Hola Habr!
Continuamos publicando reseñas de artículos científicos de miembros de la comunidad Open Data Science del canal #article_essense. Si quieres recibirlos antes que los demás, ¡únete a la comunidad ! La primera parte de la asamblea de revisión de marzo se publicó anteriormente .
:
- NeRF: Representing Scenes as Neural Radiance Fields for View Synthesis (UC Berkeley, Google Research, UC San Diego, 2020)
- Scene Text Recognition via Transformer (China, 2020)
- PEGASUS: Pre-training with Extracted Gap-sentences for Abstractive Summarization (Imperial College London, Google Research, 2019)
- Lagrangian Neural Networks (Princeton, Oregon, Google, Flatiron, 2020)
- Deformable Style Transfer (Chicago, USA, 2020)
- Rethinking Few-Shot Image Classification: a Good Embedding Is All You Need? (MIT, Google, 2020)
- Attentive CutMix: An Enhanced Data Augmentation Approach for Deep Learning Based Image Classification (Carnegie Mellon University, USA, 2020)
1. NeRF: Representing Scenes as Neural Radiance Fields for View Synthesis
: Ben Mildenhall, Pratul P. Srinivasan, Matthew Tancik, Jonathan T. Barron, Ravi Ramamoorthi, Ren Ng (UC Berkeley, Google Research, UC San Diego, 2020)
:: GitHub project :: Video :: Blog
: ( belskikh)
3 ( 25 ) , - .

:
- 3 2 .
- 3 (x, y, z) , MLP, (r, g, b) .
- , 2 2 .
, MLP, L2 3 .
, :
- , x, y, z. : MLP x, y, z 8 (ReLU, 256 ) 256- . 4 MLP (ReLU, 128 ), RGB .
- Positional Encoding . , , . ( ) positional encoding MLP
- , , "", "". Hierarchical volume sampling.
. L2 GT "" "" . 1-2 1xV100.

2. Scene Text Recognition via Transformer
: Xinjie Feng, Hongxun Yao, Yuankai Qi, Jun Zhang, Shengping Zhang (China, 2020)
:: GitHub project
: ( belskikh)
: , .. .
Optical Character Recognition (OCR), ResNet Transformer. , ( ..).

:
- 9696
- 4 ResNet ( 1/16, )
- HxWxC (6x6x1024) H*WxC (36x1024), FC , ( 36x256)
- Word embedding ( 256)
- .
, "" , , . .
4 ResNet-101 ( torchvision). :
- 4 , -;
- multi-head self attention ;
- position-wise ;
- 4 , -, - — multi-head attention ;
- - residual layer norm;
- ( , ).
SynthText RRC-ArT. Tesla P40 ( ).
"" ( -) / .
(. ):
:
- -.
- .
- - / .

: (Imperial College London, Google Research, 2019)
: ( yorko)
extractive abstractive. – , – , , , .
PEGASUS ( – Imperial College, – Google Research) abstractive summarization Gap Sentences Generation objective . Masked Language Modeling, BERT & Co. , – . , abstractive self-supervised objective, , . extractive- , – .
. , reverse-engineering. : 3 , [MASK1], [MASK2]. “-” – . , Gap Sentences Generation objective MLM BERT, , GSG , -MLM . -MLM :).
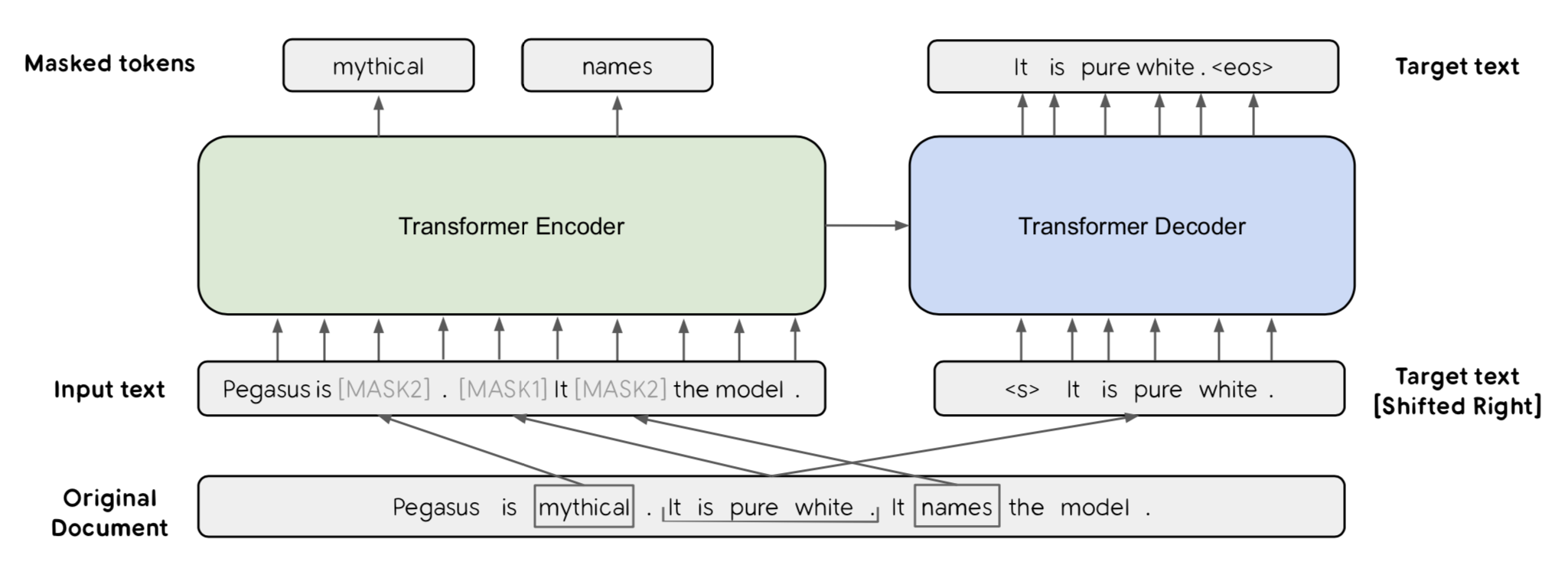
() , “” . 3 : (Random), (Lead) Principal, ROUGE1-F1. ( 30%) , .
Principal , Lead, .. bias, .
: C4 (Colossal and Cleaned version of Common Crawl, 750 Gb), HugeNews – 3.8 Tb ( , ).
12 ( , , , reddit ..), SOTA ( , . 2019). , , 1000 .
Appendix E , 10 SOTA ( , 12 ):

– , “” , , Chelsea “Jose Mourinho’s side” “The Blues”. , . - – .
: , - – , . . “big data” , .
– abstractive . ROUGE – , . ROUGE , / - . , . , SOTA .
4. Lagrangian Neural Networks
: Miles Cranmer, Sam Greydanus, Stephan Hoyer, Peter Battaglia, David Spergel, Shirley Ho (Princeton, Oregon, Google, Flatiron, 2020)
:: GitHub project :: Blog
: ( graviton)
, "" ( ) . , . "" , , , , 2- .

:
— . , (Hamiltonian Neural Networks Deep Lagrangian Networks), . :
- Hamiltonian Neural Networks — "" , -, ;
- Deep Lagrangian Networks — , .. , , .
( ). .. , , , , , . .
:
- , , .
- , — ( , , ).
- , , (), .
(-) , jax.
4- 500 . .
ReLU , .. 2- . ReLU^2, ReLU^3, tanh, sigmoid softplus. softplus .

: Sunnie S. Y. Kim, Nicholas Kolkin, Jason Salavon, Gregory Shakhnarovich (Chicago, USA, 2020)
: ( digitman)
, . , . , .

DST(deformable style transfer) "" "", : , - (, ). — , . , ( ).
( ), - , - . NBB (neural best-buddies): CNN 2- , , "" , , k (80), k 2- , .
, . dense flow field 'I' warped W(I, θ). thin-plate spline interpolation. , , θ — .

: — , f — , g — , h — .
, : Gatys ( Gramm matrix vgg , — ) STROTSS ( 3- , ). , . DST , :
I_s X ( ) I_s W(X, θ). .
— deformation loss k , p_i p_i' — source target . θ. , p_i' p_i, , , - source target . "total variation norm of the 2D warp field". .
:
α β , γ — . ( ) — warped stylized image W(I, θ).
, , , . : , , STROTSS, STROTSS, DST, , DST.

user study AMT , "" , "" .
6. Rethinking Few-Shot Image Classification: a Good Embedding Is All You Need?
: Yonglong Tian, Yue Wang, Dilip Krishnan, Joshua B. Tenenbaum, Phillip Isola (MIT, Google, 2020)
:: GitHub project
: ( belskikh)
few-show learning, . , 3%, , meta-learning .
-, , - - . . - , - - . Few-shot learning -.
, :
- ( , - , ).
- - .
- - (1-5) , .

self-distillation Born-again . , - . - GT , KL — .
, . , (, , ) -.
ResNet-12 SeResNet-12 miniImageNet, tiered- ImageNet, CIFAR-FS, FC100.
kNN, , .

7. Attentive CutMix: An Enhanced Data Augmentation Approach for Deep Learning Based Image Classification
: Devesh Walawalkar, Zhiqiang Shen, Zechun Liu, Marios Savvides (Carnegie Mellon University, USA, 2020)
: ( artgor)
cutmix. , , attention maps, . , . CIFAR-10, CIFAR-100, ImageNet (!) ResNet, DenseNet, EfficientNet. + 1.5% .

, , :
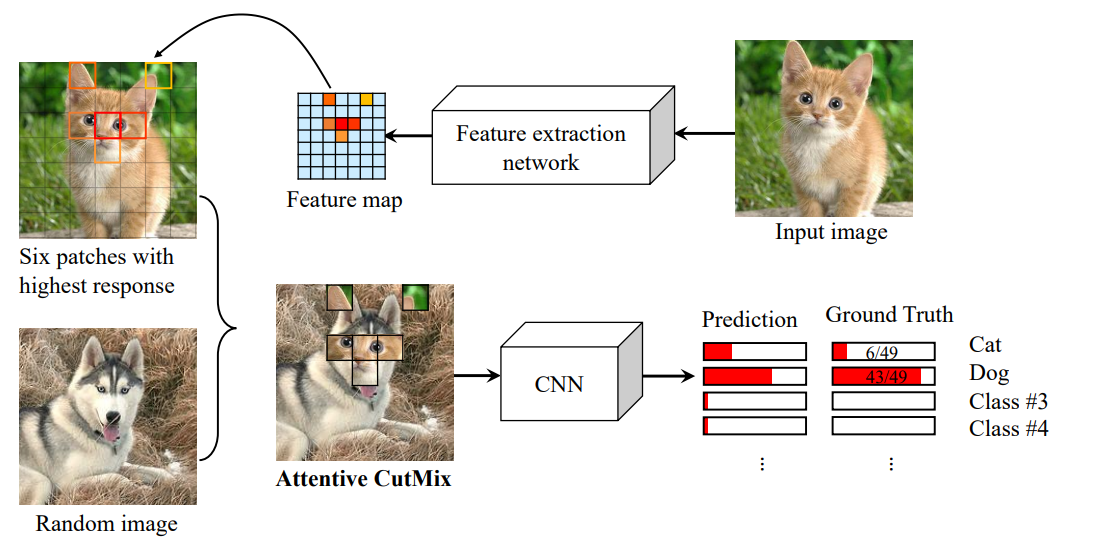
: , CAM CutMix, Chris Kaggle::Bengali.AI Handwritten Grapheme Classification.
pytorch:
- CIFAR-10 — 80 , batch size 32, learning rate 1e-3, weight decay 1e-5;
- CIFAR-100 — 120 , batch size 32, learning rate 1e-3, weight decay 1e-5;
- ImageNet — 100 ResNet DenseNet, 180 EfficientNet, batch size 64, learning rate 1e-3
Ablation study
, — , . 1 15. 6 .