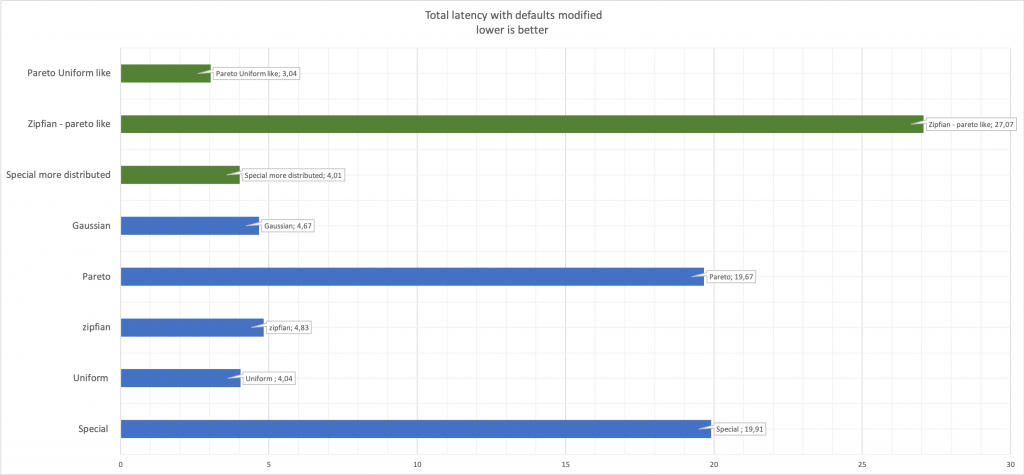 aquí, el verde muestra los valores modificados en comparación con el azul original.
aquí, el verde muestra los valores modificados en comparación con el azul original.
recomendaciones
En este punto, ya debe comprender lo fácil que es configurar la generación de números aleatorios en sysbench y lo útil que puede ser para usted. Tenga en cuenta que lo anterior se aplica a cualquier llamada, por ejemplo, al usar sysbench.rand.default:local function get_id()
return sysbench.rand.default(1, sysbench.opt.table_size)
End
Dado esto, no copie sin pensar el código de los artículos de otras personas, sino piense y profundice en lo que necesita y cómo lograrlo.Antes de ejecutar las pruebas, verifique las opciones de generación de números aleatorios para asegurarse de que sean apropiadas para sus necesidades. Para simplificar mi vida, utilizo esta simple prueba . Esta prueba muestra información de distribución de ID bastante clara.Mi consejo es que debe comprender sus necesidades y realizar pruebas / evaluaciones comparativas correctamente.Referencias
En primer lugar, este es el propio sysbench.Artículos sobre Zipfian:ParetoArtículo de Percona sobre cómo escribir sus scripts en sysbenchTodos los materiales utilizados para este artículo están en GitHub .
→ Aprenda más sobre el curso