Miles de gerentes de oficinas de ventas en todo el país registran decenas de miles de contactos en nuestro sistema CRM todos los días , hechos de comunicación con clientes potenciales o que ya trabajan con nosotros. Y para este cliente primero debe encontrar, y preferiblemente muy rápidamente. Y esto sucede con mayor frecuencia por su nombre.Por lo tanto, no es sorprendente que, una vez más analizando las solicitudes "pesadas" en una de las bases de datos más cargadas, nuestra propia cuenta VLSI corporativa , encontré "en la parte superior" una solicitud de búsqueda "rápida" por nombre de tarjetas de empresa.Además, una investigación adicional reveló un ejemplo interesante de optimización y luego degradación del rendimiento. solicitud en su posterior refinamiento por varios equipos, cada uno de los cuales actuó únicamente con buenas intenciones.0: qué quería el usuario
[KDPV desde aquí ]¿Qué quiere decir usualmente el usuario cuando dice "búsqueda rápida" por nombre? Casi nunca resulta ser una búsqueda "honesta" en una subcadena de tipo ... LIKE '%%', porque entonces no solo y , sino incluso, incluso obtienen el resultado . El usuario implica a nivel de hogar que le proporcionará una búsqueda al comienzo de una palabra en el título y mostrará más relevante lo que comienza con el ingresado. Y hágalo casi instantáneamente , con entrada interlineal.''' '''' '1: limitar la tarea
Y aún más, una persona no ingresará específicamente ' 'para que tenga que buscar cada prefijo de palabra. No, es mucho más fácil para el usuario responder a una pista rápida para la última palabra que "omitir" deliberadamente las anteriores; vea cómo funciona cualquier motor de búsqueda.En general, formular correctamente los requisitos para una tarea es más de la mitad de la solución. A veces, un análisis cuidadoso del caso de uso puede afectar significativamente el resultado .¿Qué hace el desarrollador abstracto?1.0: motor de búsqueda externo
Oh, buscar es difícil, no quiero hacer nada en absoluto, ¡vamos a dárselo a los devops! Permítanos desplegarnos un motor de búsqueda externo en relación con la base de datos: Sphinx, ElasticSearch, ... Unaopción que funciona, aunque consume mucho tiempo, en términos de sincronización y velocidad de cambio. Pero no en nuestro caso, ya que la búsqueda se realiza para cada cliente solo en el marco de los datos de su cuenta. Y los datos tienen una variabilidad bastante alta, y si el administrador ahora ha insertado la tarjeta ' ', después de 5-10 segundos ya puede recordar que olvidó indicar el correo electrónico allí y desea encontrarlo y corregirlo.Por lo tanto, busquemos "directamente en la base de datos" . Afortunadamente, PostgreSQL nos permite hacer esto, y no solo una opción: las consideraremos.1.1: subcadena "honesta"
Nos aferramos a la palabra "subcadena". Pero exactamente para la búsqueda de índice por subcadena (¡e incluso por expresiones regulares!) ¡Hay un excelente módulo pg_trgm ! Solo entonces será necesario ordenar correctamente.Tratemos de tomar un plato para simplificar el modelo:CREATE TABLE firms(
id
serial
PRIMARY KEY
, name
text
);
Completamos allí 7.8 millones de registros de organizaciones reales e indexamos:CREATE EXTENSION pg_trgm;
CREATE INDEX ON firms USING gin(lower(name) gin_trgm_ops);
Busquemos las primeras 10 entradas para la búsqueda entre líneas:SELECT
*
FROM
firms
WHERE
lower(name) ~ ('(^|\s)' || '')
ORDER BY
lower(name) ~ ('^' || '') DESC
, lower(name)
LIMIT 10;
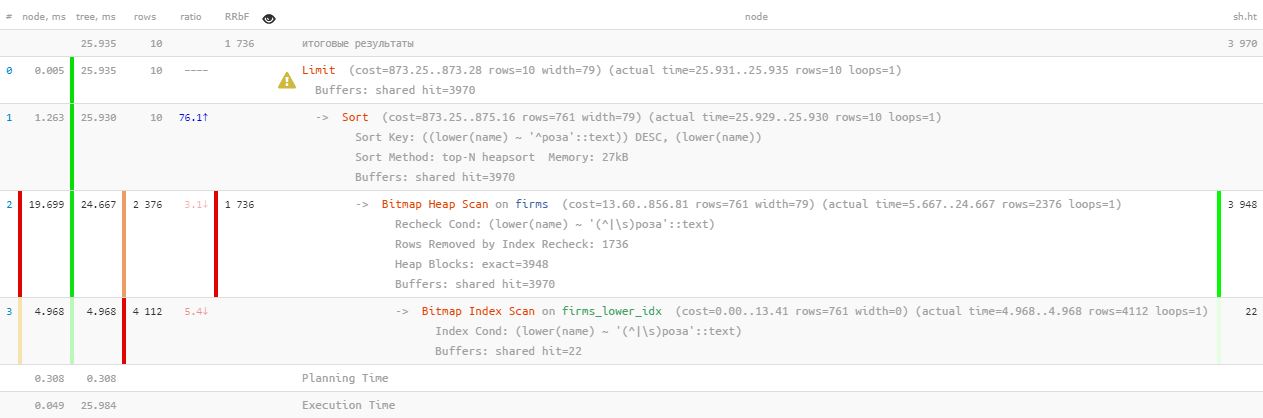 [eche un vistazo a explicar.tensor.ru]Bueno, eso es ... 26 ms, 31 MB de datos leídos y más de 1.700 registros filtrados, para 10 personas La sobrecarga es demasiado alta, ¿es posible ser de alguna manera más eficiente?
[eche un vistazo a explicar.tensor.ru]Bueno, eso es ... 26 ms, 31 MB de datos leídos y más de 1.700 registros filtrados, para 10 personas La sobrecarga es demasiado alta, ¿es posible ser de alguna manera más eficiente?1.2: búsqueda de texto? es FTS!
De hecho, PostgreSQL proporciona un mecanismo muy poderoso para la búsqueda de texto completo (Búsqueda de texto completo), incluida la posibilidad de búsqueda de prefijos. ¡Una gran opción, incluso las extensiones no necesitan ser instaladas! Intentemos:CREATE INDEX ON firms USING gin(to_tsvector('simple'::regconfig, lower(name)));
SELECT
*
FROM
firms
WHERE
to_tsvector('simple'::regconfig, lower(name)) @@ to_tsquery('simple', ':*')
ORDER BY
lower(name) ~ ('^' || '') DESC
, lower(name)
LIMIT 10;
 [mire explicar.tensor.ru]Aquí la paralelización de la ejecución de consultas nos ayudó un poco, reduciendo el tiempo a la mitad a 11 ms . Sí, y tuvimos que leer 1,5 veces menos, solo 20 MB . Y aquí, cuanto más pequeño, mejor, porque cuanto mayor sea la cantidad que restamos, mayores serán las posibilidades de perder el caché, y cada página adicional de datos leída del disco es un "freno" potencial para la solicitud.
[mire explicar.tensor.ru]Aquí la paralelización de la ejecución de consultas nos ayudó un poco, reduciendo el tiempo a la mitad a 11 ms . Sí, y tuvimos que leer 1,5 veces menos, solo 20 MB . Y aquí, cuanto más pequeño, mejor, porque cuanto mayor sea la cantidad que restamos, mayores serán las posibilidades de perder el caché, y cada página adicional de datos leída del disco es un "freno" potencial para la solicitud.1.3: ¿Aún ME GUSTA?
La solicitud anterior es buena para todos, pero solo si la extrae cien mil veces al día, se acumularán 2 TB de datos leídos. En el mejor de los casos, desde la memoria, pero si no tienes suerte, desde el disco. Así que tratemos de hacerlo más pequeño.Recuerde que el usuario quiere ver primero "que comienza con ..." . ¡Así que esto es en su forma pura una búsqueda de prefijo con text_pattern_ops! Y solo si "no somos suficientes" hasta 10 registros requeridos, tendremos que leerlos usando la búsqueda de FTS:CREATE INDEX ON firms(lower(name) text_pattern_ops);
SELECT
*
FROM
firms
WHERE
lower(name) LIKE ('' || '%')
LIMIT 10;
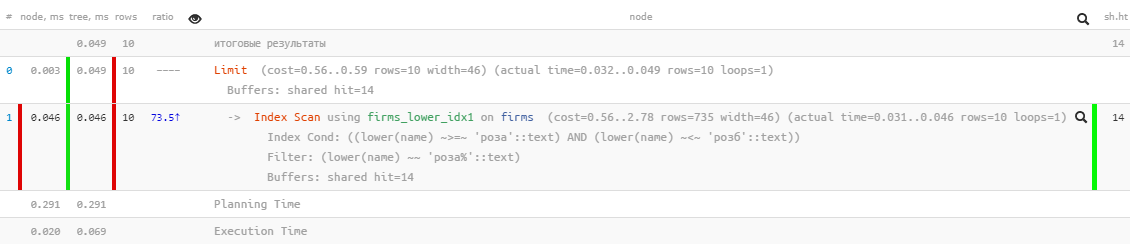 [mire explicar.tensor.ru]Excelente rendimiento: ¡solo 0.05 ms y un poco más de 100 KB de lectura! Solo nos olvidamos de ordenar por nombre para que el usuario no se pierda en los resultados:
[mire explicar.tensor.ru]Excelente rendimiento: ¡solo 0.05 ms y un poco más de 100 KB de lectura! Solo nos olvidamos de ordenar por nombre para que el usuario no se pierda en los resultados:SELECT
*
FROM
firms
WHERE
lower(name) LIKE ('' || '%')
ORDER BY
lower(name)
LIMIT 10;
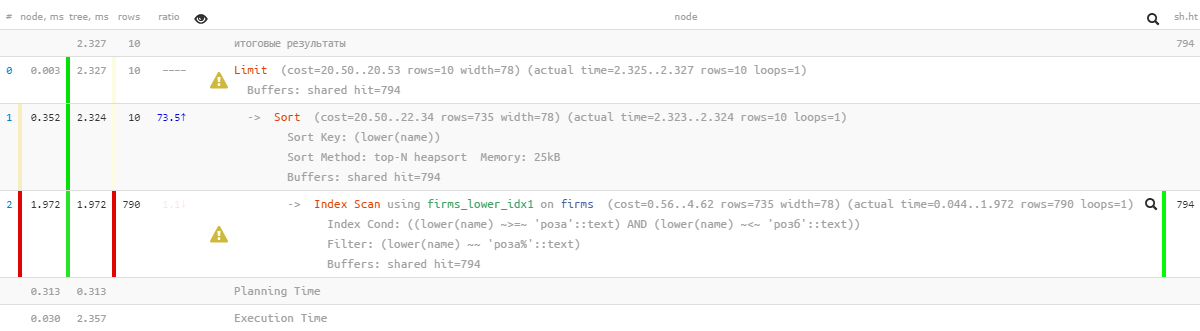 [mire explicar.tensor.ru]Oh, algo ya no es tan bonito: parece que hay un índice, pero la clasificación pasa volando ... Es, por supuesto, muchas veces más efectivo que la versión anterior, pero ...
[mire explicar.tensor.ru]Oh, algo ya no es tan bonito: parece que hay un índice, pero la clasificación pasa volando ... Es, por supuesto, muchas veces más efectivo que la versión anterior, pero ...1.4: "modificar con un archivo"
Pero hay un índice que le permite buscar por rango, y es normal usar la clasificación: ¡ btree normal !CREATE INDEX ON firms(lower(name));
Solo una solicitud para ello deberá "ensamblarse manualmente":SELECT
*
FROM
firms
WHERE
lower(name) >= '' AND
lower(name) <= ('' || chr(65535))
ORDER BY
lower(name)
LIMIT 10;
 [mire explicar.tensor.ru] ¡Genial, tanto los trabajos de clasificación como el consumo de recursos siguen siendo "microscópicos", miles de veces más eficientes que el FTS "puro" ! Queda por recopilar en una sola solicitud:
[mire explicar.tensor.ru] ¡Genial, tanto los trabajos de clasificación como el consumo de recursos siguen siendo "microscópicos", miles de veces más eficientes que el FTS "puro" ! Queda por recopilar en una sola solicitud:(
SELECT
*
FROM
firms
WHERE
lower(name) >= '' AND
lower(name) <= ('' || chr(65535))
ORDER BY
lower(name)
LIMIT 10
)
UNION ALL
(
SELECT
*
FROM
firms
WHERE
to_tsvector('simple'::regconfig, lower(name)) @@ to_tsquery('simple', ':*') AND
lower(name) NOT LIKE ('' || '%')
ORDER BY
lower(name) ~ ('^' || '') DESC
, lower(name)
LIMIT 10
)
LIMIT 10;
Observo que la segunda subconsulta solo se ejecuta si la primera devuelve menos delLIMIT número de filas esperado por la última . Ya escribí sobre este método de optimización de consultas .Entonces sí, ahora tenemos btree y gin en la mesa al mismo tiempo, pero estadísticamente resultó que menos del 10% de las solicitudes llegan al segundo bloque . Es decir, con tales limitaciones típicas tan conocidas para la tarea, ¡pudimos reducir el consumo total de recursos del servidor en casi mil veces!1.5 *: prescindir del archivo
Arriba se LIKEnos impidió usar el tipo incorrecto. Pero se puede "establecer en el camino verdadero" especificando la declaración USING:El valor predeterminado es implícito ASC. Además, puede especificar el nombre de un operador de clasificación específico en una oración USING. El operador de clasificación debe ser miembro menor o mayor que una determinada familia de operadores de árbol B. ASCgeneralmente equivalente USING <y DESCgeneralmente equivalente USING >.
En nuestro caso, "menos" es ~<~:SELECT
*
FROM
firms
WHERE
lower(name) LIKE ('' || '%')
ORDER BY
lower(name) USING ~<~
LIMIT 10;
 [mira explicar.tensor.ru]
[mira explicar.tensor.ru]2: cómo "agriar" solicitudes
Ahora dejamos nuestra solicitud de "insistir" durante medio año o un año, y con sorpresa lo volvemos a encontrar "en la parte superior" con indicadores del "bombeo" total diario de memoria ( buffers hit compartido ) en 5.5TB , es decir, incluso más de lo que era originalmente.No, por supuesto, nuestro negocio ha crecido y la carga ha aumentado, ¡pero no tanto! Entonces algo está sucio aquí, vamos a resolverlo.2.1: el nacimiento de la paginación
En algún momento, otro equipo de desarrollo quería hacer posible "saltar" al registro desde una búsqueda rápida de subíndices con los mismos resultados, pero ampliados. ¿Y qué registro sin navegación de página? ¡A la mierda!( ... LIMIT <N> + 10)
UNION ALL
( ... LIMIT <N> + 10)
LIMIT 10 OFFSET <N>;
Ahora era posible sin esfuerzo para el desarrollador mostrar el registro de resultados de búsqueda con la carga de "página de tipo".Por supuesto, de hecho, para cada página de datos siguiente, se está leyendo más y más (todo el tiempo anterior, que descartamos, más la "cola" deseada), es decir, este es un antipatrón inequívoco. Y sería más correcto comenzar la búsqueda en la próxima iteración desde la clave almacenada en la interfaz, pero al respecto, en otra ocasión.2.2: quiere exótico
En algún momento, el desarrollador quería diversificar la selección resultante con datos de otra tabla, para lo cual se envió toda la solicitud anterior al CTE:WITH q AS (
...
LIMIT <N> + 10
)
SELECT
*
, (SELECT ...) sub_query
FROM
q
LIMIT 10 OFFSET <N>;
Y aún así, no está mal, porque una subconsulta se calcula solo para 10 registros devueltos, si no ...2.3: DISTINTO sin sentido y despiadado
En algún lugar del proceso de tal evolución, se perdióNOT LIKE una condición de la segunda subconsulta . Está claro que después de eso UNION ALLcomencé a devolver algunos registros dos veces , primero encontrados al comienzo de la línea, y luego nuevamente, al comienzo de la primera palabra de esta línea. En el límite, todos los registros de la segunda subconsulta podrían coincidir con los registros de la primera.¿Qué hace un desarrollador en lugar de buscar una razón? .. ¡Sin dudas!- duplicar el tamaño de las muestras originales
- ponga DISTINCT para que obtengamos solo instancias individuales de cada fila
WITH q AS (
( ... LIMIT <2 * N> + 10)
UNION ALL
( ... LIMIT <2 * N> + 10)
LIMIT <2 * N> + 10
)
SELECT DISTINCT
*
, (SELECT ...) sub_query
FROM
q
LIMIT 10 OFFSET <N>;
Es decir, está claro que el resultado, al final, es exactamente el mismo, pero la posibilidad de "volar" a la segunda subconsulta CTE se ha vuelto mucho mayor, y sin esto, claramente se lee más .Pero esto no es lo más triste. Como el desarrollador me pidió que seleccionara, DISTINCTno por específico, sino inmediatamente por todos los campos del registro, el campo sub_query, el resultado de la subconsulta, también llegó allí automáticamente. Ahora, para la ejecución DISTINCT, la base de datos tenía que ejecutar no 10 subconsultas, ¡sino todas <2 * N> + 10 !2.4: ¡cooperación sobre todo!
Por lo tanto, los desarrolladores vivieron, no se molestaron, porque en el registro fueron "parcheados" a valores significativos de N con una desaceleración crónica en la recepción de cada "página" siguiente.Hasta que los desarrolladores de otro departamento acudieron a ellos y no quisieron utilizar un método tan conveniente para la búsqueda iterativa , es decir, tomamos una pieza de alguna muestra, filtramos por condiciones adicionales, dibujamos el resultado, luego la siguiente pieza (que en nuestro caso se logra mediante aumentar N), y así sucesivamente hasta que llenemos la pantalla.En general, en el espécimen capturado, N alcanzó valores de casi 17K , y en solo 24 horas, al menos 4K, tales solicitudes se ejecutaron "en la cadena". El último de ellos ya escaneado audazmente1 GB de memoria en cada iteración ...