Flant tiene una serie de desarrollos de código abierto, principalmente para Kubernetes, y loghouse es uno de los más populares. Esta es nuestra herramienta de registro central en K8, que se introdujo hace más de 2 años. Como mencionamos en un artículo reciente sobre los registros , requirió refinamiento y su relevancia solo creció con el tiempo. Hoy nos complace presentar una nueva versión de loghouse: v0.3.0 . Detalles sobre ella, debajo del corte.
Como mencionamos en un artículo reciente sobre los registros , requirió refinamiento y su relevancia solo creció con el tiempo. Hoy nos complace presentar una nueva versión de loghouse: v0.3.0 . Detalles sobre ella, debajo del corte.desventajas
Hemos estado utilizando loghouse en muchos grupos de Kubernetes todo este tiempo, y en general, esta solución se adapta tanto a nosotros como a los diversos clientes a los que también brindamos acceso.Sus principales ventajas son su interfaz simple e intuitiva, la capacidad de ejecutar consultas SQL, buena compresión y bajo consumo de recursos al insertar datos en la base de datos, así como una baja sobrecarga durante el almacenamiento.Los problemas más dolorosos en la casa de troncos durante la operación:- uso de tablas de partición unidas por una tabla de fusión;
- falta de un amortiguador que suavizaría ráfagas de troncos;
- Gema de panel web obsoleta y potencialmente vulnerable
- fluentd desactualizado ( loghouse-fluentd: el último no se inició debido a un conjunto de gemas problemático).
Además, se ha acumulado un número significativo de problemas en GitHub , que también me gustaría resolver.Cambios importantes en loghouse 0.3.0
De hecho, hemos acumulado suficientes cambios, pero destacaremos los más importantes. Se pueden dividir en 3 grupos principales:- mejorar el almacenamiento de registros y el esquema de la base de datos;
- recopilación de registros mejorada;
- La aparición de la vigilancia.
1. Mejoras en el almacenamiento de registros y el diseño de bases de datos
Innovaciones clave:- Los esquemas de almacenamiento de registros han cambiado, la transición al trabajo con una sola tabla y el rechazo de las tablas de particiones se ha completado .
- El mecanismo de limpieza base integrado en ClickHouse de las últimas versiones ha comenzado a aplicarse .
- Ahora puede usar una instalación externa de ClickHouse , incluso en modo de clúster.
Compare el rendimiento de los circuitos antiguos y nuevos en un proyecto real. Aquí hay un ejemplo de búsqueda de URL únicas en los registros de aplicaciones del popular recurso en línea dtf.ru :SELECT
string_fields.values[indexOf(string_fields.names, 'path')] AS path,
count(*) AS count
FROM logs
WHERE (namespace = 'kube-nginx-ingress') AND ((string_fields.values[indexOf(string_fields.names, 'vhost')]) LIKE '%foobar.baz%') AND (date = '2020-02-29')
GROUP BY string_fields.values[indexOf(string_fields.names, 'path')]
ORDER BY count DESC
LIMIT 20
La selección se lleva a cabo en decenas de millones de registros. El esquema anterior funcionó en 20 segundos: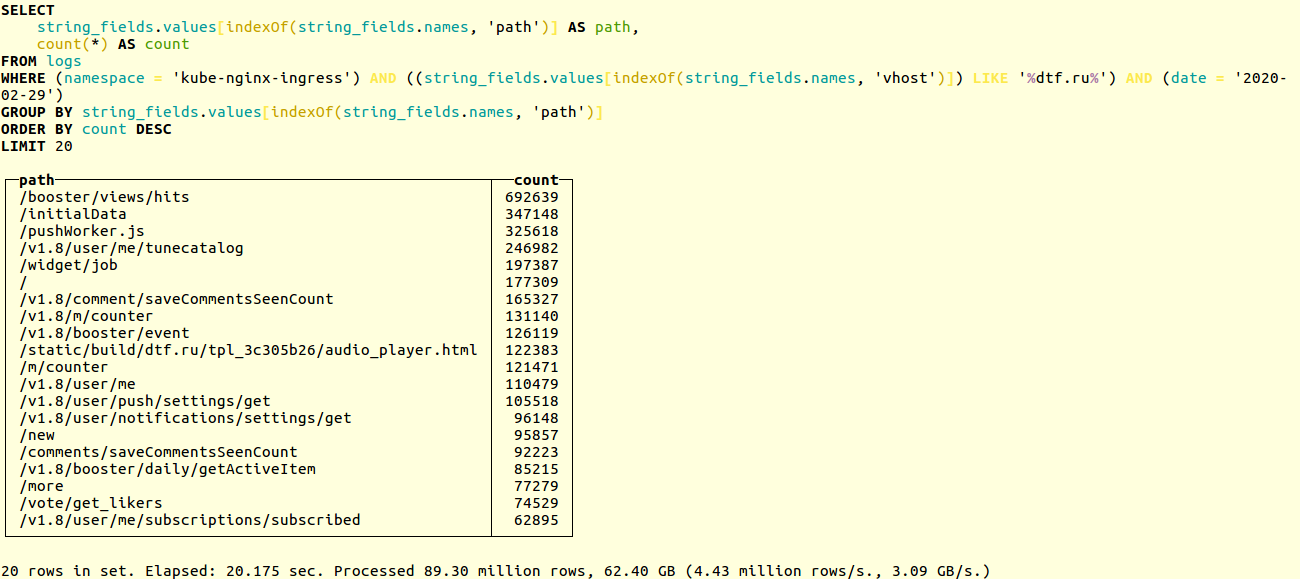 Nuevo - en 14:
Nuevo - en 14: si usa nuestro Helm-chart , al actualizar la casa de registro, la base de datos se migrará automáticamente al nuevo formato. De lo contrario, tendrá que hacer la migración manualmente. El proceso se describe en la documentación . En resumen, solo ejecuta:
si usa nuestro Helm-chart , al actualizar la casa de registro, la base de datos se migrará automáticamente al nuevo formato. De lo contrario, tendrá que hacer la migración manualmente. El proceso se describe en la documentación . En resumen, solo ejecuta:DO_DB_DEPLOY=true rake create_logs_tables
Además, comenzamos a usar TTL para las tablas ClickHouse . Esto le permite eliminar automáticamente datos de la base de datos que son más antiguos que el intervalo de tiempo especificado:CREATE TABLE logs
(
....
)
ENGINE = MergeTree()
PARTITION BY (date)
ORDER BY (timestamp, nsec, namespace, container_name)
TTL date + toIntervalDay(14)
SETTINGS index_granularity = 32768;
En la documentación se pueden encontrar ejemplos de configuraciones y esquemas de bases de datos para ClickHouse, incluido un ejemplo de trabajo con el clúster CH .Colección de registro mejorada
Innovaciones clave:- Se ha agregado un búfer diseñado para suavizar las ráfagas cuando aparece una gran cantidad de registros.
- Se implementó la capacidad de enviar registros a la casa de registro directamente desde la aplicación: a través de TCP y UDP, en formato JSON.
La batería de loghouse en loghouse es una nueva tabla logs_bufferagregada al esquema de la base de datos. Esta tabla está en memoria, es decir almacenado en RAM (tiene un tipo especial de Buffer ); es ella quien debe suavizar la carga en la base. Gracias por el consejo de agregarlo.Sovigod!Los registros de envío implementados directamente a loghouse desde la aplicación le permiten hacer esto incluso a través de netcat:echo '{"log": {"level": "info", "msg": "hello world"}}' | nc fluentd.loghouse 5170
Estos registros se pueden ver en el espacio de nombres donde está instalado loghouse en la secuencia net: Los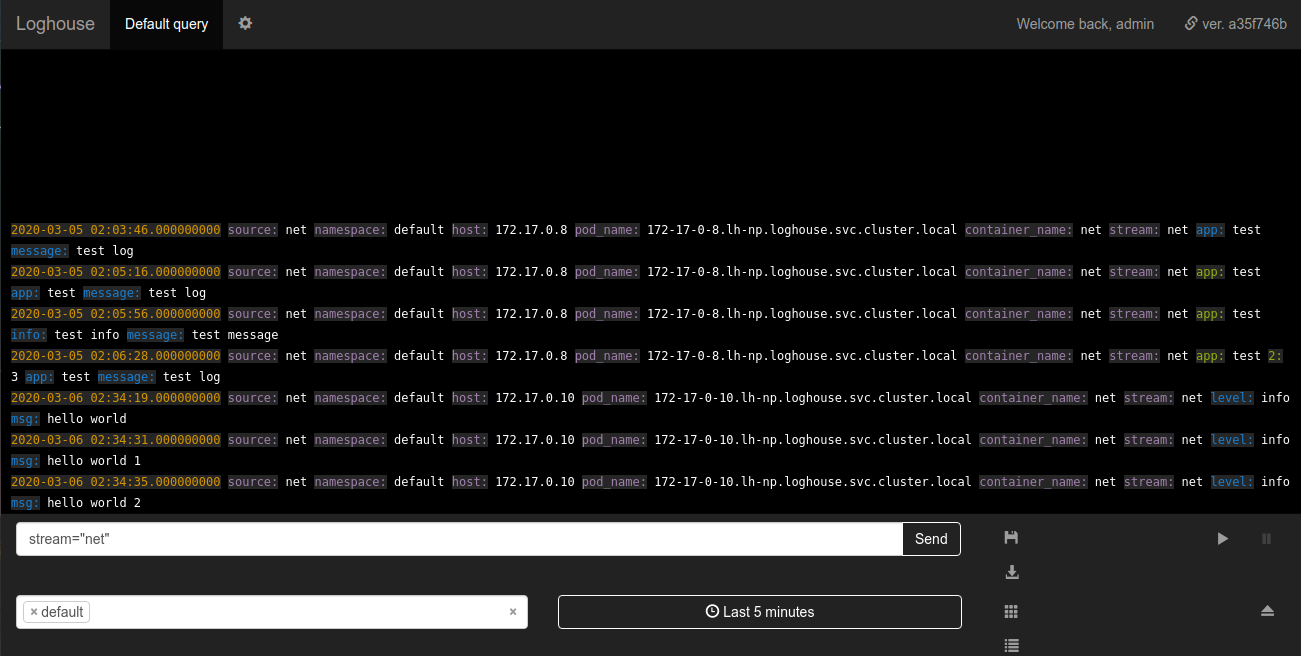 requisitos para que se envíen los datos son mínimos: el mensaje debe ser un JSON válido con un campo
requisitos para que se envíen los datos son mínimos: el mensaje debe ser un JSON válido con un campo log. El campo log, a su vez, puede ser una cadena o un JSON anidado.Subsistema de registro de monitoreo
Una mejora importante fue el monitoreo de fluidos a través de Prometeo. Ahora el loghouse viene con un panel para Grafana, que muestra todas las métricas básicas, como:- cantidad de trabajadores con fluidez;
- cantidad de eventos enviados a ClickHouse;
- tamaño del búfer libre en porcentaje.
El código del panel para Grafana se puede ver en la documentación .El panel de ClickHouse se hizo sobre la base de un producto ya hecho - de f1yegor , para lo cual muchas gracias al autor.Como puede ver, el panel muestra la cantidad de conexiones a ClickHouse, el uso del búfer, la actividad de las tareas en segundo plano y la cantidad de fusiones. Esto es suficiente para comprender el estado del sistema: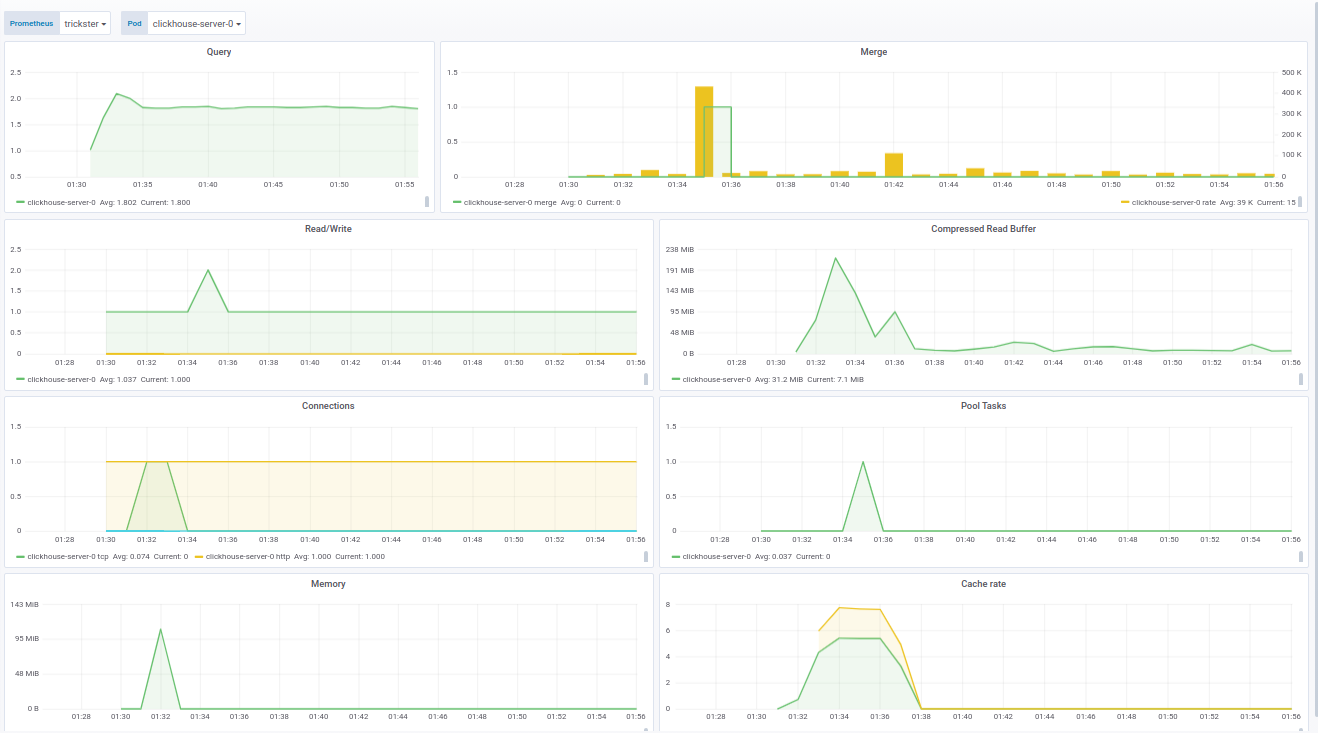 el panel de fluentd muestra las instancias activas de fluentd. Esto es especialmente crítico para aquellos que no quieren / no pueden perder registros:
el panel de fluentd muestra las instancias activas de fluentd. Esto es especialmente crítico para aquellos que no quieren / no pueden perder registros: Además del estado de los pods, el panel muestra la carga en la cola para enviar registros a ClickHouse. A su vez, puede comprender si ClickHouse está manejando la carga o no. En los casos en que no se puede perder el registro, este parámetro también se vuelve crítico.Se agudizan ejemplos de paneles para nuestro suministro de Prometheus Operator, sin embargo, se modifican fácilmente a través de las variables en la configuración.Finalmente, como parte del trabajo de monitoreo de loghouse, reunimos una imagen actual de Docker con clickhouse_exporter 0.1.0 publicado por Percona Labs, ya que el autor del clickhouse_exporter original abandonó su repositorio.
Además del estado de los pods, el panel muestra la carga en la cola para enviar registros a ClickHouse. A su vez, puede comprender si ClickHouse está manejando la carga o no. En los casos en que no se puede perder el registro, este parámetro también se vuelve crítico.Se agudizan ejemplos de paneles para nuestro suministro de Prometheus Operator, sin embargo, se modifican fácilmente a través de las variables en la configuración.Finalmente, como parte del trabajo de monitoreo de loghouse, reunimos una imagen actual de Docker con clickhouse_exporter 0.1.0 publicado por Percona Labs, ya que el autor del clickhouse_exporter original abandonó su repositorio.Planes futuros
- Haga posible implementar un clúster ClickHouse en Kubernetes.
- Trabaje con la selección de registros asíncronos y elimínelos de la parte Ruby del back-end.
- Ruby- , .
- , Go.
- .
Es agradable ver que el proyecto loghouse ha encontrado su audiencia, no solo por haber ganado estrellas en GitHub (600+), sino también alentar a los usuarios reales a hablar sobre sus éxitos y problemas.Habiendo creado loghouse hace más de 2 años, no estábamos seguros de sus perspectivas, esperando que el mercado y / o la comunidad Open Source ofrecieran las mejores soluciones. Sin embargo, hoy vemos que este es un camino viable, que nosotros mismos elegimos y usamos en los muchos grupos de Kubernetes.Esperamos cualquier ayuda para mejorar y desarrollar la casa de troncos. Si le falta algo en la casa de troncos, escriba los comentarios. Además, por supuesto, estaremos encantados de estar activos en GitHub .PD
Lea también en nuestro blog: