La compresión de encabezados estándar apareció en HTTP / 2, pero el cuerpo de los valores de URI, Cookie, User-Agent todavía puede ser de decenas de kilobytes y requiere tokenización, búsqueda y comparación de subcadenas. La tarea se vuelve crítica si un analizador HTTP necesita manejar tráfico malicioso pesado. Las bibliotecas estándar proporcionan amplias herramientas de procesamiento de cadenas, pero las cadenas HTTP tienen sus propios detalles. Es por esta especificidad que se desarrolló el analizador HTTP Tempesta FW. Su rendimiento es varias veces mayor en comparación con las soluciones modernas de código abierto y supera a las más rápidas.Alexander Krizhanovsky (krizhanovsky) fundador y arquitecto de sistemas Tempesta Technologies, experto en informática de alto rendimiento en Linux / x86-64. Alexander hablará sobre las peculiaridades de la estructura de las cadenas HTTP, explicará por qué las bibliotecas estándar no son adecuadas para procesarlas y presentará la solución Tempesta FW.Debajo del corte: cómo HTTP Flood convierte su analizador HTTP en un cuello de botella, problemas x86-64 con predicciones erróneas de ramificación, almacenamiento en caché y falta de memoria en tareas típicas de analizador HTTP, comparación FSM con saltos directos, optimización GCC, vectorización automática, strspn () - y algoritmos similares a strcasecmp () para cadenas HTTP, SSE, AVX2 y ataques de inyección de filtrado utilizando AVX2.En Tempesta Technologies desarrollamos software a medida: nos especializamos en áreas complejas relacionadas con el alto rendimiento. Estamos especialmente orgullosos del desarrollo del núcleo de la primera versión WAF de Positive Technologies. Web Application Firewall (WAF) es un proxy HTTP: se ocupa de un análisis muy profundo del tráfico HTTP para ataques (Web y DDoS). Escribimos el primer núcleo para ello.Además de la consultoría, estamos desarrollando Tempesta FW : este es el controlador de entrega de aplicaciones (ADC). Hablaremos de él.Controlador de entrega de aplicaciones
Application Delivery Controller es un proxy HTTP con funcionalidad mejorada. Pero hablaré sobre una función relacionada con la seguridad: sobre el filtrado de ataques DDoS y web. También mencionaré limitaciones, y mostraré el trabajo y las funciones con ejemplos de código.
Actuación
Tempesta FW está integrado en el núcleo de pila TCP / IP de Linux. Gracias a esto y a varias otras optimizaciones, es muy rápido: puede procesar 1,8 millones de solicitudes por segundo en hardware barato. Esto es 3 veces más rápido que Nginx en la carga superior y también es rápido en comparación con el enfoque de derivación del núcleo.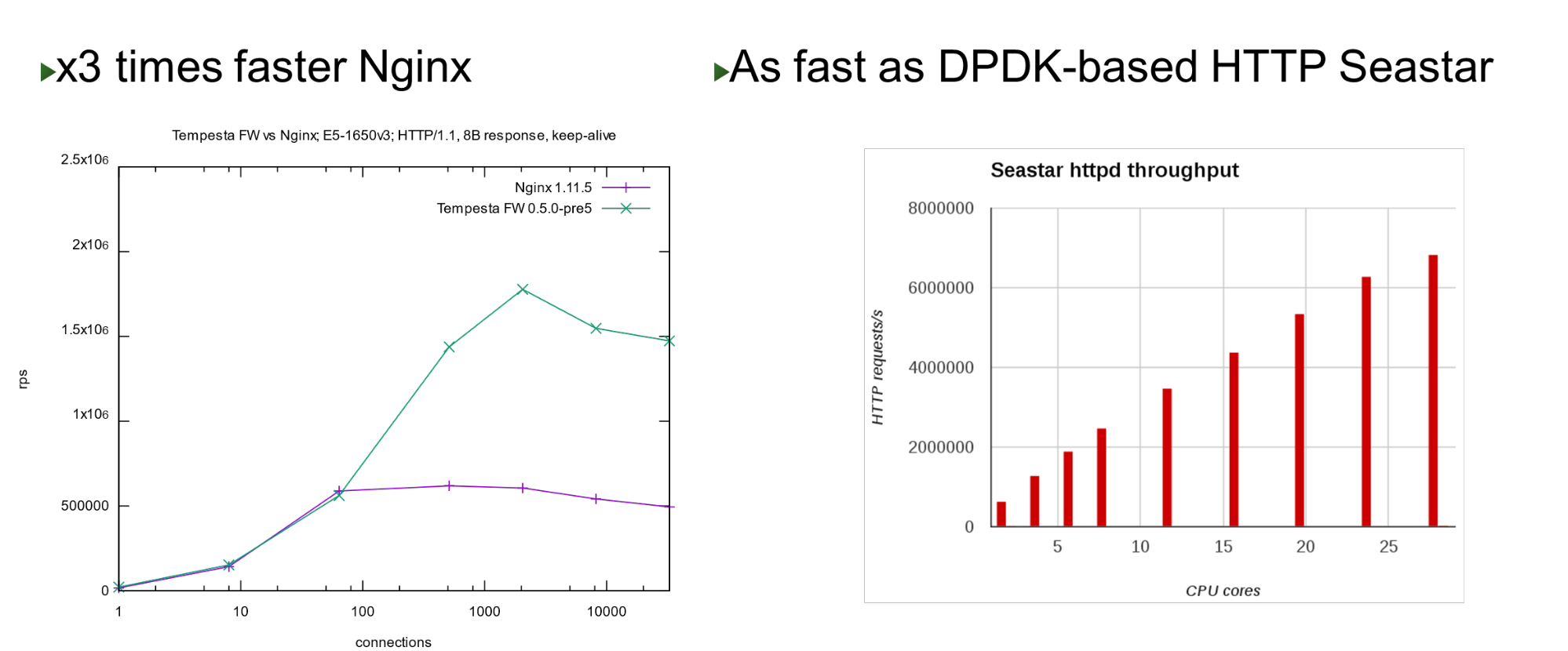 En un pequeño número de núcleos, muestra un rendimiento similar con el proyecto Seastar, que se utiliza en ScyllaDB (escrito en DPDK).
En un pequeño número de núcleos, muestra un rendimiento similar con el proyecto Seastar, que se utiliza en ScyllaDB (escrito en DPDK).Problema
El proyecto nació cuando comenzamos a trabajar en PT AF, en 2013. Este WAF se basó en un acelerador HTTP de código abierto popular. Nginx, HAProxy, Varnish o Apache Traffic son buenos aceleradores HTTP: entregan contenido fino, caché, modificación, pero ninguno de ellos está diseñado para el procesamiento y filtrado de tráfico masivo .Por lo tanto, pensamos que si hay un firewall de nivel de red, ¿por qué no continuar con esta idea e integrarla en la pila TCP / IP como un firewall de nivel de aplicación? En realidad, resultó Tempesta FW, un híbrido de acelerador HTTP y firewall .Nota: Nginx se usará como ejemplo en el informe porque es un servidor web simple y popular. En cambio, podría haber cualquier otro servidor HTTP de código abierto.HTTP
Veamos nuestra solicitud HTTP (HTTP / (1, ~ 2))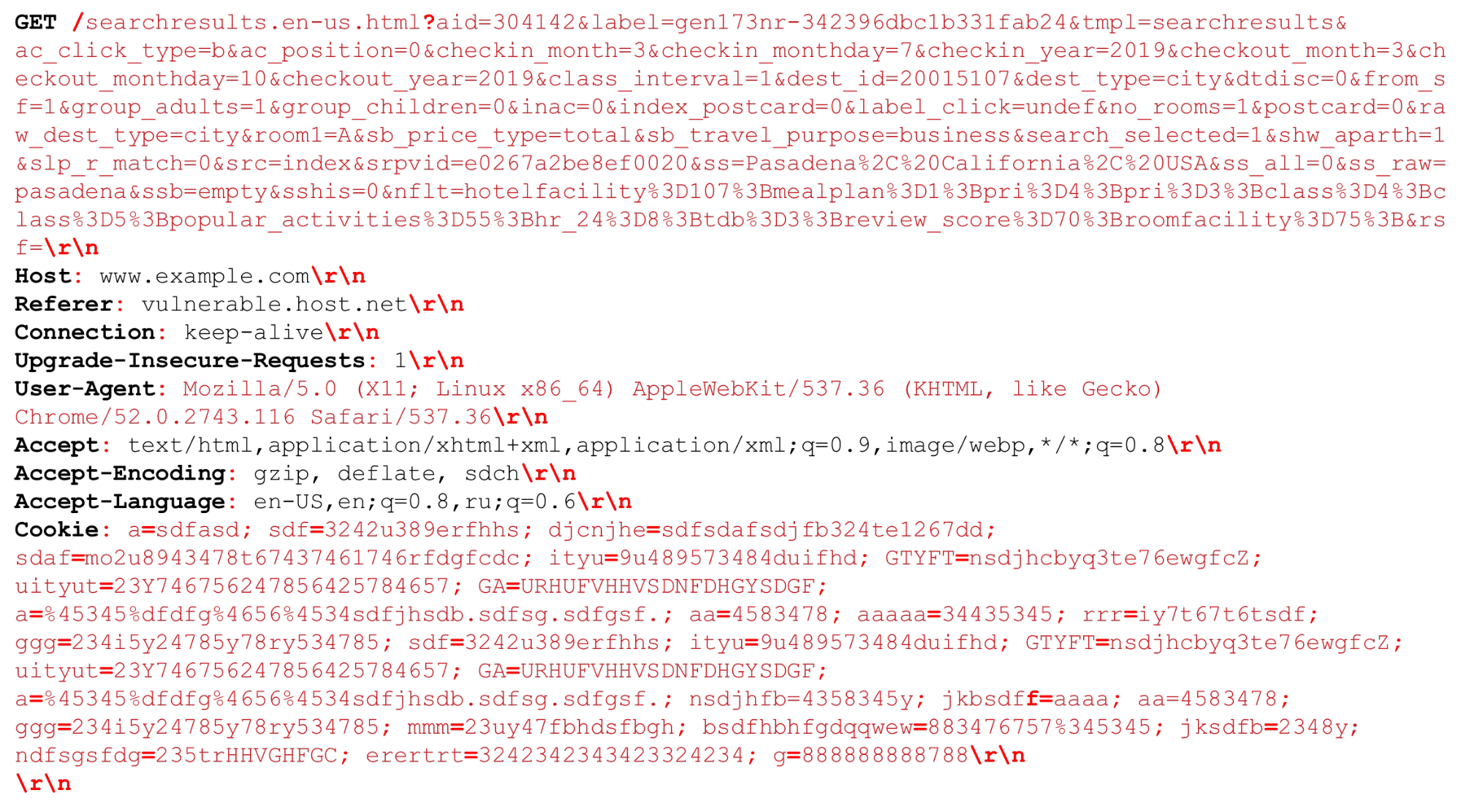 Podemos tener un URI muy grande. Los separadores que son importantes en el momento del análisis HTTP se resaltan en negrita roja . Destacaré las características: cadenas grandes de varios kilobytes, así como diferentes delimitadores, por ejemplo, "puntos y comas" adicionales que necesitamos analizar, o la secuencia "\ r \ n".También se necesita decir un poco sobre HTTP / 2.
Podemos tener un URI muy grande. Los separadores que son importantes en el momento del análisis HTTP se resaltan en negrita roja . Destacaré las características: cadenas grandes de varios kilobytes, así como diferentes delimitadores, por ejemplo, "puntos y comas" adicionales que necesitamos analizar, o la secuencia "\ r \ n".También se necesita decir un poco sobre HTTP / 2.Características HTTP / 2
HTTP / 2 es una mezcla de cadenas y datos binarios . Esta combinación se trata más de optimizar el ancho de banda de una conexión que de ahorrar recursos del servidor.HTTP / 2 en HPACK usa una tabla dinámica . La primera solicitud del cliente no está optimizada, no está en la tabla. Debe analizarlo para que se agregue a la tabla. Si HTTP / 2 DDoS llega a usted, este será el caso. En el caso normal, HTTP / 2 es un protocolo binario, pero aún debe analizar el texto: nombres de encabezado de texto, datos.Codificación Huffman. Esta es una codificación simple, pero Huffman es monstruosamente difícil de programar rápidamente para la compresión: la codificación de Huffman cruza el límite de bytes, no puede usar extensiones vectoriales y debe ir por bytes. No podrá procesar datos rápidamente en 32 o 16 bytes.Cookies, User-Agent, Referer, URI pueden ser muy grandes . Primero, elimine Huffman, luego envíelo a un analizador HTTP normal, igual que en HTTP / 1. Aunque está permitido por el RFC, no se recomienda comprimir las cookies, ya que se trata de datos confidenciales; no debe proporcionar al atacante información sobre su tamaño.Procesamiento HTTP lento . Todos los servidores HTTP primero decodifican HTTP / 2 y luego envían estas líneas al analizador HTTP / 1 que HTTP / 1 ya utiliza.¿Cuál es el problema con el análisis HTTP / 1?- Necesita programar rápidamente la máquina de estado.
- Necesita procesar rápidamente líneas consecutivas.
El tráfico malicioso se dirige a la parte más lenta (más débil) del proceso. Por lo tanto, si queremos hacer un filtro, debemos prestar atención a las partes lentas para que también funcionen rápidamente.Perfil Nginx
Veamos el perfil nginx bajo la inundación HTTP. Deshabilite el registro de acceso para que el sistema de archivos no se ralentice. Cuando incluso se solicita una página de índice regular, el analizador sube en la parte superior.Izquierda - "Perfil plano". Curiosamente, el punto más caliente no es mucho más pesado que el siguiente, y después de eso, el perfil desciende suavemente. Esto significa, por ejemplo, que optimizar la primera función dos veces no ayudará a mejorar significativamente el rendimiento. Es por eso que no optimizamos el mismo Nginx, sino que hicimos un nuevo proyecto que mejorará el rendimiento de toda la cola del perfil.Cómo se codifican los analizadores HTTP normales
Por lo general, tenemos un bucle ( while) que se ejecuta a lo largo de la línea y dos variables: estado ( state) y datos actuales ( str_ptr).Entramos en el ciclo (1) y observamos el estado actual (verificar estado). Pasamos a los datos recibidos (símbolo 'b') e implementamos algo de lógica. Pasamos al segundo estado (2). Vaya al final
Vaya al final switch(3): esta es la segunda transición en relación con el comienzo de nuestro código y, posiblemente, la segunda falta en el caché de instrucciones. Luego vamos al principio while(4), comemos el siguiente personaje ... ... y nuevamente buscamos el estado en las instrucciones dentro
... y nuevamente buscamos el estado en las instrucciones dentro case 2:.Cuando a una variable ya se le ha asignado un statevalor2, podríamos ir a la siguiente instrucción. Pero en cambio, subieron nuevamente y bajaron nuevamente. "Cortamos círculos" por código en lugar de simplemente bajar. Los analizadores normales no, por ejemplo, Ragel genera un analizador con transiciones directas.
Analizador HTTP Nginx
Algunas palabras sobre el analizador nginx y su entorno.Nginx funciona con la API de socket normal : los datos que van al adaptador se copian en el espacio del usuario. Como resultado, tenemos una gran porción de datos en la que estamos buscando lo que necesitamos.Nginx utiliza un algoritmo que funciona en dos pasadas: primero busca la longitud, luego la verifica. En el primer paso, escanea la cadena en busca de tokens, busca el primer token ("prueba"). En el segundo, tokens, comprueba el final de la solicitud ( Get) y comienza switch, de acuerdo con el tamaño del token.for (p = b->pos; p < b->last; p++) {
...
switch (state) {
...
case sw_method:
if (ch == ' ') {
m = r->request_start;
switch (p - m) {
case 3:
if (ngx_str3_cmp(m, 'G', 'E', 'T', ' ')) {
...
}
if ((ch < 'A' || ch > 'Z') && ch != '_' && ch != '-')
return NGX_HTTP_PARSE_INVALID_METHOD;
break;
...
"Obtener" siempre está en la misma porción de datos . Tempesta FW funciona con copia cero. Esto significa que los datos pueden tener un tamaño completamente arbitrario: 1 byte o 1000 bytes cada uno. Este "mecanismo" no nos conviene.Veamos cómo funciona switchen GCC.Gcc
Tabla de búsqueda . A la izquierda hay un ejemplo típico de enumeración: comience con 0, luego etiquetas consecutivas, 26 constantes y luego algún código que lo procese todo. A la derecha está el código que genera el compilador. Primero, compare la variable
Primero, compare la variable stateen el registro EAX con una constante. A continuación, presentamos todas las etiquetas en forma de una matriz secuencial de punteros de 8 bytes (tabla de búsqueda). En esta instrucción, pasamos el desplazamiento en esta matriz: es una doble desreferenciación de punteros. Abajo a la derecha está el código al que cambiamos desde esta tabla.Resulta una doble desreferenciación de la memoria: si recibimos datos secretos, entonces por bytes encontramos la dirección en la matriz y vamos a este puntero. Es importante saber que en la vida todavía es peor que en el ejemplo: para la tabla de búsqueda, el compilador generael código es más complicado en el caso de un script para un ataque Spectre.La búsqueda binaria . El siguiente caso switchno es con constantes secuenciales, sino con arbitrarias. El código es el mismo, pero ahora GCC no puede compilar una matriz tan grande y usar constantes como el índice de la matriz. Cambia a la búsqueda binaria. A la derecha vemos una comparación secuencial, la transición a la dirección y la continuación de la comparación: la búsqueda binaria es por código.Analizador HTTP Nginx. Veamos qué es la máquina de estado nginx. Tiene 9 kilobytes de código, esto es tres veces menos que el caché de primer nivel en la máquina en la que se lanzaron los puntos de referencia (como en la mayoría de los procesadores x86-64).
A la derecha vemos una comparación secuencial, la transición a la dirección y la continuación de la comparación: la búsqueda binaria es por código.Analizador HTTP Nginx. Veamos qué es la máquina de estado nginx. Tiene 9 kilobytes de código, esto es tres veces menos que el caché de primer nivel en la máquina en la que se lanzaron los puntos de referencia (como en la mayoría de los procesadores x86-64).$ nm -S /opt/nginx-1.11.5/sbin/nginx
| grep http_parse | cut -d' ' -f 2
| perl -le '$a += hex($_) while (<>); print $a'
9220
$ getconf LEVEL1_ICACHE_SIZE
32768
$ grep -c 'case sw_' src/http/ngx_http_parse.c
84
El analizador de encabezado nginx ngx_http_parse_header_line ()es un tokenizador simple. No hace nada con los valores de los encabezados y sus nombres, sino que simplemente coloca los tokens de los encabezados HTTP en un hash. Si necesita algún valor de encabezado, escanee la tabla de encabezado y repita el análisis.Debemos verificar estrictamente los nombres y valores de los encabezados por razones de seguridad .Tempesta FW: validación de cadenas de cadenas HTTP
Nuestra máquina de estados es un orden de magnitud más potente: validamos el encabezado RFC e inmediatamente, en el analizador, procesamos casi todo. Si nginx tiene 80 estados, entonces tenemos 520, y hay más de ellos. Si switchcontinuamos, sería 10 veces más grande.Tenemos E / S de copia cero : trozos de diferentes tamaños pueden cortar datos en diferentes lugares. diferentes fragmentos pueden cortar nuestros datos. En E / S de copia cero, por ejemplo, "GET" puede (rara vez) aparecer como "GET", "GE" y "T" o "G", "E" y "T", por lo que debe almacenar el estado entre datos . Prácticamente eliminamos los costos de E / S, pero en el perfil se eleva, todo está mal. El gran analizador HTTP es uno de los lugares más críticos del proyecto.$ grep -c '__FSM_STATE\|__FSM_TX\|__FSM_METH_MOVE\|__TFW_HTTP_PARSE_' http_parser.c
520
7.64% [tempesta_fw] [k] tfw_http_parse_req
2.79% [e1000] [k] e1000_xmit_frame
2.32% [tempesta_fw] [k] __tfw_strspn_simd
2.31% [tempesta_fw] [k] __tfw_http_msg_add_str_data
1.60% [tempesta_fw] [k] __new_pgfrag
1.58% [kernel] [k] skb_release_data
1.55% [tempesta_fw] [k] __str_grow_tree
1.41% [kernel] [k] __inet_lookup_established
1.35% [tempesta_fw] [k] tfw_cache_do_action
1.35% [tempesta_fw] [k] __tfw_strcmpspn
¿Qué hacer para mejorar esta situación?Referencias directas de FSM
Lo primero que hacemos es usar no un bucle, sino transiciones directas por etiquetas ( go to) . Los generadores de analizadores normales como Ragel hacen esto. Codificamos cada uno de nuestros estados con una etiqueta
Codificamos cada uno de nuestros estados con una etiqueta switchy una etiqueta en C con el mismo nombre . Cada vez que queremos ir, encontramos una etiqueta switcho accedemos al mismo estado directamente desde el código. La primera vez que pasamos switch, y luego dentro de ella, vamos directamente a la etiqueta deseada.Desventaja : cuando queremos cambiar al siguiente estado, debemos evaluar de inmediato si todavía tenemos datos disponibles (porque E / S de copia cero). Condición del cuerpoforSe copia en cada estado: en lugar de una condición en un FSM controlado por conmutador normal, tenemos 500 de ellos según el número de estados. Generar código para cada estado no es genial.En el caso de máquinas de estado grandes, porque forcon un gran switchinterior, GTC también repite la condición forvarias veces dentro del código.Reemplazar con switchtransiciones directas. La siguiente optimización es que no la usamos switchy cambiamos a saltos directos a las meta direcciones guardadas. Queremos ir inmediatamente al punto deseado tan pronto como ingresemos a la función. GCC le permite hacer esto. GCC tiene una extensión estándar que puede ayudar. Tomamos el nombre de la etiqueta (aquí está
GCC tiene una extensión estándar que puede ayudar. Tomamos el nombre de la etiqueta (aquí está from) y asignamos su dirección a alguna variable C mediante doble ampersand (&&). Ahora podemos hacer una instrucción de salto directojmpa la dirección de esta etiqueta con goto.Veamos que sale de eso.Rendimiento de conversión directa
En un pequeño número de estados, el generador de código de transición directa es incluso un poco más lento de lo normal switch. Pero para grandes máquinas de estado, la productividad se duplica. Si la máquina de estado es pequeña, es mejor usar la habitual switch.$ grep -m 2 'model name\|bugs' /proc/cpuinfo
model name : Intel(R) Core(TM) i7-6500U CPU @ 2.50GHz
bugs : cpu_meltdown spectre_v1 spectre_v2 spec_store_bypass l1tf
$ gcc --version|head -1
gcc (GCC) 8.2.1 20181105 (Red Hat 8.2.1-5)
States Switch-driven automaton Goto-driven automaton
7 header_line: 139ms header_line: 156ms
27 request_line: 210ms request_line: 186ms
406 big_header_line: 1406ms goto_big_header_line: 727ms
Nota: el código de Tempesta es más complicado que los ejemplos. GitHub tiene todos los puntos de referencia para que pueda ver todo en detalle. El código del analizador original está disponible en el enlace (analizador HTTP principal). Además de eso, en Tempesta FW hay analizadores más pequeños que usan FSM más fácilmente.¿Por qué las transiciones directas pueden ser más lentas?
En la máquina de estado, pasamos por un montón de código, por lo que (esperado) habrá muchas predicciones erróneas de la rama. Realicemos el "perfilado" de acuerdo con la predicción de errores de rama:perf record -e branch-misses -g ./http_benchmark
406 states: switch - 38% on switch(),
direct jumps - 13% on header value parsing
7,27 states: switch - <18% switch(), up to 40% for()
direct jumps – up to 46% on header & URI parsing
En una máquina de estado grande con 406 estados, pasamos el 38% del tiempo procesando transiciones switch. En una máquina de estado con transiciones directas, los puntos calientes son análisis de línea. Analizar una cadena en cada estado incluye verificar la condición del final de la cadena: la condición foren la máquina de estado encendida switch.perf stat -e L1-icache-load-misses ./http_benchmark
Switch-driven automaton Goto-driven automaton
big FSM code size: 29156 49202
L1-icache-load-misses: 4M 2M
A continuación, analizamos el perfil de ambos tipos de máquinas de estado por eventos L1 de caché de instrucciones: casi 30 kilobytes para switchy 50 kilobytes para saltos directos (más que el caché de las instrucciones de primer nivel).Parece que si no encajamos en el caché, debería haber muchos errores de caché para tal máquina de estado. Pero no, son 2 veces menos. Esto se debe a que la memoria caché funciona mejor: trabajamos con el código secuencialmente y logramos extraer datos de las memorias caché más antiguas.El compilador cambia el orden del código.
Cuando programamos el código de máquina de estado go to, primero tenemos los estados que se llamarán primero cuando se reciban los datos: el método HTTP, el URI y luego los encabezados HTTP. Parece lógico que el código se cargue en la memoria caché del procesador de forma secuencial, de arriba a abajo, justo cuando revisamos los datos. Pero esto está completamente mal. Si observa el código del ensamblador, verá cosas increíbles. A la izquierda está lo que programamos: primero analizamos los métodos
A la izquierda está lo que programamos: primero analizamos los métodos GETy POSTluego en algún lugar muy por debajo del método poco probable UNLOCK. Por lo tanto, esperamos ver el análisis GETy al comienzo del ensamblador POST, y luego UNLOCK. Pero todo es todo lo contrario: GETen el medio, POSTal final y UNLOCKarriba.Esto se debe a que el compilador no comprende cómo nos llegan los datos. Distribuye el código de acuerdo con su imagen de código hermoso. Para que pueda organizar el código en el orden correcto, debemos usar la barrera del compilador .La barrera del compilador es un conjunto ficticio a través del cual el compilador no se reordenará. Simplemente colocando tales barreras, mejoramos la productividad en un 4% .STATE(sw_method) {
...
MATCH(NGX_HTTP_GET, "GET ");
MATCH(NGX_HTTP_POST, "POST");
__asm__ __volatile__("": : :"memory");
...
METH_MOVE(Req_MethU, 'N', Req_MethUn);
METH_MOVE(Req_MethUn, 'L', Req_MethUnl);
METH_MOVE(Req_MethUnl, 'O', Req_MethUnlo);
METH_MOVE(Req_MethUnlo, 'C', Req_MethUnloc);
METH_MOVE_finish(Req_MethUnloc, 'K', NGX_HTTP_UNLOCK)
Redacta el código a tu manera
Dado que el compilador no organiza los datos como queremos, haremos una optimización guiada por el generador de perfiles (optimización bajo el control del generador de perfiles). La optimización guiada del generador de perfiles (PGO) es el número total de muestras, no una secuencia de llamadas. Por ejemplo, un URI recibe más muestras que un análisis de método, por lo que posicionará el código de procesamiento de URI antes de procesar el método.¿Cómo funciona? Escribiremos el código, ejecutaremos puntos de referencia en él, daremos el resultado del perfil al compilador y generará el código óptimo para nuestras cargas. Pero el problema es que simplemente compila las secciones más populares del código, pero no rastrea la dependencia del tiempo. Si el URI más grande en la carga, entonces este será el lugar más caluroso. El URI se elevará a la parte superior de la función, y PGO no mostrará que el nombre del método siempre está antes del URI. En consecuencia, PGO no funciona.Req_Method: {
if (likely(PI(p) == CHAR4_INT('G', 'E', 'T', ' '))) {
...
goto Req_Uri;
}
if (likely(PI(p) == CHAR4_INT('P', 'O', 'S', 'T'))) {
...
goto Req_UriSpace;
}
goto Req_Meth_SlowPath;
}
...
Req_Uri:
...
Req_Meth_SlowPath:
...
Que funcionalikely/ unlikely macros (para el código del kernel de Linux, los intrínsecos de GCC están disponibles en el espacio del usuario __builtin_expect()). Dicen qué código colocar más cerca. Por ejemplo, probablemente informa que el cuerpo de la solicitud debería estar inmediatamente detrás if. Luego, la captación previa del código (captación previa del procesador) seleccionará ese código y todo será rápido. La imagen muestra el comienzo del método de análisis, el final y la barrera. No esperábamos ver el código detrás de la barrera. Parece que esto no debería ser, hemos puesto una barrera.¿Pero qué pasa en la realidad? El compilador ve la
La imagen muestra el comienzo del método de análisis, el final y la barrera. No esperábamos ver el código detrás de la barrera. Parece que esto no debería ser, hemos puesto una barrera.¿Pero qué pasa en la realidad? El compilador ve la likelycondición: lo más probable es que ingresemos al cuerpo de la condición y allí cambiemos a un salto incondicional a la etiquetaReq_Uri. Resulta que el código que está después de nuestra condición no se procesa en la "ruta activa". El compilador mueve el código debajo de la etiqueta detrás if, a pesar de la barrera, porque se cumple la condición de código activo.Para esto no fue así, GCC tiene una extensión: los atributos hoty coldpara las etiquetas. Dicen qué etiqueta está caliente (lo más probable) y cuál está fría (menos probable). Aquí acordamos qué es
Aquí acordamos qué es GETmás probable POSTy se lo dejamos a él likely. Bajo esta condición, el procesamiento de URI aumenta y POSTse reduce. El resto del código para la máquina de estado menos probable permanece debajo porque la etiqueta está fría.Ambiguo -O3
Veamos la optimización del compilador. Lo primero que viene a la mente es usar no O2, sino O3: debería ser más rápido. Pero esto no es así: O3 a veces genera un código peor. O3 es una colección de algunas optimizaciones . Si los agregamos a O2 por separado, obtenemos diferentes opciones: algunas optimizaciones ayudan, otras interfieren. Para nuestro código específico, seleccionamos solo aquellas optimizaciones que generan mejor el código. Dejamos el mejor resultado: aquí hay 1.820 segundos en relación con 1.838 y 1.858.Algunas opciones están resaltadas en verde: esta es la vectorización automática.
O3 es una colección de algunas optimizaciones . Si los agregamos a O2 por separado, obtenemos diferentes opciones: algunas optimizaciones ayudan, otras interfieren. Para nuestro código específico, seleccionamos solo aquellas optimizaciones que generan mejor el código. Dejamos el mejor resultado: aquí hay 1.820 segundos en relación con 1.838 y 1.858.Algunas opciones están resaltadas en verde: esta es la vectorización automática.Autovectorización
Un ejemplo de un ciclo de la guía GCC .int a[256], b[256], c[256];
void foo () {
for (int i = 0; i < 256; i++)
a[i] = b[i] + c[i];
}
Si tenemos una matriz variable que se repite, podemos optimizar el ciclo: descomponerlo en vectores. Por defecto, la auto- vectorización está habilitada en el tercer nivel de optimización -O3 : GCC genera el código vectorial donde puede. Pero no todo el código se puede vectorizar automáticamente (incluso si se vectoriza en principio).Podemos habilitar la opción GCC -fopt-info-vec-all, que muestra lo que se ha vectorizado y lo que no. Obtenemos que para nuestro punto de referencia, nada está vectorizado, pero el código aún se genera peor. Por lo tanto, la vectorización no siempre funciona: a veces ralentiza el código. Pero siempre podemos ver qué se ha vectorizado y qué no, y desactivar la vectorización, si es necesario.Alineación: ¿cómo comparar una cadena con GET?
Hacemos un pequeño truco, como en nginx: no analizamos líneas por bytes, sino que calculamos inty comparamos líneas con ellos.#define CHAR4_INT(a, b, c, d) ((d << 24) | (c << 16) | (b << 8) | a)
if (p == CHAR4_INT('G', 'E', 'T', ' ')))
Sabemos que si no está intalineado, se ralentiza 2-3 veces. Escribimos un pequeño punto de referencia que lo demuestra.$ ./int_align
Unaligned access = 6.20482
Aligned access = 2.87012
Read four bytes = 2.45249
Luego intenta alinear int. Miraremos, si la dirección está intalineada, luego compararemos int, si no, bytes. (((long)(p) & 3)
? ((unsigned int)((p)[0]) | ((unsigned int)((p)[1]) << 8)
| ((unsigned int)((p)[2]) << 16) | ((unsigned int)((p)[3]) << 24))
: *(unsigned int *)(p));
Pero resulta que este enfoque funciona peor:full request line: no difference
method only: unaligned - 214ms
aligned - 231ms
bytes - 216ms
En resumen: existe una diferencia entre el código de referencia aislado, no optimizable, y el código del analizador incorporado, que pierde la optimización debido a la gran cantidad de código. No hubo penalidad en el perfil.Nota: una discusión detallada de por qué esto está sucediendo en nuestra tarea se puede leer en GitHub .¿Por qué las cadenas HTTP son importantes para nosotros?
Por ejemplo, este es un URI normal: si es lo suficientemente exigente con el hotel, vaya a Reservas y configure algunos filtros, obtenga un URI de más de un kilobyte.Nginx tiene una máquina de análisis bastante masiva en
si es lo suficientemente exigente con el hotel, vaya a Reservas y configure algunos filtros, obtenga un URI de más de un kilobyte.Nginx tiene una máquina de análisis bastante masiva en switch/ case. No funciona muy rápido. Además, en el caso de Tempesta FW, necesitamos no solo analizar el URI, sino también verificar si hay inyecciones.case sw_check_uri:
if (usual[ch >> 5] & (1U << (ch & 0x1f)))
break;
switch (ch) {
case '/':
r->uri_ext = NULL;
state = sw_after_slash_in_uri;
break;
case '.':
r->uri_ext = p + 1;
break;
case ' ':
r->uri_end = p;
state = sw_check_uri_http_09;
break;
case CR:
r->uri_end = p;
r->http_minor = 9;
state = sw_almost_done;
break;
case LF:
r->uri_end = p;
r->http_minor = 9;
goto done;
case '%':
r->quoted_uri = 1;
...
Otro URI: /redir_lang.jsp?lang=foobar%0d%0aContent-Length:%200%0d%0a% 0d% 0aHTTP / 1.1% 20200% 20OK% 0d% 0aContent-Type:% 20text /html% 0d% 0aContent -Longitud:% 2019% 0d% 0a% 0d% 0aShazam </html>.Parece el primero, pero tiene una inyección. Tendrás que cavar lo suficientemente profundo como para entender esto.Ejecutemos una prueba : tome el primer URI, alimente wrk, configúrelo en nginx y vea que analizar nginx se calienta mucho. Si en la consulta de índice regular anterior estaba claro que el analizador ya estaba en la parte superior, aquí se calienta aún más.
Si en la consulta de índice regular anterior estaba claro que el analizador ya estaba en la parte superior, aquí se calienta aún más.8.62% nginx [.] ngx_http_parse_request_line
2.52% nginx [.] ngx_http_parse_header_line
1.42% nginx [.] ngx_palloc
0.90% [kernel] [k] copy_user_enhanced_fast_string
0.85% nginx [.] ngx_strstrn
0.78% libc-2.24.so [.] _int_malloc
0.69% nginx [.] ngx_hash_find
0.66% [kernel] [k] tcp_recvmsg
¿Qué tienen de especial las cadenas HTTP? Hay diferentes separadores ' : 'e ' , ', e incluso el final de las líneas, que pueden ser de doble byte \r\no de un solo byte \n, que se discutió al principio. No hay terminación 0 de las líneas C; por razones de seguridad, queremos verificar con mayor precisión lo que nos llega. Tenemos dos funciones estándar que ayudan en el analizador.strspn: comprueba el alfabeto, los caracteres disponibles en una cadena, compila dinámicamente un alfabeto válido, aunque se conoce en la etapa de compilación del programa.strcasecmp(). No hay necesidad de convertir el caso de comparar xcon Foo:. En la mayoría de los casos strcasecmp(), solo se requiere cumplimiento / incumplimiento, y no es necesario conocer la posición en la línea.
Trabajan despacio. Veamos los puntos de referencia y comprendamos qué les pasa.Analizadores rápidos
Hay varios analizadores.Nginx es el analizador más simple, analiza estrictamente el cumplimiento de RFC. También hay analizadores PicoHTTPParser (H2O) y Cloudflare. Procesan los datos más rápido, pero pueden omitir caracteres que no están permitidos por el RFC.PCMESTRI. Los analizadores usan varios enfoques diferentes. La primera es la instrucción PCMESTRI, que se usa en el analizador Pico.Establecemos rangos en las instrucciones. Desafortunadamente, podemos cargar 16 caracteres u 8 rangos. Si el rango consta de un solo carácter, simplemente repita. Debido a esta limitación, el analizador Pico no puede verificar completamente el cumplimiento de RFC, porque el RFC tiene más de 8 rangos en esta ubicación. Cargamos el alfabeto en el registro, cargamos la cadena, ejecutamos la instrucción. En la salida, vemos rápidamente si hay una coincidencia o no.AVX2 - Enfoque CloudFlare. El analizador CloudFlare, que utiliza AVX2, procesa 32 bytes de una cadena a la vez, en lugar de 16 bytes con un analizador Pico. El análisis es mejor en CloudFlare porque se transfirió a AVX2.
Cargamos el alfabeto en el registro, cargamos la cadena, ejecutamos la instrucción. En la salida, vemos rápidamente si hay una coincidencia o no.AVX2 - Enfoque CloudFlare. El analizador CloudFlare, que utiliza AVX2, procesa 32 bytes de una cadena a la vez, en lugar de 16 bytes con un analizador Pico. El análisis es mejor en CloudFlare porque se transfirió a AVX2. Verificamos todos los caracteres en un espacio en la tabla ASCII, todos los caracteres son mayores que 128 y toman el rango entre ellos. El código simple es rápido.Compare PCMESTRI y AVX2. Para nosotros, el límite actual es 1500. Este es el tamaño máximo de paquete que nos llega. Vemos que el código AVX2 en Big Data es mucho más rápido que el analizador Pico. Pero funciona más lento en datos pequeños, porque las instrucciones son más pesadas en AVX2.
Verificamos todos los caracteres en un espacio en la tabla ASCII, todos los caracteres son mayores que 128 y toman el rango entre ellos. El código simple es rápido.Compare PCMESTRI y AVX2. Para nosotros, el límite actual es 1500. Este es el tamaño máximo de paquete que nos llega. Vemos que el código AVX2 en Big Data es mucho más rápido que el analizador Pico. Pero funciona más lento en datos pequeños, porque las instrucciones son más pesadas en AVX2. Comparable a
Comparable astrspn. Si decidimos usarlo strspn, las cosas empeoran, especialmente en big data. En el "combate" no se puede usar el analizador sintáctico strspn.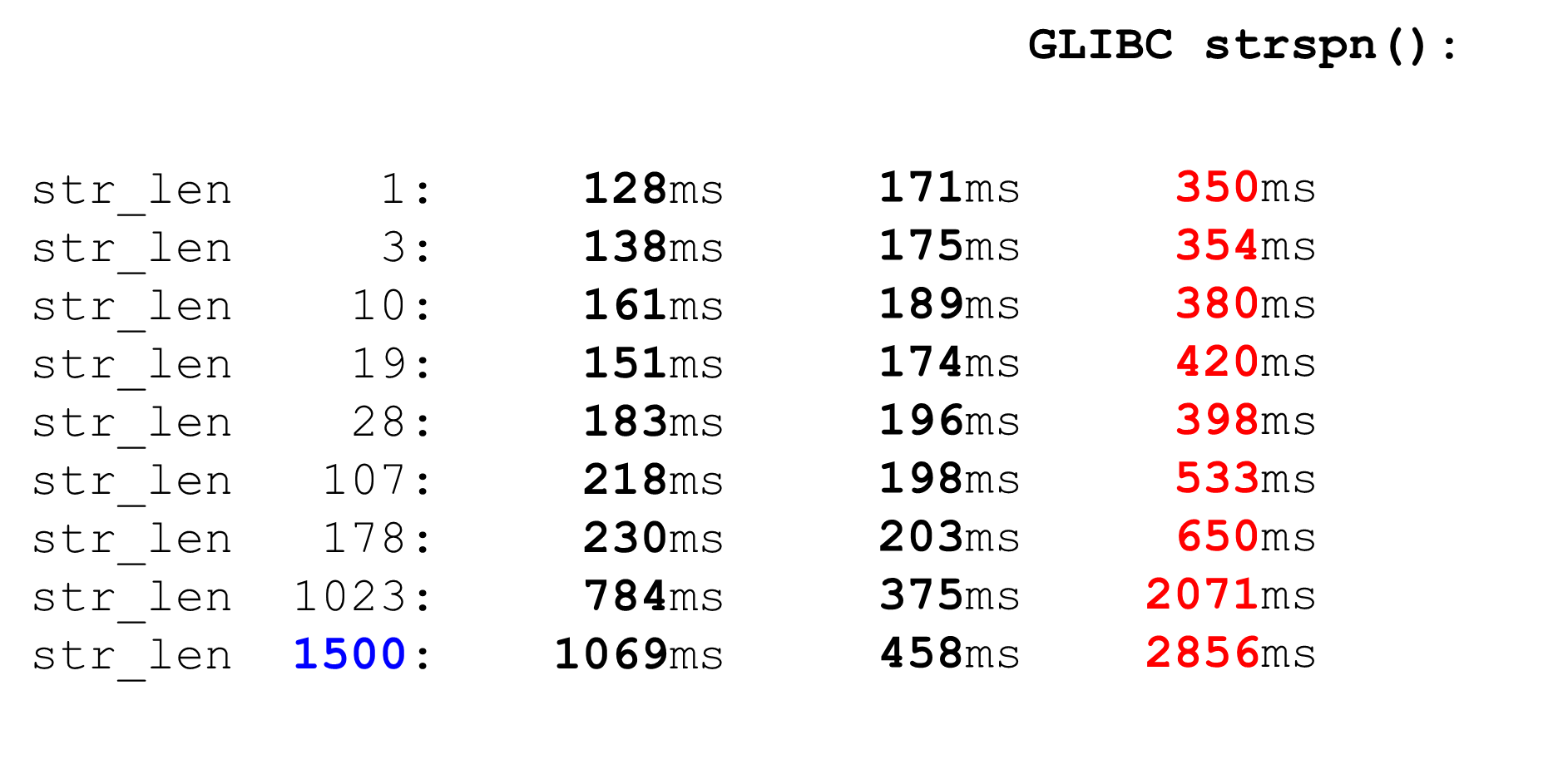
Tempesta Matcher es más rápido y más preciso
Nuestro analizador de velocidad es como estos dos. En datos pequeños, es tan rápido como un analizador Pico, en grandes, como CloudFlare. Sin embargo, no omite caracteres no válidos. ¿Cómo se organiza el analizador? Nosotros, como nginx, definimos una matriz de bytes y verificamos los datos de entrada por este: este es el prólogo de la función. Aquí trabajamos solo con términos cortos, lo usamos
¿Cómo se organiza el analizador? Nosotros, como nginx, definimos una matriz de bytes y verificamos los datos de entrada por este: este es el prólogo de la función. Aquí trabajamos solo con términos cortos, lo usamos likelyporque la predicción errónea de las ramas es más dolorosa para las líneas cortas que para las largas. Tomamos este código. Tenemos un límite de 4 debido a la última línea: debemos escribir una condición bastante poderosa. Si procesamos más de 4 bytes, la condición será más difícil y el código más lento.static const unsigned char uri_a[] __attribute__((aligned(64))) = {
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 1, 0, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1,
...
if (likely(len <= 4)) {
switch (len) {
case 0:
return 0;
case 4:
c3 = uri_a[s[3]];
case 3:
c2 = uri_a[s[2]];
case 2:
c1 = uri_a[s[1]];
case 1:
c0 = uri_a[s[0]];
}
return (c0 & c1) == 0 ? c0 : 2 + (c2 ? c2 + c3 : 0);
}
Bucle principal y cola grande. En el ciclo de procesamiento principal, dividimos los datos: si es lo suficientemente largo, procesamos 128, 64, 32 o 16 bytes cada uno. Tiene sentido procesar 128 cada uno: en paralelo, utilizamos varios canales de procesador (varias canalizaciones) y un procesador superescalar.for ( ; unlikely(s + 128 <= end); s += 128) {
n = match_symbols_mask128_c(__C.URI_BM, s);
if (n < 128)
return s - (unsigned char *)str + n;
}
if (unlikely(s + 64 <= end)) {
n = match_symbols_mask64_c(__C.URI_BM, s);
if (n < 64)
return s - (unsigned char *)str + n;
s += 64;
}
if (unlikely(s + 32 <= end)) {
n = match_symbols_mask32_c(__C.URI_BM, s);
if (n < 32)
return s - (unsigned char *)str + n;
s += 32;
}
if (unlikely(s + 16 <= end)) {
n = match_symbols_mask16_c(__C.URI_BM128, s);
if (n < 16)
return s - (unsigned char *)str + n;
s += 16;
}
Cola. El final de la función es similar al principio. Si tenemos menos de 16 bytes, procesamos 4 bytes en un bucle y luego no más de 3 bytes al final.while (s + 4 <= end) {
c0 = uri_a[s[0]];
c1 = uri_a[s[1]];
c2 = uri_a[s[2]];
c3 = uri_a[s[3]];
if (!(c0 & c1 & c2 & c3)) {
n = s - (unsigned char *)str;
return !(c0 & c1) ? n + c0 : n + 2 + (c2 ? c2 + c3 : 0);
}
s += 4;
}
c0 = c1 = c2 = 0;
switch (end - s) {
case 3:
c2 = uri_a[s[2]];
case 2:
c1 = uri_a[s[1]];
case 1:
c0 = uri_a[s[0]];
}
n = s - (unsigned char *)str;
return !(c0 & c1) ? n + c0 : n + 2 + c2;
Descargue máscaras de bits y datos: este es el algoritmo principal del cuerpo principal de la función. Presentamos una tabla ASCII (como en la imagen) con 16 filas y 8 columnas. Primero, codificamos nuestras filas de tabla en el primer registro de BM URI: la primera y segunda fila.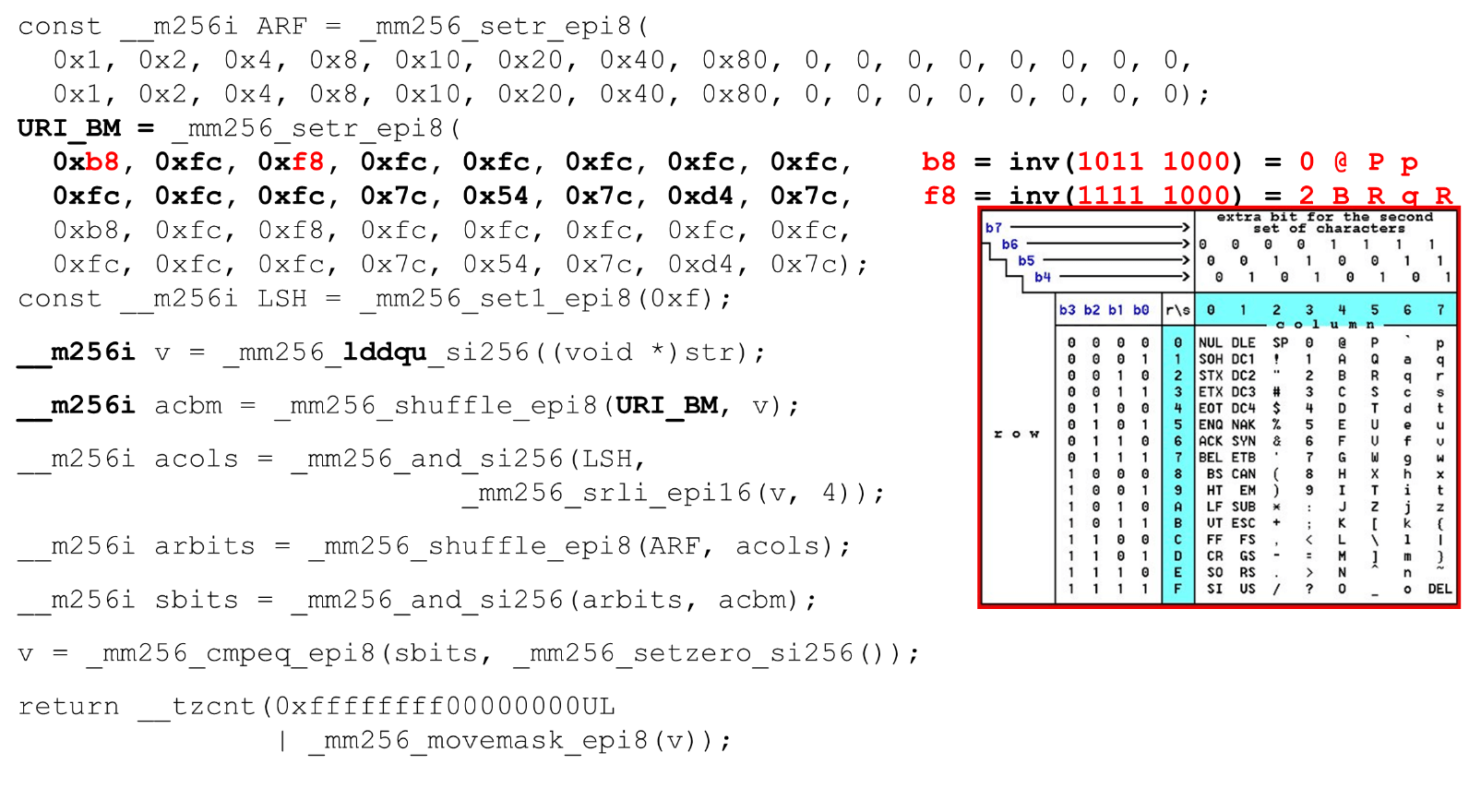 Los símbolos reales que permitimos son
Los símbolos reales que permitimos son 0 @ P py 2 B R q R. Están codificados de la siguiente manera: b8 = inv(1011 1000) = 0 @ P p, f8 = inv(1111 1000) = 2 B R q R.Codificamos en orden inverso: comenzamos en 0, el primer carácter de servicio no está permitido, y luego las unidades son lo que está permitido.Establecer las máscaras de bits ASCII. Por ejemplo, entra una línea "pr": el primer carácter de la primera línea es ASCII, el segundo de la segunda línea. Ejecutamos la instrucción aleatoria, que baraja las filas de nuestra tabla codificada de acuerdo con el orden de estos caracteres en la entrada. ID de columna para entrada. A continuación, colocamos las columnas de la tabla ASCII en un registro diferente. Luego "cruzamos" los registros de columnas y filas, y obtenemos una correspondencia: nuestro carácter o no.Como las columnas son los 4 bits más significativos del byte, nos desplazamos hacia la izquierda. AVX tiene un desplazamiento de solo 2 bytes, así que primero cambie el byte, luego n con nuestra máscara para obtener solo bits significativos.
ID de columna para entrada. A continuación, colocamos las columnas de la tabla ASCII en un registro diferente. Luego "cruzamos" los registros de columnas y filas, y obtenemos una correspondencia: nuestro carácter o no.Como las columnas son los 4 bits más significativos del byte, nos desplazamos hacia la izquierda. AVX tiene un desplazamiento de solo 2 bytes, así que primero cambie el byte, luego n con nuestra máscara para obtener solo bits significativos. Organización de columnas ASCII Ejecute la segunda combinación aleatoria, mueva la columna a las posiciones deseadas. En ambos casos, el byte de entrada de la última columna, por lo que en la primera y segunda posición obtenemos la misma columna.
Organización de columnas ASCII Ejecute la segunda combinación aleatoria, mueva la columna a las posiciones deseadas. En ambos casos, el byte de entrada de la última columna, por lo que en la primera y segunda posición obtenemos la misma columna.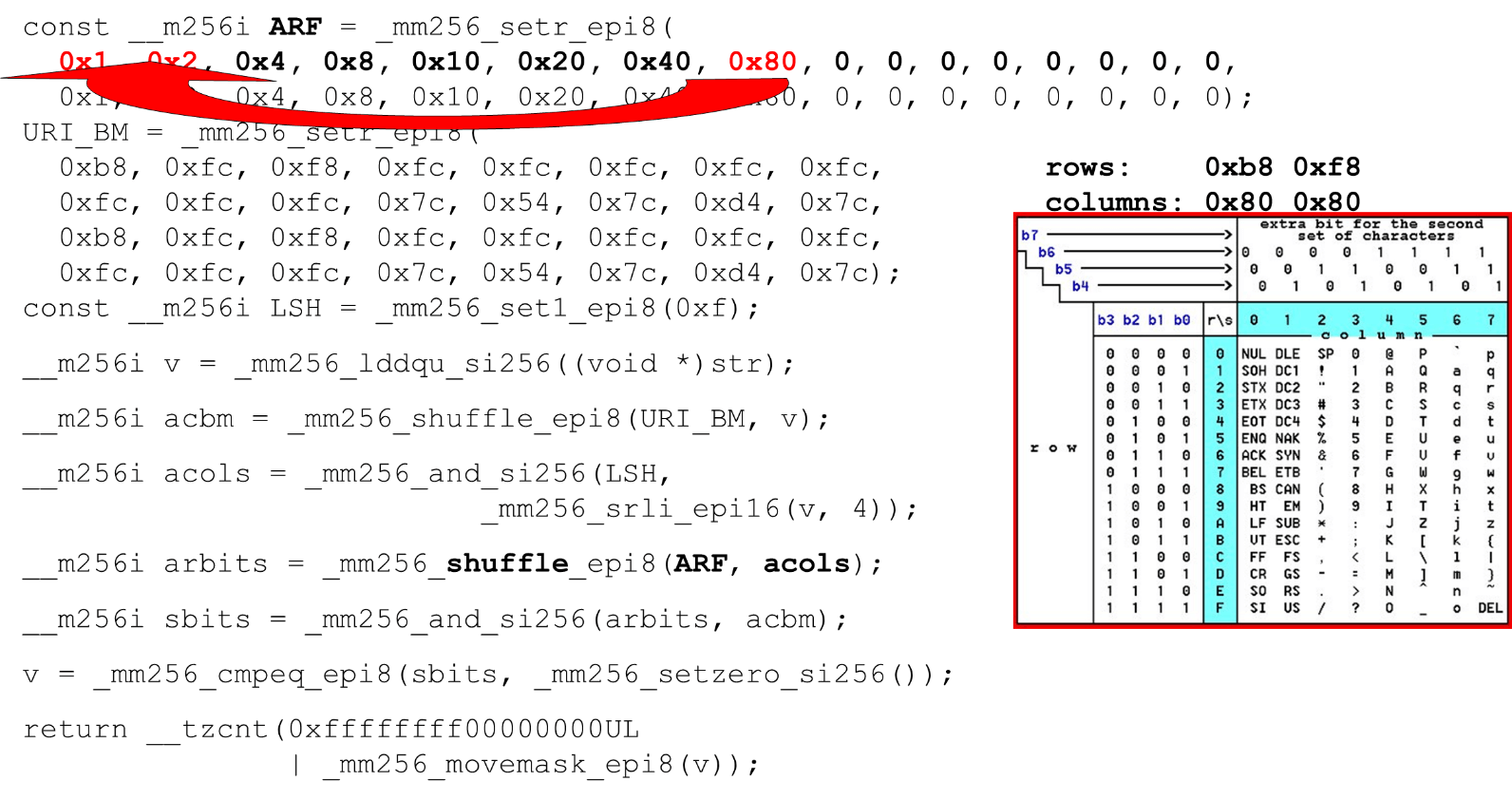 Intersección de columnas y filas de máscaras . Lo hacemos
Intersección de columnas y filas de máscaras . Lo hacemos and("cruzamos" las columnas con columnas) y obtenemos que los datos de entrada son válidos: el resultadoanddesde la intersección de columnas y filas no es cero. Cuente el número de ceros al final. Lo recolectamos todo del vector
Cuente el número de ceros al final. Lo recolectamos todo del vector inty lo devolvemos a la salida, de manera bastante simple.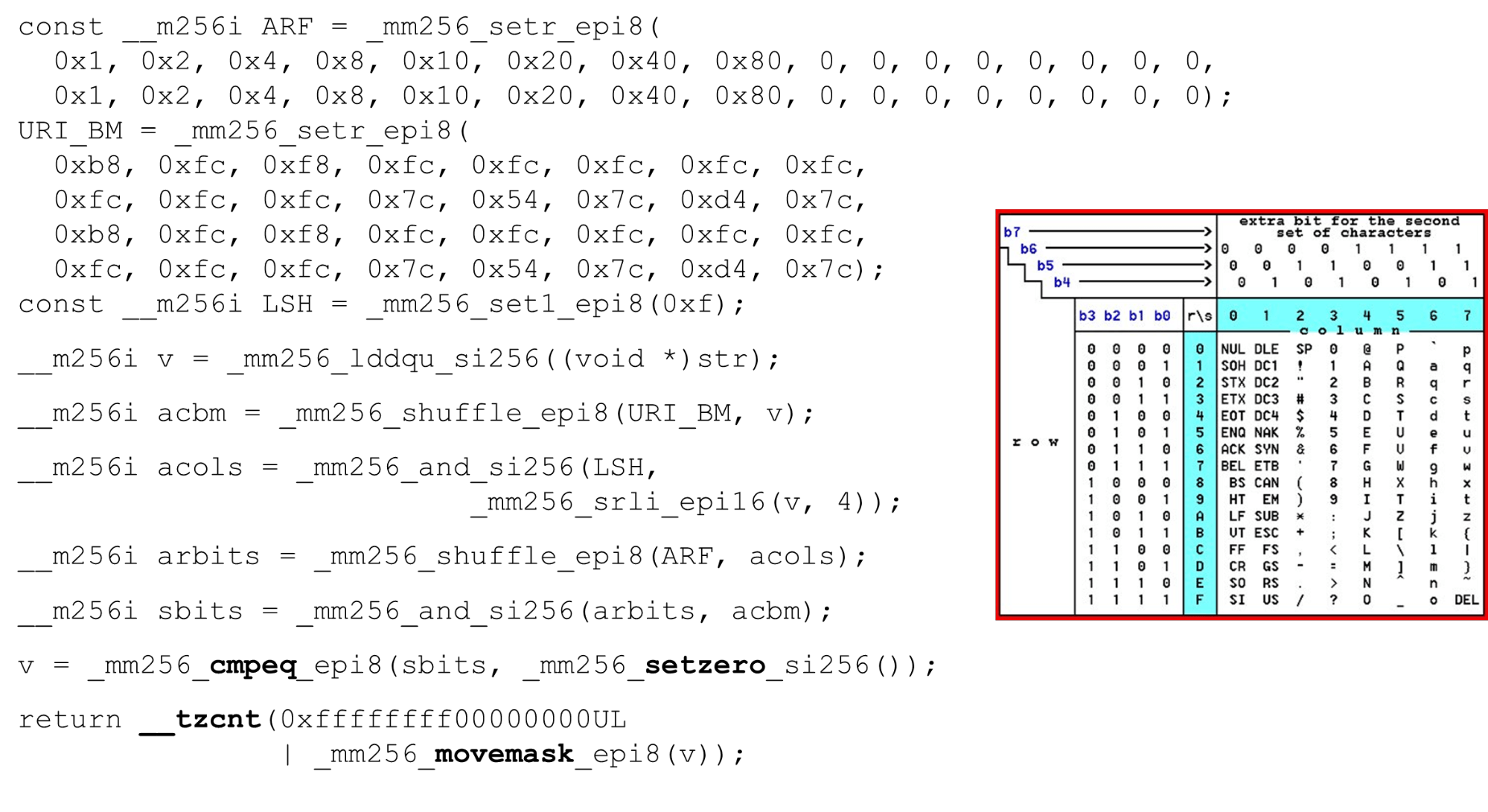 Personaliza los alfabetos. Al trabajar con la tabla ASCII, obtenemos una función económica: utilizamos tablas estáticas, pero nada nos impide preguntar al usuario qué alfabeto está disponible para los URI, los nombres y los valores de los diferentes encabezados. La solicitud HTTP URI y el encabezado usan 8 alfabetos (más o menos) para analizar una solicitud HTTP. Estas tablas pueden cargarse en el mismo código y compararse en un solo alfabeto especificado por el usuario, un URI válido. Si no, es diferente.
Personaliza los alfabetos. Al trabajar con la tabla ASCII, obtenemos una función económica: utilizamos tablas estáticas, pero nada nos impide preguntar al usuario qué alfabeto está disponible para los URI, los nombres y los valores de los diferentes encabezados. La solicitud HTTP URI y el encabezado usan 8 alfabetos (más o menos) para analizar una solicitud HTTP. Estas tablas pueden cargarse en el mismo código y compararse en un solo alfabeto especificado por el usuario, un URI válido. Si no, es diferente.Los ataques
Algunos casos en que esto puede ser útil.Ataque de SSRF con BlackHat'17 ("Una nueva era de SSRF"): http://foo@evil.com:80@google.com/un símbolo de ampersand poco probable. En algunas aplicaciones se usa, en otras no. Pero si no lo está utilizando, puede excluirlo del alfabeto válido y el ataque será bloqueado.RCE-ataque: «efectivo es el realizar ataques de inyección de comandos como», BSides'16: User-Agent: ...;echo NAELBD$((26+58))$echo(echo NAELBD)NAELBD.... El User-Agent es un encabezado estático, pero hay casos de un ataque RCE cuando algunos vienen shellcon caracteres atípicos para el User-Agent. Nos protegemos excepto por el signo del dólar.Sobreescritura de ruta relativa . El último caso es el que Google tuvo en 2016. Las llaves, los dos puntos, llegaron a la URI .../gallery?q=%0a{}*{background:red}/..//apis/howto_guide.html. Estos son caracteres poco probables que se pueden excluir del alfabeto.strcasecmp ()
Este es un código bastante trivial. También comparamos cadenas de 32 bytes, dos matrices cada una.__m256i CASE = _mm256_set1_epi8(0x20);
__m256i A = _mm256_set1_epi8('A' – 0x80);
__m256i D = _mm256_set1_epi8('Z' - 'A' + 1 – 0x80);
__m256i sub = _mm256_sub_epi8(str1, A);
__m256i cmp_r = _mm256_cmpgt_epi8(D, sub);
__m256i lc = _mm256_and_si256(cmp_r, CASE);
__m256i vl = _mm256_or_si256(str1, lc);
__m256i eq = _mm256_cmpeq_epi8(vl, str2);
return ~_mm256_movemask_epi8(eq);
Le damos al registro solo una línea, porque en la segunda programamos las constantes en nuestro analizador en minúsculas. Como tenemos comparaciones significativas, restamos 128 de cada byte (un truco de Hacker's Delight).También comparamos el rango de un carácter válido: si podemos registrarnos para esta cadena o no, es una letra o no. En el momento de verificar esto, en lugar de dos comparaciones de la a a la z, solo podemos usar una comparación (un truco de Hacker's Delight) y pasar a una constante.Rendimiento strcasecmp ()
Tempesta es mucho más rápido que GLIBC, incluso la nueva versión (18 o 19). El código strcasecmp()también usa AVX, pero no la segunda versión. AVX2 es más rápido, por lo que Tempesta tiene un código más rápido.
Linux kernel FPU
Usamos extensiones de procesador de vectores : están disponibles en el núcleo. Las instrucciones vectoriales son procesadas por el módulo procesador FPU. Este no es el módulo del procesador principal, ni los registros principales, sino bastante voluminoso.Por lo tanto, hay optimización en Linux. Si pasamos del kernel al espacio de usuario y viceversa, no guardamos el contexto de los registros de FPU (XMM, YMM, ZMM): cambiamos el contexto de solo los registros del módulo del procesador principal. Se supone que el kernel del sistema operativo no funciona con la extensión vectorial del procesador. Pero si lo necesita, por ejemplo, la criptografía puede hacerlo, pero necesita usar fpu_beginy fpu_endguardar y restaurar el contexto del registro FPU:__kernel_fpu_begin_bh();
memcpy_avx(dst, src, n);
__kernel_fpu_end_bh();
Estas son macros nativas que guardan y restauran el estado del módulo del procesador , que es responsable de los registros vectoriales. Estos son recursos bastante lentos.AVX y SSE
Antes de los puntos de referencia de guardar y restaurar el contexto de FPU, un par de palabras sobre operaciones vectoriales. ¿Por qué a veces tiene sentido trabajar con ensamblador? A veces, GCC genera un código subóptimo. El problema es que en los modelos de procesadores más antiguos, hay una penalización significativa por la transición de SSE a AVX. GCC tiene una nueva clave vzeroupper: úsela para que no genere esta instrucción vzeroupper, lo que borra los registros y elimina esta penalización.Debe usar esta instrucción solo si está trabajando con código antiguo que fue compilado para SSE por un tercero. Este no es nuestro caso y podemos tirar estas instrucciones con seguridad.FPU
Tenemos auto-vectorización en el procesador. Esto significa que en cualquier código de espacio de usuario habrá operaciones vectoriales. Dos procesos en el sistema usan extensiones de procesador de vectores. Cuando su proceso va al kernel y viceversa, no pierde el tiempo ahorrando y restaurando el estado vectorial del procesador. Pero si cambia de un espacio de usuario a otro (cambio de contexto), además del hecho de que los cachés de primer nivel están deshabilitados allí, el módulo de cambio de contexto en FPU begin / end también funciona mal. La operación es bastante costosa, un microbenchmark.En microbenchmarks, todo es siempre dramático, pero la operación es muy costosa. Por lo tanto, en el espacio del usuario, cambie el contexto durante mucho tiempo. No tenemos cambio de contexto en el núcleo, por lo que todo es rápido. Guardamos y restauramos el procesador de vectores solo una vez para un conjunto de paquetes suficientemente grande.
Dos procesos en el sistema usan extensiones de procesador de vectores. Cuando su proceso va al kernel y viceversa, no pierde el tiempo ahorrando y restaurando el estado vectorial del procesador. Pero si cambia de un espacio de usuario a otro (cambio de contexto), además del hecho de que los cachés de primer nivel están deshabilitados allí, el módulo de cambio de contexto en FPU begin / end también funciona mal. La operación es bastante costosa, un microbenchmark.En microbenchmarks, todo es siempre dramático, pero la operación es muy costosa. Por lo tanto, en el espacio del usuario, cambie el contexto durante mucho tiempo. No tenemos cambio de contexto en el núcleo, por lo que todo es rápido. Guardamos y restauramos el procesador de vectores solo una vez para un conjunto de paquetes suficientemente grande.Intelpocalypse
Al principio, mostré una opción de tabla de búsqueda para optimizar el código del conmutador: un proceso largo, enumeración, compila la tabla del conmutador en una matriz y sigue la doble referencia del puntero que salta sobre esta matriz. Este es un escenario para un ataque Spectre que explota la ejecución especulativa.Google tiene un buen artículo sobre cómo se organiza la doble desreferenciación de punteros en compiladores modernos en este momento (desde principios de 2018). No funciona muy bien. Si anteriormente en el registro se almacenó alguna dirección y fuimos a esta dirección, ahora tenemos un código diferente.jmp *%r11
call l1
l0: pause
lfence
jmp l0
l1: mov %r11, (%rsp)
ret
¿Como funciona? "Llamamos" a la función en l1, el proceso pasa a esta etiqueta y hacemos un hack: como si volviéramos de una función (que no es), pero reescribimos la dirección de retorno. Cuando hacemos las instrucciones call, colocamos la dirección de retorno, la dirección actual en la pila, la reescribimos con el contenido necesario del registro y vamos a l1. Pero el procesador, cuando se ejecuta su captador previo, ve que hay una función y luego una barrera. En consecuencia, todo será lento: arroja la captación previa y eliminamos la vulnerabilidad Spectre. El código es lento, el rendimiento cae un 15%.El siguiente ataque relativamente nuevo es Meltdown.. Es específico solo para procesos de espacio de usuario. Es muy doloroso leer la memoria del núcleo desde el espacio del usuario. El ataque es evitado por el Kernel Pate Table Isolation (KPTI), que se compila en los nuevos núcleos de forma predeterminada. Pero KPTI es muy costoso, hasta un 30-40% de degradación del rendimiento ( medido por MariaDB ).Esto se debe al hecho de que ya no tiene una optimización TLB perezosa: el espacio de direcciones del kernel y el procesador está completamente separado en diferentes tablas de páginas (antes, TLB perezoso seguía asignando el espacio del kernel a la tabla de páginas de cada proceso). Esto es doloroso para el espacio del usuario, pero no para Tempesta FW, que funciona completamente en el núcleo.Algunos enlaces útiles:Saint HighLoad++ . , 6 -- ( , Saint HighLoad++) , web .
PHP Russia: 13 , . — KnowledgeConf, ++ TechLead Conf — . , , .