El modo remoto de operación en el contexto del autoaislamiento universal puede tener muy malas consecuencias. Y agotamiento emocional: todavía está donde sea que vaya: después de todo, no está lejos del techo. En este sentido, como muchos, trató de "calmarse" asignando tiempo para otras clases, y comenzó a traducir los artículos más interesantes del inglés al ruso: "¡Le das aprendizaje automático a las masas!".) Debemos rendir homenaje: es una gran distracción. Si tiene sugerencias para el contenido semántico y la traducción de este texto para un lector de habla rusa, únase a la discusión. Entonces, aquí hay una traducción de la página de pronóstico de series temporales de la sección del manual de tensorflow: enlace . Mis adiciones, junto con las ilustraciones para la traducción, están destinadas a ayudar a comprender las ideas básicas en una de las áreas más interesantes de LA y la econometría en general: predicción de series de tiempo.Una pequeña introducción antes de la traducción.El manual es una descripción de la predicción de la temperatura del aire basada en series de tiempo unidimensionales (series de tiempo univariadas) y series de tiempo multivariadas ( series de tiempo multivariadas) . Para cada parte, ingrese datosdebe estar preparado en consecuencia. Teniendo en cuenta el conjunto de datos meteorológicos considerado en este manual, la separación es la siguiente:
Entonces, aquí hay una traducción de la página de pronóstico de series temporales de la sección del manual de tensorflow: enlace . Mis adiciones, junto con las ilustraciones para la traducción, están destinadas a ayudar a comprender las ideas básicas en una de las áreas más interesantes de LA y la econometría en general: predicción de series de tiempo.Una pequeña introducción antes de la traducción.El manual es una descripción de la predicción de la temperatura del aire basada en series de tiempo unidimensionales (series de tiempo univariadas) y series de tiempo multivariadas ( series de tiempo multivariadas) . Para cada parte, ingrese datosdebe estar preparado en consecuencia. Teniendo en cuenta el conjunto de datos meteorológicos considerado en este manual, la separación es la siguiente: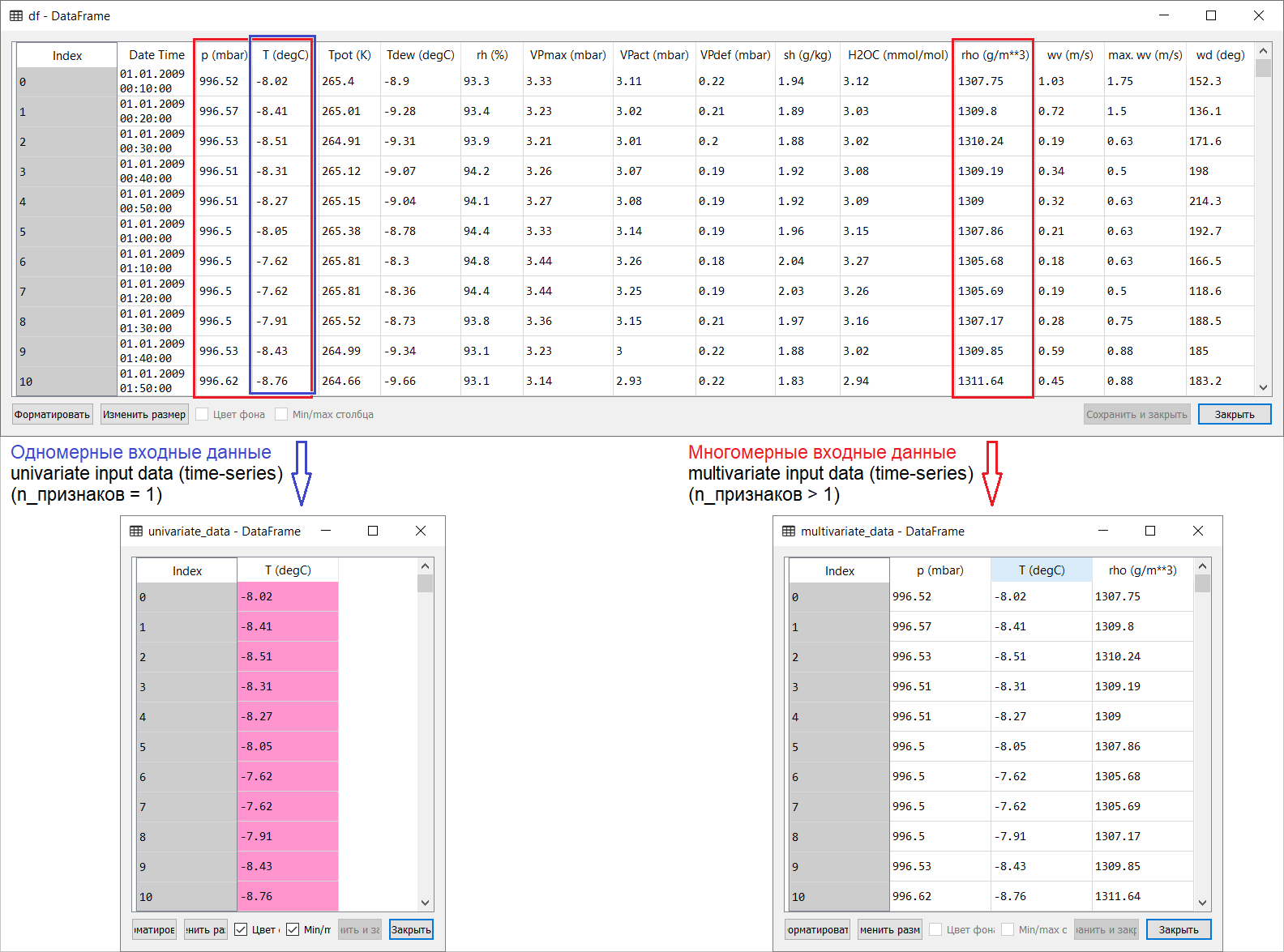 para preguntas sobre qué tomar para X y qué para Y , es decir, cómo preparar datos para la clase de entrenamiento supervisado, quedará claro a partir de las siguientes ilustraciones. Solo noto que la formación del vector objetivo (Y) para trabajar con series de tiempo unidimensionales y multidimensionales es la misma: el vector objetivo se compila sobre la base del signo T (degC)(temperatura del aire). La diferencia entre ellos está "enterrada" en la formación de un conjunto de características que se alimentan a la entrada del modelo: en el caso de una serie de tiempo unidimensional para predecir la temperatura en el futuro, el vector de entrada (X) consta de una característica: de hecho, temperatura del aire; y para multidimensional: más de uno: además de la temperatura del aire, p (mbar) (presión atmosférica) y rho (g / m ** 3) (humedad) se utilizan en el ejemplo del manual en cuestión .Al principio, muy superficial, una mirada a un ejemplo con pronóstico de temperatura parece poco convincente desde el punto de vista del uso de una entrada multidimensional: para pronosticar la temperatura, el signo más relevante será la temperatura. Sin embargo, este no es el caso en absoluto: para desarrollar un pronóstico cualitativo de la temperatura del aire, se deben tener en cuenta muchos factores, hasta la fricción del aire en la superficie de la tierra, etc. Además, en la práctica, algunas cosas están lejos de ser obvias, y el vector objetivo puede tener la forma de ese batiburrillo (o borsch). En este sentido, el análisis exploratorio de datos con la selección de las características más relevantes para la posterior formación de una entrada multidimensional es la única decisión correcta.Entonces, la traducción del manual se presenta a continuación. El texto adicional estará en cursiva .
para preguntas sobre qué tomar para X y qué para Y , es decir, cómo preparar datos para la clase de entrenamiento supervisado, quedará claro a partir de las siguientes ilustraciones. Solo noto que la formación del vector objetivo (Y) para trabajar con series de tiempo unidimensionales y multidimensionales es la misma: el vector objetivo se compila sobre la base del signo T (degC)(temperatura del aire). La diferencia entre ellos está "enterrada" en la formación de un conjunto de características que se alimentan a la entrada del modelo: en el caso de una serie de tiempo unidimensional para predecir la temperatura en el futuro, el vector de entrada (X) consta de una característica: de hecho, temperatura del aire; y para multidimensional: más de uno: además de la temperatura del aire, p (mbar) (presión atmosférica) y rho (g / m ** 3) (humedad) se utilizan en el ejemplo del manual en cuestión .Al principio, muy superficial, una mirada a un ejemplo con pronóstico de temperatura parece poco convincente desde el punto de vista del uso de una entrada multidimensional: para pronosticar la temperatura, el signo más relevante será la temperatura. Sin embargo, este no es el caso en absoluto: para desarrollar un pronóstico cualitativo de la temperatura del aire, se deben tener en cuenta muchos factores, hasta la fricción del aire en la superficie de la tierra, etc. Además, en la práctica, algunas cosas están lejos de ser obvias, y el vector objetivo puede tener la forma de ese batiburrillo (o borsch). En este sentido, el análisis exploratorio de datos con la selección de las características más relevantes para la posterior formación de una entrada multidimensional es la única decisión correcta.Entonces, la traducción del manual se presenta a continuación. El texto adicional estará en cursiva .Predicción de series de tiempo
Esta guía es una introducción a la predicción de series de tiempo utilizando redes neuronales recurrentes (RNS, de la Red neuronal recurrente inglesa , RNN ). Consta de dos partes: la primera describe la predicción de la temperatura del aire basada en una serie de tiempo unidimensional, y la segunda, basada en una serie de tiempo multidimensional.import tensorflow as tf
import matplotlib as mpl
import matplotlib.pyplot as plt
import numpy as np
import os
import pandas as pd
mpl.rcParams['figure.figsize'] = (8, 6)
mpl.rcParams['axes.grid'] = False
Un conjunto de datos meteorológicosTodos los ejemplos del manual utilizan secuencias de tiempo de datos meteorológicos registrados en una estación hidrometeorológica en el Instituto de Biogeoquímica con el nombre de Max Planck .Este conjunto de datos incluye mediciones de 14 indicadores meteorológicos diferentes (como temperatura del aire, presión atmosférica, humedad), que se realizan cada 10 minutos desde 2003. Para ahorrar tiempo y uso de memoria, el manual utilizará datos que cubren el período de 2009 a 2016. Esta sección del conjunto de datos fue preparada por François Chollet para su libro, Deep Learning with Python .zip_path = tf.keras.utils.get_file(
origin='https://storage.googleapis.com/tensorflow/tf-keras-datasets/jena_climate_2009_2016.csv.zip',
fname='jena_climate_2009_2016.csv.zip',
extract=True)
csv_path, _ = os.path.splitext(zip_path)
df = pd.read_csv(csv_path)
Veamos que tenemos.df.head()
 La tabla anterior puede verificar el hecho de que el período de registro de observación es de 10 minutos. Por lo tanto, en una hora tendrás 6 observaciones. A su vez, se acumulan 144 (6x24) observaciones por día.Digamos que desea predecir la temperatura, que será en 6 horas en el futuro. Realiza este pronóstico en función de los datos que tiene para un período determinado: por ejemplo, decide utilizar 5 días de observación. Por lo tanto, para entrenar el modelo, debe crear un intervalo de tiempo que contenga las últimas 720 (5x144) observaciones (dado que son posibles diferentes configuraciones, este conjunto de datos es una buena base para los experimentos).La siguiente función devuelve los intervalos de tiempo anteriores para entrenar el modelo. Argumento
La tabla anterior puede verificar el hecho de que el período de registro de observación es de 10 minutos. Por lo tanto, en una hora tendrás 6 observaciones. A su vez, se acumulan 144 (6x24) observaciones por día.Digamos que desea predecir la temperatura, que será en 6 horas en el futuro. Realiza este pronóstico en función de los datos que tiene para un período determinado: por ejemplo, decide utilizar 5 días de observación. Por lo tanto, para entrenar el modelo, debe crear un intervalo de tiempo que contenga las últimas 720 (5x144) observaciones (dado que son posibles diferentes configuraciones, este conjunto de datos es una buena base para los experimentos).La siguiente función devuelve los intervalos de tiempo anteriores para entrenar el modelo. Argumentohistory_size- este es el tamaño del último intervalo de tiempo, target_size- un argumento que determina qué tan lejos en el futuro el modelo debe aprender a predecir. En otras palabras, target_sizees el vector objetivo que debe predecirse.def univariate_data(dataset, start_index, end_index, history_size, target_size):
data = []
labels = []
start_index = start_index + history_size
if end_index is None:
end_index = len(dataset) - target_size
for i in range(start_index, end_index):
indices = range(i-history_size, i)
data.append(np.reshape(dataset[indices], (history_size, 1)))
labels.append(dataset[i+target_size])
return np.array(data), np.array(labels)
En ambas partes del manual, las primeras 300,000 filas de datos se usarán para entrenar el modelo, las restantes para validarlo (validarlo). En este caso, la cantidad de datos de entrenamiento es de aproximadamente 2100 días.TRAIN_SPLIT = 300000
Para garantizar resultados reproducibles, se establece la función semilla.tf.random.set_seed(13)
Parte 1. Pronóstico basado en una serie de tiempo unidimensional
En la primera parte, entrenará el modelo utilizando solo un atributo: temperatura; El modelo entrenado se utilizará para predecir las temperaturas futuras.Para comenzar, extraemos solo la temperatura del conjunto de datos.uni_data = df['T (degC)']
uni_data.index = df['Date Time']
uni_data.head()
Date Time
01.01.2009 00:10:00 -8.02
01.01.2009 00:20:00 -8.41
01.01.2009 00:30:00 -8.51
01.01.2009 00:40:00 -8.31
01.01.2009 00:50:00 -8.27
Name: T (degC), dtype: float64
Y veamos cómo cambian estos datos con el tiempo.uni_data.plot(subplots=True)

uni_data = uni_data.values
Antes de entrenar una red neuronal artificial (en adelante, ANN), un paso importante es el escalado de datos. Una de las formas comunes de realizar la escala es la estandarización ( estandarización ), realizada restando la media y dividiendo por la desviación estándar para cada característica. También puede usar un método tf.keras.utils.normalizeque escala los valores al rango [0,1].Nota : la estandarización solo debe llevarse a cabo utilizando datos de capacitación.uni_train_mean = uni_data[:TRAIN_SPLIT].mean()
uni_train_std = uni_data[:TRAIN_SPLIT].std()
Realizamos estandarización de datos.uni_data = (uni_data-uni_train_mean)/uni_train_std
A continuación, prepararemos los datos para el modelo con una entrada unidimensional. Las últimas 20 observaciones registradas de la temperatura se enviarán a la entrada del modelo, y el modelo debe estar entrenado para predecir la temperatura en el siguiente paso.univariate_past_history = 20
univariate_future_target = 0
x_train_uni, y_train_uni = univariate_data(uni_data, 0, TRAIN_SPLIT,
univariate_past_history,
univariate_future_target)
x_val_uni, y_val_uni = univariate_data(uni_data, TRAIN_SPLIT, None,
univariate_past_history,
univariate_future_target)
Los resultados de aplicar la función univariate_data.print ('Single window of past history')
print (x_train_uni[0])
print ('\n Target temperature to predict')
print (y_train_uni[0])
Single window of past history
[[-1.99766294]
[-2.04281897]
[-2.05439744]
[-2.0312405 ]
[-2.02660912]
[-2.00113649]
[-1.95134907]
[-1.95134907]
[-1.98492663]
[-2.04513467]
[-2.08334362]
[-2.09723778]
[-2.09376424]
[-2.09144854]
[-2.07176515]
[-2.07176515]
[-2.07639653]
[-2.08913285]
[-2.09260639]
[-2.10418486]]
Target temperature to predict
-2.1041848598100876
Además: la preparación de datos para un modelo con una entrada unidimensional se muestra esquemáticamente en la siguiente figura (por conveniencia, en esta y en las figuras posteriores, los datos se presentan en forma "sin procesar", antes de la estandarización, y también sin el atributo 'Fecha y hora' como índice): Ahora que los datos adecuadamente preparado, considere un ejemplo concreto. La información transmitida al ANN se resalta en azul, una cruz roja indica el valor futuro que el ANN debe predecir.
Ahora que los datos adecuadamente preparado, considere un ejemplo concreto. La información transmitida al ANN se resalta en azul, una cruz roja indica el valor futuro que el ANN debe predecir.def create_time_steps(length):
return list(range(-length, 0))
def show_plot(plot_data, delta, title):
labels = ['History', 'True Future', 'Model Prediction']
marker = ['.-', 'rx', 'go']
time_steps = create_time_steps(plot_data[0].shape[0])
if delta:
future = delta
else:
future = 0
plt.title(title)
for i, x in enumerate(plot_data):
if i:
plt.plot(future, plot_data[i], marker[i], markersize=10,
label=labels[i])
else:
plt.plot(time_steps, plot_data[i].flatten(), marker[i], label=labels[i])
plt.legend()
plt.xlim([time_steps[0], (future+5)*2])
plt.xlabel('Time-Step')
return plt
show_plot([x_train_uni[0], y_train_uni[0]], 0, 'Sample Example')
 Solución básica (sin involucrar el aprendizaje automático)Antes de comenzar la capacitación modelo, instalaremos una solución básica simple ( línea de base ). Consiste en lo siguiente: para un vector de entrada dado, el método de solución básica "escanea" todo el historial y predice el siguiente valor como el promedio de las últimas 20 observaciones.
Solución básica (sin involucrar el aprendizaje automático)Antes de comenzar la capacitación modelo, instalaremos una solución básica simple ( línea de base ). Consiste en lo siguiente: para un vector de entrada dado, el método de solución básica "escanea" todo el historial y predice el siguiente valor como el promedio de las últimas 20 observaciones.def baseline(history):
return np.mean(history)
show_plot([x_train_uni[0], y_train_uni[0], baseline(x_train_uni[0])], 0,
'Baseline Prediction Example')
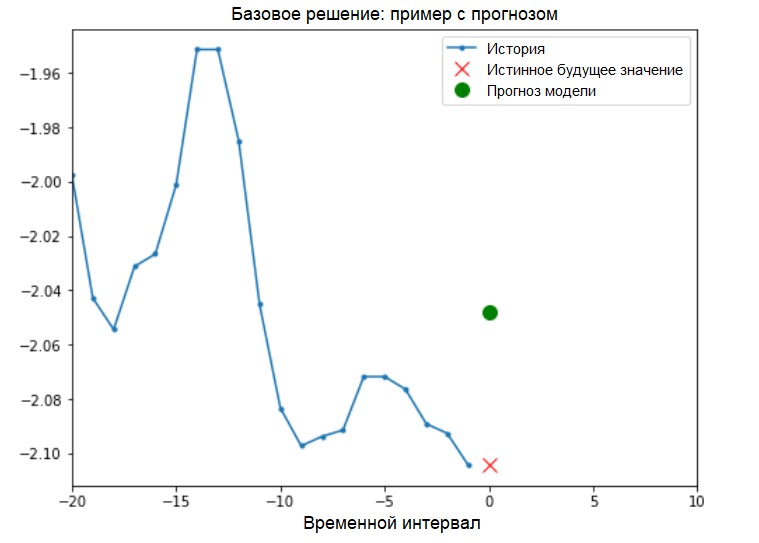 Veamos si podemos superar el resultado de "promediar" usando una red neuronal recurrente.Redneuronal recurrente Una red neuronal recurrente (RNS) es un tipo de ANN que es muy adecuada para resolver problemas de series temporales. RNS paso a paso procesa la secuencia de tiempo de los datos, ordenando sus elementos y preservando el estado interno obtenido al procesar los elementos anteriores. Puede encontrar más información sobre RNS en la siguiente guía . Esta guía utilizará una capa especializada de RNC llamada Memoria a largo plazo ( LSTM ).Uso adicional
Veamos si podemos superar el resultado de "promediar" usando una red neuronal recurrente.Redneuronal recurrente Una red neuronal recurrente (RNS) es un tipo de ANN que es muy adecuada para resolver problemas de series temporales. RNS paso a paso procesa la secuencia de tiempo de los datos, ordenando sus elementos y preservando el estado interno obtenido al procesar los elementos anteriores. Puede encontrar más información sobre RNS en la siguiente guía . Esta guía utilizará una capa especializada de RNC llamada Memoria a largo plazo ( LSTM ).Uso adicionaltf.datarealizar barajado, lote y caché del conjunto de datos.Adición:
Más información sobre los métodos de barajado, lote y caché en la página de tensorflow :BATCH_SIZE = 256
BUFFER_SIZE = 10000
train_univariate = tf.data.Dataset.from_tensor_slices((x_train_uni, y_train_uni))
train_univariate = train_univariate.cache().shuffle(BUFFER_SIZE).batch(BATCH_SIZE).repeat()
val_univariate = tf.data.Dataset.from_tensor_slices((x_val_uni, y_val_uni))
val_univariate = val_univariate.batch(BATCH_SIZE).repeat()
La siguiente visualización debería ayudarlo a comprender cómo se ven los datos después del procesamiento por lotes. Se puede ver que LSTM requiere una cierta forma de entrada de datos, que se le proporciona.
Se puede ver que LSTM requiere una cierta forma de entrada de datos, que se le proporciona.simple_lstm_model = tf.keras.models.Sequential([
tf.keras.layers.LSTM(8, input_shape=x_train_uni.shape[-2:]),
tf.keras.layers.Dense(1)
])
simple_lstm_model.compile(optimizer='adam', loss='mae')
Verifique el resultado del modelo.for x, y in val_univariate.take(1):
print(simple_lstm_model.predict(x).shape)
(256, 1)
Adición:
en términos generales, los RNS funcionan con secuencias. Esto significa que los datos suministrados a la entrada del modelo deben tener la siguiente forma:
[, , - ]
La forma de los datos de entrenamiento para el modelo con una entrada unidimensional tiene la siguiente forma:print(x_train_uni.shape)
(299980, 20, 1)A continuación, estudiaremos el modelo. Debido al gran tamaño del conjunto de datos y para ahorrar tiempo, cada época pasará por solo 200 pasos ( steps_per_epoch = 200 ) en lugar de los datos de entrenamiento completos, como generalmente se hace.EVALUATION_INTERVAL = 200
EPOCHS = 10
simple_lstm_model.fit(train_univariate, epochs=EPOCHS,
steps_per_epoch=EVALUATION_INTERVAL,
validation_data=val_univariate, validation_steps=50)
Train for 200 steps, validate for 50 steps
Epoch 1/10
200/200 [==============================] - 2s 11ms/step - loss: 0.4075 - val_loss: 0.1351
Epoch 2/10
200/200 [==============================] - 1s 4ms/step - loss: 0.1118 - val_loss: 0.0360
Epoch 3/10
200/200 [==============================] - 1s 4ms/step - loss: 0.0490 - val_loss: 0.0289
Epoch 4/10
200/200 [==============================] - 1s 4ms/step - loss: 0.0444 - val_loss: 0.0257
Epoch 5/10
200/200 [==============================] - 1s 4ms/step - loss: 0.0299 - val_loss: 0.0235
Epoch 6/10
200/200 [==============================] - 1s 4ms/step - loss: 0.0317 - val_loss: 0.0224
Epoch 7/10
200/200 [==============================] - 1s 4ms/step - loss: 0.0287 - val_loss: 0.0206
Epoch 8/10
200/200 [==============================] - 1s 4ms/step - loss: 0.0263 - val_loss: 0.0200
Epoch 9/10
200/200 [==============================] - 1s 4ms/step - loss: 0.0254 - val_loss: 0.0182
Epoch 10/10
200/200 [==============================] - 1s 4ms/step - loss: 0.0228 - val_loss: 0.0174
Predicción usando un modelo LSTM simpleDespués de completar la preparación de un modelo LSTM simple, haremos varias predicciones.for x, y in val_univariate.take(3):
plot = show_plot([x[0].numpy(), y[0].numpy(),
simple_lstm_model.predict(x)[0]], 0, 'Simple LSTM model')
plot.show()
 Se ve mejor que el nivel base.Ahora que se ha familiarizado con los conceptos básicos, pasemos a la segunda parte, que describe el trabajo con una serie de tiempo multidimensional.
Se ve mejor que el nivel base.Ahora que se ha familiarizado con los conceptos básicos, pasemos a la segunda parte, que describe el trabajo con una serie de tiempo multidimensional.Parte 2: Predicción de series de tiempo multidimensionales
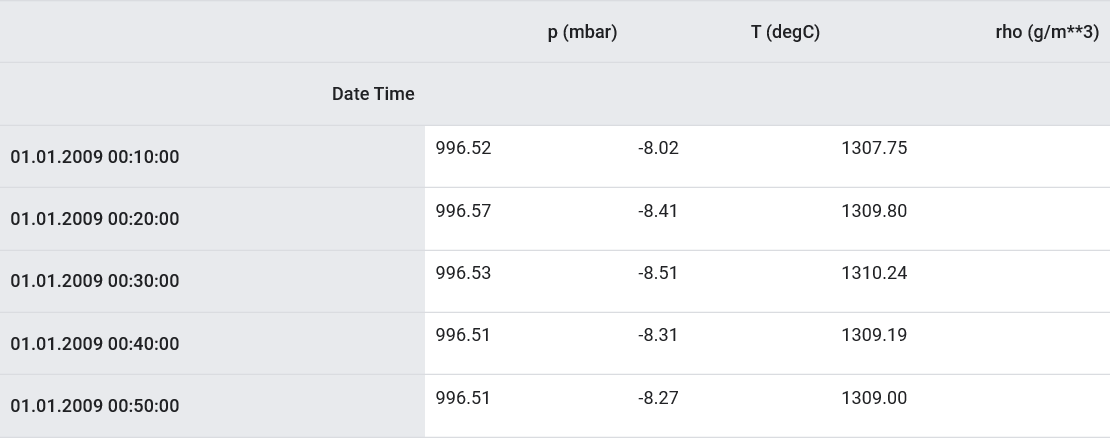
Como se indicó, el conjunto de datos original contiene 14 indicadores meteorológicos diferentes. Por simplicidad y conveniencia, en la segunda parte solo se consideran tres de ellos: temperatura del aire, presión atmosférica y densidad del aire.Para utilizar más características, sus nombres deben ser añadidos a la feature_considered lista .features_considered = ['p (mbar)', 'T (degC)', 'rho (g/m**3)']
features = df[features_considered]
features.index = df['Date Time']
features.head()
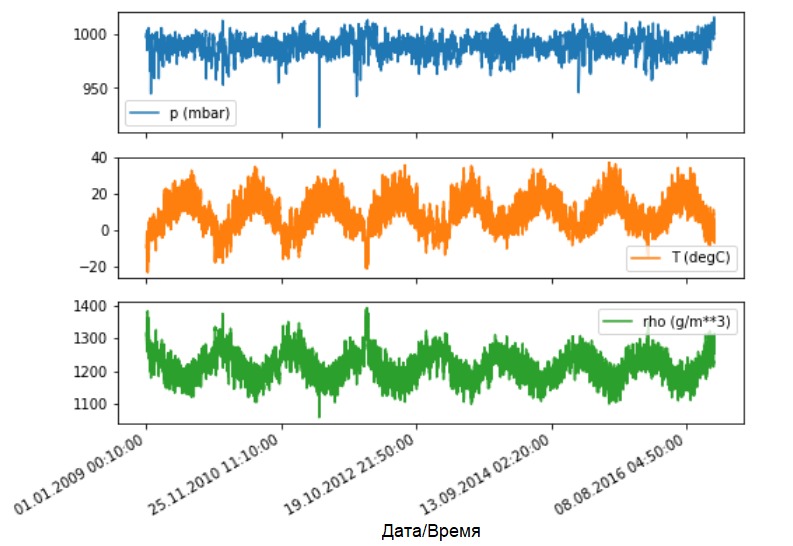
 Veamos cómo cambian estos indicadores con el tiempo.
Veamos cómo cambian estos indicadores con el tiempo.features.plot(subplots=True)
 Como antes, el primer paso será estandarizar el conjunto de datos con el cálculo del valor promedio y la desviación estándar de los datos de entrenamiento.
Como antes, el primer paso será estandarizar el conjunto de datos con el cálculo del valor promedio y la desviación estándar de los datos de entrenamiento.dataset = features.values
data_mean = dataset[:TRAIN_SPLIT].mean(axis=0)
data_std = dataset[:TRAIN_SPLIT].std(axis=0)
dataset = (dataset-data_mean)/data_std
Adición:
más adelante en el manual hablaremos sobre el pronóstico de punto e intervalo.
La conclusión es la siguiente. Si necesita que el modelo prediga un valor en el futuro (por ejemplo, el valor de la temperatura después de 12 horas) (modelo de un paso / paso único), entonces debe entrenar el modelo para que prediga solo un valor en el futuro. Si la tarea es predecir el rango de valores en el futuro (por ejemplo, temperaturas por hora durante las próximas 12 horas) (modelo de varios pasos), entonces el modelo también debe estar capacitado para predecir el rango de valores en el futuro. Predicción de puntosEn este caso, el modelo está entrenado para predecir un valor en el futuro basado en un historial disponible.La siguiente función realiza la misma tarea de organizar intervalos de tiempo solo con la diferencia de que aquí selecciona las últimas observaciones en función de un tamaño de paso dado.
Predicción de puntosEn este caso, el modelo está entrenado para predecir un valor en el futuro basado en un historial disponible.La siguiente función realiza la misma tarea de organizar intervalos de tiempo solo con la diferencia de que aquí selecciona las últimas observaciones en función de un tamaño de paso dado.def multivariate_data(dataset, target, start_index, end_index, history_size,
target_size, step, single_step=False):
data = []
labels = []
start_index = start_index + history_size
if end_index is None:
end_index = len(dataset) - target_size
for i in range(start_index, end_index):
indices = range(i-history_size, i, step)
data.append(dataset[indices])
if single_step:
labels.append(target[i+target_size])
else:
labels.append(target[i:i+target_size])
return np.array(data), np.array(labels)
En esta guía, el ANN opera con datos de los últimos cinco (5) días, es decir, 720 observaciones (6x24x5). Suponga que la selección de datos se lleva a cabo no cada 10 minutos, sino cada hora: dentro de los 60 minutos, no se esperan cambios bruscos. Por lo tanto, la historia de los últimos cinco días consta de 120 observaciones (720/6). Para un modelo que realiza predicciones puntuales, el objetivo es leer la temperatura después de 12 horas en el futuro. En este caso, el vector objetivo será la temperatura después de 72 observaciones (12x6) ( ver la siguiente adición. - Traductor aprox. ).past_history = 720
future_target = 72
STEP = 6
x_train_single, y_train_single = multivariate_data(dataset, dataset[:, 1], 0,
TRAIN_SPLIT, past_history,
future_target, STEP,
single_step=True)
x_val_single, y_val_single = multivariate_data(dataset, dataset[:, 1],
TRAIN_SPLIT, None, past_history,
future_target, STEP,
single_step=True)
Verifique el intervalo de tiempo.print ('Single window of past history : {}'.format(x_train_single[0].shape))
Single window of past history : (120, 3)
train_data_single = tf.data.Dataset.from_tensor_slices((x_train_single, y_train_single))
train_data_single = train_data_single.cache().shuffle(BUFFER_SIZE).batch(BATCH_SIZE).repeat()
val_data_single = tf.data.Dataset.from_tensor_slices((x_val_single, y_val_single))
val_data_single = val_data_single.batch(BATCH_SIZE).repeat()
single_step_model = tf.keras.models.Sequential()
single_step_model.add(tf.keras.layers.LSTM(32,
input_shape=x_train_single.shape[-2:]))
single_step_model.add(tf.keras.layers.Dense(1))
single_step_model.compile(optimizer=tf.keras.optimizers.RMSprop(), loss='mae')
Verificaremos nuestra muestra y derivaremos las curvas de pérdida en las etapas de capacitación y verificación.for x, y in val_data_single.take(1):
print(single_step_model.predict(x).shape)
(256, 1)
single_step_history = single_step_model.fit(train_data_single, epochs=EPOCHS,
steps_per_epoch=EVALUATION_INTERVAL,
validation_data=val_data_single,
validation_steps=50)
Train for 200 steps, validate for 50 steps
Epoch 1/10
200/200 [==============================] - 4s 18ms/step - loss: 0.3090 - val_loss: 0.2646
Epoch 2/10
200/200 [==============================] - 2s 9ms/step - loss: 0.2624 - val_loss: 0.2435
Epoch 3/10
200/200 [==============================] - 2s 9ms/step - loss: 0.2616 - val_loss: 0.2472
Epoch 4/10
200/200 [==============================] - 2s 9ms/step - loss: 0.2567 - val_loss: 0.2442
Epoch 5/10
200/200 [==============================] - 2s 9ms/step - loss: 0.2263 - val_loss: 0.2346
Epoch 6/10
200/200 [==============================] - 2s 9ms/step - loss: 0.2416 - val_loss: 0.2643
Epoch 7/10
200/200 [==============================] - 2s 9ms/step - loss: 0.2411 - val_loss: 0.2577
Epoch 8/10
200/200 [==============================] - 2s 9ms/step - loss: 0.2410 - val_loss: 0.2388
Epoch 9/10
200/200 [==============================] - 2s 9ms/step - loss: 0.2447 - val_loss: 0.2485
Epoch 10/10
200/200 [==============================] - 2s 9ms/step - loss: 0.2388 - val_loss: 0.2422
def plot_train_history(history, title):
loss = history.history['loss']
val_loss = history.history['val_loss']
epochs = range(len(loss))
plt.figure()
plt.plot(epochs, loss, 'b', label='Training loss')
plt.plot(epochs, val_loss, 'r', label='Validation loss')
plt.title(title)
plt.legend()
plt.show()
plot_train_history(single_step_history,
'Single Step Training and validation loss')
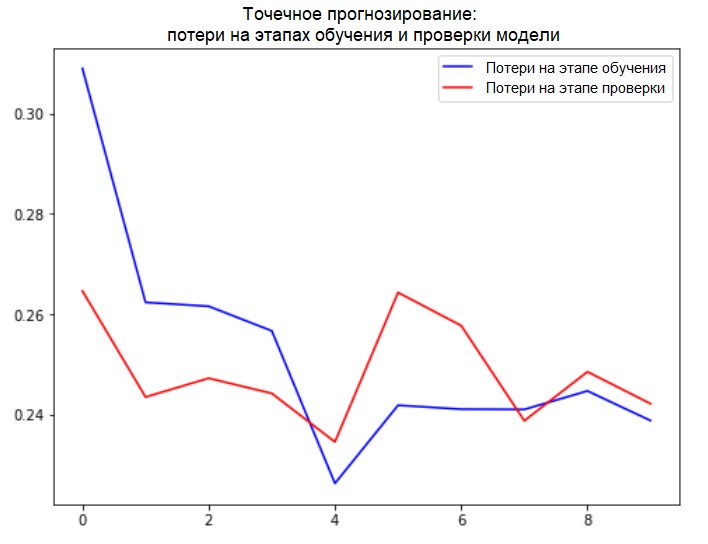 Adición:
Adición:
La preparación de datos para un modelo con una entrada multidimensional que realiza predicción de puntos se muestra esquemáticamente en la siguiente figura. Por conveniencia y para una representación más visual de la preparación de datos, el argumento STEPes 1. Tenga en cuenta que en las funciones de generador dadas, el argumento está STEP destinado solo a la formación del historial , y no al vector objetivo.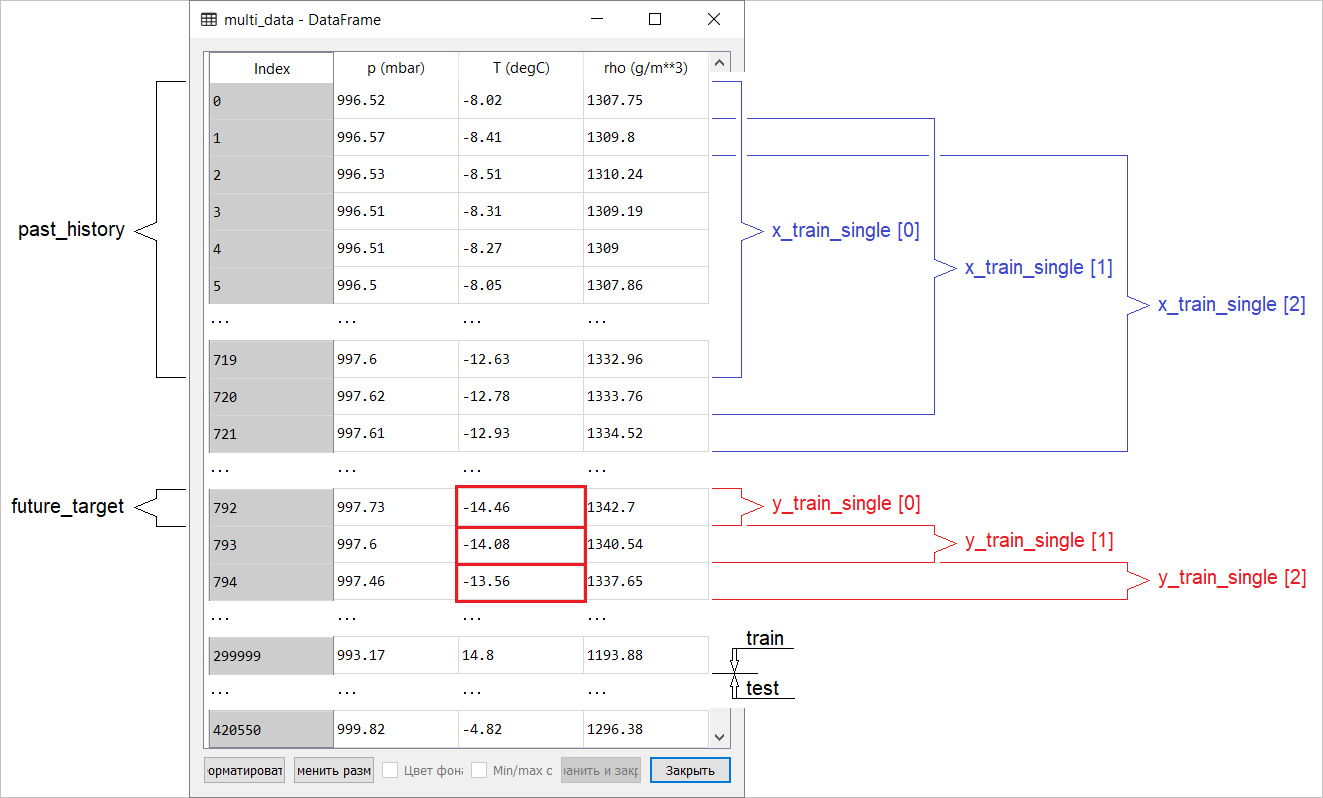 En este caso,
En este caso, x_train_singletiene la forma (299280, 720, 3).
Cuándo STEP=6, la forma tomará la siguiente forma: (299280, 120, 3)y la velocidad de la función aumentará significativamente. En general, debe dar crédito al programador: los generadores presentados en el manual son muy voraces en términos de consumo de memoria.Realizar una predicción puntualAhora que el modelo está entrenado, realizaremos varias predicciones de prueba. El historial de observaciones de 3 signos para los últimos cinco días, seleccionados cada hora (intervalo de tiempo = 120), se alimenta a la entrada del modelo. Dado que nuestro objetivo es pronosticar solo la temperatura, los valores de temperatura pasados ( historial ) se muestran en azul en el gráfico . El pronóstico se realizó medio día en el futuro (de ahí la brecha entre la historia y el valor predicho).for x, y in val_data_single.take(3):
plot = show_plot([x[0][:, 1].numpy(), y[0].numpy(),
single_step_model.predict(x)[0]], 12,
'Single Step Prediction')
plot.show()
 Predicción de intervalosEn este caso, sobre la base de algunos antecedentes disponibles, el modelo está entrenado para predecir el intervalo de valores futuros. Por lo tanto, en contraste con un modelo que predice un solo valor en el futuro, este modelo predice una secuencia de valores en el futuro.Supongamos, como en el caso del modelo que realiza la predicción de puntos, para el modelo que realiza la predicción de intervalo, los datos de entrenamiento son las mediciones por hora de los últimos cinco días (720/6). Sin embargo, en este caso, el modelo debe estar entrenado para predecir la temperatura durante las próximas 12 horas. Dado que las observaciones se registran cada 10 minutos, la salida del modelo debe consistir en 72 predicciones. Para completar esta tarea, es necesario preparar nuevamente el conjunto de datos, pero con un intervalo objetivo diferente.
Predicción de intervalosEn este caso, sobre la base de algunos antecedentes disponibles, el modelo está entrenado para predecir el intervalo de valores futuros. Por lo tanto, en contraste con un modelo que predice un solo valor en el futuro, este modelo predice una secuencia de valores en el futuro.Supongamos, como en el caso del modelo que realiza la predicción de puntos, para el modelo que realiza la predicción de intervalo, los datos de entrenamiento son las mediciones por hora de los últimos cinco días (720/6). Sin embargo, en este caso, el modelo debe estar entrenado para predecir la temperatura durante las próximas 12 horas. Dado que las observaciones se registran cada 10 minutos, la salida del modelo debe consistir en 72 predicciones. Para completar esta tarea, es necesario preparar nuevamente el conjunto de datos, pero con un intervalo objetivo diferente.future_target = 72
x_train_multi, y_train_multi = multivariate_data(dataset, dataset[:, 1], 0,
TRAIN_SPLIT, past_history,
future_target, STEP)
x_val_multi, y_val_multi = multivariate_data(dataset, dataset[:, 1],
TRAIN_SPLIT, None, past_history,
future_target, STEP)
Verifica la selección.print ('Single window of past history : {}'.format(x_train_multi[0].shape))
print ('\n Target temperature to predict : {}'.format(y_train_multi[0].shape))
Single window of past history : (120, 3)
Target temperature to predict : (72,)
train_data_multi = tf.data.Dataset.from_tensor_slices((x_train_multi, y_train_multi))
train_data_multi = train_data_multi.cache().shuffle(BUFFER_SIZE).batch(BATCH_SIZE).repeat()
val_data_multi = tf.data.Dataset.from_tensor_slices((x_val_multi, y_val_multi))
val_data_multi = val_data_multi.batch(BATCH_SIZE).repeat()
Además: la diferencia en la formación del vector objetivo para el "modelo de intervalo" del "modelo de puntos" se ve en la siguiente figura. Vamos a preparar la visualización.
Vamos a preparar la visualización.def multi_step_plot(history, true_future, prediction):
plt.figure(figsize=(12, 6))
num_in = create_time_steps(len(history))
num_out = len(true_future)
plt.plot(num_in, np.array(history[:, 1]), label='History')
plt.plot(np.arange(num_out)/STEP, np.array(true_future), 'bo',
label='True Future')
if prediction.any():
plt.plot(np.arange(num_out)/STEP, np.array(prediction), 'ro',
label='Predicted Future')
plt.legend(loc='upper left')
plt.show()
En este y en cuadros similares posteriores, el historial y los datos futuros son por hora.for x, y in train_data_multi.take(1):
multi_step_plot(x[0], y[0], np.array([0]))
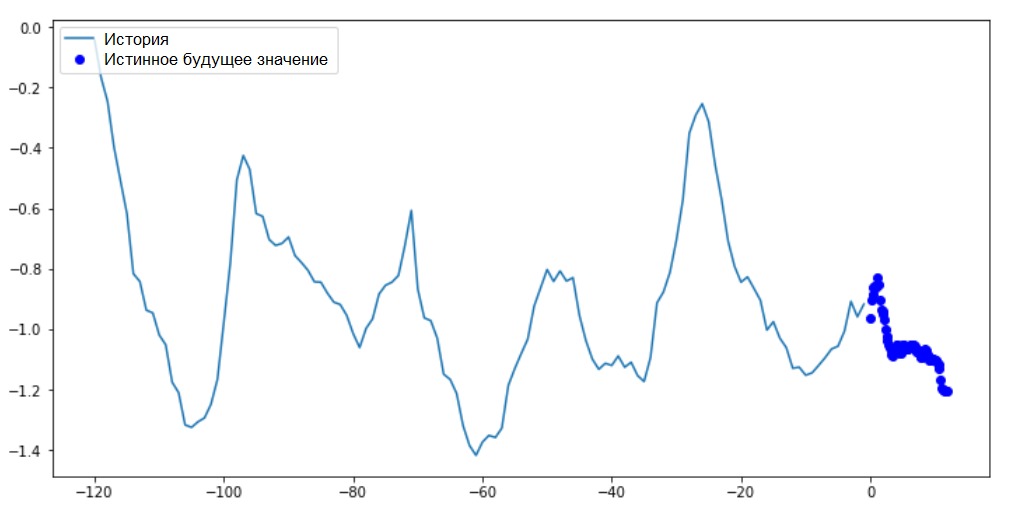 Dado que esta tarea es un poco más complicada que la anterior, el modelo constará de dos capas LSTM. Finalmente, dado que se realizan 72 predicciones, la capa de salida tiene 72 neuronas.
Dado que esta tarea es un poco más complicada que la anterior, el modelo constará de dos capas LSTM. Finalmente, dado que se realizan 72 predicciones, la capa de salida tiene 72 neuronas.multi_step_model = tf.keras.models.Sequential()
multi_step_model.add(tf.keras.layers.LSTM(32,
return_sequences=True,
input_shape=x_train_multi.shape[-2:]))
multi_step_model.add(tf.keras.layers.LSTM(16, activation='relu'))
multi_step_model.add(tf.keras.layers.Dense(72))
multi_step_model.compile(optimizer=tf.keras.optimizers.RMSprop(clipvalue=1.0), loss='mae')
Verificaremos nuestra muestra y derivaremos las curvas de pérdida en las etapas de capacitación y verificación.for x, y in val_data_multi.take(1):
print (multi_step_model.predict(x).shape)
(256, 72)
multi_step_history = multi_step_model.fit(train_data_multi, epochs=EPOCHS,
steps_per_epoch=EVALUATION_INTERVAL,
validation_data=val_data_multi,
validation_steps=50)
Train for 200 steps, validate for 50 steps
Epoch 1/10
200/200 [==============================] - 21s 103ms/step - loss: 0.4952 - val_loss: 0.3008
Epoch 2/10
200/200 [==============================] - 18s 89ms/step - loss: 0.3474 - val_loss: 0.2898
Epoch 3/10
200/200 [==============================] - 18s 89ms/step - loss: 0.3325 - val_loss: 0.2541
Epoch 4/10
200/200 [==============================] - 18s 89ms/step - loss: 0.2425 - val_loss: 0.2066
Epoch 5/10
200/200 [==============================] - 18s 89ms/step - loss: 0.1963 - val_loss: 0.1995
Epoch 6/10
200/200 [==============================] - 18s 90ms/step - loss: 0.2056 - val_loss: 0.2119
Epoch 7/10
200/200 [==============================] - 18s 91ms/step - loss: 0.1978 - val_loss: 0.2079
Epoch 8/10
200/200 [==============================] - 18s 89ms/step - loss: 0.1957 - val_loss: 0.2033
Epoch 9/10
200/200 [==============================] - 18s 90ms/step - loss: 0.1977 - val_loss: 0.1860
Epoch 10/10
200/200 [==============================] - 18s 88ms/step - loss: 0.1904 - val_loss: 0.1863
plot_train_history(multi_step_history, 'Multi-Step Training and validation loss')
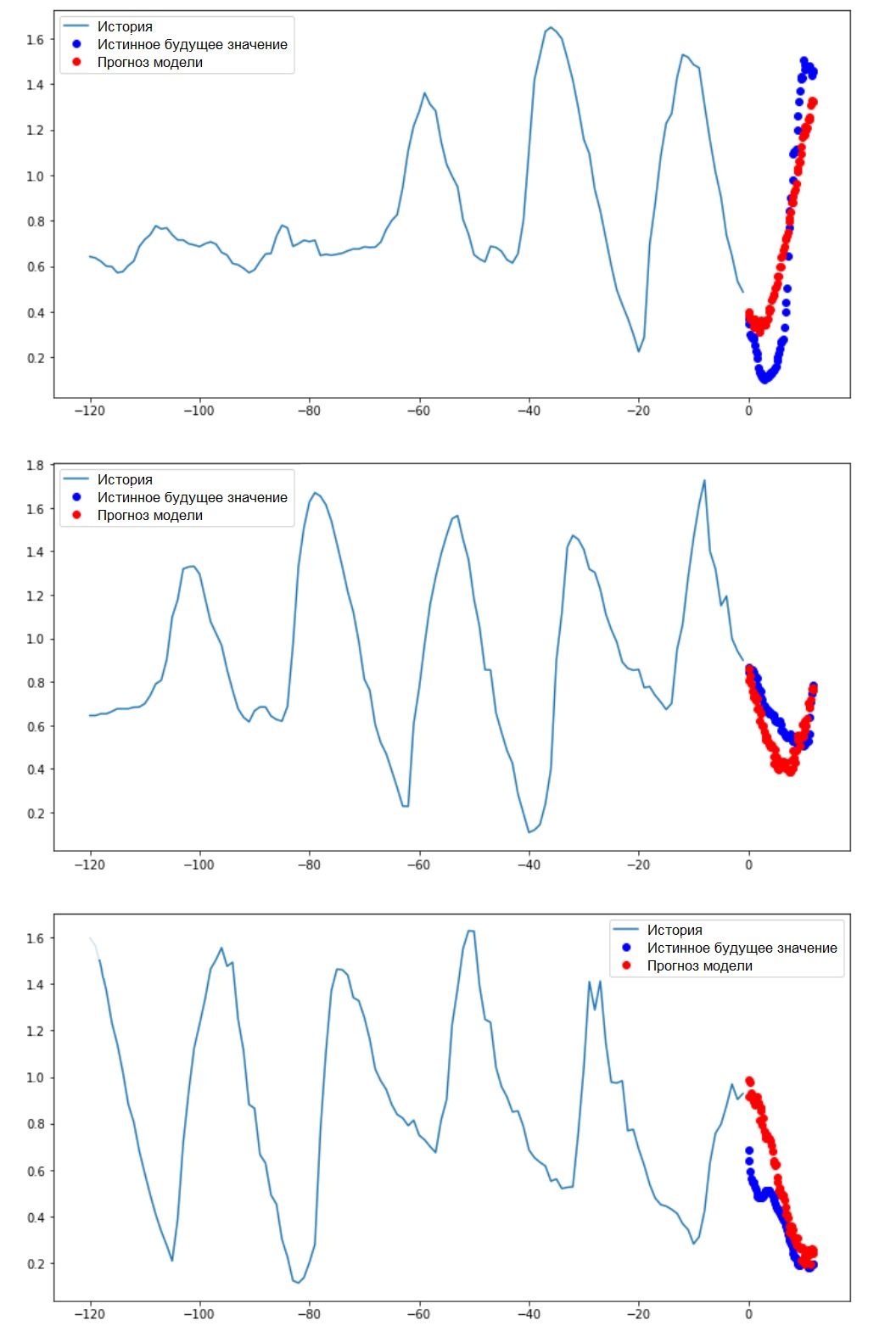
 Realización de una predicción de intervaloEntonces, descubramos cuán exitosamente un ANN capacitado hace frente a los pronósticos de valores de temperatura futuros.
Realización de una predicción de intervaloEntonces, descubramos cuán exitosamente un ANN capacitado hace frente a los pronósticos de valores de temperatura futuros.for x, y in val_data_multi.take(3):
multi_step_plot(x[0], y[0], multi_step_model.predict(x)[0])
Próximos pasos
Esta guía es una breve introducción al pronóstico de series de tiempo usando RNS. Ahora puede intentar predecir el mercado de valores y convertirse en multimillonario (en el original, así como así :). - Nota traductor) .Además, puede escribir su propio generador para preparar datos en lugar de la función uni / multivariate_data para hacer un uso más eficiente de la memoria. También puede familiarizarse con el trabajo de " ventanas de series temporales " y aportar sus ideas a esta guía.Para una mayor comprensión, se recomienda que lea el Capítulo 15 del libro "Aprendizaje automático aplicado con Scikit-Learn, Keras y TensorFlow" (Aurelien Geron, 2ª edición) y el Capítulo 6 del libro"Aprendizaje profundo en Python" (Francois Scholl).Adición final
Mientras esté en casa, cuide no solo su salud, sino que también se compadezca de la computadora ejecutando ejemplos del manual en un conjunto de datos truncado. Por ejemplo, teniendo en cuenta la proporción de 70x30 (entrenamiento / prueba), puede limitarlo de la siguiente manera:dataset = features[300000:].values
TRAIN_SPLIT = 85000