Muy a menudo, durante mis 15 años de experiencia como desarrollador de software y líder de equipo, me encuentro con lo mismo. La programación se convierte en una religión: rara vez alguien intenta introducir tecnología basada en una elección razonable, razonablemente, teniendo en cuenta las restricciones, la portabilidad, la evaluación del grado de apego al proveedor, el precio real, las perspectivas de la tecnología y la libertad de licencias. Los desarrolladores van a conferencias o leen publicaciones: comienzan a exagerar, y sus directores y gerentes de TI se alimentan no solo de historias de un futuro ágil y brillante en eventos, varios visionarios, ventas y consultores. Y resulta que las tecnologías estaban en el proyecto, sin tener en cuenta la conveniencia del desarrollo y la implementación, los requisitos no funcionales del proyecto, sino porque es exagerado y Google se usa a sí mismo,amazon recomienda (aunque sus vacantes dicen que ellos mismos no lo usan a menudo) o la gerencia de la compañía tomó la decisión más alta de implementar "esto".
Lo que afecta la elección de la base de datos.
Desde mi punto de vista, al elegir una base de datos, tengo que resolver al menos los siguientes compromisos:- procesamiento de transacciones en tiempo real o procesamiento analítico en línea
- escalable vertical u horizontalmente
- en el caso de una base distribuida - consistencia de datos / disponibilidad / resistencia de separación (teorema CAP)
- Un esquema de datos específico y restricciones en la base de datos o almacenamiento que no requieren un esquema de datos
- modelo de datos: clave-valor, jerárquico, gráfico, documento o relacional
- lógica de procesamiento lo más cercana posible a los datos o todo el procesamiento en la aplicación
- trabajar principalmente en RAM o con un subsistema de disco
- solución universal o especializada
- Utilizamos la experiencia existente en una base de datos que no es particularmente adecuada para los requisitos del proyecto o desarrollamos una nueva en capacitación adecuada pero no familiar, "sangre y sudor" (lo mismo se aplica no solo al desarrollo, sino también a la operación)
- incorporado o en otro proceso / red
- inconformista o retrógrado
A menudo obtenemos un "regalo" para la solución implementada:- Lenguaje de consulta "extranjero"
- la única API nativa para trabajar con la base de datos, lo que complicará la transición a otras bases de datos (se gastó tiempo, esfuerzo de equipo y presupuesto del proyecto)
- indisponibilidad de controladores para otras plataformas / idiomas / sistemas operativos
- falta de códigos fuente, descripciones del formato de datos en el disco (o prohibición de licencias de ingeniería inversa, especialmente Oracle con la coherencia con errores)
- crecimiento de costo de licencia año por año
- ecosistema propio y dificultad para encontrar especialistas
- , ,
La escala horizontal de los sistemas es bastante compleja y requiere la experiencia del equipo. Los desarrolladores experimentados son bastante caros en el mercado, las aplicaciones distribuidas son más difíciles de desarrollar, depurar y probar. Por lo tanto, si es posible cambiar el servidor a uno más potente y la cantidad de datos que permite el sistema, a menudo lo hacen. Ahora los servidores pueden tener terabytes de RAM y cientos de núcleos de procesador a bordo. Entonces, como nunca antes, es importante usar todos los recursos del servidor de la manera más eficiente posible. El costo de las licencias de bases de datos también es importante, y si se venden por núcleos de procesador, el presupuesto operativo, incluso con escala vertical, puede costar tanto como un programa espacial de superpotencia. Por lo tanto, es importante tener esto en cuenta para no poder escalar el rendimiento de la base de datos debido a las licencias.Está claro que con la ayuda del marketing tratarán de convencerlo de que solo la solución de una determinada empresa resolverá todos sus problemas (pero no mencionan cuántos nuevos aparecerán). No existe una base de datos ideal que se adapte a todos y que sea adecuada para todo.Por lo tanto, en el futuro previsible, aún admitiremos varias bases de datos diferentes para procesar los mismos datos para diferentes tipos de consultas en diferentes sistemas. Sin soluciones para Data Fabric sin almacenamiento en caché de datos, Data Lake aún no se puede comparar con bases de datos con arquitectura de paralelo en masa en términos de rendimiento y optimización de consultas. Los datos transaccionales aún se almacenarán en PostgreSQL, Oracle, MS Sql Server, las consultas analíticas en Citus, Greenplum, Snowflake, Redshift, Vertica, Impala, Teradata y los pantanos de datos sin procesar en HDFS / S3 / ADLS (Azure) serán administrados por Dremio , Redshift Spectrum, Apache Spark, Presto.Pero las soluciones enumeradas anteriormente no son adecuadas para analizar datos de series temporales con un tiempo de respuesta bajo. Según su popularidad al trabajar con datos de series temporales, ahora está en los favoritos de InfluxDB. En el nicho de la base de datos en memoria, kdb + y memSQL mantienen sus lugares.QuestDB
¿Qué puede oponerse a todas estas soluciones QuestDB de código abierto con una licencia de Apache?- Un intento de aprovechar al máximo el hardware para realizar consultas analíticas: vectorización de funciones de agregación, trabajar con datos a través de archivos mapeados en memoria
- SQL como lenguaje de consultas DML y operaciones DDL para gestionar la estructura de la base de datos
- soporte para tablas de unión específicas para series temporales DB
- soporte para funciones de ventana y agregación en SQL
- la capacidad de incrustar una base de datos en una aplicación en la JVM
- JVM, ServiceLoader
- Influx DB line protocol (ILP) UDP Telegraf. «What makes QuestDB faster than InfluxDB»
- PostgreSql 11 PostgreSQL: JDBC, ODBC psql
- web - REST endpoint , SQL json
- ,
- zero-GC API, .
- ( )
- 64 Windows, Linux, OSX, ARM Linux FreeBSD
- , open source,
Cuándo puede serle útil esta base de datos: si está desarrollando sistemas financieros en la JVM con una latencia baja y necesita una solución para el análisis de datos en RAM. Como reemplazo de kdb + debido al costo de las licencias. Si recopila métricas de acuerdo con el protocolo Influx / Telegraf, pero el rendimiento y la facilidad de uso de trabajar con InfluxDB no son satisfactorios. Si su proyecto se ejecuta en la JVM y necesita una base de datos integrada para almacenar métricas o datos de aplicaciones que solo se agregan y no se actualizan.La nueva versión 4.2.0 con soporte para instrucciones SIMD causó una ola de comentarios en Reddit . Para que los fanáticos participen en la competencia de conocimiento del hardware moderno y su programación efectiva, ¡recomiendo hablar con el autor de la base de datos (bluestreak01) en los comentarios!Operaciones SIMD
El equipo del proyecto realizó una prueba de datos sintéticos y comparó QuestDB 4.2.0 con kdb 4.0 para agregar mil millones de valores, aprovechando las instrucciones SIMD de los procesadores.En la plataforma Intel 8850H: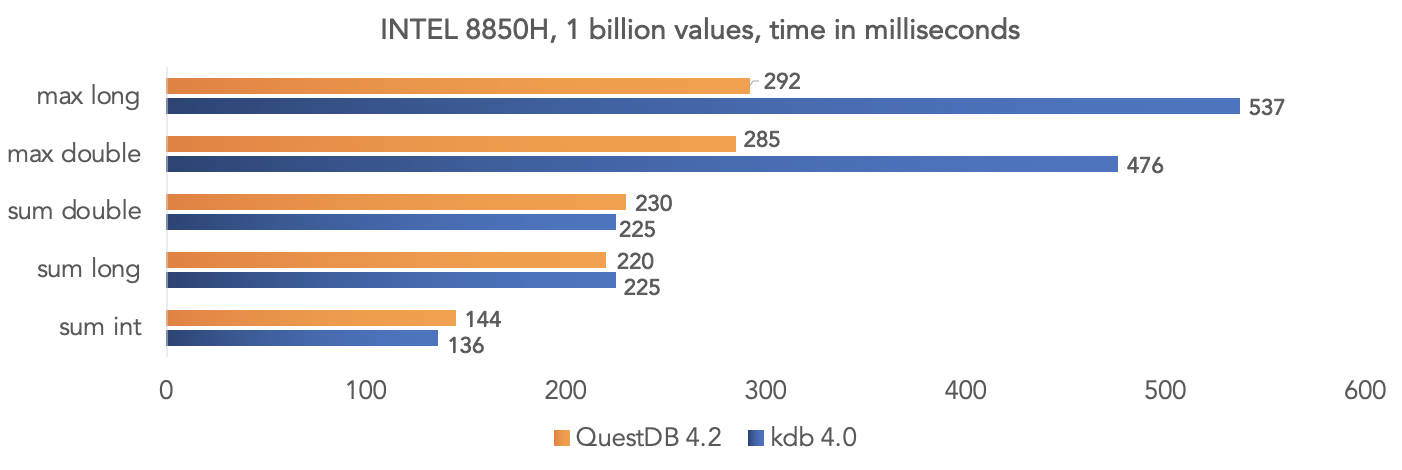 en la plataforma AMD Ryzen 3900X:
en la plataforma AMD Ryzen 3900X: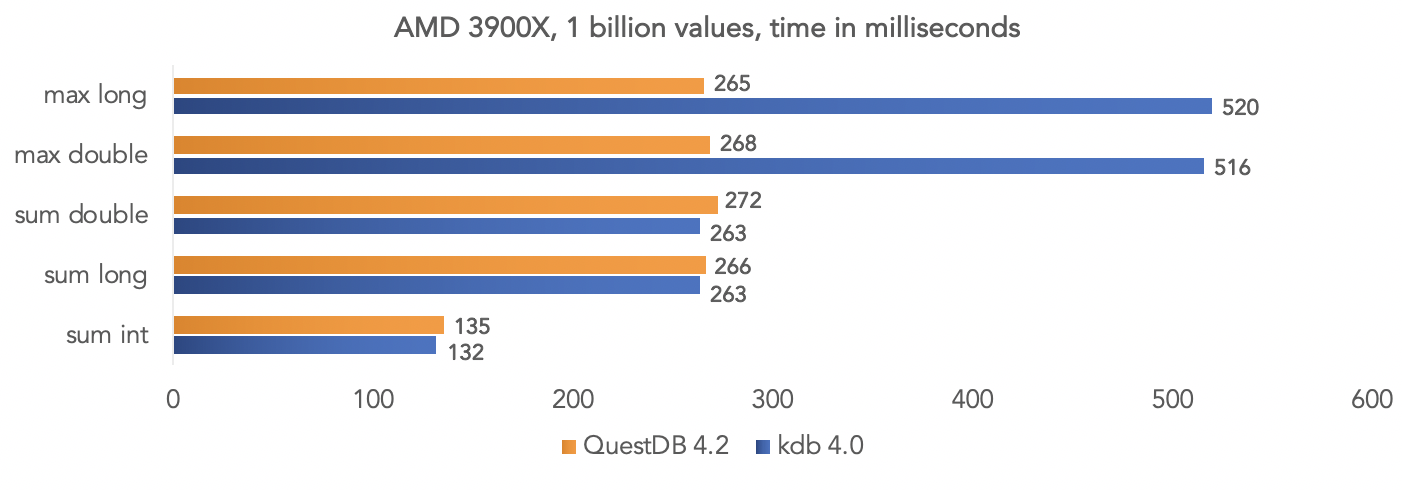 está claro que todas estas son pruebas en un "vacío", pero puede comparar sus datos si su proyecto usa kdb y compartir los resultados con la comunidad.
está claro que todas estas son pruebas en un "vacío", pero puede comparar sus datos si su proyecto usa kdb y compartir los resultados con la comunidad.Ejecutando la imagen de la base de datos de Docker
La base de datos se publica en dockerhub con cada versión. Se describen más detalles en la documentación del proyecto .Obtenga la imagen de QuestDB:docker pull questdb/questdb
Lanzamos:docker run --rm -it -p 9000:9000 -p 8812:8812 questdb/questdb
Después de eso, puede conectarse usando el protocolo PostgreSQL al puerto 8812, la consola web está disponible en el puerto 9000.Acceso jdbc
Dependiendo de nuestro proyecto, agregamos el controlador jdbc PostrgreSQL org.postgresql: postgresql: 42.2.12 , para esta prueba utilizo mi módulo QuestDB para testcontainers . La prueba está disponible en github junto con el script de compilación:import org.junit.jupiter.api.Test;
import java.sql.Connection;
import java.sql.DriverManager;
import java.sql.ResultSet;
import java.sql.Statement;
import static org.assertj.core.api.Assertions.*;
public class QuestDbDriverTest {
@Test
void containerIsUpTestByJdbcInvocation() throws Exception {
try (Connection connection = DriverManager.getConnection("jdbc:tc:questdb:///?user=admin&password=quest")){
try (Statement statement = connection.createStatement()){
try (ResultSet resultSet = statement.executeQuery("select 42 from long_sequence(1)")){
resultSet.next();
assertThat(resultSet.getInt(1)).isEqualTo(42);
}
}
}
}
}
La ejecución de Docker genera una sobrecarga adicional, y esto se puede evitar simplemente implementando org.questdb: core: jar: 4.2.0 como una dependencia del proyecto y ejecutando io.questdb.ServerMain:import io.questdb.ServerMain;
import org.junit.jupiter.api.Test;
import org.junit.jupiter.api.io.TempDir;
import java.nio.file.Path;
import java.sql.Connection;
import java.sql.DriverManager;
import java.sql.PreparedStatement;
import java.sql.Statement;
public class QuestDbJdbcTest {
@Test
void embeddedServerStartTest(@TempDir Path tempDir) throws Exception{
ServerMain.main(new String[]{"-d", tempDir.toString()});
try (DriverManager.getConnection("jdbc:postgresql://localhost:8812/", "admin", "quest")){
try (Statement statement = connection.createStatement()){
try (ResultSet resultSet = statement.executeQuery("select 42 from long_sequence(1)")){
resultSet.next();
assertThat(resultSet.getInt(1)).isEqualTo(42);
}
}
}
}
}
Incrustar en la aplicación Java
Pero esta es la forma más rápida de trabajar con la base de datos utilizando la API de Java en proceso:import io.questdb.cairo.CairoEngine;
import io.questdb.cairo.DefaultCairoConfiguration;
import io.questdb.griffin.CompiledQuery;
import io.questdb.griffin.SqlCompiler;
import io.questdb.griffin.SqlExecutionContextImpl;
import org.junit.jupiter.api.Test;
import org.junit.jupiter.api.io.TempDir;
import java.nio.file.Path;
public class TruncateExecuteTest {
@Test
void truncate(@TempDir Path tempDir) throws Exception{
SqlExecutionContextImpl executionContext = new SqlExecutionContextImpl();
DefaultCairoConfiguration configuration = new DefaultCairoConfiguration(tempDir.toAbsolutePath().toString());
try (CairoEngine engine = new CairoEngine(configuration)) {
try (SqlCompiler compiler = new SqlCompiler(engine)) {
CompiledQuery createTable = compiler.compile("create table tr_table(id long,name string)", executionContext);
compiler.compile("truncate table tr_table", executionContext);
}
}
}
}
Consola web
El proyecto incluye una consola web para consultar QuestDB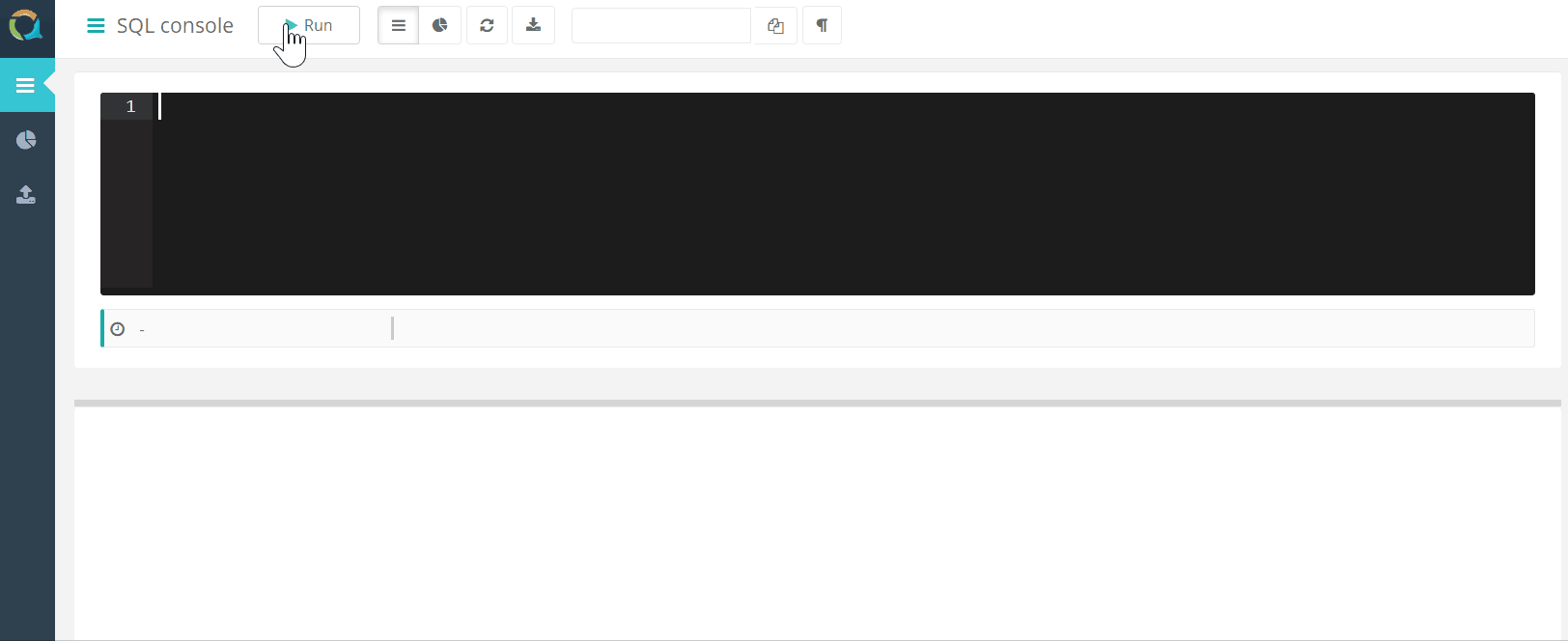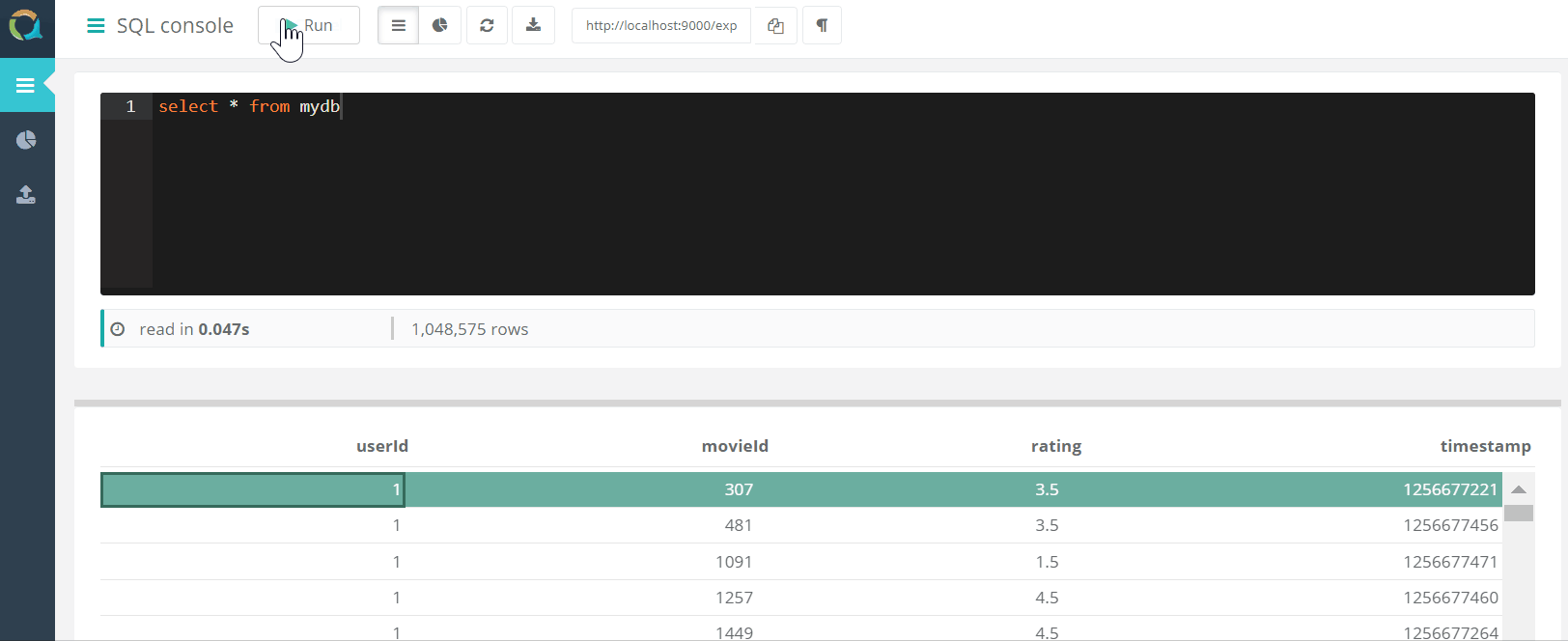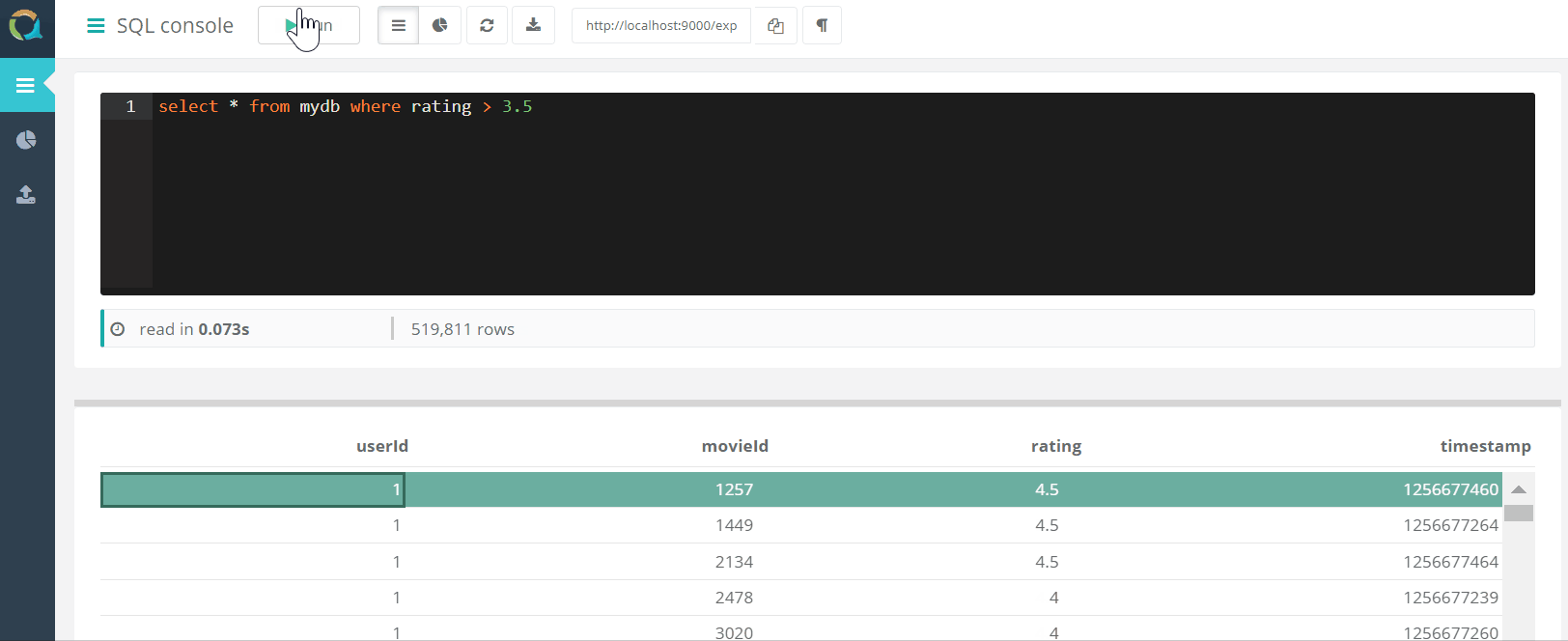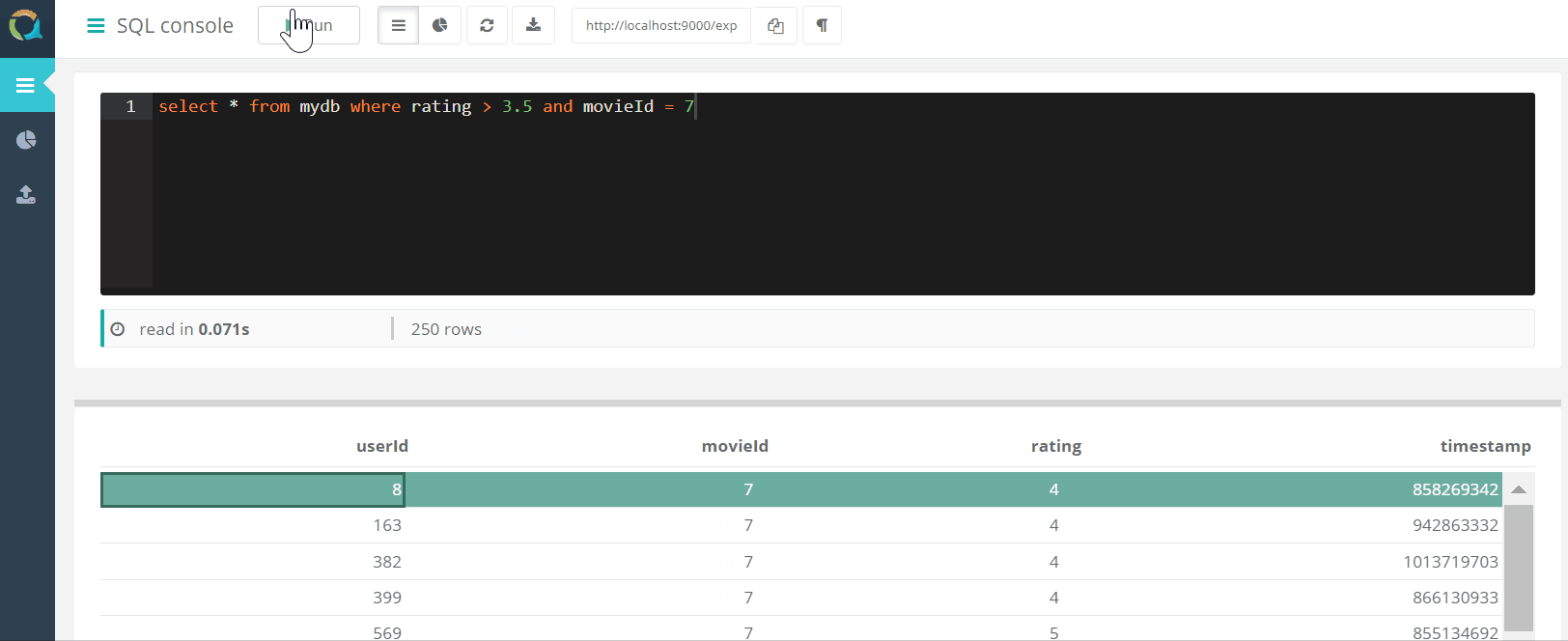 Y descargar datos a una base de datos en formato csv a través de un navegador.
Y descargar datos a una base de datos en formato csv a través de un navegador.
¿Necesitas otra base de datos?
Este proyecto es joven y aún carece de algunas características corporativas, pero se está desarrollando bastante rápido y varios colaboradores están trabajando activamente en el proyecto. He estado siguiendo QuestDB desde agosto pasado y desarrollé un par de extensiones para este proyecto ( función jdbc y osquery ), y también integré este proyecto con testcontainers. Ahora estoy tratando de resolver mis problemas actuales en Dremio con la carga de datos incremental, la partición de datos y las transacciones largas a las fuentes de datos en producción usando QuestDB, complementando con funciones de exportación de datos. Planeo compartir mi experiencia en las siguientes publicaciones. Me soborna especialmente porque puedo depurar mis funciones y mi base de datos en la plataforma con la que estoy familiarizado, escribir pruebas unitarias que se ejecutan a la velocidad de la luz.Tú decides como desarrollador experimentado. Una vez más, QuestDB no es un reemplazo para las bases de datos OLTP: PostgreSQL, Oracle, MS Sql Server, DB2 o incluso un reemplazo H2 para las pruebasen la JVM Esta es una poderosa base de datos especializada de código abierto con soporte para los protocolos de red PostgreSQL, Influx / Telegraf. Si su escenario de uso se ajusta a las características que se implementan en él y al escenario principal de usar una base de datos de columnas, ¡entonces la elección está justificada!