Ahora la programación penetra más y más en todas las áreas de la vida. Y tal vez se hizo gracias a la muy popular python ahora. Si hace 5 años, para analizar datos, tenía que usar un paquete completo de varias herramientas: C # para descargar (o bolígrafos), Excel, MatLab, SQL y constantemente "saltar" allí, borrando, verificando y verificando los datos. Ahora python, gracias a una gran cantidad de excelentes bibliotecas y módulos, en la primera aproximación reemplaza de forma segura todas estas herramientas y, junto con SQL, en general, "las montañas se pueden enrollar".Entonces que estoy haciendo. Me interesé en aprender una pitón tan popular. Y la mejor manera de aprender algo, como saben, es practicar. Y también estoy interesado en bienes raíces. Y me encontré con un problema interesante sobre los bienes raíces en Moscú: ¿clasificar los distritos de Moscú por el costo promedio de alquiler de un odnushka promedio? Padres, pensé, aquí tienen geolocalización, carga desde el sitio y análisis de datos, una gran tarea práctica.Inspirado por los maravillosos artículos aquí en Habré (al final del artículo agregaré enlaces), ¡comencemos!La tarea para nosotros es revisar las herramientas existentes dentro de Python, desarmar la técnica: cómo resolver estos problemas y pasar tiempo con placer, y no solo con beneficio.- Raspado cian
- Marco de datos único
- Procesamiento de marco de datos
- resultados
- Un poco sobre trabajar con geodatos
Raspado cian
A mediados de marzo de 2020, fue posible reunir casi 9 mil propuestas para alquilar un apartamento de 1 habitación en Moscú en cian, el sitio muestra 54 páginas. Trabajaremos con jupyter-notebook 6.0.1, python 3.7. Subimos datos del sitio y los guardamos en archivos usando la biblioteca de solicitudes .Para que el sitio no nos prohíba, nos disfrazaremos de persona agregando un retraso en las solicitudes y configurando un encabezado para que desde el lado del sitio parezcamos una persona muy inteligente que realiza solicitudes a través de un navegador. No olvide verificar la respuesta del sitio cada vez, de lo contrario, de repente se nos descubre y ya estamos prohibidos. Puede leer más y más detalladamente sobre el scraping de sitios web, por ejemplo, aquí: Web Scraping usando python .También es conveniente agregar decoradores para evaluar la velocidad de nuestras funciones y registros. El nivel de configuración = logging.INFO le permite especificar el tipo de mensajes que se muestran en el registro. También puede configurar el módulo para enviar el registro a un archivo de texto, para nosotros esto es innecesario.El códigodef timer(f):
def wrap_timer(*args, **kwargs):
start = time.time()
result = f(*args, **kwargs)
delta = time.time() - start
print (f' {f.__name__} {delta} ')
return result
return wrap_timer
def log(f):
def wrap_log(*args, **kwargs):
logging.info(f" {f.__doc__}")
result = f(*args, **kwargs)
logging.info(f": {result}")
return result
return wrap_log
logging.basicConfig(level=logging.INFO)
@timer
@log
def requests_site(N):
headers = ({'User-Agent':'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_13_6) AppleWebKit/605.1.15 (KHTML, like Gecko) Version/13.0.5 Safari/605.1.15'})
pages = [106 + i for i in range(N)]
n = 0
for i in pages:
s = f"https://www.cian.ru/cat.php?deal_type=rent&engine_version=2&page={i}&offer_type=flat®ion=1&room1=1&type=-2"
response = requests.get(s, headers = headers)
if response.status_code == 200:
name = f'sheets/sheet_{i}.txt'
with open(name, 'w') as f:
f.write(response.text)
n += 1
logging.info(f" {i}")
else:
print(f" {i} response.status_code = {response.status_code}")
time.sleep(np.random.randint(7,13))
return f" {n} "
requests_site(300)
Marco de datos único
Para raspar páginas, elija BeautifulSoup y lxml . Usamos "sopa hermosa" simplemente por su nombre genial, aunque dicen que lxml es más rápido.Puede hacerlo maravillosamente, tomar una lista de archivos de una carpeta usando la biblioteca os , filtrar las extensiones que necesitamos y revisarlas. Pero lo haremos más fácil, ya que sabemos la cantidad exacta de archivos y sus nombres exactos. A menos que agreguemos decoración en forma de barra de progreso, usando la biblioteca tqdmEl código
from bs4 import BeautifulSoup
import re
import pandas as pd
from dateutil.parser import parse
from datetime import datetime, date, time
def read_file(filename):
with open(filename) as input_file:
text = input_file.read()
return text
import tqdm
site_texts = []
pages = [1 + i for i in range(309)]
for i in tqdm.tqdm(pages):
name = f'sheets/sheet_{i}.txt'
site_texts.append(read_file(name))
print(f" {len(site_texts)} .")
def parse_tag(tag, tag_value, item):
key = tag
value = "None"
if item.find('div', {'class': tag_value}):
if key == 'link':
value = item.find('div', {'class': tag_value}).find('a').get('href')
elif (key == 'price' or key == 'price_meter'):
value = parse_digits(item.find('div', {'class': tag_value}).text, key)
elif key == 'pub_datetime':
value = parse_date(item.find('div', {'class': tag_value}).text)
else:
value = item.find('div', {'class': tag_value}).text
return key, value
def parse_digits(string, type_digit):
digit = 0
try:
if type_digit == 'flats_counts':
digit = int(re.sub(r" ", "", string[:string.find("")]))
elif type_digit == 'price':
digit = re.sub(r" ", "", re.sub(r"₽", "", string))
elif type_digit == 'price_meter':
digit = re.sub(r" ", "", re.sub(r"₽/²", "", string))
except:
return -1
return digit
def parse_date(string):
now = datetime.strptime("15.03.20 00:00", "%d.%m.%y %H:%M")
s = string
if string.find('') >= 0:
s = "{} {}".format(now.day, now.strftime("%b"))
s = string.replace('', s)
elif string.find('') >= 0:
s = "{} {}".format(now.day - 1, now.strftime("%b"))
s = string.replace('',s)
if (s.find('') > 0):
s = s.replace('','mar')
if (s.find('') > 0):
s = s.replace('','feb')
if (s.find('') > 0):
s = s.replace('','jan')
return parse(s).strftime('%Y-%m-%d %H:%M:%S')
def parse_text(text, index):
tag_table = '_93444fe79c--wrapper--E9jWb'
tag_items = ['_93444fe79c--card--_yguQ', '_93444fe79c--card--_yguQ']
tag_flats_counts = '_93444fe79c--totalOffers--22-FL'
tags = {
'link':('c6e8ba5398--info-section--Sfnx- c6e8ba5398--main-info--oWcMk','undefined c6e8ba5398--main-info--oWcMk'),
'desc': ('c6e8ba5398--title--2CW78','c6e8ba5398--single_title--22TGT', 'c6e8ba5398--subtitle--UTwbQ'),
'price': ('c6e8ba5398--header--1df-X', 'c6e8ba5398--header--1dF9r'),
'price_meter': 'c6e8ba5398--term--3kvtJ',
'metro': 'c6e8ba5398--underground-name--1efZ3',
'pub_datetime': 'c6e8ba5398--absolute--9uFLj',
'address': 'c6e8ba5398--address-links--1tfGW',
'square': ''
}
res = []
flats_counts = 0
soup = BeautifulSoup(text)
if soup.find('div', {'class': tag_flats_counts}):
flats_counts = parse_digits(soup.find('div', {'class': tag_flats_counts}).text, 'flats_counts')
flats_list = soup.find('div', {'class': tag_table})
if flats_list:
items = flats_list.find_all('div', {'class': tag_items})
for i, item in enumerate(items):
d = {'index': index}
index += 1
for tag in tags.keys():
tag_value = tags[tag]
key, value = parse_tag(tag, tag_value, item)
d[key] = value
results[index] = d
return flats_counts, index
from IPython.display import clear_output
sum_flats = 0
index = 0
results = {}
for i, text in enumerate(site_texts):
flats_counts, index = parse_text(text, index)
sum_flats = len(results)
clear_output(wait=True)
print(f" {i + 1} flats = {flats_counts}, {sum_flats} ")
print(f" sum_flats ({sum_flats}) = flats_counts({flats_counts})")
Un matiz interesante fue que la cifra indicada en la parte superior de la página e indicando el número total de apartamentos encontrados a pedido difiere de una página a otra. Entonces, en nuestro ejemplo, estas 5.402 ofertas están ordenadas de manera predeterminada, que van desde 5343 a 5402, disminuyendo gradualmente al aumentar el número de páginas de la solicitud (pero no por el número de anuncios mostrados). Además, era posible continuar descargando páginas más allá de los límites del número de páginas indicadas en el sitio. En nuestro caso, solo se ofrecieron 54 páginas en el sitio, pero pudimos descargar 309 páginas, con solo anuncios antiguos, para un total de 8640 anuncios de alquiler de apartamentos.Una investigación de este hecho quedará fuera del alcance de este artículo.Procesamiento de marco de datos
Por lo tanto, tenemos un único marco de datos con datos sin procesar en 8640 ofertas. Llevaremos a cabo un análisis de superficie de los precios promedio y mediano en los distritos, calcularemos el precio promedio de alquiler por metro cuadrado del apartamento y el costo del apartamento en el distrito "en promedio".Procederemos de los siguientes supuestos para nuestro estudio:- Falta de repeticiones: todos los apartamentos encontrados son apartamentos verdaderamente existentes. En la primera etapa, eliminamos los apartamentos repetidos en la dirección y la cuadratura, pero si el apartamento tiene una cuadratura o dirección ligeramente diferente, consideramos estas opciones como apartamentos diferentes.
- — .
— «» ? ( ) , , , , . , , , . «» : . «» ( ) , .
Necesitaremos:price_per_month - precio de alquiler mensual en rubloscuadrados - área deokrug - distrito, en este estudio no nos interesa toda la direcciónprice_meter - precio de alquiler por 1 metro cuadradoEl códigodf['price_per_month'] = df['price'].str.strip('/.').astype(int)
new_desc = df["desc"].str.split(",", n = 3, expand = True)
df["square"]= new_desc[1].str.strip(' ²').astype(int)
df["floor"]= new_desc[2]
new_address = df['address'].str.split(',', n = 3, expand = True)
df['okrug'] = new_address[1].str.strip(" ")
df['price_per_meter'] = (df['price_per_month'] / df['square']).round(2)
df = df.drop(['index','metro', 'price_meter','link', 'price','desc','address','pub_datetime','floor'], axis='columns')
Ahora "cuidaremos" las emisiones manualmente de acuerdo con los cronogramas. Para visualizar los datos, veamos tres bibliotecas: matplotlib , seaborn y plotly .Histogramas de datos . Matplotlib le permite mostrar rápida y fácilmente todos los gráficos de los grupos de datos que nos interesan, no necesitamos más. La figura a continuación, según la cual solo 1 propuesta en Mitino no puede servir como una evaluación cualitativa del apartamento promedio, se elimina. Otra imagen interesante en el Okrug administrativo del sur: la mayoría de las ofertas (más de 500 unidades) con un valor de alquiler por debajo de 1000 rublos, y un aumento en las ofertas (casi 300 unidades) en 1700 rublos por metro cuadrado. En el futuro, puede ver por qué sucede esto: hurgando en otros indicadores para estos apartamentos.Solo una línea de código proporciona histogramas allí para conjuntos de datos agrupados:hists = df['price_per_meter'].hist(by=df['okrug'], figsize=(16, 14), color = "tab:blue", grid = True)
 La dispersión de los valores . A continuación se presentan los gráficos utilizando las tres bibliotecas. Seaborn por defecto es más hermoso y brillante, pero gráficamente le permite mostrar los valores inmediatamente cuando pasa el mouse, lo cual es muy conveniente para nosotros para seleccionar los valores de los "valores atípicos" que eliminaremos.matplotlib
La dispersión de los valores . A continuación se presentan los gráficos utilizando las tres bibliotecas. Seaborn por defecto es más hermoso y brillante, pero gráficamente le permite mostrar los valores inmediatamente cuando pasa el mouse, lo cual es muy conveniente para nosotros para seleccionar los valores de los "valores atípicos" que eliminaremos.matplotlibfig, axes = plt.subplots(nrows=4,ncols=3,figsize=(15,15))
for i, (name, group) in enumerate(df_copy.groupby('okrug')):
axes = axes.flatten()
axes[i].scatter(group['price_per_meter'],group['square'], color ='blue')
axes[i].set_title(name)
axes[i].set(xlabel=' 1 ..', ylabel=', 2')
fig.tight_layout()
 marinero
marinerosns.pairplot(vars=["price_per_meter","square"], data=df_copy, hue="okrug", height=5)
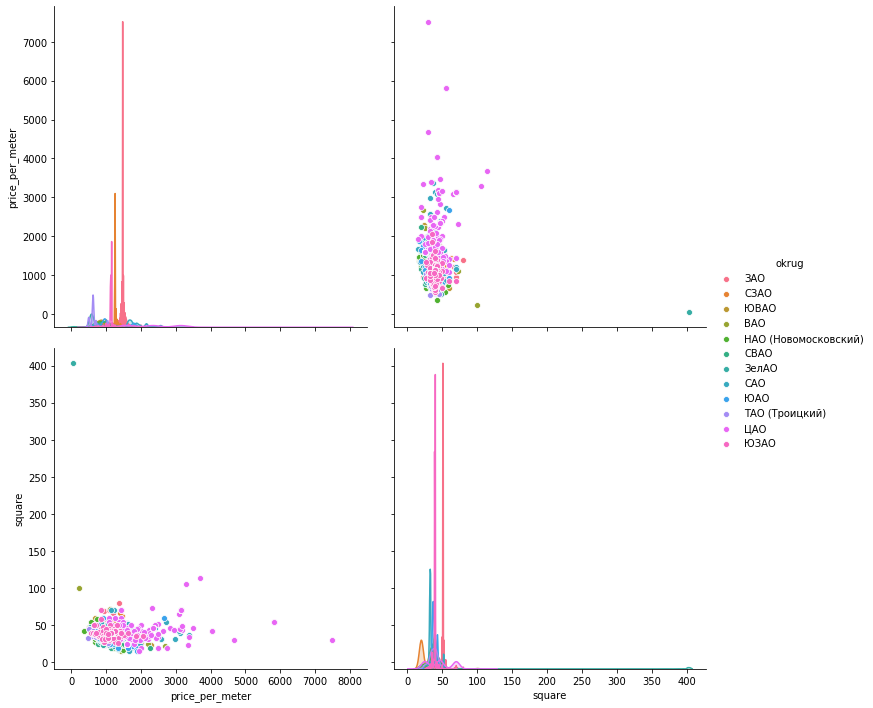 argumentalmenteCreo que habrá suficiente ejemplo para un distrito.
argumentalmenteCreo que habrá suficiente ejemplo para un distrito.import plotly.express as px
for i, (name, group) in enumerate(df_copy.groupby('okrug')):
fig = px.scatter(group, x="price_per_meter", y="square", facet_col="okrug",
width=400, height=400)
fig.update_layout(
margin=dict(l=20, r=20, t=20, b=20),
paper_bgcolor="LightSteelBlue",
)
fig.show()
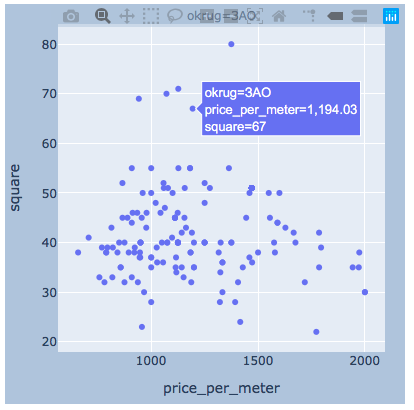
resultados
Entonces, después de haber limpiado los datos, eliminando expertamente las emisiones, tenemos 8602 ofertas "limpias".A continuación, calculamos las estadísticas principales de acuerdo con los datos: promedio, mediana, desviación estándar, obtenemos la siguiente calificación de los distritos de Moscú a medida que disminuye el costo promedio de alquiler de un apartamento promedio: puede dibujar hermosos histogramas comparando, por ejemplo, los precios promedio y promedio en el distrito:
puede dibujar hermosos histogramas comparando, por ejemplo, los precios promedio y promedio en el distrito: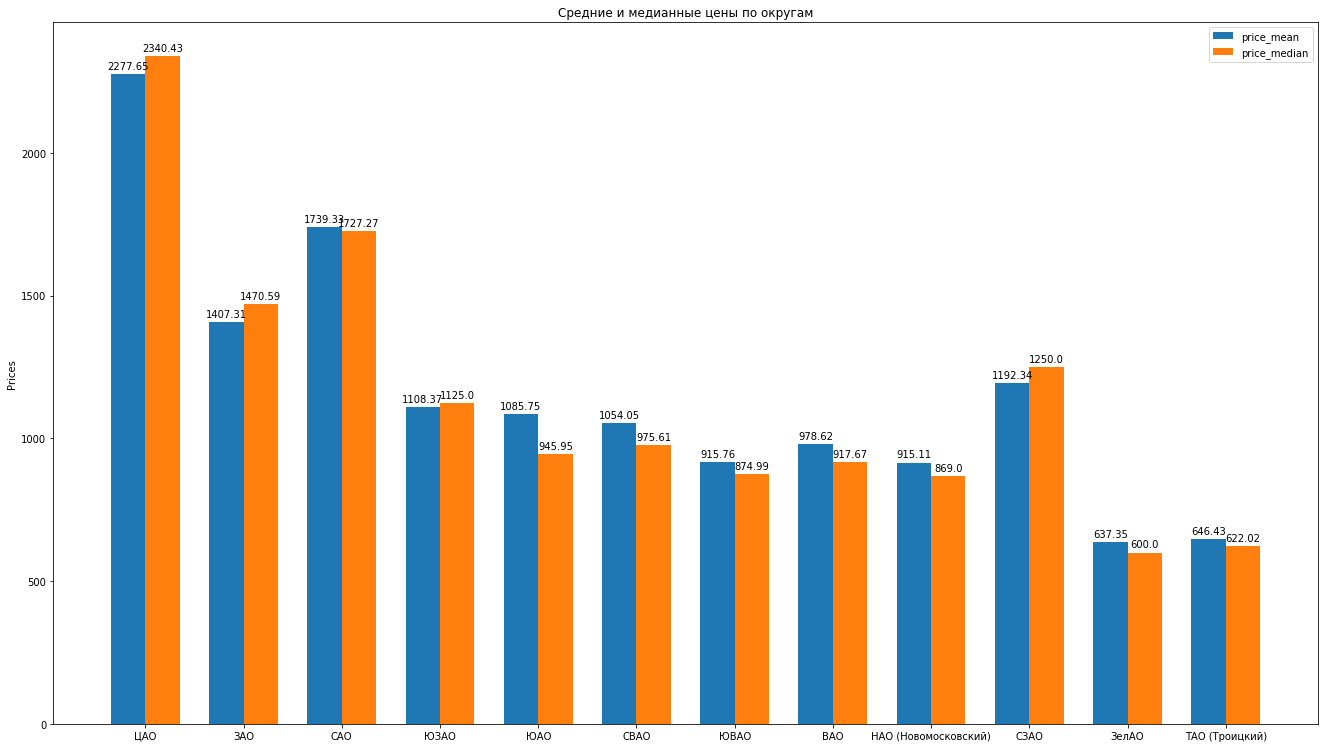 ¿Qué más puede hacer? decir sobre la estructura de las propuestas de apartamentos de alquiler basadas en datos:
¿Qué más puede hacer? decir sobre la estructura de las propuestas de apartamentos de alquiler basadas en datos:- , , , . “” , ( ). , , , , , , “” . , , .
- . . « ». , «» — . . . , , , , , - , , . . .
- , “” , . , , — .
Un capítulo separado, increíblemente interesante y hermoso es el tema de los geodatos, la visualización de nuestros datos en relación con el mapa. Puede mirar con gran detalle y detalle, por ejemplo, en los siguientes artículos:Visualización de resultados electorales en Moscú en un mapa en un Jupyter NotebookLikbez en proyecciones cartográficas con imágenes deOpenStreetMap como fuente de geodatos.Brevemente, OpenStreetMap es nuestro todo, las herramientas convenientes son: geopandas , cartoframes (dicen que ya es murió?) y folio , que usaremos.Así es como se verán nuestros datos en un mapa interactivo.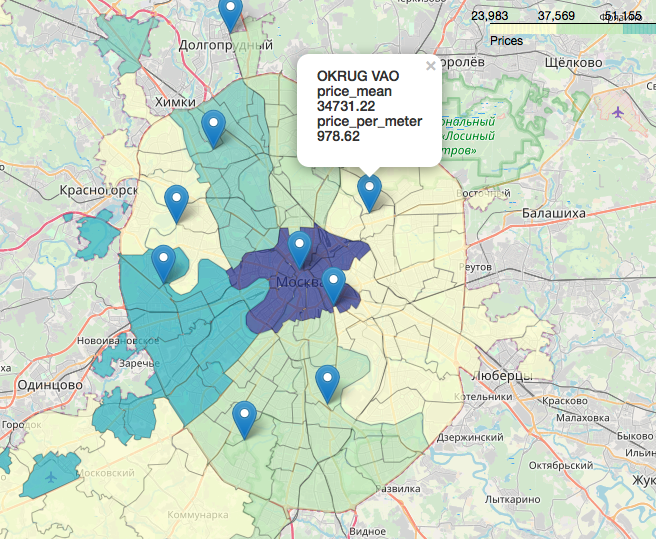 Materiales que resultaron útiles en el trabajo del artículo:Espero que te haya interesado, como yo.Gracias por leer. La crítica constructiva es bienvenida.Las fuentes y los conjuntos de datos se publican en el github aquí .
Materiales que resultaron útiles en el trabajo del artículo:Espero que te haya interesado, como yo.Gracias por leer. La crítica constructiva es bienvenida.Las fuentes y los conjuntos de datos se publican en el github aquí .