¿Qué le decimos al dios de la muerte? - Hoy no.
Sirio Trout, serie de televisión Juego de tronos.¿Qué tan peligroso es el coronavirus COVID-19? ¿Cuántas personas morirán de coronavirus en el mundo? ¿Y cuánto en Rusia? ¿Son realmente necesarias medidas estrictas para combatir el coronavirus en la mayoría de los países del mundo? ¿Qué causará más daño: la muerte de personas por coronavirus o el declive económico causado por medidas restrictivas?Para responder a estas preguntas urgentes, es necesario llevar a cabo un modelo matemático y predecir el daño del coronavirus para países individuales y para el mundo en general. La construcción de tales pronósticos está dedicada a este artículo.Para hacer que el material sea accesible para todos los lectores, al comienzo del artículo nos concentraremos en análisis cualitativos y bellas imágenes. Y al final, para aquellos interesados, les daremos el código fuente para los cálculos realizados en Python.
Minuto de atención ovni
La pandemia COVID-19, una infección respiratoria aguda potencialmente grave causada por el coronavirus SARS-CoV-2 (2019-nCoV), se ha anunciado oficialmente en el mundo. Hay mucha información sobre Habré sobre este tema; recuerde siempre que puede ser confiable / útil, y viceversa.
Le instamos a que sea crítico con cualquier información publicada.
Lávese las manos, cuide a sus seres queridos, quédese en casa siempre que sea posible y trabaje de forma remota.
Leer publicaciones sobre: coronavirus | trabajo remoto
Contando solo la muerte
Tenga en cuenta que evaluaremos el daño de COVID-19 en el número de muertes humanas asociadas con esta enfermedad. Una gran parte del artículo se dedicará a pronosticar el número de muertes por coronavirus. Generalmente nos negamos a considerar el número de pacientes con coronavirus y predecir su número. Hay varias razones para esto. Lo principal es que es imposible comparar estadísticas sobre el número de casos de COVID-19 en diferentes países. En algunos países, los métodos de prueba rápida están disponibles mucho más que en otros. En algunos países, se realiza un cribado casi universal de la población, mientras que en otros solo se controlan las personas con síntomas graves. Dado que en un número significativo de casos, la enfermedad es casi asintomática, vemos una gran propagación en el número de muertes entre pacientes: de menos del 0,5% a más del 3,5%.Lo más probable es que la dispersión en los datos de mortalidad se deba principalmente a la detección de casos de COVID-19.Las estadísticas de mortalidad en este caso parecen mucho más confiables. Naturalmente, podemos encontrar tanto una subestimación del número de muertes, cuando la causa de la muerte no se indica como un coronavirus, sino una enfermedad concomitante, y viceversa, sobreestimación, cuando COVID-19 se diagnostica incorrectamente, y una persona muere, por ejemplo, de gripe estacional. Sin embargo, podemos esperar que las estadísticas sobre muertes sean más confiables, porque Una enfermedad asintomática con un alto grado de probabilidad generalmente puede pasar por la atención de especialistas, y los médicos se ven obligados a analizar cada caso de muerte.También notamos que el daño real a la sociedad es causado por la muerte de sus miembros, y no por una enfermedad leve que pasa relativamente rápido.¿Creías que el mundo está gobernado por un expositor? ¡Y no!
Tan pronto como comenzamos a predecir el número de muertes, nos encontramos inmediatamente con el primer mito: decenas o incluso cientos de millones de personas morirán a causa del coronavirus. Este mito se basa en la creencia de que el mundo está gobernado por un expositor. Echa un vistazo a la tabla.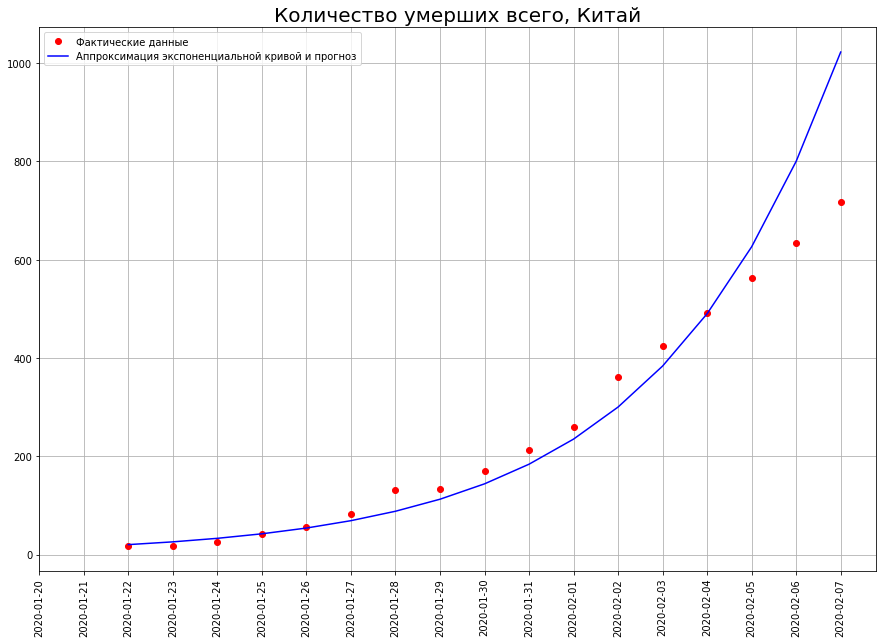 Muestra el número de muertes por COVID-19 en China a partir del 7 de febrero. Si construimos un pronóstico basado en este gráfico usando una función exponencial, ¡obtenemos que para el 29 de febrero, 50 millones de personas deberían haber muerto en China!
Muestra el número de muertes por COVID-19 en China a partir del 7 de febrero. Si construimos un pronóstico basado en este gráfico usando una función exponencial, ¡obtenemos que para el 29 de febrero, 50 millones de personas deberían haber muerto en China! ¿Y cuántos murieron realmente? 2837 personas. ¿Por qué una diferencia tan colosal?La cuestión es que el mundo no está gobernado por un expositor, sino por una curva logística.A diferencia del expositor, la curva logística no pasa no solo en la escuela, sino incluso en las principales universidades técnicas (por ejemplo, en el Departamento de Física de la Universidad Estatal de Moscú y en el PhysTech). Por lo tanto, los físicos y técnicos en general a menudo no tienen idea al respecto.Sin embargo, una gran cantidad de fenómenos en economía, biología, sociología, ciencia y tecnología se están desarrollando de acuerdo con este modelo matemático. Echemos un vistazo más de cerca. Aqui esta ella. El tiempo se representa en el eje xy en y el número que caracteriza los fenómenos estudiados por nosotros (en nuestro caso, el número de muertes por coronavirus).
¿Y cuántos murieron realmente? 2837 personas. ¿Por qué una diferencia tan colosal?La cuestión es que el mundo no está gobernado por un expositor, sino por una curva logística.A diferencia del expositor, la curva logística no pasa no solo en la escuela, sino incluso en las principales universidades técnicas (por ejemplo, en el Departamento de Física de la Universidad Estatal de Moscú y en el PhysTech). Por lo tanto, los físicos y técnicos en general a menudo no tienen idea al respecto.Sin embargo, una gran cantidad de fenómenos en economía, biología, sociología, ciencia y tecnología se están desarrollando de acuerdo con este modelo matemático. Echemos un vistazo más de cerca. Aqui esta ella. El tiempo se representa en el eje xy en y el número que caracteriza los fenómenos estudiados por nosotros (en nuestro caso, el número de muertes por coronavirus).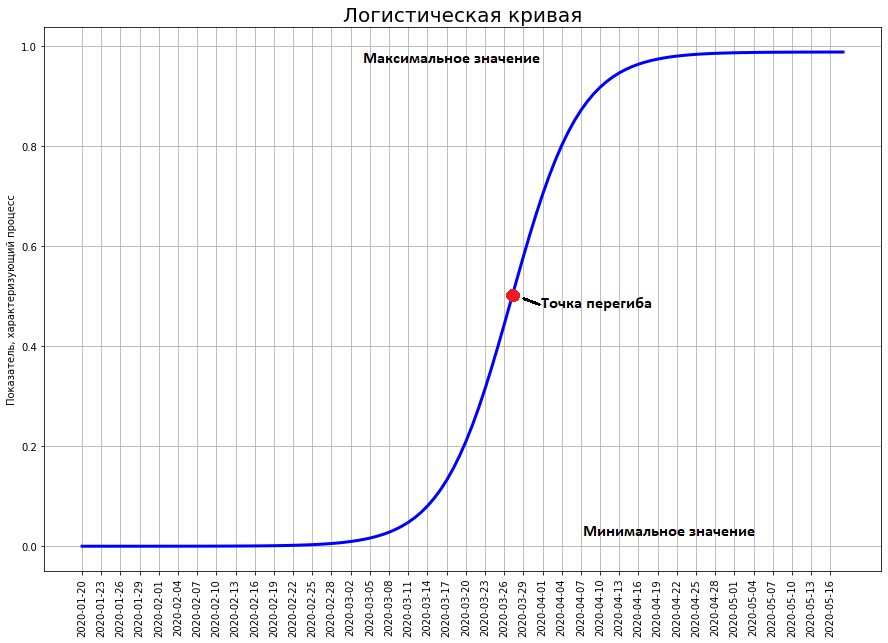
Curva insidiosa que rompe todo el bombo
La curva logística muestra la transición entre dos estados estables. El estado inferior se considera tradicionalmente igual a cero. El estado superior es el máximo que, en principio, puede alcanzar el fenómeno investigado. La curva se acerca a ella de manera arbitraria, pero nunca alcanza su valor máximo.El punto más importante en la curva es el punto de inflexión. Se encuentra exactamente en el medio entre el mínimo y el máximo. Es en este punto que la tasa de crecimiento máxima de la curva. Pero se produce una inflexión en él. Hasta este punto, el crecimiento de la curva solo se acelera. Después, solo se desvanece.Por lo general, al principio nadie nota un cierto fenómeno (ya que el coronavirus no se notó hasta finales de enero). En este punto, el valor de la curva está cerca de cero. Poco a poco, el fenómeno está creciendo, comienzan a notarlo, surge una exageración a su alrededor. El bombo puede ser tanto positivo (como, por ejemplo, en el momento del vuelo de Gagarin, las personas de todo el mundo se enfermaron de espacio) como negativo (la situación con el coronavirus actual). En el momento de la exageración, todos predicen que el fenómeno adquirirá proporciones increíbles y trastornará el mundo. Entonces, en el momento del vuelo de Gagarin, incluso los profesionales pensaban que la conquista del sistema solar ocurriría en el siglo XX. Y no esperaban en absoluto que todos los éxitos de la astronáutica terminaran en 1969 con el aterrizaje de un hombre en la luna.Es en el momento de la exageración máxima que la curva alcanza la mitad de su máximo futuro. Luego, el crecimiento se desvanece y el fenómeno no justifica por completo las esperanzas puestas en él (ni los temores).Curva logística china
Veamos qué pasó en China.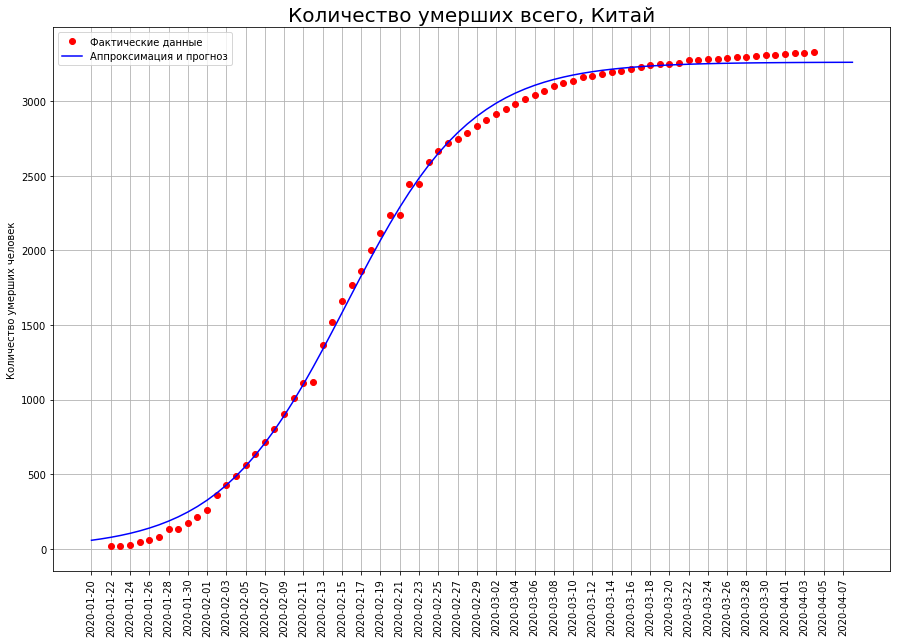 En el gráfico a continuación, los puntos rojos indican el número de muertes por el virus en una fecha determinada. La curva azul es una curva logística que se aproxima a datos reales. Vemos que los datos recaen casi a la perfección. El siguiente gráfico muestra el número de muertes que ocurrieron en una fecha específica. De hecho, esta es la diferencia entre los valores de la curva logística para hoy y para ayer. Desde un punto de vista matemático, esta es la primera derivada de la curva logística.
En el gráfico a continuación, los puntos rojos indican el número de muertes por el virus en una fecha determinada. La curva azul es una curva logística que se aproxima a datos reales. Vemos que los datos recaen casi a la perfección. El siguiente gráfico muestra el número de muertes que ocurrieron en una fecha específica. De hecho, esta es la diferencia entre los valores de la curva logística para hoy y para ayer. Desde un punto de vista matemático, esta es la primera derivada de la curva logística.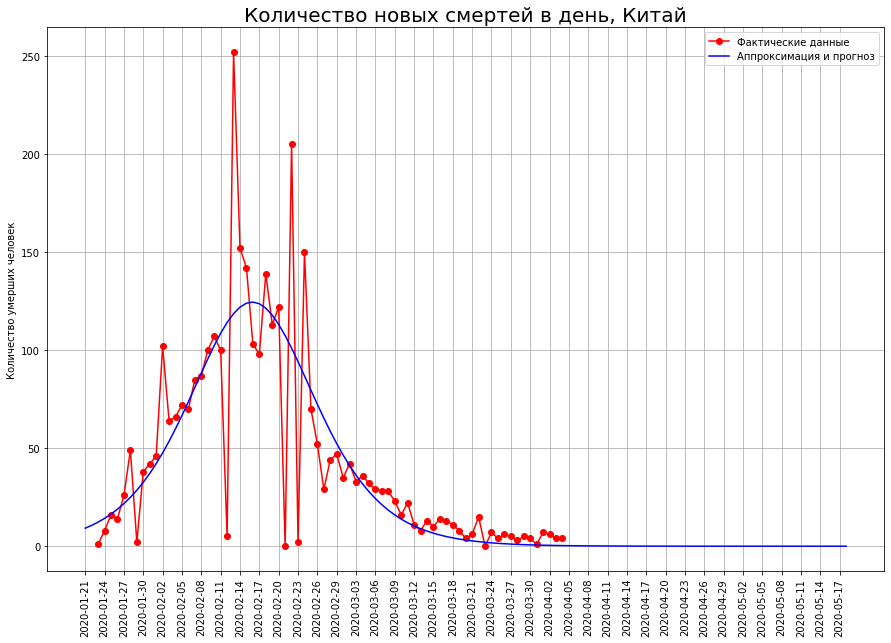 Vemos que al principio el número de nuevas muertes está creciendo casi exponencialmente. Luego, el crecimiento comienza a disminuir, la curva de nuevas muertes alcanza un máximo en el punto de inflexión, cuando la curva logística alcanza la mitad de su valor máximo. Luego, el número de nuevas muertes disminuye y se apresura a cero. Los puntos rojos indican nuevas muertes, la curva azul es la derivada de la curva logística que se aproxima a ellas.Tenga en cuenta que la curva logística es simétrica sobre el punto de su inflexión, y su primera derivada es relativa a la línea vertical que pasa por este punto. También observamos que los datos reales se encuentran idealmente en la curva logística, pero "bailan" en relación con su primera derivada. El hecho es que la tasa de mortalidad en un punto está sujeta a una gran dispersión, y la tasa de mortalidad total es la suma de dichos indicadores. Se suaviza de acuerdo con el teorema del límite central.Entonces, vemos que la curva logística se puede usar efectivamente para predecir muertes por coronavirus. Una propiedad importante aquí es su simetría. Cuando se alcanza el punto de inflexión, podemos restaurar la otra mitad con alta precisión desde la mitad de la curva.A su vez, para determinar si se alcanza el punto de inflexión, solo necesita mirar el gráfico de la primera derivada. Tan pronto como cayó, se alcanzó el punto correspondiente.
Vemos que al principio el número de nuevas muertes está creciendo casi exponencialmente. Luego, el crecimiento comienza a disminuir, la curva de nuevas muertes alcanza un máximo en el punto de inflexión, cuando la curva logística alcanza la mitad de su valor máximo. Luego, el número de nuevas muertes disminuye y se apresura a cero. Los puntos rojos indican nuevas muertes, la curva azul es la derivada de la curva logística que se aproxima a ellas.Tenga en cuenta que la curva logística es simétrica sobre el punto de su inflexión, y su primera derivada es relativa a la línea vertical que pasa por este punto. También observamos que los datos reales se encuentran idealmente en la curva logística, pero "bailan" en relación con su primera derivada. El hecho es que la tasa de mortalidad en un punto está sujeta a una gran dispersión, y la tasa de mortalidad total es la suma de dichos indicadores. Se suaviza de acuerdo con el teorema del límite central.Entonces, vemos que la curva logística se puede usar efectivamente para predecir muertes por coronavirus. Una propiedad importante aquí es su simetría. Cuando se alcanza el punto de inflexión, podemos restaurar la otra mitad con alta precisión desde la mitad de la curva.A su vez, para determinar si se alcanza el punto de inflexión, solo necesita mirar el gráfico de la primera derivada. Tan pronto como cayó, se alcanzó el punto correspondiente.¿Cómo terminará la catástrofe italiana?
Volvamos nuestra visión de los tres países a la letra "I": Italia, Irán y España. Al observar las curvas de muerte en una fecha específica, vemos que, muy probablemente, el pico de la catástrofe ha pasado allí, y es hora de hacer un balance.

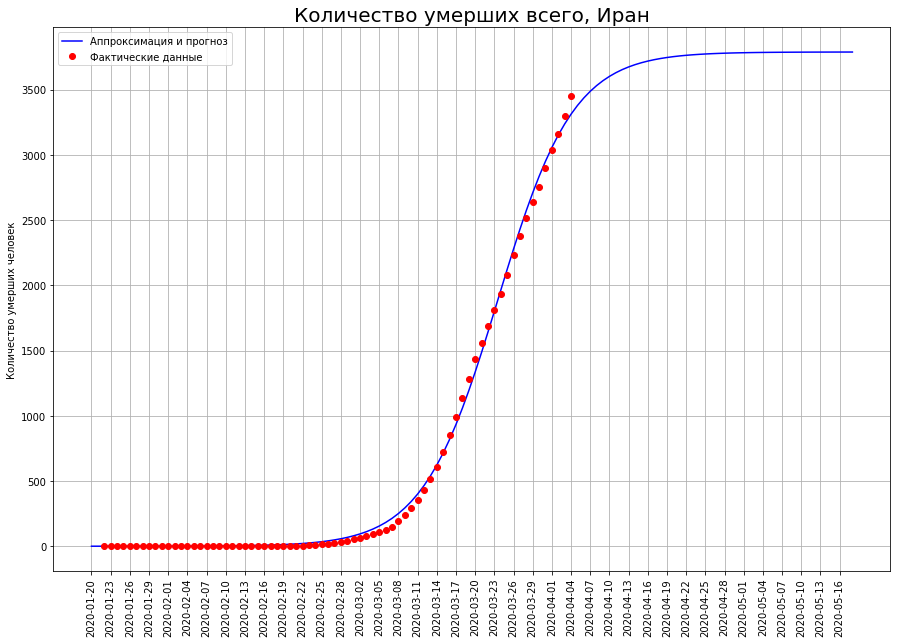
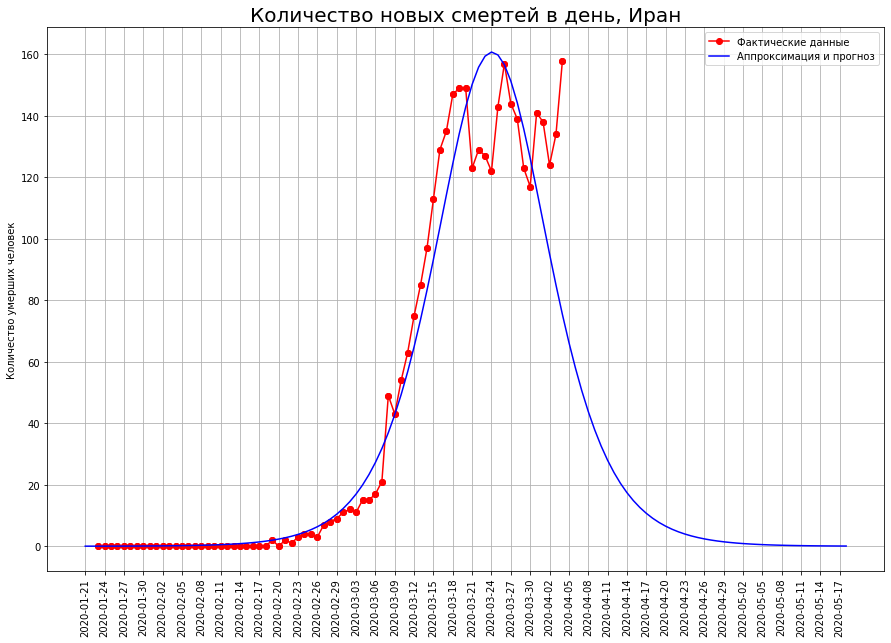
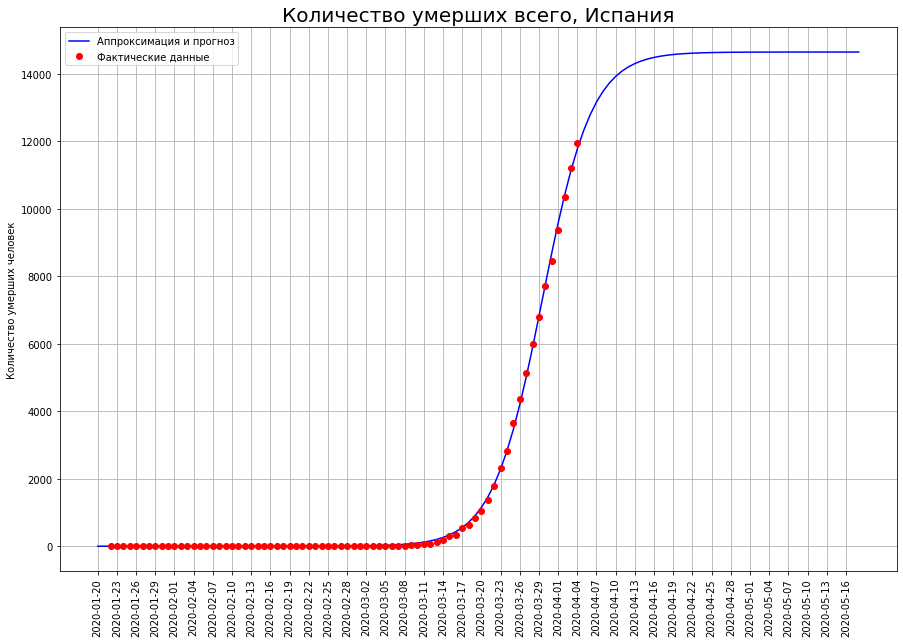
 Según nuestras previsiones, solo COVID-19 morirá:en Italia, unas 19 mil personas,en Irán, unas 4 mil personas,en España, unas 15 mil personas.
Según nuestras previsiones, solo COVID-19 morirá:en Italia, unas 19 mil personas,en Irán, unas 4 mil personas,en España, unas 15 mil personas.A medio camino de la mortalidad final
La epidemia en Alemania parece haber alcanzado su punto máximo y el número total de muertes por coronavirus en este país será de aproximadamente 2.600 personas.
 En países como los Países Bajos, Suiza y Bélgica, los modelos matemáticos muestran que la epidemia se encuentra en un punto de inflexión. Si esto es así, entonces el número esperado de muertes en ellos:en los Países Bajos, alrededor de 2.5 mil personas,en Suiza, alrededor de 1.1 mil personas,en Bélgica, alrededor de 2.2 mil personas.
En países como los Países Bajos, Suiza y Bélgica, los modelos matemáticos muestran que la epidemia se encuentra en un punto de inflexión. Si esto es así, entonces el número esperado de muertes en ellos:en los Países Bajos, alrededor de 2.5 mil personas,en Suiza, alrededor de 1.1 mil personas,en Bélgica, alrededor de 2.2 mil personas.



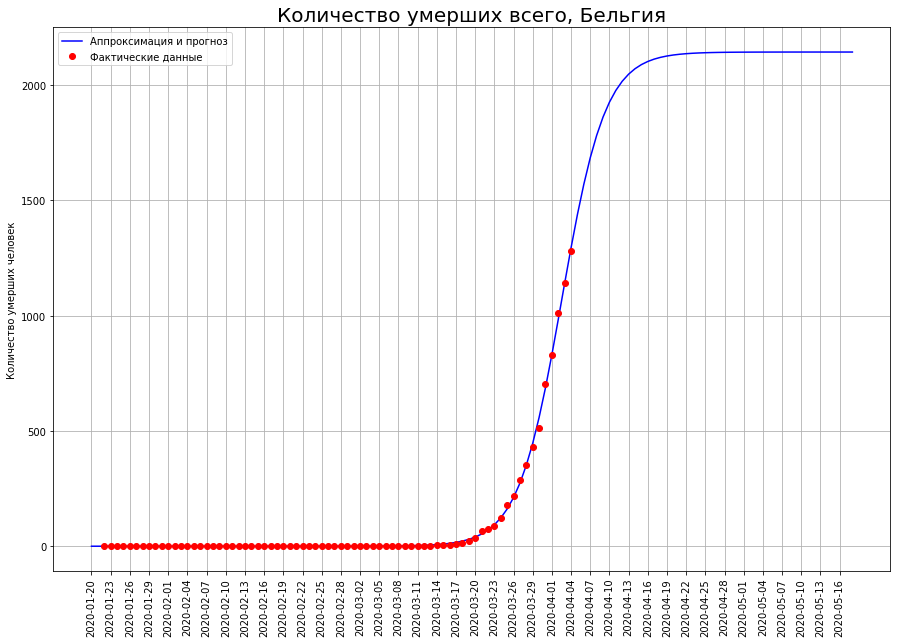
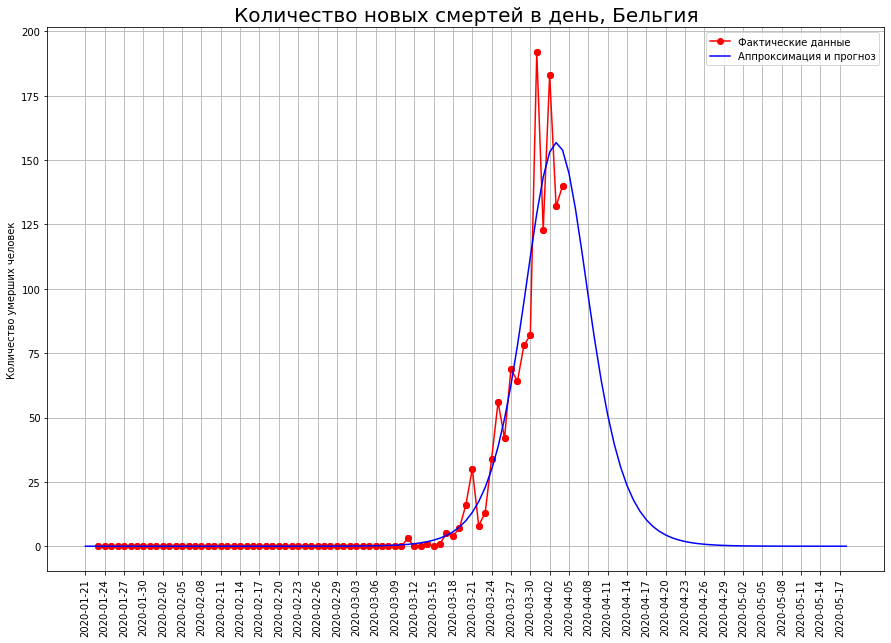
Para alguien, es solo el comienzo
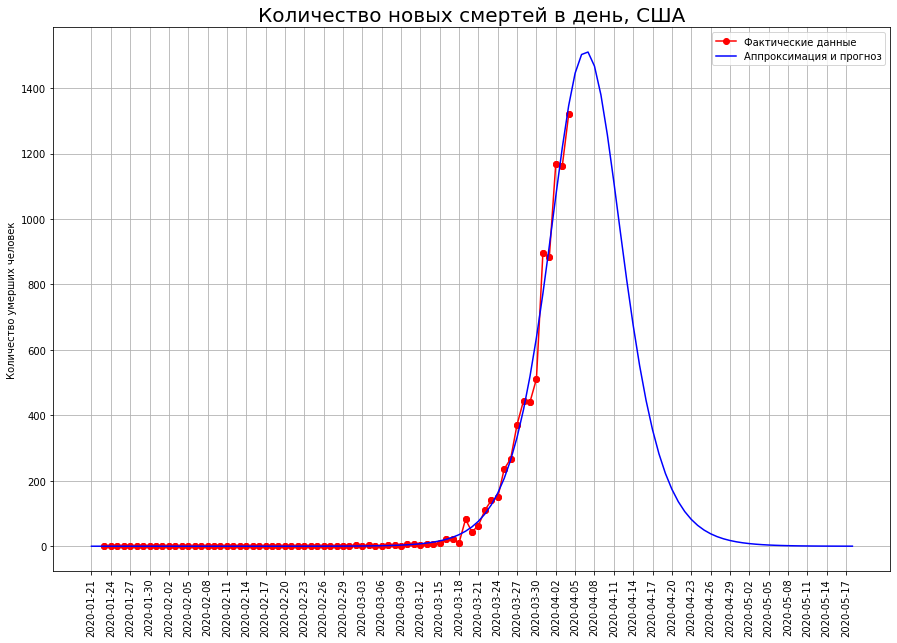
En los EE. UU., El punto de inflexión aún no se ha superado, por lo que el pronóstico para ellos se puede ajustar significativamente. Actualmente, son 23 mil personas.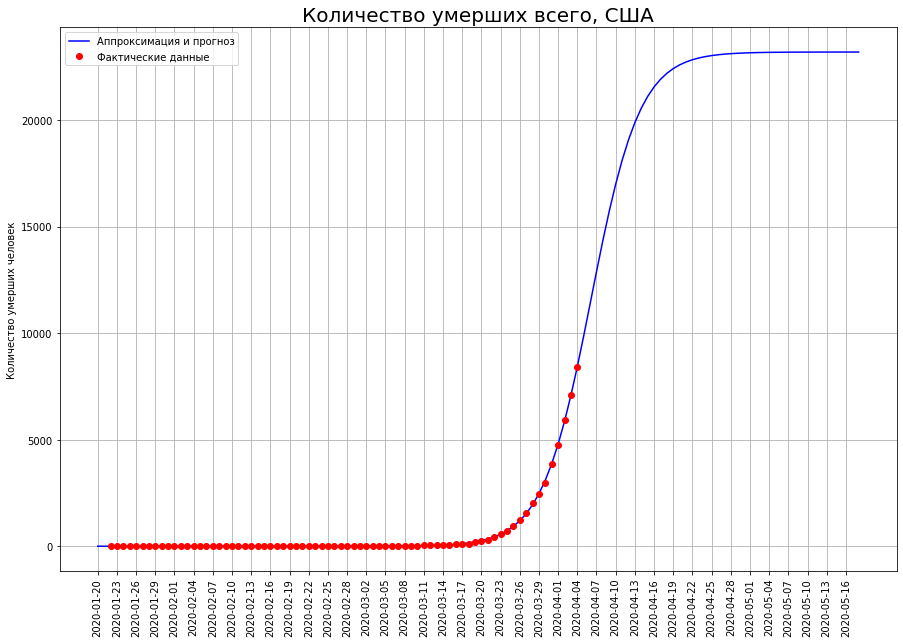
¿Es el Reino Unido un nuevo epicentro de la tragedia?
Finalmente, sigue habiendo una gran incertidumbre para que los dos países lleguen al punto de inflexión. Estos son el Reino Unido y Francia.

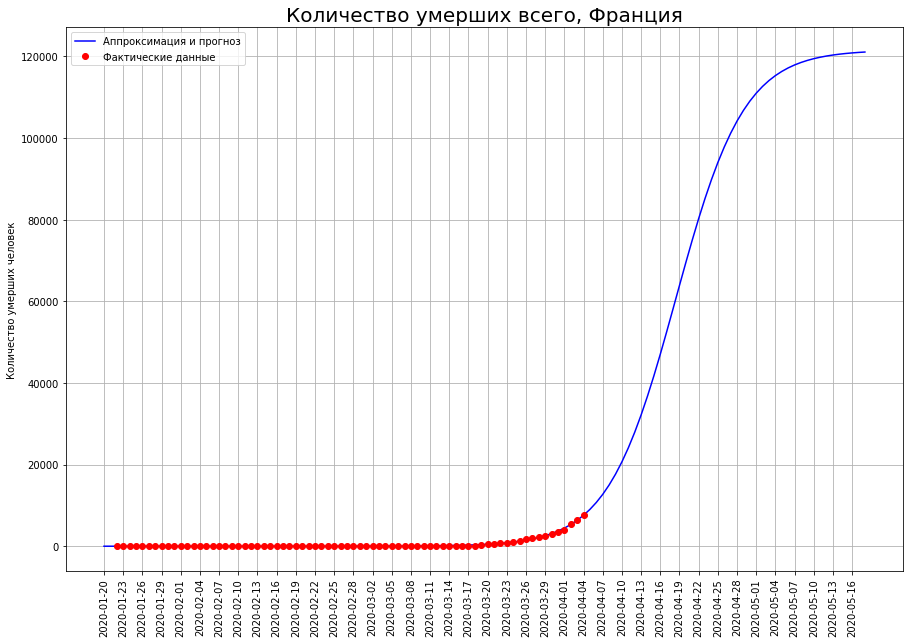
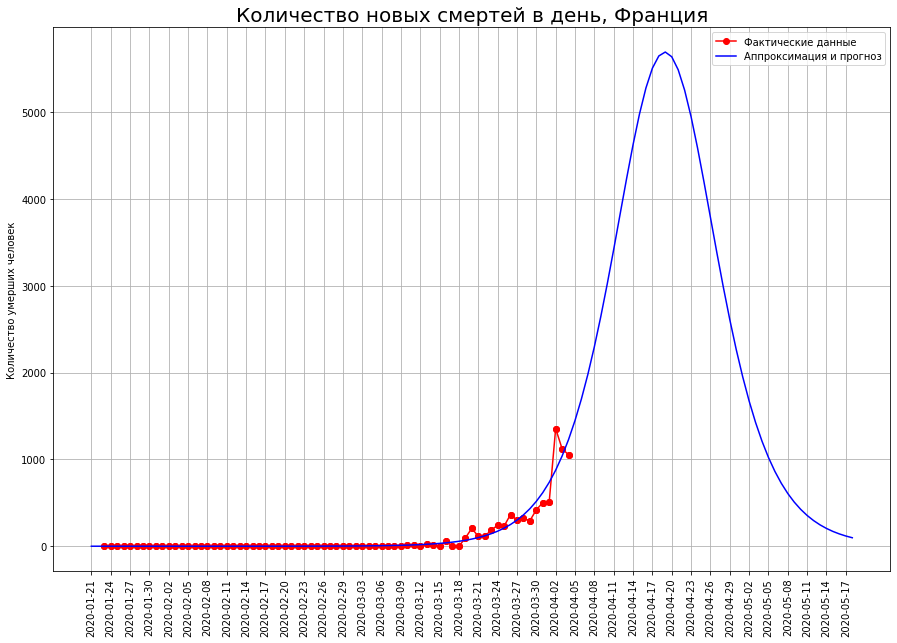 Las previsiones del número final de muertes en ellos aumentan constantemente. Actualmente comprenden:
Las previsiones del número final de muertes en ellos aumentan constantemente. Actualmente comprenden:- en el Reino Unido - unas 33 mil personas
- en Francia, alrededor de 12 mil personas.
El autor espera que estos pronósticos sean el resultado de fluctuaciones aleatorias, y en los próximos días se ajustarán a la baja.De particular preocupación para el autor es el Reino Unido. Según los datos al 25 de marzo, el autor predijo la mortalidad en este país en el nivel de 1 mil personas, según los datos a partir del 01.04, en el nivel de 8 mil, ahora el pronóstico muestra ya 33 mil. Las previsiones para ningún otro país tienen tanta volatilidad.Quizás el epicentro de la tragedia de las muertes por coronavirus se está trasladando gradualmente a Gran Bretaña. También es posible que el desarrollo de la situación en el país esté conectado con la política inicialmente irresponsable de Boris Johnson, quien hasta hace poco se negó a imponer restricciones estrictas y esperaba "la inmunización del rebaño". En este caso, el autor espera que los ciudadanos, a quienes Johnson expresó tan irrespetuosamente, le recuerden esta política en las próximas elecciones, sino más bien extraordinarias.Pronóstico para Rusia
Dado que la epidemia en Rusia recién comienza, no será posible predecir el número de muertes utilizando la curva logística. A continuación, utilizaremos un método de pronóstico diferente.¿Y qué a escala global?
Es hora de hacer un pronóstico para todo el mundo.
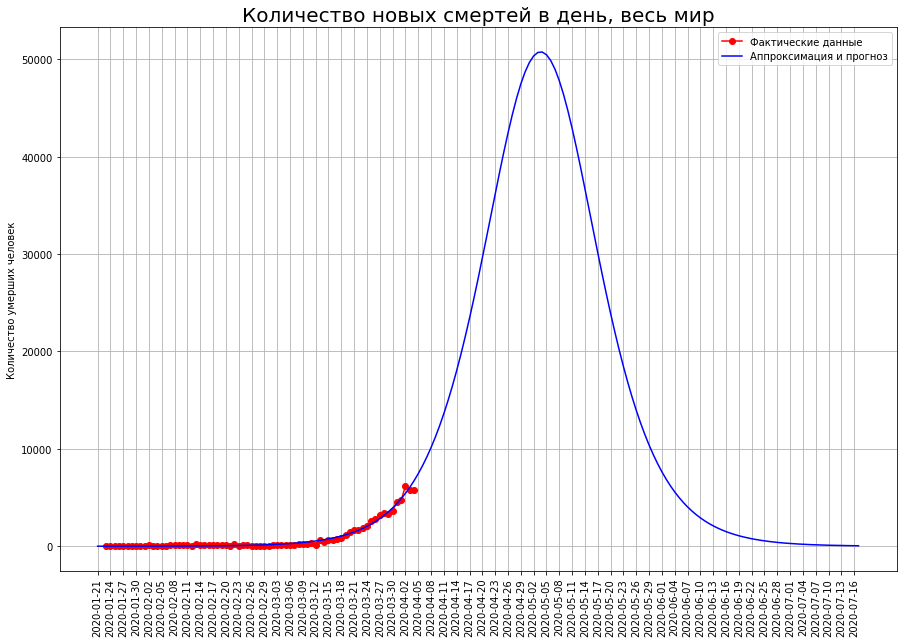 La curva logística que construimos da los siguientes resultados: el pico de la crisis ocurrirá en los primeros diez días de mayo y la epidemia terminará a mediados de julio. Matará a aproximadamente 1 millón 800 mil personas.Dado que la epidemia a escala global solo se está agravando, un pronóstico basado en una curva logística puede dar un resultado incorrecto, por lo que utilizaremos un método de pronóstico alternativo.Considere los países para los cuales hicimos pronósticos.
La curva logística que construimos da los siguientes resultados: el pico de la crisis ocurrirá en los primeros diez días de mayo y la epidemia terminará a mediados de julio. Matará a aproximadamente 1 millón 800 mil personas.Dado que la epidemia a escala global solo se está agravando, un pronóstico basado en una curva logística puede dar un resultado incorrecto, por lo que utilizaremos un método de pronóstico alternativo.Considere los países para los cuales hicimos pronósticos.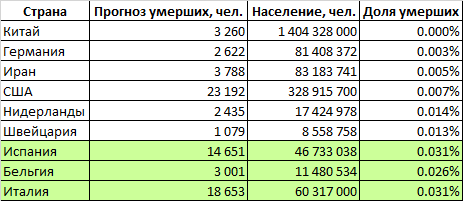 La tabla define la proporción de la población de estos países que morirá a causa del coronavirus (Gran Bretaña y Francia están temporalmente excluidas debido a la alta incertidumbre de los pronósticos). Vemos que los dos grupos de países son significativamente diferentes. En países como Italia, España y Bélgica, la mortalidad se proyecta en 0.029% de la población. En un grupo de países más próspero (China, Alemania, Irán, EE. UU., Países Bajos, Suiza), se espera que la tasa de mortalidad sea alrededor de 0.007%, 4 veces menor.Se puede suponer que el mundo en su conjunto se caracterizará por una mayor tasa de mortalidad. El hecho es que en nuestro análisis examinamos países relativamente ricos con gobiernos capaces que tienen recursos financieros y organizativos para hacer frente a la epidemia. Pero en la Tierra hay muchos estados que tienen capacidades mucho más modestas, tanto financiera como organizativamente. Muchos de estos países están muy densamente poblados. Se puede suponer que en estos países la epidemia recogerá incluso un mayor porcentaje de víctimas que en los ricos Italia, España y Bélgica. Por otro lado, la proporción de la población de edad avanzada en dichos países es menor, lo que reduce la mortalidad potencial.Si estimamos la mortalidad mundial al nivel del peor grupo de países, aproximadamente 2 millones 100 mil personas morirán en el mundo. Si usa valores promedio, entonces alrededor de 900 mil.Nuestro pronóstico pesimista para el número de muertes en el mundo, calculado sobre la base de la proporción de la población fallecida, fue sorprendentemente cercano al pronóstico calculado sobre la base de la curva logística.Por lo tanto, 1-2 millones de personas morirán en el mundo, y la cifra de 2 millones es más probable.
La tabla define la proporción de la población de estos países que morirá a causa del coronavirus (Gran Bretaña y Francia están temporalmente excluidas debido a la alta incertidumbre de los pronósticos). Vemos que los dos grupos de países son significativamente diferentes. En países como Italia, España y Bélgica, la mortalidad se proyecta en 0.029% de la población. En un grupo de países más próspero (China, Alemania, Irán, EE. UU., Países Bajos, Suiza), se espera que la tasa de mortalidad sea alrededor de 0.007%, 4 veces menor.Se puede suponer que el mundo en su conjunto se caracterizará por una mayor tasa de mortalidad. El hecho es que en nuestro análisis examinamos países relativamente ricos con gobiernos capaces que tienen recursos financieros y organizativos para hacer frente a la epidemia. Pero en la Tierra hay muchos estados que tienen capacidades mucho más modestas, tanto financiera como organizativamente. Muchos de estos países están muy densamente poblados. Se puede suponer que en estos países la epidemia recogerá incluso un mayor porcentaje de víctimas que en los ricos Italia, España y Bélgica. Por otro lado, la proporción de la población de edad avanzada en dichos países es menor, lo que reduce la mortalidad potencial.Si estimamos la mortalidad mundial al nivel del peor grupo de países, aproximadamente 2 millones 100 mil personas morirán en el mundo. Si usa valores promedio, entonces alrededor de 900 mil.Nuestro pronóstico pesimista para el número de muertes en el mundo, calculado sobre la base de la proporción de la población fallecida, fue sorprendentemente cercano al pronóstico calculado sobre la base de la curva logística.Por lo tanto, 1-2 millones de personas morirán en el mundo, y la cifra de 2 millones es más probable.¿Qué pasará con la patria y con nosotros?
En cuanto a Rusia, con una población de 148 millones de personas, el pronóstico optimista (basado en el promedio de todos los países, excepto los tres principales forasteros) es de 10 mil personas. Y pesimista (basado en la mortalidad a nivel de Italia, España y Bélgica): 40 mil.La cifra de 10 mil es mucho más probable. El hecho es que Rusia tiene varios factores favorables: baja densidad de población, grandes distancias entre grandes ciudades, flujos de migración relativamente bajos entre regiones (excluyendo la región metropolitana), decisión, adecuación y oportunidad de las acciones de las autoridades para combatir la epidemia. Estos factores dan esperanza para evitar desarrollar la situación según la versión italiano-española-belga.En cuanto al momento de la finalización de la epidemia en Rusia, pasamos a la tabla a continuación. En él, representamos las curvas logísticas para diferentes países en un gráfico. En este caso, normalizamos todas las curvas de altura para que el valor máximo fuera uno, y combinamos el punto de inflexión, colocándolo en cero.El gráfico muestra que la epidemia termina en 40-60 días. Si tomamos el 30 de marzo como punto de partida, en Rusia la epidemia tendrá que terminar entre el 10 y el 30 de mayo.¿Están justificadas las víctimas?
Y finalmente, la última pregunta que se planteó al comienzo del artículo: ¿qué tan justificadas están las estrictas medidas de cuarentena tomadas por los gobiernos de la mayoría de los países del mundo?Alrededor de 58 millones de personas mueren cada año en el mundo. 2 millones que, según un pronóstico pesimista, morirán de un coronavirus, aumentarán esta cifra en un 3,5%. Por otro lado, la cuarentena mundial a gran escala amenaza con convertirse en la mayor crisis económica desde la Gran Depresión. Como resultado, decenas o incluso cientos de millones de personas permanecerán sin trabajo. Los ingresos de la población caerán, y muchos morirán de hambre o la incapacidad de pagar la atención médica.A menudo se expresan opiniones, incluso por parte de algunos líderes mundiales, de que sería mejor dejar a las personas a su suerte y no arruinar la economía. Al final, de 300 a 650 mil personas mueren de gripe estacional cada año, pero nadie toma medidas tan destructivas y restrictivas para la economía.Nuestro modelo nos permite establecer lo siguiente: COVID-19 no es una gripe estacional en absoluto. Este virus es incomparablemente más peligroso. El hecho es que el punto de inflexión de la curva logística no existe por sí mismo. Se ve muy afectado por las condiciones de la epidemia. El curso de cualquier epidemia se describe mediante una curva logística, pero las curvas logísticas son una familia completa. Recordamos que el punto de inflexión es exactamente la mitad de la curva máxima. Por lo tanto, cuanto más tarde pase el pico de mortalidad, mayor será el número final de muertes. Vimos que cerca del punto de inflexión la curva logística crece lo más rápido posible. Por lo tanto, si el pico de la enfermedad se pasa 10 días después, ¡el número de víctimas puede aumentar varias veces!Los pronósticos que recibimos para los puntos de inflexión de las curvas logísticas ya incluyen todas las medidas de cuarentena tomadas por los gobiernos de los países del mundo. Si no existieran tales medidas, los puntos de inflexión se alcanzarían mucho más tarde. En este caso, la mortalidad podría alcanzar el nivel de 0.4-0.5% de toda la población mundial.¿Por qué estimamos la tasa de mortalidad de una epidemia no controlada en 0.4-0.5% de la población? Suponemos que en este caso, de una forma u otra, toda la población de la Tierra estará enferma con el virus. Sin embargo, en un número significativo de personas, la enfermedad será asintomática. Por lo tanto, utilizamos estadísticas de países como Corea del Sur y Alemania, que lograron organizar la prueba más amplia posible de coronavirus en la población e identificar la mayoría de los casos reales. En otros países, en nuestra opinión, las estadísticas están distorsionadas precisamente porque el número de casos está muy subestimado. De ahí la tasa de mortalidad súper alta del 3,5%.0.4-0.5% de la población mundial es de 28-35 millones de personas. A pesar de todas las guerras que la humanidad ha librado en toda su historia, solo el número de pérdidas en la Segunda Guerra Mundial supera esta cifra. El hecho de que los gobiernos de la gran mayoría de los países del mundo hicieron sacrificios económicos sin precedentes en aras de salvar a la gente muestra cuánto ha crecido el precio de la vida humana en el mundo. Cuán difundidas son las ideas del humanismo y la prioridad de los intereses del individuo. Y esto inspira al autor con orgullo en la humanidad y la esperanza de un futuro mejor para toda la humanidad.El mayor inconveniente de este artículo
Y aquí está el mayor inconveniente de este artículo. Desafortunadamente, las estadísticas clásicas no nos proporcionan herramientas para estimar errores de pronóstico basados en una función logística. Esto se debe a la forma de la función, que tiene una inflexión. Si esta inflexión no fuera así, y la curva fuera monotónica, nosotros, con la ayuda de la transformación de Box-Cox, primero llevaríamos la función a una forma lineal. Después de eso, usando la ecuación de error para la regresión lineal, construiríamos el límite superior e inferior de los errores, y luego, usando la transformación inversa de Box-Cox, obtendríamos límites de error curvilíneos, sobre la base de los cuales construiríamos el pronóstico máximo y mínimo para el número de muertes por coronavirus.Por desgracia, las herramientas de la estadística clásica hacen imposible construir límites de error en el caso de una curva con una inflexión. Pero los métodos de aprendizaje automático pueden ayudarnos. En el próximo artículo, mostraré cómo se construyen los límites de los errores en este caso, y elaboraré los pronósticos mínimos y máximos para el número de muertes para cada país considerado anteriormente por separado, y para todo el mundo.Y ahora muchos códigos y números
Bueno, ahora, de hecho, las matemáticas para aquellos que quieren entender cómo llegamos a las conclusiones mencionadas anteriormente. Aquellos que no están interesados en cálculos aburridos no pueden seguir leyendo.Los cálculos se realizaron en Python en el entorno de Júpiter utilizando bibliotecas adicionales scipy, numpy, pandas, datetime. Para la visualización, utilizamos el paquete matplotlib.pyplot. Los datos iniciales sobre el número de muertes se obtuvieron en este enlace y se procesaron previamente en Excel. Información tomada a partir del 4 de abril. Aquí hay un enlace al archivo con la información de origen .Entonces, importamos las bibliotecas, que usaremos más adelante:import numpy as np
import matplotlib.pyplot as plt
%matplotlib inline
import pandas as pd
from IPython.display import display
import scipy as sp
from datetime import datetime
from scipy.optimize import minimize
Leemos los datos de origen y los convertimos en un objeto DataFrame. Las etiquetas variables se convierten en un objeto de marca de tiempo. En principio, podríamos restringirnos a simples matrices numpy, pero utilizamos un DataFrame para la comodidad de almacenar datos con su fecha correspondiente, y Timestamp para visualización, para mostrar estas fechas en gráficos.corona = pd.read_csv ('D: /coronavirus.csv',sep= ";")
corona.set_index (' Date ', inplace = True)
corona.index = pd.to_datetime (corona.index)
Luego, a partir de un solo DataFrame, creamos variables del tipo Serie que corresponden a la mortalidad total en cada país. X es una variable igual al número de día desde el comienzo del año. Lo necesitaremos cuando pronostiquemos.X = corona['X']
chi = corona['China']
fr = corona['France']
ir = corona['Iran']
it = corona['Italy']
sp = corona['Spain']
uk = corona['UK']
us = corona['US']
bg = corona['Belgium']
gm = corona['Germany']
nt = corona['Netherlands']
sw = corona['Switzerland']
tot = corona['Total']
Después de eso, calculamos matrices numpy simples para la mortalidad en una fecha específica. Tenga en cuenta que la longitud de dicha matriz es 1 menor que la longitud de la variable de la serie correspondiente.dchi = chi[1:].values - chi[:-1].values
dfr = fr[1:].values - fr[:-1].values
dit = it[1:].values - it[:-1].values
diran = ir[1:].values - ir[:-1].values
dsp = sp[1:].values - sp[:-1].values
duk = uk[1:].values - uk[:-1].values
dus = us[1:].values - us[:-1].values
dbg = bg[1:].values - bg[:-1].values
dgm = gm[1:].values - gm[:-1].values
dnt = nt[1:].values - nt[:-1].values
dsw = sw[1:].values - sw[:-1].values
dtot = tot[1:].values - tot[:-1].values
Introducimos una variable adicional para el pronóstico. Este es un conjunto que comienza el 20 de enero y termina en 180 días el 17 de julio. También creamos un objeto Timestamp correspondiente a esta matriz para firmar los ejes.X_long = np.arange(20, 200)
time_long = pd.date_range('2020-01-20', periods=180)
Definimos la función resLogistic, cuyo argumento de entrada es una matriz de 3 dígitos, y la salida es la suma de los cuadrados de la diferencia entre los valores de la curva logística y el número real de muertes por la epidemia en China.def resLogistic(coefficents):
A0 = coefficents[0]
A1 = coefficents[1]
A2 = coefficents[2]
teor = A0 / (1 + np.exp(A1 * (X.ravel() - A2)))
return np.sum((teor - chi) ** 2)
El número de muertes se toma en cada fecha como un total acumulado. La curva logística está determinada por 3 componentes del vector de entrada. El cero (el recuento de elementos de matriz en Python comienza desde cero) del componente es responsable del valor máximo, el primero caracteriza la tasa de crecimiento de la función, el segundo, la posición del punto de inflexión en el eje del tiempo.teor: el número de muertes por día, basado en el vector de parámetros de entrada, chi, el número real de muertes en China. La función devuelve la suma de las diferencias al cuadrado entre el valor teórico y el real.Ahora, utilizando el método de minimización de la biblioteca scipy.optimize, encontramos un vector que minimiza la suma de las desviaciones al cuadrado. La curva logística construida sobre la base de este vector es el pronóstico de mortalidad deseado realizado sobre la base del método de mínimos cuadrados.Agregamos que el método de minimización requiere un punto de partida. Lo seleccionamos en función de las propiedades de la función logística que conocemos (el máximo debería ser mayor que cualquier número empírico de muertes, y el punto de inflexión debería estar cerca del máximo de la curva dtot que caracteriza el número de nuevas muertes por día). Por lo general, los resultados del método de minimizar son independientes del punto de partida, pero hay excepciones.mimim.x son los valores del vector de minimización.minim = minimize(resLogistic, [3200, -.16, 46])
minim.x
Ahora mostramos el número real de muertes en el gráfico, aproximando su curva de pronóstico logístico, y también firmamos el eje del tiempo con fechas.plt.figure(figsize=(15,10))
teorChi = minim.x[0] / (1 + np.exp(minim.x[1] * (X_long - minim.x[2])))
plt.plot(X,chi,'ro', label=' ')
plt.plot(X_long[:80], teorChi[:80],'b', label=' ')
plt.xticks(X_long[:80][::2], time_long.date[:80][::2], rotation='90');
plt.title(' , ', Size=20);
plt.ylabel(' ')
plt.legend()
plt.grid()
En el gráfico inferior, graficamos la primera derivada de la curva logística seleccionada arriba (línea azul), así como la curva real de nuevas muertes (línea roja).plt.figure(figsize = (15,10))
plt.grid()
plt.title(' , ', Size=20);
plt.plot(X[1:], dchi, 'r', Marker='o', label=' ')
plt.xticks(X_long[1:120][::3], time_long.date[1:120][::3], rotation='90');
plt.plot(X_long[1:120], teorChi[1:120] - teorChi[:119],'b', label=' ')
plt.ylabel(' ')
plt.legend()
Realizamos cálculos similares para cada uno de los países mencionados en el artículo.Luego, el autor escribió un código no muy hermoso. Era necesario escribir una función para todos los países y pasar el número de muertes reales a través de los parámetros del método de minimizar. Pero el autor no tuvo tiempo para lidiar con este mecanismo, por lo que escribió su propia función para cada país, y dentro de la función presentó una apelación a una variable que contenía información sobre el número de muertes en un país determinado.A continuación se muestran los cálculos para Irán, Italia, España, EE. UU. Para restaurar los cálculos para otros países, creo que los lectores no serán difíciles.def resLogisticIr(coefficents):
A0 = coefficents[0]
A1 = coefficents[1]
A2 = coefficents[2]
teor = A0 / (1 + np.exp(A1 * (X.ravel() - A2)))
return np.sum((teor - ir) ** 2)
minim = minimize(resLogisticIr, [3200, -.16, 80])
minim.x
plt.figure(figsize=(15,10))
teorIr = minim.x[0] / (1 + np.exp(minim.x[1] * (X_long - minim.x[2])))
plt.plot(X_long[:120], teorIr[:120],'b', label=' ')
plt.xticks(X_long[:120][::3], time_long.date[:120][::3], rotation='90');
plt.title(' , ', Size=20);
plt.plot(X,ir,'ro', label=' ')
plt.grid()
plt.legend()
plt.ylabel(' ')
plt.figure(figsize = (15,10))
plt.grid()
plt.title(' , ', Size=20);
plt.plot(X[1:], diran, 'r', Marker='o', label=' ')
plt.plot(X[1:], diran, 'ro')
plt.xticks(X_long[1:120][::3], time_long.date[1:120][::3], rotation='90');
plt.plot(X_long[1:120], teorIr[1:120] - teorIr[:119],'b', label=' ')
plt.ylabel(' ')
plt.legend()
def resLogisticIt(coefficents):
A0 = coefficents[0]
A1 = coefficents[1]
A2 = coefficents[2]
teor = A0 / (1 + np.exp(A1 * (X.ravel() - A2)))
return np.sum((teor - it) ** 2)
minim = minimize(resLogisticIt, [3200, -.16, 46])
minim.x
plt.figure(figsize=(15,10))
teorIt = minim.x[0] / (1 + np.exp(minim.x[1] * (X_long - minim.x[2])))
plt.plot(X,it,'ro', label=' ')
plt.plot(X_long[:120], teorIt[:120],'b', label=' ')
plt.xticks(X_long[:120][::3], time_long.date[:120][::3], rotation='90');
plt.title(' , ', Size=20);
plt.ylabel(' ')
plt.grid()
plt.legend()
plt.figure(figsize = (15,10))
plt.grid()
plt.title(' , ', Size=20);
plt.plot(X[1:], dit, 'r', Marker='o', label=' ')
plt.xticks(X_long[1:120][::3], time_long.date[1:120][::3], rotation='90');
plt.plot(X_long[1:120], teorIt[1:120] - teorIt[:119],'b', label=' ')
plt.ylabel(' ')
plt.legend()
def resLogisticSp(coefficents):
A0 = coefficents[0]
A1 = coefficents[1]
A2 = coefficents[2]
teor = A0 / (1 + np.exp(A1 * (X.ravel() - A2)))
return np.sum((teor - sp) ** 2)
minim = minimize(resLogisticSp, [3200, -.16, 80])
minim.x
plt.figure(figsize=(15,10))
teorSp = minim.x[0] / (1 + np.exp(minim.x[1] * (X_long - minim.x[2])))
plt.plot(X_long[:120], teorSp[:120],'b', label=' ')
plt.xticks(X_long[:120][::3], time_long.date[:120][::3], rotation='90');
plt.title(' , ', Size=20);
plt.plot(X,sp,'ro', label=' ')
plt.grid()
plt.legend()
plt.ylabel(' ')
plt.figure(figsize = (15,10))
plt.grid()
plt.plot(X[1:], dsp, 'r', Marker='o', label=' ')
plt.plot(X[1:], dsp, 'ro')
plt.xticks(X_long[1:120][::3], time_long.date[1:120][::3], rotation='90');
plt.title(' , ', Size=20);
plt.plot(X_long[1:120], teorSp[1:120] - teorSp[:119],'b', label=' ')
plt.ylabel(' ')
plt.legend()
def resLogisticUs(coefficents):
A0 = coefficents[0]
A1 = coefficents[1]
A2 = coefficents[2]
teor = A0 / (1 + np.exp(A1 * (X.ravel() - A2)))
return np.sum((teor - us) ** 2)
minim = minimize(resLogisticUs, [3200, -.16, 100])
minim.x
plt.figure(figsize=(15,10))
teorUS = minim.x[0] / (1 + np.exp(minim.x[1] * (X_long - minim.x[2])))
plt.plot(X_long[:120], teorUS[:120],'b', label=' ')
plt.xticks(X_long[:120][::3], time_long.date[:120][::3], rotation='90');
plt.title(' , ', Size=20);
plt.plot(X,us,'ro', label=' ')
plt.grid()
plt.legend()
plt.ylabel(' ')
plt.figure(figsize = (15,10))
plt.grid()
plt.title(' , ', Size=20);
plt.plot(X[1:], dus, 'r', Marker='o', label=' ')
plt.plot(X[1:], dus, 'ro')
plt.xticks(X_long[1:120][::3], time_long.date[1:120][::3], rotation='90');
plt.plot(X_long[1:120], teorUS[1:120] - teorUS[:119],'b', label=' ')
plt.ylabel(' ')
plt.legend()