Este artículo será útil para aquellos que acaban de comenzar a familiarizarse con la arquitectura de microservicios y con el servicio Apache Kafka. El material no pretende ser un tutorial detallado, pero lo ayudará a comenzar rápidamente con esta tecnología. Hablaré sobre cómo instalar y configurar Kafka en Windows 10. También crearemos un proyecto usando Intellij IDEA y Spring Boot.¿Para qué?
Las dificultades para comprender varias herramientas a menudo se asocian con el hecho de que el desarrollador nunca ha encontrado situaciones en las que estas herramientas puedan ser necesarias. Con Kafka, esto es exactamente lo mismo. Describimos la situación en la que esta tecnología será útil. Si tiene una arquitectura de aplicación monolítica, entonces, por supuesto, no necesita Kafka. Todo cambia con la transición a microservicios. De hecho, cada microservicio es un programa separado que realiza una u otra función, y que se puede iniciar independientemente de otros microservicios. Los microservicios se pueden comparar con los empleados de la oficina, que se sientan en escritorios separados y resuelven su problema de forma independiente. El trabajo de un equipo tan distribuido es impensable sin una coordinación central.Los empleados deben poder intercambiar mensajes y resultados de su trabajo entre ellos. Apache Kafka para microservicios está diseñado para resolver este problema.Apache Kafka es un agente de mensajes. Con él, los microservicios pueden interactuar entre sí, enviando y recibiendo información importante. Surge la pregunta, ¿por qué no utilizar la POST - solicitud regular para estos fines, en cuyo cuerpo puede transferir los datos necesarios y obtener la respuesta de la misma manera? Este enfoque tiene una serie de desventajas obvias. Por ejemplo, un productor (un servicio que envía un mensaje) puede enviar datos solo en forma de respuesta en respuesta a una solicitud de un consumidor (un servicio que recibe datos). Supongamos que un consumidor envía una solicitud POST y el productor la responde. En este momento, por alguna razón, el consumidor no puede aceptar la respuesta. ¿Qué pasará con los datos? Estarán perdidos. El consumidor nuevamente tendrá que enviar una solicitud y esperar que los datos que desea recibir no hayan cambiado durante este tiempo,y el productor todavía está listo para aceptar la solicitud.Apache Kafka resuelve este y muchos otros problemas que surgen al intercambiar mensajes entre microservicios. No será un error recordar que el intercambio de datos conveniente e ininterrumpido es uno de los problemas clave que deben resolverse para garantizar el funcionamiento estable de la arquitectura de microservicios.Instalar y configurar ZooKeeper y Apache Kafka en Windows 10
Lo primero que debe saber para comenzar es que Apache Kafka se ejecuta sobre el servicio ZooKeeper. ZooKeeper es un servicio distribuido de configuración y sincronización, y eso es todo lo que necesitamos saber al respecto en este contexto. Debemos descargarlo, configurarlo y ejecutarlo antes de comenzar con Kafka. Antes de comenzar a trabajar con ZooKeeper, asegúrese de tener JRE instalado y configurado.Puede descargar la última versión de ZooKeeper desde el sitio web oficial .Extraemos los archivos del archivo ZooKeeper descargado a una carpeta en el disco.En la carpeta zookeeper con el número de versión, encontramos la carpeta conf y en ella el archivo "zoo_sample.cfg". Cópielo y cambie el nombre de la copia a "zoo.cfg". Abra el archivo de copia y busque la línea dataDir = / tmp / zookeeper en él. En esta línea escribimos la ruta completa a nuestra carpeta zookeeper-x.x.x. A mí me parece esto: dataDir = C: \\ ZooKeeper \\ zookeeper-3.6.0
Cópielo y cambie el nombre de la copia a "zoo.cfg". Abra el archivo de copia y busque la línea dataDir = / tmp / zookeeper en él. En esta línea escribimos la ruta completa a nuestra carpeta zookeeper-x.x.x. A mí me parece esto: dataDir = C: \\ ZooKeeper \\ zookeeper-3.6.0 Ahora agregamos la variable de entorno del sistema: ZOOKEEPER_HOME = C: \ ZooKeeper \ zookeeper-3.4.9 y al final de la variable de sistema Path, agregue la entrada:;% ZOOKEEPER_HOME % \ bin;Ejecute la línea de comando y escriba el comando:
Ahora agregamos la variable de entorno del sistema: ZOOKEEPER_HOME = C: \ ZooKeeper \ zookeeper-3.4.9 y al final de la variable de sistema Path, agregue la entrada:;% ZOOKEEPER_HOME % \ bin;Ejecute la línea de comando y escriba el comando:zkserver
Si todo se hace correctamente, verá algo como lo siguiente.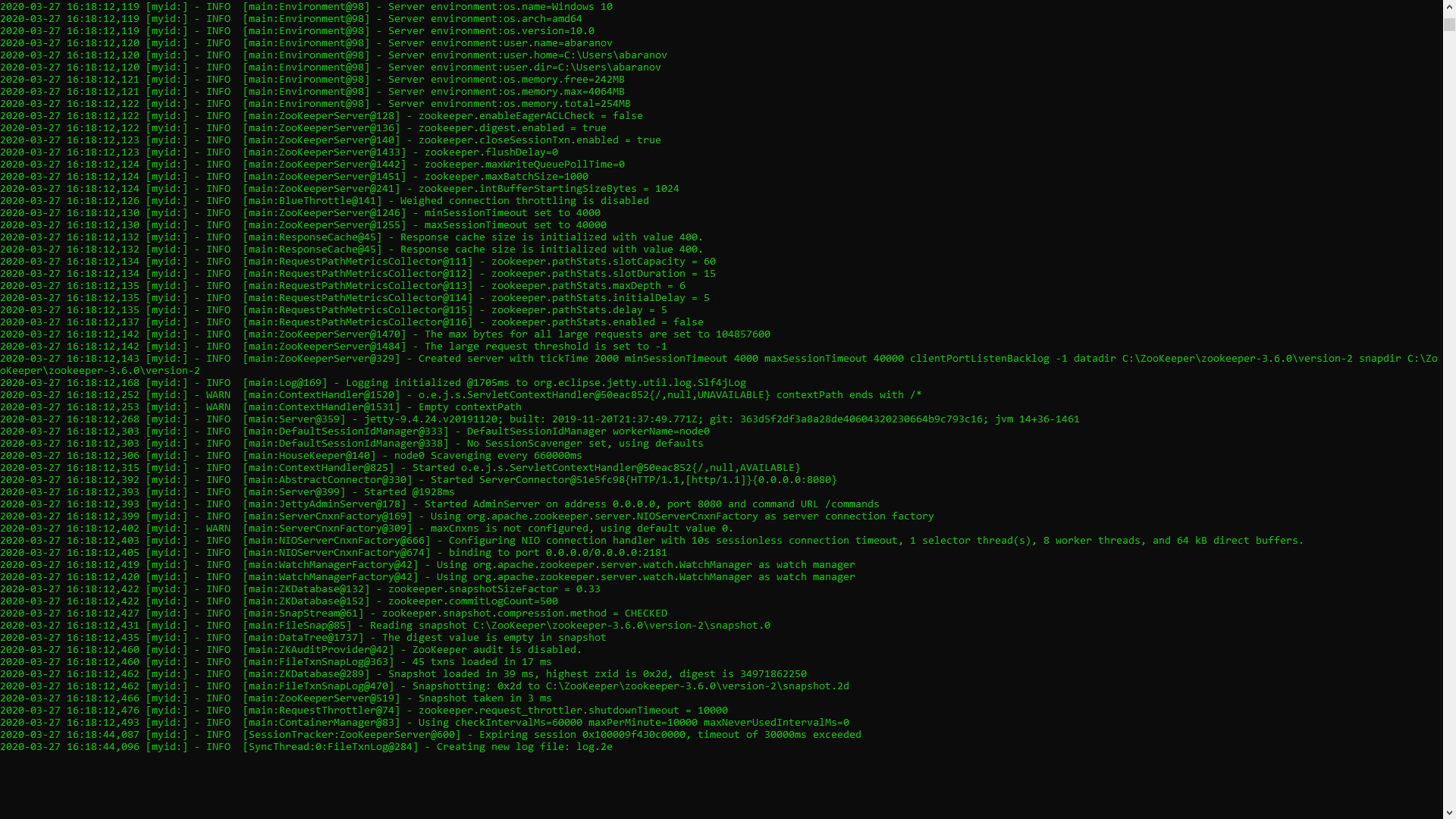 Esto significa que ZooKeeper comenzó normalmente. Procedemos directamente a la instalación y configuración del servidor Apache Kafka. Descargue la última versión del sitio oficial y extraiga el contenido del archivo: kafka.apache.org/downloadsEn la carpeta con Kafka encontramos la carpeta de configuración, en ella encontramos el archivo server.properties y lo abrimos.
Esto significa que ZooKeeper comenzó normalmente. Procedemos directamente a la instalación y configuración del servidor Apache Kafka. Descargue la última versión del sitio oficial y extraiga el contenido del archivo: kafka.apache.org/downloadsEn la carpeta con Kafka encontramos la carpeta de configuración, en ella encontramos el archivo server.properties y lo abrimos. Encontramos la línea log.dirs = / tmp / kafka-logs e indicamos en ella la ruta donde Kafka guardará los registros: log.dirs = c: / kafka / kafka-logs.
Encontramos la línea log.dirs = / tmp / kafka-logs e indicamos en ella la ruta donde Kafka guardará los registros: log.dirs = c: / kafka / kafka-logs.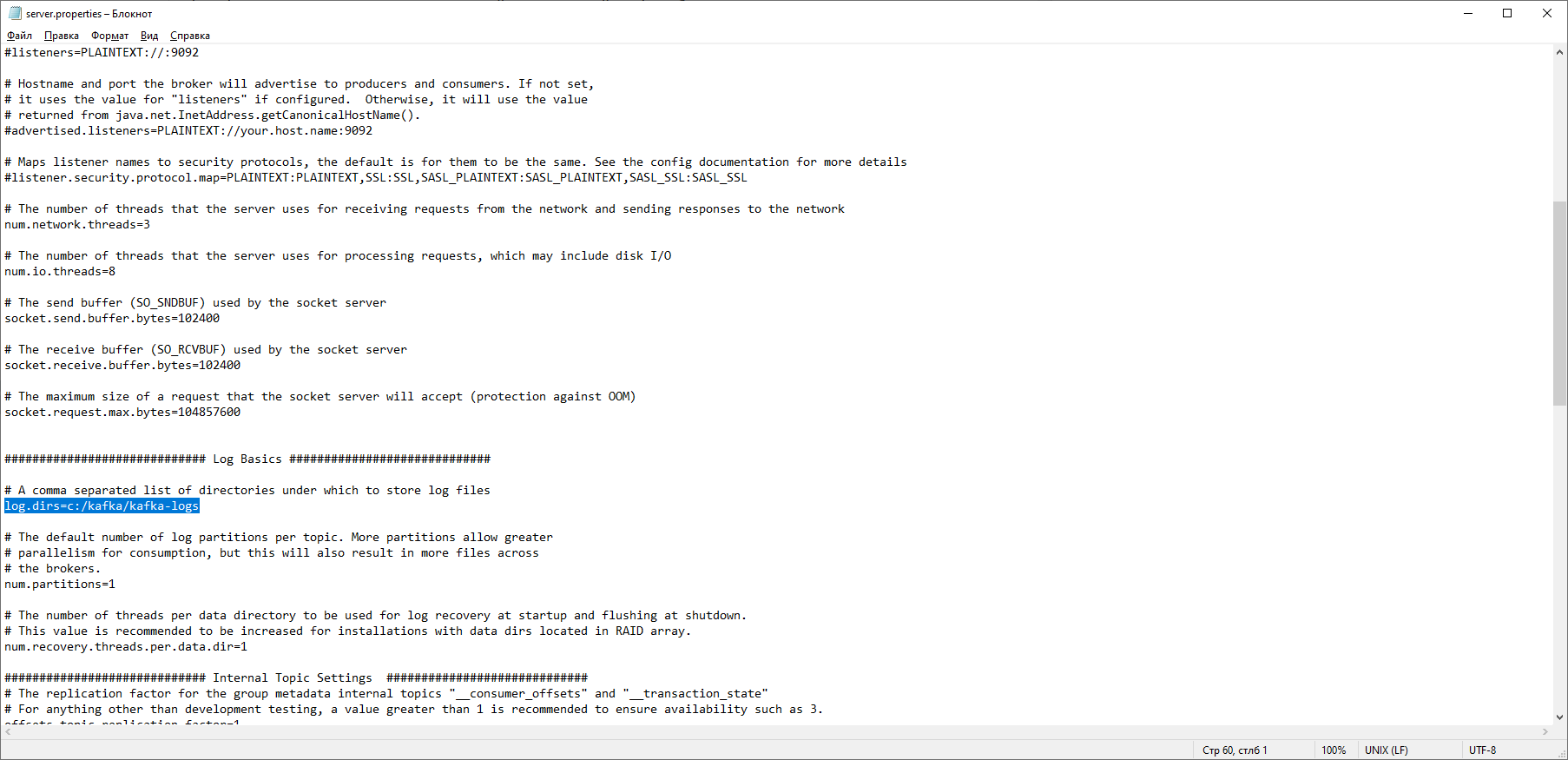 En la misma carpeta, edite el archivo zookeeper.properties. Cambiamos la línea dataDir = / tmp / zookeeper a dataDir = c: / kafka / zookeeper-data, sin olvidar indicar la ruta a su carpeta Kafka después del nombre del disco. Si hiciste todo bien, puedes ejecutar ZooKeeper y Kafka.
En la misma carpeta, edite el archivo zookeeper.properties. Cambiamos la línea dataDir = / tmp / zookeeper a dataDir = c: / kafka / zookeeper-data, sin olvidar indicar la ruta a su carpeta Kafka después del nombre del disco. Si hiciste todo bien, puedes ejecutar ZooKeeper y Kafka. Para algunos, puede ser una sorpresa desagradable que no haya GUI para controlar Kafka. Quizás esto se deba a que el servicio está diseñado para nerds duros que trabajan exclusivamente con la consola. De una forma u otra, para ejecutar Kafka necesitamos una línea de comando.Primero necesitas iniciar ZooKeeper. En la carpeta con el kafka encontramos la carpeta bin / windows, en ella encontramos el archivo para iniciar el servicio zookeeper-server-start.bat, haga clic en él. ¿No pasa nada? Debería ser así. Abra la consola en esta carpeta y escriba:
Para algunos, puede ser una sorpresa desagradable que no haya GUI para controlar Kafka. Quizás esto se deba a que el servicio está diseñado para nerds duros que trabajan exclusivamente con la consola. De una forma u otra, para ejecutar Kafka necesitamos una línea de comando.Primero necesitas iniciar ZooKeeper. En la carpeta con el kafka encontramos la carpeta bin / windows, en ella encontramos el archivo para iniciar el servicio zookeeper-server-start.bat, haga clic en él. ¿No pasa nada? Debería ser así. Abra la consola en esta carpeta y escriba: start zookeeper-server-start.bat
¿No funciona de nuevo? Esta es la norma Esto se debe a que zookeeper-server-start.bat requiere los parámetros especificados en el archivo zookeeper.properties, que, como recordamos, se encuentra en la carpeta de configuración para su trabajo. Escribimos a la consola:start zookeeper-server-start.bat c:\kafka\config\zookeeper.properties
Ahora todo debería comenzar normalmente. Una vez más, abra la consola en esta carpeta (¡no cierre ZooKeeper!) Y ejecute kafka:
Una vez más, abra la consola en esta carpeta (¡no cierre ZooKeeper!) Y ejecute kafka:start kafka-server-start.bat c:\kafka\config\server.properties
Para no escribir comandos cada vez en la línea de comandos, puede usar el método probado anterior y crear un archivo por lotes con el siguiente contenido:start C:\kafka\bin\windows\zookeeper-server-start.bat C:\kafka\config\zookeeper.properties
timeout 10
start C:\kafka\bin\windows\kafka-server-start.bat C:\kafka\config\server.properties
La línea de tiempo de espera 10 es necesaria para establecer una pausa entre el cuidador del zoológico y el kafka. Si hizo todo bien, al hacer clic en el archivo por lotes, se abrirán dos consolas con zookeeper y kafka en ejecución. Ahora podemos crear un productor y un consumidor de mensajes con los parámetros necesarios directamente desde la línea de comandos. Pero, en la práctica, puede ser necesario a menos que se pruebe el servicio. Estaremos mucho más interesados en cómo trabajar con kafka de IDEA.Trabaja con kafka de IDEA
Escribiremos la aplicación más simple posible, que simultáneamente será el productor y el consumidor del mensaje, y luego le agregaremos funciones útiles. Crea un nuevo proyecto de primavera. Esto se hace más convenientemente usando un inicializador de resorte. Agregue las dependencias org.springframework.kafka y spring-boot-starter-web
 Como resultado, el archivo pom.xml debería tener este aspecto:
Como resultado, el archivo pom.xml debería tener este aspecto: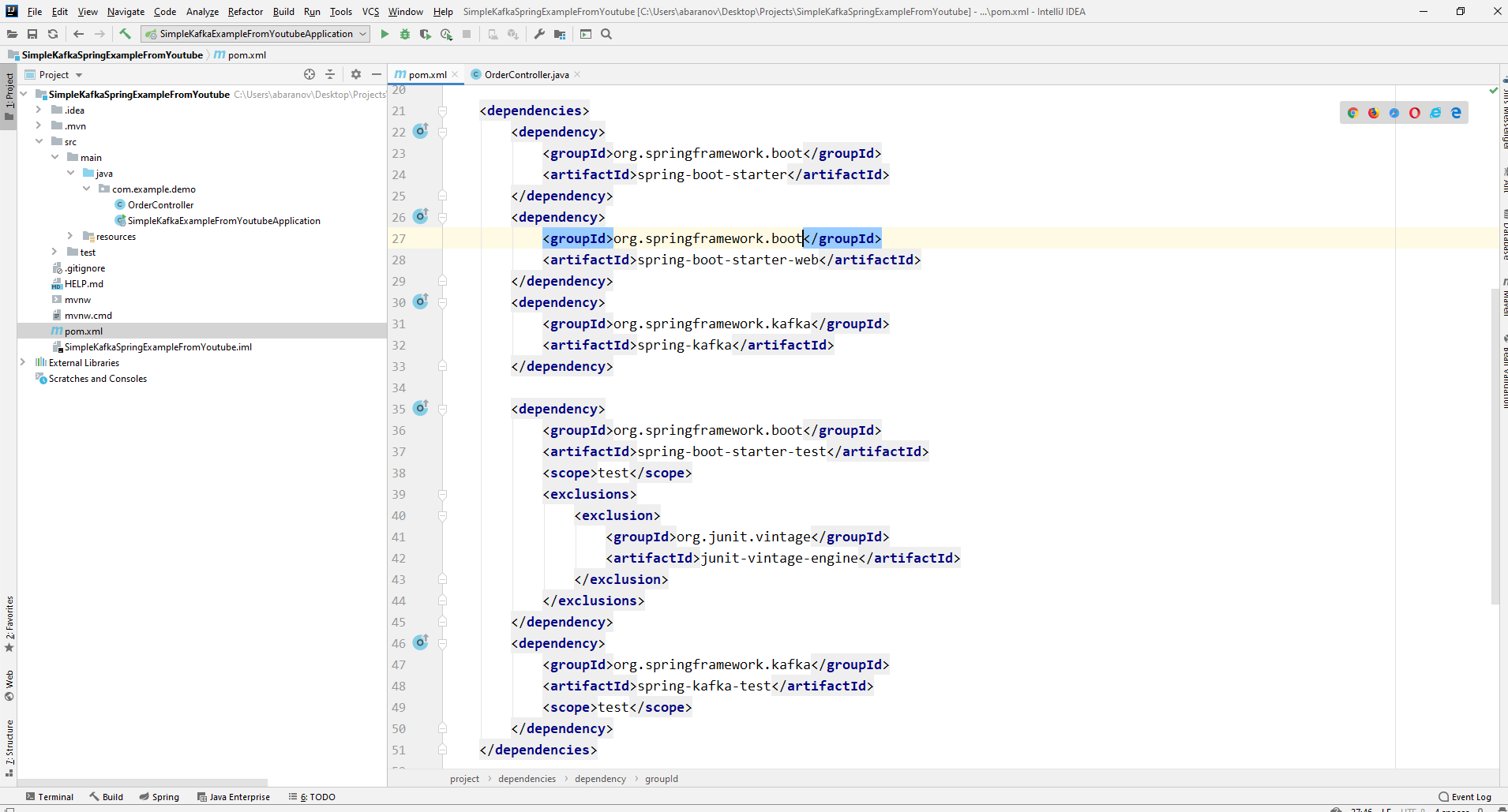 para enviar mensajes, necesitamos el objeto KafkaTemplate <K, V>. Como vemos, el objeto está escrito. El primer parámetro es el tipo de clave, el segundo es el mensaje en sí. Por ahora, indicaremos ambos parámetros como String. Crearemos el objeto en el controlador de clase. Declare KafkaTemplate y pídale a Spring que lo inicialice anotandoAutowired.
para enviar mensajes, necesitamos el objeto KafkaTemplate <K, V>. Como vemos, el objeto está escrito. El primer parámetro es el tipo de clave, el segundo es el mensaje en sí. Por ahora, indicaremos ambos parámetros como String. Crearemos el objeto en el controlador de clase. Declare KafkaTemplate y pídale a Spring que lo inicialice anotandoAutowired.@Autowired
private KafkaTemplate<String, String> kafkaTemplate;
En principio, nuestro productor está listo. Todo lo que queda por hacer es llamar al método send () en él. Hay varias versiones sobrecargadas de este método. Usamos en nuestro proyecto una opción con 3 parámetros: enviar (tema de cadena, clave K, datos V). Como KafkaTemplate está escrito por String, la clave y los datos en el método de envío serán una cadena. El primer parámetro indica el tema, es decir, el tema al que se enviarán los mensajes y a los que los consumidores pueden suscribirse para recibirlos. Si el tema especificado en el método de envío no existe, se creará automáticamente. El texto completo de la clase se ve así.@RestController
@RequestMapping("msg")
public class MsgController {
@Autowired
private KafkaTemplate<String, String> kafkaTemplate;
@PostMapping
public void sendOrder(String msgId, String msg){
kafkaTemplate.send("msg", msgId, msg);
}
}
El controlador se asigna a localhost : 8080 / msg, la clave y el mensaje en sí se transmiten en el cuerpo de la solicitud.El remitente del mensaje está listo, ahora cree un oyente. Spring también te permite hacer esto sin mucho esfuerzo. Es suficiente crear un método y marcarlo con la anotación @KafkaListener, en cuyos parámetros puede especificar solo el tema que se escuchará. En nuestro caso, se ve así.@KafkaListener(topics="msg")
El método en sí, marcado con anotaciones, puede especificar un parámetro aceptado, que tiene el tipo de mensaje transmitido por el productor.La clase en la que se creará el consumidor debe estar marcada con la anotación @EnableKafka.@EnableKafka
@SpringBootApplication
public class SimpleKafkaExampleApplication {
@KafkaListener(topics="msg")
public void msgListener(String msg){
System.out.println(msg);
}
public static void main(String[] args) {
SpringApplication.run(SimpleKafkaExampleApplication.class, args);
}
}
Además, en el archivo de configuración de application.property, debe especificar el parámetro de concierge groupe-id. Si esto no se hace, la aplicación no se iniciará. El parámetro es de tipo String y puede ser cualquier cosa.spring.kafka.consumer.group-id=app.1
Nuestro proyecto kafka más simple está listo. Tenemos un remitente y un destinatario de mensajes. Solo queda correr. Primero, inicie ZooKeeper y Kafka utilizando el archivo por lotes que escribimos anteriormente, luego inicie nuestra aplicación. Es más conveniente enviar una solicitud utilizando Postman. En el cuerpo de la solicitud, no olvide especificar los parámetros msgId y msg. Si vemos esa imagen en IDEA, entonces todo funciona: el productor envió un mensaje, el consumidor lo recibió y lo mostró en la consola.
Si vemos esa imagen en IDEA, entonces todo funciona: el productor envió un mensaje, el consumidor lo recibió y lo mostró en la consola.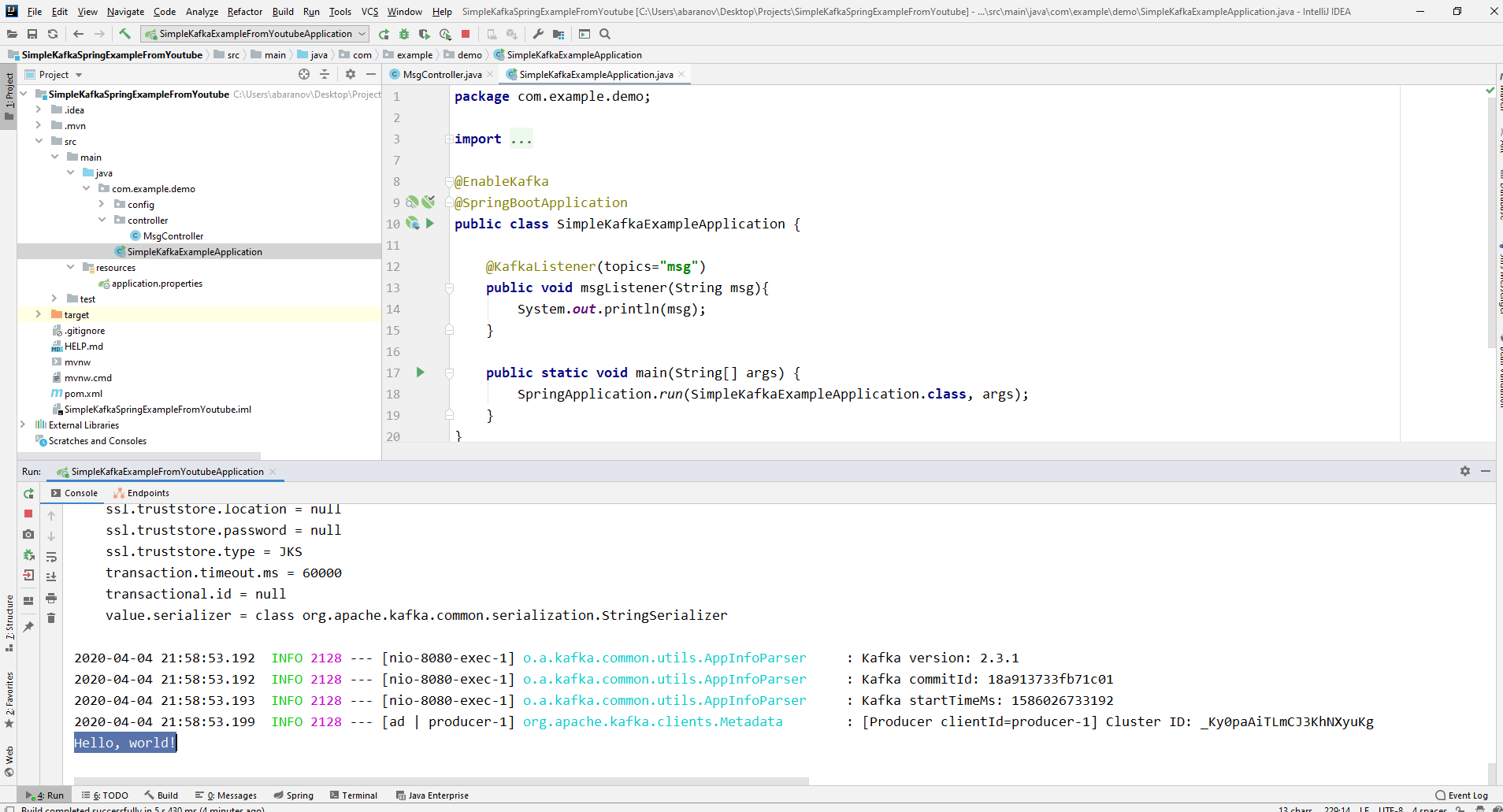
Complicamos el proyecto
Los proyectos reales que usan Kafka son ciertamente más complicados que el que creamos. Ahora que hemos descubierto las funciones básicas del servicio, considere qué características adicionales proporciona. Para empezar, mejoraremos al productor.Si abrió el método send (), puede notar que todas sus variantes tienen un valor de retorno de ListenableFuture <SendResult <K, V >>. Ahora no consideraremos en detalle las capacidades de esta interfaz. Aquí bastará decir que es necesario ver el resultado del envío de un mensaje.@PostMapping
public void sendMsg(String msgId, String msg){
ListenableFuture<SendResult<String, String>> future = kafkaTemplate.send("msg", msgId, msg);
future.addCallback(System.out::println, System.err::println);
kafkaTemplate.flush();
}
El método addCallback () acepta dos parámetros: SuccessCallback y FailureCallback. Ambos son interfaces funcionales. Por el nombre puede comprender que el método del primero se llamará como resultado del envío exitoso del mensaje, el segundo, como resultado de un error. Ahora, si ejecutamos el proyecto, veremos algo como lo siguiente en la consola:SendResult [producerRecord=ProducerRecord(topic=msg, partition=null, headers=RecordHeaders(headers = [], isReadOnly = true), key=1, value=Hello, world!, timestamp=null), recordMetadata=msg-0@6]
Miremos cuidadosamente a nuestro productor nuevamente. Curiosamente, ¿qué sucede si la clave no es String, sino, digamos, Long, pero como mensaje transmitido, peor aún, algún tipo de DTO complicado? Primero, intentemos cambiar la clave a un valor numérico ... Si especificamos Long como la clave en el productor, la aplicación se iniciará normalmente, pero cuando intente enviar un mensaje, se lanzará una ClassCastException y se informará que la clase Long no se puede convertir a la clase String.
Si especificamos Long como la clave en el productor, la aplicación se iniciará normalmente, pero cuando intente enviar un mensaje, se lanzará una ClassCastException y se informará que la clase Long no se puede convertir a la clase String. Si intentamos crear manualmente el objeto KafkaTemplate, veremos que el objeto de interfaz ProducerFactory <K, V>, por ejemplo, DefaultKafkaProducerFactory <>, se pasa al constructor como un parámetro. Para crear un DefaultKafkaProducerFactory, necesitamos pasar un Mapa que contenga su configuración de productor a su constructor. Todo el código para la configuración y creación del productor se colocará en una clase separada. Para hacer esto, cree el paquete de configuración y en él la clase KafkaProducerConfig.
Si intentamos crear manualmente el objeto KafkaTemplate, veremos que el objeto de interfaz ProducerFactory <K, V>, por ejemplo, DefaultKafkaProducerFactory <>, se pasa al constructor como un parámetro. Para crear un DefaultKafkaProducerFactory, necesitamos pasar un Mapa que contenga su configuración de productor a su constructor. Todo el código para la configuración y creación del productor se colocará en una clase separada. Para hacer esto, cree el paquete de configuración y en él la clase KafkaProducerConfig.@Configuration
public class KafkaProducerConfig {
private String kafkaServer="localhost:9092";
@Bean
public Map<String, Object> producerConfigs() {
Map<String, Object> props = new HashMap<>();
props.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG,
kafkaServer);
props.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG,
LongSerializer.class);
props.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG,
StringSerializer.class);
return props;
}
@Bean
public ProducerFactory<Long, String> producerFactory() {
return new DefaultKafkaProducerFactory<>(producerConfigs());
}
@Bean
public KafkaTemplate<Long, String> kafkaTemplate() {
return new KafkaTemplate<>(producerFactory());
}
}
En el método productorConfigs (), cree un mapa con las configuraciones y especifique LongSerializer.class como el serializador para la clave. Comenzamos, enviamos una solicitud de Postman y vemos que ahora todo funciona como debería: el productor envía un mensaje y el consumidor lo recibe.Ahora cambiemos el tipo del valor transmitido. ¿Qué pasa si no tenemos una clase estándar de la biblioteca de Java, sino algún tipo de DTO personalizado? Digamos esto@Data
public class UserDto {
private Long age;
private String name;
private Address address;
}
@Data
@AllArgsConstructor
public class Address {
private String country;
private String city;
private String street;
private Long homeNumber;
private Long flatNumber;
}
Para enviar DTO como mensaje, debe realizar algunos cambios en la configuración del productor. Especifique JsonSerializer.class como el serializador del valor del mensaje y no olvide cambiar el tipo de Cadena a UserDto en todas partes.@Configuration
public class KafkaProducerConfig {
private String kafkaServer="localhost:9092";
@Bean
public Map<String, Object> producerConfigs() {
Map<String, Object> props = new HashMap<>();
props.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG,
kafkaServer);
props.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG,
LongSerializer.class);
props.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG,
JsonSerializer.class);
return props;
}
@Bean
public ProducerFactory<Long, UserDto> producerFactory() {
return new DefaultKafkaProducerFactory<>(producerConfigs());
}
@Bean
public KafkaTemplate<Long, UserDto> kafkaTemplate() {
return new KafkaTemplate<>(producerFactory());
}
}
Enviar un mensaje. La siguiente línea se mostrará en la consola: Ahora vamos a complicar al consumidor. Antes de esto, nuestro método public void msgListener (String msg), marcado con la anotación @KafkaListener (topics = "msg") tomó String como parámetro y lo mostró en la consola. ¿Qué sucede si queremos obtener otros parámetros del mensaje transmitido, por ejemplo, una clave o una partición? En este caso, se debe cambiar el tipo del valor transmitido.
Ahora vamos a complicar al consumidor. Antes de esto, nuestro método public void msgListener (String msg), marcado con la anotación @KafkaListener (topics = "msg") tomó String como parámetro y lo mostró en la consola. ¿Qué sucede si queremos obtener otros parámetros del mensaje transmitido, por ejemplo, una clave o una partición? En este caso, se debe cambiar el tipo del valor transmitido.@KafkaListener(topics="msg")
public void orderListener(ConsumerRecord<Long, UserDto> record){
System.out.println(record.partition());
System.out.println(record.key());
System.out.println(record.value());
}
Desde el objeto ConsumerRecord podemos obtener todos los parámetros que nos interesan.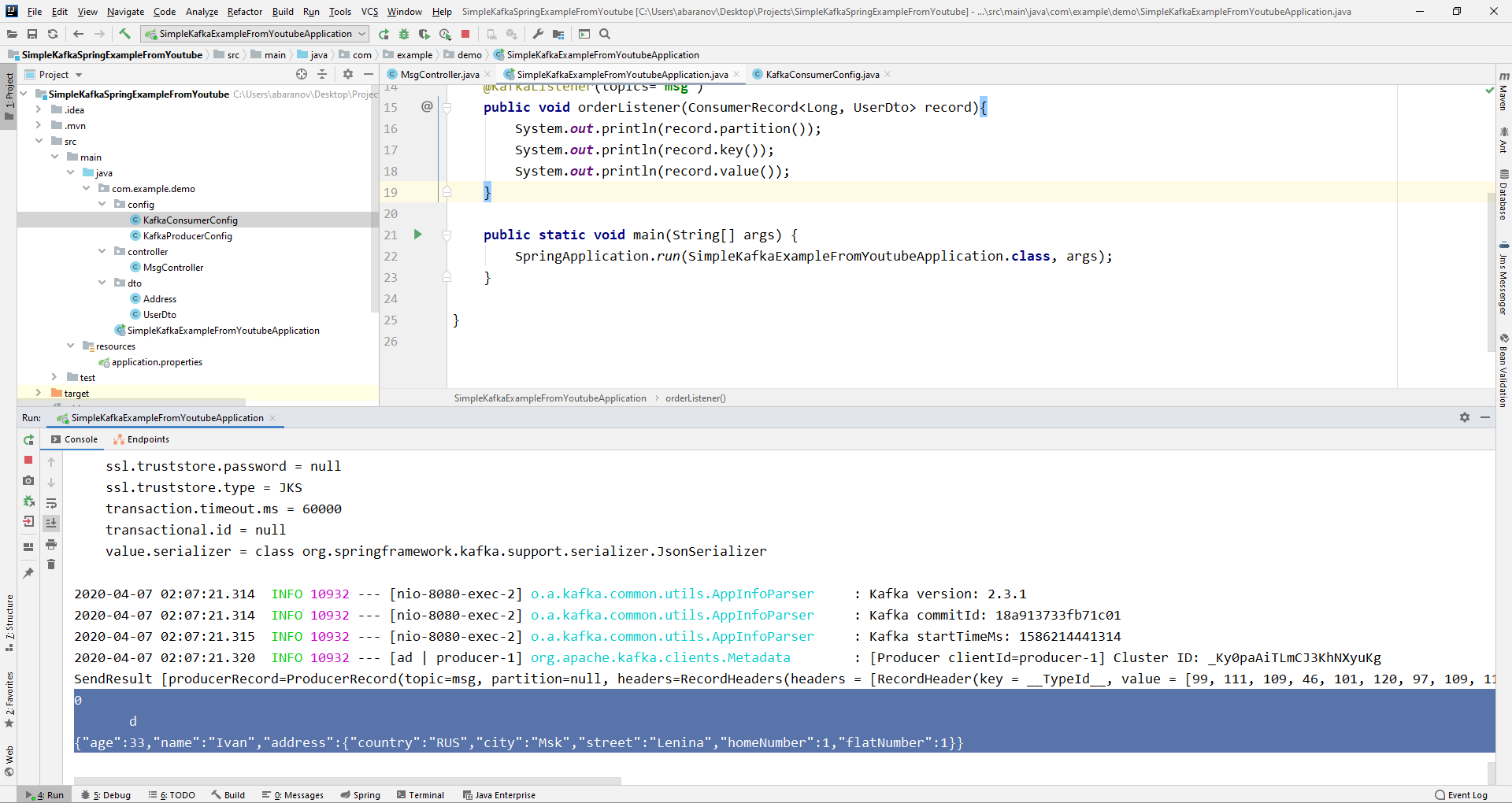 Vemos que en lugar de la clave en la consola, se muestra algún tipo de krakozyabry. Esto se debe a que StringDeserializer se usa de forma predeterminada para deserializar la clave, y si queremos que la clave en el formato entero se muestre correctamente, debemos cambiarla a LongDeserializer. Para configurar el consumidor en el paquete de configuración, cree la clase KafkaConsumerConfig.
Vemos que en lugar de la clave en la consola, se muestra algún tipo de krakozyabry. Esto se debe a que StringDeserializer se usa de forma predeterminada para deserializar la clave, y si queremos que la clave en el formato entero se muestre correctamente, debemos cambiarla a LongDeserializer. Para configurar el consumidor en el paquete de configuración, cree la clase KafkaConsumerConfig.@Configuration
public class KafkaConsumerConfig {
@Value("${spring.kafka.bootstrap-servers}")
private String kafkaServer;
@Value("${spring.kafka.consumer.group-id}")
private String kafkaGroupId;
@Bean
public Map<String, Object> consumerConfigs() {
Map<String, Object> props = new HashMap<>();
props.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG, kafkaServer);
props.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG, LongDeserializer.class);
props.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class);
props.put(ConsumerConfig.GROUP_ID_CONFIG, kafkaGroupId);
return props;
}
@Bean
public KafkaListenerContainerFactory<?> kafkaListenerContainerFactory() {
ConcurrentKafkaListenerContainerFactory<Long, UserDto> factory =
new ConcurrentKafkaListenerContainerFactory<>();
factory.setConsumerFactory(consumerFactory());
return factory;
}
@Bean
public ConsumerFactory<Long, UserDto> consumerFactory() {
return new DefaultKafkaConsumerFactory<>(consumerConfigs());
}
}
La clase KafkaConsumerConfig es muy similar a la KafkaProducerConfig que creamos anteriormente. También hay un mapa que contiene las configuraciones necesarias, por ejemplo, como un deserializador para la clave y el valor. El mapa creado se usa para crear ConsumerFactory <>, que, a su vez, es necesario para crear KafkaListenerContainerFactory <?>. Un detalle importante: el método que devuelve KafkaListenerContainerFactory <?> Debería llamarse kafkaListenerContainerFactory (), de lo contrario Spring no podrá encontrar el bean deseado y el proyecto no se compilará. Empezamos. Vemos que ahora la clave se muestra como debería, lo que significa que todo funciona. Por supuesto, las capacidades de Apache Kafka van mucho más allá de las descritas en este artículo, sin embargo, espero que después de leerlo tenga una idea sobre este servicio y, lo más importante, pueda comenzar a trabajar con él.Lávese las manos con más frecuencia, use máscaras, no salga sin necesidad y sea saludable.
Vemos que ahora la clave se muestra como debería, lo que significa que todo funciona. Por supuesto, las capacidades de Apache Kafka van mucho más allá de las descritas en este artículo, sin embargo, espero que después de leerlo tenga una idea sobre este servicio y, lo más importante, pueda comenzar a trabajar con él.Lávese las manos con más frecuencia, use máscaras, no salga sin necesidad y sea saludable.