Hace algún tiempo, comencé un viaje increíble al mundo del compilador JIT para encontrar lugares donde puedas meter las manos y acelerar algo, como En el curso del trabajo principal, se ha acumulado una pequeña cantidad de conocimiento en LLVM y sus optimizaciones. En este artículo, me gustaría compartir una lista de mis mejoras en JIT (en .NET se llama RyuJIT en honor a algún dragón o anime, no lo descubrí), la mayoría de los cuales ya han llegado a master y estarán disponibles en .NET (Core) 5 Mis optimizaciones afectan diferentes fases de JIT, que se pueden mostrar de manera muy esquemática de la siguiente manera: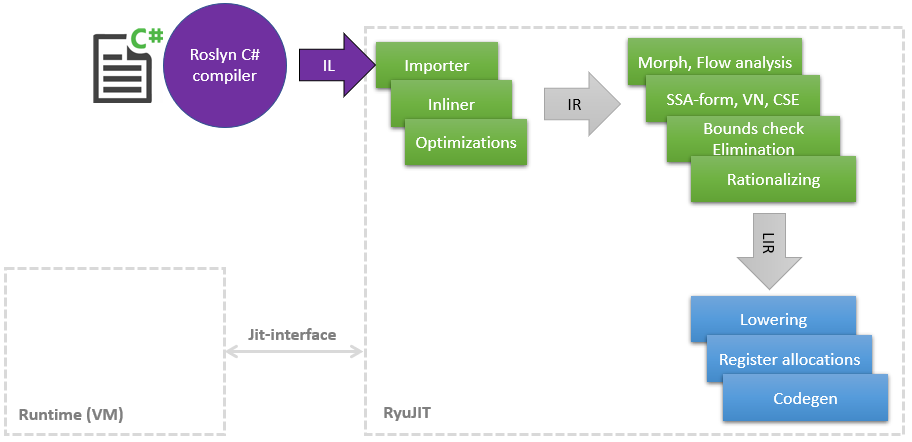 Como se puede ver en el diagrama, JIT es un módulo separado relacionado con la interfaz Jit estrecha , por la cual JIT consulta sobre algunas cosas, por ejemplo, ¿es posible?echa una clase a otra. Cuanto más tarde el JIT compila el método en Tier1, más información puede proporcionar el tiempo de ejecución, por ejemplo, que los
Como se puede ver en el diagrama, JIT es un módulo separado relacionado con la interfaz Jit estrecha , por la cual JIT consulta sobre algunas cosas, por ejemplo, ¿es posible?echa una clase a otra. Cuanto más tarde el JIT compila el método en Tier1, más información puede proporcionar el tiempo de ejecución, por ejemplo, que los static readonlycampos se pueden reemplazar con una constante, porque la clase ya está inicializada estáticamente.Entonces, comencemos con la lista.PR # 1817 : optimizaciones de boxing / unboxing en coincidencia de patrones
Fase: ImportadorMuchas de las nuevas características de C # a menudo pecan al insertar códigos de operación CIL de box / unbox . Esta es una operación muy costosa, que es esencialmente la asignación de un nuevo objeto en el montón, copiando el valor de la pila en él, y luego también carga el GC al final. Ya hay varias optimizaciones en JIT para este caso, pero encontré la falta de coincidencia de patrones en C # 8, por ejemplo:public static int Case1<T>(T o)
{
if (o is int x)
return x;
return 0;
}
public static int Case2<T>(T o) => o is int n ? n : 42;
public static int Case3<T>(T o)
{
return o switch
{
int n => n,
string str => str.Length,
_ => 0
};
}
Y veamos el asm-codegen antes de mi optimización (por ejemplo, para la especialización int) para los tres métodos: Y ahora después de mi mejora:
Y ahora después de mi mejora: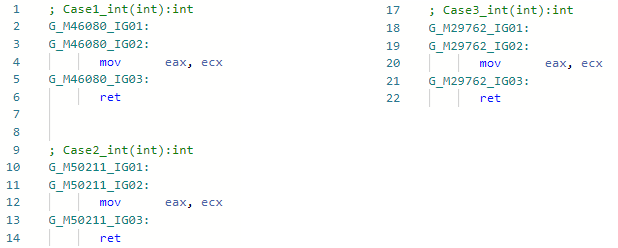 El hecho es que la optimización ha encontrado patrones de código IL
El hecho es que la optimización ha encontrado patrones de código ILbox !!T
isinst Type1
unbox.any Type2
Al importar y tener información sobre tipos, pude simplemente ignorar estos códigos de operación y no insertar boxing-anboxing. Por cierto, también implementé la misma optimización en Mono. En lo sucesivo, un enlace a Pull-Request está contenido en el encabezado de la descripción de optimización.PR # 1157 typeof (T) .IsValueType ⇨ verdadero / falso
Fase: ImportadorAquí entrené a JIT para reemplazar inmediatamente Type.IsValueType con una constante si es posible. Este es un desafío menos y la capacidad de cortar condiciones y ramas completas en el futuro, un ejemplo:void Foo<T>()
{
if (!typeof(T).IsValueType)
Console.WriteLine("not a valuetype");
}
Y veamos el codegen para la especialización Foo <int> antes de la mejora: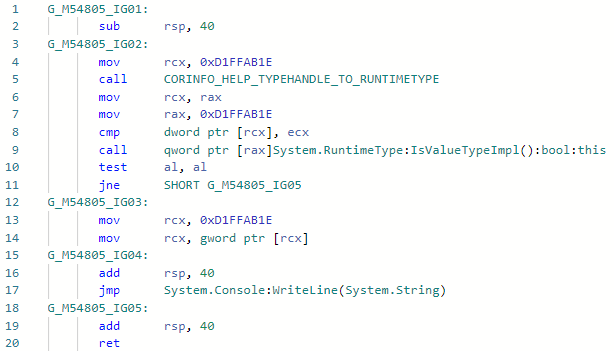 Y después de la mejora: lo
Y después de la mejora: lo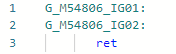 mismo se puede hacer con otras propiedades de Tipo si es necesario.
mismo se puede hacer con otras propiedades de Tipo si es necesario.PR # 1157 typeof(T1).IsAssignableFrom(typeof(T2)) ⇨ true/false
Fase: ImportadorCasi lo mismo: ahora puede verificar la jerarquía en métodos genéricos sin temor a que esto no esté optimizado, por ejemplo:void Foo<T1, T2>()
{
if (!typeof(T1).IsAssignableFrom(typeof(T2)))
Console.WriteLine("T1 is not assignable from T2");
}
Del mismo modo, será reemplazado por una constante true/falsey la condición se puede eliminar por completo. En tales optimizaciones, por supuesto, hay algunos casos de esquina que siempre debe tener en cuenta: Sistema .__ Canon compartió genéricos, matrices, variabilidad co (ntr), valores nulos, objetos COM, etc.PR # 1378 "Hello".Length ⇨ 5
Fase: ImportadorA pesar de que la optimización es lo más obvia y simple posible, tuve que sudar mucho para implementarla en JIT-e. La cuestión es que JIT no sabía sobre el contenido de la cadena, vio literales de cadena ( GT_CNS_STR ), pero no sabía nada sobre el contenido específico de las cadenas. Tuve que ayudarlo contactando a VM (para expandir la interfaz JIT mencionada anteriormente), y la optimización en sí misma es esencialmente unas pocas líneas de código . Hay muchos casos de usuarios, además de los obvios, como: str.IndexOf("foo") + "foo".Lengthpara los no obvios en los que está involucrada la alineación (le recuerdo: Roslyn no se ocupa de la alineación, por lo que esta optimización sería ineficaz, además, como todas las demás), por ejemplo:bool Validate(string str) => str.Length > 0 && str.Length <= 100;
bool Test() => Validate("Hello");
Veamos el codegen para Test ( Validar está en línea):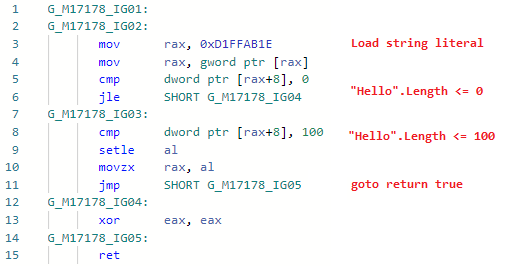 y ahora el codegen después de agregar la optimización:
y ahora el codegen después de agregar la optimización: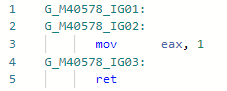 es decir alinee el método, reemplace las variables con literales de cadena, reemplace .Length de literales con longitudes de cadena reales, doble las constantes, elimine el código muerto. Por cierto, dado que JIT ahora puede verificar el contenido de una cadena, se han abierto puertas para otras optimizaciones relacionadas con los literales de cadena. La optimización en sí misma se mencionó en el anuncio de la primera vista previa de .NET 5.0: devblogs.microsoft.com/dotnet/announcing-net-5-0-preview-1 en la sección Mejoras en la calidad del código en RyuJIT .
es decir alinee el método, reemplace las variables con literales de cadena, reemplace .Length de literales con longitudes de cadena reales, doble las constantes, elimine el código muerto. Por cierto, dado que JIT ahora puede verificar el contenido de una cadena, se han abierto puertas para otras optimizaciones relacionadas con los literales de cadena. La optimización en sí misma se mencionó en el anuncio de la primera vista previa de .NET 5.0: devblogs.microsoft.com/dotnet/announcing-net-5-0-preview-1 en la sección Mejoras en la calidad del código en RyuJIT .PR # 1644: Optimización de cheques encuadernados.
Fase: eliminación de verificación de límitesPara muchos, no será un secreto que cada vez que acceda a una matriz por índice, el JIT inserta una verificación para usted de que la matriz no va más allá y arroja una excepción si esto sucede; en el caso de una lógica errónea, no podría para leer memoria aleatoria, obtener algo de valor y continuar.int Foo(int[] array, int index)
{
return array[index];
}
Tal verificación es útil, pero puede afectar en gran medida el rendimiento: en primer lugar, agrega una operación de comparación y hace que su código no esté ramificado, y en segundo lugar, agrega un código de llamada de excepción a su método con todas las consecuencias. Sin embargo, en muchos casos, el JIT puede eliminar estas verificaciones si puede probarse a sí mismo que el índice nunca irá más allá de eso, o que ya hay alguna otra verificación y no necesita agregar una más: Eliminación de verificación de límites (rango). Encontré varios casos en los que no pudo hacer frente y los corrigió (y en el futuro planeo algunas mejoras más de esta fase).var item = array[index & mask];
Aquí en este código, le digo a JIT que & maskesencialmente limita el índice de arriba a un valor mask, es decir si el valor masky la longitud de la matriz son conocidos por JIT , no puede insertar una verificación enlazada. Lo mismo ocurre con%, (& x >> y) operaciones. Un ejemplo del uso de esta optimización en aspnetcore .Además, si sabemos que en nuestra matriz, por ejemplo, hay 256 elementos o más, entonces si nuestro indexador desconocido es del tipo byte, no importa cuánto lo intente, nunca podrá salir de los límites. PR: github.com/dotnet/coreclr/pull/25912PR # 24584: x / 2 ⇨ x * 0.5
Fase: MorphC de este PR y comencé mi increíble inmersión en el mundo de las optimizaciones JIT. La operación "división" es más lenta que la operación "multiplicación" (y si es para enteros y, en general, un orden de magnitud). Funciona para constantes solo iguales a la potencia de dos, por ejemplo:static float DivideBy2(float x) => x / 2;
Codegen antes de la optimización: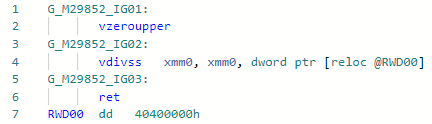 y después:
y después: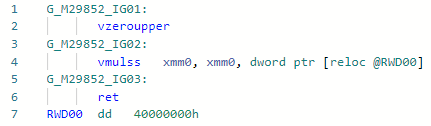 si comparamos estas dos instrucciones para Haswell, entonces todo quedará claro:
si comparamos estas dos instrucciones para Haswell, entonces todo quedará claro:vdivss (Latency: 10-20, R.Throughput: 7-14)
vmulss (Latency: 5, R.Throughput: 0.5)
Esto será seguido por optimizaciones que todavía están en la etapa de revisión de código y no por el hecho de que serán aceptadas.PR # 31978: Math.Pow(x, 2) ⇨ x * x
Fase: ImportadorTodo es simple aquí: en lugar de llamar a pow (f) para un caso bastante popular, cuando el grado es constante 2 (bueno, es gratis para 1, -1, 0), puede expandirlo en un simple x * x. Puede expandir cualquier otro grado, pero para esto debe esperar la implementación del modo de "matemática rápida" en .NET, en el cual la especificación IEEE-754 puede ser descuidada por razones de rendimiento. Ejemplo:static float Pow2(float x) => MathF.Pow(x, 2);
Codegen antes de la optimización: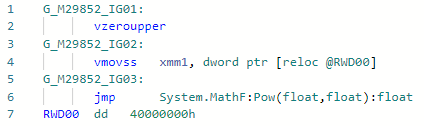 y después:
y después: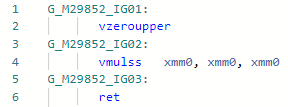
PR # 33024: x * 2 ⇨ x + x
Fase: DisminuciónTambién la optimización de micro (nano) piphol bastante simple, le permite multiplicar por 2 sin cargar la constante en el registro.static float MultiplyBy2(float x) => x * 2;
Codegen antes de la optimización: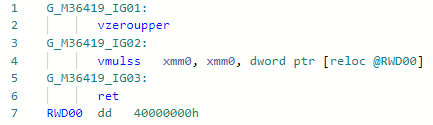 Después:
Después: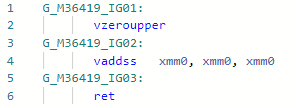 en general, la instrucción es la
en general, la instrucción es la mul(ss/sd/ps/pd)misma en latencia y rendimiento que add(ss/sd/ps/pd), pero la necesidad de cargar la constante "2" puede ralentizar un poco el trabajo. Aquí, en el ejemplo del codegen anterior, vaddsshice todo dentro del marco de un registro.PR # 32368: Optimización de Array.Length / c (o% s)
Fase: MorphDio la casualidad de que el campo Longitud de Array es un tipo con signo, y dividir y el resto por una constante es mucho más eficiente de un tipo sin signo (y no solo una potencia de dos), solo compara este codegen: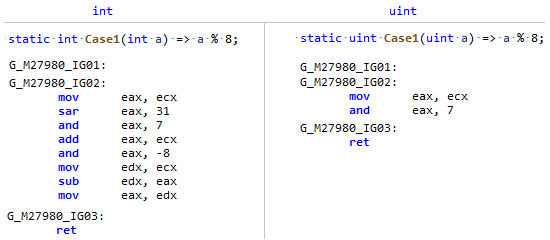 Mi PR solo le recuerda a JIT que
Mi PR solo le recuerda a JIT que Array.Lengthaunque significativo, pero de hecho, la longitud de la matriz NUNCA (a menos que sea un anarquista ) puede ser menor que cero, lo que significa que puede verlo como un número sin signo y aplicar algunas optimizaciones como para uint.PR # 32716: Optimización de comparaciones simples en código sin ramificación
Fase: Análisis de flujoEsta es otra clase de optimizaciones que opera con bloques básicos en lugar de expresiones dentro de uno. Aquí JIT es un poco conservador y tiene margen para mejoras, por ejemplo, inserte cmove cuando sea posible. Comencé con una optimización simple para este caso:x = condition ? A : B;
si A y B son constantes y la diferencia entre ellas es la unidad, por ejemplo, condition ? 1 : 2entonces, sabiendo que la operación de comparación en sí misma devuelve 0 o 1, podemos reemplazar el salto con sumar. En términos de RyuJIT, se parece a esto: recomiendo ver la descripción del RP en sí, espero que todo se describa claramente allí.
recomiendo ver la descripción del RP en sí, espero que todo se describa claramente allí.No todas las optimizaciones son igualmente útiles.
Las optimizaciones requieren una tarifa bastante alta:* Aumento = complejidad del código existente para soporte y lectura* Errores potenciales: probar optimizaciones del compilador es increíblemente difícil y fácil perder algo y obtener algún tipo de falla por parte de los usuarios.* Compilación lenta* Aumento del tamaño del binario JITComo ya entendió, no se aceptan todas las ideas y prototipos de optimizaciones y es necesario demostrar que tienen derecho a la vida. Una de las formas aceptadas para probar esto en .NET es ejecutar la utilidad jit-utils, que AOT compilará un conjunto de bibliotecas (todas BCL y corelib) y comparará el código del ensamblador para todos los métodos antes y después de las optimizaciones, así es como este informe busca la optimización"str".Length. Además del informe, todavía hay un cierto círculo de personas (como jkotas ) que, de un vistazo, pueden evaluar la utilidad y piratear todo desde la altura de su experiencia y comprender qué lugares en .NET pueden ser un cuello de botella y cuáles no. Y una cosa más: no juzgue la optimización por el argumento "nadie escribe", "sería mejor simplemente mostrar una advertencia en Roslyn": nunca se sabe cómo se verá su código después de que JIT alinee todo lo que sea posible y complete constantes.