Hola Habr!En este artículo nos gustaría hablar sobre la automatización de la infraestructura de red. Se presentará un diagrama de red de trabajo, que opera en una empresa pequeña pero muy orgullosa. Todas las coincidencias con el hardware de red real son aleatorias. Consideraremos un caso que ocurrió en esta red, que podría llevar a un cierre comercial por mucho tiempo y serias pérdidas financieras. La solución de este caso encaja muy bien en el concepto de "Automatización de la infraestructura de red". Usando herramientas de automatización, le mostraremos cómo puede resolver eficazmente problemas complejos en poco tiempo, y reflexionaremos sobre el tema de por qué estas tareas son más prometedoras de resolver de esta manera y no de otra manera (a través de la consola) .Descargo de responsabilidad
Nuestras principales herramientas de automatización son Ansible (como medio de automatización) y Git (como repositorio de los libros de jugadas de Ansible). Inmediatamente quiero hacer una reserva de que este no es un artículo de investigación, donde hablamos sobre la lógica de Ansible o Git, y explicamos cosas básicas (por ejemplo, qué son roles \ tareas \ módulos \ archivos de inventario \ variables en Ansible, o qué sucede cuando ingresas comandos git push o git commit). Esta historia no trata sobre cómo practicar en Ansible, configurarlo en equipos NTP o SMTP. Esta es una historia sobre cómo puede resolver rápida y preferiblemente sin errores un problema de red. También es deseable tener una buena idea de cómo funciona la red, en particular, qué es la pila de protocolos TCP / IP, OSPF, BGP. La elección de Ansible y Git también está fuera de discusión. Si todavía tiene la opción de una solución específica,Recomendamos encarecidamente leer el libro Network Programmability and Automation. Habilidades para el ingeniero de redes de próxima generación ”por Jason Edelman, Scott S. Lowe y Matt Oswalt.Ahora al grano.Formulación del problema
Imagine una situación: a las 3 a.m., duerme profundamente y sueña. La llamada al teléfono. El director técnico llama:- ¿Sí?- ###, ####, #####, el grupo de cortafuegos ha caído y no sube !!!Se frota los ojos, trata de darse cuenta de lo que está sucediendo e imagina cómo tal cosa podría haber sucedido. En el tubo se puede escuchar el pelo desgarrado en la cabeza del director, y él le pide que vuelva a llamar, porque el general lo llama en la segunda línea.Después de media hora, recolectó las primeras notas introductorias del turno de servicio, despertó a todos con los que podía despertarse. Como resultado, el director técnico no mintió, todo es así, el grupo principal de cortafuegos se ha caído y ningún gesto básico lo ha llevado a la normalidad. Todos los servicios que ofrece la empresa no funcionan.Elija un problema para su gusto, todos recordarán algo diferente. Por ejemplo, después de una actualización nocturna, en ausencia de una carga pesada, todo funcionó bien, y todos satisfechos se fueron a la cama. El tráfico se fue y los búferes de interfaz comenzaron a desbordarse debido a un error en el controlador de la tarjeta de red.La situación bien puede describir a Jackie Chan. Gracias Jackie.La situación no es muy agradable, ¿verdad?Vayámonos por el tiempo de nuestra red hermano con sus pensamientos tristes.Discutiremos cómo se desarrollarán más los eventos.Ofrecemos el siguiente orden de presentación del material.
Gracias Jackie.La situación no es muy agradable, ¿verdad?Vayámonos por el tiempo de nuestra red hermano con sus pensamientos tristes.Discutiremos cómo se desarrollarán más los eventos.Ofrecemos el siguiente orden de presentación del material.- Considere el diagrama de red y analice cómo funciona;
- Describiremos cómo transferimos configuraciones de un enrutador a otro usando Ansible;
- Hablemos de la automatización de la infraestructura de TI en general.
Diagrama de red y su descripción
Esquema
 Considere la lógica de nuestra organización. No nombraremos fabricantes específicos de equipos, esto no importa dentro del artículo (el lector atento adivinará qué tipo de equipo se utiliza) . Esta es solo una de las buenas ventajas de trabajar con Ansible, cuando configuramos, en general, no nos importa qué tipo de equipo es. Solo para entender, este equipo es conocido en proveedores como Cisco, Juniper, Check Point, Fortinet, Palo Alto ... puede sustituir su propia versión.Tenemos dos tareas principales para mover el tráfico:
Considere la lógica de nuestra organización. No nombraremos fabricantes específicos de equipos, esto no importa dentro del artículo (el lector atento adivinará qué tipo de equipo se utiliza) . Esta es solo una de las buenas ventajas de trabajar con Ansible, cuando configuramos, en general, no nos importa qué tipo de equipo es. Solo para entender, este equipo es conocido en proveedores como Cisco, Juniper, Check Point, Fortinet, Palo Alto ... puede sustituir su propia versión.Tenemos dos tareas principales para mover el tráfico:- Asegurar la publicación de nuestros servicios, que son el negocio de la empresa;
- Proporcione comunicación con sucursales, un centro de datos remoto y organizaciones de terceros (socios y clientes), así como acceso a Internet a través de la oficina central.
Comencemos con los elementos básicos:- Dos enrutadores de borde (BRD-01, BRD-02);
- Grupo de cortafuegos (FW-CLUSTER);
- Kernel Switch (L3-CORE);
- Un enrutador que se convertirá en un salvavidas (en el proceso de resolver el problema, transferiremos la configuración de red de FW-CLUSTER a EMERGENCY) (EMERGENCIA);
- Conmutadores para gestionar la infraestructura de red (L2-MGMT);
- Máquina virtual con Git y Ansible (VM-AUTOMATION);
- Una computadora portátil que prueba y desarrolla libros de jugadas para Ansible (Laptop-Automation).
Se configura un protocolo de enrutamiento OSPF dinámico en la red con las siguientes áreas:- Área 0: el área en la que se incluyen los enrutadores responsables del movimiento del tráfico en la zona de INTERCAMBIO;
- Área 1: el área en la que se incluyen los enrutadores responsables del trabajo de los servicios de la compañía;
- Área 2: el área en la que se incluyen los enrutadores responsables del tráfico de administración de enrutamiento;
- Área N: áreas de red de sucursales.
En los enrutadores fronterizos se crea en un enrutador virtual (VRF-INTERNET), en el que se eleva la vista completa de eBGP con el AS asignado correspondiente. Entre VRFs iBGP está configurado. La compañía tiene un grupo de direcciones blancas que se publican en estos VRF-INTERNET. Algunas de las direcciones blancas se enrutan directamente a FW-CLUSTER (las direcciones en las que trabajan los servicios de la compañía), algunas se enrutan a través de la zona de INTERCAMBIO (servicios internos de la compañía que requieren direcciones IP externas y direcciones NAT externas para las oficinas). Además, el tráfico llega a enrutadores virtuales creados en L3-CORE con direcciones blancas y grises (zonas de seguridad).Las redes de administración usan conmutadores dedicados y son una red físicamente dedicada. La red de gestión también se divide en zonas de seguridad.El enrutador de EMERGENCIA duplica física y lógicamente el FW-CLUSTER. Todas las interfaces están deshabilitadas, excepto las que miran a la red de administración.Automatización y su descripción.
Descubrimos cómo funciona la red. Ahora echemos un vistazo a los pasos, qué haremos para transferir el tráfico de FW-CLUSTER a EMERGENCY:- Deshabilite las interfaces en el conmutador del núcleo (L3-CORE) que lo conectan al FW-CLUSTER;
- Deshabilite las interfaces en el conmutador central L2-MGMT que lo conectan al FW-CLUSTER;
- Configure el enrutador de EMERGENCIA (de forma predeterminada, todas las interfaces están deshabilitadas en él, excepto las asociadas con L2-MGMT):
- Incluimos interfaces en EMERGENCIA;
- Configure la dirección IP externa (para NAT), que estaba en FW-Cluster;
- Generamos solicitudes de gARP para que en las tablas arp L3-CORE las direcciones de amapola cambien de FW-Cluster a EMERGENCY;
- BRD-01, BRD-02;
- NAT;
- EMERGENCY OSPF Area 1;
- EMERGENCY OSPF Area 2;
- Area 1 10;
- Area 1 10;
- ip-, L2-MGMT ( , FW-CLUSTER);
- gARP , arp- L2-MGMT - FW-CLUSTER EMERGENCY.
Nuevamente, volvemos a la formulación original del problema. Tres de la mañana, un gran estrés, un error en cualquier etapa puede conducir a nuevos problemas. ¿Listo para escribir comandos a través de la CLI? ¿Si? Ok, ve al menos a enjuagarte la cara, toma café y reúne tu voluntad en un puño.Bruce, por favor ayuda a los chicos. Bueno, seguimos reduciendo nuestra automatización.A continuación se muestra un diagrama del libro de trabajo en términos de Ansible. Este diagrama refleja lo que describimos anteriormente, solo una implementación concreta en Ansible.
Bueno, seguimos reduciendo nuestra automatización.A continuación se muestra un diagrama del libro de trabajo en términos de Ansible. Este diagrama refleja lo que describimos anteriormente, solo una implementación concreta en Ansible.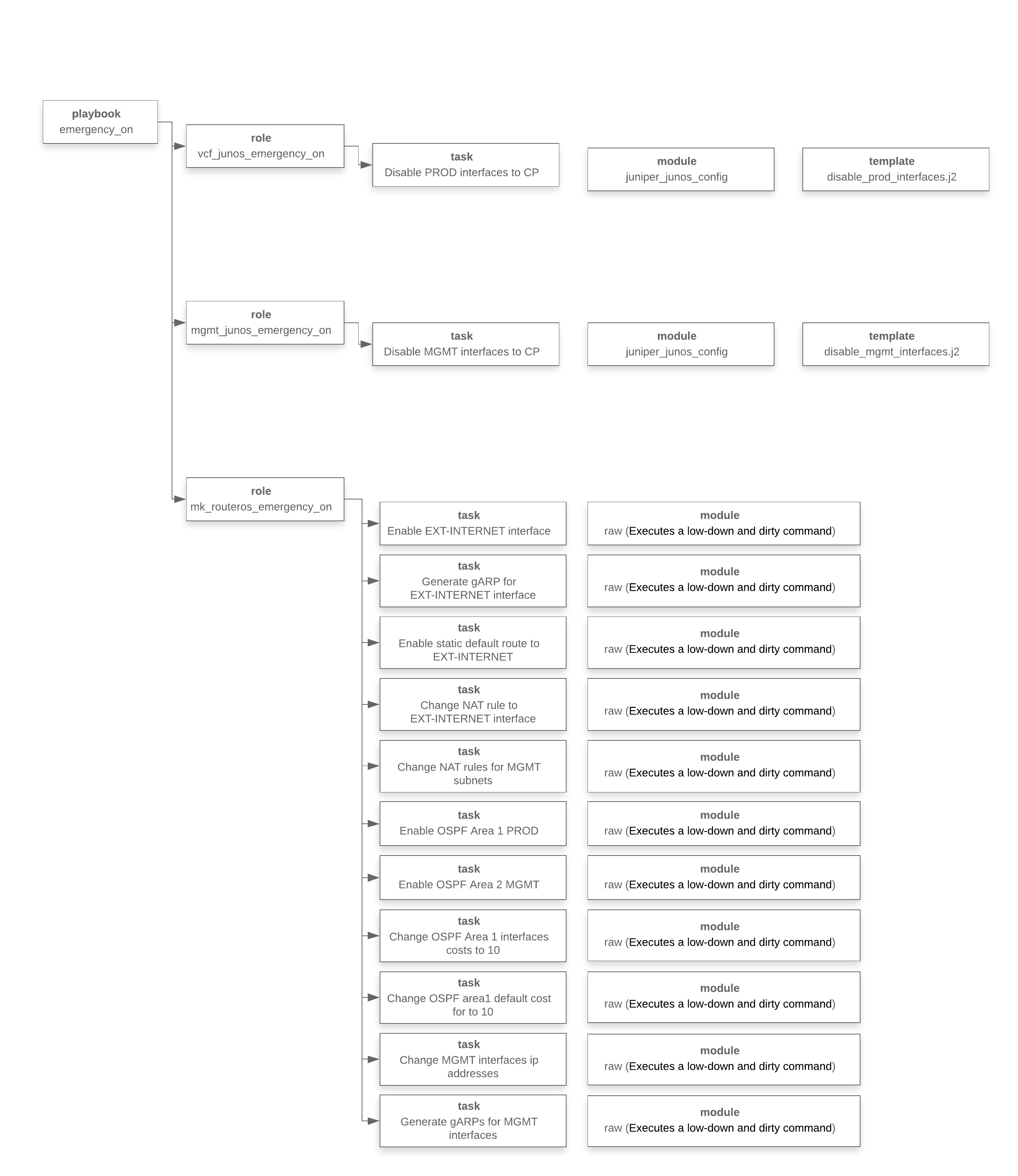 En esta etapa, nos dimos cuenta de lo que había que hacer, desarrollamos un libro de jugadas, realizamos pruebas, ahora estamos listos para lanzarlo.Otra pequeña digresión. La facilidad de la narración no debe confundirte. El proceso de escribir libros de jugadas no fue tan simple y rápido como podría parecer. Las pruebas tomaron bastante tiempo, se creó un soporte virtual, la solución se implementó muchas veces, se realizaron aproximadamente 100 pruebas.Comenzamos ... Hay una sensación de que todo sucede muy lentamente, en algún lugar hay un error, algo no funcionará al final. La sensación de un salto en paracaídas, y el paracaídas no quiere abrirse de inmediato ... eso es normal.A continuación, leemos el resultado de las operaciones del libro de jugadas Ansible (reemplazamos las direcciones IP con fines de conspiración):
En esta etapa, nos dimos cuenta de lo que había que hacer, desarrollamos un libro de jugadas, realizamos pruebas, ahora estamos listos para lanzarlo.Otra pequeña digresión. La facilidad de la narración no debe confundirte. El proceso de escribir libros de jugadas no fue tan simple y rápido como podría parecer. Las pruebas tomaron bastante tiempo, se creó un soporte virtual, la solución se implementó muchas veces, se realizaron aproximadamente 100 pruebas.Comenzamos ... Hay una sensación de que todo sucede muy lentamente, en algún lugar hay un error, algo no funcionará al final. La sensación de un salto en paracaídas, y el paracaídas no quiere abrirse de inmediato ... eso es normal.A continuación, leemos el resultado de las operaciones del libro de jugadas Ansible (reemplazamos las direcciones IP con fines de conspiración):[xxx@emergency ansible]$ ansible-playbook -i /etc/ansible/inventories/prod_inventory.ini /etc/ansible/playbooks/emergency_on.yml
PLAY [------->Emergency on VCF] ********************************************************
TASK [vcf_junos_emergency_on : Disable PROD interfaces to FW-CLUSTER] *********************
changed: [vcf]
PLAY [------->Emergency on MGMT-CORE] ************************************************
TASK [mgmt_junos_emergency_on : Disable MGMT interfaces to FW-CLUSTER] ******************
changed: [m9-03-sw-03-mgmt-core]
PLAY [------->Emergency on] ****************************************************
TASK [mk_routeros_emergency_on : Enable EXT-INTERNET interface] **************************
changed: [m9-04-r-04]
TASK [mk_routeros_emergency_on : Generate gARP for EXT-INTERNET interface] ****************
changed: [m9-04-r-04]
TASK [mk_routeros_emergency_on : Enable static default route to EXT-INTERNET] ****************
changed: [m9-04-r-04]
TASK [mk_routeros_emergency_on : Change NAT rule to EXT-INTERNET interface] ****************
changed: [m9-04-r-04] => (item=12)
changed: [m9-04-r-04] => (item=14)
changed: [m9-04-r-04] => (item=15)
changed: [m9-04-r-04] => (item=16)
changed: [m9-04-r-04] => (item=17)
TASK [mk_routeros_emergency_on : Enable OSPF Area 1 PROD] ******************************
changed: [m9-04-r-04]
TASK [mk_routeros_emergency_on : Enable OSPF Area 2 MGMT] *****************************
changed: [m9-04-r-04]
TASK [mk_routeros_emergency_on : Change OSPF Area 1 interfaces costs to 10] *****************
changed: [m9-04-r-04] => (item=VLAN-1001)
changed: [m9-04-r-04] => (item=VLAN-1002)
changed: [m9-04-r-04] => (item=VLAN-1003)
changed: [m9-04-r-04] => (item=VLAN-1004)
changed: [m9-04-r-04] => (item=VLAN-1005)
changed: [m9-04-r-04] => (item=VLAN-1006)
changed: [m9-04-r-04] => (item=VLAN-1007)
changed: [m9-04-r-04] => (item=VLAN-1008)
changed: [m9-04-r-04] => (item=VLAN-1009)
changed: [m9-04-r-04] => (item=VLAN-1010)
changed: [m9-04-r-04] => (item=VLAN-1011)
changed: [m9-04-r-04] => (item=VLAN-1012)
changed: [m9-04-r-04] => (item=VLAN-1013)
changed: [m9-04-r-04] => (item=VLAN-1100)
TASK [mk_routeros_emergency_on : Change OSPF area1 default cost for to 10] ******************
changed: [m9-04-r-04]
TASK [mk_routeros_emergency_on : Change MGMT interfaces ip addresses] ********************
changed: [m9-04-r-04] => (item={u'ip': u'..n.254', u'name': u'VLAN-803'})
changed: [m9-04-r-04] => (item={u'ip': u'..n+1.254', u'name': u'VLAN-805'})
changed: [m9-04-r-04] => (item={u'ip': u'..n+2.254', u'name': u'VLAN-807'})
changed: [m9-04-r-04] => (item={u'ip': u'..n+3.254', u'name': u'VLAN-809'})
changed: [m9-04-r-04] => (item={u'ip': u'..n+4.254', u'name': u'VLAN-820'})
changed: [m9-04-r-04] => (item={u'ip': u'..n+5.254', u'name': u'VLAN-822'})
changed: [m9-04-r-04] => (item={u'ip': u'..n+6.254', u'name': u'VLAN-823'})
changed: [m9-04-r-04] => (item={u'ip': u'..n+7.254', u'name': u'VLAN-824'})
changed: [m9-04-r-04] => (item={u'ip': u'..n+8.254', u'name': u'VLAN-850'})
changed: [m9-04-r-04] => (item={u'ip': u'..n+9.254', u'name': u'VLAN-851'})
changed: [m9-04-r-04] => (item={u'ip': u'..n+10.254', u'name': u'VLAN-852'})
changed: [m9-04-r-04] => (item={u'ip': u'..n+11.254', u'name': u'VLAN-853'})
changed: [m9-04-r-04] => (item={u'ip': u'..n+12.254', u'name': u'VLAN-870'})
changed: [m9-04-r-04] => (item={u'ip': u'..n+13.254', u'name': u'VLAN-898'})
changed: [m9-04-r-04] => (item={u'ip': u'..n+14.254', u'name': u'VLAN-899'})
TASK [mk_routeros_emergency_on : Generate gARPs for MGMT interfaces] *********************
changed: [m9-04-r-04] => (item={u'ip': u'..n.254', u'name': u'VLAN-803'})
changed: [m9-04-r-04] => (item={u'ip': u'..n+1.254', u'name': u'VLAN-805'})
changed: [m9-04-r-04] => (item={u'ip': u'..n+2.254', u'name': u'VLAN-807'})
changed: [m9-04-r-04] => (item={u'ip': u'..n+3.254', u'name': u'VLAN-809'})
changed: [m9-04-r-04] => (item={u'ip': u'..n+4.254', u'name': u'VLAN-820'})
changed: [m9-04-r-04] => (item={u'ip': u'..n+5.254', u'name': u'VLAN-822'})
changed: [m9-04-r-04] => (item={u'ip': u'..n+6.254', u'name': u'VLAN-823'})
changed: [m9-04-r-04] => (item={u'ip': u'..n+7.254', u'name': u'VLAN-824'})
changed: [m9-04-r-04] => (item={u'ip': u'..n+8.254', u'name': u'VLAN-850'})
changed: [m9-04-r-04] => (item={u'ip': u'..n+9.254', u'name': u'VLAN-851'})
changed: [m9-04-r-04] => (item={u'ip': u'..n+10.254', u'name': u'VLAN-852'})
changed: [m9-04-r-04] => (item={u'ip': u'..n+11.254', u'name': u'VLAN-853'})
changed: [m9-04-r-04] => (item={u'ip': u'..n+12.254', u'name': u'VLAN-870'})
changed: [m9-04-r-04] => (item={u'ip': u'..n+13.254', u'name': u'VLAN-898'})
changed: [m9-04-r-04] => (item={u'ip': u'..n+14.254', u'name': u'VLAN-899'})
PLAY RECAP ************************************************************************
¡Hecho!En realidad, no está listo, no se olvide de la convergencia de los protocolos de enrutamiento dinámico y la carga de una gran cantidad de rutas en la FIB. No podemos influir en esto de ninguna manera. Esperamos. Se unió. Ahora está listoY en el pueblo de Vilabaggio (que no quiere automatizar la configuración de la red), continúan lavando platos. Bruce (aunque ya es diferente, pero no menos interesante) está tratando de averiguar cuántos equipos más se reconfiguran manualmente. También me gustaría detenerme en un punto importante. ¿Cómo recuperamos todo? Después de un tiempo, daremos vida a nuestro FW-CLUSTER. Este es el equipo principal, no el de respaldo, la red debería funcionar en él.¿Tienes ganas de empezar a quemar en los networkers? El director técnico escuchará miles de argumentos por los cuales esto no es necesario, por qué puede hacerse más tarde. Desafortunadamente, así es como la red funciona a partir de un montón de parches, piezas, restos de antiguos lujos. Resulta una colcha. Nuestra tarea como un todo, no en esta situación particular, pero en general, en principio, como especialistas en TI, es llevar la red a la hermosa palabra inglesa "consistencia", es muy multifacética, se puede traducir como: consistencia, consistencia, consistencia, coherencia, consistencia, comparabilidad, conectividad. Esto se trata de él. Solo en este estado es manejable la red, entendemos claramente qué y cómo funciona, entendemos claramente qué necesita ser cambiado, si es necesario, sabemos claramente dónde buscar en caso de problemas.Y solo en esa red puedes hacer trucos como los que acabamos de describir.En realidad, se preparó otro libro de jugadas, que devolvió la configuración a su estado original. La lógica de su trabajo es la misma (es importante recordar, el orden de las tareas es muy importante), para no extender el artículo ya largo, decidimos no publicar la lista del libro de jugadas. Después de realizar dichos ejercicios, se sentirá mucho más tranquilo y seguro en el futuro, además, cualquier muleta que apile allí se encontrará de inmediato.Todos pueden escribirnos y obtener el código fuente de todo el código escrito, junto con todos los libros de cálculo. Contactos en el perfil.
También me gustaría detenerme en un punto importante. ¿Cómo recuperamos todo? Después de un tiempo, daremos vida a nuestro FW-CLUSTER. Este es el equipo principal, no el de respaldo, la red debería funcionar en él.¿Tienes ganas de empezar a quemar en los networkers? El director técnico escuchará miles de argumentos por los cuales esto no es necesario, por qué puede hacerse más tarde. Desafortunadamente, así es como la red funciona a partir de un montón de parches, piezas, restos de antiguos lujos. Resulta una colcha. Nuestra tarea como un todo, no en esta situación particular, pero en general, en principio, como especialistas en TI, es llevar la red a la hermosa palabra inglesa "consistencia", es muy multifacética, se puede traducir como: consistencia, consistencia, consistencia, coherencia, consistencia, comparabilidad, conectividad. Esto se trata de él. Solo en este estado es manejable la red, entendemos claramente qué y cómo funciona, entendemos claramente qué necesita ser cambiado, si es necesario, sabemos claramente dónde buscar en caso de problemas.Y solo en esa red puedes hacer trucos como los que acabamos de describir.En realidad, se preparó otro libro de jugadas, que devolvió la configuración a su estado original. La lógica de su trabajo es la misma (es importante recordar, el orden de las tareas es muy importante), para no extender el artículo ya largo, decidimos no publicar la lista del libro de jugadas. Después de realizar dichos ejercicios, se sentirá mucho más tranquilo y seguro en el futuro, además, cualquier muleta que apile allí se encontrará de inmediato.Todos pueden escribirnos y obtener el código fuente de todo el código escrito, junto con todos los libros de cálculo. Contactos en el perfil.recomendaciones
En nuestra opinión, los procesos que pueden automatizarse aún no se han cristalizado. Según lo que encontramos y lo que nuestros colegas occidentales están discutiendo, los siguientes temas aún son visibles:- Aprovisionamiento de dispositivos;
- Recopilación de datos;
- Informes
- Solución de problemas;
- Conformidad
Si hay interés, podemos continuar la discusión sobre uno de los temas dados.También quiero especular un poco sobre la automatización. ¿Qué debería ser a nuestro entender?- El sistema debe vivir sin un hombre, mientras mejora al hombre. El sistema no debe depender de la persona;
- La operación debe ser experta. No hay una clase de especialistas que realicen tareas rutinarias. Hay expertos que han automatizado toda la rutina y resuelven solo problemas complejos;
- Las tareas rutinarias \ estándar se realizan automáticamente "por botón", los recursos no se desperdician. El resultado de tales tareas es siempre predecible y comprensible.
Y a qué deberían conducir estos puntos:- Transparencia de la infraestructura de TI (Menos riesgos de operación, modernización, implementación. Menos tiempo de inactividad por año);
- La capacidad de planificar recursos de TI (sistema de planificación de capacidad: puede ver cuánto se consume, cuántos recursos se necesitan en un solo sistema y no mediante cartas y visitas a los principales departamentos);
- Capacidad para reducir la cantidad de personal de TI.
Autores del artículo: Alexander Manov (CCIE RS, CCIE SP) y Pavel Kirillov. Estamos interesados en discutir y proponer soluciones sobre el tema de la automatización de la infraestructura de TI.