El advenimiento de async / await en C # ha llevado a una redefinición de cómo escribir código paralelo simple y correcto. A menudo, usando la programación asincrónica, los programadores no solo no resuelven los problemas que estaban con los hilos, sino que también introducen otros nuevos. Los puntos muertos y los vuelos no van a ninguna parte, simplemente se vuelven más difíciles de diagnosticar. Dmitry Ivanov - Software Analysis TeamLead en Huawei, un antiguo techlide de JetBrains Rider y desarrollador del núcleo ReSharper: estructuras de datos, cachés, subprocesos múltiples y un orador habitual en la conferencia DotNext .Bajo la escena: grabación de video y transcripción de texto del informe de Dmitry de la conferencia DotNext 2019 Piter.Narración adicional en nombre del orador.En el código multiproceso o asíncrono, a menudo algo se rompe. La razón podría ser tanto un punto muerto como una carrera. Como regla general, una raza se bloquea una vez de cada mil, a menudo no localmente, sino solo en un servidor de compilación, y lleva varios días atraparla. Estoy seguro de que para muchos esta es una situación familiar.Además, al observar el código asincrónico incluso por desarrolladores experimentados, me encuentro pensando que algunas cosas pueden escribirse tres veces más cortas y más correctamente.Esto sugiere que el problema no está en las personas, sino en el instrumento. La gente simplemente usa la herramienta y quiere que resuelva su problema. La herramienta en sí tiene una gran cantidad de capacidades (a veces incluso superfluas), configuraciones, un contexto implícito, lo que lleva al hecho de que es muy fácil de usar incorrectamente. Intentemos descubrir cómo usar async / await y trabajar con una clase
Dmitry Ivanov - Software Analysis TeamLead en Huawei, un antiguo techlide de JetBrains Rider y desarrollador del núcleo ReSharper: estructuras de datos, cachés, subprocesos múltiples y un orador habitual en la conferencia DotNext .Bajo la escena: grabación de video y transcripción de texto del informe de Dmitry de la conferencia DotNext 2019 Piter.Narración adicional en nombre del orador.En el código multiproceso o asíncrono, a menudo algo se rompe. La razón podría ser tanto un punto muerto como una carrera. Como regla general, una raza se bloquea una vez de cada mil, a menudo no localmente, sino solo en un servidor de compilación, y lleva varios días atraparla. Estoy seguro de que para muchos esta es una situación familiar.Además, al observar el código asincrónico incluso por desarrolladores experimentados, me encuentro pensando que algunas cosas pueden escribirse tres veces más cortas y más correctamente.Esto sugiere que el problema no está en las personas, sino en el instrumento. La gente simplemente usa la herramienta y quiere que resuelva su problema. La herramienta en sí tiene una gran cantidad de capacidades (a veces incluso superfluas), configuraciones, un contexto implícito, lo que lleva al hecho de que es muy fácil de usar incorrectamente. Intentemos descubrir cómo usar async / await y trabajar con una clase Tasken .NET.Plan
- Problemas con los enfoques que se resuelven con async / wait.
- Ejemplos de diseño controvertido.
- Una tarea de la vida real que resolveremos de forma asincrónica.
Asíncrono / espera y problemas por resolver
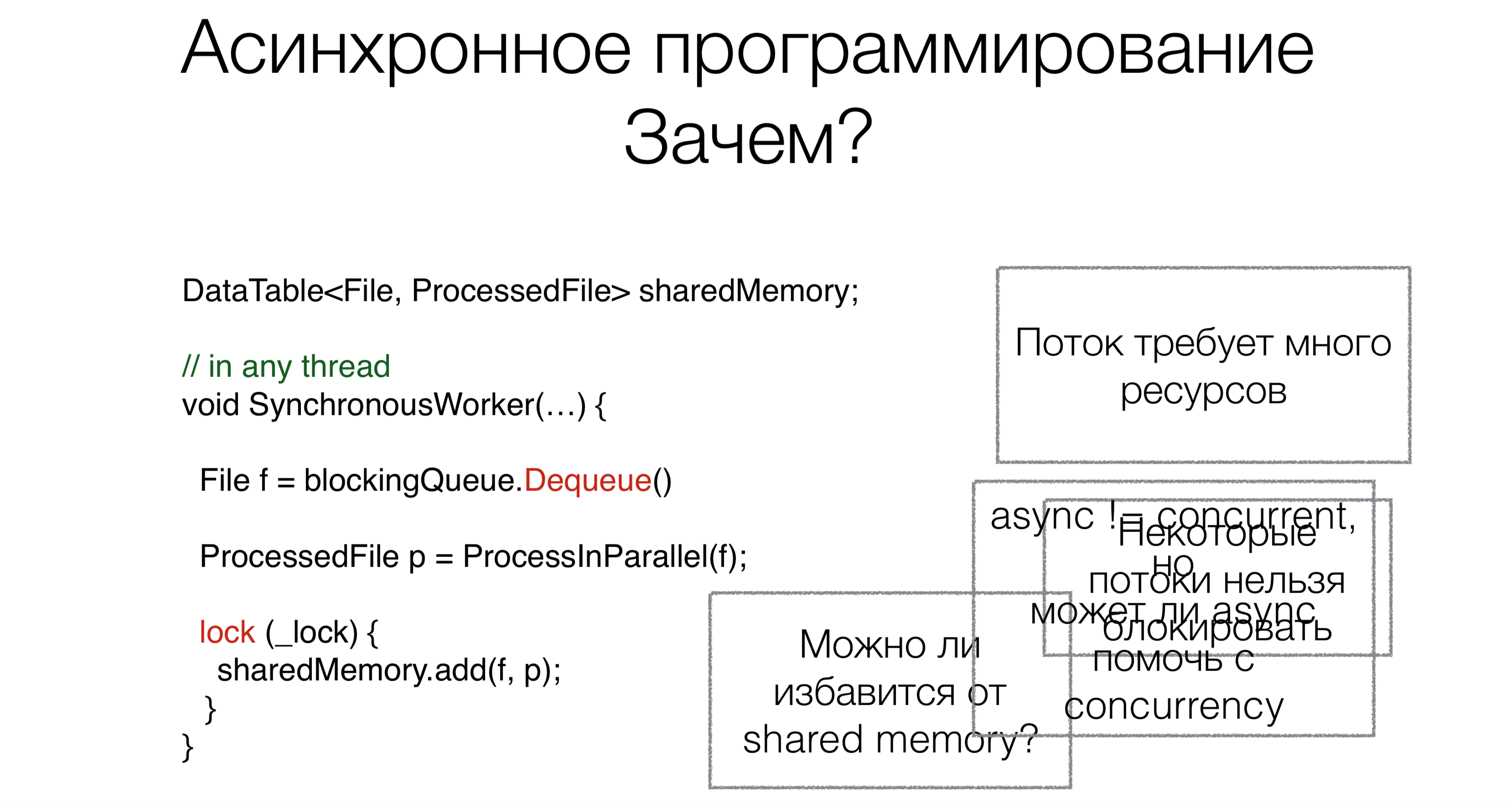 ¿Por qué necesitamos async / wait? Digamos que tenemos código que funciona con memoria compartida compartida.Al comienzo del trabajo, leemos la solicitud, en este caso, el archivo de la cola de bloqueo (por ejemplo, de Internet o del disco), utilizando la solicitud de bloqueo Dequeue (las solicitudes de bloqueo se marcarán en rojo en las imágenes con ejemplos).Este enfoque requiere muchos subprocesos, y cada subproceso requiere recursos, crea una carga en el planificador. Pero este no es el problema principal. Supongamos que las personas pudieran reescribir los sistemas operativos para que estos sistemas admitan cientos de miles y un millón de subprocesos. Pero el problema principal es que algunos hilos simplemente no se pueden tomar. Por ejemplo, tiene un hilo de interfaz de usuario. No hay marcos de interfaz de usuario adecuados normales donde el acceso a los datos no sea solo desde un hilo, todavía. El subproceso de la interfaz de usuario no se puede bloquear. Y para no bloquearlo, necesitamos un código asincrónico.Ahora hablemos de la segunda tarea. Después de leer el archivo, debe procesarse de alguna manera. Lo haremos en paralelo.Muchos de ustedes han escuchado que el paralelismo no es lo mismo que la asincronía. En este caso, surge la pregunta: ¿puede la asincronía ayudar a escribir código paralelo más compacto, hermoso y más rápido?La última tarea es trabajar con memoria compartida. ¿Necesitamos arrastrar este mecanismo con bloqueos, sincronización a código asincrónico, o se puede evitar de alguna manera? ¿Puede async / esperar ayuda con esto?
¿Por qué necesitamos async / wait? Digamos que tenemos código que funciona con memoria compartida compartida.Al comienzo del trabajo, leemos la solicitud, en este caso, el archivo de la cola de bloqueo (por ejemplo, de Internet o del disco), utilizando la solicitud de bloqueo Dequeue (las solicitudes de bloqueo se marcarán en rojo en las imágenes con ejemplos).Este enfoque requiere muchos subprocesos, y cada subproceso requiere recursos, crea una carga en el planificador. Pero este no es el problema principal. Supongamos que las personas pudieran reescribir los sistemas operativos para que estos sistemas admitan cientos de miles y un millón de subprocesos. Pero el problema principal es que algunos hilos simplemente no se pueden tomar. Por ejemplo, tiene un hilo de interfaz de usuario. No hay marcos de interfaz de usuario adecuados normales donde el acceso a los datos no sea solo desde un hilo, todavía. El subproceso de la interfaz de usuario no se puede bloquear. Y para no bloquearlo, necesitamos un código asincrónico.Ahora hablemos de la segunda tarea. Después de leer el archivo, debe procesarse de alguna manera. Lo haremos en paralelo.Muchos de ustedes han escuchado que el paralelismo no es lo mismo que la asincronía. En este caso, surge la pregunta: ¿puede la asincronía ayudar a escribir código paralelo más compacto, hermoso y más rápido?La última tarea es trabajar con memoria compartida. ¿Necesitamos arrastrar este mecanismo con bloqueos, sincronización a código asincrónico, o se puede evitar de alguna manera? ¿Puede async / esperar ayuda con esto?Camino a async / esperar
Veamos la evolución de la programación asincrónica en general en el mundo y en .NET.Llamar de vuelta
Void Foo(params, Action callback) {…}
Void OurMethod() {
…
Foo(params,() =>{
…
});
}
La programación asincrónica comenzó con devoluciones de llamada. Es decir, primero debe llamar a una parte del código de forma sincrónica, y la segunda parte, de forma asincrónica. Por ejemplo, lee de un archivo y, cuando los datos están listos, se le entregarán de alguna manera. Esta parte asincrónica se pasa como una devolución de llamada .Más devoluciones de llamada
void Foo(params, Action callback) {...}
void Bar(Action callback) {...}
void Baz(Action callback) {...}
void OurMethod() {
...
Foo(params, () => {
...
Bar(() => {
Baz(() => {
});
});
});
}
Por lo tanto, desde una devolución de llamada puede registrar otra devolución de llamada , desde la cual puede registrar una tercera devolución de llamada, y al final todo se convierte en un infierno de devolución de llamada .
Devolución de llamada: excepciones
void Foo(params, Action onSuccess, Action onFailure) {...}
void OurMethod() {
...
Foo(params, () => {
...
},
() => {
...
});
}
¿Cómo trabajar con excepciones? Por ejemplo, ReSharper, cuando responde por separado a las excepciones y a una buena ejecución, no demuestra las piezas de código más bellas: hay devoluciones de llamada separadas para una situación excepcional y para una continuación exitosa. El resultado es un infierno de devolución de llamada , pero no lineal, sino en forma de árbol, lo que puede ser completamente confuso. En .NET, el primer enfoque de devolución de llamada se llama Modelo de programación asincrónica (APM). Se llamará al método
En .NET, el primer enfoque de devolución de llamada se llama Modelo de programación asincrónica (APM). Se llamará al método AsyncCallback, que es esencialmente el mismo Action, pero el enfoque tiene algunas características. En primer lugar, los métodos deben comenzar con la palabra "Comenzar" (la lectura de un archivo es BeginRead), que devuelve algunos AsyncResult. Él mismoAsyncResult- Este es un controlador que sabe que la operación se ha completado y que tiene un mecanismo WaitHandle. Puede WaitHandleesperar, esperando que la operación se complete de forma asincrónica. Por otro lado, puede llamar EndOperation, es decir, hacer EndReady colgar sincrónicamente (que es muy similar a una propiedad Task.Result).Este enfoque tiene varios problemas. En primer lugar, no nos protege del infierno de devolución de llamadas . En segundo lugar, sigue sin estar completamente claro qué hacer con las excepciones. En tercer lugar, no está claro en qué hilo se llamará esta devolución de llamada: no tenemos control sobre la llamada. Cuarto, surge la pregunta, ¿cómo combinar fragmentos de código con devoluciones de llamada? El segundo modelo se llama Patrón asincrónico basado en eventos. Este es un enfoque de devolución de llamada reactivo. La idea del método es que pasemos al método
El segundo modelo se llama Patrón asincrónico basado en eventos. Este es un enfoque de devolución de llamada reactivo. La idea del método es que pasemos al método OperationNameAsyncalgún objeto que tenga el evento Completado y nos suscribamos a este evento. Como notaron, los BeginOperationNamecambios a OperationNameAsync. La confusión puede ocurrir cuando ingresa a la clase Socket, donde se mezclan dos patrones: ConnectAsyncy BeginConnect.Tenga en cuenta que debe llamar para cancelar OperationNameAsyncCancel. Como en .NET esto no se encuentra en ningún otro lugar, generalmente todos envían CancellationToken s . Por lo tanto, si accidentalmente encuentra un método en la biblioteca que termina con Async, debe comprender que no necesariamente regresa Task, pero puede devolver una construcción similar. Considere un modelo que se conoce en Java comoFuturos , en JavaScript, como Promesas , y en .NET, como Patrones asincrónicos de tareas , en otras palabras, "tareas". Este método supone que tiene algún objeto de cálculo y puede ver el estado de este objeto (en ejecución o terminado). En .NET, existe una llamada
Considere un modelo que se conoce en Java comoFuturos , en JavaScript, como Promesas , y en .NET, como Patrones asincrónicos de tareas , en otras palabras, "tareas". Este método supone que tiene algún objeto de cálculo y puede ver el estado de este objeto (en ejecución o terminado). En .NET, existe una llamada RnToCompletionseparación conveniente de dos estados: el inicio de la tarea y la finalización de la tarea. Se produce un error común cuando se llama a un método en una tarea IsCompletedque devuelve una continuación no exitosa, pero RnToCompletion, Canceledy Faulted. Por lo tanto, el resultado de hacer clic en "Cancelar" en la aplicación de interfaz de usuario debe diferir de la devolución de excepciones (ejecuciones). En .NET, se ha hecho una distinción: si la ejecución es su error que desea proteger, entonces Cancelar- operación forzada.En .NET, también se introdujo un concepto TaskScheduler: es una especie de abstracción en la parte superior de los hilos que indica dónde ejecutar la tarea. En este caso, el soporte de cancelación se diseñó a nivel de diseño. Casi todas las operaciones en la biblioteca en .NET tienen CancellationTokenque se pueden pasar. Esto no funciona para todos los idiomas: por ejemplo, en Kotlin puede deshacer la tarea, pero en .NET no puede hacerlo. La solución puede ser la división de responsabilidades entre quienes cancelan la tarea y la tarea misma. Cuando recibe una tarea, no puede cancelarla de otra manera que no sea explícitamente, debe pasarla CancellationToken.Un objeto especial le TaskCompletionSourepermite adaptar fácilmente las API antiguas que están asociadas con el patrón asincrónico basado en eventos o el modelo de programación asincrónica. Hay un documento que debe leer si programa en tareas. Describe todos los acuerdos sobre tarifas. Por ejemplo, cualquier método, que devuelve la tarea, debe devolverlo en un estado de ejecución, lo que significa que no puede serlo Created, mientras que todas esas operaciones deben terminar Async.Combinando continuaciones
Task ourMethod() {
return Task.RunSynchronously(() =>{
...
})
.ContinueWith(_ =>{
Foo();
})
.ContinueWith(_ =>{
Bar();
})
.ContinueWith(_ =>{
Baz();
})
}
En cuanto a la combinación, teniendo en cuenta el infierno de devolución de llamada , puede aparecer en una forma más lineal, a pesar de la presencia de piezas de código repetitivo con cambios mínimos. Parece que el código está mejorando de esta manera, pero también hay dificultades aquí.Iniciar y continuar tareas
Task.Factory.StartNew(Action,
TaskCreationOptions,
TaskScheduler,
CancellationToken
)
Task.ContinueWith(Action<Task>,
TaskContinuationOptions,
TaskScheduler,
CancellationToken
)
Pasemos a tres parámetros durante el inicio de la tarea estándar: el primero son las opciones para iniciar la tarea, el segundo es scheduleraquel en el que se inicia la tarea y el tercero - CancellationToken. TaskScheduler le dice dónde comienza la tarea y es un objeto que puede anular independientemente. Por ejemplo, puede anular un método
TaskScheduler le dice dónde comienza la tarea y es un objeto que puede anular independientemente. Por ejemplo, puede anular un método Queue. Si lo hace TaskSchedulerpor thread poolel método de Queuetoma de un hilo thread pooly envía su tarea allí.Si se hace schedulercargo del hilo principal, pone todo en una cola y las tareas se ejecutan secuencialmente en el hilo principal. Sin embargo, el problema es que en .NET puede ejecutar la tarea sin pasar TaskScheduler. Surge la pregunta: ¿cómo, entonces, calcula .NET qué tarea se le pasó? Cuando la tarea comienza por StartNewdentroAction, ThreadStatic. Currentexhibido en el TaskSchedulerque le dimos.Este diseño parece bastante controvertido debido al contexto implícito. Hubo casos en los que TaskSchedulercontenía código asincrónico que heredó en algún lugar muy profundamente TaskScheduler.Currenty se superpuso con otro planificador, lo que condujo a puntos muertos. En este caso, puede usar la opción TaskCreationOption.HideScheduler. Esta es una campana de alarma que dice que tenemos alguna opción que anula la ThreadStaticconfiguración.Todo es igual con continuaciones. Surge la pregunta: ¿de dónde viene TaskSchedulerpara las continuaciones? En primer lugar, se toma en el método en el que comenzó Continuation. También se TaskSchedulertoma de ThreadStatic. Es importante que para async / wait, las continuaciones funcionen de manera muy diferente. Pasamos a los parámetros
Pasamos a los parámetros TaskCreationOptionsy TaskContinuationOptions. Su principal problema es que hay muchos de ellos. Algunos de estos parámetros se cancelan entre sí, algunos son mutuamente excluyentes. Todos estos parámetros se pueden usar en todas las combinaciones posibles, por lo que es difícil tener en cuenta todo lo que puede suceder con el anhelo. Algunas de estas opciones funcionan de manera completamente incomprensible. Por ejemplo, los parámetros
Por ejemplo, los parámetros ExecuteSynchronouslyy RunContinuationsAsynchronouslyrepresentan dos posibles opciones de aplicación, pero si la continuación se iniciará de forma síncrona o asíncrona depende de tantas cosas que no sabrá. Otro ejemplo: lanzamos la tarea, iniciamos la continuación y simultáneamente dimos dos parámetros
Otro ejemplo: lanzamos la tarea, iniciamos la continuación y simultáneamente dimos dos parámetrosTaskContinuations.ExecuteSynchronously, después de lo cual comenzaron la continuación de forma asincrónica. ¿Se ejecutará en la misma pila donde finaliza la tarea anterior o se transferirá thread pool? En este caso, habrá una tercera opción: depende.
TaskCompletionSource
Considere TaskCompletionSource. Cuando crea una tarea, establece su resultado SetResultpara adaptar los patrones asincrónicos anteriores al mundo de la tarea. Puede TaskCompletionSourcesolicitar tcs.Task, y esta tarea entrará en estado finishcuando llame tcs.SetResult. Sin embargo, si ejecuta esto en el grupo de subprocesos , obtendrá un punto muerto . La pregunta es, ¿por qué si no escribimos nada incluso sincrónicamente? Creamos
Creamos TaskCompletionSource, comenzamos una nueva tarea, y tenemos un segundo hilo que inicia algo en esta tarea. Pasa y cae en la expectativa de cien milisegundos. Entonces nuestro hilo principal, el verde, va a esperar y eso es todo. Libera la pila, la pila se cuelga, esperando ser llamada en una continuacióntask.Waitcuando tcsexpuestoEn el hilo azul llegamos tcs, y luego el más interesante. Basado en consideraciones internas de .NET, él TaskCompletionSourcecree que la continuación de esto tcspuede realizarse sincrónicamente, es decir, directamente en la misma pila, luego esto task.Waitse realiza sincrónicamente en la misma pila. Esto es muy extraño, a pesar de que ni siquiera hemos escrito en ningún lado ExecuteSynchronously. Este es probablemente el problema con la mezcla de código síncrono y asíncrono. Otro problema con esto
Otro problema con esto TaskCompletionSourcees que cuando llamamos SetResultbajo el candado , no puede llamar a un código arbitrario, ya que bajo el candado solo puede realizar una pequeña actividad granular. Corre debajo de algunas acciones, es imposible venir de donde vinieron. ¿Cómo resolver este problema?var tcs = new TaskCompletionSource<int>(
TaskContinuationsOptions.RunContinuationsAsynchronously
) ;
lock(mylock)
{
tcs.SetResult(O);
});
Vale la TaskCompletionSourcepena usar solo para la adaptación del código no Task en las bibliotecas. Casi todo lo demás se puede resolver a través de la espera. En este caso, siempre se recomienda encarecidamente prescribir el parámetro "TaskCompletionSource.RunContinuationsAsynchronously" . Casi siempre necesita ejecutar una continuación de forma asincrónica. En este caso, tcs.SetResulttiene algo debajo de lo cual no se iniciará nada. ¿Por qué la continuación debe realizarse sincrónicamente? Porque se
¿Por qué la continuación debe realizarse sincrónicamente? Porque se RunContinuationsAsynchronouslyrefiere a lo siguiente ContinueWith, y no a lo nuestro. Para relacionarse con los nuestros, debe escribir lo siguiente: Este ejemplo muestra cómo los parámetros no son intuitivos, cómo se cruzan entre sí, cómo introducen la complejidad cognitiva; es muy difícil escribir.
Este ejemplo muestra cómo los parámetros no son intuitivos, cómo se cruzan entre sí, cómo introducen la complejidad cognitiva; es muy difícil escribir.Jerarquía padre-hijo
Task.Factory.StartNew(() =>
{
Task.Factory.StartNew(() => {
})
})
.ContinueWith(...)
Hay otras opciones para usar parámetros. Por ejemplo, una jerarquía padre-hijo surge cuando inicia una tarea y ejecuta otra debajo de ella. En este caso, si escribe ContinueWith, ContinueWithno esperará la tarea iniciada en su interior.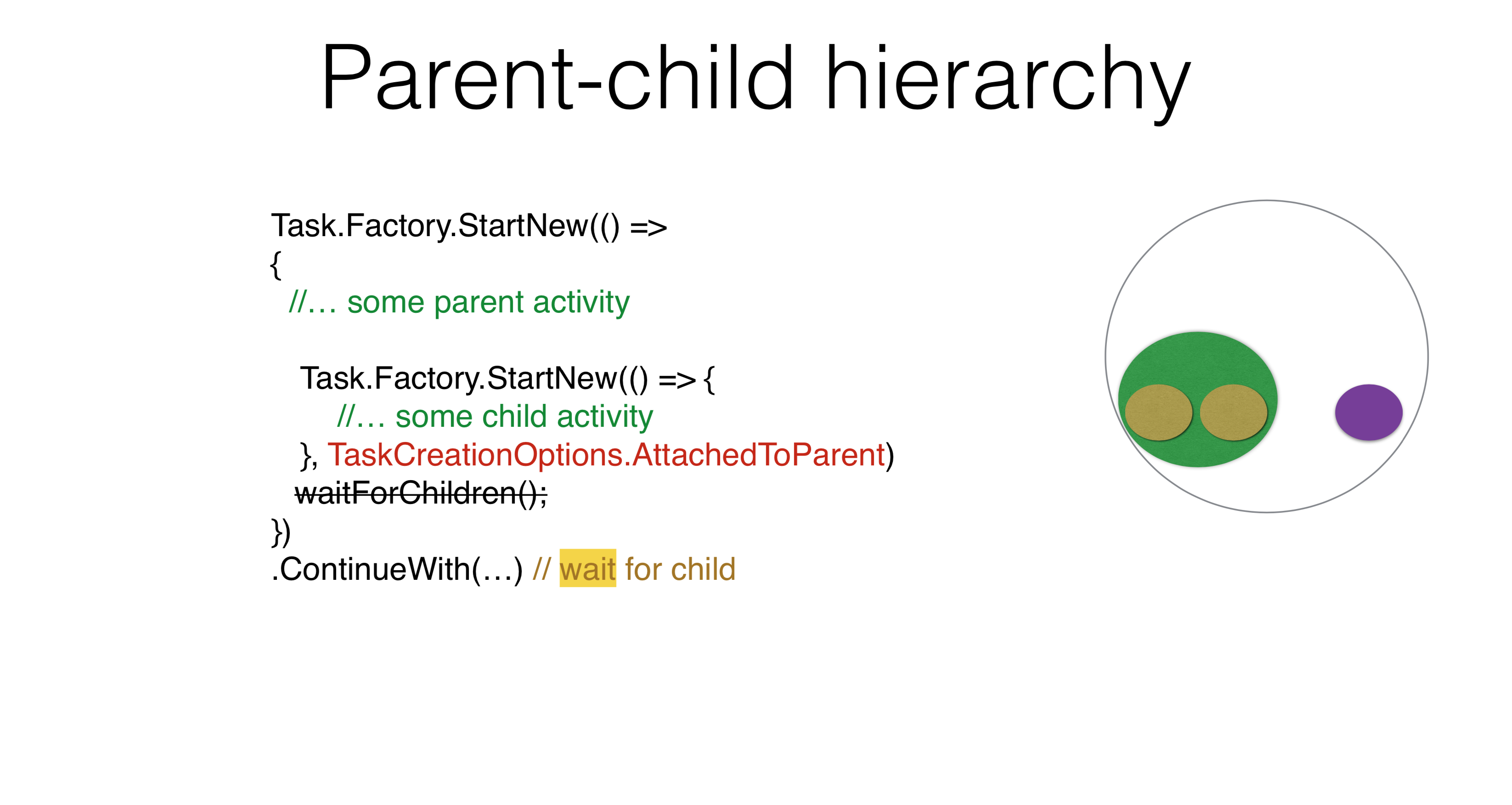 Si escribes
Si escribes TaskCreationOptions.AttachedToParent, ContinueWithesperará. Puede usar esta propiedad en sus productos. Creo que todos pueden encontrar un ejemplo en el que haya una jerarquía de tareas, con la tarea esperando la subtarea y la subtarea para sus subtareas. No es necesario escribir en ningún lado WaitForChildren, esta espera ocurre de forma asíncrona. Es decir, el cuerpo de la tarea principal finaliza y, después de eso, la tarea principal no se considera completa, no comienza sus continuaciones hasta que las tareas secundarias funcionen.Task.Factory.StartNew(() =>
{
Foo();
})
.ContinueWith(...)
void Foo() {
Task.Factory.StartNew(() => {
}, TaskCreationOptions.AttachedToParent);
}
Puede haber un problema en el que la tarea se transfiere en algún lugar ThreadStatic, entonces todo lo que comenzó AttachedToParentse agregará a esta tarea principal, que es una campana de alarma.Task.Factory.StartNew(() =>
{
Foo();
}, TaskCreationOptions.DenyChildAttach)
.ContinueWith(...)
void Foo() {
Task.Factory.StartNew(() => {
}, TaskCreationOptions.AttachedToParent);
}
Por otro lado, hay una opción que cancela la opción anterior DenyChildAttach. Tal aplicación ocurre con bastante frecuencia.Task.Run(() =>
{
Foo();
})
.ContinueWith(...)
void Foo() {
Task.Factory.StartNew(() => {
}, TaskCreationOptions.AttachedToParent);
}
Vale la pena recordar que Task.Runesta es la forma estándar de comenzar, lo que por defecto implica DenyChildAttach.El contexto implícito que pones te ThreadStaticagrega complejidad. No comprende cómo funciona la tarea, porque necesita conocer el contexto. Otro problema que puede surgir está relacionado con el estado inactivo de asíncrono / espera. Eso es porque en async / wait no tienes tareas, sino acciones. La continuación no es tarea honesta, sino acción. Cuando escribe código asíncrono / espera, no necesita usarlo AttachedToParentporque vincula explícitamente las tareas para esperar en espera, y este es el enfoque correcto. Tiene seis opciones sobre cómo comenzar una continuación. Lanzaste tarea, lanzaste
Tiene seis opciones sobre cómo comenzar una continuación. Lanzaste tarea, lanzasteContinueWith. Pregunta: ¿Qué estado tendrá esta continuación? Hay cinco respuestas posibles:- la continuación general se completará con éxito; se ejecutará RunToCompletion;
- la tarea estará en error;
- se producirá la cancelación;
- la tarea no llegará a completarse en absoluto, será en algún tipo de limbo;
- opción - "depende".
 En este caso, la tarea estará en el estado "cancelado", aunque en ninguna parte está la palabra "cancelado" en ninguna parte. Aquí tiramos la recepción y no hacemos nada. El problema es que cuando lees el código de otra persona con muchas opciones, incluso si conocías estas opciones hace 10 minutos, todavía olvidas lo que sucede aquí. Entonces no escribas.
En este caso, la tarea estará en el estado "cancelado", aunque en ninguna parte está la palabra "cancelado" en ninguna parte. Aquí tiramos la recepción y no hacemos nada. El problema es que cuando lees el código de otra persona con muchas opciones, incluso si conocías estas opciones hace 10 minutos, todavía olvidas lo que sucede aquí. Entonces no escribas.Cancelación
Task.Factory.StartNew(() =>
{
throw new OperationCanceledException();
});
Failed
El tercer parámetro al comienzo de la tarea es kancellation. Usted escribe OperationCanceledException, es decir, una acción especial que pone la tarea en el estado "Cancelado". En este caso, la tarea estará en el estado "Fallido", porque no todos OperationCanceledExceptionson iguales.Task.Factory.StartNew(() =>
{
throw new OperationCanceledException(cancellationToken);
}, cancellationToken);
Canceled
Para que la tarea sea posible Canceled, debe lanzarla OperationCanceledExceptionjunto con su CancellationToken. En realidad, nunca haces esto explícitamente, pero hazlo de esta manera:Task.Factory.StartNew(() =>
{
cancellationToken.ThrowIfCancellationRequested();
}, cancellationToken);
Canceled
¿Es necesario distinguir cancelationToken? En algún lugar dentro de la tarea, verifica que alguien lo haya eliminado: cancelación de lanzamiento, luego la tarea entra en estado Canceled. O alguien hizo clic en "Cancelar" en tiempo de ejecución y canceló la tarea. Nuestra práctica en JetBrains sugiere que no es necesario distinguir entre estos tokens. Si obtiene una excepción OperationCanceledException , un tipo especial que ocurre cuando se produce alguna cancelación, puede distinguirla. En este caso, solo necesita completar la tarea normalmente, no inicie sesión y cuando reciba la ejecución, inicie sesión.Pila profunda
Task.Factory.StartNew(() =>
{
Foo();
}, cancellationToken);
void Foo() {
Bar() {
...
Baz() {
}
}
}
Digamos que tienes una pila profunda. Este CancellationTokenes el único parámetro explícito que discutimos. Debe transmitirse a todas partes a través de absolutamente todas las jerarquías. ¿Qué hacer si en presencia de una jerarquía profunda necesita cancelar su tarea en algún lugar, en el nivel más bajo, para tirar la recepción? Hay un truco tan especial que usamos. El es llamado AsyncLocal.static AsyncLocal<Cancelation> asyncLocalCancellation;
Task.Factory.StartNew(() =>
{
asyncLocalCancellation.Set(cancellationToken)
Foo();
}, cancellationToken);
void Foo() {
async Bar() {
...
Baz() {
asyncLocalCancellation.Value.CheckForInterrupt();
}
}
}
Esto es lo mismo, ThreadStaticsolo el especial ThreadLocalque sobrevive a los viajes de código asíncrono / en espera. Como su código es asíncrono y tiene esta anulación, la ingresa y, en AsyncLocalalgún lugar a un nivel profundo, puede decir " CheckForInterrupt Throw If Cancellation Requested". Nuevamente, este es el único parámetro CancellationTokenque necesita difuminar por completo el código completo, pero, en mi opinión, para la mayoría de las tareas solo necesita saber qué sucedió OperationCanceledException, y de esto sacar una conclusión de qué estado: Cancelado o Fallido.Complejidad cognitiva
Task.Factory.StartNew(Action,
TaskCreationOptions,
TaskScheduler,
CancellationToken
)
JetBrains.Lifetimes
lifetime.Start(TaskScheduler, Action)
lifetime.StartMainRead(Action)
lifetime.StartMainWrite(TaskScheduler, Action)
lifetime.StartBackgroundRead(TaskScheduler, Action)
Cuanto más difícil sea leer el código al iniciar la tarea, mayor será el riesgo de error. Si observa el código después de un año, olvidará lo que hace, porque hay una gran cantidad de parámetros. Pero tenemos la biblioteca JetBrains.Lifetimes , que ofrece vidas modernas, CancellationToken bien optimizado, con el que se reescribió el método Start y se resolvió el problema de repetir partes de código, como con Task.Factory.StartNewy TaskCreationOptions.Hay una pequeña cantidad de programadores que le permiten programar una tarea en el hilo principal con bloqueo de lectura. Es decir, el bloqueo de lectura no es algo que elija explícitamente, es un programador especial que programa su código en el hilo principal con bloqueo de lectura, así como el subproceso principal con bloqueo de escritura, subproceso de fondo, y ahora los métodos se vuelven muy simples para iniciar el reordenamiento. Al mismo tiempo, las vidas se cancelan automáticamente AsyncLocal, simplificando significativamente el código. Veamos cómo async / await resuelve estos problemas y qué problemas presentan.En este ejemplo, parte del código se ejecuta sincrónicamente, luego espera un código asíncrono. En primer lugar, es bueno que haya muchos menos códigos de repetición ( placa de caldera ). En segundo lugar, es bueno que el código asíncrono sea muy similar al código síncrono, para eso es exactamente asíncrono / espera . Puede escribir de forma asincrónica de la misma manera que escribió sincrónicamente, sin ocupar hilos.¿En qué caso se implementará el compilador? El código sincrónico se ejecutará sincrónicamente, después de lo cual la tarea
Veamos cómo async / await resuelve estos problemas y qué problemas presentan.En este ejemplo, parte del código se ejecuta sincrónicamente, luego espera un código asíncrono. En primer lugar, es bueno que haya muchos menos códigos de repetición ( placa de caldera ). En segundo lugar, es bueno que el código asíncrono sea muy similar al código síncrono, para eso es exactamente asíncrono / espera . Puede escribir de forma asincrónica de la misma manera que escribió sincrónicamente, sin ocupar hilos.¿En qué caso se implementará el compilador? El código sincrónico se ejecutará sincrónicamente, después de lo cual la tarea InnerAsyncse ejecutará sincrónicamente , ¿de dónde viene el objeto especial GetAwaiter? En este caso, estamos interesados TaskAwaiter. Puedes escribirle a tu mesero para absolutamente cualquier objeto. Como resultado, esperamos que la tarea se complete InnerAsyncy la ejecute sincrónicamente continuationCode. Si la tarea no se completó, el código de continuación se programa en el planificador de contexto . Puede ser que, aunque haya escrito aguardar , absolutamente todo se llamará sincrónicamente.async Task MyFuncAsync() {
synchronousCode();
await InnerAsync();
await Task.Yield();
continuationCode();
}
Hay un truco Task.Yield: esta es una tarea especial que garantiza que su camarero no siempre volverá a usted IsCompleted. En consecuencia, continuationno se llamará sincrónicamente en este lugar. Para un subproceso de interfaz de usuario, esto puede ser importante porque no toma este subproceso durante un período prolongado. ¿Cómo elegir un hilo para la continuación? La filosofía asíncrona / espera es la siguiente: usted escribe código asíncrono igual que sincrónico. Si tiene un grupo de subprocesos , no hay diferencia para usted: el código de continuación se ejecutará en otro subproceso. Independientemente de si se
¿Cómo elegir un hilo para la continuación? La filosofía asíncrona / espera es la siguiente: usted escribe código asíncrono igual que sincrónico. Si tiene un grupo de subprocesos , no hay diferencia para usted: el código de continuación se ejecutará en otro subproceso. Independientemente de si se InnerAsynccompletó cuando dijo esperar o no, necesita todo para ejecutar en el hilo de la interfaz de usuario.El mecanismo para la tarea en espera es el siguiente: se toma static, se llamaSynchronizationContexty de esto se crea TaskScheduler. SynchronizationContext es una cosa con el método Post, que es muy similar al método Queue. De hecho TaskScheduler, lo que era antes, simplemente toma SynchronizationContexty a través de Post realiza su tarea en él.async Task MyFuncAsync() {
synchronousCode();
await InnerAsync().ConfigureAwait(false);
continuationCode();
}
Hay una manera de cambiar este comportamiento usando un parámetro ContinueOnCapturedContext. Se llama la API más desagradable que está en .NET ConfigureAwait. En este caso, la API crea un camarero especial que es diferente del TaskAwaiterque cambia la continuación, se ejecuta en el mismo hilo, en el mismo contexto en el que terminó el método InnerAsync y donde terminó la tarea.async Task MyFuncAsync() {
synchronousCode();
await InnerAsync().ConfigureAwait(continueOnCapturedContext: false);
continuationCode();
}
Hay una cantidad increíble de consejos en Internet: si tiene un punto muerto , manche todo su código ConfigureAwait y todo estará bien. Este es el camino equivocado. ConfigureAwaitse puede usar en casos en los que desea mejorar ligeramente el rendimiento, o al final del método, en algunos métodos de biblioteca.Puntos muertos
async Task MyFuncAsync() {
synchronousCode();
await Task.Delay(10).ConfigureAwait(continueOnCapturedContext: false);
continuationCode();
}
myFuncAsync().Wait()
Este es un punto muerto clásico . En el hilo de la interfaz de usuario, esperaron diez segundos y lo hicieron Wait. Debido a lo que ha hecho Wait, continuationCodenunca se iniciará, Waitpor lo tanto , nunca volverá. Todo tiene lugar desde el principio.async Task OnBluttionClick() {
int v = Button.Text.ParseInt();
await Task.Delay(10).ConfigureAwait(continueOnCapturedContext: false);
Button.Text.Set((v+1).ToString());
}
myFuncAsync().Wait()
Imagina que esta es una actividad real. Hicimos clic en el botón, lo tomamos Button.ParseInt, lo hicimos esperar , escribimos ConfigureAwait. Decimos: "Por favor, no cierre nuestra transmisión de interfaz de usuario, realice la continuación". El problema es que queremos que la segunda parte después ConfigureAwaittambién se ejecute en el hilo de la interfaz de usuario, porque esta es la filosofía de esperar . Es decir, su código asincrónico tiene el mismo aspecto que el código síncrono y se ejecuta en el mismo contexto. En este caso, por supuesto, habrá un error. Y además Button.Text.Setpuede haber cualquier número de llamadas a métodos que también asuman su contexto. ¿Qué hacer en esta situación? Puedes hacerlo:async Task MyFuncAsync() {
synchronousCode();
await Task.Delay(10).ConfigureAwait(continueOnCapturedContext: false);
continuationCode();
}
PumpUntil(() => task.IsCompleted);
Con un subproceso de interfaz de usuario, debe prohibir hacerlo Waiten subprocesos que tienen una cola de mensajes común. En lugar de hacer Waito escribir ConfigureAwait, puede bombear esta cola de mensajes y, al mismo tiempo, también se bombeará el continuo. Si no puede mezclar código síncrono y asíncrono, entonces no debe mezclarlos. Pero a veces esto no se puede evitar.Por ejemplo, tiene un código antiguo y tiene que mezclarlos, luego bombea la transmisión de la interfaz de usuario. Visual Studio bombea el hilo de la interfaz de usuario a las expectativas, incluso SynchronizationContextcambió un poco. Si ingresas a WaitHandle en cualquiera Wait, cuando cuelgas, tu flujo de interfaz de usuario se bombea. Por lo tanto, eligen entre puntos muertos y razas a favor de la raza s.Pumpuntil- Esta es una API no ideal, es decir, cuando realiza una continuidad aleatoria en un lugar arbitrario, puede haber matices. No hay otra manera, desafortunadamente. Mezcle códigos síncronos y asíncronos. En todo caso, todo el Rider está tan organizado en los lugares antiguos, por lo que a veces también hay matices.Cambiar contexto
async Task MyFuncAsync() {
synchronousCode();
await myTaskScheduler;
continuationCode();
}
Hay otra forma interesante de usar async / await . Se puede escribir Awaiteren schedulery saltar sobre las discusiones. Leí publicaciones en Visual Studio, escribieron durante mucho tiempo que no es bueno saltar de un lado a otro en el medio del método, pero ahora lo hacen ellos mismos. Visual Studio tiene una API que salta sobre hilos a través de programadores. Para uso normal, hacer esto no es bueno.Concurrencia estructurada
async Task MyFuncAsync() {
synchronousCode();
await Task.Factory.StartNew(() => {...}, myTaskScheduler);
continuationCode();
}
Para una inmersión conveniente en el nuevo contexto y volver al antiguo, se debe construir cierta competencia estructural o paralelismo estructural. Por ejemplo, en los años sesenta, el operador GoTo se consideraba perjudicial porque violaba la estructuralidad. Entonces está aquí. Saltar sobre hilos viola lo estructural. Sorprendentemente, usar una máquina de estado asíncrono parece una buena salida. Es decir, cuando se viola su estructura habitual, salta a GoTo, puede violar la estructura del hilo: espere , mézclelo con etiquetas. Esta es una situación extremadamente extraña y rara cuando necesitas hacer esto. Aún así, es mejor cuando la espera vuelve al mismo contexto. Por lo tanto, el grupo de subprocesos no tendrá el mismo subproceso, sino el mismo contexto que originalmente.Comportamiento secuencial
¿Por qué esperar no es lo mismo que ejecución paralela? Aguardar ejecución es ejecución secuencial. En este caso, comenzamos la primera tarea, la esperamos, comenzamos la segunda tarea, esperamos. No tenemos paralelismo. Para la mayoría de los usos, el paralelismo no es necesario. El paralelismo en sí mismo es más complejo que la secuencia. El código de serie es más simple que paralelo, es un axioma. Pero a veces necesitas ejecutar algo en código paralelo, y lo haces así:async Task MyAsync() {
var task1 = StartTask1Async();
await task1;
var task2 = StartTask2Async();
await task2;
}
Comportamiento concurrente
async Task MyAsync() {
var task1 = StartTask1Async();
var task2 = StartTask2Async();
await task1;
await task2;
}
Aquí las tareas comienzan en paralelo. Está claro que los métodos pueden devolver la tarea inmediatamente en un estado de ejecución, entonces no habrá paralelismo. Digamos que ambos tasky lanzan una ejecución. Y esperaste la primera tarea, luego la primera espera despegó. Es decir, tan pronto como escribió await task1, despegó y no procesó exception task2. Curiosamente, este es un código absolutamente válido. Y es este código el que llevó a .NET al hecho de que en la versión 4.5 el comportamiento de trabajar con ejecuciones ha cambiado.Manejo de excepciones
async Task MyAsync() {
var task1 = StartTask1Async();
var task2 = StartTask2Async();
await task1;
await task2;
}
Anteriormente, las ejecuciones no controladas simplemente arrojaban el proceso, y si no captó alguna ejecución UnobservedExceptionHandler(esto también es algo staticque puede adjuntar a los planificadores), entonces este proceso no se ejecutó. Ahora este es un código absolutamente válido. Aunque .NET cambió su comportamiento, conservó la configuración para devolver el comportamiento en la dirección opuesta.async Task MyAsync(CancellationToken cancellationToken) {
await SomeTask1 Async(cancellationToken);
await Some Task2Async( cancellation Token);
}
try {
await MyAsync( cancellation Token);
} catch (OperationException e) {
} catch (Exception e) {
log.Error(e);
}
Vea cómo va el procesamiento de la ejecución. CancellationToken-s debe transmitirse, es necesario "difuminar" CancellationToken-s todo el código. El comportamiento normal de asíncrono es que no verifica en ninguna parte Task.Status ancellationToken, trabaja con código asíncrono de la misma manera que con síncrono. Es decir, en el caso de una cancelación, obtiene una ejecución y, en este caso, no hace nada cuando la recibe OperationCanceledException.La diferencia entre el estado de Cancelado y Fallido es que no recibió OperationCanceledException, sino la ejecución habitual. Y en este caso, podemos prometerlo, solo necesita obtener una ejecución y sacar conclusiones basadas en esto. Si comenzaste la tarea explícitamente, a través de la Tarea, hubieras volado AggregateException. Y en asíncrono, en el caso AggregateExceptionsiempre lanzan la primera ejecución que estaba en él (en este caso - OperationCanceled).En la práctica
Método sincrónico
DataTable<File, ProcessedFile> sharedMemory;
void SynchronousWorker(...) {
File f = blockingQueue.Dequeue();
ProcessedFile p = ProcessInParallel(f);
lock (_lock) {
sharedMemory.add(f, p);
}
}
Por ejemplo, un demonio trabaja en ReSharper, un editor que tiñe el archivo por usted. Si el archivo se abre en el editor, entonces hay alguna actividad que lo coloca en una cola de bloqueo. Nuestro proceso workerlee desde allí, después de lo cual realiza un montón de tareas diferentes con este archivo, lo tiñe, analiza, compila, luego de lo cual se agregan estos archivos sharedMemory. Con un sharedMemorybloqueo, otros mecanismos ya están trabajando con él.Método asincrónico
Al volver a escribir el código en asíncrono, en primer lugar lo reemplazaremos voidpor async Task. Asegúrese de escribir la palabra "Async" al final. Todos los métodos asincrónicos deben terminar en asíncrono; esta es una convención.DataTable<File, ProcessedFile> sharedMemory;
async Task WorkerAsync(...) {
File f = blockingQueue.Dequeue();
ProcessedFile p = ProcessInParallel(f);
lock (_lock) {
sharedMemory.add(f, p);
}
}
Después de eso, debes hacer algo con los nuestros blockingQueue. Obviamente, si hay alguna primitiva síncrona, entonces debe haber alguna primitiva asíncrona. Esta primitiva se llama canal: los canales que viven en el paquete
Esta primitiva se llama canal: los canales que viven en el paquete System.Threading.Channels. Puede crear canales y colas, limitadas e ilimitadas, que puede esperar de forma asíncrona. Además, puede crear un canal con un valor de "cero", es decir, no tendrá un búfer en absoluto. Dichos canales se denominan canales de encuentro y se promueven activamente en Go y Kotlin. Y, en principio, si es posible usar canales en código asíncrono, este es un patrón muy bueno. Es decir, cambiamos la cola al canal donde hay métodos ReadAsyncy WriteAsync.ProcessInParallel es un montón de código paralelo que procesa un archivo y lo convierte enProcessedFile. ¿Puede async ayudarnos a escribir no asíncrono, sino código paralelo más compacto?Simplifique el Código Paralelo
El código se puede reescribir de esta manera:DataTable<File, ProcessedFile> sharedMemory;
async Task WorkerAsync(...) {
File f = await channel.ReadAsync();
ProcessedFile p = await ProcessInParallelAsync(f);
lock (_lock) {
sharedMemory.add(f, p);
}
}
 ¿Cómo se ven
¿Cómo se ven ProcessInParallel? Por ejemplo, tenemos un archivo. Primero, lo dividimos en lexemas, y podemos tener dos tareas en paralelo: construir cachés de búsqueda y construir un árbol de sintaxis. Después de eso viene la tarea de "buscar errores semánticos". Aquí es importante que todas estas tareas formen un gráfico acíclico dirigido. Es decir, puede ejecutar algunas partes en subprocesos paralelos, otras no, y obviamente hay dependencias de qué tarea debería esperar otras tareas. Obtiene un gráfico de tales tareas, desea dispersarlas de alguna manera a lo largo de los hilos. ¿Es posible escribirlo bellamente, sin errores? En nuestro código, este problema se resolvió varias veces, cada una de manera diferente. Raramente ocurre cuando este código se escribe sin errores. Definimos este gráfico de tareas de la siguiente manera: digamos que cada tarea tiene otras tareas de las que depende, luego, usando el diccionario ExecuteBefore, escribimos el esqueleto de nuestro método.
Definimos este gráfico de tareas de la siguiente manera: digamos que cada tarea tiene otras tareas de las que depende, luego, usando el diccionario ExecuteBefore, escribimos el esqueleto de nuestro método.Soluciones de esqueleto
Dictionary<Action<ProcessedFile>, Action<ProcessedFile>[]> ExecuteBefore; async Task<ProcessedFile> ProcessInParallelAsync() {
var res = new ProcessedFile();
return res;
}
Si resuelve este problema de frente, debe hacer una clasificación topológica de este gráfico. Luego tome una tarea que no tenga tareas dependientes, ejecútela, analice la estructura debajo de un candado, vea qué tareas no tienen dependientes. Corre, dispersalos de alguna manera Task Runner. Lo escribimos un poco más compacto: clasificación topológica del gráfico + ejecución de tales tareas en diferentes hilos.Asíncrono perezoso
Dictionary<Action<ProcessedFile>, Action<ProcessedFile>[]> ExecuteBefore;
async Task<ProcessedFile> ProcessInParallelAsync() {
var res = new ProcessedFile();
var lazy = new Dictionary<Action<ProcessedFile>, Lazy<Task>>();
foreach ((action, beforeList) in ExecuteBefore)
lazy[action] = new Lazy<Task>(async () =>
{
await Task.WhenAll(beforeList.Select(b => lazy[b].Value))
await Task.Yield();
action(res);
}
await Task.WhenAll(lazy.Values.Select(l => l.Value))
return res;
}
Hay un patrón llamado Async Lazy. Creamos el nuestro ProcessedFileen el que se deben ejecutar diferentes acciones. Creemos un diccionario: formatearemos cada una de nuestras etapas (Action ProcessedFile) en alguna Tarea, o más bien, en Lazy desde Task y correremos a lo largo del gráfico original. La variable actiontendrá la acción en sí , y en beforeList: aquellas acciones que deben realizarse antes que la nuestra. Luego crea Lazydesde action. Escribimos en Tarea await. Por lo tanto, estamos esperando todas las tareas que deben completarse antes. En beforeList, seleccione el Lazyque está en este diccionario.Tenga en cuenta que aquí no se ejecutará nada sincrónicamente, por lo que este código no se ejecutará ItemNotFoundException in Dictionary. Realizamos todas las tareas anteriores a la nuestra, realizando una búsqueda por acciónLazy Task. Luego ejecutamos nuestra acción. Al final, solo necesita pedir que comience cada tarea, de lo contrario, nunca se sabe si algo no comenzó. En este caso, nada comenzó. Esta es la solución Este método está escrito en 10 minutos, es absolutamente obvio.Por lo tanto, el código asincrónico tomó nuestra decisión, inicialmente ocupó un par de pantallas con código competitivo complejo. Aquí él es absolutamente consistente. Ni siquiera lo uso ConcurrentDictionary, uso el habitual Dictionary, porque no le escribimos nada de forma competitiva. Hay un código consistente, consistente. Solucionamos el problema de escribir código paralelo usando async-s maravillosamente, lo que significa, sin errores.Deshágase de las cerraduras
DataTable<File, ProcessedFile> sharedMemory;
async Task WorkerAsync(...) {
File f = await channel.ReadAsync();
ProcessedFile p = await ProcessInParallelAsync(f);
lock (_lock) {
sharedMemory.add(f, p);
}
}
¿Vale la pena tirar de asíncrono y estas cerraduras? Ahora hay todo tipo de bloqueos asíncronos, semáforos asíncronos, es decir, un intento de usar las primitivas que están en código síncrono y asíncrono. Este concepto parece estar equivocado, porque con el bloqueo protege algo de la ejecución paralela. Nuestra tarea es traducir la ejecución paralela en secuencial, porque es más fácil. Y si es más simple, hay menos errores.Channel<Pair<File, ProcessedFile>> output;
async Task WorkerAsync(...) {
File f = await channel.ReadAsync();
ProcessedFile p = await ProcessInParallelAsync(f);
await output.WriteAsync();
}
Podemos crear algún canal y colocar un par de archivos y archivos procesados, y ReadAsyncalgún otro procedimiento procesará este canal , y lo hará de forma secuencial. El bloqueo en sí mismo, además de proteger la estructura, esencialmente linealiza el acceso, un lugar donde todos los hilos consecutivos se vuelven paralelos. Y estamos reemplazando esto explícitamente con el canal. La arquitectura es la siguiente: los trabajadores reciben archivos
La arquitectura es la siguiente: los trabajadores reciben archivos inputy los envían al procesador, que también procesa todo secuencialmente, no hay paralelismo. El código se ve mucho más simple. Entiendo que no todo se puede hacer de esta manera. Dicha arquitectura, cuando puede construir canalizaciones de datos, no siempre funciona. Puede ser que tenga un segundo canal que entre en su procesador y no se forme un gráfico dirigido acíclico a partir de los canales, sino un gráfico con ciclos. Este es un ejemplo que Roman Elizarov le dijo a KotlinConf en 2018. Escribió un ejemplo en Kotlin con estos canales, y hubo ciclos allí, y este ejemplo se cerró. El problema era que si tienes tales ciclos en un gráfico, entonces todo se vuelve más complicado en el mundo asincrónico. Los puntos muertos asíncronos son malos porque son mucho más difíciles de resolver que los síncronos cuando tienes una pila de subprocesos, y está claro de qué depende. Por lo tanto, es una herramienta que debe usarse correctamente.
Puede ser que tenga un segundo canal que entre en su procesador y no se forme un gráfico dirigido acíclico a partir de los canales, sino un gráfico con ciclos. Este es un ejemplo que Roman Elizarov le dijo a KotlinConf en 2018. Escribió un ejemplo en Kotlin con estos canales, y hubo ciclos allí, y este ejemplo se cerró. El problema era que si tienes tales ciclos en un gráfico, entonces todo se vuelve más complicado en el mundo asincrónico. Los puntos muertos asíncronos son malos porque son mucho más difíciles de resolver que los síncronos cuando tienes una pila de subprocesos, y está claro de qué depende. Por lo tanto, es una herramienta que debe usarse correctamente.Resumen
- Evite la sincronización en código asincrónico.
- El código de serie es más simple que el paralelo.
- El código asincrónico puede ser simple y usar un mínimo de parámetros y un contexto implícito que cambie su comportamiento.
Si ha desarrollado el hábito de escribir código síncrono, e incluso si el código asíncrono es muy similar al síncrono, no necesita arrastrar primitivas allí, a lo que está acostumbrado en código síncrono como async mutex. Utilice feeds, si es posible, y otras primitivas de paso de mensajes .El código de serie es más simple que el paralelo. Si puede escribir su arquitectura para que se vea secuencialmente, sin ejecutar código paralelo y bloqueo, entonces escriba la arquitectura secuencialmente.Y lo último que vimos de una gran cantidad de ejemplos con tareas. Cuando diseñe su sistema, trate de confiar menos en el contexto implícito. El contexto implícito conduce a un malentendido de lo que está sucediendo en el código, y puede olvidarse de los problemas implícitos en un año. Y si otra persona trabaja en este código y rehace algo en él, esto puede conducir a dificultades que una vez conoció, y el nuevo programador no lo sabe debido al contexto implícito. Como resultado, el diseño deficiente se caracteriza por una gran cantidad de parámetros, su combinación y contexto implícito.Que leer
-10 . DotNext .