El canario es un pequeño pájaro que canta constantemente. Estas aves son sensibles al metano y al monóxido de carbono. Incluso debido a una pequeña concentración de exceso de gases en el aire, pierden el conocimiento o mueren. Los mineros de oro y los mineros tomaron aves como presa: mientras los canarios cantan, puedes trabajar, si te callas, hay gas en la mina y es hora de irse. Los mineros sacrificaron un pequeño pájaro para salir con vida de las minas. Una práctica similar se ha encontrado en TI. Por ejemplo, en la tarea estándar de desplegar una nueva versión de un servicio o aplicación a producción con pruebas antes de eso. El entorno de prueba puede ser demasiado costoso, las pruebas automatizadas no cubren todo lo que nos gustaría y es arriesgado probar y sacrificar la calidad. Solo en tales casos, el enfoque de implementación de Canary ayuda cuando se lanza un poco de tráfico de producción real en una nueva versión. El enfoque ayuda a probar de forma segura la nueva versión para producción, sacrificando cosas pequeñas por un gran propósito. Con más detalle, cómo funciona el enfoque, qué es útil y cómo implementarlo, le dirá a Andrey Markelov (Andrey_V_Markelov), utilizando un ejemplo de implementación en Infobip.Andrey Markelov , un ingeniero de software líder en Infobip, ha estado desarrollando aplicaciones Java en finanzas y telecomunicaciones durante 11 años. Desarrolla productos de código abierto, participa activamente en la comunidad Atlassian y escribe complementos para productos Atlassian. Evangelista Prometeo, Docker y Redis.
Una práctica similar se ha encontrado en TI. Por ejemplo, en la tarea estándar de desplegar una nueva versión de un servicio o aplicación a producción con pruebas antes de eso. El entorno de prueba puede ser demasiado costoso, las pruebas automatizadas no cubren todo lo que nos gustaría y es arriesgado probar y sacrificar la calidad. Solo en tales casos, el enfoque de implementación de Canary ayuda cuando se lanza un poco de tráfico de producción real en una nueva versión. El enfoque ayuda a probar de forma segura la nueva versión para producción, sacrificando cosas pequeñas por un gran propósito. Con más detalle, cómo funciona el enfoque, qué es útil y cómo implementarlo, le dirá a Andrey Markelov (Andrey_V_Markelov), utilizando un ejemplo de implementación en Infobip.Andrey Markelov , un ingeniero de software líder en Infobip, ha estado desarrollando aplicaciones Java en finanzas y telecomunicaciones durante 11 años. Desarrolla productos de código abierto, participa activamente en la comunidad Atlassian y escribe complementos para productos Atlassian. Evangelista Prometeo, Docker y Redis.Sobre Infobip
Esta es una plataforma global de telecomunicaciones que permite a los bancos, minoristas, tiendas en línea y compañías de transporte enviar mensajes a sus clientes mediante SMS, push, cartas y mensajes de voz. En tal negocio, la estabilidad y la confiabilidad son importantes para que los clientes reciban los mensajes a tiempo.Infraestructura de TI de Infobip en números:- 15 centros de datos en todo el mundo;
- 500 servicios únicos en operación;
- 2500 instancias de servicios, que es mucho más que equipos;
- 4,5 TB de tráfico mensual;
- 4.5 billones de números telefónicos;
El negocio está creciendo, y con él el número de lanzamientos. Realizamos 60 lanzamientos al día , porque los clientes quieren más funciones y capacidades. Pero esto es difícil: hay muchos servicios, pero pocos equipos. Debe escribir rápidamente el código que debería funcionar en producción sin errores.Lanzamientos
Un lanzamiento típico con nosotros es así. Por ejemplo, hay servicios A, B, C, D y E, cada uno de ellos está desarrollado por un equipo separado.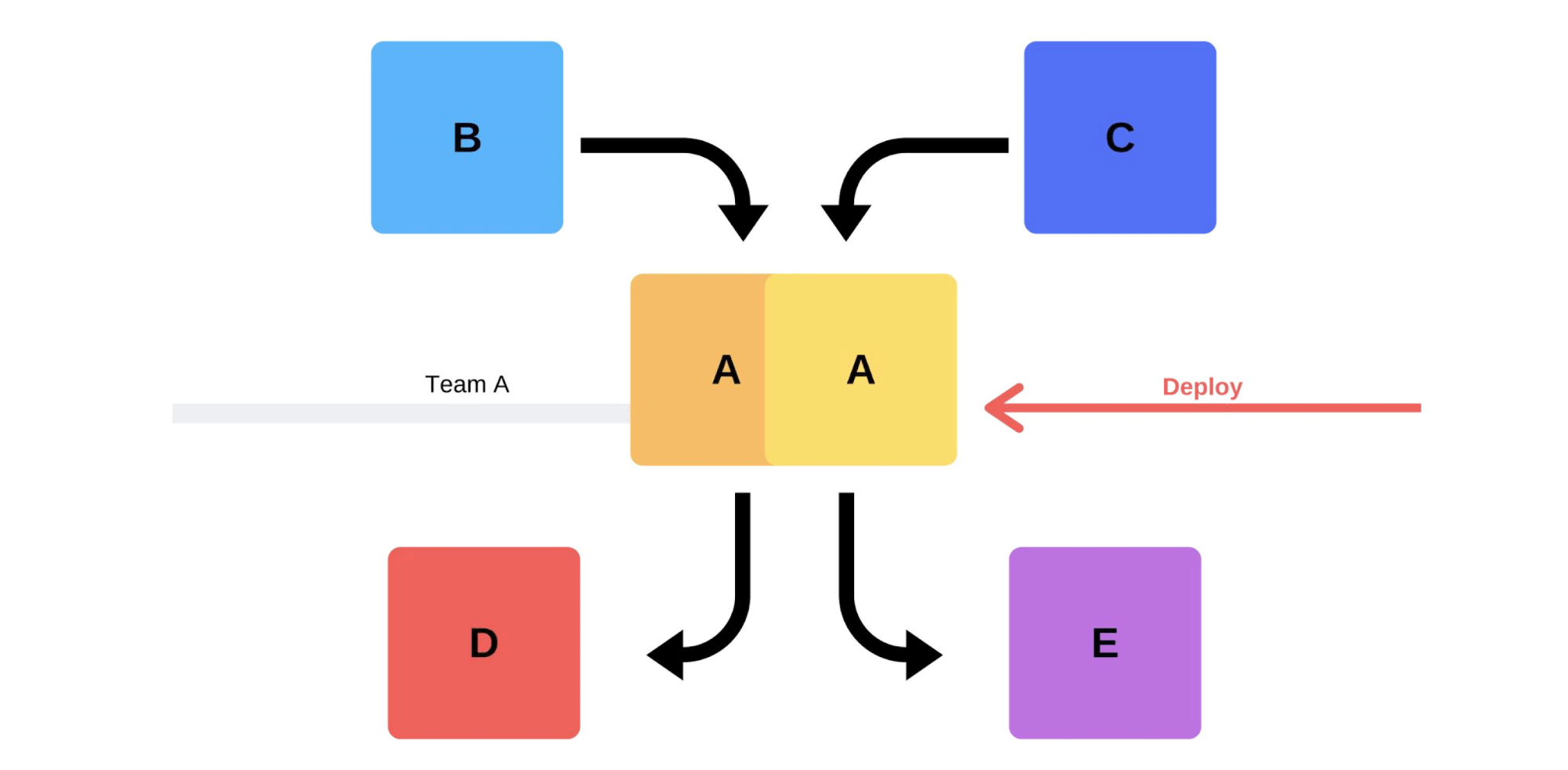 En algún momento, el equipo de servicio A decide implementar una nueva versión, pero los equipos de servicio B, C, D y E no lo saben. Hay dos opciones de cómo llega el equipo de servicio A.Llevará a cabo una versión incremental: primero reemplazará una versión, y luego la segunda.
En algún momento, el equipo de servicio A decide implementar una nueva versión, pero los equipos de servicio B, C, D y E no lo saben. Hay dos opciones de cómo llega el equipo de servicio A.Llevará a cabo una versión incremental: primero reemplazará una versión, y luego la segunda. Pero hay una segunda opción: el equipo encontrará capacidades y máquinas adicionales , implementará una nueva versión y luego cambiará el enrutador, y la versión comenzará a funcionar en la producción.
Pero hay una segunda opción: el equipo encontrará capacidades y máquinas adicionales , implementará una nueva versión y luego cambiará el enrutador, y la versión comenzará a funcionar en la producción. En cualquier caso, casi siempre habrá problemas después de la implementación, incluso si se prueba la versión. Puede probarlo con sus manos, puede automatizarse, no puede probarlo; en cualquier caso, surgirán problemas. La forma más fácil y correcta de resolverlos es volver a la versión de trabajo. Solo entonces puedes lidiar con el daño, con las causas y corregirlas.Entonces, ¿qué queremos?No necesitamos problemas. Si los clientes los encuentran más rápido que nosotros, afectará nuestra reputación. Por lo tanto, debemos encontrar los problemas más rápido que los clientes . Al ser proactivos, minimizamos el daño.Al mismo tiempo, queremos acelerar el desplieguepara que esto suceda rápida, fácilmente, por sí mismo y sin estrés del equipo. Los ingenieros, ingenieros y programadores de DevOps deben estar protegidos: el lanzamiento de la nueva versión es estresante. Un equipo no es un consumible; nos esforzamos por utilizar racionalmente los recursos humanos .
En cualquier caso, casi siempre habrá problemas después de la implementación, incluso si se prueba la versión. Puede probarlo con sus manos, puede automatizarse, no puede probarlo; en cualquier caso, surgirán problemas. La forma más fácil y correcta de resolverlos es volver a la versión de trabajo. Solo entonces puedes lidiar con el daño, con las causas y corregirlas.Entonces, ¿qué queremos?No necesitamos problemas. Si los clientes los encuentran más rápido que nosotros, afectará nuestra reputación. Por lo tanto, debemos encontrar los problemas más rápido que los clientes . Al ser proactivos, minimizamos el daño.Al mismo tiempo, queremos acelerar el desplieguepara que esto suceda rápida, fácilmente, por sí mismo y sin estrés del equipo. Los ingenieros, ingenieros y programadores de DevOps deben estar protegidos: el lanzamiento de la nueva versión es estresante. Un equipo no es un consumible; nos esforzamos por utilizar racionalmente los recursos humanos .Problemas de implementación
El tráfico de clientes es impredecible . Es imposible predecir cuándo el tráfico de clientes será mínimo. No sabemos dónde y cuándo los clientes comenzarán sus campañas, tal vez esta noche en India y mañana en Hong Kong. Dada la gran diferencia horaria, un despliegue incluso a las 2 a.m. no garantiza que los clientes no sufrirán.Problemas de proveedores . Los mensajeros y proveedores son nuestros socios. A veces tienen bloqueos que causan errores durante el despliegue de nuevas versiones.Equipos distribuidos . Los equipos que desarrollan el lado del cliente y el backend están en diferentes zonas horarias. Debido a esto, a menudo no pueden ponerse de acuerdo entre ellos.Los centros de datos no pueden repetirse en el escenario. Hay 200 bastidores en un centro de datos; repetir esto en el sandbox ni siquiera funcionará aproximadamente.¡Los tiempos de inactividad no están permitidos! Tenemos un nivel aceptable de accesibilidad (presupuesto de errores) cuando trabajamos el 99.99% del tiempo, por ejemplo, y los porcentajes restantes son "el derecho a cometer errores". Es imposible alcanzar el 100% de confiabilidad, pero es importante monitorear constantemente el tiempo de inactividad y el tiempo de inactividad.Soluciones clásicas
Escribe código sin errores . Cuando era un desarrollador joven, los gerentes se me acercaron con una solicitud para liberar sin errores, pero esto no siempre es posible.Escribe exámenes . Las pruebas funcionan, pero a veces no es lo que la empresa quiere. Ganar dinero no es una tarea de prueba.Prueba en el escenario . Durante los 3.5 años de mi trabajo en Infobip, nunca he visto un estado en el escenario que coincida, al menos parcialmente, con la producción. Incluso intentamos desarrollar esta idea: primero teníamos una etapa, luego preproducción y luego preproducción preproducción. Pero esto tampoco ayudó, ni siquiera coincidieron en términos de poder. Con Stage podemos garantizar la funcionalidad básica, pero no sabemos cómo funcionará bajo cargas.El lanzamiento es realizado por el desarrollador.Esta es una buena práctica: incluso si alguien cambia el nombre de un comentario, inmediatamente lo agrega a la producción. Esto ayuda a desarrollar la responsabilidad y no olvidarse de los cambios realizados.También hay dificultades adicionales. Para un desarrollador, esto es estresante: dedica mucho tiempo a verificar todo manualmente.Lanzamientos acordados . Esta opción generalmente ofrece administración: "Acordemos que probará y agregará nuevas versiones todos los días". Esto no funciona: siempre hay un equipo que espera a todos los demás o viceversa.
Incluso intentamos desarrollar esta idea: primero teníamos una etapa, luego preproducción y luego preproducción preproducción. Pero esto tampoco ayudó, ni siquiera coincidieron en términos de poder. Con Stage podemos garantizar la funcionalidad básica, pero no sabemos cómo funcionará bajo cargas.El lanzamiento es realizado por el desarrollador.Esta es una buena práctica: incluso si alguien cambia el nombre de un comentario, inmediatamente lo agrega a la producción. Esto ayuda a desarrollar la responsabilidad y no olvidarse de los cambios realizados.También hay dificultades adicionales. Para un desarrollador, esto es estresante: dedica mucho tiempo a verificar todo manualmente.Lanzamientos acordados . Esta opción generalmente ofrece administración: "Acordemos que probará y agregará nuevas versiones todos los días". Esto no funciona: siempre hay un equipo que espera a todos los demás o viceversa.Pruebas de humo
Otra forma de resolver nuestros problemas de implementación. Veamos cómo funcionan las pruebas de humo en el ejemplo anterior, cuando el equipo A quiere implementar una nueva versión.Primero, el equipo despliega una instancia en producción. Los mensajes a la instancia de simulacros simulan el tráfico real para que coincida con el tráfico diario normal. Si todo está bien, el equipo cambia la nueva versión al tráfico de usuarios.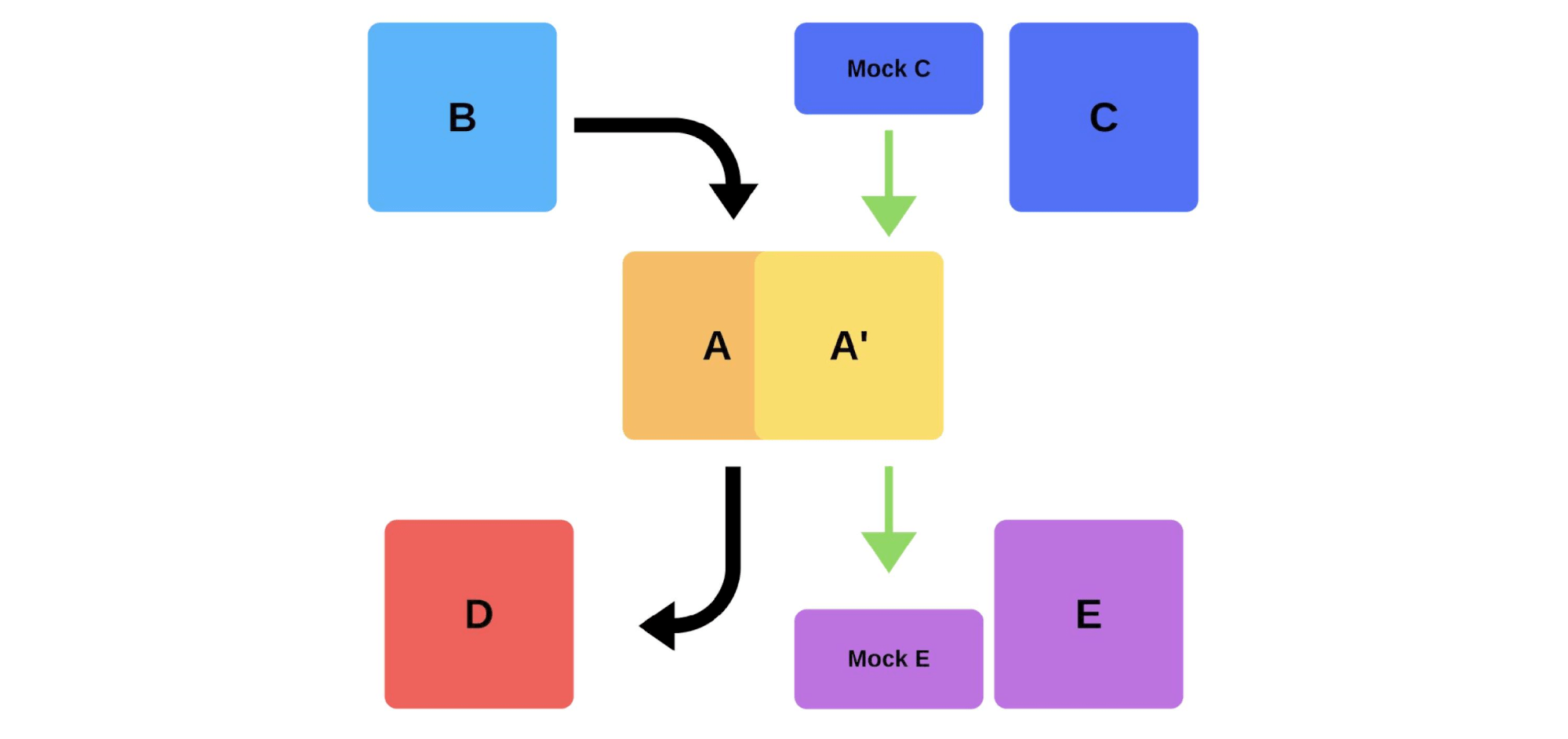 La segunda opción es desplegar con hierro adicional. El equipo lo prueba para producción, luego lo cambia y todo funciona.
La segunda opción es desplegar con hierro adicional. El equipo lo prueba para producción, luego lo cambia y todo funciona. Desventajas de las pruebas de humo:
Desventajas de las pruebas de humo:- No se puede confiar en las pruebas. ¿Dónde obtener el mismo tráfico que para la producción? Puede usar ayer o hace una semana, pero no siempre coincide con el actual.
- Es difícil de mantener. Deberá admitir cuentas de prueba, restablecerlas constantemente antes de cada implementación, cuando los registros activos se envían al repositorio. Esto es más difícil que escribir una prueba en su caja de arena.
La única ventaja aquí es que puede verificar el rendimiento .Lanzamientos canarios
Debido a los defectos de las pruebas de humo, comenzamos a usar lanzamientos de canarios.Una práctica similar a la forma en que los mineros usaban canarios para indicar que los niveles de gas se encontraban en TI. Estamos lanzando un poco de tráfico de producción real a la nueva versión , mientras tratamos de cumplir con el Acuerdo de Nivel de Servicio (SLA). SLA es nuestro "derecho a cometer errores", que podemos usar una vez al año (o por algún otro período de tiempo). Si todo va bien, agregue más tráfico. Si no, devolveremos las versiones anteriores.
Implementación y matices
¿Cómo implementamos los lanzamientos canarios? Por ejemplo, un grupo de clientes envía mensajes a través de nuestro servicio.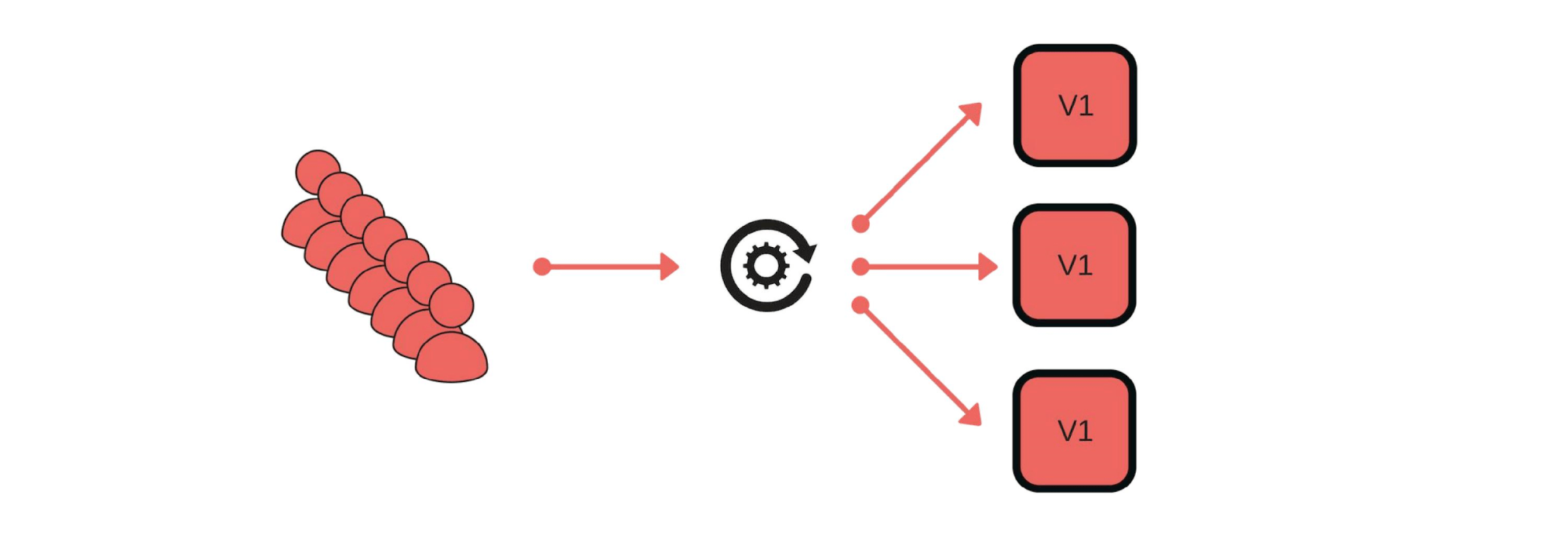 El despliegue es así: elimine un nodo debajo del equilibrador (1), cambie la versión (2) e inicie por separado algo de tráfico (3).
El despliegue es así: elimine un nodo debajo del equilibrador (1), cambie la versión (2) e inicie por separado algo de tráfico (3). En general, todos en el grupo estarán contentos, incluso si un usuario no está contento. Si todo está bien, cambie todas las versiones.
En general, todos en el grupo estarán contentos, incluso si un usuario no está contento. Si todo está bien, cambie todas las versiones. Mostraré esquemáticamente cómo se ven los microservicios en la mayoría de los casos.Hay Service Discovery y dos servicios más: S1N1 y S2. El primer servicio (S1N1) notifica a Service Discovery cuando se inicia, y Service Discovery lo recuerda. El segundo servicio con dos nodos (S2N1 y S2N2) también notifica a Service Discovery al inicio.
Mostraré esquemáticamente cómo se ven los microservicios en la mayoría de los casos.Hay Service Discovery y dos servicios más: S1N1 y S2. El primer servicio (S1N1) notifica a Service Discovery cuando se inicia, y Service Discovery lo recuerda. El segundo servicio con dos nodos (S2N1 y S2N2) también notifica a Service Discovery al inicio.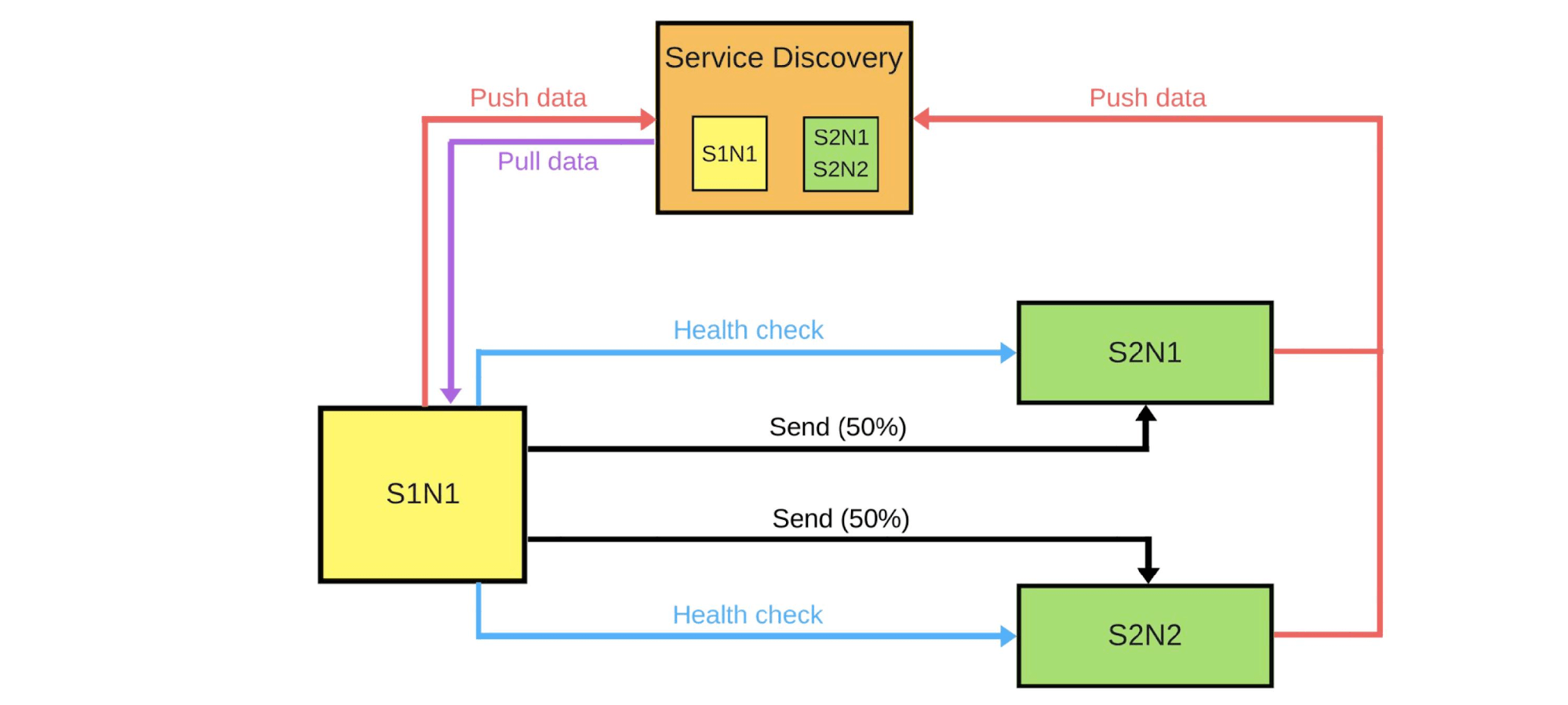 El segundo servicio para el primero funciona como servidor. El primero solicita información sobre sus servidores de Service Discovery y, cuando la recibe, los busca y los verifica ("comprobación de estado"). Cuando verifique, les enviará mensajes.Cuando alguien quiere implementar una nueva versión del segundo servicio, le dice a Service Discovery que el segundo nodo será un nodo canario: se le enviará menos tráfico, ya que se implementará ahora. Eliminamos el nodo canario de debajo del equilibrador y el primer servicio no le envía tráfico.
El segundo servicio para el primero funciona como servidor. El primero solicita información sobre sus servidores de Service Discovery y, cuando la recibe, los busca y los verifica ("comprobación de estado"). Cuando verifique, les enviará mensajes.Cuando alguien quiere implementar una nueva versión del segundo servicio, le dice a Service Discovery que el segundo nodo será un nodo canario: se le enviará menos tráfico, ya que se implementará ahora. Eliminamos el nodo canario de debajo del equilibrador y el primer servicio no le envía tráfico.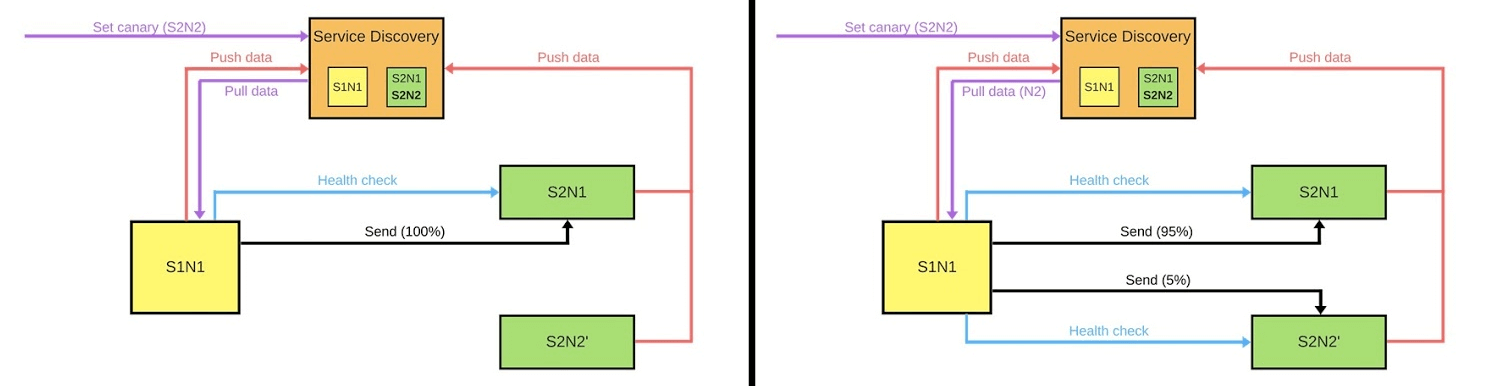 Cambiamos la versión y Service Discovery sabe que el segundo nodo ahora es canario; puede darle menos carga (5%). Si todo está bien, cambie la versión, devuelva la carga y continúe.Para implementar todo esto, necesitamos:
Cambiamos la versión y Service Discovery sabe que el segundo nodo ahora es canario; puede darle menos carga (5%). Si todo está bien, cambie la versión, devuelva la carga y continúe.Para implementar todo esto, necesitamos:- equilibrio
- , , , ;
- , , ;
- — (deployment pipeline).
 Esto es lo primero en lo que debemos pensar. Hay dos estrategias de equilibrio.La opción más simple es cuando un nodo siempre es canario . Este nodo siempre recibe menos tráfico y comenzamos a implementarlo. En caso de problemas, compararemos su trabajo con el despliegue y durante el mismo. Por ejemplo, si hay 2 veces más errores, entonces el daño ha aumentado 2 veces.El nodo Canario se establece durante el proceso de implementación . Cuando finalice la implementación y eliminemos el estado del nodo canario, se restablecerá el equilibrio del tráfico. Con menos autos, obtenemos una distribución honesta.
Esto es lo primero en lo que debemos pensar. Hay dos estrategias de equilibrio.La opción más simple es cuando un nodo siempre es canario . Este nodo siempre recibe menos tráfico y comenzamos a implementarlo. En caso de problemas, compararemos su trabajo con el despliegue y durante el mismo. Por ejemplo, si hay 2 veces más errores, entonces el daño ha aumentado 2 veces.El nodo Canario se establece durante el proceso de implementación . Cuando finalice la implementación y eliminemos el estado del nodo canario, se restablecerá el equilibrio del tráfico. Con menos autos, obtenemos una distribución honesta.Supervisión
La piedra angular de los lanzamientos canarios. Debemos entender exactamente por qué estamos haciendo esto y qué métricas queremos recopilar.Ejemplos de métricas que recopilamos de nuestros servicios.- , . , . , .
- (latency). , .
- (throughput).
- .
- 95% .
- -: . , , .
Ejemplos de métricas en los sistemas de monitoreo más populares.Mostrador Este es un valor creciente, por ejemplo, el número de errores. Es fácil interpolar esta métrica y estudiar el gráfico: ayer hubo 2 errores y hoy 500, entonces algo salió mal.El número de errores por minuto o por segundo es el indicador más importante que se puede calcular con Counter. Estos datos dan una idea clara del funcionamiento del sistema a distancia. Veamos un ejemplo de un gráfico del número de errores por segundo para dos versiones de un sistema de producción. Hubo pocos errores en la primera versión; la auditoría puede no haber funcionado. En la segunda versión, todo es mucho peor. Podemos decir con certeza que hay problemas, por lo que debemos revertir esta versión.Calibre.Las métricas son similares a Counter, pero registramos valores que pueden aumentar o disminuir. Por ejemplo, el tiempo de ejecución de la consulta o el tamaño de la cola.El gráfico muestra un ejemplo de tiempo de respuesta (latencia). El gráfico muestra que las versiones son similares, puede trabajar con ellas. Pero si nos fijamos bien, se nota cómo cambia la cantidad. Si el tiempo de ejecución de las solicitudes aumenta cuando se agregan usuarios, entonces está claro de inmediato que hay problemas; este no era el caso antes.
Hubo pocos errores en la primera versión; la auditoría puede no haber funcionado. En la segunda versión, todo es mucho peor. Podemos decir con certeza que hay problemas, por lo que debemos revertir esta versión.Calibre.Las métricas son similares a Counter, pero registramos valores que pueden aumentar o disminuir. Por ejemplo, el tiempo de ejecución de la consulta o el tamaño de la cola.El gráfico muestra un ejemplo de tiempo de respuesta (latencia). El gráfico muestra que las versiones son similares, puede trabajar con ellas. Pero si nos fijamos bien, se nota cómo cambia la cantidad. Si el tiempo de ejecución de las solicitudes aumenta cuando se agregan usuarios, entonces está claro de inmediato que hay problemas; este no era el caso antes. Resumen Uno de los indicadores más importantes para las empresas son los percentiles. La métrica muestra que en el 95% de los casos, nuestro sistema funciona de la manera que queremos. Podemos llegar a un acuerdo si hay problemas en alguna parte, porque entendemos la tendencia general de cuán bueno o malo es todo.
Resumen Uno de los indicadores más importantes para las empresas son los percentiles. La métrica muestra que en el 95% de los casos, nuestro sistema funciona de la manera que queremos. Podemos llegar a un acuerdo si hay problemas en alguna parte, porque entendemos la tendencia general de cuán bueno o malo es todo.Herramientas
ELK Stack . Puede implementar canary usando Elasticsearch: escribimos errores en él cuando ocurren eventos. Basta con llamar a la API, puede obtener errores en cualquier momento, y compararlo con los segmentos anteriores: GET /applg/_cunt?q=level:errr.Prometeo. Se mostró bien en Infobip. Le permite implementar métricas multidimensionales porque se utilizan etiquetas.Podemos utilizar level, instance, service, para combinarlos en un solo sistema. Al offsetusarlo, puede ver, por ejemplo, el valor de hace una semana con un solo comando GET /api/v1/query?query={query}, donde {query}:rate(logback_appender_total{
level="error",
instance=~"$instance"
}[5m] offset $offset_value)
Análisis de versiones
Hay varias estrategias de versiones.Ver métricas de solo nodos canarios. Una de las opciones más simples: desplegar una nueva versión y estudiar solo el trabajo. Pero si el ingeniero en este momento comienza a estudiar los registros, recargando constantemente las páginas nerviosamente, entonces esta solución no es diferente del resto.Un nodo canario se compara con cualquier otro nodo . Esta es una comparación con otras instancias que se ejecutan en tráfico completo. Por ejemplo, si con poco tráfico las cosas son peores, o no mejores que en casos reales, entonces algo está mal.Un nodo canario se compara con sí mismo en el pasado. Los nodos asignados para canario se pueden comparar con datos históricos. Por ejemplo, si hace una semana todo estaba bien, entonces podemos centrarnos en estos datos para comprender la situación actual.Automatización
Queremos liberar a los ingenieros de las comparaciones manuales, por lo que es importante implementar la automatización. El proceso de canalización de implementación generalmente se ve así:- empezamos;
- eliminar el nodo debajo del equilibrador;
- establecer el nodo canario;
- encienda el equilibrador con una cantidad limitada de tráfico;
- comparar.
 En este punto, implementamos una comparación automática . Cómo puede verse y por qué es mejor que verificar después de la implementación, consideraremos el ejemplo de Jenkins.Esta es la tubería a Groovy.
En este punto, implementamos una comparación automática . Cómo puede verse y por qué es mejor que verificar después de la implementación, consideraremos el ejemplo de Jenkins.Esta es la tubería a Groovy.while (System.currentTimeMillis() < endCanaryTs) {
def isOk = compare(srv, canary, time, base, offset, metrics)
if (isOk) {
sleep DEFAULT SLEEP
} else {
echo "Canary failed, need to revert"
return false
}
}
Aquí en el ciclo establecemos que compararemos el nuevo nodo durante una hora. Si el proceso canario aún no ha finalizado el proceso, llamamos a la función. Ella informa que todo está bien o no: def isOk = compare(srv, canary, time, base, offset, metrics).Si todo está bien, sleep DEFAULT SLEEPpor ejemplo, por un segundo, y continúe. Si no, salimos, el despliegue falló.Descripción de la métrica. Veamos cómo podría verse una función compareen el ejemplo de DSL.metric(
'errorCounts',
'rate(errorCounts{node=~"$canaryInst"}[5m] offset $offset)',
{ baseValue, canaryValue ->
if (canaryValue > baseValue * 1.3) return false
return true
}
)
Supongamos que comparamos la cantidad de errores y queremos saber la cantidad de errores por segundo en los últimos 5 minutos.Tenemos dos valores: base y nodos canarios. El valor del nodo canario es el actual. Básico: baseValuees el valor de cualquier otro nodo no canario. Comparamos los valores entre sí de acuerdo con la fórmula, que establecemos en función de nuestra experiencia y observaciones. Si el valor es canaryValuemalo, la implementación falló y retrocedemos.¿Por qué es todo esto necesario?El hombre no puede verificar cientos y miles de métricasespecialmente para hacerlo rápido. Una comparación automática ayuda a verificar todas las métricas y lo alerta rápidamente de problemas. El tiempo de notificación es crítico: si algo sucedió en los últimos 2 segundos, entonces el daño no será tan grande como si hubiera sucedido hace 15 minutos. Hasta que alguien note un problema, escriba soporte, y podemos perder clientes para revertir el soporte.Si el proceso fue bien y todo está bien, implementaremos todos los demás nodos automáticamente. Los ingenieros no están haciendo nada en este momento. Solo cuando ejecutan Canary deciden qué métricas tomar, cuánto tiempo hacer la comparación, qué estrategia usar. Si hay problemas, revertimos automáticamente el nodo canario, trabajamos en versiones anteriores y corregimos los errores que encontramos. Por métricas, son fáciles de encontrar y ver el daño de la nueva versión.
Si hay problemas, revertimos automáticamente el nodo canario, trabajamos en versiones anteriores y corregimos los errores que encontramos. Por métricas, son fáciles de encontrar y ver el daño de la nueva versión.Los obstáculos
Implementar esto, por supuesto, no es fácil. En primer lugar, necesitamos un sistema de monitoreo común . Los ingenieros tienen sus propias métricas, el soporte y los analistas tienen diferentes, y las empresas tienen terceros. Un sistema común es un lenguaje común hablado por los negocios y el desarrollo.Es necesario verificar en la práctica la estabilidad de las métricas. La verificación ayuda a comprender cuál es el conjunto mínimo de métricas necesarias para garantizar la calidad .¿Cómo lograr esto? Utilice el servicio canario no en el momento de la implementación . Agregamos un cierto servicio en la versión anterior, que en cualquier momento podrá tomar cualquier nodo asignado, reducir el tráfico sin implementación. Después de comparar: estudiamos los errores y buscamos esa línea cuando logramos calidad.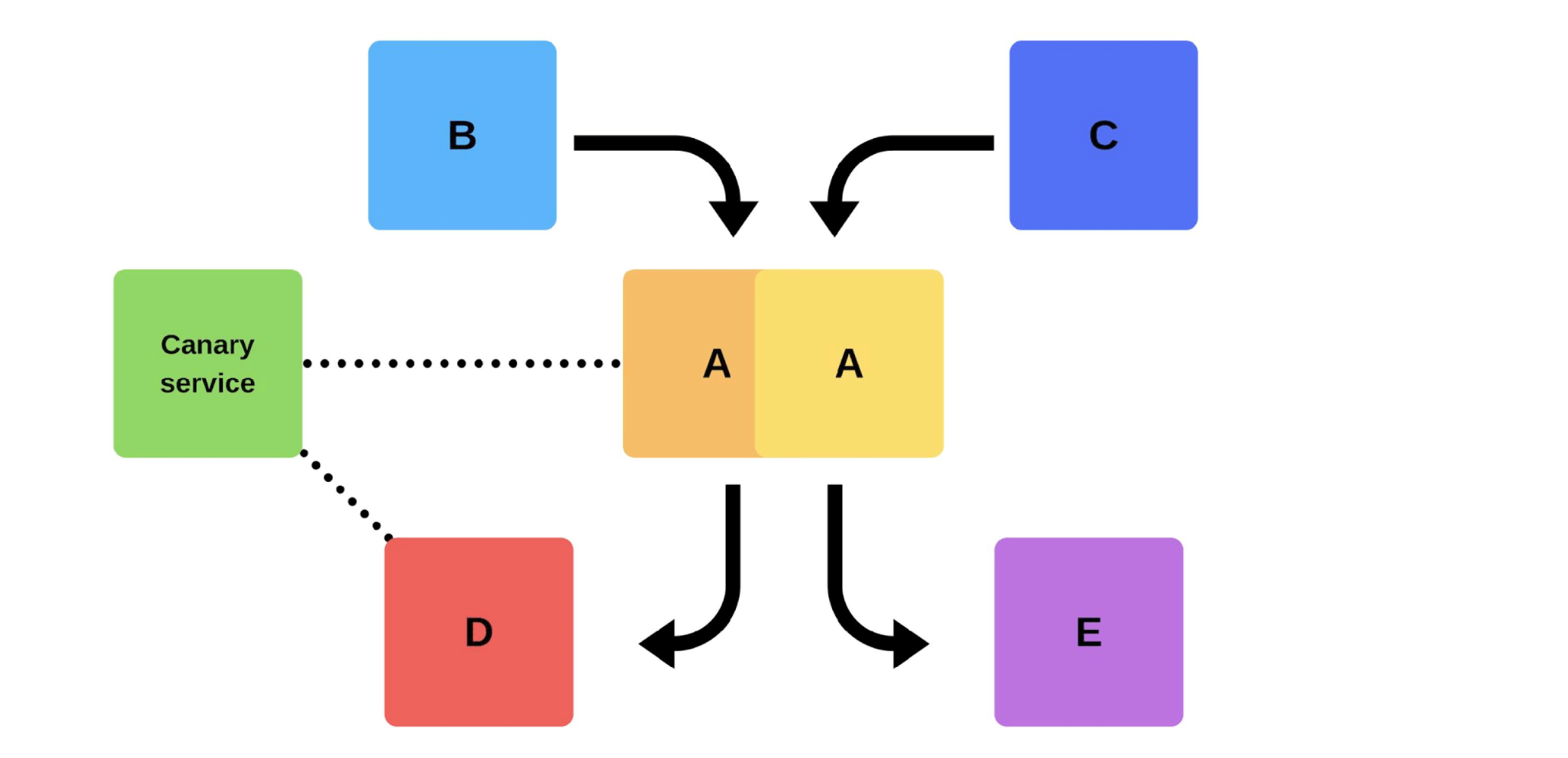
¿Qué beneficio tenemos de las liberaciones canarias?
Minimizó el porcentaje de daño por errores. La mayoría de los errores de implementación ocurren debido a inconsistencias en algunos datos o prioridades. Tales errores se han vuelto mucho más pequeños, porque podemos resolver el problema en los primeros segundos.Optimizado el trabajo de los equipos. Los principiantes tienen el "derecho a cometer un error": pueden desplegarse en la producción sin temor a errores, aparece una iniciativa adicional, un incentivo para trabajar. Si rompen algo, entonces no será crítico y la persona equivocada no será despedida.Despliegue automatizado . Esto ya no es un proceso manual, como antes, sino un proceso automatizado real. Pero lleva más tiempo.Métricas importantes destacadas. Toda la empresa, comenzando por las empresas y los ingenieros, comprende lo que es realmente importante en nuestro producto, qué métricas, por ejemplo, la salida y la afluencia de usuarios. Controlamos el proceso: probamos las métricas, presentamos nuevas, vemos cómo funcionan las antiguas para construir un sistema que hará que el dinero sea más productivo.Tenemos muchas prácticas y sistemas geniales que nos ayudan. A pesar de esto, nos esforzamos por ser profesionales y hacer nuestro trabajo de manera eficiente, independientemente de si tenemos un sistema que nos ayudará o no.— TechLead Conf. , , — .
TechLead Conf 8 9 . , , — , .