 En octubre del año pasado, se celebró la primera conferencia en la nube Yandex Yandex Scale. Anunció el lanzamiento de muchos servicios nuevos, incluido Yandex IoT Core, que le permite intercambiar datos con millones de dispositivos IoT.En este artículo, hablaré sobre por qué se necesita Yandex IoT Core y cómo funciona, así como también cómo puede interactuar con otros servicios de Yandex.Cloud. Aprenderá sobre la arquitectura, las complejidades de la interacción de los componentes y las características de la implementación de la funcionalidad; todo esto lo ayudará a optimizar el uso de estos servicios.Primero, recordemos las principales ventajas de las nubes públicas y PaaS: reducir el tiempo y los costos de desarrollo, así como los costos de soporte e infraestructura, que también son relevantes para los proyectos de IoT. Pero hay algunas características útiles menos obvias que puede obtener en la nube. Esta escala efectiva y tolerancia a fallas son aspectos importantes cuando se trabaja con dispositivos, especialmente en proyectos para infraestructura de información crítica.El escalado efectivo es la capacidad de aumentar o disminuir libremente el número de dispositivos sin experimentar problemas técnicos y ver un cambio predecible en el costo del sistema después de los cambios.La tolerancia a fallas es la confianza de que los servicios están diseñados e implementados de tal manera que se garantice el mayor rendimiento posible incluso en caso de falla de algunos recursos.Ahora entremos en los detalles.
En octubre del año pasado, se celebró la primera conferencia en la nube Yandex Yandex Scale. Anunció el lanzamiento de muchos servicios nuevos, incluido Yandex IoT Core, que le permite intercambiar datos con millones de dispositivos IoT.En este artículo, hablaré sobre por qué se necesita Yandex IoT Core y cómo funciona, así como también cómo puede interactuar con otros servicios de Yandex.Cloud. Aprenderá sobre la arquitectura, las complejidades de la interacción de los componentes y las características de la implementación de la funcionalidad; todo esto lo ayudará a optimizar el uso de estos servicios.Primero, recordemos las principales ventajas de las nubes públicas y PaaS: reducir el tiempo y los costos de desarrollo, así como los costos de soporte e infraestructura, que también son relevantes para los proyectos de IoT. Pero hay algunas características útiles menos obvias que puede obtener en la nube. Esta escala efectiva y tolerancia a fallas son aspectos importantes cuando se trabaja con dispositivos, especialmente en proyectos para infraestructura de información crítica.El escalado efectivo es la capacidad de aumentar o disminuir libremente el número de dispositivos sin experimentar problemas técnicos y ver un cambio predecible en el costo del sistema después de los cambios.La tolerancia a fallas es la confianza de que los servicios están diseñados e implementados de tal manera que se garantice el mayor rendimiento posible incluso en caso de falla de algunos recursos.Ahora entremos en los detalles.IoT Script Architecture
Primero, veamos cómo se ve la arquitectura general del script IoT. En él se pueden distinguir dos partes grandes:
En él se pueden distinguir dos partes grandes:- El primero es la entrega de datos al almacenamiento y la entrega de comandos a los dispositivos. Cuando crea un sistema IoT, esta tarea debe resolverse en cualquier caso, sin importar el proyecto que realice.
- El segundo está trabajando con los datos recibidos. Todo es similar a cualquier otro proyecto basado en el análisis y visualización de conjuntos de datos. Tiene un repositorio con una matriz inicial de información, trabajando con el cual le permitirá realizar su tarea.
La primera parte es aproximadamente la misma en todos los sistemas IoT: se basa en principios generales y se ajusta a un escenario común adecuado para la mayoría de los sistemas IoT.La segunda parte es casi siempre única en términos de las funciones realizadas, aunque se basa en componentes estándar. Al mismo tiempo, sin un sistema escalable, tolerante a fallas y de alta calidad para interactuar con el hardware, la efectividad de la parte analítica de la arquitectura se reduce a casi cero, porque simplemente no hay nada que analizar.Es por eso que el equipo de Yandex.Cloud decidió en primer lugar concentrarse en la construcción de un ecosistema conveniente de servicios que entregara datos de dispositivos de manera rápida, eficiente y confiable y viceversa, enviar comandos a los dispositivos. Para resolver estos problemas, estamos trabajando en la funcionalidad e integración de Yandex IoT Core, Yandex Functions y servicios de almacenamiento de datos en la nube:
Para resolver estos problemas, estamos trabajando en la funcionalidad e integración de Yandex IoT Core, Yandex Functions y servicios de almacenamiento de datos en la nube:- El servicio Yandex IoT Core es un bróker MQTT escalable a prueba de fallos de múltiples inquilinos con un conjunto de funciones útiles adicionales.
- El servicio Yandex Cloud Functions es un representante de la prometedora dirección sin servidor y le permite ejecutar su código como una función en un entorno seguro, tolerante a fallas y escalable automáticamente sin crear y mantener máquinas virtuales.
- Yandex Object Storage es un almacenamiento efectivo de grandes matrices de datos y es muy adecuado para registros de archivos "históricos".
- , , Yandex Managed Service for ClickHouse, «» . «» , , , .
Si los servicios de almacenamiento y análisis de datos son servicios de "propósito general" que ya se han escrito sobre mucho, entonces Yandex IoT Core y su interacción con Yandex Cloud Functions generalmente generan muchas preguntas, especialmente para las personas que recién comienzan a comprender Internet de las cosas y las tecnologías de la nube. Y dado que estos servicios proporcionan tolerancia a fallas y escalado del trabajo con dispositivos, primero veremos qué tienen debajo del capó.Cómo funciona Yandex IoT Core
Yandex IoT Core es un servicio de plataforma especializado para el intercambio de datos bidireccional entre la nube y los dispositivos que ejecutan el protocolo MQTT. De hecho, este protocolo se ha convertido en el estándar para transferir datos a IoT. Utiliza el concepto de colas con nombre (temas), donde, por un lado, puede escribir datos y, por otro lado, recibirlos de forma asincrónica suscribiéndose a eventos de esta cola.El servicio Yandex IoT Core es multiinquilino, lo que significa una única entidad que es accesible para todos los usuarios. Es decir, todos los dispositivos y todos los usuarios interactúan con la misma instancia de servicio.Esto permite, por un lado, garantizar la uniformidad del trabajo para todos los usuarios, por otro lado, una escala efectiva y tolerancia a fallas, para mantener una conexión con un número ilimitado de dispositivos y procesar una cantidad ilimitada de datos tanto en volumen como en velocidad.De ello se deduce que el servicio debe tener mecanismos de redundancia y la capacidad de administrar de manera flexible los recursos utilizados, a fin de responder a los cambios de carga.Además, la tenencia múltiple requiere una lógica especial para compartir los derechos de acceso a los temas de MQTT.Veamos cómo se implementa esto.Al igual que muchos otros servicios de Yandex.Cloud, Yandex IoT Core se divide lógicamente en dos partes: plano de control y plano de datos: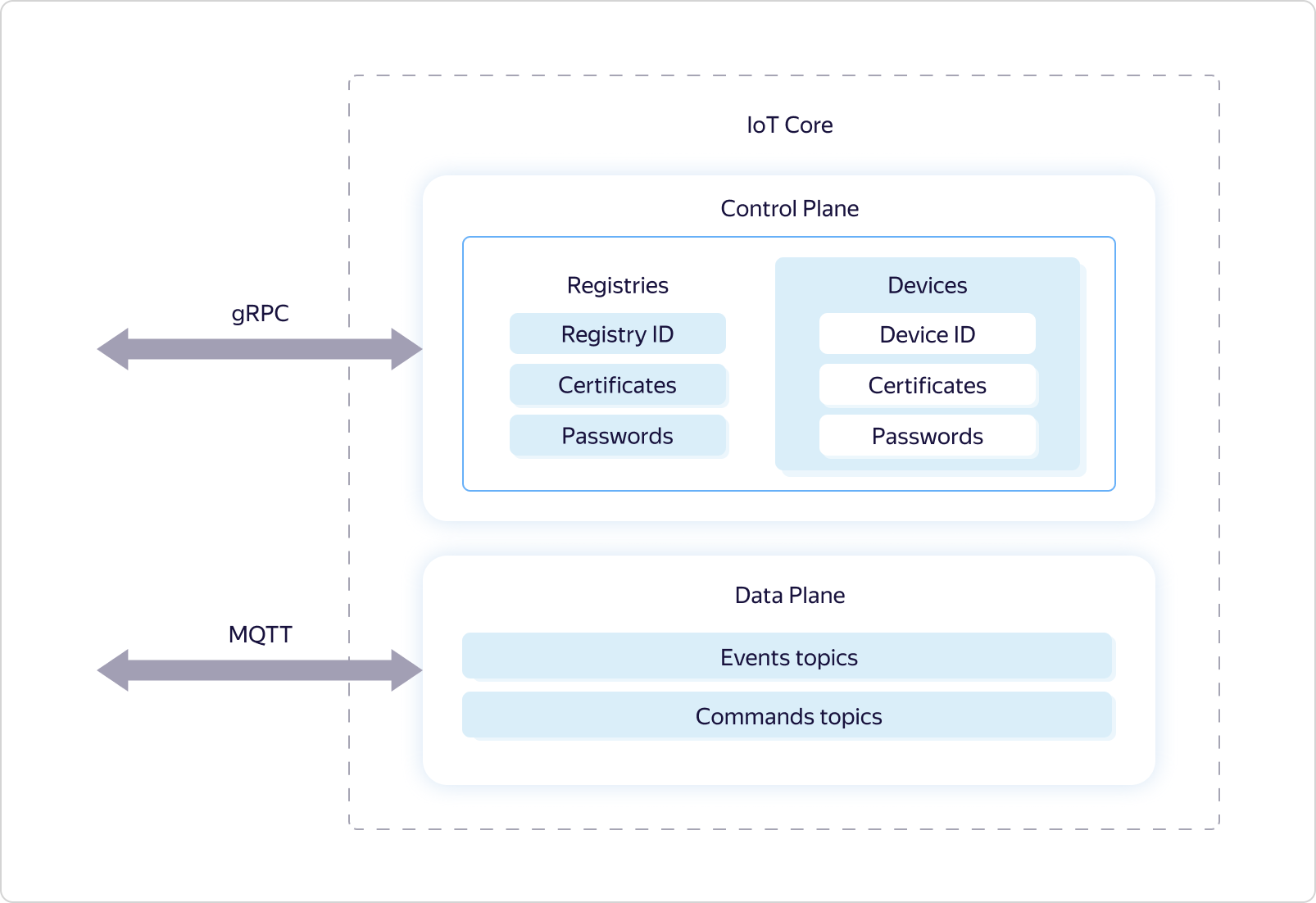 Data Plane es responsable de la lógica de operación bajo el protocolo MQTT, y Control Plane es responsable de delimitar los derechos de acceso a ciertos temas y utiliza las entidades lógicas Registro y Dispositivo para esto.
Data Plane es responsable de la lógica de operación bajo el protocolo MQTT, y Control Plane es responsable de delimitar los derechos de acceso a ciertos temas y utiliza las entidades lógicas Registro y Dispositivo para esto. Cada usuario de Yandex.Cloud puede tener varios registros, cada uno de los cuales puede contener su propio subconjunto de dispositivos.El acceso a los temas se proporciona de la siguiente manera: los
Cada usuario de Yandex.Cloud puede tener varios registros, cada uno de los cuales puede contener su propio subconjunto de dispositivos.El acceso a los temas se proporciona de la siguiente manera: los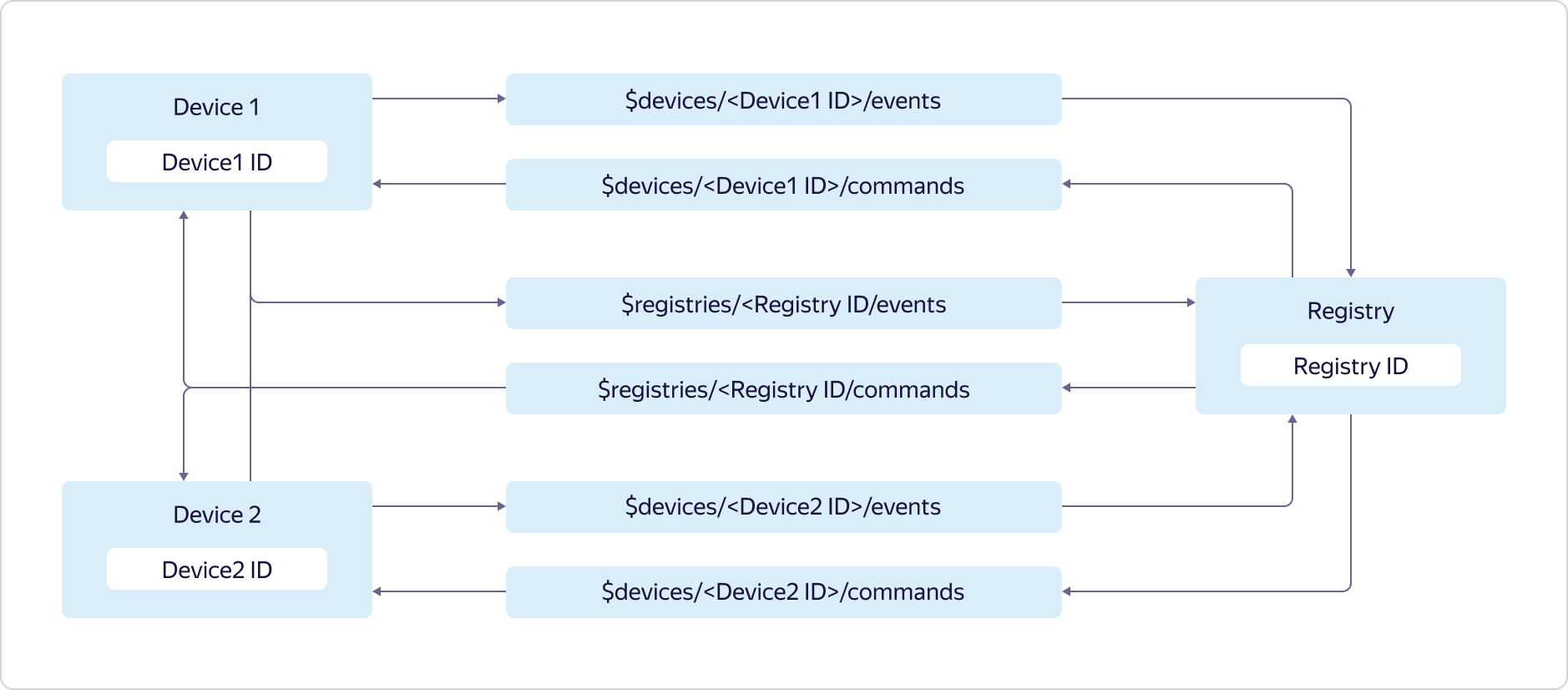 dispositivos pueden enviar datos solo a su tema de eventos y tema de eventos de registro:
dispositivos pueden enviar datos solo a su tema de eventos y tema de eventos de registro:$devices/<Device1 ID>/events
$registries/<Registry ID>/events
y suscríbase a mensajes solo de su tema de comandos y tema de comandos de registro:$devices/<Device1 ID>/commands
$registries/<Registry ID>/commands
El registro puede enviar datos a todos los temas de los comandos del dispositivo y al tema de los comandos del registro:$devices/<Device1 ID>/commands
$devices/<Device2 ID>/commands
$registries/<Registry ID>/commands
y suscríbase a mensajes de todos los temas de eventos de dispositivos y el tema de eventos de registro:$devices/<Device1 ID>/events
$devices/<Device2 ID>/events
$registries/<Registry ID>/events
Para trabajar con todas las entidades descritas anteriormente, Data Plane tiene un protocolo gRPC y un protocolo REST, en función del cual se implementa el acceso a través de la consola GUI de Yandex.Cloud y la interfaz de línea de comandos CLI.En cuanto al plano de datos, es compatible con el protocolo MQTT versión 3.1.1. Sin embargo, hay varias características:- Al conectarse, asegúrese de usar TLS.
- Solo se admite la conexión TCP. WebSocket aún no está disponible.
- La autorización está disponible tanto por inicio de sesión como por contraseña (donde el inicio de sesión es el dispositivo o el ID de registro, y el usuario establece las contraseñas) y mediante certificados.
- El indicador Retener no es compatible, cuando se utiliza el agente MQTT guarda el mensaje marcado con el indicador y lo envía la próxima vez que se suscriba al tema.
- No se admite la sesión persistente, en la cual el agente MQTT guarda información sobre el cliente (dispositivo o registro) para facilitar la reconexión.
- Con suscribirse y publicar, solo se admiten los dos primeros niveles de servicio:
- QoS0: como máximo una vez. No hay garantía de entrega, pero no hay reenvío del mismo mensaje.
- QoS1: al menos una vez. La entrega está garantizada, pero existe la posibilidad de volver a recibir el mismo mensaje.
Para simplificar la conexión a Yandex IoT Core, agregamos regularmente nuevos ejemplos para diferentes plataformas e idiomas a nuestro repositorio en GitHub, y también describimos los scripts en la documentación.La arquitectura del servicio tiene este aspecto: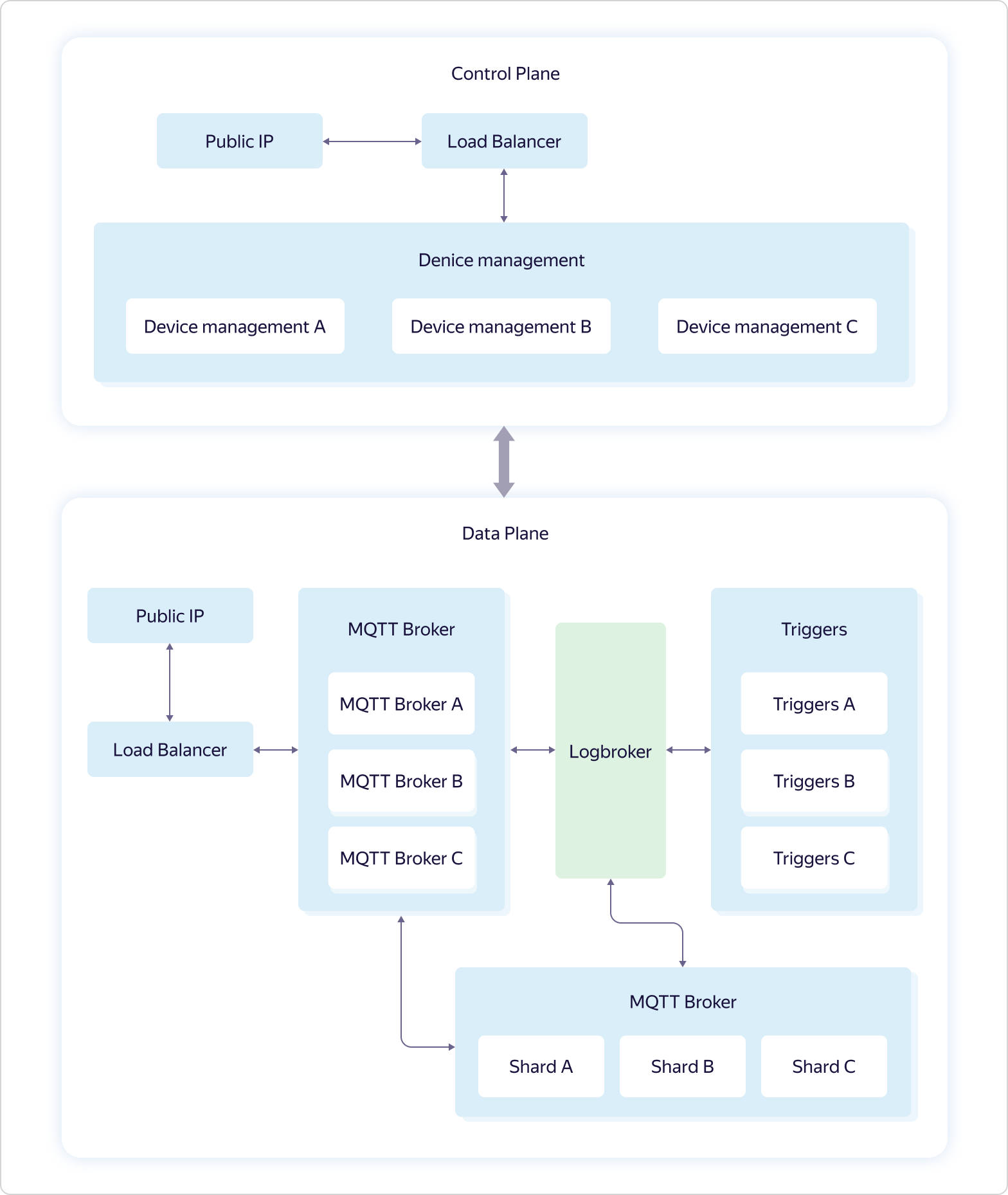 la lógica empresarial del servicio incluye cuatro partes:
la lógica empresarial del servicio incluye cuatro partes:- Device management — . Control Plane.
- MQTT Broker — MQTT-. Data Plane.
- Triggers — Yandex Cloud Functions. Data Plane.
- Shards — MQTT- . Data Plane.
Toda interacción con el "mundo exterior" pasa por equilibradores de carga. Además, de acuerdo con la filosofía de alimentación de perros, se utiliza Yandex Load Balancer, que está disponible para todos los usuarios de Yandex.Cloud.Cada parte de la lógica de negocios consta de varios conjuntos de tres máquinas virtuales, una en cada zona de disponibilidad (en los Esquemas A, B y C). Las máquinas virtuales son exactamente iguales a todos los usuarios de Yandex.Cloud. Cuando aumenta la carga, la escala se produce con la ayuda de todo el conjunto: se agregan tres máquinas a la vez en el marco de una parte de la lógica empresarial. Esto significa que si un conjunto de tres máquinas MQTT Broker no hace frente a la carga, se agrega otro conjunto de tres máquinas MQTT Broker, mientras que la configuración de otras partes de la lógica empresarial sigue siendo la misma.Y solo Logbroker no está disponible públicamente. Es un servicio para una operación eficiente a prueba de fallas con flujos de datos. Se basa en Apache Kafka, pero tiene muchas otras funciones útiles: implementa procesos de recuperación ante desastres (incluso exactamente una semántica cuando tiene una garantía de entrega de mensajes sin duplicación) y procesos de servicio (como la replicación entre centros, la distribución de datos a clústeres de cálculo), y también tiene un mecanismo para la distribución uniforme y no duplicada de datos entre suscriptores de flujo, un tipo de equilibrador de carga.Las funciones de administración de dispositivos en Control Plane se describen anteriormente. Pero con Data Plane, todo es mucho más interesante.Cada instancia de MQTT Broker funciona de forma independiente y no sabe nada sobre otras instancias. Los corredores envían todos los datos recibidos (publicación de los clientes) a Logbroker, desde donde los recogen Shards and Triggers. Y es en fragmentos donde se produce la sincronización entre instancias de corredores. Los fragmentos conocen todos los clientes MQTT y la distribución de sus suscripciones (suscribirse) entre instancias de corredores MQTT y determinan dónde enviar los datos recibidos.Por ejemplo, el cliente MQTT A está suscrito al tema del intermediario A, y el cliente MQTT B está suscrito al mismo tema del intermediario B. Si el cliente MQTT C hace publicar en el mismo tema, pero al intermediario C, el fragmento transfiere datos de intermediario C a intermediarios A y B, como resultado de lo cual los datos serán recibidos tanto por el cliente MQTT A como por el cliente MQTT B.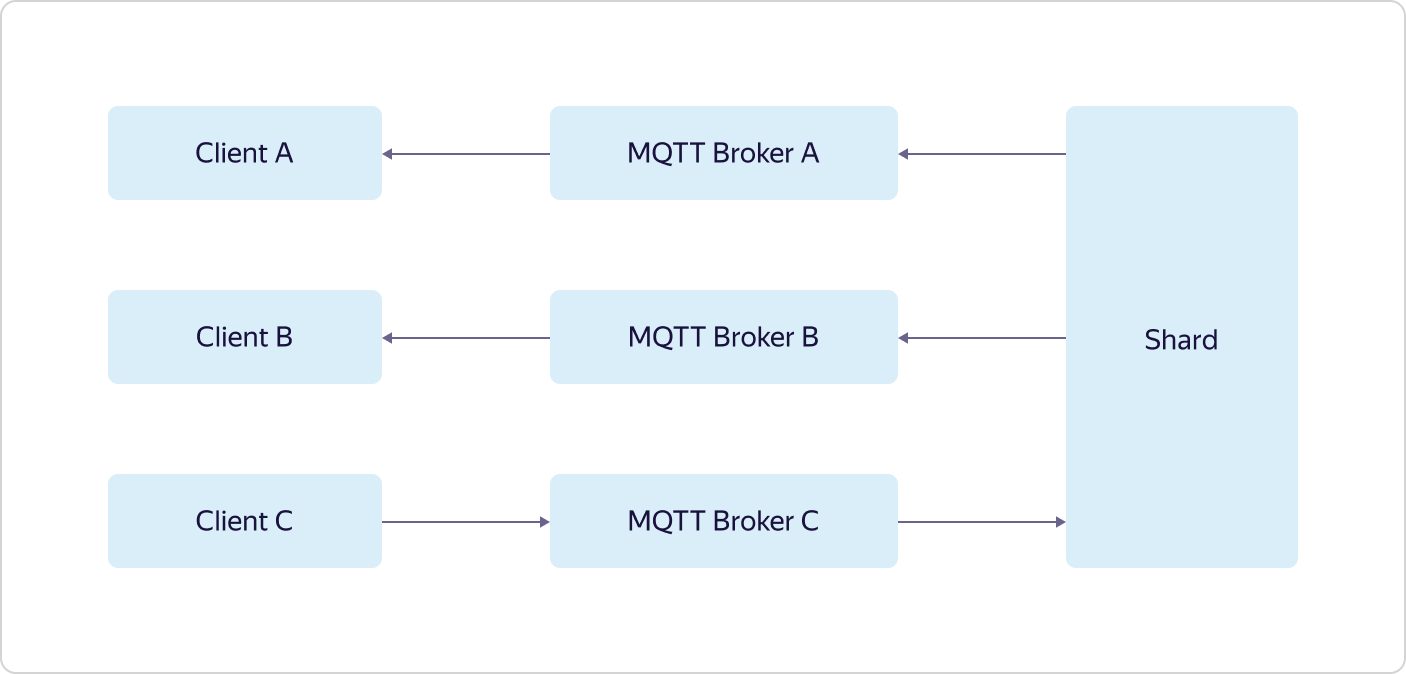 La última parte de la lógica de negocios, triggers (Triggers), también recibe todos los datos recibidos de los clientes MQTT y, si el usuario lo configura, los pasa a los activadores del servicio Yandex Cloud Functions.Como puede ver, Yandex IoT Core tiene una arquitectura y una lógica de trabajo bastante complicadas, que es difícil de repetir en instalaciones locales. Esto le permite soportar la pérdida de incluso dos de las tres zonas de disponibilidad, y resolver un número ilimitado de conexiones y volúmenes de datos ilimitados.Además, toda esta lógica está oculta para el usuario "debajo del capó", pero desde el exterior todo parece muy simple, como si estuviera trabajando con un solo agente MQTT.
La última parte de la lógica de negocios, triggers (Triggers), también recibe todos los datos recibidos de los clientes MQTT y, si el usuario lo configura, los pasa a los activadores del servicio Yandex Cloud Functions.Como puede ver, Yandex IoT Core tiene una arquitectura y una lógica de trabajo bastante complicadas, que es difícil de repetir en instalaciones locales. Esto le permite soportar la pérdida de incluso dos de las tres zonas de disponibilidad, y resolver un número ilimitado de conexiones y volúmenes de datos ilimitados.Además, toda esta lógica está oculta para el usuario "debajo del capó", pero desde el exterior todo parece muy simple, como si estuviera trabajando con un solo agente MQTT.Triggers y Yandex Cloud Functions
Yandex Cloud Functions es un representante de los llamados servicios "sin servidor" (sin servidor) en Yandex.Cloud. La esencia principal de dichos servicios es que el usuario no pasa su tiempo configurando, implementando y escalando el entorno para ejecutar código, sino que solo se ocupa de lo más valioso para él: escribir el código que realiza la tarea necesaria. En el caso de las funciones, este es el llamado código atómico sin estado que puede ser activado por algún evento. "Atómico" y "sin estado" significan que este código debe realizar una tarea relativamente pequeña pero integral, mientras que el código no debe usar ninguna variable para almacenar valores entre llamadas.Hay varias formas de llamar a funciones: una llamada HTTP directa, una llamada de temporizador (cron) o una suscripción a eventos. Como último, el servicio ya admite la suscripción a colas de mensajes (Yandex Message Queue), eventos generados por el servicio Object Storage y (lo más valioso para el escenario IoT) suscripción a mensajes en Yandex IoT Core.A pesar de que puede trabajar con Yandex IoT Core utilizando cualquier cliente compatible con MQTT, Yandex Cloud Functions es una de las formas más óptimas y convenientes para recibir y procesar datos. La razon para esto es muy simple. Se puede invocar una función en cada mensaje entrante desde cualquier dispositivo, y las funciones se ejecutarán en paralelo entre sí (debido a la atomicidad y el enfoque sin estado), y el número de sus llamadas cambiará naturalmente a medida que cambie el número de mensajes entrantes de los dispositivos. Por lo tanto, el usuario puede ignorar por completo los problemas de configuración de la infraestructura y, además, a diferencia de las mismas máquinas virtuales, el pago solo se realizará por el trabajo realmente realizado.Esto le permitirá ahorrar significativamente a baja carga y obtener un costo claro y predecible con el crecimiento.El mecanismo para llamar a funciones en eventos (suscribirse a eventos) se llama disparador (Trigger). Su esencia se representa en el diagrama: un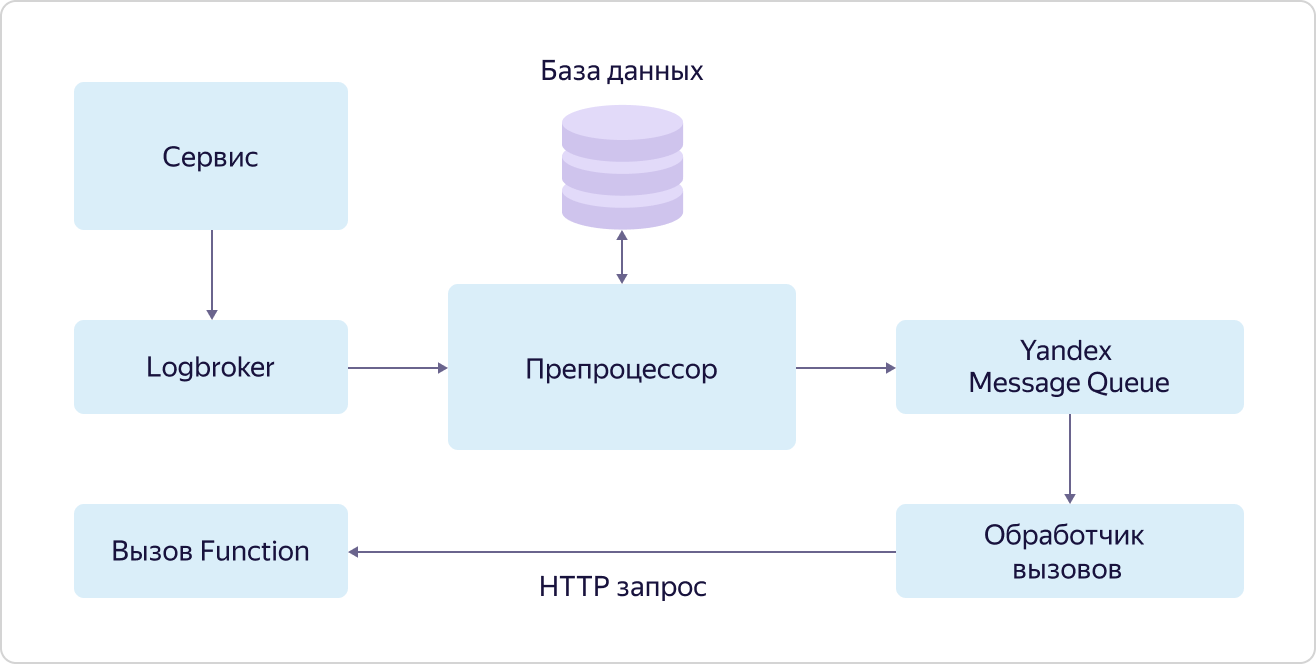 servicio que genera eventos para llamar a funciones los pone en una cola en Logbroker. En el caso de Yandex IoT Core, los activadores de Data Plane hacen esto. Además, estos eventos son tomados por el preprocesador, que está buscando un registro en la base de datos para este evento que indique la función que se llamará. Si se encuentra dicha entrada, el preprocesador coloca la información sobre la llamada de función (ID de función y parámetros de llamada) en la cola en el servicio Yandex Message Queue, desde donde la recoge el manejador de llamadas. El controlador, a su vez, envía una solicitud HTTP para llamar a la función al servicio Yandex Cloud Functions.Al mismo tiempo, de nuevo, de acuerdo con la filosofía de alimentación de perros, se utiliza el servicio Yandex Message Queue, accesible para todos los usuarios, y las funciones se invocan exactamente de la misma manera que cualquier otro usuario puede llamar a sus funciones.Digamos algunas palabras sobre Yandex Message Queue. A pesar de que esto, como Logbroker, es un servicio de cola, existe una diferencia significativa entre ellos. Al procesar mensajes de colas, el controlador informa a la cola que ha finalizado y que el mensaje se puede eliminar. Este es un mecanismo de confiabilidad importante en dichos servicios, pero complica la lógica de trabajar con mensajes.Yandex Message Queue le permite "paralelizar" el procesamiento de cada mensaje dentro de la cola. En otras palabras, el mensaje de la cola que se está procesando actualmente no bloquea la posibilidad de que otro "hilo" recoja el siguiente evento de la cola para su procesamiento. Esto se llama concurrencia a nivel de mensaje.Y LogBroker opera en grupos de mensajes, y hasta que se procese todo el grupo, el siguiente grupo no puede ser recogido para su procesamiento. Este enfoque se llama concurrencia a nivel de partición.Y es precisamente el uso de Yandex Message Queue lo que le permite procesar de manera rápida y eficiente en paralelo muchas solicitudes para llamar a una función para eventos de un servicio en particular.A pesar de que los disparadores son una unidad independiente separada, son parte del servicio Yandex Cloud Functions. Solo tenemos que descubrir exactamente cómo se llaman las funciones.
servicio que genera eventos para llamar a funciones los pone en una cola en Logbroker. En el caso de Yandex IoT Core, los activadores de Data Plane hacen esto. Además, estos eventos son tomados por el preprocesador, que está buscando un registro en la base de datos para este evento que indique la función que se llamará. Si se encuentra dicha entrada, el preprocesador coloca la información sobre la llamada de función (ID de función y parámetros de llamada) en la cola en el servicio Yandex Message Queue, desde donde la recoge el manejador de llamadas. El controlador, a su vez, envía una solicitud HTTP para llamar a la función al servicio Yandex Cloud Functions.Al mismo tiempo, de nuevo, de acuerdo con la filosofía de alimentación de perros, se utiliza el servicio Yandex Message Queue, accesible para todos los usuarios, y las funciones se invocan exactamente de la misma manera que cualquier otro usuario puede llamar a sus funciones.Digamos algunas palabras sobre Yandex Message Queue. A pesar de que esto, como Logbroker, es un servicio de cola, existe una diferencia significativa entre ellos. Al procesar mensajes de colas, el controlador informa a la cola que ha finalizado y que el mensaje se puede eliminar. Este es un mecanismo de confiabilidad importante en dichos servicios, pero complica la lógica de trabajar con mensajes.Yandex Message Queue le permite "paralelizar" el procesamiento de cada mensaje dentro de la cola. En otras palabras, el mensaje de la cola que se está procesando actualmente no bloquea la posibilidad de que otro "hilo" recoja el siguiente evento de la cola para su procesamiento. Esto se llama concurrencia a nivel de mensaje.Y LogBroker opera en grupos de mensajes, y hasta que se procese todo el grupo, el siguiente grupo no puede ser recogido para su procesamiento. Este enfoque se llama concurrencia a nivel de partición.Y es precisamente el uso de Yandex Message Queue lo que le permite procesar de manera rápida y eficiente en paralelo muchas solicitudes para llamar a una función para eventos de un servicio en particular.A pesar de que los disparadores son una unidad independiente separada, son parte del servicio Yandex Cloud Functions. Solo tenemos que descubrir exactamente cómo se llaman las funciones. Todas las solicitudes para llamar a funciones (tanto externas como internas) caen en el equilibrador de carga, que las distribuye a enrutadores en diferentes zonas de acceso (AZ), se implementan varias piezas en cada zona. Al recibir una solicitud, el enrutador primero va al servicio del administrador de Identidad y Acceso (IAM) para asegurarse de que la fuente de la solicitud tenga derechos para llamar a esta función. Luego recurre al planificador y pregunta en qué trabajador ejecutar la función. Worker es una máquina virtual con un tiempo de ejecución personalizado de funciones aisladas. Además, el enrutador, después de haber recibido del planificador la dirección del trabajador en el que ejecutar la función, envía un comando a este trabajador para iniciar la función con ciertos parámetros.¿De dónde viene el trabajador? Aquí es donde sucede toda la magia sin servidor. Los programadores, analizando la carga (el número y la duración de las funciones), administran (inician y detienen) máquinas virtuales con un tiempo de ejecución particular. NodeJS y Python ahora son compatibles. Y aquí un parámetro es extremadamente importante: la velocidad de lanzamiento de funciones. El equipo de desarrollo de servicios ha hecho un gran trabajo, y ahora la máquina virtual se inicia en un máximo de 250 ms, mientras utiliza el entorno más seguro para aislar las funciones entre sí: la virtualización QEMU, que ejecuta todo Yandex. Cloud. Al mismo tiempo, si ya hay un trabajador que trabaja para la solicitud entrante, la función se inicia casi instantáneamente.Y, de acuerdo con el mismo enfoque de alimentación de perros, Load Balancer utiliza un servicio público accesible para todos los usuarios, y el trabajador, el planificador y el enrutador son máquinas virtuales comunes, lo mismo que todos los usuarios.Por lo tanto, la tolerancia a fallas del servicio se implementa a nivel del equilibrador de carga y la redundancia de los componentes clave del sistema (enrutador y planificador), y el escalado se produce debido a la implementación o la reducción del número de trabajadores. Además, cada zona de accesibilidad funciona de forma independiente, lo que permite sobrevivir incluso a la pérdida de dos de las tres zonas.
Todas las solicitudes para llamar a funciones (tanto externas como internas) caen en el equilibrador de carga, que las distribuye a enrutadores en diferentes zonas de acceso (AZ), se implementan varias piezas en cada zona. Al recibir una solicitud, el enrutador primero va al servicio del administrador de Identidad y Acceso (IAM) para asegurarse de que la fuente de la solicitud tenga derechos para llamar a esta función. Luego recurre al planificador y pregunta en qué trabajador ejecutar la función. Worker es una máquina virtual con un tiempo de ejecución personalizado de funciones aisladas. Además, el enrutador, después de haber recibido del planificador la dirección del trabajador en el que ejecutar la función, envía un comando a este trabajador para iniciar la función con ciertos parámetros.¿De dónde viene el trabajador? Aquí es donde sucede toda la magia sin servidor. Los programadores, analizando la carga (el número y la duración de las funciones), administran (inician y detienen) máquinas virtuales con un tiempo de ejecución particular. NodeJS y Python ahora son compatibles. Y aquí un parámetro es extremadamente importante: la velocidad de lanzamiento de funciones. El equipo de desarrollo de servicios ha hecho un gran trabajo, y ahora la máquina virtual se inicia en un máximo de 250 ms, mientras utiliza el entorno más seguro para aislar las funciones entre sí: la virtualización QEMU, que ejecuta todo Yandex. Cloud. Al mismo tiempo, si ya hay un trabajador que trabaja para la solicitud entrante, la función se inicia casi instantáneamente.Y, de acuerdo con el mismo enfoque de alimentación de perros, Load Balancer utiliza un servicio público accesible para todos los usuarios, y el trabajador, el planificador y el enrutador son máquinas virtuales comunes, lo mismo que todos los usuarios.Por lo tanto, la tolerancia a fallas del servicio se implementa a nivel del equilibrador de carga y la redundancia de los componentes clave del sistema (enrutador y planificador), y el escalado se produce debido a la implementación o la reducción del número de trabajadores. Además, cada zona de accesibilidad funciona de forma independiente, lo que permite sobrevivir incluso a la pérdida de dos de las tres zonas.Enlaces útiles
En conclusión, quiero dar algunos enlaces que le permitirán estudiar los servicios con más detalle: