En los procesadores Intel x86 modernos, la tubería se puede dividir en 2 partes: Front End y Back End.Front End es responsable de cargar el código de la memoria y decodificarlo en microoperaciones.Back End es responsable de realizar microoperaciones desde Front End. Dado que estas microoperaciones pueden ser realizadas por el núcleo fuera de servicio, el Back End también asegura que el resultado de estas microoperaciones corresponda estrictamente al orden en que van en el código.En la mayoría de los casos, el uso ineficiente de Front End'a no tiene un efecto notable en el rendimiento. El ancho de banda máximo en la mayoría de los procesadores Intel es de 4 micro operaciones por ciclo, por lo tanto, por ejemplo, para un código enlazado con Memoria / L3, la CPU no podrá utilizarlo por completo.Pro relativamente nuevo Ice Lake, Ice Lake 4 5 . , , .
Sin embargo, en algunos casos, la diferencia en el rendimiento puede ser bastante significativa. Debajo del corte hay un análisis del impacto del caché de microoperación en el rendimiento.El contenido del articulo
- Medio ambiente
- Descripción general de los procesadores Front End'a Intel
- Análisis de ancho de banda máximo µop cache -> IDQ
- Ejemplo
Medio ambiente
Para todas las mediciones en este artículo se utilizará i7-8550U Kaby Lake, HT habilitado / Ubuntu 18.04/Linux Kernel 5.3.0-45-generic. En este caso, dicho entorno puede ser significativo, porque Cada modelo de CPU tiene su propio evento de rendimiento. En particular, para las microarquitecturas más antiguas que Sandy Bridge, algunos de los eventos utilizados en el futuro simplemente no tienen sentido.Descripción general de los procesadores Front End'a Intel
La organización de la línea de ensamblaje de alto nivel es información disponible públicamente y se publica en la documentación oficial de Intel sobre optimización de software . Puede encontrar una descripción más detallada de algunas de las funciones que se omiten de la documentación oficial en otras fuentes acreditadas, como Agner Fog o Travis Downs . Entonces, por ejemplo, el esquema de la tubería de ensamblaje para Skylake en la documentación de Intel se ve así: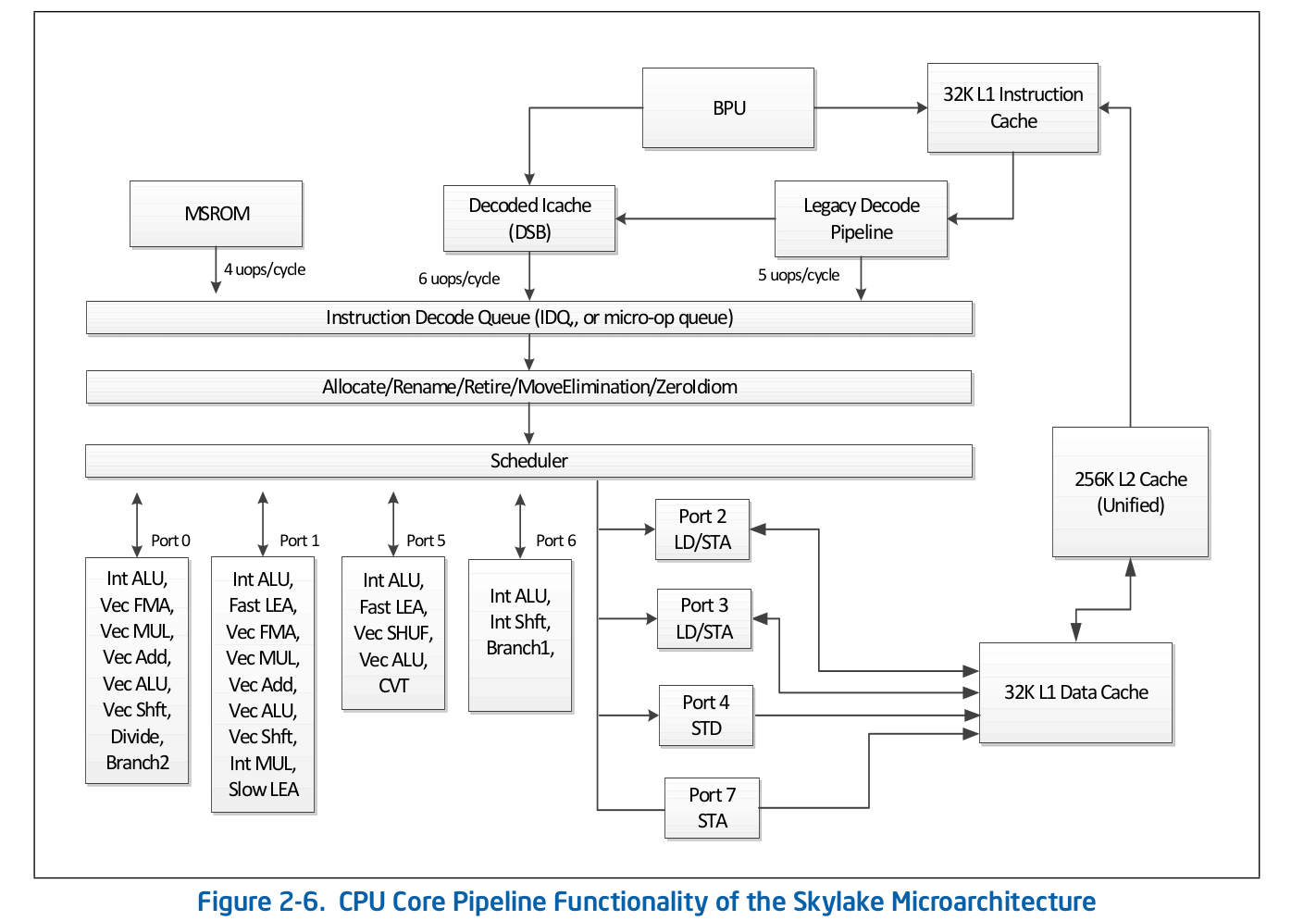 Echemos un vistazo más de cerca a la parte superior de este esquema: Front End.
Echemos un vistazo más de cerca a la parte superior de este esquema: Front End. Legacy Decode Pipeline es responsable de decodificar el código en microoperaciones. Se compone de los siguientes componentes:
Legacy Decode Pipeline es responsable de decodificar el código en microoperaciones. Se compone de los siguientes componentes:- Unidad de búsqueda de instrucciones - IFU
- Caché de instrucciones de primer nivel - L1i
- Caché de direcciones de traducción del registro de instrucciones - ITLB
- Instructor Prefector
- Instrucciones de predescodificador
- Cola de instrucciones pre-decodificadas
- Decodificadores de instrucciones precodificados por microoperación
Considere cada una de las partes del Legacy Decode Pipeline individualmente.Unidad de búsqueda de instrucciones.Es responsable de cargar el código, precodificar (determinar la longitud de la instrucción y propiedades tales como "si la instrucción es una rama") y entregar instrucciones precodificadas a la cola.Caché de instrucciones de primer nivel - L1iPara descargar el código, la IFU usa L1i, el caché de instrucciones de primer nivel, y L2 / LLC, el caché de segundo nivel y el caché offcore de nivel superior, comunes al código y los datos. La descarga se realiza en piezas de 16 bytes, también alineados a 16 bytes. Cuando se carga el siguiente fragmento de código de 16 bytes en orden, se realiza una llamada a L1i y, si no se encuentra la línea correspondiente, se realiza una búsqueda en L2 y, en caso de falla, en LLC y memoria. Antes de Skylake LLC, el caché era inclusivo: cada línea en L1 (i / d) y L2 debería estar contenida en la LLC. Por lo tanto, LLC "sabía" acerca de todas las líneas en todos los núcleos y, en el caso de un deslizamiento de LLC, se sabía si los cachés en otros núcleos contenían la línea requerida en el estado Modificado, lo que significa que esta línea podría cargarse desde otro núcleo. Skylake LLC se convirtió en un caché de víctimas L2 no inclusivo, pero el tamaño de L2 aumentó 4 veces. No lo sési L2 es inclusivo con respecto a L1i. L2no inclusivo con respecto a L1d.Traducción de direcciones lógicas de instrucciones - ITLBAntes de descargar datos del caché, debe buscar la línea correspondiente. Para ncachés asociativos de ida , cada línea puede estar en ndiferentes lugares en el propio caché. Para determinar las posibles posiciones en el caché, se usa un índice (generalmente unos pocos bits más bajos de la dirección). Para determinar si la línea coincide con la dirección que necesitamos, se utiliza una etiqueta (el resto de la dirección). Qué direcciones usar: físicas o lógicas, depende de la implementación de la memoria caché. El uso de direcciones físicas requiere traducción de direcciones. Para la traducción de direcciones, se utiliza un búfer TLB, que almacena en caché los resultados de las visitas a la página, lo que reduce el retraso en la recepción de una dirección física de una dirección lógica en las llamadas posteriores. Para obtener instrucciones, hay su propio búfer TLB de instrucciones, ubicado por separado del TLB de datos. El núcleo de la CPU también tiene un TLB de segundo nivel común al código y los datos: STLB. No sé si STLB es inclusivo (se rumorea que no es un caché de víctimas inclusivo en relación con D / I TLB). Uso de instrucciones de captación previa de softwareprefetcht1puede abrir la línea con el código en L2, sin embargo, el registro TLB correspondiente solo se levantará en DTLB. Si STLB no es inclusivo, cuando busque esta línea con el código en los cachés, obtendrá la falta de ITLB -> Falta de STLB -> recorrido de página (de hecho, no es tan simple, porque el núcleo puede iniciar un recorrido de página especulativo antes de que ocurra Señorita TLB). La documentación de Intel también desalienta el uso de captaciones previas de SW para el código, Intel Software Optimization Manual / 2.5.5.4:La captación previa controlada por software está destinada a la captación previa de datos, pero no a la captación previa de código.
Sin embargo, Travis D. mencionó que tal captación previa puede ser muy efectiva (y muy probablemente lo sea), pero hasta ahora esto no es obvio para mí y para estar convencido de esto, tendré que examinar este tema por separado.Instructor PrefectorLa descarga de datos a la caché (L1d / i, L2, etc.) ocurre cuando se accede a una sección de memoria no almacenada en caché. Sin embargo, si esto sucediera solo bajo tales condiciones, entonces como resultado obtendríamos un uso ineficiente del ancho de banda de caché. Por ejemplo, en Sandy Bridge para L1d: 2 operaciones de lectura, 1 escritura de 16 bytes por ciclo; para la operación de lectura L1i - 1 de 16 bytes, el rendimiento de escritura no se especifica en la documentación, tampoco se encontró Agner Fog. Para resolver este problema, hay buscadores de hardware que pueden determinar el patrón de acceso a la memoria y extraer las líneas necesarias en la memoria caché antes de que el código las aborde realmente. La documentación de Intel define 4 captadores previos: 2 para L1d, 2 para L2:- L1 DCU : prefijo de líneas de caché serie. Solo lectura hacia adelante
- L1 IP — (. 0x5555555545a0, 0x5555555545b0, 0x5555555545c0, ...), , ,
- L2 Spatial — L2 -, 128-. LLC
- L2 Streamer — . L1 DCU «». LLC
La documentación de Intel no describe el principio del prefector L1i. Todo lo que se sabe es que la Unidad de predicción de sucursal (BPU) está involucrada en este proceso, Intel Software Optimization Manual / 2.6.2: Agner Fog tampoco ve ningún detalle.La captación previa de código en L2 / LLC se define explícitamente solo para Streamer. Manual de optimización / 2.5.5.4 Preprogramación de datos:
Agner Fog tampoco ve ningún detalle.La captación previa de código en L2 / LLC se define explícitamente solo para Streamer. Manual de optimización / 2.5.5.4 Preprogramación de datos:Streamer : este prefetcher monitorea las solicitudes de lectura del caché L1 para secuencias de direcciones ascendentes y descendentes. Las solicitudes de lectura monitoreadas incluyen las solicitudes L1 DCache iniciadas por las operaciones de carga y almacenamiento y por los captadores de hardware, y las solicitudes L1 ICache para la búsqueda de código.
Para el prefetcher espacial, esto claramente no se explica:Prefetcher espacial: este prefetcher se esfuerza por completar cada línea de caché obtenida en el caché L2 con la línea de pares que la completa en un fragmento alineado de 128 bytes.
Pero esto puede ser verificado. Cada uno de estos captadores previos se puede desactivar utilizando MSR 0x1A4, como se describe en el manual de Registros específicos del modelo.Acerca de MSR 0x1A4MSR L2 Spatial L1i. . , LLC. L2 Streamer 2.5 .
Linux msr , msr . $ sudo wrmsr -p 1 0x1a4 1 L2 Streamer 1.
Instrucciones de predescodificadorDespués de cargar el siguiente código de 16 bytes, se incluyen en las instrucciones de predescodificador. Su tarea es determinar la longitud de la instrucción, decodificar los prefijos y marcar si la instrucción correspondiente es una rama (lo más probable es que todavía haya muchas propiedades diferentes, pero la documentación sobre ellas es silenciosa). Manual de optimización de software Intel / 2.6.2.2:The predecode unit accepts the sixteen bytes from the instruction cache or prefetch buffers and carries out the following tasks:
- Determine the length of the instructions
- Decode all prefixes associated with instructions
- Mark various properties of instructions for the decoders (for example, “is branch.”)
Una línea de instrucciones predescodificadas.Desde la IFU, las instrucciones se agregan a la cola de instrucciones precodificadas. Esta cola ha aparecido desde Nehalem, de acuerdo con la documentación de Intel, su tamaño es de 18 instrucciones. Agner Fog también menciona que esta cola no contiene más de 64 bytes.También en Core2, esta cola se usó como caché de bucle. Si todas las microoperaciones del ciclo están en la cola, entonces en algunos casos se podría evitar el costo de carga y codificación previa. El Loop Stream Detector (LSD) puede entregar instrucciones que ya están en la cola hasta que la BPU indique que el ciclo ha finalizado. Agner Fog tiene una serie de notas interesantes sobre LSD en Core2:- Consta de 4 líneas de 16 bytes.
- Máximo rendimiento de hasta 32 bytes de código por ciclo
Comenzando con Sandy Bridge, este caché de bucle se ha movido de la cola de instrucciones predescodificadas de nuevo a IDQ.Decodificadores de instrucciones predescodificadas en microoperaciónDesde la cola de instrucciones predescodificadas , el código se envía a la decodificación en microoperación. Los decodificadores son responsables de la decodificación: hay 4 en total. Según la documentación de Intel, uno de los decodificadores puede decodificar instrucciones que consisten en 4 microoperaciones o menos. El resto decodifica las instrucciones que consisten en una microoperación (micro / macro fusionada), Manual de optimización de software Intel / 2.5.2.1:There are four decoding units that decode instruction into micro-ops. The first can decode all IA-32 and Intel 64 instructions up to four micro-ops in size. The remaining three decoding units handle single-micro-op instructions. All four decoding units support the common cases of single micro-op flows including micro-fusion and macro-fusion.
Las instrucciones decodificadas en una gran cantidad de microoperaciones (por ejemplo, rep movsb utilizado en la implementación de memcpy en libc en ciertos tamaños de memoria copiada) provienen de Microcode Sequencer (MS ROM). El ancho de banda máximo del secuenciador es de 4 microoperaciones por ciclo.Como puede ver en el diagrama de la línea de ensamblaje, el Legacy Decode Pipeline puede decodificar hasta 5 micro operaciones por ciclo en Skylake. En Broadwell y versiones anteriores, el rendimiento máximo de Legacy Decode Pipeline fue de 4 microoperaciones por ciclo.Caché de microoperaciónDespués de que las instrucciones se descodifiquen en microoperaciones, desde el Legacy Decode Pipeline caen en la cola de microoperación especial: Cola de decodificación de instrucciones (IDQ), así como el llamado caché de microoperación (Decoded ICache, µop cache). El caché de microoperaciones se introdujo originalmente en Sandy Bridge y se usa para evitar buscar y decodificar instrucciones en microoperaciones, lo que aumenta el rendimiento para entregar microoperaciones en IDQ, hasta 6 por ciclo. Después de ingresar a IDQ, las microoperaciones van al Back End para su ejecución con un rendimiento máximo de 4 microoperaciones por ciclo.De acuerdo con la documentación de Intel, el caché de microoperación consta de 32 conjuntos, cada conjunto contiene 8 líneas, cada línea puede almacenar en caché hasta 6 micro operaciones (micro / macro fusionadas), lo que permite un caché total de hasta 32 * 8 * 6 = 1536 micro operaciones . El almacenamiento en caché de microoperación se produce con una granularidad de 32 bytes, es decir Las microoperaciones que siguen instrucciones de diferentes regiones de 32 bytes no pueden caer en una sola línea. Sin embargo, hasta 3 líneas de caché diferentes pueden corresponder a una región de 32 bytes. Por lo tanto, hasta 18 microoperaciones en caché µop pueden corresponder a cada región de 32 bytes.Manual de optimización de software Intel / 2.5.5.2The Decoded ICache consists of 32 sets. Each set contains eight Ways. Each Way can hold up to six micro-ops. The Decoded ICache can ideally hold up to 1536 micro-ops. The following are some of the rules how the Decoded ICache is filled with micro-ops:
- ll micro-ops in a Way represent instructions which are statically contiguous in the code and have their EIPs within the same aligned 32-byte region.
- Up to three Ways may be dedicated to the same 32-byte aligned chunk, allowing a total of 18 micro-ops to be cached per 32-byte region of the original IA program.
- A multi micro-op instruction cannot be split across Ways.
- Up to two branches are allowed per Way.
- An instruction which turns on the MSROM consumes an entire Way.
- A non-conditional branch is the last micro-op in a Way.
- Micro-fused micro-ops (load+op and stores) are kept as one micro-op.
- A pair of macro-fused instructions is kept as one micro-op.
- Instructions with 64-bit immediate require two slots to hold the immediate.
Agner Fog también menciona que solo se pueden descargar micro operaciones de una sola línea por ciclo (no se indica explícitamente en la documentación de Intel, aunque se puede verificar fácilmente de forma manual).µop cache --> IDQ
En algunos casos, es muy conveniente usar noplongitudes de 1 byte para estudiar el comportamiento de Front End . Al mismo tiempo, podemos estar seguros de que estamos investigando el Front End, y no el Puesto de recursos en el Back End, por cualquier motivo. El hecho es que nop, además de otras instrucciones, se decodifican en la tubería de decodificación heredada, se mezclan en caché µop y se envían a IDQ. Además nop, al igual que otras instrucciones, se remonta. La diferencia significativa es que de los recursos en el Back End noputiliza solo el Reorden Buffer y no requiere un espacio en la Estación de Reserva (también conocido como Programador). Por lo tanto, inmediatamente después de ingresar Reorder Buffer, está noplisto para la jubilación, que se realizará de acuerdo con el orden en el código del programa.Para probar el rendimiento, declare una funciónvoid test_decoded_icache(size_t iteration_count);
con implementación en nasm:align 32
test_decoded_icache:
;nop', 0 23
dec rdi
ja test_decoded_icache
ret
jaNo fue elegido por casualidad. jay decutilizar diferentes banderas - jalee de CFy ZF, decno se está grabando en el CF, por lo macro fusión no se aplica. Esto se hace únicamente por la conveniencia de contar microoperaciones en un ciclo; cada instrucción corresponde a una microoperación.Para las mediciones, necesitamos los siguientes eventos de rendimiento:1. uops_issued.any- Se utiliza para contar las microoperaciones que Renamer toma de IDQ.La Guía de programación del sistema Intel documenta este evento como el número de microoperaciones que Renamer pone en la Estación de reserva:Cuenta el número de uops que la tabla de asignación de recursos (RAT) emite a la estación de reserva (RS).
Esta descripción no se correlaciona completamente con los valores que se pueden obtener de los experimentos. En particular, nopcaen en este mostrador, aunque es solo un hecho que no son necesarios en absoluto en la Estación de Reservaciones.2. uops_retired.retire_slots- el número total de microoperaciones retiradas teniendo en cuenta la micro / macro fusión3. uops_retired.stall_cycles- el número de ticks para los cuales no hubo una sola microoperación retirada4. resource_stalls.any- el número de ticks del transportador inactivo debido a la inaccesibilidad de cualquiera de los recursos Back Enden el Intel Software Optimization Manual / B .4.1 hay un diagrama de contenido que caracteriza los eventos descritos anteriormente: 5.
5. idq.all_dsb_cycles_4_uops- el número de ciclos de reloj para los cuales se entregaron 4 (o más) instrucciones desde el caché µop.El hecho de que esta métrica tenga en cuenta la entrega de más de 4 microoperaciones por ciclo no se describe en la documentación de Intel, pero está muy de acuerdo con los experimentos.6. idq.all_dsb_cycles_any_uops- el número de medidas para las cuales se entregó al menos una microoperación.7. idq.dsb_cycles- El número total de medidas en las que la entrega se realizó desde el caché µop8. idq_uops_not_delivered.cycles_le_N_uop_deliv.core- El número de medidas para las cuales Renamer tomó una No menos microoperaciones y no hubo tiempo de inactividad en el lado de Back End , N- 1, 2, 3.Tomamos para la investigación iteration_count = 1 << 31. Comenzamos el análisis de lo que está sucediendo en la CPU examinando el número de microoperaciones y, primero, midiendo el ancho de banda promedio de retiro, es decir uops_retired.retire_slots/uops_retired.total_cycle: Lo que llama la atención de inmediato es la subsidencia del rendimiento de la jubilación en un ciclo de 7 microoperaciones. Para entender qué es, consideremos cómo la tasa de entrega promedio de caché μop -
Lo que llama la atención de inmediato es la subsidencia del rendimiento de la jubilación en un ciclo de 7 microoperaciones. Para entender qué es, consideremos cómo la tasa de entrega promedio de caché μop - idq.all_dsb_cycles_any_uops / idq.dsb_cycles: y cómo relacionar el número total de ciclos de reloj y ciclos para los cuales se entregó caché μop en IDQ: por lo
y cómo relacionar el número total de ciclos de reloj y ciclos para los cuales se entregó caché μop en IDQ: por lo tanto, se puede ver que el ciclo de 6 microoperaciones tenemos efectivo Utilización de ancho de banda de caché µop: 6 micro operaciones por ciclo. Debido al hecho de que Renamer no puede recoger tanto como el caché µop entrega, algunos de los ciclos de caché µop no entregan nada, lo cual es claramente visible en el gráfico anterior.Con un ciclo de 7 microoperaciones, obtenemos una fuerte caída en el rendimiento del caché µop: 3.5 microoperaciones por ciclo. Al mismo tiempo, como se puede ver en el gráfico anterior, el caché µop está constantemente en funcionamiento. Por lo tanto, con un ciclo de 7 microoperaciones, obtenemos una utilización ineficiente de la caché µop de ancho de banda. El hecho es que, como se señaló anteriormente, la caché µop por ciclo puede entregar microoperaciones desde una sola línea. En caso de microoperaciones 7, los primeros 6 caen en una línea y los 7 restantes, en otra. De esta manera, obtenemos 7 microoperaciones por 2 ciclos, o 3,5 microoperaciones por ciclo.Ahora veamos cómo Renamer toma microoperaciones de IDQ. Para esto necesitamos
tanto, se puede ver que el ciclo de 6 microoperaciones tenemos efectivo Utilización de ancho de banda de caché µop: 6 micro operaciones por ciclo. Debido al hecho de que Renamer no puede recoger tanto como el caché µop entrega, algunos de los ciclos de caché µop no entregan nada, lo cual es claramente visible en el gráfico anterior.Con un ciclo de 7 microoperaciones, obtenemos una fuerte caída en el rendimiento del caché µop: 3.5 microoperaciones por ciclo. Al mismo tiempo, como se puede ver en el gráfico anterior, el caché µop está constantemente en funcionamiento. Por lo tanto, con un ciclo de 7 microoperaciones, obtenemos una utilización ineficiente de la caché µop de ancho de banda. El hecho es que, como se señaló anteriormente, la caché µop por ciclo puede entregar microoperaciones desde una sola línea. En caso de microoperaciones 7, los primeros 6 caen en una línea y los 7 restantes, en otra. De esta manera, obtenemos 7 microoperaciones por 2 ciclos, o 3,5 microoperaciones por ciclo.Ahora veamos cómo Renamer toma microoperaciones de IDQ. Para esto necesitamos idq_uops_not_delivered.corey idq_uops_not_delivered.cycles_le_N_uop_deliv.core: Puede notar que con 7 microoperaciones, solo 3 microoperaciones a la vez toman la mitad de los ciclos de Renamer. A partir de aquí, obtenemos un rendimiento de jubilación de un promedio de 3.5 microoperaciones por ciclo.Otro punto interesante relacionado con este ejemplo se puede ver si consideramos el rendimiento efectivo de la jubilación. Aquellos. sin considerar
Puede notar que con 7 microoperaciones, solo 3 microoperaciones a la vez toman la mitad de los ciclos de Renamer. A partir de aquí, obtenemos un rendimiento de jubilación de un promedio de 3.5 microoperaciones por ciclo.Otro punto interesante relacionado con este ejemplo se puede ver si consideramos el rendimiento efectivo de la jubilación. Aquellos. sin considerar uops_retired.stall_cycles: Se puede observar que con 7 microoperaciones, cada 7 medidas se realiza el retiro de 4 microoperaciones, y cada octava medida está inactiva sin microoperaciones retiradas (parada de retiro). Después de realizar una serie de experimentos, fue posible encontrar que tal comportamiento siempre se observó durante 7 microoperaciones, independientemente de su diseño 1-6, 6-1, 2-5, 5-2, 3-4, 4-3. No sé por qué este es exactamente el caso, y no, por ejemplo, el retiro de 3 microoperaciones se realiza en un ciclo de reloj y 4 en el siguiente. Agner Fog mencionó que las transiciones de rama solo pueden usar parte de las ranuras de la estación de retiro. Quizás esta restricción sea la razón de este comportamiento de jubilación.
Se puede observar que con 7 microoperaciones, cada 7 medidas se realiza el retiro de 4 microoperaciones, y cada octava medida está inactiva sin microoperaciones retiradas (parada de retiro). Después de realizar una serie de experimentos, fue posible encontrar que tal comportamiento siempre se observó durante 7 microoperaciones, independientemente de su diseño 1-6, 6-1, 2-5, 5-2, 3-4, 4-3. No sé por qué este es exactamente el caso, y no, por ejemplo, el retiro de 3 microoperaciones se realiza en un ciclo de reloj y 4 en el siguiente. Agner Fog mencionó que las transiciones de rama solo pueden usar parte de las ranuras de la estación de retiro. Quizás esta restricción sea la razón de este comportamiento de jubilación.Ejemplo
Para entender si todo esto tiene un efecto en la práctica, considere el siguiente ejemplo un poco más práctico que con nops:se dan dos matrices unsigned. Es necesario acumular la suma de los medios aritméticos para cada índice y escribirlo en la tercera matriz.Un ejemplo de implementación podría verse así:
static unsigned arr1[] = { ... };
static unsigned arr2[] = { ... };
static void arithmetic_mean(unsigned *arr1, unsigned *arr2, unsigned *out, size_t sz){
unsigned sum = 0;
size_t idx = 0;
while(idx < sz){
sum += (arr1[idx] + arr2[idx]) >> 1;
out[idx] = sum;
idx++;
}
__asm__ __volatile__("" ::: "memory");
}
int main(void){
unsigned out[sizeof arr1 / sizeof(unsigned)];
for(size_t i = 0; i < 4096 * 4096; i++){
arithmetic_mean(arr1, arr2, out, sizeof arr1 / sizeof(unsigned));
}
}
Compilar con banderas gcc-Werror
-Wextra
-Wall
-pedantic
-Wno-stack-protector
-g3
-O3
-Wno-unused-result
-Wno-unused-parameter
Es bastante obvio que la función arithmetic_meanno estará presente en el código y se insertará directamente en main:(gdb) disas main
Dump of assembler code for function main:
#...
0x00000000000005dc <+60>: nop DWORD PTR [rax+0x0]
0x00000000000005e0 <+64>: mov edx,DWORD PTR [rdi+rax*4]
0x00000000000005e3 <+67>: add edx,DWORD PTR [r8+rax*4]
0x00000000000005e7 <+71>: shr edx,1
0x00000000000005e9 <+73>: add ecx,edx
0x00000000000005eb <+75>: mov DWORD PTR [rsi+rax*4],ecx
0x00000000000005ee <+78>: add rax,0x1
0x00000000000005f2 <+82>: cmp rax,0x80
0x00000000000005f8 <+88>: jne 0x5e0 <main+64>
0x00000000000005fa <+90>: sub r9,0x1
0x00000000000005fe <+94>: jne 0x5d8 <main+56>
#...
Tenga en cuenta que el compilador alineó el código de bucle a 32 bytes ( nop DWORD PTR [rax+0x0]), que es exactamente lo que necesitamos. Después de asegurarnos de que no haya resource_stalls.anyBack End (todas las mediciones se realizan teniendo en cuenta el caché L1d calentado), podemos comenzar a considerar los contadores asociados con la entrega a IDQ: Performance counter stats for './test_decoded_icache':
2 273 343 251 idq.all_dsb_cycles_4_uops (15,94%)
4 458 322 025 idq.all_dsb_cycles_any_uops (16,26%)
15 473 065 238 idq.dsb_uops (16,59%)
4 358 690 532 idq.dsb_cycles (16,91%)
2 528 373 243 idq_uops_not_delivered.core (16,93%)
73 728 040 idq_uops_not_delivered.cycles_0_uops_deliv.core (16,93%)
107 262 304 idq_uops_not_delivered.cycles_le_1_uop_deliv.core (16,93%)
108 454 043 idq_uops_not_delivered.cycles_le_2_uop_deliv.core (16,65%)
2 248 557 762 idq_uops_not_delivered.cycles_le_3_uop_deliv.core (16,32%)
2 385 493 805 idq_uops_not_delivered.cycles_fe_was_ok (16,00%)
15 147 004 678 uops_retired.retire_slots
4 724 790 623 uops_retired.total_cycles
1,228684264 seconds time elapsed
Tenga en cuenta que el ancho de retiro incorrecto en este caso = 15147004678/4724790623 = 3.20585733562, y también que solo 3 microoperaciones toman la mitad de los relojes de Renamer.Ahora agregue la promoción de bucle manual a la implementación:static void arithmetic_mean(unsigned *arr1, unsigned *arr2, unsigned *out, size_t sz){
unsigned sum = 0;
size_t idx = 0;
if(sz & 2){
sum += (arr1[idx] + arr2[idx]) >> 1;
out[idx] = sum;
idx++;
}
while(idx < sz){
sum += (arr1[idx] + arr2[idx]) >> 1;
out[idx] = sum;
idx++;
sum += (arr1[idx] + arr2[idx]) >> 1;
out[idx] = sum;
idx++;
}
__asm__ __volatile__("" ::: "memory");
}
Los contadores de rendimiento resultantes se ven así:Performance counter stats for './test_decoded_icache':
2 152 818 549 idq.all_dsb_cycles_4_uops (14,79%)
3 207 203 856 idq.all_dsb_cycles_any_uops (15,25%)
12 855 932 240 idq.dsb_uops (15,70%)
3 184 814 613 idq.dsb_cycles (16,15%)
24 946 367 idq_uops_not_delivered.core (16,24%)
3 011 119 idq_uops_not_delivered.cycles_0_uops_deliv.core (16,24%)
5 239 222 idq_uops_not_delivered.cycles_le_1_uop_deliv.core (16,24%)
7 373 563 idq_uops_not_delivered.cycles_le_2_uop_deliv.core (16,24%)
7 837 764 idq_uops_not_delivered.cycles_le_3_uop_deliv.core (16,24%)
3 418 529 799 idq_uops_not_delivered.cycles_fe_was_ok (16,24%)
3 444 833 440 uops_retired.total_cycles (18,18%)
13 037 919 196 uops_retired.retire_slots (18,17%)
0,871040207 seconds time elapsed
En este caso, tenemos un ancho de banda de retiro = 13037919196/3444833440 = 3.78477491672, así como una utilización eficiente del ancho de banda de Renamer.Por lo tanto, no solo nos deshicimos de una ramificación y una operación de incremento en un bucle, sino que también aumentamos el ancho de banda de retiro mediante la utilización eficiente del rendimiento del caché de microoperación, lo que dio un aumento total del 28% en el rendimiento.Tenga en cuenta que solo una reducción en una operación de rama e incremento proporciona un aumento de rendimiento promedio del 9%.Pequeño comentario
En la CPU que se utilizó para realizar estos experimentos, LSD está desactivado. Parece que el LSD podría manejar tal situación. Para las CPU con LSD habilitado, estos casos deberán investigarse por separado.