No estaba seguro de haber escuchado correctamente. ¡Depende mucho de eso! Pero no preguntes de nuevo? (c) Boris Akunin. El mundo entero es un teatro.
Mientras trabajaba en el asistente de voz que se mencionó en el artículo anterior , me di cuenta de que no puedo evitar compartir la hermosa biblioteca FuzzyWuzzy con usted .En resumen, gracias a ella, es posible hacer una comparación de cadenas difusas sin ningún sufrimiento.Primeros pasos
Para comenzar, debe seguir dos pasos:/ ¡IMPORTANTE! Python versión 2.7 y superior /Paso 1. Instalación.Abra la línea de comando e ingrese:pip install fuzzywuzzy
Presione Entrar.A continuación, instale python-Levenshtein de la misma manera para acelerar la coincidencia de cadenas de 3 a 10 veces.pip install python-Levenshtein
Una vez completada la instalación, la biblioteca está lista para importar.Paso 2. Importar al proyecto.from fuzzywuzzy import fuzz
from fuzzywuzzy import process
Funcional
1. La comparación más común:a = fuzz.ratio(' ', ' ')
print(a)
Si cambiamos un par de caracteres, la salida obtendrá un número diferente.a = fuzz.ratio(' ', ' ')
print(a)
2. Comparación parcial:este tipo de comparación en toda la segunda línea busca una coincidencia con la inicial, por ejemplo:a = fuzz.partial_ratio(' ', ' !')
print(a)
Oa = fuzz.partial_ratio(' ', ' , ')
print(a)
Pero debe recordar sobre el registro, ya quea = fuzz.partial_ratio(' ', ' , ')
print(a)
3. Comparación detokens 1) Relación de clasificación de tokensLas palabras se comparan entre sí, independientemente del caso o el ordena = fuzz.token_sort_ratio(' ', ' ')
print(a)
a = fuzz.token_sort_ratio(' ', ' ')
print(a)
a = fuzz.token_sort_ratio('1 2 ', '1 2 ')
print(a)
2) Relación de conjunto de fichasEsta comparación, a diferencia del pasado, iguala las cadenas, si su diferencia es la repetición de palabras.a = fuzz.token_set_ratio(' ', ' ')
print(a)
4. Comparación regular avanzadaEn muchos casos, es más aconsejable usar exactamente WRatio , ya que distingue entre mayúsculas y minúsculas (no divide la cadena)a = fuzz.WRatio(' ', '! !')
print(a)
a = fuzz.WRatio(' ', '!, !')
print(a)
5. Trabajar con la listaPara comparar las líneas con las líneas de la lista, se utiliza el módulo de procesocity = ["", "-", "", "", "", "", "", "", "", "", ""]
a = process.extract("", city, limit=2)
print(a)
Si solo se necesita el primero de la lista, entonces es mejor usar extractOnecity = ["", "-", "", "", "", "", "", "", "", "", ""]
a = process.extractOne("", city)
print(a)
Solicitud
Cómo y dónde aplicar todo lo anterior depende de usted, pero aquí hay un ejemplo de mi trabajo final :
try:
files = os.listdir('C:\\Users\\hartp\\Desktop\\')
filestart = process.extractOne(namerec, files)
if filestart[1] >= 80:
os.startfile('C:\\Users\\hartp\\Desktop\\' + filestart[0])
else:
speak(' ')
except FileNotFoundError:
speak(' ')
Repasemos el código y comprendamos qué es qué. Con elcomando os.listdir, obtenemos una lista de todos los archivos que están presentes al final de la ruta especificada (en nuestro caso, al escritorio).files = os.listdir('C:\\Users\\hartp\\Desktop\\')
print(files)
Lo siguiente es una comparación de las líneas de la lista de archivos con el nombre del archivo que nombró el usuario (variable namerec ). Espero que hayas notado que el resultado de la función extractOne es una tupla de cadena y número (índice de similitud)Ejemplo del último capítulocity = ["", "-", "", "", "", "", "", "", "", "", ""]
a = process.extractOne("", city)
print(a)
.
En base a esto, verificamos el índice de similitud de inicio de archivo [1]> = 80 ([1], ya que la tupla está numerada desde 0, como en una matriz) y, si la condición es verdadera, ejecuta la función os.startfile con un archivo llamado filestart [0 ] De lo contrario, si el índice de similitud es inferior a 80 o se produce un error de que no se encontró el archivo, informamos al usuario a través de la función de voz .Todos los caminos conducen a Matan
Escondido de personas que tienen miedo a las matemáticas., , ().
, .
( , ) — , .
S1 i S2 j
S1=vrhk
S2=rhgr
3 :
- : r → v
- : -r
- : rVhgr
:

0 1? ( — «0»), r , r ( , — «1»). v .
rh h, r ( ), , :
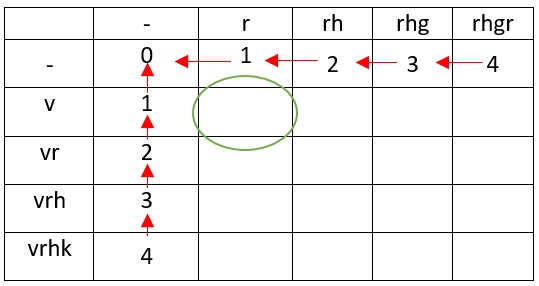
v r ( ).
, — v.
1. ? r , v. r , v, rv. , v v.
v rh
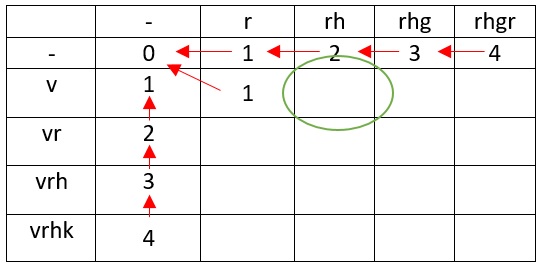
— v h r .
.
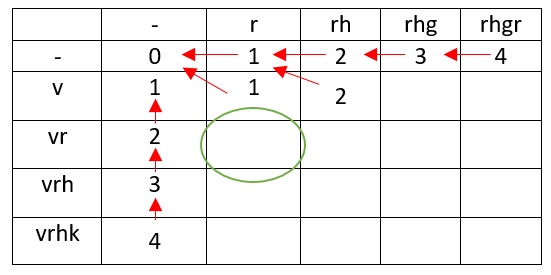
vr r , , , , .
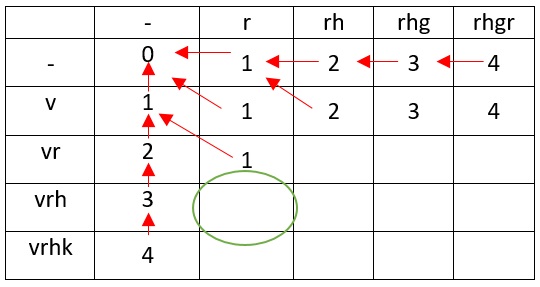
vrh r h ( vr r), 2

vr r vrh rh, , .
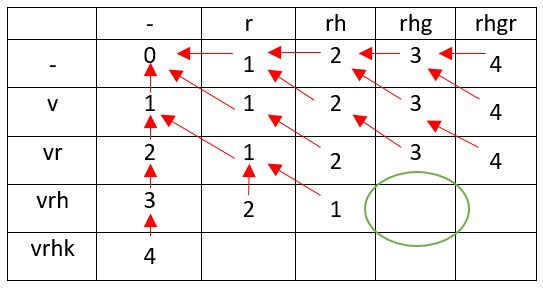
, vrh rhg , , , - ( ).
, , ( ) — vrhk rhgr.
¡Gracias a todos por su atención! Espero que este artículo sea útil para alguien.