Pandas no necesita presentación: hoy es la herramienta principal para analizar datos en Python. Trabajo como especialista en análisis de datos y, a pesar de que uso pandas todos los días, nunca dejo de sorprenderme de la diversidad de la funcionalidad de esta biblioteca. En este artículo quiero hablar sobre cinco funciones de pandas poco conocidas que aprendí recientemente y que ahora uso productivamente.Para principiantes: Pandas es un juego de herramientas de alto rendimiento para el análisis de datos en Python con estructuras de datos simples y convenientes. El nombre proviene del concepto de "datos de panel", un término econométrico que se refiere a datos sobre observaciones de los mismos sujetos durante diferentes períodos de tiempo.Aquí puede descargar el Jupyter Notebook con ejemplos del artículo.1. Intervalos de fechas [Intervalos de fechas]
A menudo necesita especificar rangos de fechas cuando solicita datos de una API o base de datos externa. Los pandas no nos dejarán en problemas. Solo para estos casos, existe la función data_range , que devuelve una matriz de fechas aumentadas por días, meses, años, etc.Digamos que necesitamos un rango de fechas por día:date_from = "2019-01-01"
date_to = "2019-01-12"
date_range = pd.date_range(date_from, date_to, freq="D")
date_range
 Transformaremos el generado desde
Transformaremos el generado desde date_rangeen pares de fechas "desde" y "hasta", que pueden transferirse a la función correspondiente.for i, (date_from, date_to) in enumerate(zip(date_range[:-1], date_range[1:]), 1):
date_from = date_from.date().isoformat()
date_to = date_to.date().isoformat()
print("%d. date_from: %s, date_to: %s" % (i, date_from, date_to))
1. date_from: 2019-01-01, date_to: 2019-01-02
2. date_from: 2019-01-02, date_to: 2019-01-03
3. date_from: 2019-01-03, date_to: 2019-01-04
4. date_from: 2019-01-04, date_to: 2019-01-05
5. date_from: 2019-01-05, date_to: 2019-01-06
6. date_from: 2019-01-06, date_to: 2019-01-07
7. date_from: 2019-01-07, date_to: 2019-01-08
8. date_from: 2019-01-08, date_to: 2019-01-09
9. date_from: 2019-01-09, date_to: 2019-01-10
10. date_from: 2019-01-10, date_to: 2019-01-11
11. date_from: 2019-01-11, date_to: 2019-01-12
2. Fusionar con el indicador de fuente [Fusionar con indicador]
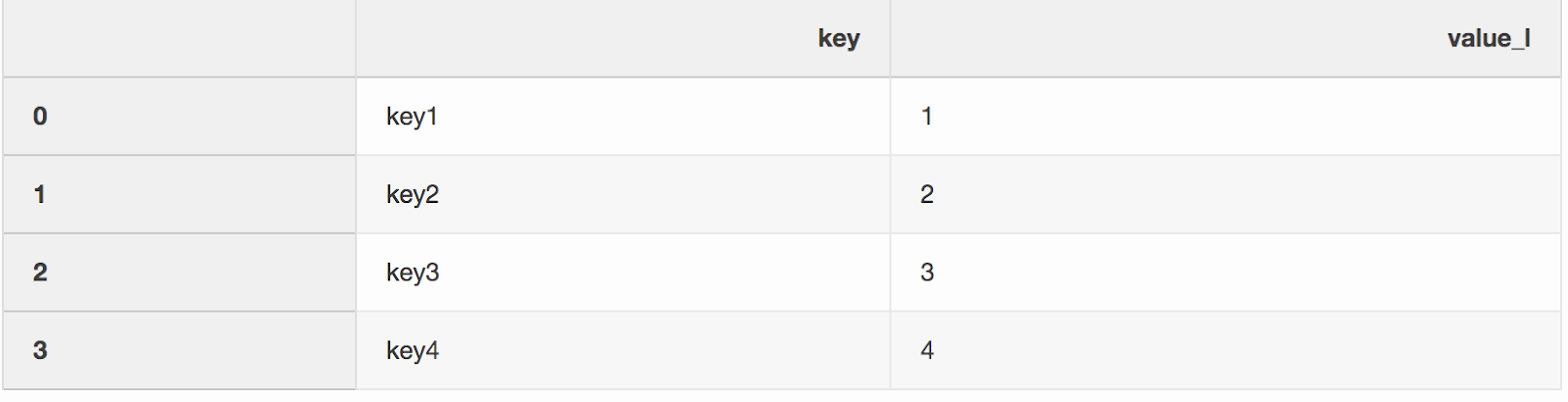
Fusionar dos conjuntos de datos es, curiosamente, el proceso de combinar dos conjuntos de datos en uno cuyas filas se asignan en función de columnas o propiedades comunes.Uno de los dos argumentos para la función de fusión, que de alguna manera me perdí, es indicator. El "Indicador" agrega una columna _mergeal DataFrame que muestra de dónde proviene la fila, desde la izquierda, la derecha o ambos DataFrames. La columna _mergepuede ser muy útil cuando se trabaja con grandes conjuntos de datos para verificar que la fusión sea correcta.left = pd.DataFrame({"key": ["key1", "key2", "key3", "key4"], "value_l": [1, 2, 3, 4]})
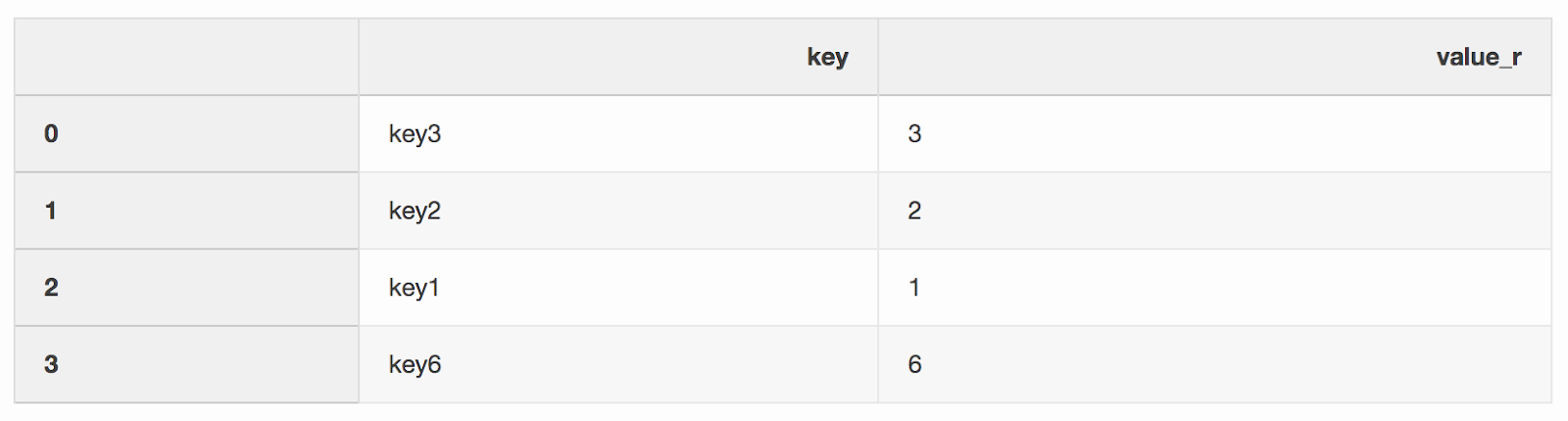
right = pd.DataFrame({"key": ["key3", "key2", "key1", "key6"], "value_r": [3, 2, 1, 6]})
df_merge = left.merge(right, on='key', how='left', indicator=True)
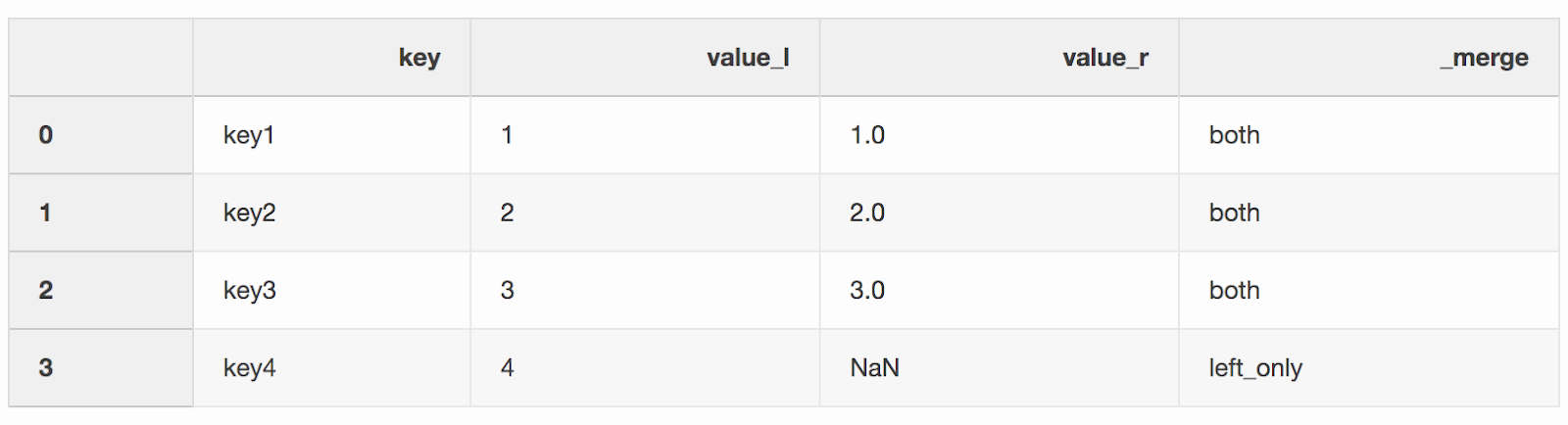 La columna
La columna _mergese puede usar para verificar si se tomó el número correcto de filas con datos de ambos DataFrames.df_merge._merge.value_counts()
both 3
left_only 1
right_only 0
Name: _merge, dtype: int64
3. Fusionar por el valor más cercano [Fusión más cercana]
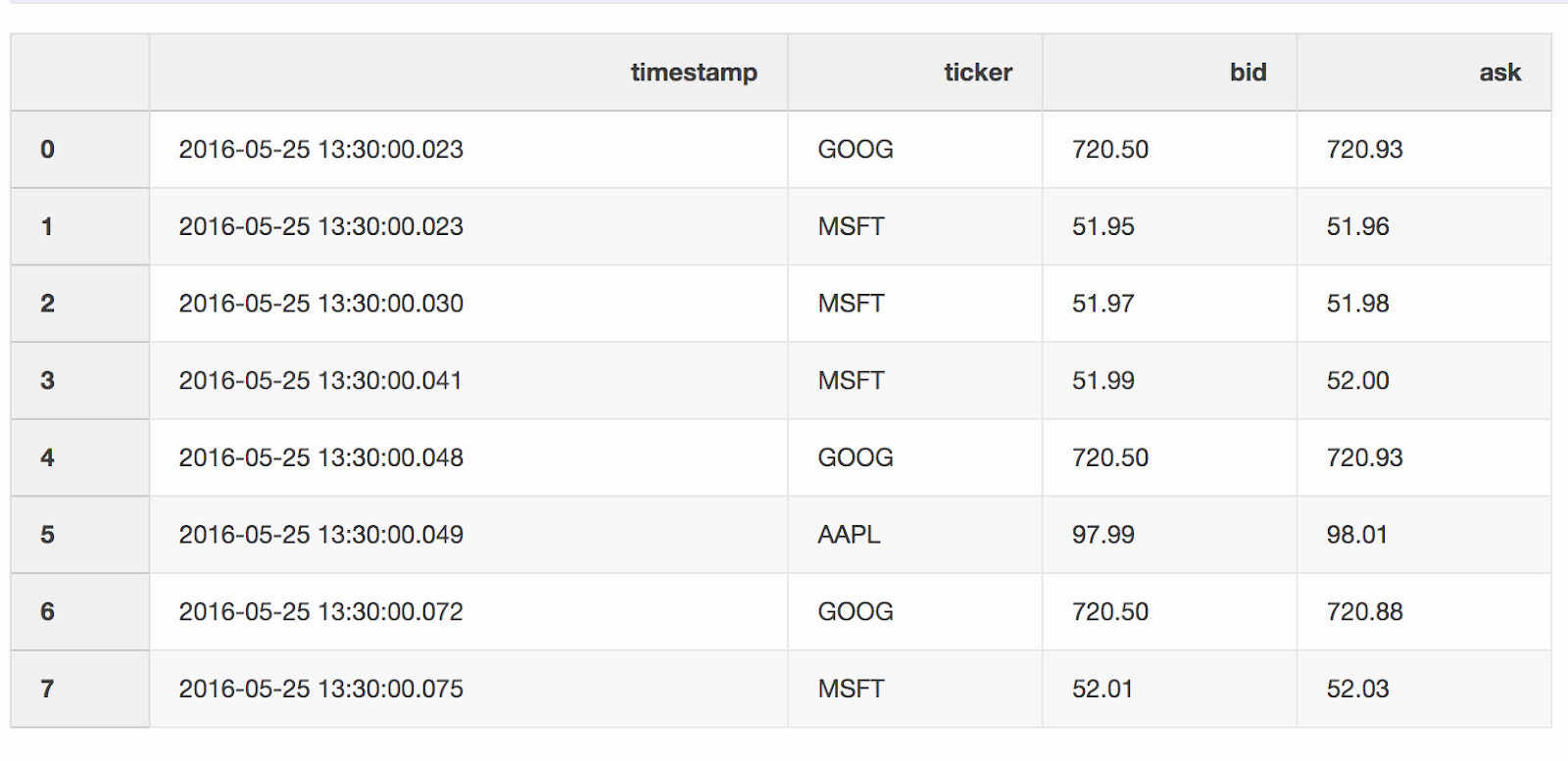
Al trabajar con datos financieros, como criptomonedas y valores, puede ser necesario comparar cotizaciones (cambios de precios) con transacciones. Digamos que queremos combinar cada operación con una cotización que se actualizó unos pocos milisegundos antes de la operación. Pandas tiene una función merge_asofdebido a la cual es posible combinar DataFrames por el valor clave más cercano ( timestampen nuestro caso). Los conjuntos de datos con citas y ofertas se toman del ejemplo de pandas .DataFrame quotes("cotizaciones") contiene cambios de precios para diferentes acciones. Como regla general, hay muchas más citas que ofertas.quotes = pd.DataFrame(
[
["2016-05-25 13:30:00.023", "GOOG", 720.50, 720.93],
["2016-05-25 13:30:00.023", "MSFT", 51.95, 51.96],
["2016-05-25 13:30:00.030", "MSFT", 51.97, 51.98],
["2016-05-25 13:30:00.041", "MSFT", 51.99, 52.00],
["2016-05-25 13:30:00.048", "GOOG", 720.50, 720.93],
["2016-05-25 13:30:00.049", "AAPL", 97.99, 98.01],
["2016-05-25 13:30:00.072", "GOOG", 720.50, 720.88],
["2016-05-25 13:30:00.075", "MSFT", 52.01, 52.03],
],
columns=["timestamp", "ticker", "bid", "ask"],
)
quotes['timestamp'] = pd.to_datetime(quotes['timestamp'])
 DataFrame
DataFrame tradescontiene ofertas para diferentes acciones.trades = pd.DataFrame(
[
["2016-05-25 13:30:00.023", "MSFT", 51.95, 75],
["2016-05-25 13:30:00.038", "MSFT", 51.95, 155],
["2016-05-25 13:30:00.048", "GOOG", 720.77, 100],
["2016-05-25 13:30:00.048", "GOOG", 720.92, 100],
["2016-05-25 13:30:00.048", "AAPL", 98.00, 100],
],
columns=["timestamp", "ticker", "price", "quantity"],
)
trades['timestamp'] = pd.to_datetime(trades['timestamp'])
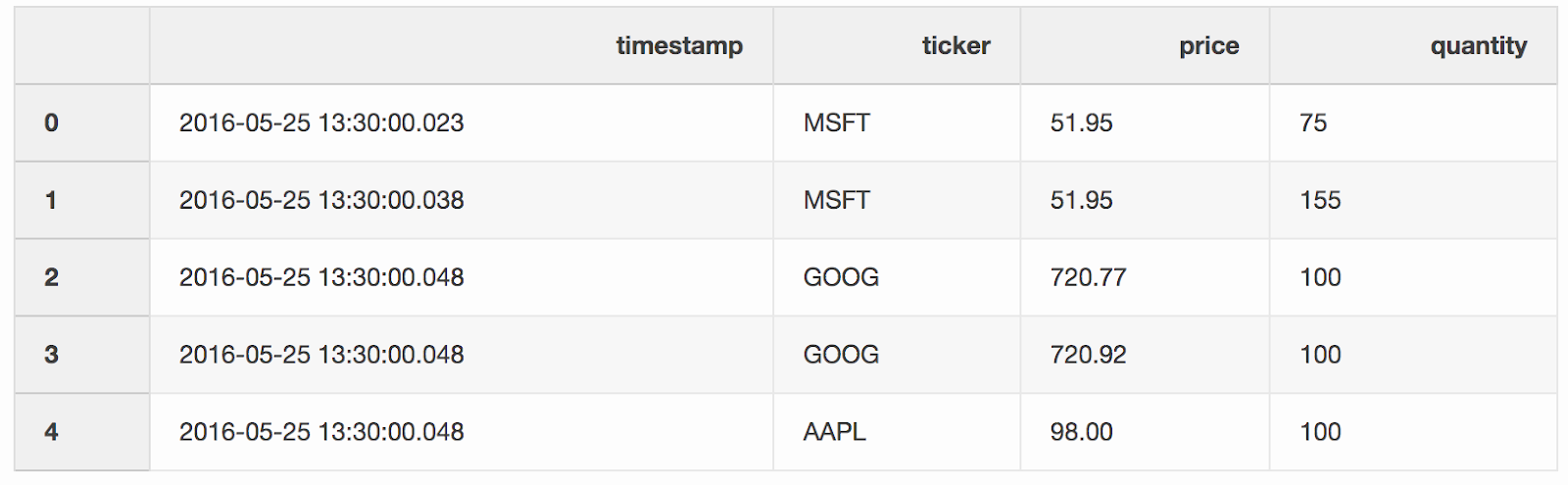 Fusionamos transacciones y cotizaciones por tickers (un instrumento cotizado, como acciones), siempre que la
Fusionamos transacciones y cotizaciones por tickers (un instrumento cotizado, como acciones), siempre que la timestampúltima cotización sea 10 ms menor que la transacción. Si la cotización apareció antes de la transacción durante más de 10 ms, la oferta (el precio que el comprador está listo para pagar) y la solicitud (el precio al que el vendedor está listo para vender) para esta cotización será null(ticker AAPL en este ejemplo).pd.merge_asof(trades, quotes, on="timestamp", by='ticker', tolerance=pd.Timedelta('10ms'), direction='backward')

4. Crear un informe de Excel
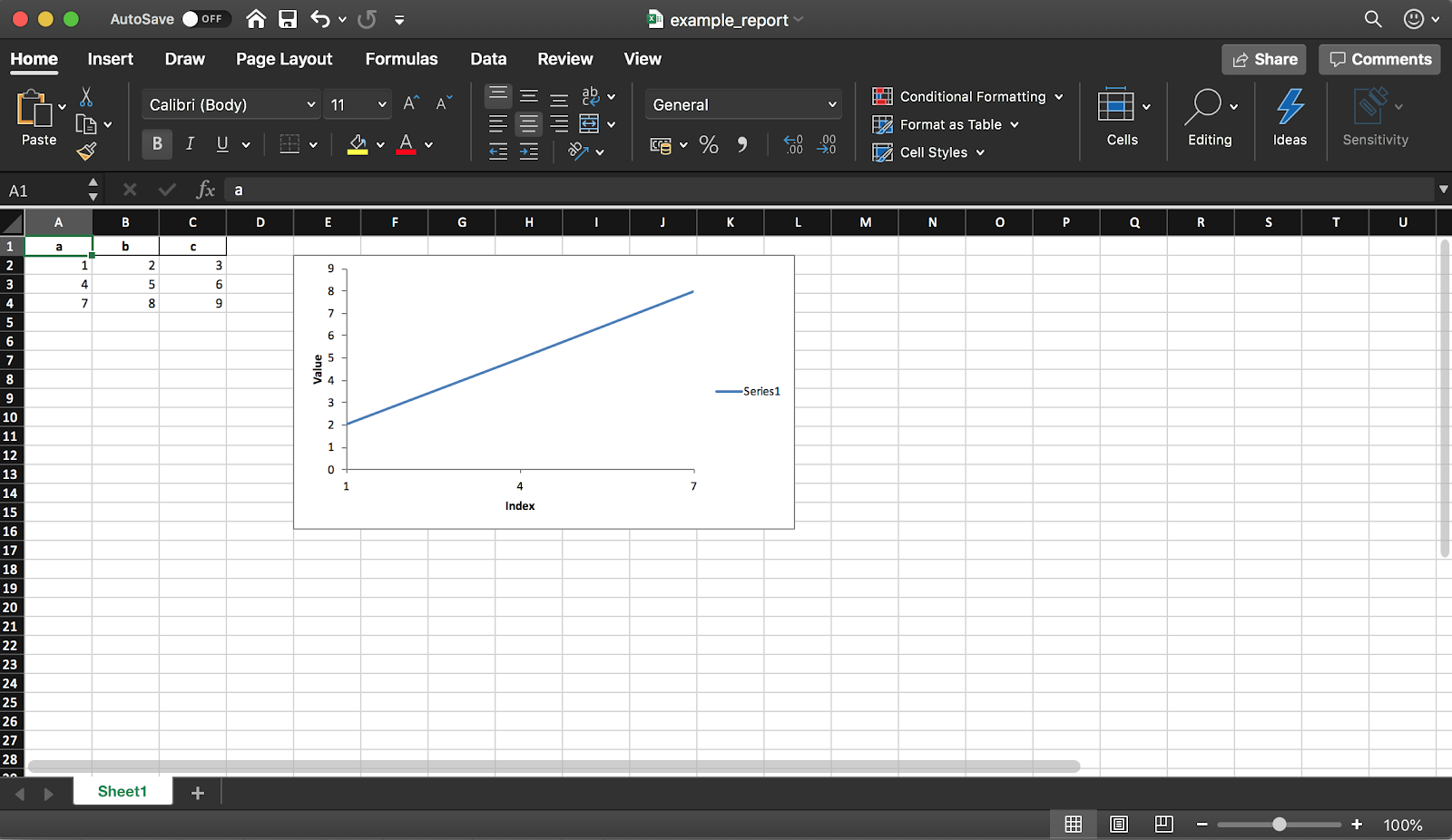 Pandas (con la biblioteca XlsxWriter) le permite crear un informe de Excel desde un DataFrame. Esto puede ahorrarle un montón de tiempo, ya no tendrá que exportar un DataFrame a CSV ni el formateo manual a Excel. Todo tipo de diagramas , etc. también están disponibles .
Pandas (con la biblioteca XlsxWriter) le permite crear un informe de Excel desde un DataFrame. Esto puede ahorrarle un montón de tiempo, ya no tendrá que exportar un DataFrame a CSV ni el formateo manual a Excel. Todo tipo de diagramas , etc. también están disponibles .df = pd.DataFrame(pd.np.array([[1, 2, 3], [4, 5, 6], [7, 8, 9]]), columns=["a", "b", "c"])
El fragmento de código a continuación crea una tabla en formato Excel. Descomente la línea para guardarla en un archivo writer.save().report_name = 'example_report.xlsx'
sheet_name = 'Sheet1'
writer = pd.ExcelWriter(report_name, engine='xlsxwriter')
df.to_excel(writer, sheet_name=sheet_name, index=False)
Como se mencionó anteriormente, al usar la biblioteca también puede agregar gráficos al informe. Debe establecer el tipo de gráfico (lineal en nuestro ejemplo) y el rango de datos (el rango de datos debe estar en la tabla de Excel).
workbook = writer.book
worksheet = writer.sheets[sheet_name]
chart = workbook.add_chart({'type': 'line'})
chart.add_series({
'categories': [sheet_name, 1, 0, 3, 0],
'values': [sheet_name, 1, 1, 3, 1],
})
chart.set_x_axis({'name': 'Index', 'position_axis': 'on_tick'})
chart.set_y_axis({'name': 'Value', 'major_gridlines': {'visible': False}})
worksheet.insert_chart('E2', chart)
writer.save()
5. Ahorra espacio en disco
El trabajo en una gran cantidad de proyectos de análisis de datos generalmente deja una marca en la forma de una gran cantidad de datos procesados de varios experimentos. El SSD en la computadora portátil se llena bastante rápido. Pandas le permite comprimir datos mientras los guarda en el disco y luego volver a leerlos desde un formato comprimido.Cree un gran DataFrame con números aleatorios.df = pd.DataFrame(pd.np.random.randn(50000,300))
 Si lo guarda como un archivo CSV, el archivo ocupará casi 300 MB en su disco duro.
Si lo guarda como un archivo CSV, el archivo ocupará casi 300 MB en su disco duro.df.to_csv('random_data.csv', index=False)
Un argumento compression='gzip'reduce el tamaño del archivo a 136 MB.df.to_csv('random_data.gz', compression='gzip', index=False)
Un archivo comprimido se lee de la misma manera que un archivo normal, por lo que no perdemos ninguna funcionalidad.df = pd.read_csv('random_data.gz')
Conclusión
Estos pequeños trucos han aumentado la productividad de mi trabajo diario con los pandas. Espero que hayas aprendido de este artículo sobre algunas características útiles que también te ayudarán a ser más productivo.¿Cuál es tu truco favorito con los pandas?