Una vez que se volvió interesante, qué temas destacaría la LDA (colocación latente de Dirichlet) en los materiales de LiveJournal. Como dicen, hay interés, no hay problema.Para empezar, un poco sobre LDA en los dedos, no entraremos en detalles matemáticos (cualquiera que esté interesado - lee). Entonces, LDA - es uno de los algoritmos más comunes para temas de modelado. Cada documento (ya sea un artículo, un libro o cualquier otra fuente de datos textuales) es una mezcla de temas, y cada tema es una mezcla de palabras.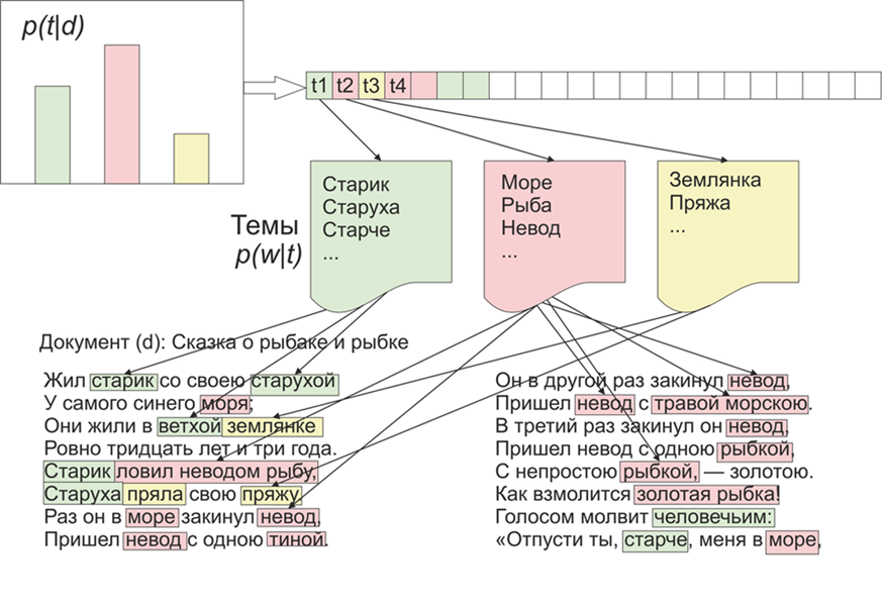 Imagen tomada de WikipediaPor lo tanto, la tarea de la LDA es encontrar grupos de palabras que formen temas a partir de una colección de documentos. Luego, según los temas, puede agrupar textos o simplemente resaltar palabras clave.Se recibieron alrededor de 1800 artículos del sitio web de LifeJournal, todos ellos se convirtieron al formato jsonl. Dejaré los artículos sucios en el disco Yandex . Haremos un poco de limpieza y normalización de los datos: deseche los comentarios, elimine las palabras de detención (la lista junto con el código fuente está disponible en github), llevaremos todas las palabras a la ortografía en minúsculas, eliminaremos la puntuación y las palabras que contengan 3 letras o menos. Pero una de las principales operaciones de preprocesamiento: eliminar palabras frecuentes, en principio, puede limitarse a eliminar solo palabras de detención, pero luego las palabras utilizadas con frecuencia se incluirán en casi todos los temas con una alta probabilidad. En este caso, será posible procesar y eliminar tales palabras. La decisión es tuya.
Imagen tomada de WikipediaPor lo tanto, la tarea de la LDA es encontrar grupos de palabras que formen temas a partir de una colección de documentos. Luego, según los temas, puede agrupar textos o simplemente resaltar palabras clave.Se recibieron alrededor de 1800 artículos del sitio web de LifeJournal, todos ellos se convirtieron al formato jsonl. Dejaré los artículos sucios en el disco Yandex . Haremos un poco de limpieza y normalización de los datos: deseche los comentarios, elimine las palabras de detención (la lista junto con el código fuente está disponible en github), llevaremos todas las palabras a la ortografía en minúsculas, eliminaremos la puntuación y las palabras que contengan 3 letras o menos. Pero una de las principales operaciones de preprocesamiento: eliminar palabras frecuentes, en principio, puede limitarse a eliminar solo palabras de detención, pero luego las palabras utilizadas con frecuencia se incluirán en casi todos los temas con una alta probabilidad. En este caso, será posible procesar y eliminar tales palabras. La decisión es tuya.stop=open('stop.txt')
stop_words=[]
for line in stop:
stop_words.append(line)
for i in range(0,len(stop_words)):
stop_words[i]=stop_words[i][:-1]
texts=[re.split( r' [\w\.\&\?!,_\-#)(:;*%$№"\@]* ' ,texts[i])[0].replace("\n","") for i in range(0,len(texts))]
texts=[test_re(line) for line in texts]
texts=[t.lower() for t in texts]
texts = [[word for word in document.split() if word not in stop_words] for document in texts]
texts=[[word for word in document if len(word)>=3]for document in texts]
A continuación, traemos todas las palabras a su forma normal: para esto usamos la biblioteca pymorphy2, que se puede instalar a través de pip.morph = pymorphy2.MorphAnalyzer()
for i in range(0,len(texts)):
for j in range(0,len(texts[i])):
texts[i][j] = morph.parse(texts[i][j])[0].normal_form
Sí, perderemos información sobre la forma de las palabras, pero en este contexto, estamos más interesados en la compatibilidad de las palabras entre sí. Aquí es donde termina nuestro preprocesamiento, no está completo, pero es suficiente para ver cómo funciona el algoritmo LDA.Además, el punto mencionado anteriormente, en principio, puede omitirse, pero en mi opinión, los resultados son más adecuados, nuevamente, qué umbral será, usted decide, por ejemplo, puede construir una función que dependa de la longitud promedio de los documentos y su número :counter = collections.Counter()
for t in texts:
for r in t:
counter[r]+=1
limit = len(texts)/5
too_common = [w for w in counter if counter[w] > limit]
too_common=set(too_common)
texts = [[word for word in document if word not in too_common] for document in texts]
Pasemos directamente a la capacitación del modelo, para esto necesitamos instalar la biblioteca gensim, que contiene un montón de bollos geniales. Primero debe codificar todas las palabras, la función Diccionario lo hará por nosotros, luego reemplazaremos las palabras con sus equivalentes numéricos. La versión comentada de la llamada LDA es más larga, ya que se actualiza después de cada documento, puede jugar con la configuración y seleccionar la opción adecuada.texts=preposition_text_for_lda(my_r)
dictionary = gensim.corpora.Dictionary(texts)
corpus = [dictionary.doc2bow(text) for text in texts]
lda = gensim.models.ldamodel.LdaModel(corpus=corpus, id2word=dictionary, num_topics=10)
Después del trabajo del programa, los temas se pueden ver con el comandolda.show_topic(i,topn=30)
, donde i es el número de tema y topn es el número de palabras en el tema que se mostrará.Ahora una pequeña ventaja para visualizar temas, para esto necesita instalar la biblioteca de wordcloud (como, utilidades similares también están en matplotlib). Este código visualiza temas y los guarda en la carpeta actual.from wordcloud import WordCloud, STOPWORDS
for i in range(0,10):
a=lda.show_topic(i,topn=30)
wordcloud = WordCloud(
relative_scaling = 1.0,
stopwords = too_common
).generate_from_frequencies(dict(a))
wordcloud.to_file('society'+str(i)+'.png')
Y finalmente, algunos ejemplos de los temas que obtuve:
 Experimente y podrá obtener resultados aún más significativos.
Experimente y podrá obtener resultados aún más significativos.