Hace unos meses, anunciamos aclarar.tensor.ru , un servicio público para analizar y visualizar planes de consulta para PostgreSQL.En el pasado, ya lo ha usado más de 6,000 veces, pero una de las funciones convenientes podría pasar desapercibida: estas son sugerencias estructurales que se parecen a esto: escúchelas y sus solicitudes "se volverán suaves y sedosas". :)Pero en serio, muchas de las situaciones que hacen que la solicitud sea lenta y "glotona" en términos de recursos son típicas y pueden ser reconocidas por la estructura y los datos del plan .En este caso, cada desarrollador individual no tendrá que buscar una opción de optimización por su cuenta, confiando únicamente en su experiencia: podemos decirle qué está sucediendo aquí, cuál podría ser el motivo y cómo abordar la solución . Lo cual hicimos.
escúchelas y sus solicitudes "se volverán suaves y sedosas". :)Pero en serio, muchas de las situaciones que hacen que la solicitud sea lenta y "glotona" en términos de recursos son típicas y pueden ser reconocidas por la estructura y los datos del plan .En este caso, cada desarrollador individual no tendrá que buscar una opción de optimización por su cuenta, confiando únicamente en su experiencia: podemos decirle qué está sucediendo aquí, cuál podría ser el motivo y cómo abordar la solución . Lo cual hicimos. Echemos un vistazo más de cerca a estos casos: cómo se determinan y a qué recomendaciones conducen.Para una mejor comprensión del tema, primero puede escuchar el bloque correspondiente de mi informe sobre PGConf.Russia 2020 , y solo luego pasar a un análisis detallado de cada ejemplo:
Echemos un vistazo más de cerca a estos casos: cómo se determinan y a qué recomendaciones conducen.Para una mejor comprensión del tema, primero puede escuchar el bloque correspondiente de mi informe sobre PGConf.Russia 2020 , y solo luego pasar a un análisis detallado de cada ejemplo:# 1: índice "subestimación"
Cuando surge
Mostrar la última factura para el cliente "LLC Bell".Cómo reconocer
-> Limit
-> Sort
-> Index [Only] Scan [Backward] | Bitmap Heap Scan
Recomendaciones
Use el índice utilizado para ordenar los campos .Ejemplo:CREATE TABLE tbl AS
SELECT
generate_series(1, 100000) pk
, (random() * 1000)::integer fk_cli;
CREATE INDEX ON tbl(fk_cli);
SELECT
*
FROM
tbl
WHERE
fk_cli = 1
ORDER BY
pk DESC
LIMIT 1;
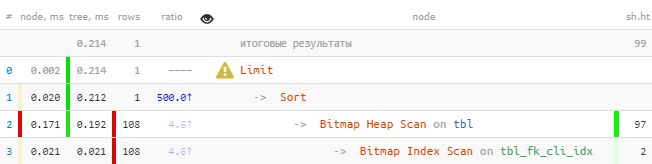 [mire explicar.tensor.ru] Puedenotar de inmediato que el índice resta más de 100 entradas, que luego se ordenaron, y luego quedó la única.Arreglemos:
[mire explicar.tensor.ru] Puedenotar de inmediato que el índice resta más de 100 entradas, que luego se ordenaron, y luego quedó la única.Arreglemos:DROP INDEX tbl_fk_cli_idx;
CREATE INDEX ON tbl(fk_cli, pk DESC);
 [mire explicar.tensor.ru]Incluso en una muestra tan primitiva: 8.5 veces más rápido y 33 veces menos lecturas . El efecto será más visible cuanto más "hechos" tenga para cada valor
[mire explicar.tensor.ru]Incluso en una muestra tan primitiva: 8.5 veces más rápido y 33 veces menos lecturas . El efecto será más visible cuanto más "hechos" tenga para cada valor fk.Observo que dicho índice funcionará como "prefijo" no peor que el anterior para otras consultas fk, donde pkno hubo clasificación ni clasificación (se puede encontrar más información sobre esto en mi artículo sobre cómo encontrar índices ineficientes ). En particular, proporcionará soporte normal para una clave foránea explícita en este campo.# 2: intersección de índice (BitmapAnd)
Cuando surge
Mostrar todos los contratos para el cliente LLC Kolokolchik celebrado en nombre de NAO Buttercup.Cómo reconocer
-> BitmapAnd
-> Bitmap Index Scan
-> Bitmap Index Scan
Recomendaciones
Cree un índice compuesto para los campos desde el origen o expanda uno de los campos existentes desde el segundo.Ejemplo:CREATE TABLE tbl AS
SELECT
generate_series(1, 100000) pk
, (random() * 100)::integer fk_org
, (random() * 1000)::integer fk_cli;
CREATE INDEX ON tbl(fk_org);
CREATE INDEX ON tbl(fk_cli);
SELECT
*
FROM
tbl
WHERE
(fk_org, fk_cli) = (1, 999);
 [mire explicar.tensor.ru]Correcto:
[mire explicar.tensor.ru]Correcto:DROP INDEX tbl_fk_org_idx;
CREATE INDEX ON tbl(fk_org, fk_cli);
 [mire explicar.tensor.ru]Aquí la ganancia es menor, porque Bitmap Heap Scan es bastante efectivo en sí mismo. Pero sigue siendo 7 veces más rápido y 2,5 veces menos lecturas .
[mire explicar.tensor.ru]Aquí la ganancia es menor, porque Bitmap Heap Scan es bastante efectivo en sí mismo. Pero sigue siendo 7 veces más rápido y 2,5 veces menos lecturas .# 3: agrupación de índices (BitmapOr)
Cuando surge
Muestre las primeras 20 aplicaciones "propias" o no asignadas más antiguas para el procesamiento, y su prioridad.Cómo reconocer
-> BitmapOr
-> Bitmap Index Scan
-> Bitmap Index Scan
Recomendaciones
Use UNION [ALL] para combinar subconsultas para cada uno de los bloques OR de condiciones.Ejemplo:CREATE TABLE tbl AS
SELECT
generate_series(1, 100000) pk
, CASE
WHEN random() < 1::real/16 THEN NULL
ELSE (random() * 100)::integer
END fk_own;
CREATE INDEX ON tbl(fk_own, pk);
SELECT
*
FROM
tbl
WHERE
fk_own = 1 OR
fk_own IS NULL
ORDER BY
pk
, (fk_own = 1) DESC
LIMIT 20;
 [mire explicar.tensor.ru]Correcto:
[mire explicar.tensor.ru]Correcto:(
SELECT
*
FROM
tbl
WHERE
fk_own = 1
ORDER BY
pk
LIMIT 20
)
UNION ALL
(
SELECT
*
FROM
tbl
WHERE
fk_own IS NULL
ORDER BY
pk
LIMIT 20
)
LIMIT 20;
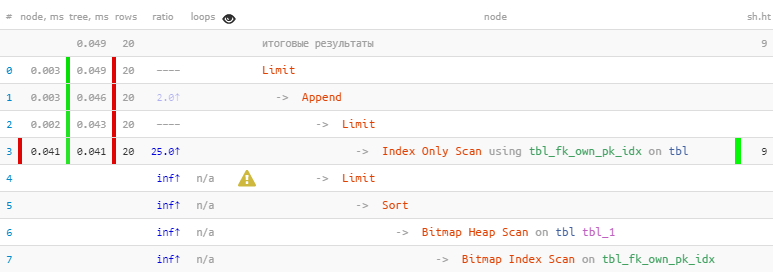 [mire explicar.tensor.ru]Aprovechamos el hecho de que los 20 registros necesarios se recibieron de inmediato en el primer bloque, por lo que el segundo, con la exploración de montón de mapas de bits más "costosa", ni siquiera se realizó, como resultado , 22 veces más rápido, en ¡44 veces menos lecturas !
[mire explicar.tensor.ru]Aprovechamos el hecho de que los 20 registros necesarios se recibieron de inmediato en el primer bloque, por lo que el segundo, con la exploración de montón de mapas de bits más "costosa", ni siquiera se realizó, como resultado , 22 veces más rápido, en ¡44 veces menos lecturas !Se puede encontrar una historia más detallada sobre este método de optimización utilizando ejemplos específicos en los artículos de PostgreSQL Antipatterns: perjudicial JOIN y OR y PostgreSQL Antipatterns: un cuento sobre el refinamiento iterativo de la búsqueda por nombre, o "Optimización de ida y vuelta" .
Se consideró una versión generalizada de la selección ordenada por varias teclas (y no solo por el par const / NULL) en el artículo de SQL HowTo: escribimos el ciclo while directamente en la consulta, o "Elemental de tres vías" .
# 4: lee muchas cosas innecesarias
Cuando surge
Como regla, surge si desea "fijar otro filtro" a una solicitud existente."¿Y no tienes lo mismo, pero con botones de perlas ?" película "Diamond Hand"
Por ejemplo, al modificar la tarea anterior, muestre las primeras 20 aplicaciones "críticas" más antiguas para el procesamiento, independientemente de su propósito.Cómo reconocer
-> Seq Scan | Bitmap Heap Scan | Index [Only] Scan [Backward]
&& 5 × rows < RRbF -- >80%
&& loops × RRbF > 100 -- 100
Recomendaciones
Cree un [más] índice personalizado con una cláusula WHERE o incluya campos adicionales en el índice.Si la condición del filtro es "estática" para sus tareas, es decir, no implica expandir la lista de valores en el futuro, es mejor usar el índice WHERE. Los diferentes estados booleanos / enum encajan bien en esta categoría.
Si la condición del filtro puede tomar valores diferentes , entonces es mejor expandir el índice con estos campos, como en la situación con BitmapAnd arriba.
Ejemplo:CREATE TABLE tbl AS
SELECT
generate_series(1, 100000) pk
, CASE
WHEN random() < 1::real/16 THEN NULL
ELSE (random() * 100)::integer
END fk_own
, (random() < 1::real/50) critical;
CREATE INDEX ON tbl(pk);
CREATE INDEX ON tbl(fk_own, pk);
SELECT
*
FROM
tbl
WHERE
critical
ORDER BY
pk
LIMIT 20;
 [mire explicar.tensor.ru]Correcto:
[mire explicar.tensor.ru]Correcto:CREATE INDEX ON tbl(pk)
WHERE critical;
 [mire explicar.tensor.ru]Como puede ver, el filtrado ha desaparecido por completo del plan y la solicitud se ha vuelto 5 veces más rápida .
[mire explicar.tensor.ru]Como puede ver, el filtrado ha desaparecido por completo del plan y la solicitud se ha vuelto 5 veces más rápida .# 5: mesa escasa
Cuando surge
Varios intentos de hacer su propia cola de tareas de procesamiento cuando una gran cantidad de actualizaciones / eliminaciones de registros en la tabla conducen a una situación de una gran cantidad de registros "muertos".Cómo reconocer
-> Seq Scan | Bitmap Heap Scan | Index [Only] Scan [Backward]
&& loops × (rows + RRbF) < (shared hit + shared read) × 8
-- 1KB
&& shared hit + shared read > 64
Recomendaciones
Realice manualmente VACÍO [COMPLETO] manualmente o logre pruebas de vacío automático frecuentes adecuadas ajustando sus parámetros, incluso para una tabla específica .En la mayoría de los casos, estos problemas son causados por consultas mal estructuradas cuando se llama desde la lógica de negocios, como las discutidas en PostgreSQL Antipatterns: luchando contra hordas de "muertos" .
Pero debe comprender que incluso VACUUM FULL no siempre ayuda. Para tales casos, debe familiarizarse con el algoritmo del artículo de DBA: cuando VACUUM pasa, limpiamos la tabla manualmente .
# 6: lectura desde la mitad del índice
Cuando surge
Parece que no leyeron mucho, y todo por índice, y no filtraron nada extra, pero de todos modos, se leyeron significativamente más páginas de las que quisiéramos.Cómo reconocer
-> Index [Only] Scan [Backward]
&& loops × (rows + RRbF) < (shared hit + shared read) × 8
-- 1KB
&& shared hit + shared read > 64
Recomendaciones
Observe detenidamente la estructura del índice utilizado y los campos clave especificados en la solicitud; lo más probable es que parte del índice no esté especificado . Lo más probable es que tenga que crear un índice similar, pero sin campos de prefijo o aprender a iterar sobre sus valores .Ejemplo:CREATE TABLE tbl AS
SELECT
generate_series(1, 100000) pk
, (random() * 100)::integer fk_org
, (random() * 1000)::integer fk_cli;
CREATE INDEX ON tbl(fk_org, fk_cli);
SELECT
*
FROM
tbl
WHERE
fk_cli = 999
LIMIT 20;
 [mire explicar.tensor.ru] Todoparece estar bien, incluso por índice, pero de alguna manera sospechosa, para cada uno de los 20 registros leídos, tuve que restar 4 páginas de datos, 32 KB por registro, ¿no está en negrita? Sí, y el nombre del índice es sugerente. Arreglemos:
[mire explicar.tensor.ru] Todoparece estar bien, incluso por índice, pero de alguna manera sospechosa, para cada uno de los 20 registros leídos, tuve que restar 4 páginas de datos, 32 KB por registro, ¿no está en negrita? Sí, y el nombre del índice es sugerente. Arreglemos:tbl_fk_org_fk_cli_idxCREATE INDEX ON tbl(fk_cli);
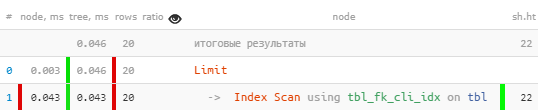 [mire explicar.tensor.ru]De repente, ¡ 10 veces más rápido y 4 veces menos leído !
[mire explicar.tensor.ru]De repente, ¡ 10 veces más rápido y 4 veces menos leído !Se pueden ver otros ejemplos de situaciones de uso ineficiente de índices en el artículo de DBA: Buscar índices inútiles .
# 7: CTE × CTE
Cuando surge
En la consulta escribimos CTE "gordos" de diferentes tablas, y luego decidimos hacer entre ellos JOIN.El caso es relevante para versiones inferiores a v12 o solicitudes de WITH MATERIALIZED.Cómo reconocer
-> CTE Scan
&& loops > 10
&& loops × (rows + RRbF) > 10000
-- CTE
Recomendaciones
Analice cuidadosamente la solicitud: ¿ se necesita CTE aquí ? Si es lo mismo, entonces aplique "rasgado" en hstore / json de acuerdo con el modelo descrito en PostgreSQL Antipatterns: golpee el diccionario con un JOIN pesado .# 8: cambiar a disco (temp escrito)
Cuando surge
El procesamiento único (clasificación o unificación) de un gran número de registros no cabe en la memoria asignada para esto.Cómo reconocer
-> *
&& temp written > 0
Recomendaciones
Si la cantidad de memoria utilizada por la operación no excede en gran medida el valor establecido del parámetro work_mem , vale la pena ajustarlo. Puede inmediatamente en la configuración para todos, pero puede hacerlo SET [LOCAL]para una solicitud / transacción específica.Ejemplo:SHOW work_mem;
SELECT
random()
FROM
generate_series(1, 1000000)
ORDER BY
1;
 [mire explicar.tensor.ru]Correcto:
[mire explicar.tensor.ru]Correcto:SET work_mem = '128MB';
 [mire explicar.tensor.ru]Por razones obvias, si solo se usa memoria, no un disco, la solicitud se ejecutará mucho más rápido. Al mismo tiempo, también se elimina parte de la carga del HDD.Pero debe comprender que asignar una gran cantidad de memoria tampoco siempre funciona, no será suficiente para todos.
[mire explicar.tensor.ru]Por razones obvias, si solo se usa memoria, no un disco, la solicitud se ejecutará mucho más rápido. Al mismo tiempo, también se elimina parte de la carga del HDD.Pero debe comprender que asignar una gran cantidad de memoria tampoco siempre funciona, no será suficiente para todos.# 9: estadísticas irrelevantes
Cuando surge
Vertieron mucho de una vez en la base de datos, pero no lograron ahuyentarlos ANALYZE.Cómo reconocer
-> Seq Scan | Bitmap Heap Scan | Index [Only] Scan [Backward]
&& ratio >> 10
Recomendaciones
Haz lo mismo ANALYZE.Esta situación se describe con más detalle en PostgreSQL Antipatterns: las estadísticas están en la cabeza .
# 10: "algo salió mal"
Cuando surge
Había una expectativa de un bloqueo impuesto por una solicitud competitiva, o no había suficientes recursos de hardware de CPU / hipervisor.Cómo reconocer
-> *
&& (shared hit / 8K) + (shared read / 1K) < time / 1000
-- RAM hit = 64MB/s, HDD read = 8MB/s
&& time > 100ms -- ,
Recomendaciones
Use un sistema externo para monitorear el servidor en busca de bloqueos o consumo anormal de recursos. Sobre nuestra versión de la organización de este proceso para cientos de servidores, ya hablamos aquí y aquí .