Durante los 10 años de existencia de ivi, hemos compilado una base de datos de 90,000 videos de varias longitudes, tamaños y calidad. Cientos de nuevos aparecen cada semana. Tenemos gigabytes de metadatos, que son útiles para recomendaciones, simplificar la navegación del servicio y configurar la publicidad. Pero comenzamos a extraer información directamente del video hace solo dos años.En este artículo, le diré cómo analizamos las películas en elementos estructurales y por qué las necesitamos. Al final, hay un enlace al repositorio de Github con código de algoritmo y ejemplos.
¿En qué consiste un video?
El video clip tiene una estructura jerárquica. Se trata de video digital, por lo que en el nivel más bajo hay píxeles , puntos de colores que forman una imagen fija.Las imágenes fijas se llaman marcos : se reemplazan entre sí y crean el efecto del movimiento. En la instalación, los marcos se cortan en grupos que, según las indicaciones del director, se intercambian y pegan. La secuencia de fotogramas de un ensamblaje pegado a otro en inglés se llama el término disparo. Desafortunadamente, la terminología rusa no tiene éxito, porque en ella estos grupos también se llaman marcos. Para no confundirse, usemos el término en inglés. Simplemente ingrese la versión en ruso: "tiro" .Las tomas se agrupan por significado, se llaman escenas.La escena se caracteriza por la unidad de lugar, tiempo y personajes.Podemos obtener fácilmente cuadros individuales e incluso píxeles de estos cuadros, porque los algoritmos de codificación de video digital están dispuestos de esta manera. Esta información es necesaria para la reproducción.Las fronteras de tomas y escenas son mucho más difíciles de obtener. Las fuentes de los programas de instalación pueden ayudar, pero no están disponibles para nosotros.Afortunadamente, los algoritmos pueden hacer esto, aunque no con una precisión perfecta. Te contaré sobre el algoritmo para dividir en escenas.
En la instalación, los marcos se cortan en grupos que, según las indicaciones del director, se intercambian y pegan. La secuencia de fotogramas de un ensamblaje pegado a otro en inglés se llama el término disparo. Desafortunadamente, la terminología rusa no tiene éxito, porque en ella estos grupos también se llaman marcos. Para no confundirse, usemos el término en inglés. Simplemente ingrese la versión en ruso: "tiro" .Las tomas se agrupan por significado, se llaman escenas.La escena se caracteriza por la unidad de lugar, tiempo y personajes.Podemos obtener fácilmente cuadros individuales e incluso píxeles de estos cuadros, porque los algoritmos de codificación de video digital están dispuestos de esta manera. Esta información es necesaria para la reproducción.Las fronteras de tomas y escenas son mucho más difíciles de obtener. Las fuentes de los programas de instalación pueden ayudar, pero no están disponibles para nosotros.Afortunadamente, los algoritmos pueden hacer esto, aunque no con una precisión perfecta. Te contaré sobre el algoritmo para dividir en escenas.¿Porqué necesitamos esto?
Resolvemos el problema de búsqueda dentro del video y queremos probar automáticamente cada escena de cada película en ivi. Dividir en escenas es una parte importante de esta tubería.Para saber dónde comienzan y terminan las escenas, debe crear trailers sintéticos. Ya tenemos un algoritmo que los genera, pero hasta ahora, la detección de escena no se usa allí.El sistema de recomendación también es útil para dividir en escenas. De ellos, se obtienen signos que describen qué películas les gusta a los usuarios en la estructura.¿Cuáles son los enfoques para resolver el problema?
El problema se resuelve desde dos lados:- Toman todo el video y buscan los límites de las escenas.
- Primero, dividen el video en tomas y luego las combinan en escenas.
Fuimos de la segunda manera, porque es más fácil formalizar, y hay artículos científicos sobre este tema. Ya sabemos cómo dividir el video en tomas. Queda por recoger estos disparos en escenas.Lo primero que quieres probar es la agrupación. Tome las fotos, conviértalas en vectores y luego divida los vectores en grupos clásicos utilizando algoritmos de agrupamiento clásicos. El principal inconveniente de este enfoque: no tiene en cuenta que las tomas y las escenas se suceden. Una toma de otra escena no puede estar entre dos tomas de una escena, y con la agrupación esto es posible.En 2016, Daniel Rothman y sus colegas de IBM propusieron un algoritmo que tiene en cuenta la estructura temporal y formularon la combinación de tomas en escenas como una tarea de Agrupación secuencial óptima:
El principal inconveniente de este enfoque: no tiene en cuenta que las tomas y las escenas se suceden. Una toma de otra escena no puede estar entre dos tomas de una escena, y con la agrupación esto es posible.En 2016, Daniel Rothman y sus colegas de IBM propusieron un algoritmo que tiene en cuenta la estructura temporal y formularon la combinación de tomas en escenas como una tarea de Agrupación secuencial óptima:- dada una secuencia de disparos
- necesita dividirlo en segmentos para que esta separación sea óptima.
¿Qué es la separación óptima?
Por ahora, suponemos que dado, es decir, se conoce el número de escenas. Solo se desconocen sus fronteras.Obviamente, se necesita algún tipo de métrica. Se inventaron tres métricas, se basan en la idea de distancias por pares entre disparos.Los pasos preparatorios son los siguientes:- Convertimos los disparos en vectores (un histograma o salidas de la penúltima capa de una red neuronal)
- Encuentre las distancias por pares entre los vectores (Euclidiana, coseno u otro)
- Obtenemos una matriz cuadrada donde cada elemento es la distancia entre disparos y .
 Esta matriz es simétrica, y en la diagonal principal siempre tendrá ceros, porque la distancia del vector a sí misma es cero.Los cuadrados oscuros se trazan a lo largo de la diagonal, áreas donde los disparos vecinos son similares entre sí, en consecuencia, menos distancia.Si elegimos buenas incrustaciones que reflejan la semántica de los disparos y elegimos una buena función de distancia, entonces estos cuadrados son las escenas. Encuentra los bordes de los cuadrados: encontraremos los bordes de las escenas.Al observar la matriz, los colegas israelíes formularon tres criterios para una partición óptima:
Esta matriz es simétrica, y en la diagonal principal siempre tendrá ceros, porque la distancia del vector a sí misma es cero.Los cuadrados oscuros se trazan a lo largo de la diagonal, áreas donde los disparos vecinos son similares entre sí, en consecuencia, menos distancia.Si elegimos buenas incrustaciones que reflejan la semántica de los disparos y elegimos una buena función de distancia, entonces estos cuadrados son las escenas. Encuentra los bordes de los cuadrados: encontraremos los bordes de las escenas.Al observar la matriz, los colegas israelíes formularon tres criterios para una partición óptima:
Es el vector de borde de escena.¿Cuál de los criterios para una partición óptima elegir?
Una buena función de pérdida para una tarea de Agrupación secuencial óptima tiene dos propiedades:- Si la película consta de una escena, donde sea que tratemos de dividirla en dos partes, el valor de la función siempre será el mismo.
- Si se divide adecuadamente en escenas, el valor será menor que si no es correcto.
Resulta y no cumpla con estos requisitos, pero albardilla. Para ilustrar esto, realizaremos dos experimentos.En el primer experimento, haremos una matriz sintética de distancias por pares, llenándola de ruido uniforme. Si tratamos de dividirnos en dos escenas, obtenemos la siguiente imagen: dice que en el medio del video hay un cambio de escenas, lo que en realidad no es cierto. Asaltos anormales si la partición se coloca al principio o al final del video. Solamentese comporta como se requiere.En el segundo experimento, haremos la misma matriz con un ruido uniforme, pero le restaremos dos cuadrados, como si tuviéramos dos escenas que son ligeramente diferentes entre sí.
dice que en el medio del video hay un cambio de escenas, lo que en realidad no es cierto. Asaltos anormales si la partición se coloca al principio o al final del video. Solamentese comporta como se requiere.En el segundo experimento, haremos la misma matriz con un ruido uniforme, pero le restaremos dos cuadrados, como si tuviéramos dos escenas que son ligeramente diferentes entre sí.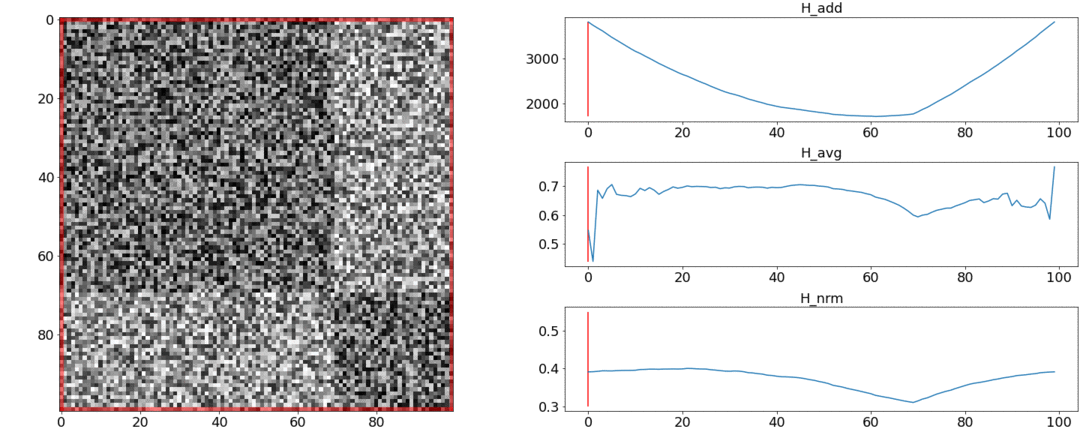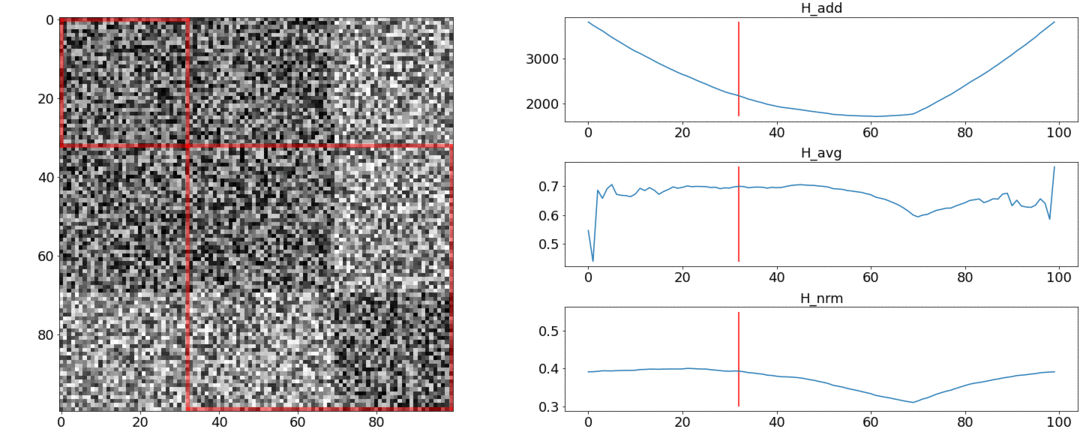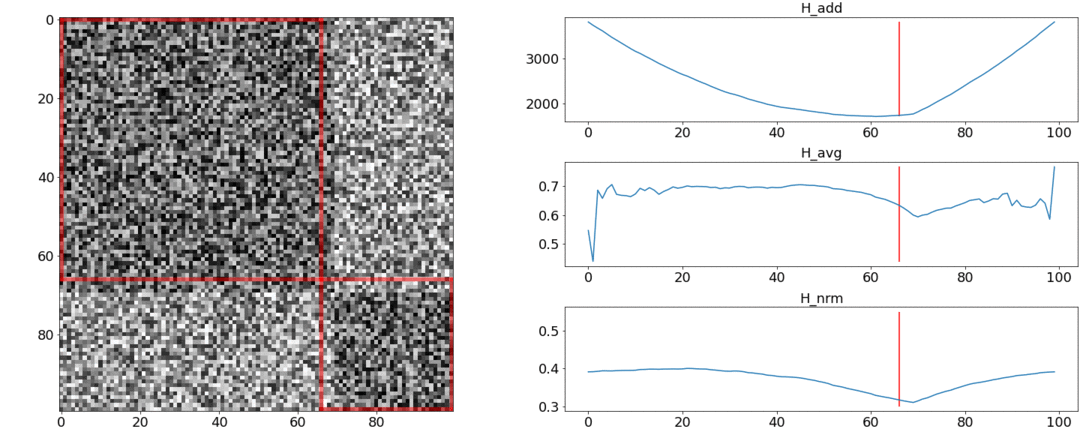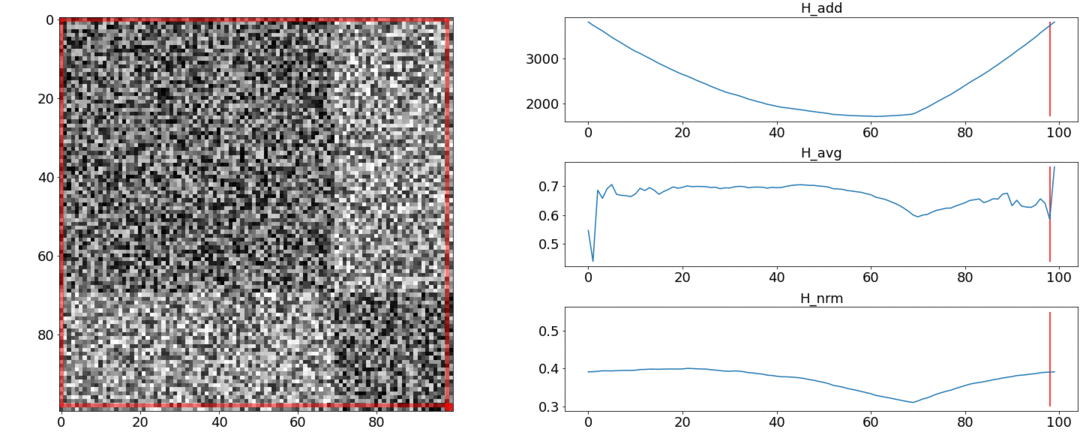 Para detectar este pegado, la función debe tomar un valor mínimo cuando. Pero un mínimo aún más cerca del medio del segmento, mientras - Al Principio. A un mínimo claro es visible en .Las pruebas también muestran que la división más precisa se logra utilizando. Parece que debes tomarlo, y todo estará bien. Pero primero veamos la complejidad del algoritmo de optimización.Daniel Rothman y su grupo sugirieron buscar una partición óptima mediante programación dinámica . La tarea se divide en subtareas de manera recursiva y se resuelve a su vez. Este método proporciona un óptimo global, pero para encontrarlo, debe iterar sobre cadatodas las combinaciones de particiones desde el 0 al Nth disparos y elige el mejor. aquí - el número de escenas, y - El número de disparos.Sin ajustes y optimizaciones de aceleraciones trabajará a tiempo . AHay un parámetro más para la enumeración: el área de la partición, y en cada paso es necesario verificar todos sus valores. En consecuencia, el tiempo aumenta a.Logramos mejorar y acelerar la optimización utilizando la técnica de Memorización, almacenando en caché los resultados de la recursividad en la memoria para no leer lo mismo muchas veces. Pero, como muestran las pruebas a continuación, no se logró un fuerte aumento de la velocidad.
Para detectar este pegado, la función debe tomar un valor mínimo cuando. Pero un mínimo aún más cerca del medio del segmento, mientras - Al Principio. A un mínimo claro es visible en .Las pruebas también muestran que la división más precisa se logra utilizando. Parece que debes tomarlo, y todo estará bien. Pero primero veamos la complejidad del algoritmo de optimización.Daniel Rothman y su grupo sugirieron buscar una partición óptima mediante programación dinámica . La tarea se divide en subtareas de manera recursiva y se resuelve a su vez. Este método proporciona un óptimo global, pero para encontrarlo, debe iterar sobre cadatodas las combinaciones de particiones desde el 0 al Nth disparos y elige el mejor. aquí - el número de escenas, y - El número de disparos.Sin ajustes y optimizaciones de aceleraciones trabajará a tiempo . AHay un parámetro más para la enumeración: el área de la partición, y en cada paso es necesario verificar todos sus valores. En consecuencia, el tiempo aumenta a.Logramos mejorar y acelerar la optimización utilizando la técnica de Memorización, almacenando en caché los resultados de la recursividad en la memoria para no leer lo mismo muchas veces. Pero, como muestran las pruebas a continuación, no se logró un fuerte aumento de la velocidad.¿Cómo estimar el número de escenas?
Un grupo de IBM sugirió que dado que muchas filas de la matriz dependen linealmente, el número de grupos cuadrados a lo largo de la diagonal será aproximadamente igual al rango de la matriz.Para obtenerlo y al mismo tiempo filtrar el ruido, necesita una descomposición singular de la matriz.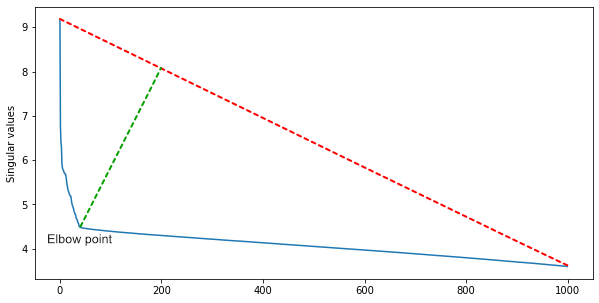 Entre los valores singulares, ordenados en orden descendente, encontramos el punto del codo, desde el cual la disminución de los valores se desacelera bruscamente. El índice del punto del codo es el número aproximado de escenas en una película.Para una primera aproximación, esto es suficiente, pero puede complementar el algoritmo con heurística para diferentes géneros de cine. En las películas de acción, hay más escenas, y en una sala de arte, menos.
Entre los valores singulares, ordenados en orden descendente, encontramos el punto del codo, desde el cual la disminución de los valores se desacelera bruscamente. El índice del punto del codo es el número aproximado de escenas en una película.Para una primera aproximación, esto es suficiente, pero puede complementar el algoritmo con heurística para diferentes géneros de cine. En las películas de acción, hay más escenas, y en una sala de arte, menos.Pruebas
Queríamos entender dos cosas:- ¿Es la diferencia de velocidad tan dramática?
- ¿Cuánta precisión sufre cuando se utiliza un algoritmo más rápido?
Las pruebas se dividieron en dos grupos: datos sintéticos y reales. En las pruebas sintéticas, se comparó la calidad y la velocidad de ambos algoritmos, y en las reales, midieron la calidad del algoritmo más rápido. Las pruebas de velocidad se realizaron en el MacBook Pro 2017, Intel Core i5 de 2.3 GHz, 16 GB 2133 MHz LPDDR3.Pruebas de calidad sintética
Generamos 999 matrices de distancias por pares que varían en tamaño de 12 a 122 disparos, las dividimos aleatoriamente en 2-10 escenas y agregamos ruido normal desde arriba.Para cada matriz, las particiones óptimas se encontraron en términos de y , y luego contó las métricas de precisión, recuperación, F1 e IoU.Consideramos la precisión y la recuperación del intervalo utilizando las siguientes fórmulas:
Consideramos F1 como de costumbre, sustituyendo el intervalo Precisión y Recuperación:
Para comparar los segmentos predichos y verdaderos dentro de la película, para cada uno predicho, encontramos el segmento verdadero con la intersección más grande y consideramos la métrica para este par.Aquí están los resultados: optimización de funciones ganó en todas las métricas, como en las pruebas de los autores del algoritmo.
optimización de funciones ganó en todas las métricas, como en las pruebas de los autores del algoritmo.Pruebas sintéticas de velocidad
Para probar la velocidad, realizamos otras pruebas sintéticas. El primero es cómo el tiempo de ejecución del algoritmo depende del número de disparos.con un número fijo de escenas: la prueba confirmó una evaluación teórica: tiempo de optimización crece polinomialmente con el crecimiento en comparación con el tiempo lineal a .Si arreglas el número de disparos y aumentar gradualmente el número de escenas , obtenemos una imagen más interesante. Al principio, se espera que el tiempo crezca, pero luego comienza a caer en picado. El hecho es que el número de posibles valores del denominador (fórmula) que debemos comprobar en proporción a la cantidad de formas en que podemos romper segmentos en . Se calcula utilizando la combinación de por :
la prueba confirmó una evaluación teórica: tiempo de optimización crece polinomialmente con el crecimiento en comparación con el tiempo lineal a .Si arreglas el número de disparos y aumentar gradualmente el número de escenas , obtenemos una imagen más interesante. Al principio, se espera que el tiempo crezca, pero luego comienza a caer en picado. El hecho es que el número de posibles valores del denominador (fórmula) que debemos comprobar en proporción a la cantidad de formas en que podemos romper segmentos en . Se calcula utilizando la combinación de por :
Con crecimiento la cantidad de combinaciones primero crece y luego cae a medida que te acercas . Esto parece ser genial, pero el número de escenas rara vez será igual al número de tomas, y siempre tendrá un valor tal que haya muchas combinaciones. En los ya mencionados "Avengers" 2700 disparos y 105 escenas. Numero de combinaciones:
Esto parece ser genial, pero el número de escenas rara vez será igual al número de tomas, y siempre tendrá un valor tal que haya muchas combinaciones. En los ya mencionados "Avengers" 2700 disparos y 105 escenas. Numero de combinaciones:
Para asegurarnos de que todo se entendía correctamente y no se enredaba en la anotación de los artículos originales, escribimos una carta a Daniel Rothman. Confirmó que muy lento para optimizar y no apto para videos de más de 10 minutos, y en la práctica da resultados aceptables.Pruebas de datos reales
Entonces, hemos elegido una métrica , que, aunque un poco menos preciso, funciona mucho más rápido. Ahora necesitamos métricas, a partir de las cuales construiremos sobre la búsqueda de un mejor algoritmo.Para la prueba marcamos 20 películas de diferentes géneros y años. El marcado se realizó en cinco etapas:- :
- , .
- . « ?»
- CV. — , .
- , « ».
Así es como se ve el escritor y la pantalla del inspector: y así es como se dividen en escenas las primeras 300 tomas de la película "Vengadores: Guerra Infinita". A la izquierda están las escenas verdaderas, y a la derecha están las predichas por el algoritmo:
y así es como se dividen en escenas las primeras 300 tomas de la película "Vengadores: Guerra Infinita". A la izquierda están las escenas verdaderas, y a la derecha están las predichas por el algoritmo: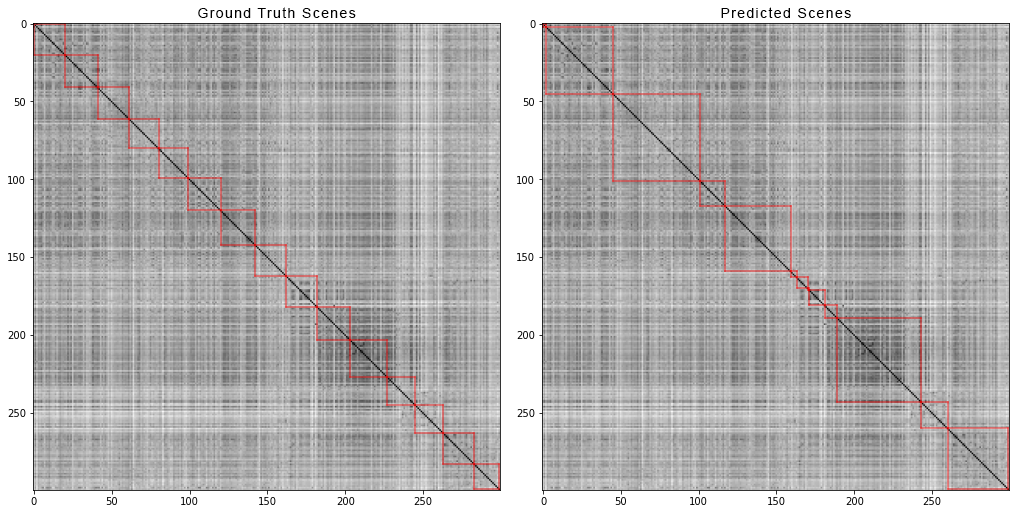 para obtener una matriz de distancias por pares, hicimos lo siguiente:Para cada video del conjunto de datos, generamos matrices de distancias por pares y, al igual que para los datos sintéticos, calculamos cuatro métricas. Aquí están los números que salieron:
para obtener una matriz de distancias por pares, hicimos lo siguiente:Para cada video del conjunto de datos, generamos matrices de distancias por pares y, al igual que para los datos sintéticos, calculamos cuatro métricas. Aquí están los números que salieron:- Precisión : 0.4861919030708739
- Retirada : 0.8225937459424839
- F1 : 0.513676858711775
- IoU : 0.37560909807842874
¿Y qué?
Tenemos una línea base que no funciona a la perfección, pero ahora puede desarrollarla mientras buscamos métodos más precisos.Algunos de los planes adicionales:- Pruebe otras arquitecturas CNN para la extracción de características.
- Pruebe otras métricas de distancia entre disparos.
- Pruebe otros métodos de optimización. , por ejemplo, algoritmos genéticos.
- Intente reducir la descomposición de toda la película en partes separadas en las que cumple en un tiempo razonable, y compara lo que será la pérdida de calidad.
El código de ambos métodos y experimentos con datos sintéticos se publicó en Github . Puede tocar e intentar acelerar usted mismo. Gustos y solicitudes de extracción son bienvenidos.¡Adiós a todos, nos vemos en los próximos artículos!