Los informes de cobertura modernos en algunos casos son bastante inútiles, y los métodos para medirlos son principalmente adecuados solo para desarrolladores. Siempre puede averiguar el porcentaje de cobertura o ver el código que no se utilizó durante las pruebas, pero ¿qué sucede si desea visibilidad, simplicidad y automatización? Bajo el corte - video y transcripción de un informe de Artem Eroshenko de Qameta Software de la conferencia Heisenbug . Introdujo varias soluciones simples y elegantes desarrolladas que ayudan al equipo de Yandex.Verticals a evaluar la cobertura de las pruebas escritas por ingenieros de automatización de pruebas. Artem le dirá cómo descubrir rápidamente qué está cubierto, qué cubierto, qué pruebas han pasado y ver instantáneamente informes visuales.Mi nombre es artyom eroshenko eroshenkoam, He estado haciendo pruebas de automatización por más de 10 años. Fui gerente de automatización de pruebas, gerente de equipo de desarrollo de herramientas, desarrollador de herramientas.Actualmente soy consultor en el campo de la automatización de pruebas, trabajo con varias empresas con las que desarrollamos procesos.También soy el desarrollador y administrador secreto de Allure Report. Recientemente arreglamos algo genial : ahora en JUnit 5 hay accesorios.
Bajo el corte - video y transcripción de un informe de Artem Eroshenko de Qameta Software de la conferencia Heisenbug . Introdujo varias soluciones simples y elegantes desarrolladas que ayudan al equipo de Yandex.Verticals a evaluar la cobertura de las pruebas escritas por ingenieros de automatización de pruebas. Artem le dirá cómo descubrir rápidamente qué está cubierto, qué cubierto, qué pruebas han pasado y ver instantáneamente informes visuales.Mi nombre es artyom eroshenko eroshenkoam, He estado haciendo pruebas de automatización por más de 10 años. Fui gerente de automatización de pruebas, gerente de equipo de desarrollo de herramientas, desarrollador de herramientas.Actualmente soy consultor en el campo de la automatización de pruebas, trabajo con varias empresas con las que desarrollamos procesos.También soy el desarrollador y administrador secreto de Allure Report. Recientemente arreglamos algo genial : ahora en JUnit 5 hay accesorios.Marco Atlas
Mi desarrollo es el Atlas Framework . Si alguien comenzó a automatizar en 2012, cuando los controladores web de Java apenas comenzaban a funcionar, en ese momento hice una biblioteca de código abierto llamada HTML Elements .Html Elements tiene su continuación y replanteamiento en la biblioteca Atlas, que se basa en interfaces: no hay clases como tales, no hay campos, una biblioteca muy conveniente, ligera y fácilmente extensible. Si desea comprenderlo, puede leer el artículo o ver el informe .Mi informe está dedicado al problema de la automatización de pruebas y principalmente a los recubrimientos. Como antecedentes, me gustaría referirme a cómo se organizan los procesos de prueba en Yandex.Verticals.¿Cómo funciona la automatización en verticales?
Solo hay cuatro personas en el equipo de automatización de pruebas de Yandex.Verticals que automatizan cuatro servicios: Yandex.Avto, Work, Real Estate y Parts. Es decir, este es un pequeño equipo de automatizadores que hacen mucho. Automatizamos la API, la interfaz web, las aplicaciones móviles, etc. En total, tenemos alrededor de 15.5 mil pruebas que se realizan en diferentes niveles.La estabilidad de las pruebas en el equipo es de aproximadamente el 97%, aunque algunos de mis colegas dicen que aproximadamente el 99%. Tal alta estabilidad se logra precisamente gracias a pruebas cortas en tecnologías muy nativas. Como regla general, nuestras pruebas toman aproximadamente 15 minutos, lo cual es muy amplio, y las ejecutamos en aproximadamente 800 hilos. Es decir, tenemos 800 navegadores que comienzan al mismo tiempo, una prueba de estrés de nuestras pruebas. Como hierro usamos Selenoid (Aerokube). Puede obtener más información sobre la automatización de pruebas en Yandex.Verticals al ver mi informe de 2017, que sigue siendo relevante.Otra característica de nuestro equipo es que automatizamos todo , incluidos los probadores manuales, que hacen una gran contribución al desarrollo de la automatización de pruebas. Para ellos, organizamos escuelas, les enseñamos exámenes, enseñamos cómo escribir exámenes para la API, la interfaz web y, a menudo, ayudan a acompañar los exámenes. Por lo tanto, los chicos responsables de la liberación pueden corregir inmediatamente la prueba, si es necesario.En Verticals, los desarrolladores de pruebas escriben pruebas, y están tan interesados en el desarrollo de pruebas que compiten con nosotros. Puede obtener más información sobre este proceso en el informe "El ciclo completo de prueba de las aplicaciones React", donde Alexei Androsov y Natalya Stus hablan sobre cómo escriben las pruebas de Unidad en Puppeteer en paralelo con nuestras pruebas de extremo a extremo de Java.Los ingenieros de automatización de pruebas también escriben pruebas en nuestro equipo. Pero a menudo estamos desarrollando algunos enfoques nuevos para optimizarlos. Por ejemplo, implementamos pruebas de captura de pantalla, pruebas a través de moki, reducción de pruebas. En general, nuestra área es principalmente desarrolladora de software en prueba (SDET), somos más sobre cómo escribir pruebas, y la base de prueba está parcialmente llena por nosotros y es respaldada por probadores manuales.Los desarrolladores también nos ayudan, y eso es genial.
El problema que surge dentro de estos procesos es que no siempre entendemos lo que ya está cubierto y lo que no. Mirando a través de 15 mil pruebas, no siempre está claro qué es exactamente lo que verificamos. Esto es especialmente cierto en el contexto de la comunicación con los gerentes, quienes, por supuesto, no evalúan, sino que monitorean y hacen preguntas. En particular, si surge la pregunta de si un botón en particular se ha probado en la interfaz o en el flujo, entonces es difícil de responder, porque debe ir al código de prueba y ver esta información.¿Qué se prueba y qué no?
Si tiene muchas pruebas en diferentes idiomas y está escrito por personas con diferentes grados de capacitación, tarde o temprano surge la pregunta: ¿estas pruebas no se cruzan en absoluto? En el contexto de este problema, el tema de la cobertura se está volviendo particularmente relevante. Voy a describir tres temas clave:- Formas de medir efectivamente la cobertura.
- Cobertura para pruebas API.
- Cobertura para pruebas web.
En primer lugar, determinemos que hay dos formas de cubrir: cubrir los requisitos y cubrir el código del producto.Cómo se mide la cobertura de requisitos
Considere la cobertura de requisitos utilizando auto.ru como ejemplo. En lugar del probador auto.ru, haría lo siguiente. En primer lugar, buscaría en Google e inmediatamente encontraría una tabla de requisitos especiales. Esta es la base de la cobertura de requisitos.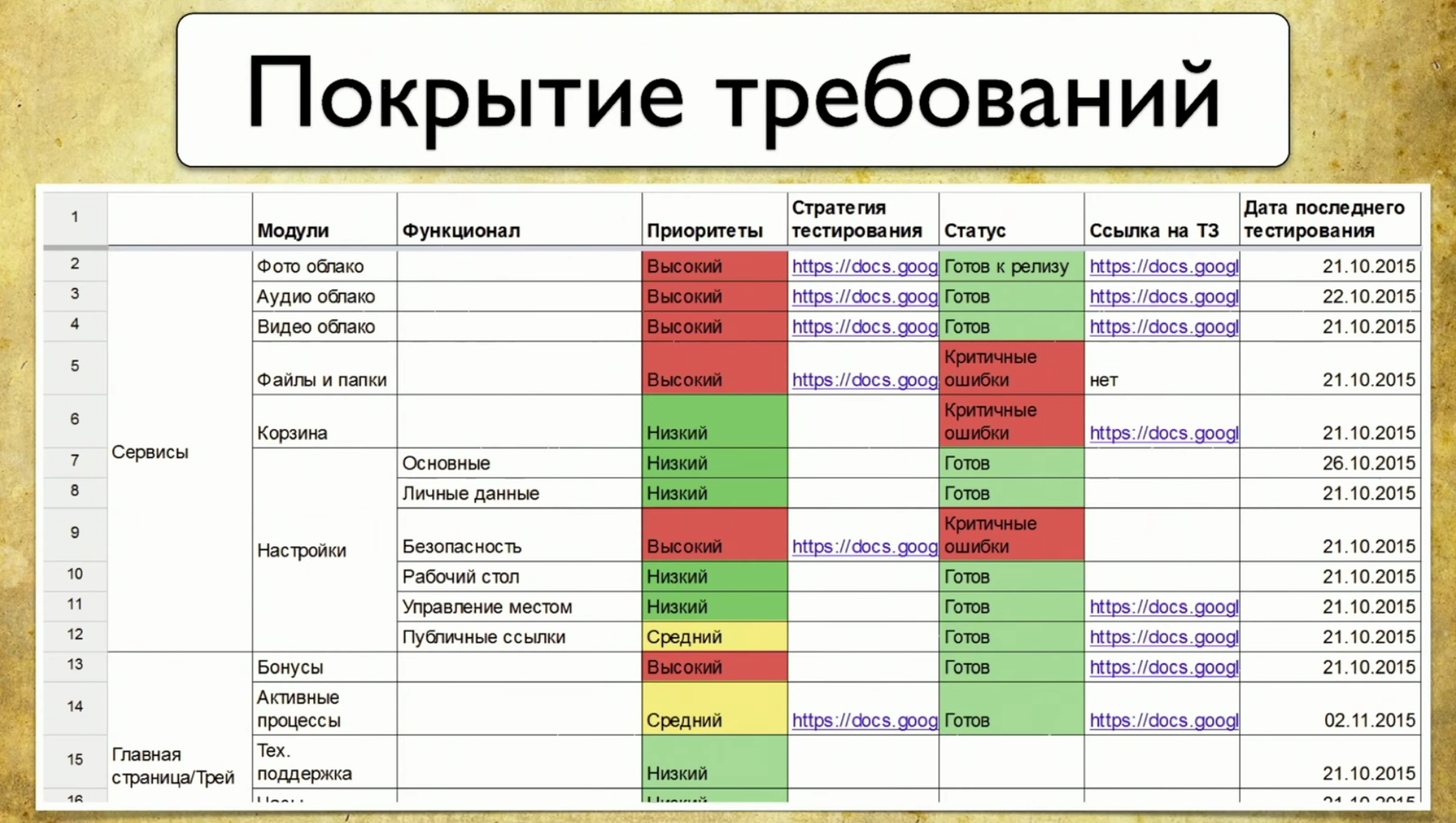 En esta tabla, los nombres de los requisitos están escritos a la izquierda. En este caso: cuenta, anuncios, verificación y pago, es decir, verificación del anuncio. En general, esta es la cobertura. El detalle de la parte izquierda depende del nivel del probador. Por ejemplo, los ingenieros de Google tienen 49 tipos de recubrimientos que se prueban en diferentes niveles.El lado derecho de la tabla son los atributos de requisitos. Podemos usar cualquier cosa en forma de atributos, por ejemplo: prioridad, cobertura y estado. Esta puede ser la fecha del último lanzamiento.
En esta tabla, los nombres de los requisitos están escritos a la izquierda. En este caso: cuenta, anuncios, verificación y pago, es decir, verificación del anuncio. En general, esta es la cobertura. El detalle de la parte izquierda depende del nivel del probador. Por ejemplo, los ingenieros de Google tienen 49 tipos de recubrimientos que se prueban en diferentes niveles.El lado derecho de la tabla son los atributos de requisitos. Podemos usar cualquier cosa en forma de atributos, por ejemplo: prioridad, cobertura y estado. Esta puede ser la fecha del último lanzamiento. Por lo tanto, algunos datos aparecen en la tabla. Puede usar herramientas profesionales para mantener una tabla de requisitos, por ejemplo, TestRail.Hay información sobre el árbol a la derecha: las carpetas indican qué requisitos tenemos, cómo se pueden cubrir. Hay casos de prueba, etc.
Por lo tanto, algunos datos aparecen en la tabla. Puede usar herramientas profesionales para mantener una tabla de requisitos, por ejemplo, TestRail.Hay información sobre el árbol a la derecha: las carpetas indican qué requisitos tenemos, cómo se pueden cubrir. Hay casos de prueba, etc. En las Verticales, este proceso se ve así: un probador manual describe los requisitos y los casos de prueba, luego los pasa a la automatización de la prueba, y la herramienta automatizada escribe el código para estas pruebas. Además, anteriormente se nos dieron casos de prueba detallados en los que el probador manual describía la estructura completa. Entonces alguien se comprometió con el github, y la prueba comenzó a ser beneficiosa.¿Cuáles son los pros y los contras de este enfoque? La ventaja es que este enfoque responde nuestras preguntas. Si el gerente pregunta qué hemos cubierto, abriré la tableta y mostraré qué funciones están cubiertas. Por otro lado, estos requisitos siempre deben mantenerse actualizados y se vuelven obsoletos muy rápidamente.Cuando tienes 15 mil pruebas, mirar TestRail es como mirar una estrella en el espacio: explotó durante mucho tiempo y la luz te ha llegado justo ahora. Miras el caso de prueba actual, y ya está desactualizado hace mucho tiempo e irrevocablemente.Este problema es difícil de resolver. Para nosotros, estos son generalmente dos mundos diferentes: hay un mundo de automatización que gira de acuerdo con sus propias leyes, donde cada prueba que falla se repara de inmediato, y hay un mundo de pruebas manuales y tarjetas de requisitos. El muro entre ellos es impenetrable, a menos que use Allure Server. Ahora solo resolvemos este problema para ellos.El tercer punto de los "pros y contras" es la necesidad de trabajo manual. En un nuevo proyecto, debe volver a crear un mapa de requisitos, escribir todos los casos de prueba, etc. Siempre requiere trabajo manual, y en realidad es muy triste.
En las Verticales, este proceso se ve así: un probador manual describe los requisitos y los casos de prueba, luego los pasa a la automatización de la prueba, y la herramienta automatizada escribe el código para estas pruebas. Además, anteriormente se nos dieron casos de prueba detallados en los que el probador manual describía la estructura completa. Entonces alguien se comprometió con el github, y la prueba comenzó a ser beneficiosa.¿Cuáles son los pros y los contras de este enfoque? La ventaja es que este enfoque responde nuestras preguntas. Si el gerente pregunta qué hemos cubierto, abriré la tableta y mostraré qué funciones están cubiertas. Por otro lado, estos requisitos siempre deben mantenerse actualizados y se vuelven obsoletos muy rápidamente.Cuando tienes 15 mil pruebas, mirar TestRail es como mirar una estrella en el espacio: explotó durante mucho tiempo y la luz te ha llegado justo ahora. Miras el caso de prueba actual, y ya está desactualizado hace mucho tiempo e irrevocablemente.Este problema es difícil de resolver. Para nosotros, estos son generalmente dos mundos diferentes: hay un mundo de automatización que gira de acuerdo con sus propias leyes, donde cada prueba que falla se repara de inmediato, y hay un mundo de pruebas manuales y tarjetas de requisitos. El muro entre ellos es impenetrable, a menos que use Allure Server. Ahora solo resolvemos este problema para ellos.El tercer punto de los "pros y contras" es la necesidad de trabajo manual. En un nuevo proyecto, debe volver a crear un mapa de requisitos, escribir todos los casos de prueba, etc. Siempre requiere trabajo manual, y en realidad es muy triste.Cómo se mide la cobertura del código
Una alternativa a este enfoque es la cobertura del código. Esta parece ser la solución a nuestro problema. Así es como se ve la cobertura del código del producto: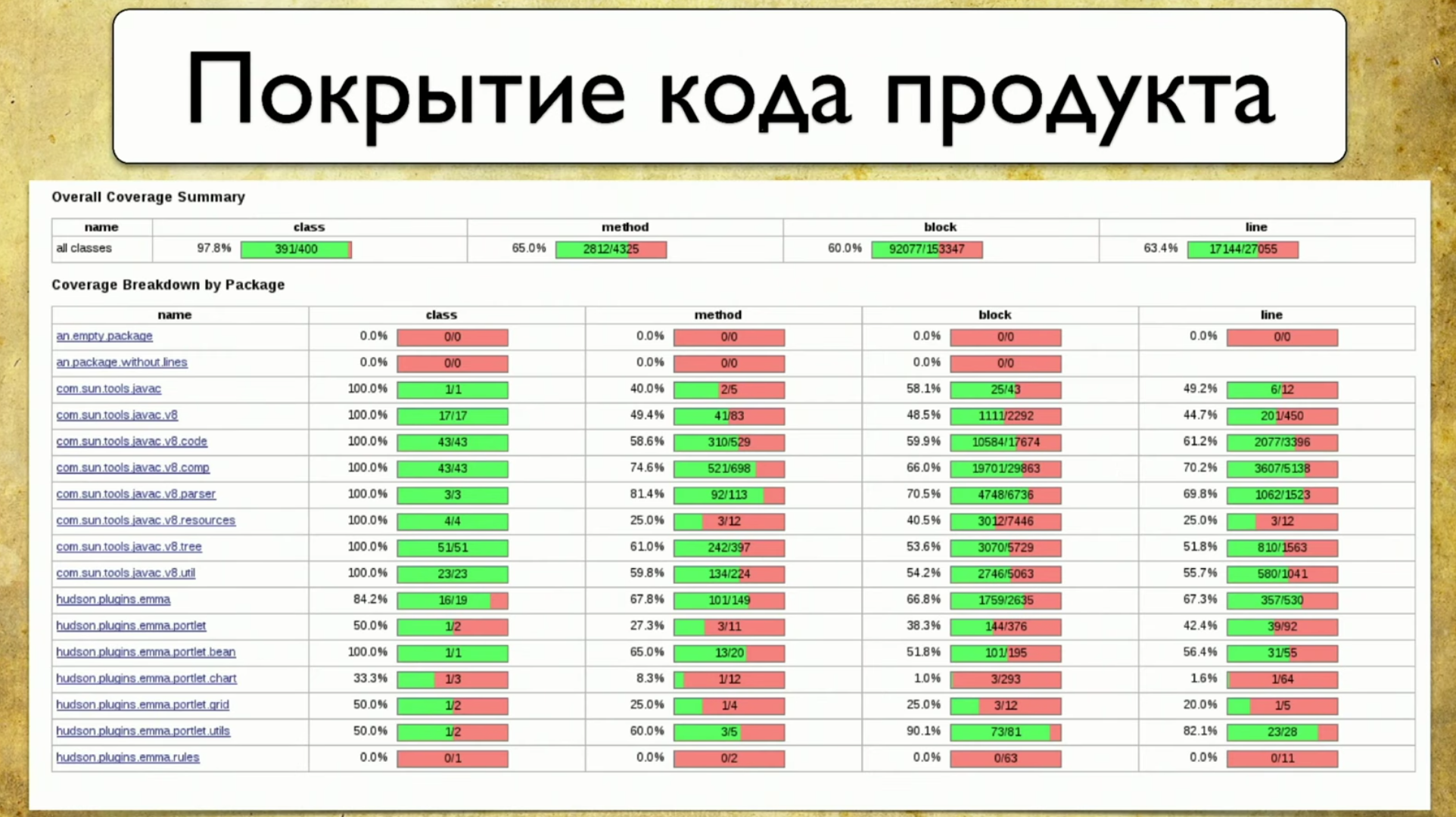 refleja la cobertura del paquete, o más bien, una pequeña parte de lo que generalmente está en el producto. El paquete está escrito a la izquierda, ya que las características se escribieron antes. Es decir, nuestro recubrimiento finalmente se une a algunas cosas tangibles, en este caso: Paquete. Los atributos están escritos a la derecha: cobertura por clase, cobertura por métodos, cobertura por bloques de código y cobertura por líneas de código.El proceso de recopilación de cobertura consiste en comprender qué línea de código pasó la prueba y cuál no. Esta es una tarea bastante simple, pero recientemente muy relevante.
refleja la cobertura del paquete, o más bien, una pequeña parte de lo que generalmente está en el producto. El paquete está escrito a la izquierda, ya que las características se escribieron antes. Es decir, nuestro recubrimiento finalmente se une a algunas cosas tangibles, en este caso: Paquete. Los atributos están escritos a la derecha: cobertura por clase, cobertura por métodos, cobertura por bloques de código y cobertura por líneas de código.El proceso de recopilación de cobertura consiste en comprender qué línea de código pasó la prueba y cuál no. Esta es una tarea bastante simple, pero recientemente muy relevante.La primera mención de la cobertura del código fue en 1963, pero el progreso serio en esta dirección aparece solo ahora.
Entonces, tenemos una prueba que interactúa con el sistema. No importa cómo interactúa con ella: a través del front-end, API o directamente se arrastra hacia el back-end, simplemente asumiremos que lo tenemos.Entonces se debe hacer la instrumentación. Este es un proceso que le permite comprender qué líneas de código se verificaron y cuáles no. No necesita estudiarlo en detalle, solo necesita buscar el nombre de su marco, en el que escribe, digamos, Spring , luego instrumentación y cobertura ; con estas tres palabras comprenderá cómo se hace esto.Cuando sus pruebas verifican qué línea de código alcanzó la prueba y cuál no, guardan archivos con información sobre qué líneas están cubiertas. Según esta información, tiene datos.¿Cuáles son los pros y los contras de la cobertura del código?
Cobertura de código llamaría inmediatamente un menos . No acudirá al gerente, no mostrará esta placa y no dirá que todos se han automatizado, ya que estos datos no se pueden leer, él le pedirá que devuelva datos claros que pueda ver rápidamente y comprender todo.Informe de cobertura de código más cercano al desarrollo. No se puede utilizar como un enfoque normal para proporcionar todos los datos a un equipo si queremos que todo el equipo pueda ver. La ventaja de este enfoque es que siempre proporciona datos relevantes. No tiene que hacer mucho trabajo, todo está automatizado para usted. Simplemente conecte la biblioteca, sus portadas comienzan a despegar, y es realmente genial.Otra ventaja de este enfoque es que solo requiere personalización. No hay nada especial que hacer allí: solo venga con una instrucción específica, ajuste la cobertura y funcionará automáticamente.La cobertura de los requisitos le permite identificar los requisitos no cumplidos, pero no permite evaluar la integridad en relación con el código. Por ejemplo, comenzó a escribir una nueva función de "autorización", simplemente ingrese la "función de autorización", comience a lanzar casos de prueba. No puede ver de inmediato esta cobertura en el código, incluso si escribe alguna clase nueva, todavía no habrá información, hay una brecha. Por otro lado, este es un requisito de autorización, incluso cuando ya esté implementado, cuando cuente la cobertura, esta parte no puede ser relevante, debe mantenerse actualizada manualmente.Por lo tanto, tuvimos una idea: ¿qué pasa si tomamos lo mejor de todos? Para que la cobertura respondiera a nuestras preguntas, siempre era relevante y solo requería personalización. Solo tenemos que mirar el recubrimiento desde un ángulo diferente, es decir, tomar otro sistema como base del recubrimiento. Al mismo tiempo, asegúrese de que se recopile de forma completamente automática y que traiga muchos beneficios. Y para esto entraremos en cobertura para las pruebas de API.
La ventaja de este enfoque es que siempre proporciona datos relevantes. No tiene que hacer mucho trabajo, todo está automatizado para usted. Simplemente conecte la biblioteca, sus portadas comienzan a despegar, y es realmente genial.Otra ventaja de este enfoque es que solo requiere personalización. No hay nada especial que hacer allí: solo venga con una instrucción específica, ajuste la cobertura y funcionará automáticamente.La cobertura de los requisitos le permite identificar los requisitos no cumplidos, pero no permite evaluar la integridad en relación con el código. Por ejemplo, comenzó a escribir una nueva función de "autorización", simplemente ingrese la "función de autorización", comience a lanzar casos de prueba. No puede ver de inmediato esta cobertura en el código, incluso si escribe alguna clase nueva, todavía no habrá información, hay una brecha. Por otro lado, este es un requisito de autorización, incluso cuando ya esté implementado, cuando cuente la cobertura, esta parte no puede ser relevante, debe mantenerse actualizada manualmente.Por lo tanto, tuvimos una idea: ¿qué pasa si tomamos lo mejor de todos? Para que la cobertura respondiera a nuestras preguntas, siempre era relevante y solo requería personalización. Solo tenemos que mirar el recubrimiento desde un ángulo diferente, es decir, tomar otro sistema como base del recubrimiento. Al mismo tiempo, asegúrese de que se recopile de forma completamente automática y que traiga muchos beneficios. Y para esto entraremos en cobertura para las pruebas de API.API de cobertura de prueba
¿Cuál es la base de la cobertura? Para hacer esto, usamos Swagger : esta es la API de documentación. Ahora no puedo imaginar mi trabajo sin Swagger, es una herramienta que uso constantemente para las pruebas. Si no usa Swagger, le recomiendo que visite el sitio y se familiarice. Allí verá de inmediato un ejemplo de uso muy intuitivo y comprensible.De hecho, Swagger es la documentación que genera su servicio. Contiene:- Lista de solicitudes.
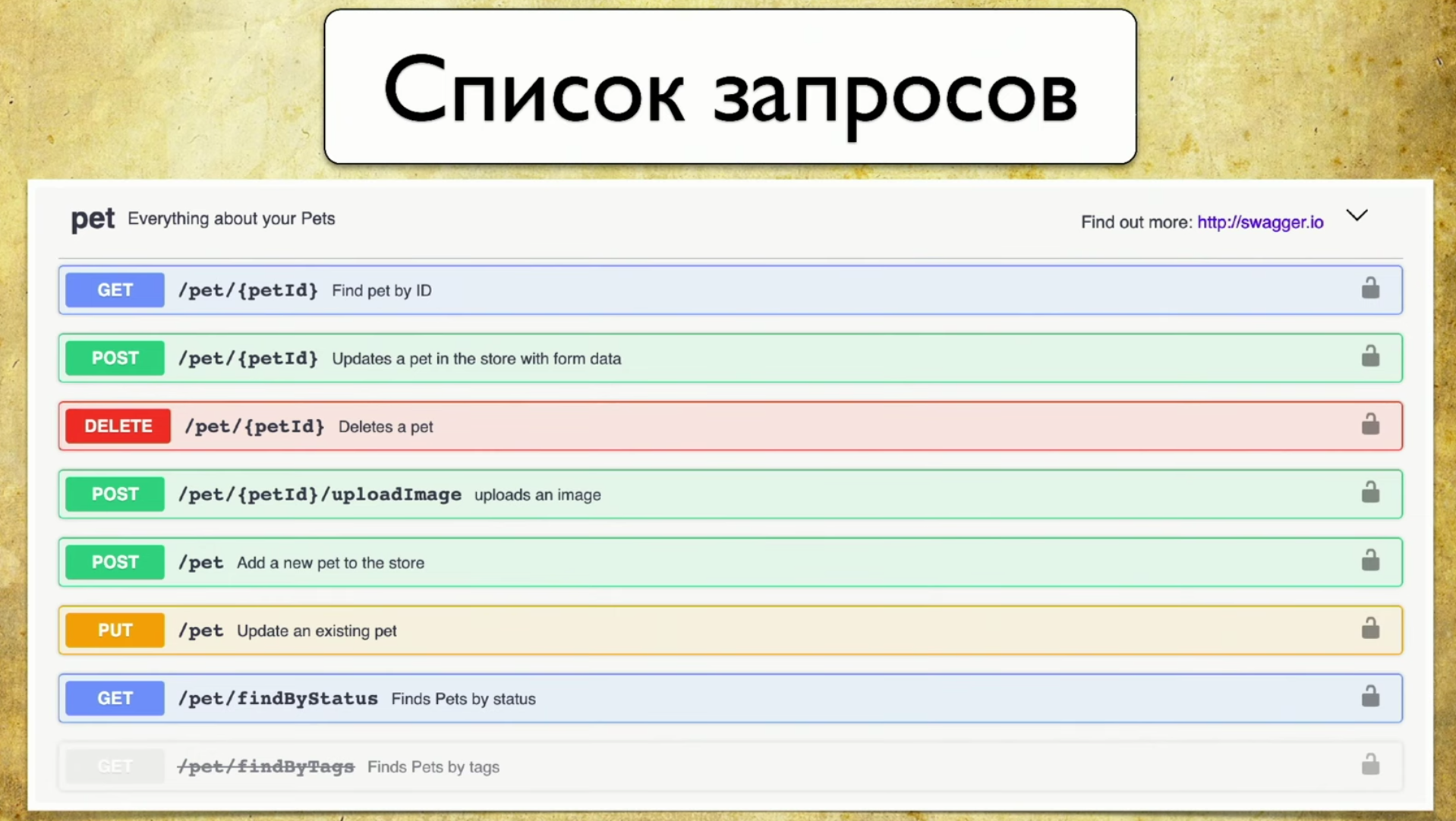
- Parámetros de solicitud: no es necesario extraer el desarrollador y preguntar qué parámetros son.
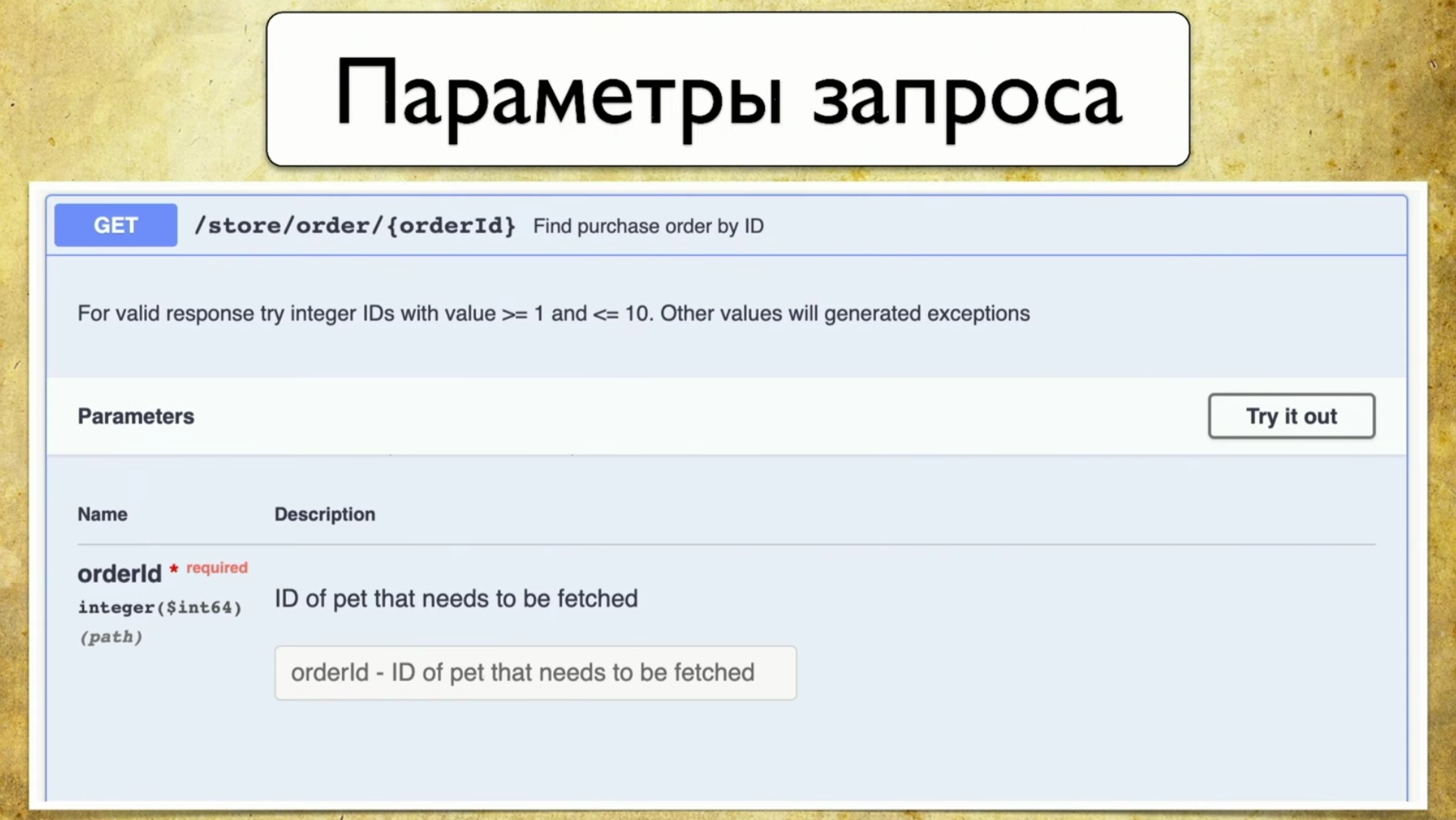
- Códigos de respuesta

El principio de funcionamiento de Swagger es la generación. No importa qué marco utilices. Digamos Spring o Go Server, usted usa el componente Swagger Codegen y genera swagger.json . Esta es una especificación, sobre la base de la cual se dibuja una hermosa interfaz de usuario.Es importante para nosotros que se use swagger.json : su soporte está disponible para todos los idiomas ampliamente utilizados.Tenemos la especificación Open API swagger.json . Se ve así: las solicitudes se ven más o menos así: resumen, descripción, códigos de respuesta y un "identificador" (ruta: / usuarios). También hay información sobre el parámetro de consulta: todo está estructurado, hay un parámetro de ID de usuario, está en la ruta donde se requiere, tal descripción y tipo - entero.
solicitudes se ven más o menos así: resumen, descripción, códigos de respuesta y un "identificador" (ruta: / usuarios). También hay información sobre el parámetro de consulta: todo está estructurado, hay un parámetro de ID de usuario, está en la ruta donde se requiere, tal descripción y tipo - entero. Hay códigos de respuesta, también están documentados:
Hay códigos de respuesta, también están documentados: Y se nos ocurrió la idea: tenemos un servicio que genera Swagger, y queríamos mantener el mismo Swagger en las pruebas, para poder compararlos más tarde. En otras palabras, cuando se ejecutan las pruebas, generan exactamente el mismo Swagger, lo arrojamos al Swagger Diff, entendemos qué parámetros, identificadores, códigos de estado que hemos verificado, etc. Esta es la misma instrumentación, la misma cobertura, solo finalmente en los requisitos que entendemos.
Y se nos ocurrió la idea: tenemos un servicio que genera Swagger, y queríamos mantener el mismo Swagger en las pruebas, para poder compararlos más tarde. En otras palabras, cuando se ejecutan las pruebas, generan exactamente el mismo Swagger, lo arrojamos al Swagger Diff, entendemos qué parámetros, identificadores, códigos de estado que hemos verificado, etc. Esta es la misma instrumentación, la misma cobertura, solo finalmente en los requisitos que entendemos.Pero, ¿y si construyes un diff?
Nos dirigimos a la biblioteca de diferencias Swagger , que es lo que necesitamos para esto. Su principio de funcionamiento es algo como esto: tiene la versión 1.0, con la versión 1.1 de la API, ambos generan swagger.json , luego los arroja a Swagger diff y ve el resultado.El resultado se ve más o menos así: tiene información de que hay, por ejemplo, una nueva pluma. También tiene información sobre lo que se elimina. Esto significa que es hora de eliminar las pruebas, ya no son relevantes. Con la aparición de información sobre los cambios, los parámetros también cambian, por lo que es obvio que sus pruebas caerán en ese momento.Nos gustó esta idea y comenzamos a implementarla. Como decidimos hacer: tenemos un Swagger de "referencia" que se genera a partir del código del desarrollador, también tenemos pruebas de API que generarán nuestro Swagger, y diferiremos entre ellos.Entonces, ejecutamos pruebas para el servicio: tenemos Rest Assured , que a su vez accede a los servicios en la API. Y lo instrumentamos. Hay un enfoque: puede hacer filtros, la solicitud va a él y guarda la información sobre la solicitud en forma de swagger.json directamente para sí mismo.Aquí está todo el código que necesitábamos para escribir, había 69-70 líneas, este es un código muy simple.
tiene información de que hay, por ejemplo, una nueva pluma. También tiene información sobre lo que se elimina. Esto significa que es hora de eliminar las pruebas, ya no son relevantes. Con la aparición de información sobre los cambios, los parámetros también cambian, por lo que es obvio que sus pruebas caerán en ese momento.Nos gustó esta idea y comenzamos a implementarla. Como decidimos hacer: tenemos un Swagger de "referencia" que se genera a partir del código del desarrollador, también tenemos pruebas de API que generarán nuestro Swagger, y diferiremos entre ellos.Entonces, ejecutamos pruebas para el servicio: tenemos Rest Assured , que a su vez accede a los servicios en la API. Y lo instrumentamos. Hay un enfoque: puede hacer filtros, la solicitud va a él y guarda la información sobre la solicitud en forma de swagger.json directamente para sí mismo.Aquí está todo el código que necesitábamos para escribir, había 69-70 líneas, este es un código muy simple. Lo curioso es que utilizamos el cliente nativo para Swagger, escribió allí mismo. Ni siquiera necesitábamos crear nuestros binarios, solo completamos la especificación Swagger.
Lo curioso es que utilizamos el cliente nativo para Swagger, escribió allí mismo. Ni siquiera necesitábamos crear nuestros binarios, solo completamos la especificación Swagger. Obtuvimos muchos archivos .json con los que tuvimos que hacer algo: escribieron un agregador Swagger. Este es un programa muy simple que funciona de acuerdo con el siguiente principio:
Obtuvimos muchos archivos .json con los que tuvimos que hacer algo: escribieron un agregador Swagger. Este es un programa muy simple que funciona de acuerdo con el siguiente principio:- Ella cumple con una nueva solicitud, si no está en nuestra base de datos, agrega.
- Ella cumple con la solicitud, él tiene un nuevo parámetro: agrega.
- Lo mismo con los códigos de estado.
Por lo tanto, obtenemos información sobre todos los bolígrafos, parámetros y códigos de estado que utilizamos. Además, aquí puede recopilar datos con los que se realizaron estas solicitudes: nombre de usuario, inicios de sesión, etc. Todavía no hemos descubierto cómo usar esta información, porque todo se genera con nosotros, pero puede entender con qué parámetros se llamaron ciertas solicitudes.Entonces, estábamos a un tiro de piedra de la victoria, pero como resultado rechazamos Swagger Diff, porque funciona en un concepto ligeramente diferente, en el concepto de diferencial.
Swagger Diff dice qué ha cambiado, no qué está cubierto, pero queríamos mostrar el resultado de la cobertura. Hay muchos datos adicionales, almacena información sobre la descripción, resumen y otra metainformación, pero no tenemos esta información. Y cuando hacemos Diff, nos escriben que "este bolígrafo no tiene una descripción", pero no existía.Propio informe
Hicimos nuestra implementación y funciona de la siguiente manera: tenemos muchos archivos que provienen de las pruebas automáticas, tenemos la API del servicio Swagger y generamos un informe basado en ella.Un informe simple se ve así: arriba puede ver información sobre cuántos bolígrafos (349) en total, información sobre qué están completamente cubiertos (cada parámetro, código de estado, etc.). Puede elegir sus propios criterios, por ejemplo, cubrir varios parámetros.También hay información aquí de que el 40% está parcialmente cubierto, esto significa que ya tenemos pruebas para estos bolígrafos, pero algunas cosas aún no están cubiertas, y debe buscar cuidadosamente allí. La cobertura vacía también se refleja.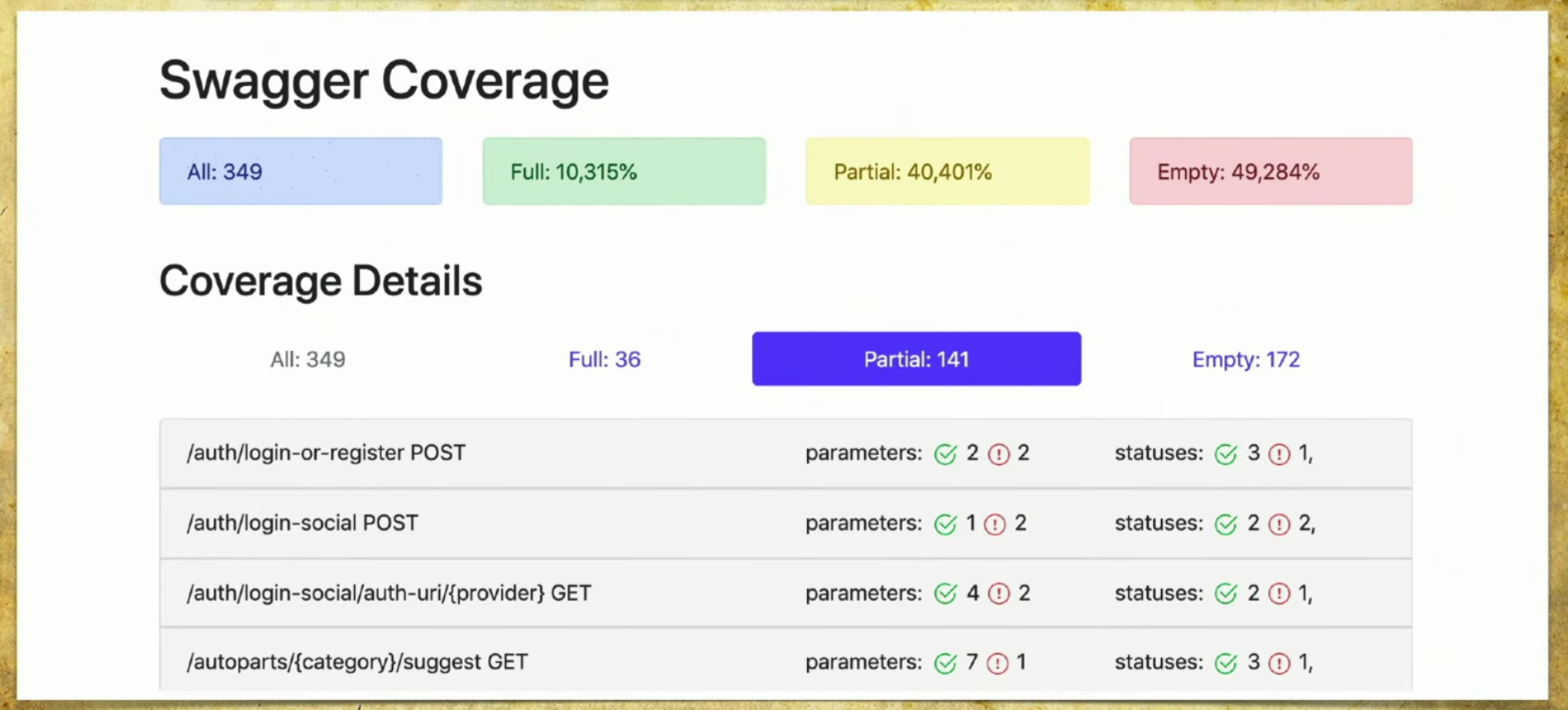 Veamos las pestañas. Esta es una cobertura completa , vemos todos los parámetros que tenemos, que están cubiertos, códigos de estado, etc.
Veamos las pestañas. Esta es una cobertura completa , vemos todos los parámetros que tenemos, que están cubiertos, códigos de estado, etc.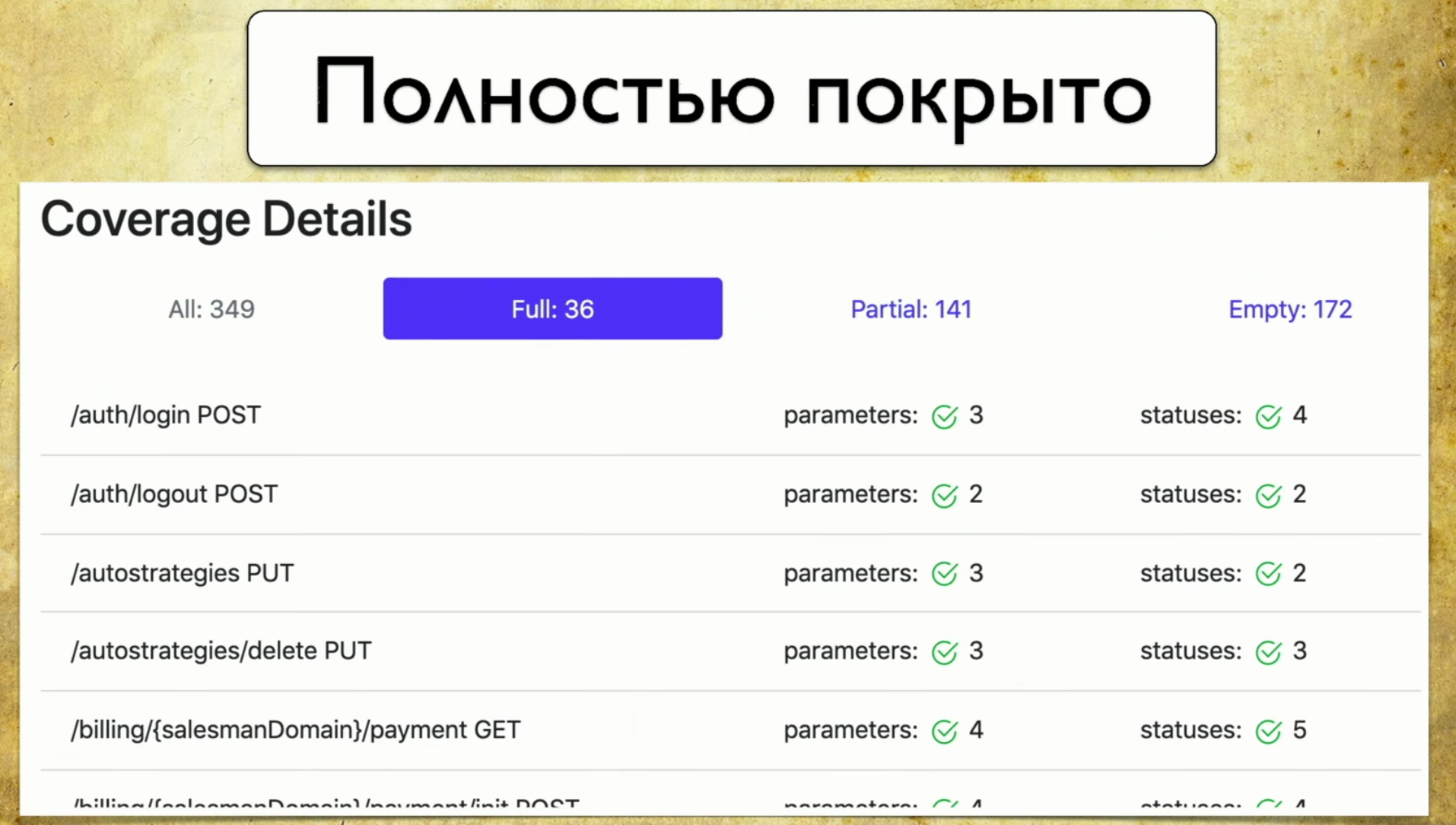 Entonces tenemos una cobertura parcial . Vemos que en el inicio de sesión social se cubre un parámetro, y dos no. Y podemos expandirlo y ver qué parámetros específicos y códigos de estado están cubiertos. Y en este momento se vuelve muy conveniente para el desarrollador: las versiones de la aplicación se ejecutan muy rápidamente, y a menudo podemos olvidar algunos parámetros.
Entonces tenemos una cobertura parcial . Vemos que en el inicio de sesión social se cubre un parámetro, y dos no. Y podemos expandirlo y ver qué parámetros específicos y códigos de estado están cubiertos. Y en este momento se vuelve muy conveniente para el desarrollador: las versiones de la aplicación se ejecutan muy rápidamente, y a menudo podemos olvidar algunos parámetros. Esta herramienta le permite estar siempre en buena forma y comprender lo que hemos cubierto parcialmente, qué parámetro se olvida, etc.Por último - Gloria de la vergüenza, todavía tenemos que hacerlo. Cuando miras esta página y ves Vacío allí: 172 - tus manos caen, y luego comienzas a enseñar a los evaluadores de mano cómo escribir autotests, ese es el punto.
Esta herramienta le permite estar siempre en buena forma y comprender lo que hemos cubierto parcialmente, qué parámetro se olvida, etc.Por último - Gloria de la vergüenza, todavía tenemos que hacerlo. Cuando miras esta página y ves Vacío allí: 172 - tus manos caen, y luego comienzas a enseñar a los evaluadores de mano cómo escribir autotests, ese es el punto.
¿Qué beneficio obtuvimos cuando lanzamos nuestra solución?
Primero, comenzamos a escribir pruebas de manera más significativa. Entendemos que estamos probando, y al mismo tiempo tenemos dos estrategias. Primero, automatizamos algo que no existe cuando vienen los probadores manuales y decimos que para un servicio en particular es fundamental que una solicitud se ejecute al menos una vez, y abrimos Empty.La segunda opción: no nos olvidamos de las colas. Como dije, las API se lanzarán muy rápidamente, puede haber algunas versiones dos o tres veces al día. Allí se agregan constantemente algunos parámetros: en cinco mil pruebas es imposible comprender qué se verifica y qué no. Por lo tanto, esta es la única forma de elegir conscientemente una estrategia de prueba y al menos hacer algo.El tercer beneficio es un proceso totalmente automático. Hemos tomado prestado el enfoque y la automatización funciona: no necesitamos hacer nada, todo se recopila automáticamente.Ideas de desarrollo
En primer lugar, realmente no quiero mantener el segundo informe, pero quiero integrarlo en la interfaz de usuario de Swagger. Este es mi "informe de Photoshop Edition" favorito: un chip que he estado desarrollando últimamente. Aquí de inmediato hay información sobre los parámetros que hemos probado y que no. Y sería genial dar esta información de inmediato con Swagger. Por ejemplo, el front-end puede ver por sí mismo qué parámetros no se han probado, priorizar y decidir que si bien no es necesario llevarlos al desarrollo, no se sabe qué tan bien funcionan. O el backend escribe un nuevo bolígrafo, ve rojo y patea probadores para que todo sea verde. Esto es bastante fácil de hacer, vamos en esta dirección.La segunda idea es apoyar otras herramientas. De hecho, no quiero escribir filtros para implementaciones específicas: para Java, Python, etc. Existe la idea de hacer un tipo de proxy que pase todas las solicitudes a través de sí mismo y guarde la información de Swagger para sí mismo. Por lo tanto, tendremos una biblioteca universal que puede usarse sin importar el idioma que tenga.La tercera idea de desarrollo es la integración con Allure Report. Lo veo así:
Por ejemplo, el front-end puede ver por sí mismo qué parámetros no se han probado, priorizar y decidir que si bien no es necesario llevarlos al desarrollo, no se sabe qué tan bien funcionan. O el backend escribe un nuevo bolígrafo, ve rojo y patea probadores para que todo sea verde. Esto es bastante fácil de hacer, vamos en esta dirección.La segunda idea es apoyar otras herramientas. De hecho, no quiero escribir filtros para implementaciones específicas: para Java, Python, etc. Existe la idea de hacer un tipo de proxy que pase todas las solicitudes a través de sí mismo y guarde la información de Swagger para sí mismo. Por lo tanto, tendremos una biblioteca universal que puede usarse sin importar el idioma que tenga.La tercera idea de desarrollo es la integración con Allure Report. Lo veo así: como regla, cuando el parámetro se "prueba", esto no siempre nos dice cómo se prueba. Y quiero señalar este parámetro y ver los pasos específicos de la prueba.
como regla, cuando el parámetro se "prueba", esto no siempre nos dice cómo se prueba. Y quiero señalar este parámetro y ver los pasos específicos de la prueba.Cobertura de pruebas web
El siguiente punto del que quiero hablar es la cobertura de las pruebas web. La cobertura se basa en el sitio que está probando, escribiendo pruebas en el sitio. Pero puede convertirlo en una interfaz web para su cobertura. Por ejemplo, se verá así: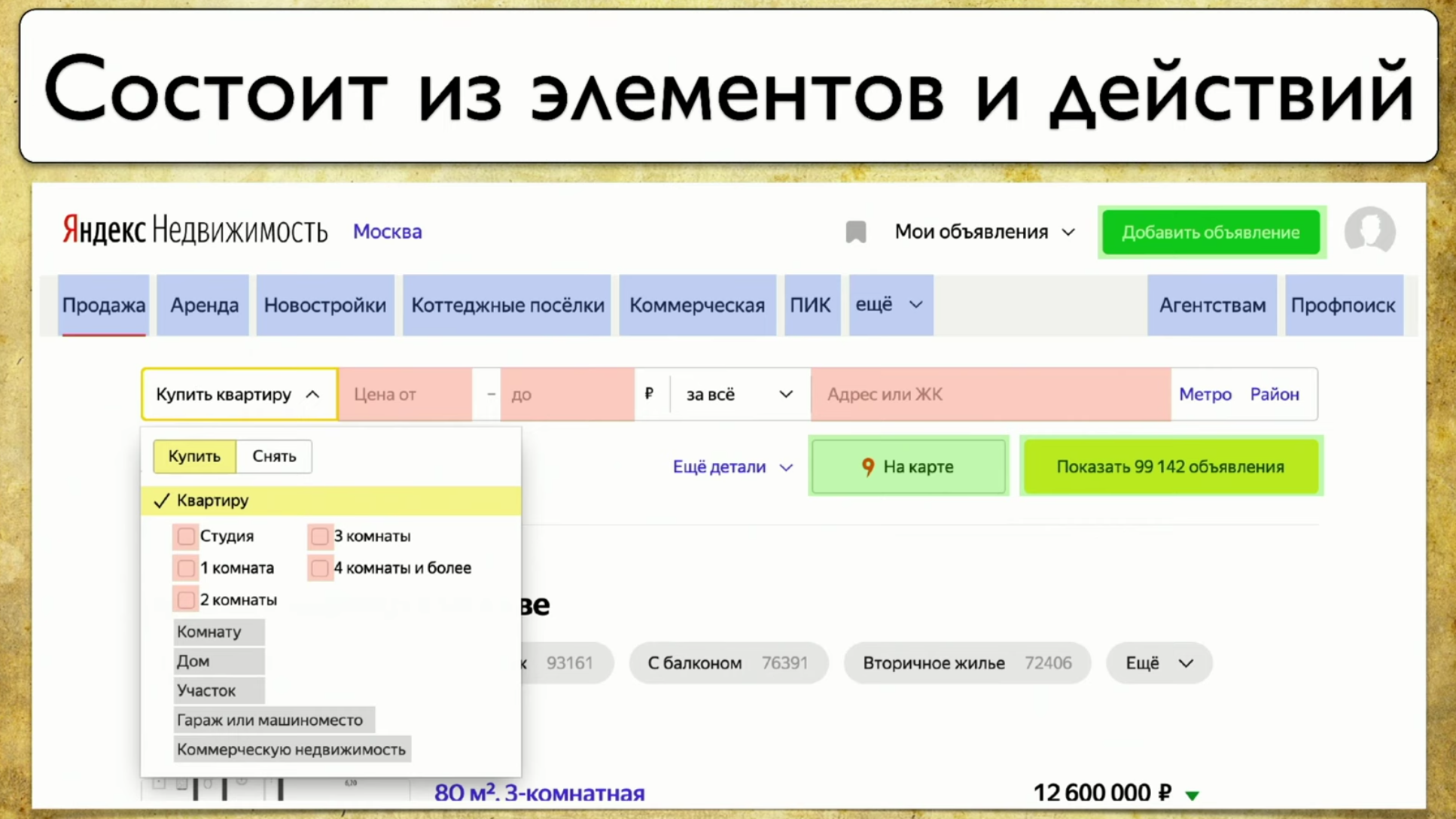 si observa su sitio, este es un conjunto de elementos y formas de interactuar con ellos. Esta es una descripción completa: "un elemento es una forma de interactuar con él". Puede hacer clic en el enlace, puede copiar el texto, puede introducir algo en la entrada. El sitio en su conjunto consta de elementos y formas de interacción:
si observa su sitio, este es un conjunto de elementos y formas de interactuar con ellos. Esta es una descripción completa: "un elemento es una forma de interactuar con él". Puede hacer clic en el enlace, puede copiar el texto, puede introducir algo en la entrada. El sitio en su conjunto consta de elementos y formas de interacción: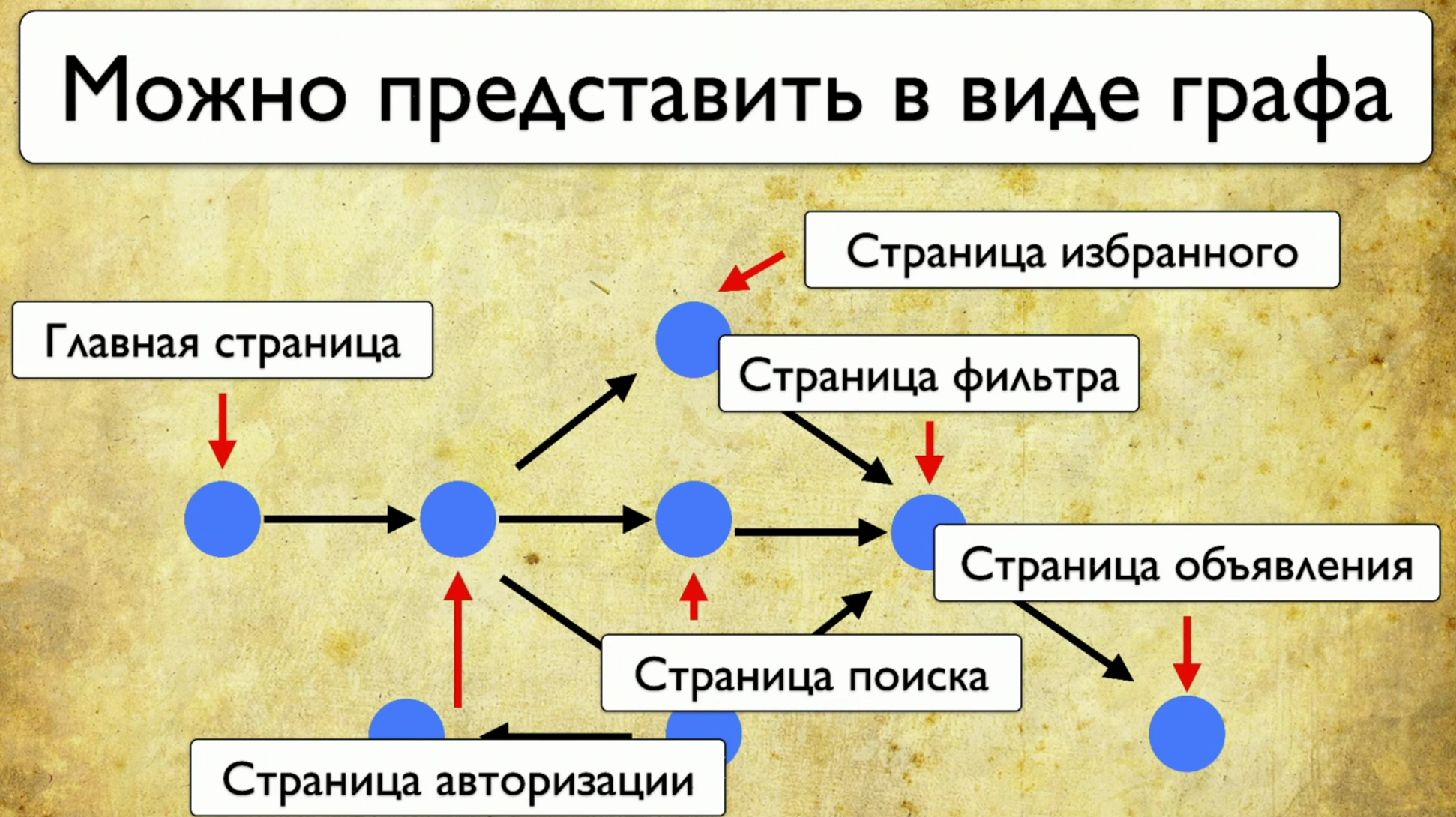 cómo se ejecutan las pruebas: comienzan desde algún punto, luego, por ejemplo, llenan un formulario, por ejemplo, un formulario de autorización, luego se dispersan a otras páginas, luego otro a otro y finalizan .Si el gerente pregunta si se está probando un botón en particular, pero esta pregunta es difícil de responder: debe abrir el código o ir a TestRail, entonces quiero ver esta solución al problema:
cómo se ejecutan las pruebas: comienzan desde algún punto, luego, por ejemplo, llenan un formulario, por ejemplo, un formulario de autorización, luego se dispersan a otras páginas, luego otro a otro y finalizan .Si el gerente pregunta si se está probando un botón en particular, pero esta pregunta es difícil de responder: debe abrir el código o ir a TestRail, entonces quiero ver esta solución al problema: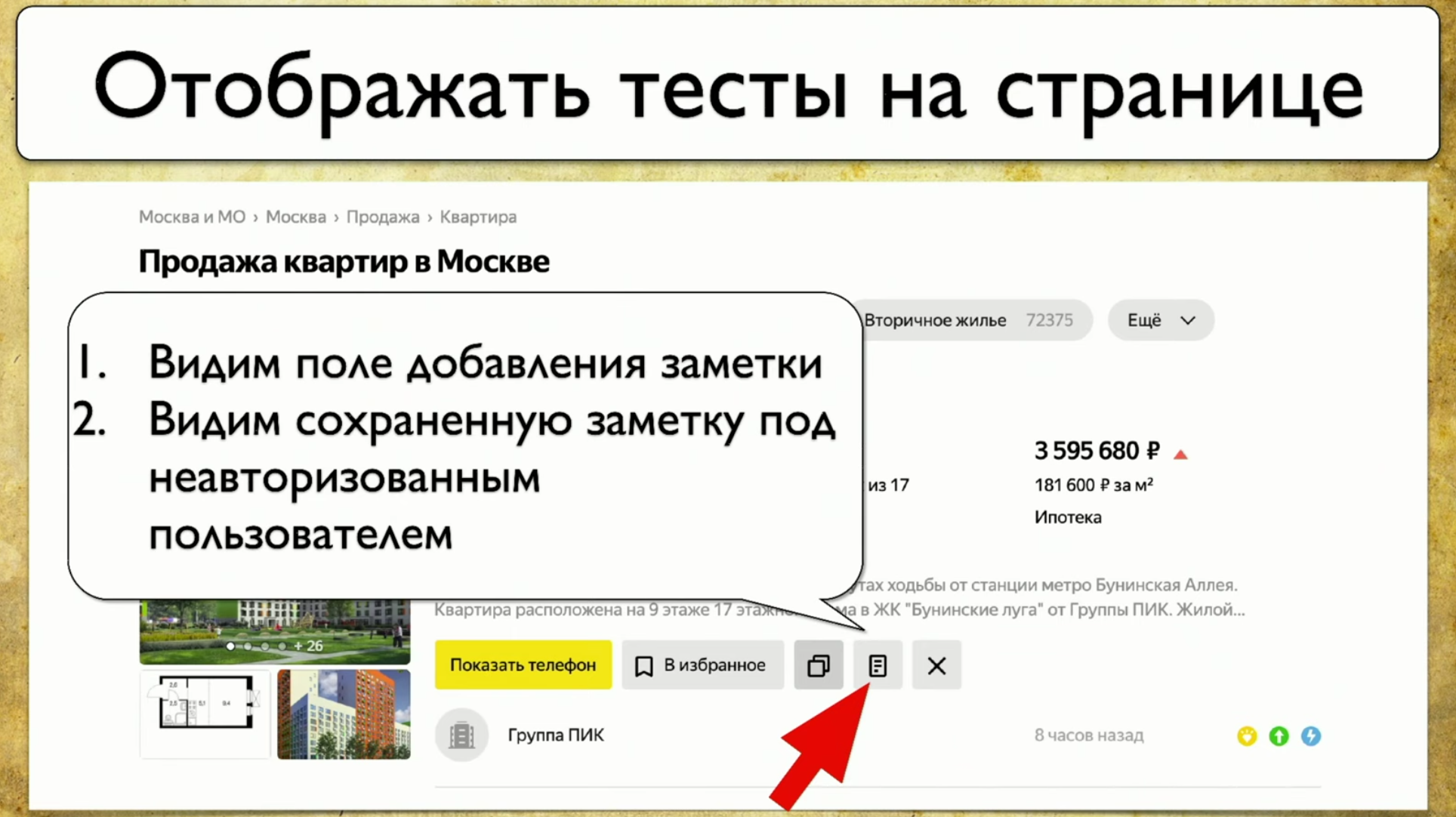 quiero señalar este elemento y ver todas las pruebas que tenemos en este artículo Si hubiera tal instrumento, sería feliz. Cuando comenzamos a pensar en esta idea, primero miramos a Yandex.Metrica. En realidad, tienen aproximadamente la misma funcionalidad que un mapa de enlaces. Una buena idea.La conclusión es que están resaltados exactamente como si ya dieran la información que necesitamos. Dicen: "Aquí hemos pasado este enlace 14 veces", lo que en traducción al lenguaje de prueba significa: "14 pruebas fueron probadas en este enlace" y de alguna manera pasaron por él. Pero este enlace rojo tomó hasta 120 pruebas, ¡qué pruebas interesantes!Puede dibujar todo tipo de tendencias, agregar metainformación, pero ¿qué sucede si lo tomamos todo y dibujamos desde el punto de vista de las pruebas? Entonces, tenemos una tarea: señalar algún elemento y obtener una nota con una lista de pruebas.
quiero señalar este elemento y ver todas las pruebas que tenemos en este artículo Si hubiera tal instrumento, sería feliz. Cuando comenzamos a pensar en esta idea, primero miramos a Yandex.Metrica. En realidad, tienen aproximadamente la misma funcionalidad que un mapa de enlaces. Una buena idea.La conclusión es que están resaltados exactamente como si ya dieran la información que necesitamos. Dicen: "Aquí hemos pasado este enlace 14 veces", lo que en traducción al lenguaje de prueba significa: "14 pruebas fueron probadas en este enlace" y de alguna manera pasaron por él. Pero este enlace rojo tomó hasta 120 pruebas, ¡qué pruebas interesantes!Puede dibujar todo tipo de tendencias, agregar metainformación, pero ¿qué sucede si lo tomamos todo y dibujamos desde el punto de vista de las pruebas? Entonces, tenemos una tarea: señalar algún elemento y obtener una nota con una lista de pruebas. Para implementar esto, debe hacer clic en el icono, luego escribir una nota, y esta es nuestra prueba completa. Usamos Atlas en nuestro lugar, y la integración hasta ahora es solo con él.Atlas se parece a esto:
Para implementar esto, debe hacer clic en el icono, luego escribir una nota, y esta es nuestra prueba completa. Usamos Atlas en nuestro lugar, y la integración hasta ahora es solo con él.Atlas se parece a esto:SearchPage.open ();
SearchPage.offersList().should(hasSizeGreaterThan(0));
Queremos que se muestre al menos un resultado, de lo contrario no lo probaremos. Luego movemos el cursor al elemento, luego hacemos clic en él.searchPage.offer(FIRST).moveCursor();
searchPage.offer(FIRST).actionBar().note().click();
Luego guardamos en la entrada User_Text y lo enviamos .searchPage.offer(FIRST).addNoteInput().sendKeys(USER_TEXT);
searchPage.offer(FIRST).saveNote().click();
Después de eso, verificamos que el texto es exactamente el que debería haber sido. searchPage.offer(FIRST).addNoteInput().should(hasValue(USER_TEXT));
Las pruebas se ejecutan en un navegador, Atlas es un proxy de esta prueba, aplicamos el mismo enfoque aquí que todos usan cuando recopilan cobertura: crearemos un localizador con .json. Guardaremos la información sobre todas las aperturas de página, todas las iteraciones con elementos, quién envió, quién envió la clave, quién hizo clic, qué ID, etc., mantendremos un registro completo.Luego adjuntamos este registro a Allure en la forma de cada prueba, y cuando tenemos muchos locators.json , generamos meta.json . El esquema es el mismo para todos los elementos.Tenemos un complemento para Google Chrome. Queríamos tomar una decisión en forma de complemento. Hice una captura de pantalla de curva especialmente para que un detalle importante fuera visible en la diapositiva: ruta a locators.json . Si generó un informe ahora, entonces hay un mapa de cobertura para hoy. Si toma el informe de las dos semanas anteriores y lo pega aquí, aparecerá un mapa de cobertura del período hace dos semanas. ¡Tienes una máquina del tiempo!Sin embargo, cuando conecta este complemento, dibuja una interfaz no tan amigable.
Si generó un informe ahora, entonces hay un mapa de cobertura para hoy. Si toma el informe de las dos semanas anteriores y lo pega aquí, aparecerá un mapa de cobertura del período hace dos semanas. ¡Tienes una máquina del tiempo!Sin embargo, cuando conecta este complemento, dibuja una interfaz no tan amigable. Cada elemento tiene una serie de pruebas que lo atraviesan: está claro que 40 pruebas pasan por "comprar un apartamento", el encabezado se prueba una prueba a la vez, es genial, y también se muestra la opción "apartamento". Obtiene un mapa de cobertura completo.Si pasa el mouse sobre algún elemento, tomará los datos e imprimirá sus pruebas reales desde su tms, Allure Board, etc. El resultado es información completa sobre lo que se está probando y cómo.Tenga en cuenta que en cada prueba puede fallar directamente en el informe de Allure.
Cada elemento tiene una serie de pruebas que lo atraviesan: está claro que 40 pruebas pasan por "comprar un apartamento", el encabezado se prueba una prueba a la vez, es genial, y también se muestra la opción "apartamento". Obtiene un mapa de cobertura completo.Si pasa el mouse sobre algún elemento, tomará los datos e imprimirá sus pruebas reales desde su tms, Allure Board, etc. El resultado es información completa sobre lo que se está probando y cómo.Tenga en cuenta que en cada prueba puede fallar directamente en el informe de Allure. Cuando abre cualquier cosa, carga nuevos selectores: si tiene alguna prueba que pasa por estos selectores e hizo algo con el sitio, procesará y mostrará la imagen completa.
Cuando abre cualquier cosa, carga nuevos selectores: si tiene alguna prueba que pasa por estos selectores e hizo algo con el sitio, procesará y mostrará la imagen completa.¿Cuál es el beneficio?
Tan pronto como implementamos este enfoque simple, principalmente, comenzamos a comprender lo que probamos en las pruebas.
Ahora cualquiera puede entrar y encontrar cualquier "hilo" que conduzca al guión. Por ejemplo, asume que necesita probar el pago. El pago, obviamente, se lleva a través del botón de pago: haga clic: aparecen todas las pruebas que pasan por el botón de pago. ¡Esto es bueno! Entras en cualquiera de ellos y ves el guión.Además, entiendes lo que se ha probado antes. Generamos un archivo estático, puede especificar la ruta e indicar qué pruebas fueron hace dos semanas. Si el gerente dice que hay un error en la producción y pregunta si probamos esta o aquella funcionalidad hace un par de semanas, usted toma el informe de Allure, por ejemplo, dice que no lo probó.Otro beneficio es la revisión después de probar la automatización. Antes de eso, teníamos una revisión antes de probar la automatización, ahora puede hacer sus pruebas exactamente como las ve. Si quería hacer una prueba, listo, tomó una rama, lanzó Allure, soltó el enlace del complemento a un probador manual y solicitó ver las pruebas. Este es exactamente el proceso que le permitirá fortalecer la estrategia Agile: el líder del equipo realiza la revisión del código y los probadores manuales hacen sus pruebas (scripts).Otra ventaja de este enfoque son los elementos de uso frecuente. Si anulamos este bloque, en el que hay 87 pruebas, todas caerán. Empiezas a entender cuán frágiles son tus exámenes. Y si se anula el "precio desde" del bloque, entonces está bien, una prueba caerá, una persona lo corregirá. Si cambia el bloque con 87 pruebas, la cobertura se reducirá considerablemente, porque 87 pruebas no pasarán y no comprobarán ningún resultado. Este bloque necesita mayor atención. Luego debe decirle al desarrollador que este bloque debe estar con una ID, porque si se va, todo se vendrá abajo.
Y si se anula el "precio desde" del bloque, entonces está bien, una prueba caerá, una persona lo corregirá. Si cambia el bloque con 87 pruebas, la cobertura se reducirá considerablemente, porque 87 pruebas no pasarán y no comprobarán ningún resultado. Este bloque necesita mayor atención. Luego debe decirle al desarrollador que este bloque debe estar con una ID, porque si se va, todo se vendrá abajo.¿Cómo puedes desarrollar más?
Por ejemplo, puede seguir el camino del desarrollo de soporte para otras herramientas, por ejemplo, para Selenide. Incluso me gustaría admitir no un Selenide específico, sino una implementación de controlador que le permita recopilar localizadores, independientemente de la herramienta que utilice. Este proxy volcará la información y luego la mostrará.Otra idea es mostrar el resultado de la prueba actual. Por ejemplo, es conveniente arrojar de inmediato una imagen de este tipo a un probador manual: no tiene que pensar qué pruebas se rompieron, porque puede ir al sitio, hacer clic en la prueba y pasarla sin verificar otras pruebas. Esto es fácil, puede recoger esta información de Allure y dibujarla aquí mismo.También puede agregar la puntuación total, porque a todos les encantan los gráficos, porque quiero lidiar con pruebas duplicadas que son muy similares entre sí, cuya parte central es la misma, y el comienzo y la cola han cambiado un poco.
no tiene que pensar qué pruebas se rompieron, porque puede ir al sitio, hacer clic en la prueba y pasarla sin verificar otras pruebas. Esto es fácil, puede recoger esta información de Allure y dibujarla aquí mismo.También puede agregar la puntuación total, porque a todos les encantan los gráficos, porque quiero lidiar con pruebas duplicadas que son muy similares entre sí, cuya parte central es la misma, y el comienzo y la cola han cambiado un poco. También me gustaría ver de inmediato la cantidad de selectores duplicados. Si es alto, entonces en esta página debe refactorizar y ejecutar pruebas, de lo contrario, se agruparán demasiado. Lo mismo ocurre con la cantidad de elementos con los que interactuamos. Este es un síntoma común. Sin embargo, tan pronto como interactúe con la página, la cifra se saltará debido a los nuevos elementos y al número total de casos de prueba, por lo que debe agregar algún tipo de análisis, no será superfluo.También puede agregar la distribución de pruebas por capas, porque desea ver no solo que tenemos estas pruebas, sino todos los tipos de pruebas que se encuentran en esta página, posiblemente incluso pruebas manuales.Por lo tanto, si hay pruebas de Java y pruebas en Puppeteer que otro equipo escribe, podemos mirar una página específica e inmediatamente decir dónde se cruzan nuestras pruebas. Es decir, hablaremos el mismo idioma con ellos y no necesitaremos recopilar esta información poco a poco. Si tenemos una herramienta que muestra todo en la interfaz web, la tarea de comparar pruebas en Java y Puppeteer ya no parece irresoluble.Finalmente, hablemos de la estrategia general. Ya hemos hablado sobre qué tipos de cobertura son, nombrados dos, se nos ocurrió un tercer tipo de recubrimiento, que usamos como resultado. Entonces tomamos y miramos este problema desde un ángulo diferente.
También me gustaría ver de inmediato la cantidad de selectores duplicados. Si es alto, entonces en esta página debe refactorizar y ejecutar pruebas, de lo contrario, se agruparán demasiado. Lo mismo ocurre con la cantidad de elementos con los que interactuamos. Este es un síntoma común. Sin embargo, tan pronto como interactúe con la página, la cifra se saltará debido a los nuevos elementos y al número total de casos de prueba, por lo que debe agregar algún tipo de análisis, no será superfluo.También puede agregar la distribución de pruebas por capas, porque desea ver no solo que tenemos estas pruebas, sino todos los tipos de pruebas que se encuentran en esta página, posiblemente incluso pruebas manuales.Por lo tanto, si hay pruebas de Java y pruebas en Puppeteer que otro equipo escribe, podemos mirar una página específica e inmediatamente decir dónde se cruzan nuestras pruebas. Es decir, hablaremos el mismo idioma con ellos y no necesitaremos recopilar esta información poco a poco. Si tenemos una herramienta que muestra todo en la interfaz web, la tarea de comparar pruebas en Java y Puppeteer ya no parece irresoluble.Finalmente, hablemos de la estrategia general. Ya hemos hablado sobre qué tipos de cobertura son, nombrados dos, se nos ocurrió un tercer tipo de recubrimiento, que usamos como resultado. Entonces tomamos y miramos este problema desde un ángulo diferente.Por un lado, hay una cobertura que se inició desde 1963, por otro lado, hay probadores manuales que están acostumbrados a vivir en un mundo más real que el código. Solo queda combinar estos dos enfoques.
Los interesados siempre pueden unirse a nuestra comunidad. Aquí hay dos repositorios de nuestros muchachos que se ocupan del problema de cobertura: