Hola Habr! Quiero contarles cómo escribimos e implementamos un servicio para monitorear la calidad de los datos. Tenemos muchas fuentes de datos: datos de los mercados financieros, actividad comercial de nuestros clientes, cotizaciones y mucho más. Todo esto genera miles de millones de registros por día en nuestros procesos. La integridad y consistencia de los datos comerciales es un componente crítico del negocio de Exness.Si está cerca de problemas de garantía de calidad de datos y está interesado en cómo resolvimos este problema en casa, bienvenido a cat. Mi nombre es Dmitry, trabajo en un equipo que almacena datos sin procesar y la transformación, agregación y provisión de todos los datos procesados de la compañía a todos los departamentos de la compañía. Muchos equipos de la empresa consumen nuestros datos, como Business Intelligence, Anti-Fraud, Finance, y también los proporcionamos a nuestros socios de b2b.Trabajar con datos es una misión responsable y difícil, porque detener un proceso ETL puede conducir a la parálisis de parte del negocio de Exness. Para resolver problemas de ETL, utilizamos una variedad de herramientas:
Mi nombre es Dmitry, trabajo en un equipo que almacena datos sin procesar y la transformación, agregación y provisión de todos los datos procesados de la compañía a todos los departamentos de la compañía. Muchos equipos de la empresa consumen nuestros datos, como Business Intelligence, Anti-Fraud, Finance, y también los proporcionamos a nuestros socios de b2b.Trabajar con datos es una misión responsable y difícil, porque detener un proceso ETL puede conducir a la parálisis de parte del negocio de Exness. Para resolver problemas de ETL, utilizamos una variedad de herramientas: desafíos que enfrentamos todos los días:
desafíos que enfrentamos todos los días:- Decenas de millones de registros de transacciones diarias;
- Miles de millones de entradas en el mercado diariamente (cotizaciones, etc.);
- La heterogeneidad de las fuentes de datos (como fuentes externas de Market Data, diferentes plataformas de negociación);
- Proporcionar exactamente una vez la semántica para datos importantes (transacciones financieras);
- Asegurar la integridad e integridad de los datos;
- Brindando garantías de que durante el tiempo estipulado la transacción se agregará a todas las tablas y agregados necesarios.
Para proporcionar tales garantías, era necesario aprender cómo rastrear, medir y responder proactivamente a las desviaciones en la calidad de los datos.Dada la complejidad de nuestros procesos de recopilación y procesamiento de datos, dada la alta velocidad de desarrollo y modificación de los procesos ETL, se hace necesario monitorear la calidad de los datos ya en el punto final. Generalmente tenemos una base de datos Clickhouse o PostgreSQL. Dichas métricas nos dirán qué tan rápido funcionan nuestros procesos:SELECT server,
avg(updated - close_time)
FROM trades
WHERE close_time > subtractHours(Now(), 2)
GROUP BY server
Ayudarán a encontrar duplicados en los datos (no hay restricción única en Clickhouse):SELECT SUM(count) FROM (
SELECT
COUNT(*) AS count
FROM trades
GROUP BY order_id
HAVING count > 1
)
Puede generar una tonelada de consultas (muchas de las cuales ya usamos) que ayudan a controlar la calidad de los datos: comparar el número de filas en la tabla de origen y la tabla de destino, el tiempo de la última inserción en la tabla, comparar el contenido de dos consultas y mucho más.Las métricas son síntomas. Por sí mismos, no indican la causa del problema, pero nos permiten mostrar que hay un problema. Esto será un disparador para que el ingeniero preste atención al problema e identifique la causa raíz. Analogía: si una persona tiene temperatura, entonces algo se ha roto en su cuerpo. La temperatura es un síntoma suficiente para comenzar a comprender y encontrar la causa del colapso.Buscamos una solución preparada que pudiera recopilar tales métricas de síntomas para nosotros. Nuestras necesidades:- Soporte para varias fuentes de datos (bases de datos, colas, solicitudes http);
- ;
- ( , );
- .
Al comienzo del artículo, enumeré las tecnologías que utilizamos en ETL. Como puede ver, ¡somos partidarios de las soluciones de código abierto! Un ejemplo: utilizamos la base de datos Clickhouse orientada a columnas como el almacén de datos principal. Nuestro equipo realizó cambios en el código fuente de Clickhouse varias veces (principalmente corrigiendo errores). Como herramientas para trabajar con métricas y series de tiempo, utilizamos: influxdb del ecosistema, métricas prometheus y victoria, zabbix.Para nuestra sorpresa, resultó que no existe una herramienta conveniente y preparada para monitorear la calidad de los datos que se ajustan a las tecnologías que hemos elegido. ¿O nos veíamos mal?Sí, zabbix tiene la capacidad de ejecutar Scripts personalizados y telegrafPuede enseñar cómo ejecutar consultas SQL y convertir sus resultados en métricas. Pero esto requirió un acabado serio, y no funcionó de la caja de la manera que queríamos. Por lo tanto, escribimos nuestro propio servicio (daemon) para monitorear la calidad de los datos. Conoce a nervio!Características nerviosas
Ideológicamente, el nervio se puede describir con la siguiente frase:Este es un servicio que ejecuta tareas programadas, heterogéneas y personalizadas para recopilar valores numéricos, y presenta los resultados como métricas para diferentes sistemas de recopilación de métricas.
Características clave del programa:- Soporte para diferentes tipos de tareas: Consulta, CompareQueries, etc.
- La capacidad de escribir sus tipos de tareas en Python como un complemento de tiempo de ejecución;
- Trabaja con diferentes tipos de recursos: Clickhouse, Postgres, etc.
- Modelo de métricas de datos, como en prometeo
metric_name{label="value"} 123.3 ;
- pull prometheus;
- : crontab-style;
- WEB UI ;
- yaml ;
- Twelve-Factor App.
Tarea y Recurso son las entidades básicas para configurar y trabajar con nervios. Tarea: una acción periódica escrita, como resultado de la cual obtenemos métricas. Recurso: un objeto que contiene configuración y lógica específica para trabajar con un origen de datos específico. Veamos cómo funciona el nervio con un ejemplo.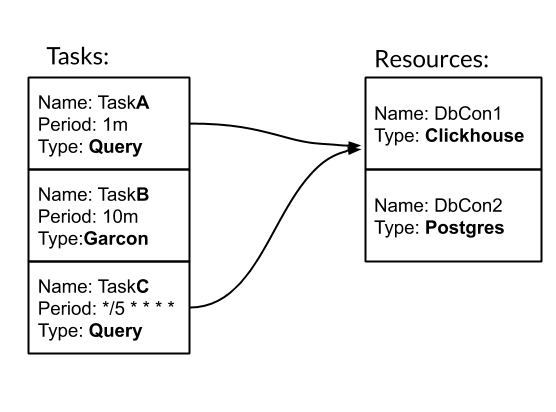 Tenemos tres tareas. Dos de ellos son de tipo Consulta - Consulta SQL. Uno es del tipo Garcon: esta es una tarea personalizada que se destina a uno de nuestros servicios. La frecuencia de la tarea se puede establecer por un período de tiempo. Por ejemplo, 10 m significa una vez cada diez minutos. O estilo crontab "* / 5 * * * *" - cada quinto minuto completo. Las tareas TaskA y TaskC están asociadas con el recurso DbCon1, que es de tipo Clickhouse. Veamos cómo se verá la configuración:
Tenemos tres tareas. Dos de ellos son de tipo Consulta - Consulta SQL. Uno es del tipo Garcon: esta es una tarea personalizada que se destina a uno de nuestros servicios. La frecuencia de la tarea se puede establecer por un período de tiempo. Por ejemplo, 10 m significa una vez cada diez minutos. O estilo crontab "* / 5 * * * *" - cada quinto minuto completo. Las tareas TaskA y TaskC están asociadas con el recurso DbCon1, que es de tipo Clickhouse. Veamos cómo se verá la configuración:tasks:
- name: TaskA
type: Query
resources: DbCon1
period: 1m
config:
query: SELECT COUNT(*) FROM ticks
gauge: metric_count{table="ticks"}
- name: TaskB
type: Garcon
period: 10m
config:
url: "http://hostname:9003/api/v1/orders/backups/"
gauge: backup_ago
- name: TaskC
type: Query
period: "*/5 * * * *"
resources: DbCon1
config:
query: SELECT now() - toDateTime(time_msc/1000)
FROM deals WHERE trade_server= 'Real'
ORDER BY deal DESC LIMIT 1
gauge: orders_lag
resources:
- name: DbCon1
type: Clickhouse
config:
host: clickhouse.env
port: 9000
user: readonly
password: "***"
database: data
results:
common_labels:
env="prod"
task_types_paths:
- "./tasks"
La ruta "./tasks" es la ruta a las tareas personalizadas. En particular, el tipo de tarea Garcon se define allí. En este artículo omitiré el momento de crear mis tipos de tareas.Como resultado del lanzamiento del servicio de nervios con dicha configuración, en la interfaz de usuario web será posible monitorear cómo se realizan las tareas: y las métricas / métricas para la recopilación estarán disponibles:
y las métricas / métricas para la recopilación estarán disponibles: tipo de tarea de consulta más utilizado en nuestro equipo. Por lo tanto, hemos ampliado sus capacidades para trabajar con GROUP BY y plantillas. Estos mecanismos permiten recopilar mucha información sobre los datos con una solicitud a la vez:
tipo de tarea de consulta más utilizado en nuestro equipo. Por lo tanto, hemos ampliado sus capacidades para trabajar con GROUP BY y plantillas. Estos mecanismos permiten recopilar mucha información sobre los datos con una solicitud a la vez: la tarea TradesLag recopilará el retraso máximo para que una orden cerrada ingrese a la tabla de operaciones cada cinco minutos, teniendo en cuenta solo las órdenes cerradas en las últimas dos horas.Algunas palabras sobre la implementación. Nerve es una aplicación Python3 ~ 3k LoC de subprocesos múltiples que es fácil de ejecutar a través de Docker, y la complementa con una configuración de tareas.
la tarea TradesLag recopilará el retraso máximo para que una orden cerrada ingrese a la tabla de operaciones cada cinco minutos, teniendo en cuenta solo las órdenes cerradas en las últimas dos horas.Algunas palabras sobre la implementación. Nerve es una aplicación Python3 ~ 3k LoC de subprocesos múltiples que es fácil de ejecutar a través de Docker, y la complementa con una configuración de tareas.Que pasó
Con nerviosismo, obtuvimos lo que queríamos. Por el momento, además de nuestro equipo, otros equipos en Exness han mostrado interés en él. Hace girar alrededor de 40 tareas con una frecuencia de 30 segundos a un día. Nerve recopila alrededor de 500 métricas sobre nuestros datos. Agregar nuevas métricas es una cuestión de 5-10 minutos. El flujo completo de trabajo con métricas se ve así: nervio → prometeo → Métricas Victoria → Tableros de Grafana → Alertas en PagerDuty.Con nerviosismo, también comenzamos a recopilar métricas comerciales: seleccionamos periódicamente eventos sin procesar en el sistema comercial para evaluar las condiciones comerciales.Gracias, ciudadano de Khabrovsk, por leer mi artículo hasta el final. Preveo su pregunta: ¿dónde está el enlace a github? La respuesta es esta: todavía no hemos publicado nervios en código abierto. Esto requiere un trabajo adicional de nuestra parte para mejorar la documentación y finalizar un par de características. Si este artículo es bien recibido por la comunidad, ¡esto nos dará un incentivo adicional para compartir nuestro desarrollo con usted!Bueno para todos!