Cientos, miles y, en algunos servicios, millones de colas, a través de las cuales pasa una gran cantidad de datos, giran bajo el capó de nuestro producto. Todo esto debe ser procesado de alguna manera mágica y no ser fusilado. En esta publicación, le diré qué enfoques arquitectónicos usamos en casa, teniendo una pila de tecnología bastante modesta y no teniendo un pequeño centro de datos en nuestra "despensa".
¿Que tenemos?
Entonces, por un lado, tenemos una pila de tecnología bien conocida: Nginx, PHP, PostgreSQL, Redis. Por otro lado, decenas de miles de eventos ocurren en nuestro sistema cada minuto, y en el pico puede alcanzar cientos de miles de eventos. Para dejar en claro cuáles son estos eventos y cómo debemos responder a ellos, haré una pequeña digresión del producto, después de lo cual le contaré cómo desarrollamos el sistema de automatización basado en eventos.ManyChat es una plataforma para la automatización del marketing. El propietario de la página de Facebook puede conectarla a nuestra plataforma y configurar la automatización de la interacción con sus suscriptores (en otras palabras, crear un bot de chat). La automatización generalmente consta de muchas cadenas de interacciones que pueden no estar interconectadas. Dentro de estas cadenas de automatización, ciertas acciones pueden ocurrir con el suscriptor, por ejemplo, asignar una etiqueta específica en el sistema o asignar / cambiar el valor de un campo en la tarjeta de un suscriptor. Estos datos además le permiten segmentar la audiencia y crear una interacción más relevante con los suscriptores de la página.Nuestros clientes realmente querían la automatización basada en eventos: la capacidad de personalizar la ejecución de una acción cuando se desencadena un evento específico dentro del suscriptor (por ejemplo, etiquetado).Dado que un evento desencadenante puede funcionar desde diferentes cadenas de automatización, es importante que haya un único punto de configuración para todas las acciones basadas en eventos en el lado del cliente, y en nuestro lado de procesamiento debe haber un solo bus que procese el cambio en el contexto del suscriptor desde diferentes puntos de automatización.En nuestro sistema, hay un bus común a través del cual pasan todos los eventos que ocurren con los suscriptores. Esto es más de 500 millones de eventos por día. Su procesamiento es bastante delicado: este es un registro en el almacén de datos, por lo que el propietario de la página tiene la oportunidad de ver históricamente todo lo que sucedió a sus suscriptores.Parece que para implementar un sistema basado en eventos ya tenemos todo, y es suficiente para nosotros integrar nuestra lógica de negocios en el procesamiento de un bus de eventos común. Pero tenemos ciertos requisitos para nuestro nuevo sistema:- No queremos que el rendimiento disminuya al procesar el bus de eventos principal
- Es importante para nosotros mantener el orden de procesamiento de mensajes en el nuevo sistema, ya que esto puede estar vinculado a la lógica de negocios del cliente que configura la automatización
- Evite el efecto de vecinos ruidosos cuando las páginas activas con un gran número de suscriptores obstruyen la cola y bloquean el procesamiento de eventos de páginas "pequeñas"
Si integramos el procesamiento de nuestra lógica en el procesamiento de un bus de eventos común, obtendremos una degradación grave en el rendimiento, ya que tendremos que verificar que cada evento cumpla con la automatización configurada. Como parte de la configuración de la automatización, se pueden aplicar ciertos filtros (por ejemplo, iniciar la automatización cuando se activa un evento solo para clientes mayores de 30 años). Es decir, al procesar eventos en el bus principal, se procesará una gran cantidad de solicitudes adicionales a la base de datos, y también una lógica bastante pesada comenzará a comparar el contexto actual del suscriptor con la configuración de automatización. Esta opción no nos conviene, así que fuimos a pensar más.
Organización de una cascada de colas.
Dado que nuestra lógica de negocios asociada con el sistema basado en eventos se puede separar muy bien de la lógica para procesar eventos desde el bus principal, decidimos colocar los tipos de eventos que necesitamos del bus compartido en una cola separada para su posterior procesamiento en un flujo de datos separado. Por lo tanto, eliminamos el problema asociado con la degradación del rendimiento en el procesamiento del bus de eventos principal.En la misma etapa, decidimos qué sería genial transferir eventos a la siguiente cola en cascada para colocar estos eventos en colas separadas para cada bot. Por lo tanto, aislar la actividad de cada bot con el marco de su turno, lo que nos permite resolver el problema asociado con el efecto de vecinos ruidosos.Nuestro diagrama de flujo de datos ahora se ve así: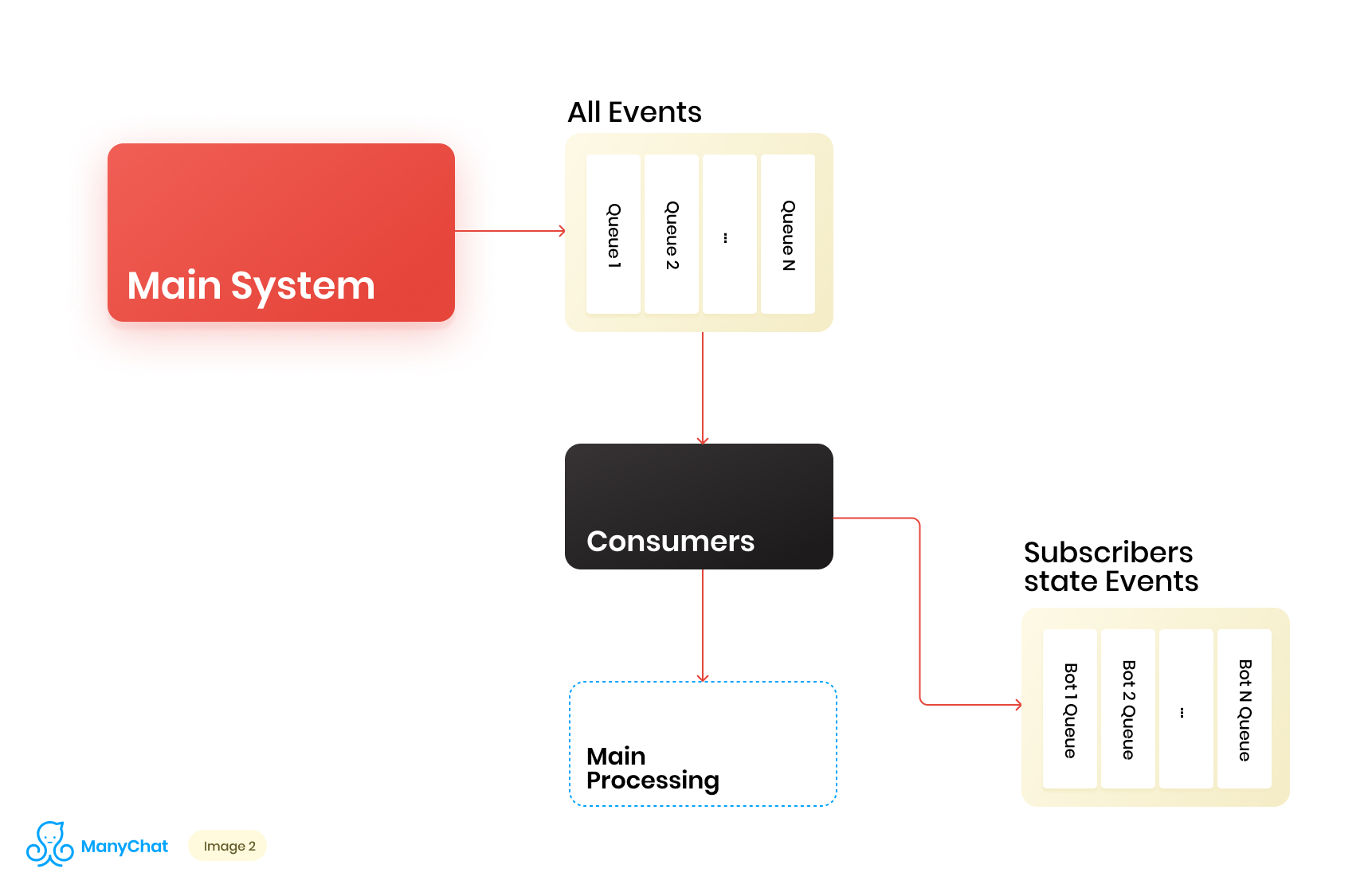 Sin embargo, para que este esquema funcione, debemos resolver el problema del procesamiento de nuevas colas.Hay más de 1 millón de páginas conectadas (bots) en nuestra plataforma, lo que significa que potencialmente podemos obtener ~ 1 millón de colas en nuestro esquema, solo al nivel de la capa basada en eventos. Desde un punto de vista técnico, esto no nos da miedo. Como servidor de colas, utilizamos Redis con sus tipos de datos estándar, como LIST, SORTED SET y otros. Esto significa que cada cola es la estructura de datos estándar para Redis en RAM, que se puede crear o eliminar sobre la marcha, lo que nos permite operar de manera fácil y flexible una gran cantidad de colas en nuestro sistema. Voy a hablar más profundamente sobre el uso de Redis como un servidor de cola con detalles técnicos en una publicación separada, pero por ahora volvamos a nuestra arquitectura.Está claro que cada bot tiene una actividad diferente, y que la probabilidad de obtener 1 millón de colas en el estado "necesita procesar ahora" es extremadamente pequeña. Pero en un momento dado, es muy posible que tengamos un par de decenas de miles de colas activas que requieren procesamiento. El número de estas colas cambia constantemente. Estas colas también cambian, algunas se restan por completo y se eliminan, otras se crean dinámicamente y se llenan de eventos para su procesamiento. En consecuencia, debemos encontrar una forma efectiva de manejarlos.
Sin embargo, para que este esquema funcione, debemos resolver el problema del procesamiento de nuevas colas.Hay más de 1 millón de páginas conectadas (bots) en nuestra plataforma, lo que significa que potencialmente podemos obtener ~ 1 millón de colas en nuestro esquema, solo al nivel de la capa basada en eventos. Desde un punto de vista técnico, esto no nos da miedo. Como servidor de colas, utilizamos Redis con sus tipos de datos estándar, como LIST, SORTED SET y otros. Esto significa que cada cola es la estructura de datos estándar para Redis en RAM, que se puede crear o eliminar sobre la marcha, lo que nos permite operar de manera fácil y flexible una gran cantidad de colas en nuestro sistema. Voy a hablar más profundamente sobre el uso de Redis como un servidor de cola con detalles técnicos en una publicación separada, pero por ahora volvamos a nuestra arquitectura.Está claro que cada bot tiene una actividad diferente, y que la probabilidad de obtener 1 millón de colas en el estado "necesita procesar ahora" es extremadamente pequeña. Pero en un momento dado, es muy posible que tengamos un par de decenas de miles de colas activas que requieren procesamiento. El número de estas colas cambia constantemente. Estas colas también cambian, algunas se restan por completo y se eliminan, otras se crean dinámicamente y se llenan de eventos para su procesamiento. En consecuencia, debemos encontrar una forma efectiva de manejarlos.Procesando un gran grupo de colas
Entonces tenemos un montón de colas. En cada momento, puede haber una cantidad aleatoria. Una condición importante para procesar cada cola, que se mencionó al principio de su publicación, es que los eventos dentro de cada página deben procesarse estrictamente secuencialmente. Esto significa que en un momento dado, cada cola no puede ser procesada por más de un trabajador para evitar problemas competitivos.Pero hacer que la proporción de colas a manejadores 1: 1 sea una tarea dudosa. El número de colas cambia constantemente, tanto hacia arriba como hacia abajo. El número de controladores en ejecución tampoco es infinito, al menos tenemos una limitación por parte del sistema operativo y el hardware, y no queremos que los trabajadores permanezcan inactivos en colas vacías. Para resolver el problema de la interacción entre manejadores y colas, implementamos un sistema round robin para procesar nuestro grupo de colas.Y aquí la línea de control vino en nuestra ayuda. Cuando el evento se reenvía desde el bus compartido a la cola basada en eventos de un bot en particular, también colocamos el identificador de esta cola de bot en la cola de control. La cola de control almacena solo los identificadores de las colas que se encuentran en el grupo y que deben procesarse. Solo se almacenan valores únicos en la cola de control, es decir, el mismo identificador de cola de bot se almacenará en la cola de control solo una vez, independientemente de cuántas veces se escriba allí. En Redis, esto se implementa utilizando la estructura de datos SORTED SET.Además, podemos distinguir un cierto número de trabajadores, cada uno de los cuales recibirá de la cola de control su identificador de la cola de bot para su procesamiento. Por lo tanto, cada trabajador procesará independientemente el fragmento de la cola que se le asignó, después de procesar el fragmento, devolverá el identificador de la cola procesada al control, devolviéndolo así a nuestro round robin. Lo principal es no olvidar proporcionar bloqueos a todo, de modo que dos trabajadores no puedan procesar la misma cola de bot en paralelo. Esta situación es posible si el identificador de bot ingresa a la cola de control cuando el trabajador ya lo está procesando. Para las cerraduras, también utilizamos Redis como clave: almacén de valores con TTL.Cuando tomamos una tarea con un identificador de cola de bot de la cola de control, colocamos un bloqueo TTL en la cola tomada y comenzamos a procesarla. Si el otro consumidor toma la tarea con la cola que ya se está procesando desde la cola de control, no podrá establecer el bloqueo, devolver la tarea a la cola de control y recibir la siguiente tarea. Después de que el consumidor procesa la cola del bot, él elimina el bloqueo y pasa a la cola de control para la siguiente tarea.El esquema final es el siguiente:
Cuando el evento se reenvía desde el bus compartido a la cola basada en eventos de un bot en particular, también colocamos el identificador de esta cola de bot en la cola de control. La cola de control almacena solo los identificadores de las colas que se encuentran en el grupo y que deben procesarse. Solo se almacenan valores únicos en la cola de control, es decir, el mismo identificador de cola de bot se almacenará en la cola de control solo una vez, independientemente de cuántas veces se escriba allí. En Redis, esto se implementa utilizando la estructura de datos SORTED SET.Además, podemos distinguir un cierto número de trabajadores, cada uno de los cuales recibirá de la cola de control su identificador de la cola de bot para su procesamiento. Por lo tanto, cada trabajador procesará independientemente el fragmento de la cola que se le asignó, después de procesar el fragmento, devolverá el identificador de la cola procesada al control, devolviéndolo así a nuestro round robin. Lo principal es no olvidar proporcionar bloqueos a todo, de modo que dos trabajadores no puedan procesar la misma cola de bot en paralelo. Esta situación es posible si el identificador de bot ingresa a la cola de control cuando el trabajador ya lo está procesando. Para las cerraduras, también utilizamos Redis como clave: almacén de valores con TTL.Cuando tomamos una tarea con un identificador de cola de bot de la cola de control, colocamos un bloqueo TTL en la cola tomada y comenzamos a procesarla. Si el otro consumidor toma la tarea con la cola que ya se está procesando desde la cola de control, no podrá establecer el bloqueo, devolver la tarea a la cola de control y recibir la siguiente tarea. Después de que el consumidor procesa la cola del bot, él elimina el bloqueo y pasa a la cola de control para la siguiente tarea.El esquema final es el siguiente: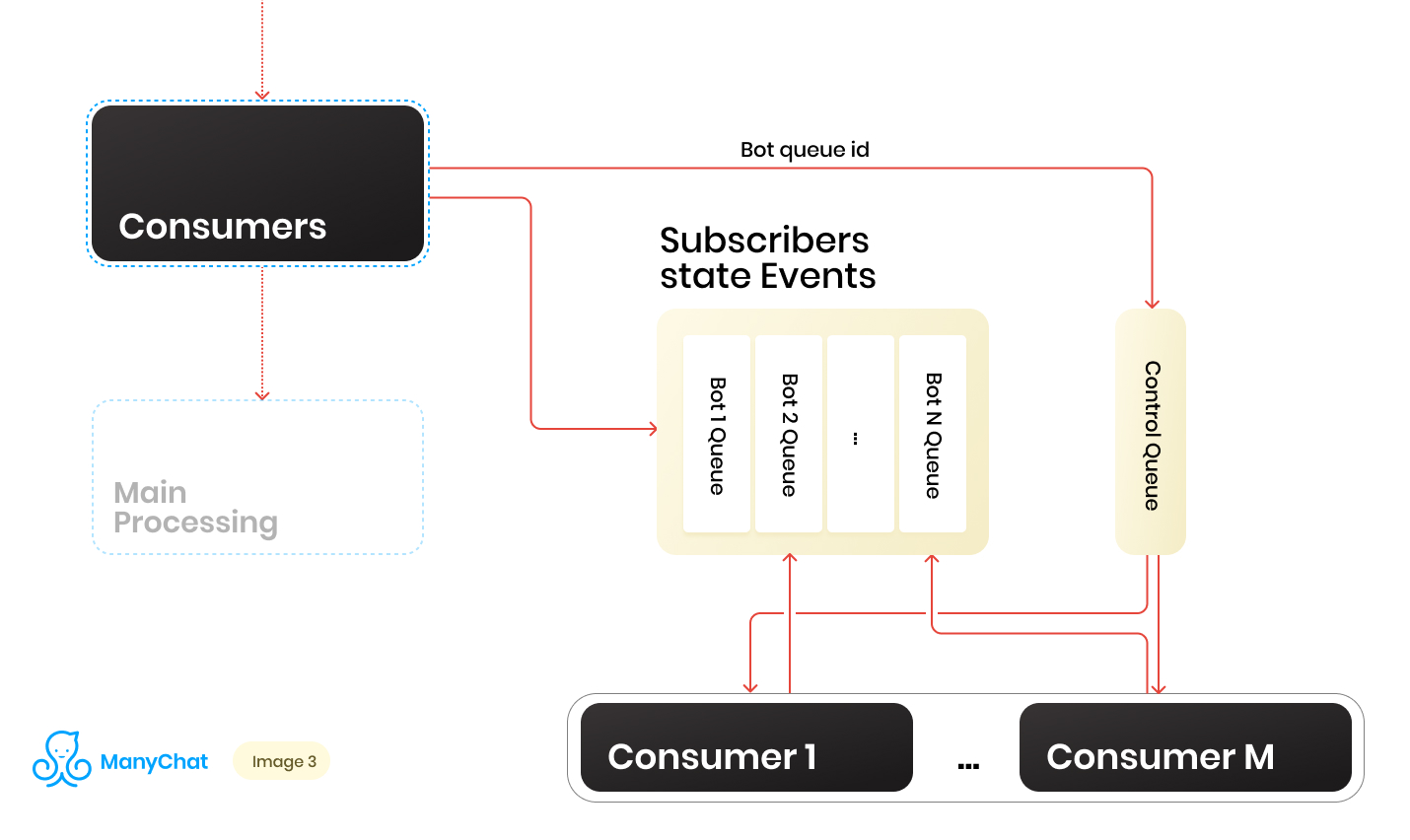 Como resultado, con el esquema actual, resolvimos los principales problemas identificados:
Como resultado, con el esquema actual, resolvimos los principales problemas identificados:- Degradación del rendimiento en el bus de eventos principal
- Violación de manejo de eventos
- El efecto de vecinos ruidosos
¿Cómo lidiar con la carga dinámica?
El esquema funciona, pero en él tenemos un número fijo de consumidores para un número dinámico de colas. Obviamente, con este enfoque, nos hundiremos en el procesamiento de colas cada vez que su número aumente bruscamente. Parece que sería bueno para nuestros trabajadores iniciar o extinguir dinámicamente cuando sea necesario. También sería bueno si esto no complicara en gran medida el proceso de implementación del nuevo código. En esos momentos, las manos son muy picantes para ir y escribir su administrador de procesos. En el futuro, hicimos exactamente eso, pero esta historia es diferente.Pensamos, decidimos, ¿por qué no usar una vez más todas las herramientas familiares y familiares? Entonces obtuvimos nuestra API interna, que funcionó en un paquete estándar de NGINX + PHP-FPM. Como resultado, podemos reemplazar nuestro grupo fijo de trabajadores con API, y permitir que NGINX + PHP-FPM resuelva y administre a los trabajadores nosotros mismos, y es suficiente para que tengamos entre la cola de control y nuestra API interna solo un consumidor de control, que enviará identificadores de cola a nuestra API a procesamiento, y la cola misma se procesará en el trabajador generado por PHP-FPM.El nuevo esquema fue el siguiente: Se ve hermoso, pero nuestro consumidor de control trabaja en un hilo y nuestra API funciona de forma sincrónica. Esto significa que el consumidor se bloqueará cada vez que PHP-FPM esté procesando una cola. Esto no nos conviene.
Se ve hermoso, pero nuestro consumidor de control trabaja en un hilo y nuestra API funciona de forma sincrónica. Esto significa que el consumidor se bloqueará cada vez que PHP-FPM esté procesando una cola. Esto no nos conviene.Hacer que nuestra API sea asincrónica
Pero, ¿qué pasaría si pudiéramos enviar una tarea a nuestra API, y dejar que reduzca la lógica de negocios allí, y nuestro consumidor de control seguirá la siguiente tarea en la cola de control, después de lo cual se retirará a la API, y así sucesivamente. Dicho y hecho.La implementación toma un par de líneas de código, y la Prueba de concepto se ve así:class Api {
public function actionDoSomething()
{
$data = $_POST;
$this->dropFPMSession();
}
protected function dropFPMSession()
{
ignore_user_abort(true);
ob_end_flush();
flush();
@session_write_close();
fastcgi_finish_request();
}
}
En el método dropFPMSession (), rompemos la conexión con el cliente, dándole una respuesta de 200, después de lo cual podemos realizar cualquier lógica pesada en el postprocesamiento. El cliente en nuestro caso es el consumidor de control. Es importante para él dispersar rápidamente las tareas de la cola de control al procesamiento en la API y saber que la tarea ha llegado a la API.Con este enfoque, nos quitamos un montón de dolores de cabeza asociados con el control dinámico de los consumidores y su escalamiento automático.Escalable aún más
Como resultado, la arquitectura de nuestro subsistema comenzó a consistir en tres capas: capa de datos, procesos y API interna. Al mismo tiempo, la información pasa a través de todos los flujos de datos sobre a qué bot pertenece el evento / tarea procesada. Obviamente, podemos usar nuestro identificador de clave / bot para fragmentar, mientras continuamos escalando nuestro sistema horizontalmente.Si imaginamos nuestra arquitectura como una unidad sólida, se verá así: una vez que hayamos aumentado el número de tales unidades, podemos colocar un equilibrador delgado delante de ellas, que dispersará nuestros eventos / tareas en las unidades necesarias, dependiendo de la clave de fragmentación.
una vez que hayamos aumentado el número de tales unidades, podemos colocar un equilibrador delgado delante de ellas, que dispersará nuestros eventos / tareas en las unidades necesarias, dependiendo de la clave de fragmentación. Por lo tanto, obtenemos un amplio margen para el escalado horizontal de nuestro sistema.Al implementar la lógica empresarial, no debe olvidarse del concepto de seguridad de subprocesos, de lo contrario puede obtener resultados inesperados.Tal esquema con cascadas de colas y la eliminación de la lógica comercial pesada en el procesamiento asincrónico se ha utilizado en varias partes del sistema durante más de dos años. La carga durante este tiempo para cada uno de los subsistemas ha crecido decenas de veces, y la implementación propuesta nos permite escalar fácil y rápidamente. Al mismo tiempo, continuamos trabajando en nuestra pila principal, sin expandirla con nuevas herramientas / lenguajes y sin aumentar, por lo tanto, sobrecarga la introducción y el soporte de nuevas herramientas.
Por lo tanto, obtenemos un amplio margen para el escalado horizontal de nuestro sistema.Al implementar la lógica empresarial, no debe olvidarse del concepto de seguridad de subprocesos, de lo contrario puede obtener resultados inesperados.Tal esquema con cascadas de colas y la eliminación de la lógica comercial pesada en el procesamiento asincrónico se ha utilizado en varias partes del sistema durante más de dos años. La carga durante este tiempo para cada uno de los subsistemas ha crecido decenas de veces, y la implementación propuesta nos permite escalar fácil y rápidamente. Al mismo tiempo, continuamos trabajando en nuestra pila principal, sin expandirla con nuevas herramientas / lenguajes y sin aumentar, por lo tanto, sobrecarga la introducción y el soporte de nuevas herramientas.