 La imagen que ve está tomada del sitio DeepMind y muestra 57 juegos en los que su último desarrollo Agent57 ( revisión del artículo sobre Habré ) ha tenido éxito. El número 57 en sí no fue tomado del techo: exactamente tantos juegos fueron elegidos en 2012 para convertirse en una especie de punto de referencia entre los desarrolladores de IA para juegos de Atari, después de lo cual varios investigadores miden sus logros en este conjunto de datos en particular.En esta publicación, trataré de ver estos logros desde diferentes ángulos para evaluar su valor para las tareas aplicadas y justificar por qué no creo que este sea el futuro. Bueno y sí, habrá muchas fotos debajo del corte, advertí.En el enlace de arriba, los desarrolladores escriben las cosas correctas, diciendo que
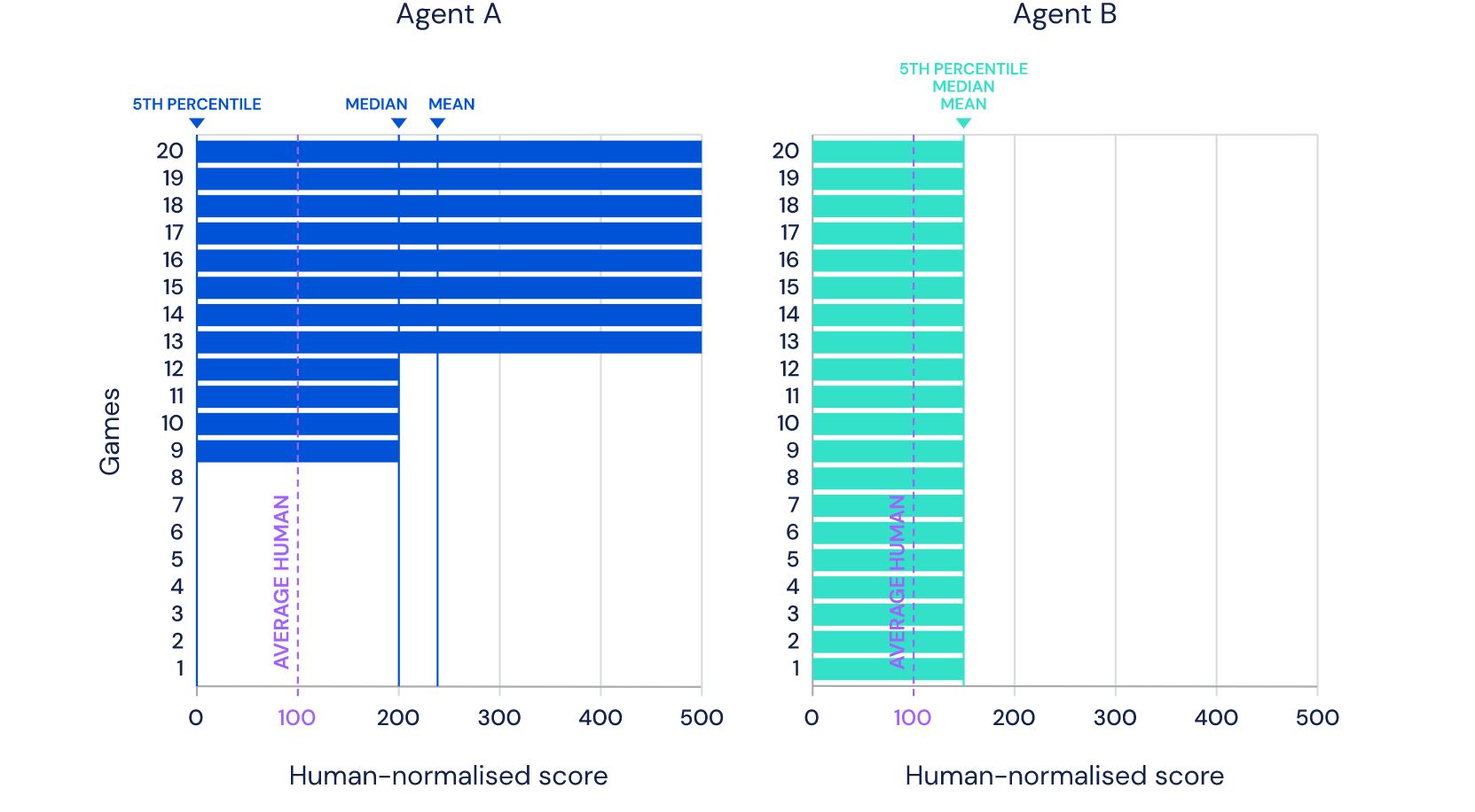
La imagen que ve está tomada del sitio DeepMind y muestra 57 juegos en los que su último desarrollo Agent57 ( revisión del artículo sobre Habré ) ha tenido éxito. El número 57 en sí no fue tomado del techo: exactamente tantos juegos fueron elegidos en 2012 para convertirse en una especie de punto de referencia entre los desarrolladores de IA para juegos de Atari, después de lo cual varios investigadores miden sus logros en este conjunto de datos en particular.En esta publicación, trataré de ver estos logros desde diferentes ángulos para evaluar su valor para las tareas aplicadas y justificar por qué no creo que este sea el futuro. Bueno y sí, habrá muchas fotos debajo del corte, advertí.En el enlace de arriba, los desarrolladores escriben las cosas correctas, diciendo queSo although average scores have increased, until now, the number of above human games has not. As an illustrative example, consider a benchmark consisting of twenty tasks. Suppose agent A obtains a score of 500% on eight tasks, 200% on four tasks, and 0% on eight tasks (mean = 240%, median = 200%), while agent B obtains a score of 150% on all tasks (mean = median = 150%). On average, agent A performs better than agent B. However, agent B possesses a more general ability: it obtains human-level performance on more tasks than agent A.
 Lo que en los dedos significa que antes se midió a todos en la clasificación "promedio", descartando los casos que son difíciles para una computadora, pero ahora solo se han ocupado de ellos. Y así, lograron una superioridad real sobre el hombre, y no super resultados en casos amigables con la computadora.Pero veamos el problema de manera más global para entender si esto es así. ¿Cuál es la interacción de DeepMind AI con un videojuego?Un asterisco en lo sucesivo denotará entidades obtenidas por un algoritmo creado no con la ayuda de AI, sino con la ayuda de la opinión de expertos.Antes de desmontar el circuito, veamos un enfoque alternativo:
Lo que en los dedos significa que antes se midió a todos en la clasificación "promedio", descartando los casos que son difíciles para una computadora, pero ahora solo se han ocupado de ellos. Y así, lograron una superioridad real sobre el hombre, y no super resultados en casos amigables con la computadora.Pero veamos el problema de manera más global para entender si esto es así. ¿Cuál es la interacción de DeepMind AI con un videojuego?Un asterisco en lo sucesivo denotará entidades obtenidas por un algoritmo creado no con la ayuda de AI, sino con la ayuda de la opinión de expertos.Antes de desmontar el circuito, veamos un enfoque alternativo:Resumen de video- + ,

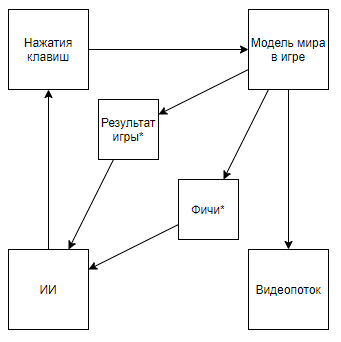 El esquema se vuelve así. Y si subes al canal del autor, puedes encontrar su aplicación para los juegos retro. Cambiando el esquema a este, llegamos a la conclusión de que la velocidad y la efectividad del entrenamiento están creciendo en órdenes de magnitud, pero el valor científico y de ingeniería de los logros de tal viaje se acerca a 0 (y sí, no tengo en cuenta el valor de popularización).Podemos suponer que el punto es que el video se lanza desde la tubería, pero considere el siguiente esquema (estoy seguro de que alguien implementó algo similar, pero no hay un enlace disponible):El cual se implementa cuando un experto que conoce las características necesarias escribe un analizador de flujo de video que calcula las características usando píxeles clave.O incluso tal esquema:Donde primero, AI1 está entrenado para extraer características seleccionadas por un experto del video.Y luego se enseña a AI2 a jugar mediante características extraídas de la transmisión de video usando AI1. Entonces tenemos un esquema que:
El esquema se vuelve así. Y si subes al canal del autor, puedes encontrar su aplicación para los juegos retro. Cambiando el esquema a este, llegamos a la conclusión de que la velocidad y la efectividad del entrenamiento están creciendo en órdenes de magnitud, pero el valor científico y de ingeniería de los logros de tal viaje se acerca a 0 (y sí, no tengo en cuenta el valor de popularización).Podemos suponer que el punto es que el video se lanza desde la tubería, pero considere el siguiente esquema (estoy seguro de que alguien implementó algo similar, pero no hay un enlace disponible):El cual se implementa cuando un experto que conoce las características necesarias escribe un analizador de flujo de video que calcula las características usando píxeles clave.O incluso tal esquema:Donde primero, AI1 está entrenado para extraer características seleccionadas por un experto del video.Y luego se enseña a AI2 a jugar mediante características extraídas de la transmisión de video usando AI1. Entonces tenemos un esquema que:- Utiliza una transmisión de video y no tiene acceso directo al modelo del mundo.
- No se basa en analizadores de flujo de video escritos por un experto
- Será entrenado a veces más fácil y más eficientemente que el desarrollo de DeepMind
Pero ... llegamos a lo mismo. Tal implementación, nuevamente, no tendrá valor científico ni de ingeniería en el contexto de la aplicación a juegos retro, ya que AI1 es una tarea muy primitiva y resuelta desde hace mucho tiempo para los algoritmos modernos de procesamiento de imágenes, y AI2 también se crea de manera muy rápida y simple, lo que confirma el autor del video anterior .Entonces, ¿cuál es el valor de los algoritmos DeepMind para los juegos de Atari? Trataré de resumir: el valor es queLos algoritmos de DeepMind pueden encontrar la estrategia de comportamiento óptima para juegos con un modelo primitivo del mundo MM en condiciones en las que el estado del modelo S mundial (MM, t) se representa con distorsiones significativas mediante una determinada función distorsionadora F (S (MM, t)), solo se puede evaluar la calidad de las decisiones tomadas una función que recibe una secuencia de valores F (S (MM, t)) y reacciones de algoritmos, y esta secuencia es de longitud desconocida (el juego puede terminar en un número diferente de pasos), pero puede repetir el experimento un número infinito de veces .Anticipando problemas, . S(MM, t) , , . F(S(MM, t)) , .
Ahora intentemos evaluar la aplicabilidad de tal valor para resolver problemas del mundo real que de alguna manera se correlacionan con las herramientas, es decir, representan un estado real con distorsiones significativas, implican que el entorno responde a las acciones del agente, da una evaluación solo después de una larga secuencia de decisiones, y sin embargo, permiten que el experimento se realice muchas veces.A primera vista, una aplicación interesante parece ser un juego en el intercambio. Incluso las sugerencias de Google, traicionándolo como la única pista con uso en el mundo real, insinúan que el tema es candente.Señalaré de inmediato un punto importante: casi todos los enfoques de análisis de mercado (sin contar los enfoques que analizan objetos del mundo real, como estacionamientos frente a supermercados, noticias, menciones de acciones en Twitter) se pueden dividir en dos tipos. El primer tipo son los enfoques que representan el mercado como una serie temporal. En segundo lugar, como un flujo de aplicaciones.De alguna manera, los defensores de los enfoques del primer tipo ven el mercado Pero la diferencia fundamental no está en los datos utilizados, sino en el hecho de que, por regla general, aquellos que analizan el mercado, como una serie de tiempo, descuidan su influencia en el mercado, creyendo que, condicionalmente, en el intervalo diario, sus transacciones no afectarán la dinámica del mercado. Si bien los partidarios del segundo enfoque pueden descuidar, creyendo que su volumen es insignificante en relación con la liquidez del mercado, y considerar el mercado como un sistema de retroalimentación, creyendo que sus acciones afectan el comportamiento de otros jugadores (por ejemplo, investigación y enfoques relacionados con la ejecución óptima de grandes pedidos, creación de mercado, comercio de alta frecuencia).Después de revisar los resultados de la búsqueda, está claro que todos los artículos y publicaciones dedicados al comercio mediante capacitación de refuerzo (el tema más cercano a los éxitos de DeepMind) se dedican al primer enfoque. Pero surge una pregunta razonable sobre la proporcionalidad del enfoque del problema.Primero, dibujemos un diagrama similar a los juegos de Atari.Realidad objetiva, . , , , , — . , , . , , , , , . , .
Parece que todo cae maravillosamente. Y sospecho que esta similitud también calienta el bombo publicitario. Pero, ¿qué pasa si aclaramos un poco el esquema?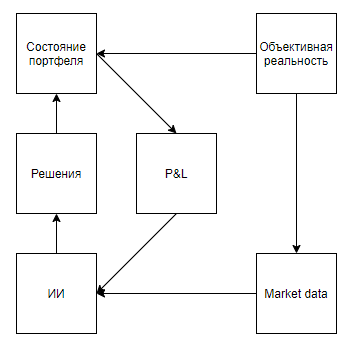
Anticipando la cuestión de las muestras autogeneradas, , , . , , . , , . , , , , , .
El segundo enfoque (con un flujo de aplicaciones) parece más prometedor. El llamado vasoA menudo está lleno de aplicaciones de robots que buscan fracciones de un porcentaje del precio, compiten en un lugar en la cola y, a menudo, crean aplicaciones solo para hacer aparecer la demanda o la oferta, y provocar que otros bots realicen acciones desventajosas. Parecería, si sueña, que si crea un emulador de intercambio y coloca bots HFT en él, que, tomando miles de millones de decisiones, aprenderá a sí mismo, jugará con los clones de sí mismos y, por lo tanto, desarrollará una estrategia ideal que tendrá en cuenta todas las contra-estrategias óptimas. ... Es una pena que si sucede algo como esto, entonces alrededor de 5 personas en todo el mundo lo descubran: los principios comerciales de los operadores de alta frecuencia implican un secreto absoluto, y se niegan a publicar resultados incluso infructuosos para que los enemigos tengan la oportunidad de pisar el mismo rastrillo.Creo que no vale la pena centrarse especialmente en la imposibilidad de aplicar dichos enfoques en marketing, recursos humanos, ventas, gestión y otras áreas donde el objeto es una persona, porque para la aplicación correcta es necesario permitir que AI haga millones, o incluso miles de millones de experimentos. E, incluso si muchas empresas tienen un millón de interacciones con un objeto en el que la IA puede tomar una decisión (elegir un banner para mostrar a un cliente potencial en función de su perfil, la decisión de despedir a un empleado), nadie obtendrá un millón de experimentos con el mismo objeto, que es exactamente lo que se requiere para una aplicación de alta calidad. Pero en lo que vale la pena centrarse es en el antifraude y la ciberseguridad.No lo sé, afortunada o desafortunadamente, pero en el mundo moderno muchas relaciones económicas se basan en proporcionar un pequeño valor sin obligaciones a cambio de esperar un gran valor en el futuro, lo que da lugar a numerosas fuentes gratuitas y potencial de fraude.Ejemplos:- El primer viaje gratis en agregadores de taxis
- Pagos de $ 70 por CPA en juegos de apuestas, para un jugador que aportó $ 5
- Pruebe $ 300 de proveedores en la nube y períodos de prueba
Además, el potencial de fraude del sistema económico moderno está respaldado por un bajo grado de protección para las transacciones con tarjeta de crédito, porque los comerciantes a menudo rechazan a propósito el mismo 3D seguro para simplificar la experiencia del usuario. Por lo tanto, para los compradores de tarjetas robadas por un pequeño porcentaje de su saldo, esta lista se puede complementar casi indefinidamente.El principal problema en la lucha contra tales casos radica en la incapacidad de recopilar un conjunto de datos de un volumen suficiente: el% de operaciones de fraude son 1-6 órdenes de magnitud más bajas que el porcentaje de buenas operaciones dependiendo del negocio. También hay un problema en la flexibilidad de los estafadores, que fácilmente pasan por alto los algoritmos estáticos, adaptándose a los sistemas antifraude que han sido entrenados en experiencias pasadas.Y, al parecer, aquí está. Algoritmos como Agent57 lanzado en el sandbox le permitirán crear el estafador ideal, actualizar constantemente sus habilidades y al mismo tiempo resolver el problema inverso: mantenga actualizado el algoritmo para identificarlo. Pero hay una advertencia. Ganar contra el modelo del mundo integrado en los juegos de Atari no es lo mismo que ganar con un sistema antifraude ya entrenado sobre la base del comportamiento de millones de jugadores, y muchas acciones con fraude son desproporcionadas con respecto a las muchas acciones de un jugador en un juego retro. Por ejemplo, incluso una acción tan simple como ingresar un inicio de sesión en el formulario de registro ya conlleva miles de millones de opciones para hacerlo. Comenzando desde qué agente de usuario transferir al servidor, y terminando con cuántos milisegundos esperar entre ingresar el segundo y tercer caracteres de inicio de sesión ...En general, lo veo todo de alguna manera. Bastante sombrío Y realmente espero estar equivocado, y en algún lugar no tomé algo en cuenta en el modelo. Estaría agradecido si veo contraejemplos en los comentarios.