Hola queridos Khabrovites, en este pequeño ejemplo quiero mostrar cómo se puede analizar una página, cuyos datos se cargan mediante widgets de JavaScript. Además, incluso si la página en este ejemplo es fácil de guardar, aún no puede analizar todas las fotos necesarias debido a estos widgets. En este caso, uso cian.ru como ejemplo , que tiene su propia API , que no usaré , sino que usaré Selenium. No trabajo en cian.ru, solo uso este sitio como ejemplo. El código en el analizador es simple y está diseñado para principiantes.
Una breve introducción: cuando estaba libre, miraba ejemplos de reparaciones en cian.ru, pensé que sería bueno guardar las fotos que me gustaban, pero guardarlas manualmente sería mucho tiempo, además este no es nuestro método, así que decidí escribir esto analizador
El analizador está escrito en python3 de la distribución de Anaconda , Selenium y chromedriver binary, lo instalé por separado de estos enlaces. (Y, por supuesto, el navegador Google Chrome debe estar instalado en el sistema )
A continuación se muestra el código del analizador completo, luego analizaré los puntos principales por separado.
from selenium import webdriver
from selenium.webdriver.chrome.options import Options
from selenium.common.exceptions import NoSuchElementException
import chromedriver_binary
import urllib
import time
print('start...')
site = "https://www.cian.ru/sale/flat/222059642/"
chrome_options = Options()
chrome_options.add_argument("--headless")
driver = webdriver.Chrome(options=chrome_options)
driver.get(site)
i = 0
while True:
try:
url = driver.find_element_by_xpath("//div[contains(@class, 'fotorama__active')]/img").get_attribute('src')
except NoSuchElementException:
break
i += 1
print(i, url)
driver.find_element_by_xpath("//div[@class='fotorama__arr fotorama__arr--next']").click()
name = url.split('/')[-1]
urllib.request.urlretrieve(url, name)
time.sleep(2)
print('done.')
https://www.cian.ru/sale/flat/222059642/ . driver get. , Headless Chrome, .. webdriver.Chrome() --headless, , , chrome_options , .
site = "https://www.cian.ru/sale/flat/222059642/"
chrome_options = Options()
chrome_options.add_argument("--headless")
driver = webdriver.Chrome(options=chrome_options)
driver.get(site)
, , , .. "next".
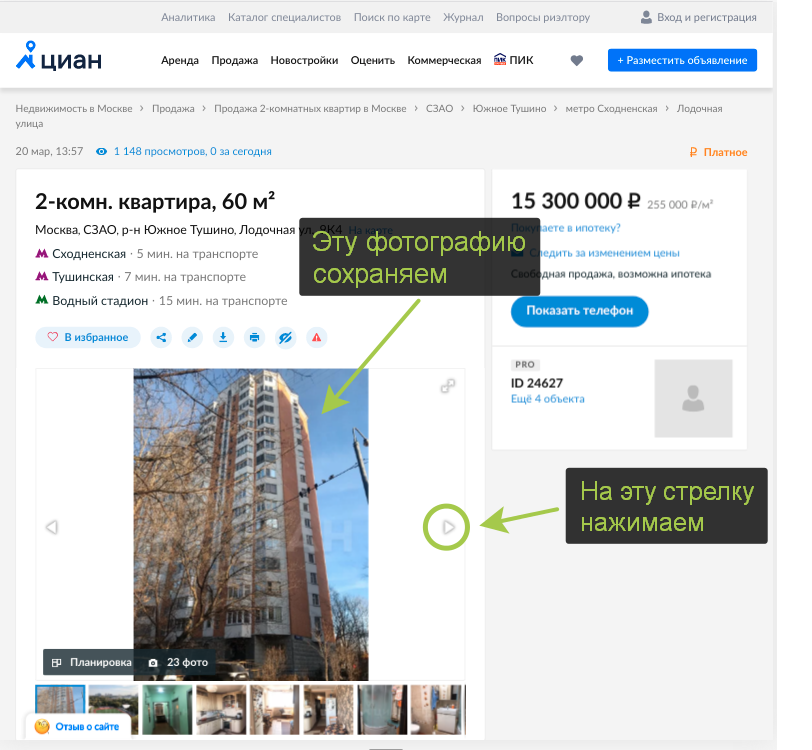
url , try/except NoSuchElementException, , Selenium .
try:
url = driver.find_element_by_xpath("//div[contains(@class, 'fotorama__active')]/img").get_attribute('src')
except NoSuchElementException:
break
.
driver.find_element_by_xpath("//div[@class='fotorama__arr fotorama__arr--next']").click()
urllib.
name = url.split('/')[-1]
urllib.request.urlretrieve(url, name)
, . ( Selenium)
time.sleep(2)
Selenium, , , - .
.