Recientemente hablé sobre cómo usar las recetas estándar para aumentar el rendimiento de las consultas de "lectura" SQL de una base de datos PostgreSQL. Hoy hablaremos sobre cómo puede hacer que la grabación en la base de datos sea más eficiente sin usar ningún "giro" en la configuración, simplemente organizando correctamente los flujos de datos.# 1 Fraccionamiento
Ya se ha publicado un artículo sobre cómo y por qué vale la pena organizar el particionamiento aplicado "en teoría" , aquí nos centraremos en la práctica de utilizar algunos enfoques dentro del marco de nuestro servicio de monitoreo para cientos de servidores PostgreSQL ."Casos de tiempos pasados ..."
Inicialmente, como cualquier MVP, nuestro proyecto comenzó bajo una carga bastante pequeña: el monitoreo se realizó solo para los diez servidores más críticos, todas las tablas eran relativamente compactas ... Pero pasó el tiempo, había más y más hosts monitoreados, y una vez más intentamos hacer algo con En una de las mesas con un tamaño de 1,5 TB , nos dimos cuenta de que, aunque es posible vivir así, es muy inconveniente.Los tiempos eran casi épicos, las diferentes versiones de PostgreSQL 9.x eran relevantes, por lo que todas las particiones tenían que hacerse "manualmente", a través de la herencia de la tabla y los desencadenadores de enrutamiento dinámico EXECUTE.La solución resultante resultó ser lo suficientemente universal como para poder traducirla a todas las tablas:PG10:
Pero la partición a través de la herencia históricamente no ha sido adecuada para trabajar con una secuencia de escritura activa o una gran cantidad de secciones secundarias. Por ejemplo, puede recordar que el algoritmo para seleccionar la sección deseada era de complejidad cuadrática , que funciona con más de 100 secciones, usted mismo comprende cómo ...En PG10, esta situación se optimizó en gran medida al implementar el soporte para la partición nativa . Por lo tanto, intentamos aplicarlo inmediatamente después de la migración del almacenamiento, pero ...Como resultó después de desenterrar el manual, la tabla con particiones nativas en esta versión:- no admite descripción de índices
- no admite desencadenantes
- no puede ser en sí mismo ningún "descendiente"
- no apoye
INSERT ... ON CONFLICT - no puede generar la sección automáticamente
Obteniendo dolorosamente un rastrillo en la frente, nos dimos cuenta de que no podíamos prescindir de modificar la aplicación, y pospusimos más investigaciones durante seis meses.PG10: Segunda oportunidad
Entonces, comenzamos a resolver los problemas a su vez:- Dado que los desencadenantes
ON CONFLICTresultaron ser necesarios en algunos lugares, creamos una tabla proxy intermedia para resolverlos . - Nos deshicimos del "enrutamiento" en los disparadores, es decir, de
EXECUTE. - Sacaron una tabla de plantilla separada con todos los índices para que ni siquiera estuvieran presentes en la tabla de proxy.
Finalmente, después de todo esto, la tabla principal ya se ha particionado de forma nativa. La creación de una nueva sección ha permanecido en la conciencia de la aplicación.Diccionarios "aserrado"
Como en cualquier sistema analítico, también teníamos "hechos" y "recortes" (diccionarios). En nuestro caso, en esta capacidad estaban, por ejemplo, el cuerpo de la "plantilla" del mismo tipo de consultas lentas o el texto de la consulta en sí.Nuestros "hechos" se dividieron por días durante mucho tiempo, por lo que eliminamos con calma las secciones obsoletas y no nos molestaron (¡registros!). Pero con los diccionarios el problemaresultó ... No quiere decir que había muchos, pero alrededor de 100 TB de "hechos" resultaron ser un diccionario para 2.5 TB . No puede eliminar convenientemente nada de esa tabla, no lo exprimirá en el tiempo adecuado y escribir en él gradualmente se hizo más lento.Parece un diccionario ... en él cada entrada debe presentarse exactamente una vez ... y eso es correcto, pero ... ¡Nadie nos molesta en tener un diccionario separado para cada día ! Sí, esto trae cierta redundancia, pero le permite:- escribir / leer más rápido debido al tamaño de sección más pequeño
- consume menos memoria trabajando con índices más compactos
- almacenar menos datos debido a la capacidad de eliminar rápidamente obsoletos
Como resultado de todo el complejo de medidas , la carga de la CPU disminuyó en ~ 30%, y en disco, en ~ 50% :Al mismo tiempo, continuamos escribiendo exactamente lo mismo en la base de datos, solo que con menos carga.# 2 Evolución de bases de datos y refactorización
Entonces, nos decidimos por el hecho de que para cada día tenemos nuestra propia sección con datos. En realidad, esta CHECK (dt = '2018-10-12'::date)es la clave de partición y la condición para que el registro caiga en una sección particular.Dado que todos los informes de nuestro servicio se crean de acuerdo con una fecha específica, los índices de los "tiempos no particionados" fueron todos de ellos (Servidor, Fecha , Plantilla de plan) , (Servidor, Fecha , Nodo de plan) , ( Fecha , Clase de error, Servidor) , ...Pero ahora cada sección tiene sus propias instancias de cada índice ... Y dentro de cada sección la fecha es constante ... Resulta que ahora estamos en cada índicetrivialmente ingresamos una constante como uno de los campos, lo que hace que tanto su volumen como el tiempo de búsqueda en él sean más, pero no arroja ningún resultado. Ellos mismos dejaron un rastrillo, oops ...La dirección de optimización es obvia: simplemente elimine el campo de fecha de todos los índices en las tablas particionadas. ¡Con nuestros volúmenes, la ganancia es de aproximadamente 1 TB / semana !Y ahora notemos que este terabyte todavía tenía que escribirse de alguna manera. Es decir, ¡también tenemos que cargar menos disco ahora ! En esta imagen, el efecto obtenido de la limpieza, al que dedicamos una semana, es claramente visible: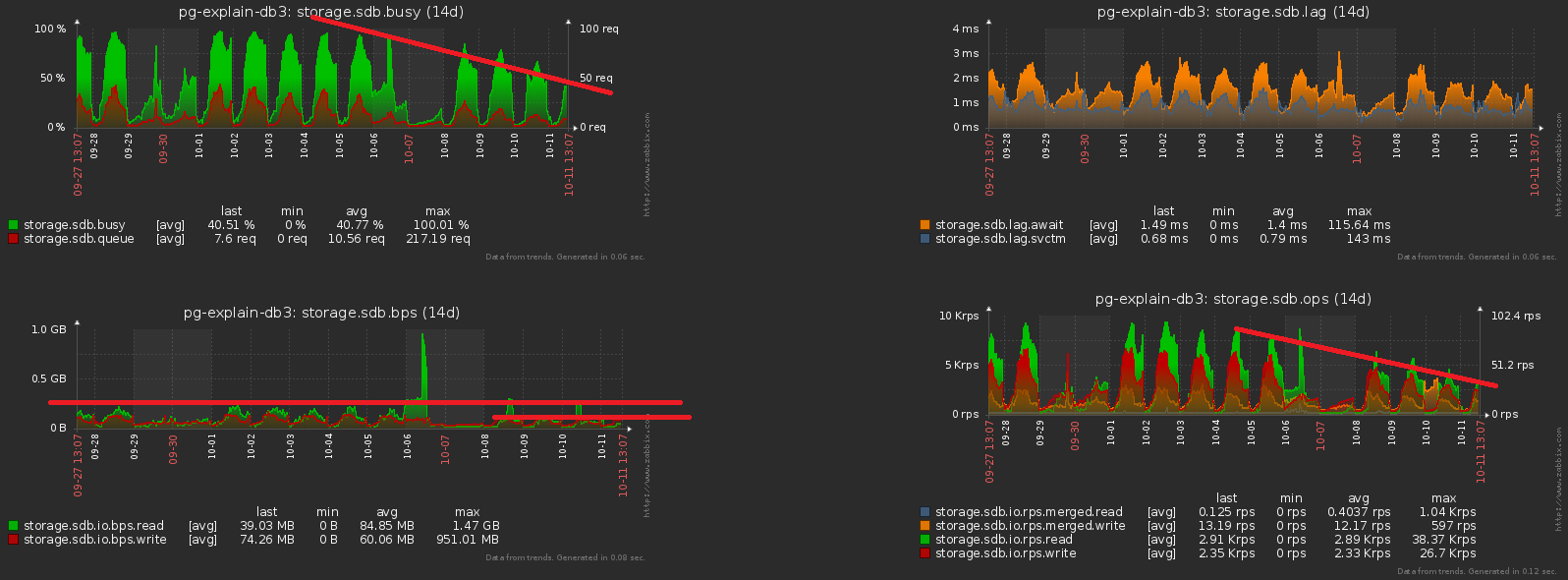
# 3 "Manchar" la carga máxima
Uno de los grandes problemas de los sistemas cargados es la sincronización excesiva de algunas operaciones que no lo requieren. A veces "porque no se dieron cuenta", a veces "fue más fácil", pero tarde o temprano tienes que deshacerte de él.Acercamos la imagen anterior, y vemos que el disco "tiembla" con una carga con una doble amplitud entre muestras vecinas, lo que obviamente no debería ser "estadísticamente" con tantas operaciones: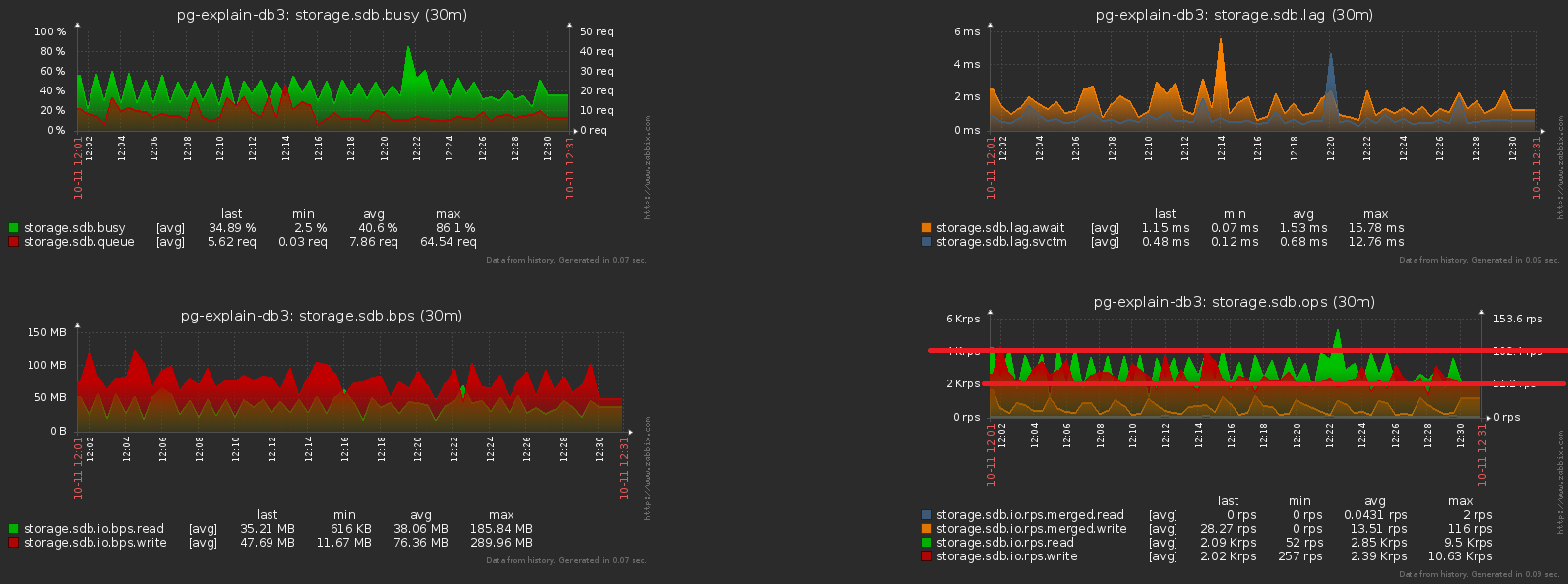 lograr esto es bastante simple. Ya se han iniciado casi 1000 servidores para el monitoreo , cada uno es procesado por una secuencia lógica separada, y cada secuencia descarga la información acumulada para enviarla a la base de datos con cierta frecuencia, algo como esto:
lograr esto es bastante simple. Ya se han iniciado casi 1000 servidores para el monitoreo , cada uno es procesado por una secuencia lógica separada, y cada secuencia descarga la información acumulada para enviarla a la base de datos con cierta frecuencia, algo como esto:setInterval(sendToDB, interval)
El problema aquí radica precisamente en el hecho de que todos los hilos comienzan aproximadamente al mismo tiempo , por lo que los tiempos de envío para ellos casi siempre coinciden "al punto". ¡Vaya! No. 2 ...Afortunadamente, esto se corrige con bastante facilidad agregando un lapso de tiempo "aleatorio" :setInterval(sendToDB, interval * (1 + 0.1 * (Math.random() - 0.5)))
# 4. Almacenamiento en caché, esa necesidad puede ser
El tercer problema tradicional de alta carga es la falta de caché donde podría estar.Por ejemplo, hicimos posible analizar el desglose de los nodos del plan (todos estos Seq Scan on users), pero inmediatamente olvidamos que, en general, son lo mismo, se han olvidado.No, por supuesto, no se escribe nada en la base de datos repetidamente, esto corta el gatillo con INSERT ... ON CONFLICT DO NOTHING. Pero los datos no llegan a la base de todos modos, y tienes que hacer una lectura adicional para verificar el conflicto . ¡Vaya! No. 3 ...La diferencia en la cantidad de registros enviados a la base de datos antes / después de habilitar el almacenamiento en caché es obvia: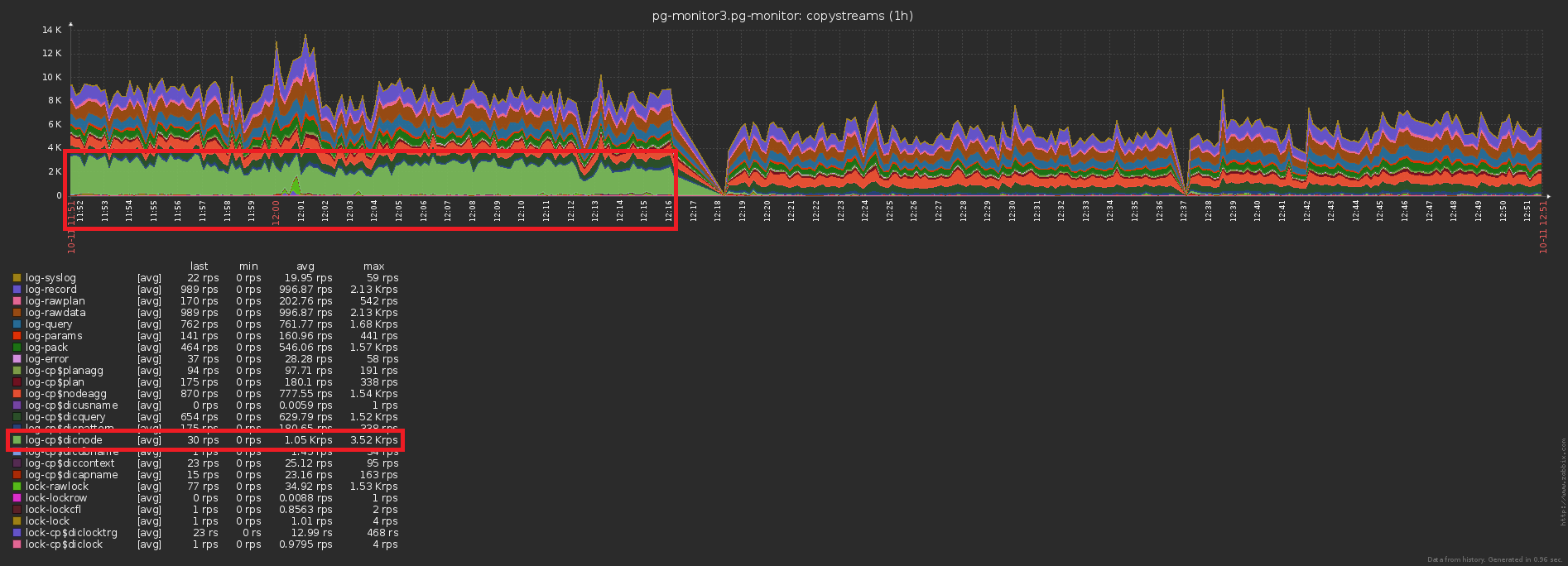 y esta es una caída concomitante en la carga de almacenamiento:
y esta es una caída concomitante en la carga de almacenamiento:
Total
Terabyte por día solo suena aterrador. Si hace todo bien, esto es solo 2 ^ 40 bytes / 86400 segundos = ~ 12.5MB / s , que incluso los tornillos IDE de escritorio tenían. :)Pero en serio, incluso con una "distorsión" de la carga durante diez veces durante el día, puede satisfacer fácilmente las posibilidades de los SSD modernos.