Al escribir aplicaciones en Python, los mapeadores relacionales de objetos (ORM) a menudo se usan para trabajar con bases de datos. Ejemplos de ORM son SQLALchemy, PonyORM y el mapeador de objetos relacionales incluido con Django. Al elegir ORM, su rendimiento juega un papel bastante importante.
En Habr, y en Internet en su conjunto, es posible encontrar ni una sola prueba de rendimiento. Como ejemplo de un punto de referencia de calidad de Python ORM, puede utilizar el punto de referencia Tortoise ORM ( enlace al repositorio ). Este punto de referencia analiza la velocidad de seis ORM para once tipos diferentes de consultas SQL.
En general, el punto de referencia de la tortuga hace posible evaluar la velocidad de ejecución de consultas utilizando diferentes ORM, pero veo un problema con este enfoque de prueba. Los ORM a menudo se usan en aplicaciones web donde varios usuarios pueden enviar diferentes solicitudes al mismo tiempo, pero no he encontrado un solo punto de referencia que evalúe el rendimiento de ORM en tales condiciones. Como resultado de esto, decidí escribir mi punto de referencia y comparar PonyORM y SQLAlchemy con él. Como base, tomé el punto de referencia TPC-C.
La empresa TPC desde 1988 desarrolla pruebas destinadas a procesar datos. Se han convertido en un estándar de la industria y son utilizados por casi todos los proveedores de equipos en varias muestras de hardware y software. La característica principal de estas pruebas es que están destinadas a realizar pruebas bajo una carga enorme en condiciones lo más cercanas posible a las reales.
TPC-C simula una red de almacenes. Incluye una combinación de cinco transacciones ejecutadas simultáneamente de varios tipos y complejidad. La base de datos consta de nueve tablas con una gran cantidad de registros. El rendimiento en la prueba TPC-C se mide en transacciones por minuto.
Decidí probar dos ORM de Python (SQLALchemy y PonyORM) usando el método de prueba TPC-C adaptado para esta tarea. El propósito de la prueba es evaluar la velocidad del procesamiento de transacciones cuando varios usuarios virtuales acceden a la base de datos al mismo tiempo.
Descripción de la prueba
En la prueba que escribí, primero se crea y se completa una base de datos, que es una base de datos de una red de almacenes. El esquema de la base se parece a esto :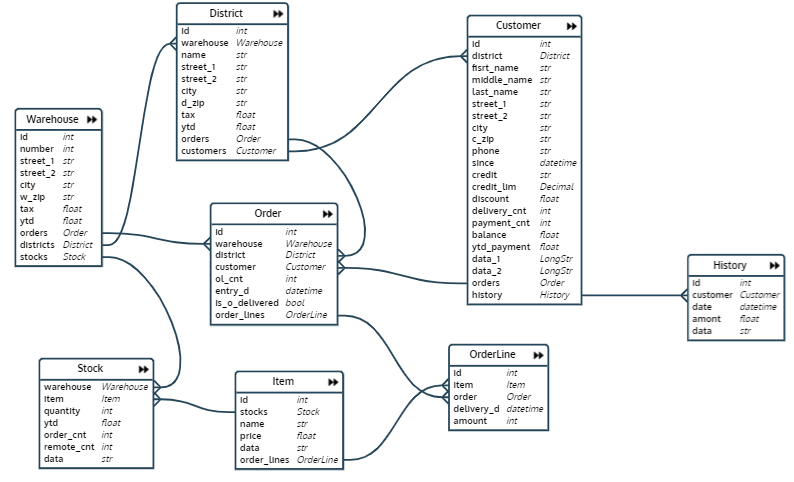
La base de datos consta de ocho relaciones:
- Almacén - almacén
- Distrito - área de almacén
- Orden orden
- OrderLine - línea de pedido (artículo de pedido)
- Stock: cantidad de un determinado producto en un almacén específico
- Artículo - artículo
- Cliente - cliente
- Historial: historial de pagos del cliente
, e . . , :
- new_order ( ) — 45%
- payment ( ) — 43%
- order_status ( ) — 4%
- delivery ( ) — 4%
- stock_level ( ) — 4%
, TPC-C.
TPC-C , , ORM, . 64+ , .
:
- ,
- . : Stock 100 000 * W, W — , : 100 * W
- 5 . Payment ID, . ID,
- NewOrder. , , Order, NewOrder. , NewOrder. , , , , , . Order bool “is_o_delivered”, False, ,
, .
New Order
- : id id
- id
- ()
- . Item.
- , .
Payment
- : id id
- id
- .
- 1
- , ,
- .
Estado del pedido
- Transacciones servidas por ID de cliente
- El cliente y su último pedido se toman de la base de datos.
- El estado se toma del pedido (entregado o no) y los artículos del pedido
Entrega
- Transacciones atendidas por ID de almacén
- El almacén se solicita de la base de datos por id y todas sus secciones
- Para cada sitio, se toma el más antiguo de los pedidos no entregados. En cada uno de ellos, el estado de entrega cambia a Verdadero
- De la base de datos se toman usuarios cuyos pedidos fueron entregados durante esta transacción, y cada uno de ellos aumenta el contador de entregas
Nivel de existencias
- Transacciones atendidas por ID de almacén
- El almacén se solicita de la base de datos por id
- Los últimos 20 pedidos de este almacén se solicitan a la base de datos.
- Para cada artículo de estos pedidos de la base de datos, se solicita la cantidad de mercancías restantes en el almacén
Resultados de la prueba
Dos ORM están involucrados en las pruebas:- SQLAlchemy Los gráficos están representados por una línea azul.
- PonyORM. Los gráficos están representados por la línea amarilla.
10 2 , . multiprocessing.
—
—
PostgreSQL
, TPC-C. Pony .

:
Pony — 2543 /
SQLAlchemy — 1353.4 /
ORM . .
“New Order”

Velocidad media:
Pony - 3349.2 trans / min
SQLAlchemy - 1415.3 trans / min
Transacción "Pago"
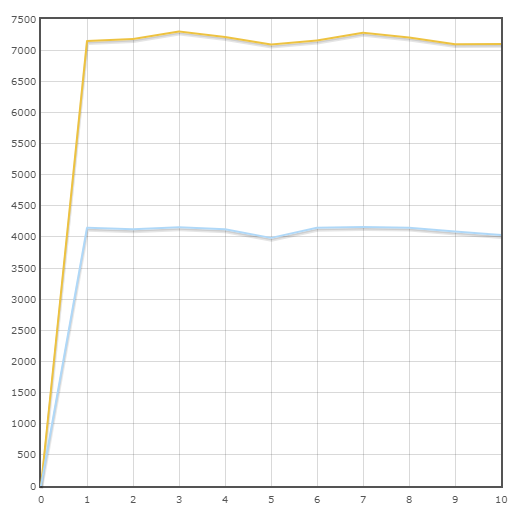
Velocidad media:
Pony - 7175.3 trans / min
SQLAlchemy - 4110.6 trans / min
Transacción "Estado del pedido"
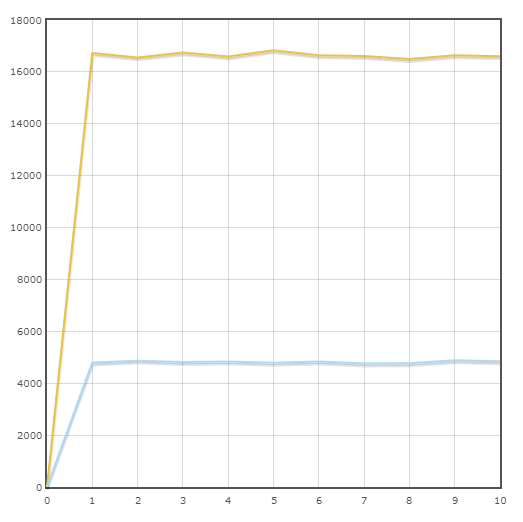
Velocidad media:
Pony - 16645.6 trans / min
SQLAlchemy - 4820.8 trans / min
Transacción "Entrega"
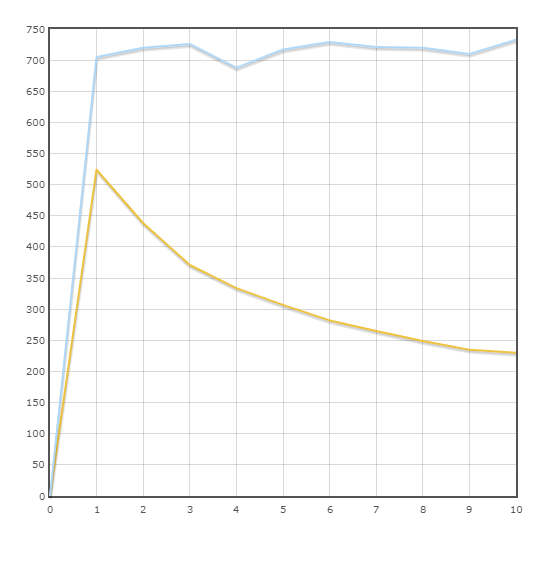
Velocidad media:
SQLAlchemy - 716.9 trans / min
Pony - 323.5 trans / min
Transacción "Nivel de stock"
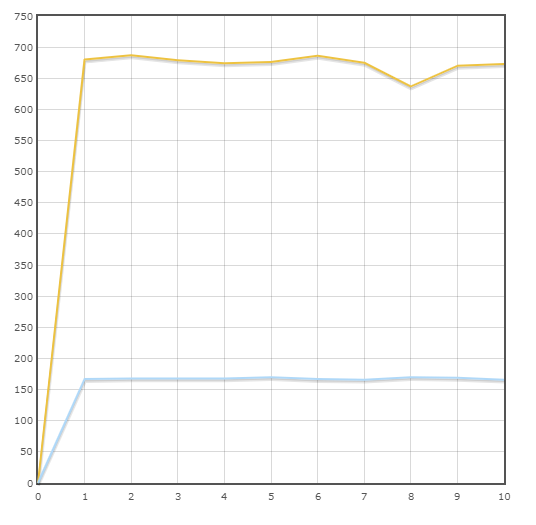
Velocidad media:
Pony - 677.3 trans / min
SQLAlchemy - 167.9 trans / min
Análisis de resultados de prueba
Después de recibir los resultados, analicé por qué, en diversas situaciones, un ORM es más rápido que otro y llegué a las siguientes conclusiones:4 5 PonyORM , , SQL PonyORM Python SQL, , SQLALchemy SQL . PonyORM:
stocks = select(stock for stock in Stock
if stock.warehouse == whouse
and stock.item in items).order_by(Stock.id).for_update()
SQLAlchemy:
stocks = session.query(Stock).filter(
Stock.warehouse == whouse, Stock.item.in_(items)).order_by(text("id")).with_for_update()
SQLAlchemy Delivery , UPDATE, , .
, SQLAlchemy:
INFO:sqlalchemy.engine.base.Engine:UPDATE order_line SET delivery_d=%(delivery_d)s WHERE order_line.id = %(order_line_id)s
INFO:sqlalchemy.engine.base.Engine:(
{'delivery_d': datetime.datetime(2020, 4, 6, 14, 33, 6, 922281), 'order_line_id': 316},
{'delivery_d': datetime.datetime(2020, 4, 6, 14, 33, 6, 922272), 'order_line_id': 317},
{'delivery_d': datetime.datetime(2020, 4, 6, 14, 33, 6, 922261))
Pony Update:
SELECT "id", "delivery_d", "item", "amount", "order"
FROM "orderline"
WHERE "order" = %(p1)s
{'p1':911}
UPDATE "orderline"
SET "delivery_d" = %(p1)s
WHERE "id" = %(p2)s
AND "order" = %(p3)s
{'p1':datetime.datetime(2020, 4, 7, 17, 48, 58, 585932), 'p2':5047, 'p3':911}
UPDATE "orderline"
SET "delivery_d" = %(p1)s
WHERE "id" = %(p2)s
AND "order" = %(p3)s
{'p1':datetime.datetime(2020, 4, 7, 17, 48, 58, 585990), 'p2':5048, 'p3':911}
Con base en los resultados de estas pruebas, puedo decir que Pony funciona mucho más rápido cuando se recupera de una base de datos, y SQLAlchemy en algunos casos puede producir consultas de actualización significativamente más rápidas.En el futuro, planeo probar otros ORM (Peewee, Django) de esta manera.
Referencias
Código de prueba: enlace del repositorio
SQLAlchemy: documentación , comunidad
Pony: documentación , comunidad