Con el procesamiento complejo de grandes conjuntos de datos (diferentes procesos ETL : importaciones, conversiones y sincronización con una fuente externa), a menudo es necesario "recordar" temporalmente y procesar inmediatamente algo voluminoso.Una tarea típica de este tipo generalmente suena así: "Aquí el departamento de contabilidad cargó los últimos pagos recibidos del banco del cliente , necesitamos subirlos rápidamente al sitio web y vincularlos a las cuentas".Pero cuando el volumen de este "algo" comienza a medirse en cientos de megabytes, y el servicio Esto debería seguir funcionando con la base en modo 24x7, hay muchos efectos secundarios que arruinarán tu vida.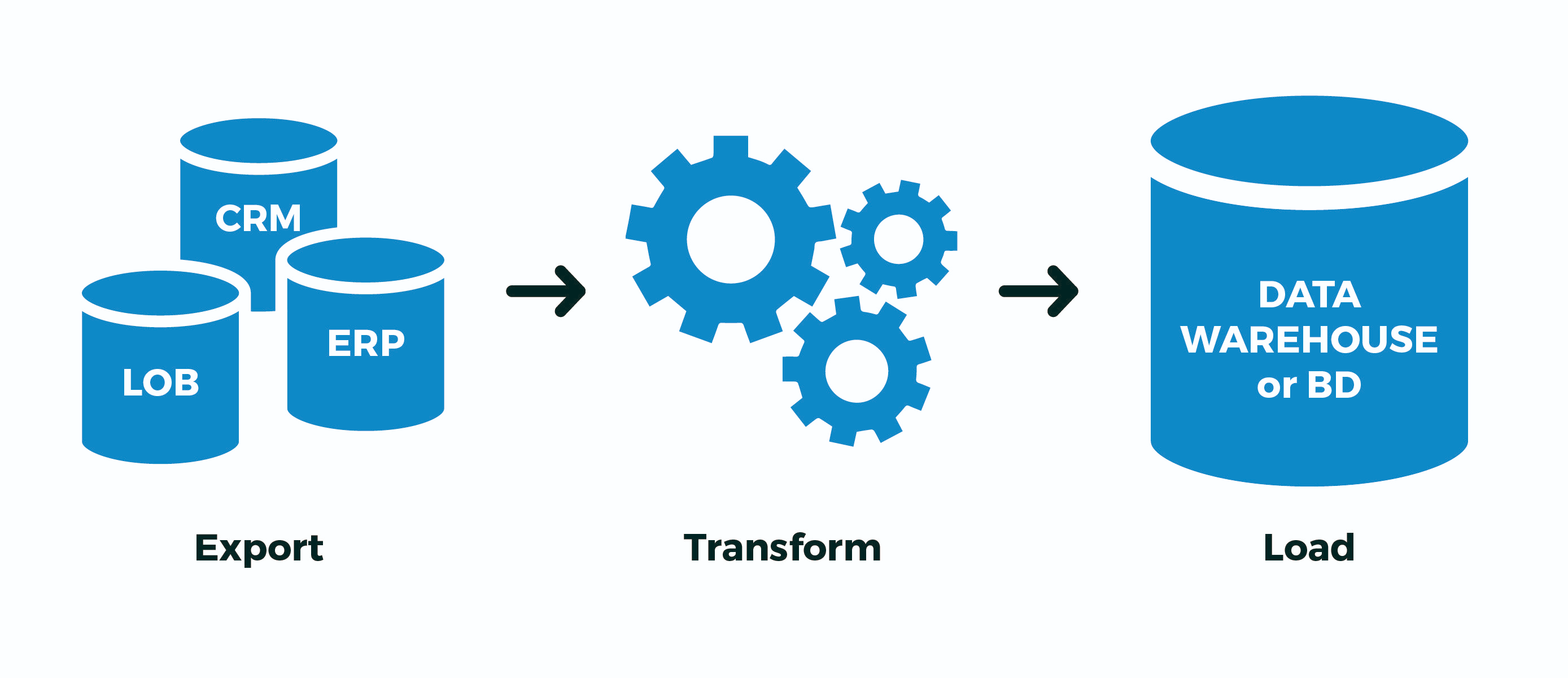 Para hacer frente a ellos en PostgreSQL (y no solo en él), puede usar algunas opciones de optimización que le permitirán procesar más rápido y con menos recursos.
Para hacer frente a ellos en PostgreSQL (y no solo en él), puede usar algunas opciones de optimización que le permitirán procesar más rápido y con menos recursos.1. ¿Dónde enviar?
Primero, decidamos dónde podemos cargar los datos que queremos "procesar".1.1. Tablas temporales (TABLA TEMPORAL)
En principio, para PostgreSQL, las temporales son las mismas tablas que cualquier otra. Por lo tanto, las supersticiones como "todo se almacena allí solo en la memoria, pero puede terminar" son incorrectas . Pero hay varias diferencias significativas.Espacio de nombres propio para cada conexión a la base de datos
Si dos conexiones intentan hacer al mismo tiempo CREATE TABLE x, entonces alguien definitivamente obtendrá un error de objetos DB no únicos .Pero si ambos intentan ejecutarse , ambos lo harán normalmente y cada uno recibirá su propia copia de la tabla. Y no habrá nada en común entre ellos.CREATE TEMPORARY TABLE x"Autodestrucción" con desconexión
Cuando cierra la conexión, todas las tablas temporales se eliminan automáticamente, por lo que DROP TABLE xno tiene sentido ejecutarlas "manualmente" , excepto ...Si trabaja a través de pgbouncer en modo de transacción , la base de datos continúa asumiendo que esta conexión todavía está activa y La mesa todavía existe.Por lo tanto, un intento de recrearlo, desde otra conexión a pgbouncer, dará como resultado un error. Pero esto se puede evitar aprovechando . Es cierto que es mejor no hacerlo de todos modos, porque entonces puede "de repente" descubrir los datos que dejó el "propietario anterior" allí. En cambio, es mucho mejor leer el manual y ver que al crear la tabla hay una oportunidad para agregarCREATE TEMPORARY TABLE IF NOT EXISTS xON COMMIT DROP - es decir, cuando se complete la transacción, la tabla se eliminará automáticamente.No replicación
Debido a que solo pertenece una combinación particular, las tablas temporales no se replican. Pero esto elimina la necesidad de escribir dos veces datos en el montón + WAL, por lo que INSERT / UPDATE / DELETE es mucho más rápido.Pero como la tabla temporal sigue siendo una tabla "casi normal", tampoco se puede crear en la réplica. Al menos por ahora, aunque el parche correspondiente ha existido durante mucho tiempo.1.2. Tablas no registradas (TABLA DESBLOQUEADA)
Pero, ¿qué hacer, por ejemplo, si tiene algún tipo de proceso ETL engorroso que no se puede implementar dentro de una sola transacción, y todavía tiene pgbouncer en modo de transacción ? ... ¿O el flujo de datos es tan grande que no hay suficiente ancho de banda por conexión? de la base de datos (lectura, un proceso en la CPU) ... ¿O parte de las operaciones se realizan de forma asíncrona en diferentes conexiones? ...Solo hay una opción: crear temporalmente una tabla no temporal . Juego de palabras, sí. Es decir:- creó "sus" tablas con nombres máximamente aleatorios para no cruzarse con nadie
- Extracto : vertió datos de una fuente externa en ellos
- Transformar : transformado, rellenado en campos de enlace clave
- Carga : vertió datos terminados en tablas de destino
- tablas "my" eliminadas
Y ahora, una mosca en la pomada. De hecho, toda la escritura en PostgreSQL ocurre dos veces : primero en el WAL , luego en el cuerpo de la tabla / índice. Todo esto se hace para admitir ACID y la visibilidad correcta de los datos entre transacciones COMMITanidadas y ROLLBACKanidadas.¡Pero no necesitamos esto! Tenemos todo el proceso o pasamos con éxito, o no . No importa cuántas transacciones intermedias contenga, no estamos interesados en "continuar el proceso desde el medio", especialmente cuando no está claro dónde estaba.Para hacer esto, los desarrolladores de PostgreSQL introdujeron la versión 9.1, como las tablas sin registro (UNLOGGED) :. , , (. 29), . , ; . , . , , .
En resumen, será mucho más rápido , pero si el servidor de la base de datos "falla", será desagradable. Pero, ¿con qué frecuencia sucede esto y su proceso ETL sabe cómo modificarlo correctamente "desde el medio" después de la "revitalización" de la base de datos?Si no es así, y el caso anterior es similar al suyo, use UNLOGGED, pero nunca incluya este atributo en tablas reales datos de los que eres querido.1.3. EN COMPROMISO {BORRAR FILAS | SOLTAR}
Este diseño permite al crear una tabla establecer un comportamiento automático cuando finaliza la transacción.Sobre lo que ya escribí anteriormente, genera , pero la situación es más interesante: aquí se genera . Dado que toda la infraestructura para almacenar la meta descripción de la tabla temporal es exactamente la misma que la habitual, la creación y eliminación constantes de tablas temporales conduce a una fuerte " expansión " de las tablas del sistema pg_class, pg_attribute, pg_attrdef, pg_depend, ... Ahora imagine que tiene un trabajador en la línea conectarse a la base de datos, que cada segundo abre una nueva transacción, crea, llena, procesa y elimina la tabla temporal ... La basura en las tablas del sistema se acumulará en exceso, y esto es frenos adicionales durante cada operación.ON COMMIT DROPDROP TABLEON COMMIT DELETE ROWSTRUNCATE TABLEEn general, no lo hagas! En este caso, es mucho más eficiente CREATE TEMPORARY TABLE x ... ON COMMIT DELETE ROWSsacarlo del ciclo de la transacción; luego, al comienzo de cada nueva transacción, la tabla ya existirá (guarde la llamada CREATE), pero estará vacía , gracias a TRUNCATE(también salvamos la llamada) al final de la transacción anterior.1.4. COMO ... INCLUYENDO ...
Mencioné al principio que uno de los casos de uso típicos para las tablas temporales es varios tipos de importaciones, y el desarrollador copia y pega cansado la lista de campos de la tabla de destino en la declaración de su temporal ... ¡Pero la pereza es el motor del progreso! Por lo tanto, crear una nueva tabla "en el modelo" puede ser mucho más simple:CREATE TEMPORARY TABLE import_table(
LIKE target_table
);
Como puede agregar muchos datos a esta tabla, las búsquedas en ella nunca serán rápidas. Pero hay una solución tradicional contra esto: ¡índices! Y sí, una tabla temporal también puede tener índices .Dado que, a menudo, los índices deseados coinciden con los índices de la tabla de destino, simplemente puede escribir . Si también necesita valores (por ejemplo, para completar los valores de la clave primaria), puede usar . Bueno, o simplemente - copiará valores predeterminados, índices, restricciones ... Pero aquí debe comprender que si creó una tabla de importación de inmediato con índices, los datos se completarán más tiempoLIKE target_table INCLUDING INDEXESDEFAULTLIKE target_table INCLUDING DEFAULTSLIKE target_table INCLUDING ALLque si primero llena todo y luego rueda los índices; mire como un ejemplo de cómo lo hace pg_dump .En definitiva, RTFM !2. ¿Cómo escribir?
Diré simplemente: use COPY-stream en lugar de "paquetes" INSERT, aceleración a veces . Incluso puede directamente desde un archivo pregenerado.3. ¿Cómo manejarlo?
Entonces, dejemos que nuestra introducción se vea más o menos así:- tiene en su base de datos una placa con datos del cliente para registros 1M
- todos los días el cliente le envía una nueva "imagen" completa
- por experiencia usted sabe que no más de 10K registros cambian de vez en cuando
Un ejemplo clásico de tal situación es la base de datos KLADR : hay muchas direcciones, pero en cada carga semanal de cambios (cambio de nombre de asentamientos, asociaciones de calles, aparición de nuevas casas) hay muy pocas, incluso en todo el país.3.1. Algoritmo de sincronización completa
Por simplicidad, supongamos que ni siquiera necesita reestructurar los datos, solo traiga la tabla en la forma correcta, es decir:- borra todo lo que ya no es
- actualice todo lo que ya estaba, y necesita actualizar
- inserte todo lo que no ha sido
¿Por qué en este orden vale la pena hacer operaciones? Porque así es como el tamaño de la tabla crece mínimamente (¡ recuerde acerca de MVCC! ).BORRAR DE dst
No, por supuesto, puedes hacer solo dos operaciones:- eliminar (
DELETE) en absoluto - pegar todo desde una nueva imagen
Pero al mismo tiempo, gracias a MVCC, ¡el tamaño de la tabla aumentará exactamente dos veces ! Obtenga registros de imágenes de + 1M en la tabla debido a la actualización de 10K, más o menos redundancia ...TRUNCATE dst
Un desarrollador más experimentado sabe que toda la placa se puede limpiar de manera bastante económica:- borrar (
TRUNCATE) toda la tabla - pegar todo desde una nueva imagen
El método es efectivo, a veces es bastante aplicable , pero hay un problema ... Completaremos 1M de registros, por lo que no podemos permitirnos dejar la tabla vacía durante todo este tiempo (como sucederá sin envolver en una sola transacción).Lo que significa:- comenzamos una transacción larga
TRUNCATEimpone AccessExclusive -Lock- hacemos el inserto durante mucho tiempo, y todos los demás en este momento ni siquiera
SELECT
Algo esta mal ...ALTERAR TABLA ... RENOMBRAR ... / DROP TABLE ...
Como opción, llene todo en una nueva tabla separada y luego simplemente cámbiele el nombre a la anterior. Un par de pequeñas cosas desagradables:- AccessExclusive también , aunque sustancialmente menos en el tiempo
- todos los planes de consulta / estadísticas de esta tabla se restablecen, es necesario conducir ANALIZAR
- todas las claves foráneas (FK) se rompen en la mesa
Hubo un parche WIP de Simon Riggs, que sugirió hacer una ALTERoperación para reemplazar el cuerpo de la tabla a nivel de archivo, sin tocar las estadísticas y FK, pero no recopiló el quórum.BORRAR, ACTUALIZAR, INSERTAR
Entonces, nos detenemos en una versión sin bloqueo de tres operaciones. Casi tres ... ¿Cómo hacer esto de manera más efectiva?
BEGIN;
CREATE TEMPORARY TABLE tmp(
LIKE dst INCLUDING INDEXES
) ON COMMIT DROP;
COPY tmp FROM STDIN;
DELETE FROM
dst D
USING
dst X
LEFT JOIN
tmp Y
USING(pk1, pk2)
WHERE
(D.pk1, D.pk2) = (X.pk1, X.pk2) AND
Y IS NOT DISTINCT FROM NULL;
UPDATE
dst D
SET
(f1, f2, f3) = (T.f1, T.f2, T.f3)
FROM
tmp T
WHERE
(D.pk1, D.pk2) = (T.pk1, T.pk2) AND
(D.f1, D.f2, D.f3) IS DISTINCT FROM (T.f1, T.f2, T.f3);
INSERT INTO
dst
SELECT
T.*
FROM
tmp T
LEFT JOIN
dst D
USING(pk1, pk2)
WHERE
D IS NOT DISTINCT FROM NULL;
COMMIT;
3.2. Importar procesamiento posterior
En el mismo KLADRE, todos los registros modificados deben ejecutarse adicionalmente a través del procesamiento posterior: normalizar, resaltar palabras clave y llevar a las estructuras necesarias. Pero, ¿cómo sabes qué ha cambiado exactamente , sin complicar el código de sincronización, idealmente sin tocarlo?Si solo su proceso tiene acceso de escritura en el momento de la sincronización, puede usar un activador que recopilará todos los cambios para nosotros:
CREATE TABLE kladr(...);
CREATE TABLE kladr_house(...);
CREATE TABLE kladr$log(
ro kladr,
rn kladr
);
CREATE TABLE kladr_house$log(
ro kladr_house,
rn kladr_house
);
CREATE OR REPLACE FUNCTION diff$log() RETURNS trigger AS $$
DECLARE
dst varchar = TG_TABLE_NAME || '$log';
stmt text = '';
BEGIN
IF TG_OP = 'UPDATE' THEN
IF NEW IS NOT DISTINCT FROM OLD THEN
RETURN NEW;
END IF;
END IF;
stmt = 'INSERT INTO ' || dst::text || '(ro,rn)VALUES(';
CASE TG_OP
WHEN 'INSERT' THEN
EXECUTE stmt || 'NULL,$1)' USING NEW;
WHEN 'UPDATE' THEN
EXECUTE stmt || '$1,$2)' USING OLD, NEW;
WHEN 'DELETE' THEN
EXECUTE stmt || '$1,NULL)' USING OLD;
END CASE;
RETURN NEW;
END;
$$ LANGUAGE plpgsql;
Ahora podemos imponer disparadores (o habilitarlos ALTER TABLE ... ENABLE TRIGGER ...) antes de comenzar la sincronización :CREATE TRIGGER log
AFTER INSERT OR UPDATE OR DELETE
ON kladr
FOR EACH ROW
EXECUTE PROCEDURE diff$log();
CREATE TRIGGER log
AFTER INSERT OR UPDATE OR DELETE
ON kladr_house
FOR EACH ROW
EXECUTE PROCEDURE diff$log();
Y luego, en silencio, de las tablas de registro extraemos todos los cambios que necesitamos y lo ejecutamos a través de controladores adicionales.3.3. Importar conjuntos relacionados
Arriba, consideramos casos en los que las estructuras de datos de la fuente y el receptor coinciden. Pero, ¿qué pasa si la descarga desde un sistema externo tiene un formato diferente de la estructura de almacenamiento en nuestra base de datos?Tome el almacenamiento de los clientes y sus cuentas como ejemplo, la opción clásica de muchos a uno:CREATE TABLE client(
client_id
serial
PRIMARY KEY
, inn
varchar
UNIQUE
, name
varchar
);
CREATE TABLE invoice(
invoice_id
serial
PRIMARY KEY
, client_id
integer
REFERENCES client(client_id)
, number
varchar
, dt
date
, sum
numeric(32,2)
);
Pero la descarga de una fuente externa nos llega en forma de "todo en uno":CREATE TEMPORARY TABLE invoice_import(
client_inn
varchar
, client_name
varchar
, invoice_number
varchar
, invoice_dt
date
, invoice_sum
numeric(32,2)
);
Obviamente, los datos del cliente pueden duplicarse de esta manera, y el registro principal es la "cuenta":0123456789;;A-01;2020-03-16;1000.00
9876543210;;A-02;2020-03-16;666.00
0123456789;;B-03;2020-03-16;9999.00
Para el modelo, simplemente inserte nuestros datos de prueba, pero recuerde, COPY¡de manera más eficiente!INSERT INTO invoice_import
VALUES
('0123456789', '', 'A-01', '2020-03-16', 1000.00)
, ('9876543210', '', 'A-02', '2020-03-16', 666.00)
, ('0123456789', '', 'B-03', '2020-03-16', 9999.00);
Primero, seleccionamos aquellos "recortes" a los que se refieren nuestros "hechos". En nuestro caso, las cuentas se refieren a clientes:CREATE TEMPORARY TABLE client_import AS
SELECT DISTINCT ON(client_inn)
client_inn inn
, client_name "name"
FROM
invoice_import;
Para asociar correctamente cuentas con ID de clientes, primero debemos descubrir o generar estos identificadores. Agregue campos para ellos:ALTER TABLE invoice_import ADD COLUMN client_id integer;
ALTER TABLE client_import ADD COLUMN client_id integer;
Utilizaremos el método de sincronización de tablas con la pequeña corrección descrita anteriormente; no actualizaremos ni eliminaremos nada en la tabla de destino, porque la importación de clientes es "solo para agregar":
UPDATE
client_import T
SET
client_id = D.client_id
FROM
client D
WHERE
T.inn = D.inn;
WITH ins AS (
INSERT INTO client(
inn
, name
)
SELECT
inn
, name
FROM
client_import
WHERE
client_id IS NULL
RETURNING *
)
UPDATE
client_import T
SET
client_id = D.client_id
FROM
ins D
WHERE
T.inn = D.inn;
UPDATE
invoice_import T
SET
client_id = D.client_id
FROM
client_import D
WHERE
T.client_inn = D.inn;
En realidad, todo: invoice_importahora hemos completado el campo de comunicación client_idcon el que insertaremos la cuenta.