 Hola, mi nombre es Andrey Schukin, ayudo a grandes empresas a migrar servicios y sistemas a la nube de CROC. Junto con colegas de Southbridge, que organiza cursos de Kubernetes en el centro de capacitación de Slerm, recientemente realizamos un seminario web para nuestros clientes.Decidí tomar materiales de una excelente conferencia de Pavel Selivanov y escribir una publicación para aquellos que recién comienzan a trabajar con herramientas de aprovisionamiento en la nube y no saben por dónde empezar. Por lo tanto, hablaré sobre la pila de tecnologías que se utilizan en nuestra capacitación y producción de CROC Cloud. Hablemos de los enfoques modernos para la gestión de la infraestructura, sobre un montón de componentes Packer, Terraform y Ansible, así como sobre la herramienta Kubeadm con la que instalaremos.Debajo del corte habrá mucho texto y configuraciones. Hay mucho material, así que agregué navegación posterior. También preparamos un pequeño repositorio donde colocamos todo lo que necesitábamos para nuestra implementación de capacitación.No le dé nombres a los pollos. Lospasteles horneados son más saludables que los fritos.Arrancamos el horno. PackerTerraform: infraestructura como códigoInicie TerraformCluster structure KubernetesKubeadmRepository con todos los archivos
Hola, mi nombre es Andrey Schukin, ayudo a grandes empresas a migrar servicios y sistemas a la nube de CROC. Junto con colegas de Southbridge, que organiza cursos de Kubernetes en el centro de capacitación de Slerm, recientemente realizamos un seminario web para nuestros clientes.Decidí tomar materiales de una excelente conferencia de Pavel Selivanov y escribir una publicación para aquellos que recién comienzan a trabajar con herramientas de aprovisionamiento en la nube y no saben por dónde empezar. Por lo tanto, hablaré sobre la pila de tecnologías que se utilizan en nuestra capacitación y producción de CROC Cloud. Hablemos de los enfoques modernos para la gestión de la infraestructura, sobre un montón de componentes Packer, Terraform y Ansible, así como sobre la herramienta Kubeadm con la que instalaremos.Debajo del corte habrá mucho texto y configuraciones. Hay mucho material, así que agregué navegación posterior. También preparamos un pequeño repositorio donde colocamos todo lo que necesitábamos para nuestra implementación de capacitación.No le dé nombres a los pollos. Lospasteles horneados son más saludables que los fritos.Arrancamos el horno. PackerTerraform: infraestructura como códigoInicie TerraformCluster structure KubernetesKubeadmRepository con todos los archivosNo dar nombres a las gallinas.
 Hay muchos conceptos diferentes de gestión de infraestructura. Uno de ellos se llama Pets vs. Ganado, es decir, "mascotas contra el ganado". Este concepto describe dos enfoques opuestos a la infraestructura.Imagina que tenemos un perro favorito. La cuidamos, lo llevamos al veterinario, le peinamos el pelaje y, en general, es único para nosotros entre muchos otros perros.En otro caso, tenemos un gallinero. También cuidamos a los pollos, alimentamos, calentamos e intentamos crear las condiciones más cómodas. Sin embargo, los pollos son un recurso sin rostro para nosotros, que cumple su función de poner huevos, y en el mejor de los casos los designamos como "ese negro en polvo que siempre picotea el cemento". Si el pollo deja de poner huevos o se rompe la pata, lo más probable es que simplemente nos proporcione un delicioso caldo para el almuerzo. De hecho, no nos importa el destino de un pollo individual, sino el gallinero en su conjunto como línea de producción.En TI, un enfoque similar comenzó a aplicarse tan pronto como aparecieron las herramientas que redujeron el umbral de entrada para los ingenieros y permitieron implementar y mantener clústeres complejos en un modo completamente automático.Anteriormente, teníamos una pequeña cantidad de servidores que eran monitoreados, ajustados manualmente y atendidos de todas las formas posibles. En el monitoreo, los registros de los servidores Cthulhu, Aylith y Dagon parpadearon. TradicionesLuego, la virtualización entró firmemente en nuestras vidas, y los nombres de las obras de Lovecraft y Star Trek dieron paso al más utilitario "vlg-vlt-vault01.company.ru". Hay muchos servidores, pero aún así aumentamos los servicios de forma más o menos manual, eliminando los problemas en cada máquina si es necesario.Ahora el enfoque para mantener la infraestructura coincide completamente con la programación. Agregamos otro nivel de abstracción y dejamos de preocuparnos por los nodos individuales. Cada uno tiene un índice sin rostro en lugar de un nombre, y en caso de problemas, la máquina virtual simplemente mata y se levanta de la instantánea de trabajo. Existen herramientas que le permiten implementar este enfoque. En nuestro caso, la primera herramienta es la nube CROC, la segunda es Terraform.
Hay muchos conceptos diferentes de gestión de infraestructura. Uno de ellos se llama Pets vs. Ganado, es decir, "mascotas contra el ganado". Este concepto describe dos enfoques opuestos a la infraestructura.Imagina que tenemos un perro favorito. La cuidamos, lo llevamos al veterinario, le peinamos el pelaje y, en general, es único para nosotros entre muchos otros perros.En otro caso, tenemos un gallinero. También cuidamos a los pollos, alimentamos, calentamos e intentamos crear las condiciones más cómodas. Sin embargo, los pollos son un recurso sin rostro para nosotros, que cumple su función de poner huevos, y en el mejor de los casos los designamos como "ese negro en polvo que siempre picotea el cemento". Si el pollo deja de poner huevos o se rompe la pata, lo más probable es que simplemente nos proporcione un delicioso caldo para el almuerzo. De hecho, no nos importa el destino de un pollo individual, sino el gallinero en su conjunto como línea de producción.En TI, un enfoque similar comenzó a aplicarse tan pronto como aparecieron las herramientas que redujeron el umbral de entrada para los ingenieros y permitieron implementar y mantener clústeres complejos en un modo completamente automático.Anteriormente, teníamos una pequeña cantidad de servidores que eran monitoreados, ajustados manualmente y atendidos de todas las formas posibles. En el monitoreo, los registros de los servidores Cthulhu, Aylith y Dagon parpadearon. TradicionesLuego, la virtualización entró firmemente en nuestras vidas, y los nombres de las obras de Lovecraft y Star Trek dieron paso al más utilitario "vlg-vlt-vault01.company.ru". Hay muchos servidores, pero aún así aumentamos los servicios de forma más o menos manual, eliminando los problemas en cada máquina si es necesario.Ahora el enfoque para mantener la infraestructura coincide completamente con la programación. Agregamos otro nivel de abstracción y dejamos de preocuparnos por los nodos individuales. Cada uno tiene un índice sin rostro en lugar de un nombre, y en caso de problemas, la máquina virtual simplemente mata y se levanta de la instantánea de trabajo. Existen herramientas que le permiten implementar este enfoque. En nuestro caso, la primera herramienta es la nube CROC, la segunda es Terraform.Los pasteles horneados son más saludables que los fritos.
 En la gestión de infraestructura hay un contraste entre los dos enfoques de Fried vs. Al horno, es decir, "frito contra horneado".El enfoque de Fried implica que tiene una imagen de sistema operativo estándar, por ejemplo, CentOS 7. Luego, después de implementar el sistema operativo, usamos el sistema de gestión de configuración para llevar el sistema al estado de destino. Por ejemplo, usando Ansible, Chef, Puppet o SaltStack.Todo funciona bien, especialmente cuando no hay muchos servidores. Cuando existe la necesidad de una implementación masiva, nos enfrentamos a problemas de rendimiento. Cientos de servidores comienzan a devorar sincrónicamente recursos de red, CPU, RAM e IOPS en el proceso de lanzar muchos paquetes nuevos. Además, este proceso puede retrasarse por un tiempo bastante largo. En resumen, el circuito es absolutamente operativo, pero no tan interesante desde el punto de vista de minimizar el tiempo de inactividad durante los accidentes.El enfoque al horno implica que tiene imágenes del sistema operativo "horneadas" listas para usar en las que ya ha instalado todos los paquetes necesarios, ha configurado la configuración y todo lo demás. En la salida, tenemos una plantilla de instantánea abstracta, enfocada para el desempeño de alguna función. La implementación de infraestructura a partir de tales imágenes horneadas lleva mucho menos tiempo y reduce el tiempo de inactividad al mínimo. Se utiliza una ideología muy similar en las imágenes de Docker de varias capas, en las que nadie toca sus manos innecesariamente. Clavado el contenedor - levantó uno nuevo.
En la gestión de infraestructura hay un contraste entre los dos enfoques de Fried vs. Al horno, es decir, "frito contra horneado".El enfoque de Fried implica que tiene una imagen de sistema operativo estándar, por ejemplo, CentOS 7. Luego, después de implementar el sistema operativo, usamos el sistema de gestión de configuración para llevar el sistema al estado de destino. Por ejemplo, usando Ansible, Chef, Puppet o SaltStack.Todo funciona bien, especialmente cuando no hay muchos servidores. Cuando existe la necesidad de una implementación masiva, nos enfrentamos a problemas de rendimiento. Cientos de servidores comienzan a devorar sincrónicamente recursos de red, CPU, RAM e IOPS en el proceso de lanzar muchos paquetes nuevos. Además, este proceso puede retrasarse por un tiempo bastante largo. En resumen, el circuito es absolutamente operativo, pero no tan interesante desde el punto de vista de minimizar el tiempo de inactividad durante los accidentes.El enfoque al horno implica que tiene imágenes del sistema operativo "horneadas" listas para usar en las que ya ha instalado todos los paquetes necesarios, ha configurado la configuración y todo lo demás. En la salida, tenemos una plantilla de instantánea abstracta, enfocada para el desempeño de alguna función. La implementación de infraestructura a partir de tales imágenes horneadas lleva mucho menos tiempo y reduce el tiempo de inactividad al mínimo. Se utiliza una ideología muy similar en las imágenes de Docker de varias capas, en las que nadie toca sus manos innecesariamente. Clavado el contenedor - levantó uno nuevo.Arrancamos el horno. Envasador
 En nuestra infraestructura, utilizamos varios productos de Hashicorp, algunos de los cuales resultaron ser extremadamente exitosos. Comencemos nuestra magia preparando y horneando una imagen usando la herramienta Packer.Packer utiliza una plantilla JSON, es decir, archivos de plantilla que contienen una descripción de lo que debe obtenerse como una máquina virtual (VM) "horneada". Después de crear la plantilla, el archivo se transfiere a Packer y se configuran los permisos necesarios para crear el servidor en la nube.Packer le permite elevar máquinas virtuales localmente en KVM, VirtualBox, Vagrant, AWS, GCP, Alibaba Cloud, OpenStack, etc. Es conveniente trabajar con Packer en CROC Cloud, ya que implementa interfaces de AWS, es decir, todas las herramientas para las que está escrito AWS, trabaje con CROC Cloud.Después de configurar las plantillas necesarias, Packer levanta VM CROC en la nube, espera a que comience y luego el "proveedor" ingresa al aprovisionador de trabajo: una utilidad que debe completar la preparación de la imagen. En nuestro caso, esto es Ansible, aunque Packer puede trabajar con otras opciones.Cuando la VM está lista, Packer crea su imagen y la coloca en la Nube de CROC para que otras VM se puedan iniciar desde la misma imagen.
En nuestra infraestructura, utilizamos varios productos de Hashicorp, algunos de los cuales resultaron ser extremadamente exitosos. Comencemos nuestra magia preparando y horneando una imagen usando la herramienta Packer.Packer utiliza una plantilla JSON, es decir, archivos de plantilla que contienen una descripción de lo que debe obtenerse como una máquina virtual (VM) "horneada". Después de crear la plantilla, el archivo se transfiere a Packer y se configuran los permisos necesarios para crear el servidor en la nube.Packer le permite elevar máquinas virtuales localmente en KVM, VirtualBox, Vagrant, AWS, GCP, Alibaba Cloud, OpenStack, etc. Es conveniente trabajar con Packer en CROC Cloud, ya que implementa interfaces de AWS, es decir, todas las herramientas para las que está escrito AWS, trabaje con CROC Cloud.Después de configurar las plantillas necesarias, Packer levanta VM CROC en la nube, espera a que comience y luego el "proveedor" ingresa al aprovisionador de trabajo: una utilidad que debe completar la preparación de la imagen. En nuestro caso, esto es Ansible, aunque Packer puede trabajar con otras opciones.Cuando la VM está lista, Packer crea su imagen y la coloca en la Nube de CROC para que otras VM se puedan iniciar desde la misma imagen.Estructura de base.json
Al principio del archivo hay una sección en la que se declaran las variables:Revelación"variables" : {
"source_ami_name": "{{env SOURCE_AMI_NAME}}",
"ami_name": "{{env AMI_NAME}}",
"instance_type": "{{env INSTANCE_TYPE}}",
"kubernetes_version": "{{env KUBERNETES_VERSION}}",
"docker_version": "{{env DOCKER_VERSION}}",
"subnet_id": "",
"availability_zone": "",
},
El conjunto principal de estas variables se establecerá desde el archivo settings.json. Y las variables que cambian con frecuencia son más convenientes para configurar desde la consola al iniciar Packer y construir una nueva imagen.La siguiente es la sección Constructores:Revelación"builders" : [
{
"type": "amazon-ebs",
"region": "croc",
"skip_region_validation": true,
"custom_endpoint_ec2": "https://api.cloud.croc.ru",
"source_ami": "",
"source_ami_filter": {
"filters": {
"name": "{{user `source_ami_name`}}"
"state": "available",
"virtualization-type": "kvm-virtio"
},
...
Las nubes de destino y el método de inicio de VM se describen aquí. Tenga en cuenta que en este caso se declara el tipo amazon-ebs, pero para que Packer trabaje con CROC Cloud, se establece la dirección correspondiente en custom_endpoint_ec2. Nuestra infraestructura tiene una API que es casi completamente compatible con los servicios web de Amazon, por lo que si tiene desarrollos listos para esta plataforma, en su mayor parte solo tendrá que especificar un punto de entrada API personalizado: api.cloud.croc.ru en nuestro ejemplo.Vale la pena señalar la sección source_ami_filter por separado. Aquí se establece la imagen inicial de la VM, en la que se realizarán los cambios necesarios. Sin embargo, Packer requiere un AMI para esta imagen, es decir, su identificador aleatorio. Dado que este identificador rara vez se conoce de antemano y cambia con cada actualización, el AMI de origen no se establece como un valor específico, sino como una variable source_ami_filter. En este caso, el parámetro determinante del filtro es el nombre de la imagen. Este nombre se establece en las variables a través del archivo settings.json.A continuación, se definen las configuraciones de VM: se especifican el tipo de instancia, procesador, tamaño de memoria, espacio asignado, etc.Revelación"instance_type": "{{user `instance_type`}}",
"launch_block_device_mappings": [
{
"device_name": "disk1",
"volume_type": "io1",
"volume_size": "8",
"iops": "1000",
"delete_on_termination": "true"
}
],
A continuación en base.json están los parámetros para conectarse a esta VM:Revelación"availability_zone": "{{user `availability_zone`}}",
"subnet_id": "{{user `subnet_id`}}",
"associate_public_ip_address": true,
"ssh_username": "ec2-user",
"ami_name": "{{user `ami_name`}}"
Es importante tener en cuenta el parámetro subnet_id aquí. Debe configurarse manualmente, ya que sin especificar la subred de VM en la nube CROC no puede crear.Otro parámetro que requiere preparación previa es associa_public_ip_address. Debe seleccionar una dirección IP blanca, porque después de crear VM Packer comenzará a aplicar la configuración necesaria a través de Ansible. En este caso, Ansible se conecta a la VM a través de SSH, que requiere una dirección IP blanca o VPN.La última sección son los aprovisionadores:Revelación"provisioners": [
{
"type": "ansible",
"playbook_file": "playbook.yml",
"extra_arguments": [
"--extra-vars",
"kubernetes_version={{user `kubernetes_version`}}",
"--extra-vars",
"docker_version={{user `docker_version`}}"
]
}
]
Estos son los proveedores, es decir, las utilidades con las que Packer configura el servidor. En este caso, se utiliza el proveedor de tipo ansible. El siguiente es el parámetro playbook_file, que define los roles Ansible y los hosts en los que se aplicarán los roles especificados. A continuación se presentan opciones adicionales extra_arguments que, al iniciar Ansible, transmiten versiones de Kubernetes y Docker.Preparación de la nube CROC
 Además de nuestros archivos de configuración, necesitamos hacer algunas cosas desde el costado del panel de control de la nube para que toda la magia funcione. Necesitamos seleccionar una IP blanca y crear una subred que funcione, que usaremos al implementar.
Además de nuestros archivos de configuración, necesitamos hacer algunas cosas desde el costado del panel de control de la nube para que toda la magia funcione. Necesitamos seleccionar una IP blanca y crear una subred que funcione, que usaremos al implementar.- Haga clic en Resaltar dirección. Packer encontrará la dirección IP blanca deseada por sí solo.
- Haga clic en Crear subred y especifique una subred y una máscara.
- Copie la ID de subred.
- Inserte este valor en el parámetro subnet_id del comando de inicio de Packer.
 Luego ejecuta Packer. Encuentra la imagen de VM original, la implementa en la Nube de CROC y realiza el rol Ansible en ella. La nueva VM se puede ver en la nube CROC en la sección "Instancias".
Luego ejecuta Packer. Encuentra la imagen de VM original, la implementa en la Nube de CROC y realiza el rol Ansible en ella. La nueva VM se puede ver en la nube CROC en la sección "Instancias".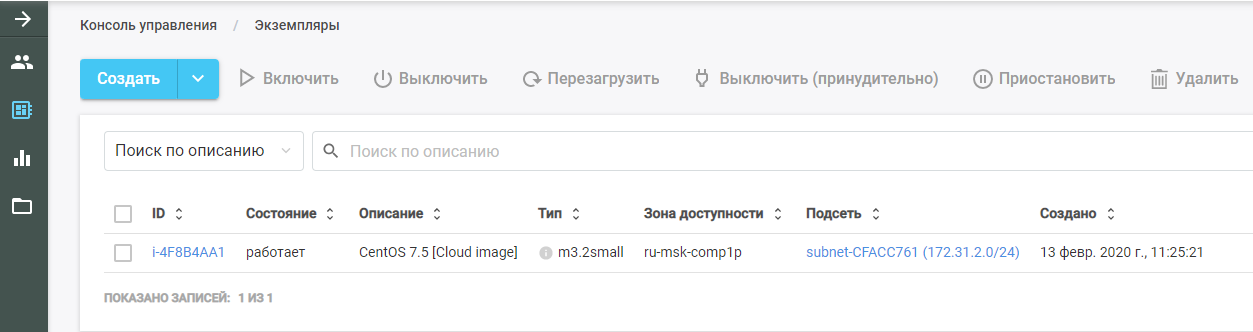
 Después de terminar el trabajo, Packer elimina la VM de la nube y deja una imagen preparada en su lugar, que se puede encontrar en la sección "Plantillas". Toda la infraestructura de Kubernetes se creará a partir de esta imagen.
Después de terminar el trabajo, Packer elimina la VM de la nube y deja una imagen preparada en su lugar, que se puede encontrar en la sección "Plantillas". Toda la infraestructura de Kubernetes se creará a partir de esta imagen.Ansible
Como se mencionó anteriormente, el parámetro del libro de jugadas se pasa en los parámetros del proveedor Ansible. El archivo playbook.yml en sí se ve así:- hosts: all
become: true
roles:
| - base
El archivo transfiere a Ansible que en todos los hosts es necesario cumplir el rol de base. Si hay otros roles, puede agregarlos al mismo archivo que una lista.El rol base le permite obtener un clúster preparado con un solo comando. El archivo main.yml muestra qué hace exactamente este rol:- Agrega un repositorio de Docker a la plantilla del sistema.
- Agrega el repositorio de Kubernetes a la plantilla del sistema.
- Instala los paquetes necesarios.
- Crea un directorio para configurar el demonio Docker.
- Configura la máquina de acuerdo con el archivo de configuración daemon.json.j2.
- Carga el núcleo br_netfilter.
- Incluye las opciones necesarias para br_netfilter.
- Incluye componentes Docker y Kubelet.
- Ejecuta Docker en VM.
- Ejecuta un comando que descarga las imágenes de Docker necesarias para que Kubernetes funcione.
En este caso, los paquetes instalados se establecen en el archivo main.yml del directorio vars. En nuestro caso, instalamos el paquete docker-ce, así como los tres paquetes necesarios para que Kubernetes funcione: kubelet, kubeadm y kubectl.Terraform - infraestructura como código
 Terraform es una herramienta muy funcional de HashiCorp para la orquestación en la nube. Tiene su propio lenguaje HCL específico, que a menudo se usa en otros productos de la compañía, por ejemplo, en HashiCorp Vault y Consul.El principio básico es similar a todos los sistemas de gestión de configuración. Simplemente indica el estado objetivo en el formato deseado, y el sistema calcula el algoritmo de cómo lograrlo. Otra cosa es que, a diferencia del mismo Ansible, que funciona como un recuadro negro en libros de jugadas complejos, Terraform puede emitir un plan de acciones futuras en una forma conveniente para el análisis. Esto es importante al planificar cambios complejos de infraestructura. Después de planificar las acciones necesarias, ejecute el comando terraform apply y Terraform desplegará la infraestructura descrita en los archivos.Al igual que Packer, esta herramienta es compatible con AWS, GCP, Alibaba Cloud, Azure, OpenStack, VMware, etc.
Terraform es una herramienta muy funcional de HashiCorp para la orquestación en la nube. Tiene su propio lenguaje HCL específico, que a menudo se usa en otros productos de la compañía, por ejemplo, en HashiCorp Vault y Consul.El principio básico es similar a todos los sistemas de gestión de configuración. Simplemente indica el estado objetivo en el formato deseado, y el sistema calcula el algoritmo de cómo lograrlo. Otra cosa es que, a diferencia del mismo Ansible, que funciona como un recuadro negro en libros de jugadas complejos, Terraform puede emitir un plan de acciones futuras en una forma conveniente para el análisis. Esto es importante al planificar cambios complejos de infraestructura. Después de planificar las acciones necesarias, ejecute el comando terraform apply y Terraform desplegará la infraestructura descrita en los archivos.Al igual que Packer, esta herramienta es compatible con AWS, GCP, Alibaba Cloud, Azure, OpenStack, VMware, etc.Describimos el proyecto
El directorio Terraform tiene un conjunto de archivos con la extensión .tf. Estos archivos describen los componentes de la infraestructura con la que trabajaremos. Divide el proyecto en módulos funcionales. Dicha estructura facilita el control de versiones y el ensamblaje de cada proyecto a partir de bloques convenientes ya hechos. Para nuestra opción, la siguiente estructura es adecuada:- main.tf
- network.tf
- security_groups.tf
- master.tf
- master.tpl
Estructura del archivo Main.tf
Comencemos con el archivo main.tf, en el que se configura el acceso a la nube. En particular, se anuncian varios parámetros que configuran Terraform para trabajar con la nube CROC:provider "aws" {
endpoints {
ec2 = "https://api.cloud.croc.ru"
}
Además, el archivo describe que Terraform debe crear independientemente una clave privada y cargar su parte pública en todos los servidores. La clave privada en sí se emite al final de Terraform:resource "tls_private_key" "ssh" {
algorithm = "RSA"
}
resource "aws_key_pair" "kube" {
key_name = "terraform"
public_key = "${tls_private_key.ssh.public_key_openssh}"
}
output "ssh" {
value = "${tls_private_key.ssh.private_key_pem}"
}
La estructura del archivo network.tf
Este archivo describe los componentes de red necesarios para iniciar la VM:Revelacióndata "aws_availability_zones" "az" {
state = "available"
}
resource "aws_vpc" "kube" {
cidr_block = "${var.vpc_cidr}"
}
resource "aws_eip" "master" {
count = "1"
vpc = true
}
resource "aws_subnet" "private" {
vpc_id = "${aws_vpc.kube.id}"
count = "${length(data.aws_availability_zones.az.names)}"
cidr_block = "${var.private_subnet_cidr_list[count.index]}"
availability_zone = "${data.aws_availability_zones.az.names[count.index]}"
}
Terraform utiliza dos tipos de componentes:- recurso: lo que debe crearse;
- datos: lo que necesita obtener.
En este caso, el parámetro de datos indica que Terraform debe recibir las zonas de disponibilidad de la nube especificada, que están en el estado disponible.El primer recurso de parámetro describe la creación de una nube privada virtual, y el siguiente parámetro describe la creación de la dirección IP elástica. Para el clúster de Kubernetes, pedimos esta dirección IP a través de Terraform.Además, en cada una de las zonas de accesibilidad, y en este momento CROC tiene dos servicios en la nube, se crea su propia subred. Se declara un recurso de tipo aws_subnet y el ID de aws_vpc generado se pasa como parte de este parámetro. Pero, dado que la ID de este recurso aún se desconoce, especificamos el parámetro aws_vpc.kube.id, que se refiere al recurso creado y sustituye el valor del campo ID.Dado que el número de subredes creadas está determinado por el número de zonas de disponibilidad en la nube y este número puede cambiar con el tiempo, este parámetro se especifica a través de la variable de longitud (data.aws_availability_zones.az.names), es decir, la longitud de la lista de zonas de acceso recibidas a través del parámetro de datos.Los dos últimos parámetros son cidr_block (la subred asignada) y la zona de disponibilidad en la que se crea esta subred. El último parámetro también se establece a través de una variable que toma un valor de la lista de datos de acuerdo con el índice del bucle declarado por [count.index] .Estructura de archivo Security_groups.tf
Los grupos de seguridad son un tipo de cortafuegos para las nubes, que se pueden crear no dentro de la propia máquina virtual, sino por la nube. En este caso, el firewall describe dos reglas.La primera regla crea un grupo de seguridad llamado kube. Este grupo de seguridad es necesario para permitir todo el tráfico saliente de los nodos de Kubernetes, permitiendo que los nodos accedan libremente a Internet. También se permite el tráfico entrante a los nodos de Kubernetes desde las subredes de los propios nodos. Por lo tanto, los nodos de Kubernetes pueden trabajar entre ellos sin restricciones.La segunda regla crea el grupo de seguridad ssh. Permite la conexión SSH desde cualquier dirección IP al puerto 22 de la VM del clúster Kubernetes:Revelaciónresource "aws_security_group" "kube" {
vpc_id = "${aws_vpc.kube.id}"
name = "kubernetes"
# Allow all outbound
egress {
from_port = 0
to_port = 0
protocol = "-1"
cidr_blocks = ["0.0.0.0/0"]
}
# Allow all internal
ingress {
from_port = 0
to_port = 0
protocol = "-1"
cidr_blocks = ["${var.vpc_cidr}"]
}
}
resource "aws_security_group" "ssh" {
vpc_id = "${aws_vpc.kube.id}"
name = "ssh"
# Allow all inbound
ingress {
from_port = 22
to_port = 22
protocol = "tcp"
cidr_blocks = ["0.0.0.0/0"]
}
}
Nodo maestro Estructura de archivo Master.tf
El archivo master.tf describe la creación de varias plantillas e instancias. En particular, se está creando una instancia maestra de Kubernetes.La variable ami establece el AMI de la imagen de origen para la VM. A continuación se describe el tipo de VM y la subred en la que se crea. Al definir una subred, se utiliza nuevamente un ciclo para crear máquinas virtuales en cada zona de disponibilidad.A continuación, se declaran los grupos de seguridad utilizados y la clave que se especificó en el archivo main.tf. El campo user_data contiene la ejecución de un conjunto de scripts de inicio en la nube, cuyos resultados se implementarán en la VM:Revelaciónresource "aws_instance" "master" {
count = "1"
ami = "${var.kubernetes_ami}"
instance_type = "c3.large"
disable_api_termination = false
instance_initiated_shutdown_behavior = "terminate"
source_dest_check = false
subnet_id = "${aws_subnet.private.*.id[count.index % length(data.aws_availability_zones.az.names)]}"
associate_public_ip_address = true
vpc_security_group_ids = [
"${aws_security_group.ssh.id}",
"${aws_security_group.kube.id}",
]
key_name = "${aws_key_pair.kube.key_name}"
user_data = "${data.template_cloudinit_config.master.rendered}"
monitoring = "true"
}
Nodo maestro Cloud init
Cloud-init es una herramienta que Canonical está desarrollando. Le permite ejecutar automáticamente en una infraestructura en la nube un determinado conjunto de comandos después de iniciar una VM. Terraform tiene mecanismos para integrarse usando plantillas .Dado que es imposible "hornear" todo lo necesario en la VM, después de comenzar, dependiendo de su tipo, debe unirse al clúster de Kubernetes o inicializar el clúster de Kubernetes. En la plantilla de archivo cloud-init llamada master.tpl, se realizan varias acciones.1. Se registran los archivos de configuración para Kubeadm:#cloud-config
write_files:
- path: etc/kubernetes/kubeadm.conf
owner: root:root
content:
...
2. Se ejecuta un conjunto de comandos:- la dirección IP del asistente se escribe en el archivo de configuración generado;
- el maestro en el clúster de Kubernetes se inicializa con el comando kubeadm init;
- en el clúster de Kubernetes, la red de superposición de Calico se instala con el comando kubectl apply.
runcmd:
- sed -i "s/CONTROL_PLANE_IP/$(curl http://169.254.169.254/latest/meta-data-local-ipv4)/g" /etc/kubernetes/kubeadm.conf
- kubeadm init --config /etc/kubernetes/kubeadm.conf
- mkdir -p $HOME/.kube
- sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config
- sudo chown $(id -u):$(id -g) $HOME/.kube/config
- kubectl apply -f https://docs.projectcalico.org/v3.8/manifests/calico.yaml
Después de ejecutar los comandos al iniciar la VM, se obtiene un clúster de Kubernetes en funcionamiento de un nodo maestro. Los nodos restantes se unirán a este nodo maestro.Nodos ordinarios. node.tf
El archivo node.tf es similar al archivo master.tf. Aquí también se crean recursos, que en este caso se denominan nodo. La única diferencia es que el nodo maestro se crea en una sola instancia, y el número de nodos de trabajo creados se establece a través de la variable node_count:resource "aws_instance" "node" {
count = "${var.nodes_count}"
ami = "${var.kubernetes_ami}"
instance_type = "c3.large"
El archivo de inicio de la nube para los nodos de trabajo ejecuta solo un comando: kubeadm join. Este comando conecta la máquina terminada al clúster de Kubernetes utilizando el token de autorización que enviamos.Lanzar Terraform
Cuando se inicia, Terraform utiliza varios módulos:- Módulo AWS
- módulo de plantilla;
- Módulo TLS responsable de la generación de claves.
Estos módulos deben instalarse en la máquina local:terraform init terraform/
Junto con este comando, se indica el directorio en el que se encuentran todos los archivos necesarios. Al inicializar, Terraform descarga todos los módulos especificados, después de lo cual debe ejecutar el comando de plan terraform:terraform plan -var-file terraform/vars/dev.tfvars terraform/
Tenga en cuenta que, además del directorio con los archivos de Terraform, se indica el archivo var, que contiene los valores de las variables utilizadas en los archivos de Terraform. El directorio vars puede contener múltiples archivos .tfvars, lo que le permite administrar diferentes tipos de infraestructuras con un conjunto de archivos Terraform.El archivo dev.tfvars contiene las siguientes variables importantes:- Kubernetes_version (versión instalable de Kubernetes);
- Kubernetes_ami (imagen AMI que creó Packer).
Después de establecer los valores necesarios de las variables, ejecute el comando de plan de terraform, después de lo cual Terraform presentará una lista de acciones necesarias para lograr el estado descrito en los archivos de Terraform.Después de verificar esta lista, aplique los cambios propuestos:terraform apply -auto-approve -var-file terraform/vars/dev.tfvars terraform/desde el comando de plan de terraformación, se distingue por la presencia de una clave: aprobación automática, que elimina la necesidad de confirmar los cambios realizados. Puede omitir esta clave, pero cada acción deberá confirmarse manualmente.Estructura de clúster de Kubernetes
 El clúster de Kubernetes consta de un nodo maestro que realiza funciones de administración y nodos de trabajo que ejecutan aplicaciones instaladas en el clúster.Se instalan cuatro componentes en el nodo maestro que garantizan el funcionamiento de este sistema:
El clúster de Kubernetes consta de un nodo maestro que realiza funciones de administración y nodos de trabajo que ejecutan aplicaciones instaladas en el clúster.Se instalan cuatro componentes en el nodo maestro que garantizan el funcionamiento de este sistema:- ETCD, es decir, la base de datos de Kubernetes
- Servidor API, a través del cual almacenamos información en Kubernetes y obtenemos información de ella;
- Gerente de controlador
- Programador
Se instalan dos componentes adicionales en los nodos de trabajo:- Kube-proxy (responsable de generar reglas de red en el clúster de Kubernetes);
- Kubelet (responsable de enviar el comando al demonio Docker para ejecutar aplicaciones en el clúster de Kubernetes).
Entre los nodos, el complemento de red Calico funciona.Diagrama de flujo de trabajo del clúster
, Kubernetes replicaset.
- API-, ETCD. .
- API- .
- Controller-manager API- , «», .
- Scheduler . ETCD API-.
- Kubelet API- Docker .
- Docker .
- Kubelet API- , .
, Kubernetes , . , , YAML-. , , API-. .
Kubeadm
 El último elemento que vale la pena mencionar es Kubeadm. La implementación de un nuevo clúster de Kubernetes siempre es un proceso minucioso. En cada etapa, existen riesgos de errores debido al factor humano, y muchas tareas son simplemente muy rutinarias y largas. Por ejemplo, verter certificados para el cifrado TLS entre nodos y mantenerlos actualizados. Aquí es donde las utilidades para la automatización básica de plantillas vienen al rescate. El truco de Kubeadm es que está oficialmente certificado para trabajar con Kubernetes.Te permite:
El último elemento que vale la pena mencionar es Kubeadm. La implementación de un nuevo clúster de Kubernetes siempre es un proceso minucioso. En cada etapa, existen riesgos de errores debido al factor humano, y muchas tareas son simplemente muy rutinarias y largas. Por ejemplo, verter certificados para el cifrado TLS entre nodos y mantenerlos actualizados. Aquí es donde las utilidades para la automatización básica de plantillas vienen al rescate. El truco de Kubeadm es que está oficialmente certificado para trabajar con Kubernetes.Te permite:- Instale, configure y ejecute todos los componentes principales del clúster
- administrar certificados, incluso rotarlos y escribir nuevos;
- administrar versiones de componentes del clúster (actualización y degradación).
Al mismo tiempo, Kubeadm no es un sistema completo de administración de clústeres de Kubernetes, pero es un tipo de bloque de construcción que le permite configurar Kubernetes en el nodo en el que se ejecuta la utilidad Kubeadm. Esto significa que se necesita un sistema de orquestación que ejecute todas las máquinas virtuales necesarias, las configure y ejecute Kubeadm en todos los nodos. Es para estos fines que se utiliza Terraform.Repositorio con todos los archivos
Aquí ponemos todos los archivos y configuraciones en un solo lugar, para que sea más conveniente para usted. Si no tiene una nube privada a mano, pero desea seguir todos estos pasos y probar la implementación en la práctica, escríbanos a cloud@croc.ru.Le daremos una versión demo para las pruebas y le asesoraremos sobre todos los problemas.Y pronto habrá un nuevo Slurm , donde puedes crear tu propio clúster. El código promocional CROC tiene un 10% de descuento.Para aquellos que ya trabajan con Kubernetes, hay un curso avanzado . El descuento es igual.Colegas, Habraparser rompe el marcado del código. Tome la fuente de GitHub del enlace de arriba.