 ¡Buen dia amigos!Este artículo explica algunos conceptos de la teoría de la música en los que opera la API de audio web (WAA). Conociendo estos conceptos, puede tomar decisiones informadas al diseñar audio en una aplicación. Este artículo no lo convertirá en un ingeniero de sonido experimentado, pero le ayudará a comprender por qué WAA funciona de la manera en que funciona.
¡Buen dia amigos!Este artículo explica algunos conceptos de la teoría de la música en los que opera la API de audio web (WAA). Conociendo estos conceptos, puede tomar decisiones informadas al diseñar audio en una aplicación. Este artículo no lo convertirá en un ingeniero de sonido experimentado, pero le ayudará a comprender por qué WAA funciona de la manera en que funciona.Circuito de audio
La esencia de WAA es realizar algunas operaciones con sonido dentro de un contexto de audio. Esta API ha sido diseñada específicamente para enrutamiento modular. Las operaciones básicas con sonido son nodos de audio, interconectados y formando un diagrama de enrutamiento (gráfico de enrutamiento de audio). Varias fuentes, con diferentes tipos de canales, se procesan dentro de un solo contexto. Este diseño modular proporciona la flexibilidad necesaria para crear funciones complejas con efectos dinámicos.Los nodos de audio están interconectados a través de entradas y salidas, forman una cadena que comienza desde una o más fuentes, pasa a través de uno o más nodos y termina en el destino. En principio, puede prescindir de un destino, por ejemplo, si solo queremos visualizar algunos datos de audio. Un flujo de trabajo de audio web típico se parece a esto:- Crea un contexto de audio
- Dentro del contexto, cree fuentes, como <audio>, un oscilador (generador de sonido) o transmisión
- Cree nodos de efectos como reverb , filtro biquad, panner o compresor
- Seleccione un destino para el audio, como altavoces en la computadora de un usuario
- Establecer una conexión entre fuentes a través de efectos a un destino.

Designación de canal
El número de canales de audio disponibles a menudo se indica en formato numérico, por ejemplo, 2.0 o 5.1. Esto se llama la designación del canal. El primer dígito indica el rango completo de frecuencias que incluye la señal. El segundo dígito indica el número de canales reservados para las salidas de efectos de baja frecuencia: subwoofers .Cada entrada o salida consta de uno o más canales construidos de acuerdo con un determinado circuito de audio. Hay varias estructuras de canales discretos como mono, estéreo, cuádruple, 5.1, etc.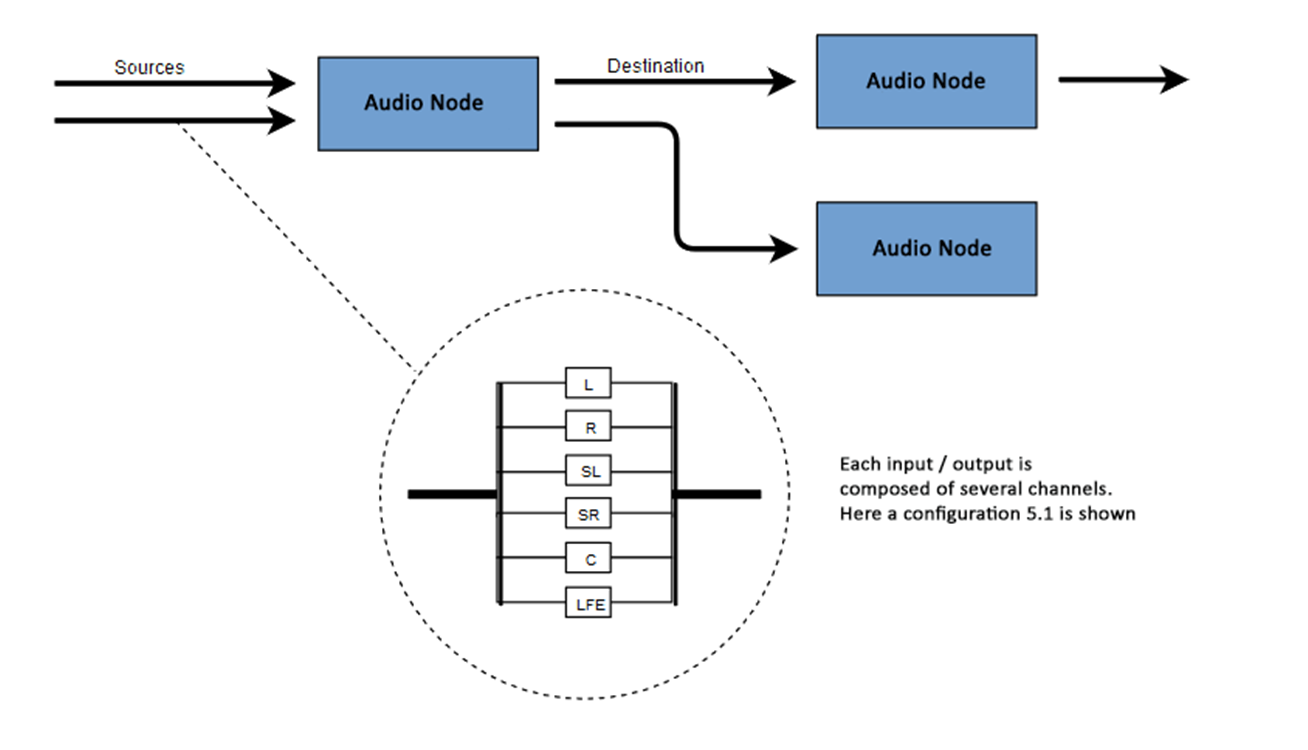 Las fuentes de audio se pueden obtener de muchas maneras. El sonido puede ser:
Las fuentes de audio se pueden obtener de muchas maneras. El sonido puede ser:- Generado por JavaScript a través de un nodo de audio (como un oscilador)
- Creado a partir de datos sin procesar utilizando PCM (modulación de código de pulso)
- Derivado de elementos multimedia HTML (como <video> o <audio>)
- Derivado de una transmisión de medios WebRTC (como una cámara web o un micrófono)
Datos de audio: qué hay en la muestra
El muestreo significa convertir una señal continua en una señal discreta (dividida) (analógica a digital). En otras palabras, una onda de sonido continua, como un concierto en vivo, se convierte en una secuencia de muestras, lo que permite que la computadora procese el audio en bloques separados.Memoria intermedia de audio: cuadros, muestras y canales
AudioBuffer acepta la cantidad de canales como parámetros (1 para mono, 2 para estéreo, etc.), longitud (la cantidad de cuadros de muestra dentro del búfer y frecuencia de muestreo), la cantidad de cuadros por segundo.Una muestra es un valor simple de punto flotante de 32 bits (float32), que es el valor de la transmisión de audio en un punto particular en el tiempo y en un canal particular (izquierdo o derecho, etc.). Un cuadro o cuadro de muestra es un conjunto de valores de todos los canales reproducidos en un determinado momento: todas las muestras de todos los canales se reproducen al mismo tiempo (dos para estéreo, seis para 5.1, etc.).La frecuencia de muestreo es el número de muestras (o cuadros, ya que todas las muestras en un cuadro se reproducen a la vez), reproducidas en un segundo, medidas en hercios (Hz). Cuanto mayor sea la frecuencia, mejor será la calidad del sonido.Veamos las memorias intermedias mono y estéreo, cada una de un segundo de duración, reproducidas a una frecuencia de 44100 Hz:- El búfer mono tendrá 44100 muestras y 44100 cuadros. El valor de la propiedad "length" es 44100
- El búfer estéreo tendrá 88.200 muestras, pero también 44.100 cuadros. El valor de la propiedad "length" será 44100: la longitud es igual al número de fotogramas
 Cuando comienza la reproducción del búfer, primero escuchamos el cuadro más a la izquierda de la muestra, luego el cuadro derecho más cercano, etc. En el caso de estéreo, escuchamos ambos canales simultáneamente. Los cuadros de muestra son independientes del número de canales y brindan la oportunidad de un procesamiento de audio muy preciso.Nota: para obtener el tiempo en segundos del número de cuadros, es necesario dividir el número de cuadros por la frecuencia de muestreo. Para obtener el número de cuadros del número de muestras, divida este último por el número de canales.Ejemplo:
Cuando comienza la reproducción del búfer, primero escuchamos el cuadro más a la izquierda de la muestra, luego el cuadro derecho más cercano, etc. En el caso de estéreo, escuchamos ambos canales simultáneamente. Los cuadros de muestra son independientes del número de canales y brindan la oportunidad de un procesamiento de audio muy preciso.Nota: para obtener el tiempo en segundos del número de cuadros, es necesario dividir el número de cuadros por la frecuencia de muestreo. Para obtener el número de cuadros del número de muestras, divida este último por el número de canales.Ejemplo:let context = new AudioContext()
let buffer = context.createBuffer(2, 22050, 44100)
Nota: en audio digital, 44100 Hz o 44,1 kHz es la frecuencia de muestreo estándar. ¿Pero por qué 44.1 kHz?En primer lugar, porque el rango de frecuencias audibles (frecuencias distinguibles por el oído humano) varía de 20 a 20,000 Hz. Según el teorema de Kotelnikov, la frecuencia de muestreo debería ser más del doble de la frecuencia más alta en el espectro de la señal. Por lo tanto, la frecuencia de muestreo debe ser superior a 40 kHz.En segundo lugar, las señales deben filtrarse con un filtro de paso bajo.antes del muestreo, de lo contrario habrá una superposición de "colas" espectrales (intercambio de frecuencia, enmascaramiento de frecuencia, alias) y la forma de la señal reconstruida se distorsionará. Idealmente, un filtro de paso bajo debería pasar frecuencias por debajo de 20 kHz (sin atenuación) y soltar frecuencias por encima de 20 kHz. En la práctica, se requiere alguna banda de transición (entre la banda de paso y la banda de supresión), donde las frecuencias están parcialmente atenuadas. Una manera más fácil y económica de hacer esto es usar un filtro anti-cambio. Para una frecuencia de muestreo de 44.1 kHz, la banda de transición es 2.05 kHz.En el ejemplo anterior, obtenemos un búfer estéreo con dos canales, reproducidos en un contexto de audio con una frecuencia de 44100 Hz (estándar), 0.5 segundos de largo (22050 cuadros / 44100 Hz = 0.5 s).let context = new AudioContext()
let buffer = context.createBuffer(1, 22050, 22050)
En este caso, obtenemos un búfer mono con un canal, reproducido en un contexto de audio con una frecuencia de 44100 Hz, sobremuestreando a 44100 Hz (y aumentando los cuadros a 44100), 1 segundo de largo (44100 cuadros / 44100 Hz = 1 s).Nota: El remuestreo de audio ("remuestreo") es muy similar al cambio de tamaño ("cambio de tamaño") de las imágenes. Supongamos que tenemos una imagen de 16x16, pero queremos llenar esta área con un tamaño de 32x32. Lo hacemos redimensionando. El resultado será menos calidad (puede ser borroso o desgarrado dependiendo del algoritmo de zoom), pero funciona. El audio muestreado es lo mismo: ahorramos espacio, pero en la práctica es poco probable que logre un sonido de alta calidad.Amortiguadores planos y rayados
WAA utiliza un formato de búfer plano. Los canales izquierdo y derecho interactúan de la siguiente manera:LLLLLLLLLLLLLLLLRRRRRRRRRRRRRRRR ( , 16 )
En este caso, cada canal funciona independientemente de los demás.Una alternativa es usar un formato alternativo:LRLRLRLRLRLRLRLRLRLRLRLRLRLRLRLR ( , 16 )
Este formato se usa a menudo para la decodificación de MP3.WAA usa solo el formato plano, ya que es más adecuado para el procesamiento de sonido. El formato plano se convierte en alternativo cuando los datos se envían a la tarjeta de sonido para su reproducción. Al decodificar MP3, se convierte el inverso.Canales de audio
Los diferentes buffers contienen un número diferente de canales: desde mono simple (un canal) y estéreo (canales izquierdo y derecho) hasta conjuntos más complejos, como quad y 5.1 con un número diferente de muestras en cada canal, lo que proporciona un sonido más rico (más rico). Los canales generalmente están representados por abreviaturas:Mezcla ascendente y descendente
Cuando el número de canales en la entrada y salida no coincide, aplique la mezcla hacia arriba o hacia abajo. La mezcla está controlada por la propiedad AudioNode.channelInterpretation:Visualización
La visualización se basa en la recepción de datos de audio de salida, como los datos sobre la amplitud o frecuencia, y su posterior procesamiento utilizando cualquier tecnología gráfica. WAA tiene un Nodo Analizador que no distorsiona la señal que lo atraviesa. Al mismo tiempo, puede extraer datos del audio y transferirlos aún más, por ejemplo, a & ltcanvas>.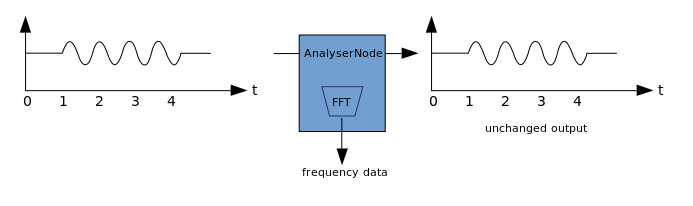 Los siguientes métodos se pueden utilizar para extraer datos:
Los siguientes métodos se pueden utilizar para extraer datos:- AnalyzerNode.getFloatByteFrequencyData () - copia los datos de frecuencia actuales a Float32Array
- AnalyzerNode.getByteFrequencyData (): copia los datos de frecuencia actuales en un Uint8Array (matriz de bytes sin signo)
- AnalyserNode.getFloatTimeDomainData() — Float32Array
- AnalyserNode.getByteTimeDomainData() — Uint8Array
La espacialización de audio (procesada por PannerNode y AudioListener) le permite modelar la posición y la dirección de la señal en un punto específico en el espacio, así como la posición del oyente.La posición del panorámico se describe utilizando coordenadas cartesianas diestras; para el movimiento, se usa el vector de velocidad necesario para crear el efecto Doppler ; para la dirección, se usa el cono de directividad. Este cono puede ser muy grande en el caso de fuentes de sonido multidireccionales. La posición del oyente se describe de la siguiente manera: movimiento - usando el vector de velocidad, la dirección donde está la cabeza del oyente - usando dos vectores direccionales, frontal y superior. El ajuste se realiza en la parte superior de la cabeza y la nariz del oyente en ángulo recto.
La posición del oyente se describe de la siguiente manera: movimiento - usando el vector de velocidad, la dirección donde está la cabeza del oyente - usando dos vectores direccionales, frontal y superior. El ajuste se realiza en la parte superior de la cabeza y la nariz del oyente en ángulo recto.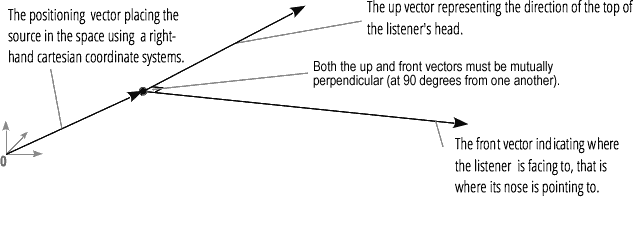
Unión y ramificación
Una conexión describe un proceso en el que un ChannelMergerNode recibe varias fuentes mono de entrada y las combina en una sola señal de salida multicanal.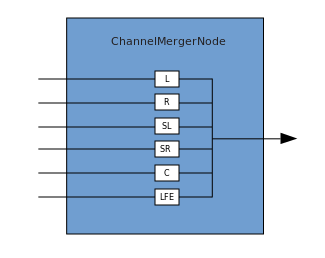 La ramificación es el proceso inverso (implementado a través de ChannelSplitterNode).
La ramificación es el proceso inverso (implementado a través de ChannelSplitterNode).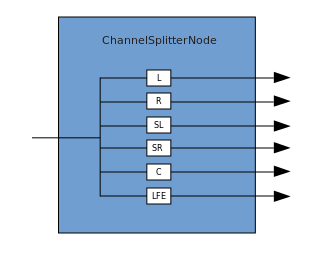 Un ejemplo de trabajo con WAA se puede encontrar aquí . El código fuente para el ejemplo está aquí . Aquí hay un artículo sobre cómo funciona todo.Gracias por su atención.
Un ejemplo de trabajo con WAA se puede encontrar aquí . El código fuente para el ejemplo está aquí . Aquí hay un artículo sobre cómo funciona todo.Gracias por su atención.