Hola habrozhiteli! Mientras nuestras noticias se imprimen en una imprenta y la oficina está en un lugar remoto, decidimos compartir un extracto del libro de Paul y Harvey Daytel "Python: Inteligencia Artificial, Big Data y Cloud Computing"Estudio de caso: Aprendizaje automático sin un maestro, Parte 2 - Agrupamiento promedio de K
En esta sección, tal vez se presentarán los algoritmos de aprendizaje automático más simples sin un maestro: agrupamiento utilizando el método k promedio. El algoritmo analiza muestras no etiquetadas e intenta combinarlas en grupos. Expliquemos que k en el "método k significa" representa el número de grupos en los que se supone que se dividen los datos.El algoritmo distribuye las muestras a un número predeterminado de grupos utilizando métricas de distancia similares a las del algoritmo de agrupamiento de k vecinos más cercanos. Cada grupo se agrupa alrededor de un centroide, el punto central del grupo. Inicialmente, el algoritmo selecciona k centroides aleatorios entre las muestras del conjunto de datos, después de lo cual las muestras restantes se distribuyen entre los grupos con el centroide más cercano. A continuación, se realiza un recálculo iterativo de los centroides, y las muestras se redistribuyen entre los grupos, hasta que para todos los grupos se minimiza la distancia desde el centroide dado a las muestras incluidas en su grupo. Como resultado del algoritmo, se crea una matriz unidimensional de etiquetas que designa el grupo al que pertenece cada muestra, así como una matriz bidimensional de centroides que representa el centro de cada grupo.Conjunto de datos de iris
Trabajaremos con el popular conjunto de datos Iris incluido con scikit-learn. Este conjunto a menudo se analiza durante la clasificación y la agrupación. Aunque el conjunto de datos está etiquetado, no utilizaremos estas etiquetas para demostrar la agrupación. Las etiquetas se utilizarán para determinar qué tan bien el algoritmo k-promedio agrupa las muestras.El conjunto de datos Iris es un conjunto de datos de juguete porque consta de solo 150 muestras y cuatro atributos. El conjunto de datos describe 50 muestras de tres tipos de flores de iris: Iris setosa, Iris versicolor e Iris virginica (ver fotos a continuación). Características de las muestras: longitud del lóbulo perianth externo (longitud del sépalo), ancho del lóbulo perianth externo (ancho del sépalo), longitud del lóbulo perianth interno (longitud del pétalo) y ancho del lóbulo perianth interno (ancho del pétalo), medido en centímetros.14.7.1. Descargar Iris Dataset
Inicie IPython con el comando ipython --matplotlib, luego use la función load_iris del módulo sklearn.datasets para obtener el objeto Bunch con el conjunto de datos:In [1]: from sklearn.datasets import load_iris
In [2]: iris = load_iris()
El atributo DESCR de un objeto Bunch indica que el conjunto de datos consta de 150 muestras de Número de instancias, cada una de las cuales tiene cuatro Número de atributos. No faltan valores en el conjunto de datos. Las muestras se clasifican con números enteros 0, 1 y 2, que representan Iris setosa, Iris versicolor e Iris virginica, respectivamente. Ignoramos las etiquetas y confiamos la definición de clases de muestra al algoritmo de agrupamiento utilizando el método k medias. Información clave de DESCR en negrita:In [3]: print(iris.DESCR)
.. _iris_dataset:
Iris plants dataset
--------------------
**Data Set Characteristics:**
:Number of Instances: 150 (50 in each of three classes)
:Number of Attributes: 4 numeric, predictive attributes and the class
:Attribute Information:
- sepal length in cm
- sepal width in cm
- petal length in cm
- petal width in cm
- class:
- Iris-Setosa
- Iris-Versicolour
- Iris-Virginica
:Summary Statistics:
============== ==== ==== ======= ===== ====================
Min Max Mean SD Class Correlation
============== ==== ==== ======= ===== ====================
sepal length: 4.3 7.9 5.84 0.83 0.7826
sepal width: 2.0 4.4 3.05 0.43 -0.4194
petal length: 1.0 6.9 3.76 1.76 0.9490 (high!)
petal width: 0.1 2.5 1.20 0.76 0.9565 (high!)
============== ==== ==== ======= ===== ====================
:Missing Attribute Values: None
:Class Distribution: 33.3% for each of 3 classes.
:Creator: R.A. Fisher
:Donor: Michael Marshall (MARSHALL%PLU@io.arc.nasa.gov)
:Date: July, 1988
...
Comprobación de la cantidad de muestras, características y valores objetivo
El número de patrones y atributos se puede encontrar en el atributo de forma de la matriz de datos, y el número de valores objetivo se puede encontrar en el atributo de forma de la matriz de destino:In [4]: iris.data.shape
Out[4]: (150, 4)
In [5]: iris.target.shape
Out[5]: (150,)
La matriz target_names contiene los nombres de las etiquetas numéricas de la matriz. La expresión target - dtype = '<U10' significa que sus elementos son cadenas con una longitud máxima de 10 caracteres:In [6]: iris.target_names
Out[6]: array(['setosa', 'versicolor', 'virginica'], dtype='<U10')
La matriz de feature_names contiene una lista de nombres de cadena para cada columna en la matriz de datos:In [7]: iris.feature_names
Out[7]:
['sepal length (cm)',
'sepal width (cm)',
'petal length (cm)',
'petal width (cm)']
14.7.2. Iris Dataset Research: Estadística descriptiva en pandas
Usamos la colección DataFrame para examinar el conjunto de datos de Iris. Al igual que con el conjunto de datos de Vivienda de California, establecemos los parámetros de pandas para formatear la salida de la columna:In [8]: import pandas as pd
In [9]: pd.set_option('max_columns', 5)
In [10]: pd.set_option('display.width', None)
Cree una colección de DataFrame con el contenido de la matriz de datos, utilizando los contenidos de la matriz de feature_names como nombres de columna:In [11]: iris_df = pd.DataFrame(iris.data, columns=iris.feature_names)
Luego agregue una columna con el nombre de la vista para cada una de las muestras. La transformación de la lista en el siguiente fragmento utiliza cada valor en la matriz de destino para buscar el nombre correspondiente en la matriz de nombres de destino:In [12]: iris_df['species'] = [iris.target_names[i] for i in iris.target]
Usaremos pandas para identificar varias muestras. Como antes, si pandas sale \ a la derecha del nombre de la columna, esto significa que las columnas que se mostrarán a continuación permanecen en la salida:In [13]: iris_df.head()
Out[13]:
sepal length (cm) sepal width (cm) petal length (cm) \
0 5.1 3.5 1.4
1 4.9 3.0 1.4
2 4.7 3.2 1.3
3 4.6 3.1 1.5
4 5.0 3.6 1.4
petal width (cm) species
0 0.2 setosa
1 0.2 setosa
2 0.2 setosa
3 0.2 setosa
4 0.2 setosa
Calculamos algunos indicadores de estadísticas descriptivas para columnas numéricas:In [14]: pd.set_option('precision', 2)
In [15]: iris_df.describe()
Out[15]:
sepal length (cm) sepal width (cm) petal length (cm) petal width (cm)
count 150.00 150.00 150.00 150.00
mean 5.84 3.06 3.76 1.20
std 0.83 0.44 1.77 0.76
min 4.30 2.00 1.00 0.10
25% 5.10 2.80 1.60 0.30
50% 5.80 3.00 4.35 1.30
75% 6.40 3.30 5.10 1.80
max 7.90 4.40 6.90 2.50
Llamar al método de descripción en la columna 'especie' confirma que contiene tres valores únicos. Sabemos de antemano que los datos consisten en tres clases, a las que pertenecen las muestras, aunque en el aprendizaje automático sin un maestro no siempre es así.In [16]: iris_df['species'].describe()
Out[16]:
count 150
unique 3
top setosa
freq 50
Name: species, dtype: object
14.7.3. Visualización del conjunto de datos de parcela
Visualizaremos las características en este conjunto de datos. Una forma de extraer información sobre sus datos es ver cómo se relacionan los atributos entre sí. Un conjunto de datos tiene cuatro atributos. No podremos construir un diagrama de correspondencia de un atributo con otros tres en un diagrama. Sin embargo, es posible construir un diagrama en el que se presentará la correspondencia entre las dos características. Fragment [20] usa la función de diagrama de pares de la biblioteca Seaborn para crear una tabla de diagramas en la que cada característica se asigna a una de las otras características:In [17]: import seaborn as sns
In [18]: sns.set(font_scale=1.1)
In [19]: sns.set_style('whitegrid')
In [20]: grid = sns.pairplot(data=iris_df, vars=iris_df.columns[0:4],
...: hue='species')
...:
Argumentos clave- una colección de DataFrame con un conjunto de datos trazado en un gráfico;
- vars: una secuencia con los nombres de las variables trazadas en el gráfico. Para una colección de DataFrame, contiene nombres de columna. En este caso, se usan las primeras cuatro columnas del DataFrame, que representan la longitud (ancho) del perianto externo y la longitud (ancho) del perianto interno, respectivamente;
- hue es una columna de la colección DataFrame utilizada para determinar los colores de los datos trazados en el gráfico. En este caso, los datos se colorean según el tipo de iris.
La llamada de diagrama de par anterior crea la siguiente tabla de diagramas 4 × 4: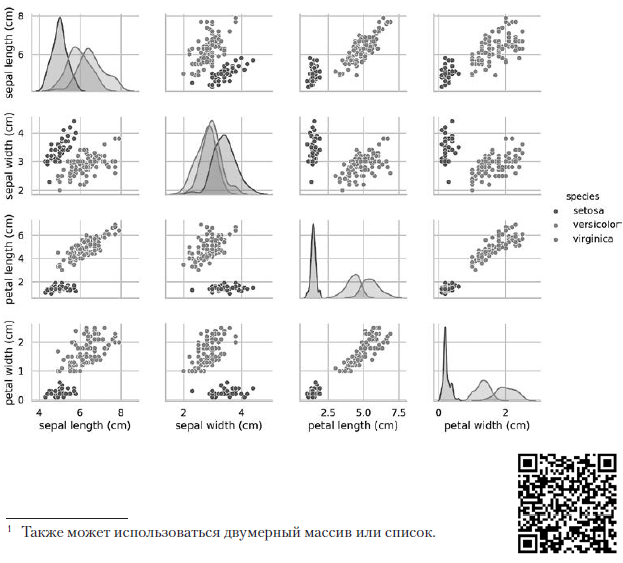 los diagramas en la diagonal que va desde la esquina superior izquierda a la esquina inferior derecha muestran la distribución del atributo que se muestra en esta columna con un rango de valores (de izquierda a derecha) y el número de muestras con estos valores (de arriba a abajo) . Tome la distribución de la longitud del perianto externo:
los diagramas en la diagonal que va desde la esquina superior izquierda a la esquina inferior derecha muestran la distribución del atributo que se muestra en esta columna con un rango de valores (de izquierda a derecha) y el número de muestras con estos valores (de arriba a abajo) . Tome la distribución de la longitud del perianto externo: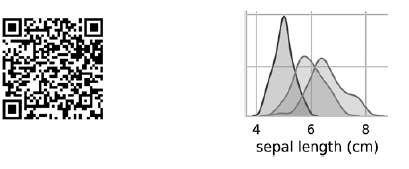 El área sombreada más alta indica que el rango de la longitud del lóbulo perianto externo (a lo largo del eje x) para la especie Iris setosa es de aproximadamente 4–6 cm, y para la mayoría de las muestras de Iris setosa, los valores se encuentran en el medio de este rango (aproximadamente 5 cm). El área sombreada extrema derecha indica que el rango de la longitud del lóbulo periantio externo (a lo largo del eje x) para la especie Iris virginica es de aproximadamente 4–8,5 cm, y para la mayoría de las muestras de Iris virginica, los valores están entre 6 y 7 cm.En otros diagramas, la columna presenta los diagramas de dispersión de datos de otras características relativas a la característica a lo largo del eje x. En la primera columna, en los primeros tres diagramas, el eje y muestra el ancho del perianto externo, la longitud del perianto interno y el ancho del perianto interno, respectivamente, y el eje x muestra la longitud del perianto externo.Cuando se ejecuta este código, aparece una imagen en color en la pantalla, que muestra la relación entre los diferentes tipos de iris a nivel de caracteres individuales. Curiosamente, en todos los diagramas, los puntos azules de Iris setosa están claramente separados de los puntos naranjas y verdes de otras especies; Esto sugiere que Iris setosa es de hecho una clase separada. También puede notar que las otras dos especies a veces pueden confundirse, como lo indican los puntos superpuestos de color naranja y verde. Por ejemplo, el diagrama del ancho y la longitud del lóbulo periantio externo muestra que los puntos de Iris versicolor e Iris virginica se mezclan. Esto sugiere que si solo están disponibles mediciones del lóbulo periantio externo, entonces será difícil distinguir entre estas dos especies.
El área sombreada más alta indica que el rango de la longitud del lóbulo perianto externo (a lo largo del eje x) para la especie Iris setosa es de aproximadamente 4–6 cm, y para la mayoría de las muestras de Iris setosa, los valores se encuentran en el medio de este rango (aproximadamente 5 cm). El área sombreada extrema derecha indica que el rango de la longitud del lóbulo periantio externo (a lo largo del eje x) para la especie Iris virginica es de aproximadamente 4–8,5 cm, y para la mayoría de las muestras de Iris virginica, los valores están entre 6 y 7 cm.En otros diagramas, la columna presenta los diagramas de dispersión de datos de otras características relativas a la característica a lo largo del eje x. En la primera columna, en los primeros tres diagramas, el eje y muestra el ancho del perianto externo, la longitud del perianto interno y el ancho del perianto interno, respectivamente, y el eje x muestra la longitud del perianto externo.Cuando se ejecuta este código, aparece una imagen en color en la pantalla, que muestra la relación entre los diferentes tipos de iris a nivel de caracteres individuales. Curiosamente, en todos los diagramas, los puntos azules de Iris setosa están claramente separados de los puntos naranjas y verdes de otras especies; Esto sugiere que Iris setosa es de hecho una clase separada. También puede notar que las otras dos especies a veces pueden confundirse, como lo indican los puntos superpuestos de color naranja y verde. Por ejemplo, el diagrama del ancho y la longitud del lóbulo periantio externo muestra que los puntos de Iris versicolor e Iris virginica se mezclan. Esto sugiere que si solo están disponibles mediciones del lóbulo periantio externo, entonces será difícil distinguir entre estas dos especies.La parcela de salida da como resultado un color
Si elimina el argumento de la clave de tono, la función de diagrama de pares usa solo un color para generar todos los datos, porque no sabe cómo distinguir entre las vistas en la salida:In [21]: grid = sns.pairplot(data=iris_df, vars=iris_df.columns[0:4])
Como se puede ver en el siguiente diagrama, en este caso, los diagramas en diagonal son histogramas con las distribuciones de todos los valores de este atributo, independientemente del tipo. Al estudiar diagramas, puede parecer que solo hay dos grupos, aunque sabemos que el conjunto de datos contiene tres tipos. Si no se conoce de antemano el número de grupos, puede ponerse en contacto con un experto en el área temática que conozca bien los datos. Un experto puede saber que hay tres tipos de datos en un conjunto de datos; Esta información puede ser útil cuando se realiza el aprendizaje automático con datos.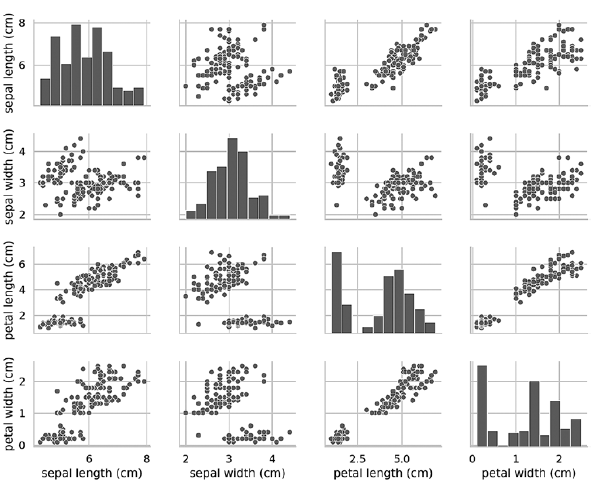 Los diagramas de diagrama de pares funcionan bien con una pequeña cantidad de entidades o un subconjunto de entidades, de modo que la cantidad de filas y columnas es limitada y con una cantidad relativamente pequeña de patrones para que los puntos de datos sean visibles. A medida que aumenta el número de características y patrones, los diagramas de dispersión de datos se vuelven demasiado pequeños para leer los datos. En grandes conjuntos de datos, puede trazar un subconjunto de características en el gráfico y, opcionalmente, un subconjunto de patrones seleccionados al azar para tener una idea de los datos.»Se puede encontrar y comprar más información sobre el libro en el sitio web del editor
Los diagramas de diagrama de pares funcionan bien con una pequeña cantidad de entidades o un subconjunto de entidades, de modo que la cantidad de filas y columnas es limitada y con una cantidad relativamente pequeña de patrones para que los puntos de datos sean visibles. A medida que aumenta el número de características y patrones, los diagramas de dispersión de datos se vuelven demasiado pequeños para leer los datos. En grandes conjuntos de datos, puede trazar un subconjunto de características en el gráfico y, opcionalmente, un subconjunto de patrones seleccionados al azar para tener una idea de los datos.»Se puede encontrar y comprar más información sobre el libro en el sitio web del editor