 ¡Hola a todos!Comprometido en pruebas de rendimiento. Y realmente me gusta configurar el monitoreo y disfrutar las métricas en Grafana . Y el estándar para almacenar métricas en herramientas de carga es InfluxDB . En InfluxDB, puede guardar métricas de herramientas tan populares como:Al trabajar con herramientas de prueba de rendimiento y sus métricas, he acumulado una selección de recetas de programación para la combinación de Grafana e InfluxDB . Propongo considerar un problema interesante que surge cuando hay una métrica con dos o más etiquetas. Creo que esto no es raro. Y en el caso general, la tarea suena así: calcular la métrica total para un grupo, que se divide en subgrupos .
¡Hola a todos!Comprometido en pruebas de rendimiento. Y realmente me gusta configurar el monitoreo y disfrutar las métricas en Grafana . Y el estándar para almacenar métricas en herramientas de carga es InfluxDB . En InfluxDB, puede guardar métricas de herramientas tan populares como:Al trabajar con herramientas de prueba de rendimiento y sus métricas, he acumulado una selección de recetas de programación para la combinación de Grafana e InfluxDB . Propongo considerar un problema interesante que surge cuando hay una métrica con dos o más etiquetas. Creo que esto no es raro. Y en el caso general, la tarea suena así: calcular la métrica total para un grupo, que se divide en subgrupos .Hay tres opciones:
- Solo la cantidad agrupada por etiqueta de tipo
- Grafana-way. Usamos una pila de valores
- Suma de máximos con subconsulta
Cómo todo empezó
Monitoreo de JVM MBean configurado utilizando Jolokia , Telegraf , InfluxDB y Grafana . Y visualizó métricas en los grupos de memoria: cuánta memoria asigna cada grupo de memoria en HEAP y más allá.Gráficos sobre agrupaciones de memoria JVM y actividad del recolector de basura desde las 13:00 del día anterior hasta la 01:00 de la noche del día actual (período de 12 horas). Aquí puede ver que los grupos de memoria se dividen en dos grupos: HEAP y NON_HEAP . Y que alrededor de las 17:00 hubo recolección de basura, después de lo cual el tamaño de los bloques de memoria disminuyó: Para métricas por cobrar a grupos de memoria, he especificado los siguientes ajustes en el telegraf fichero de configuración : telegraf.conf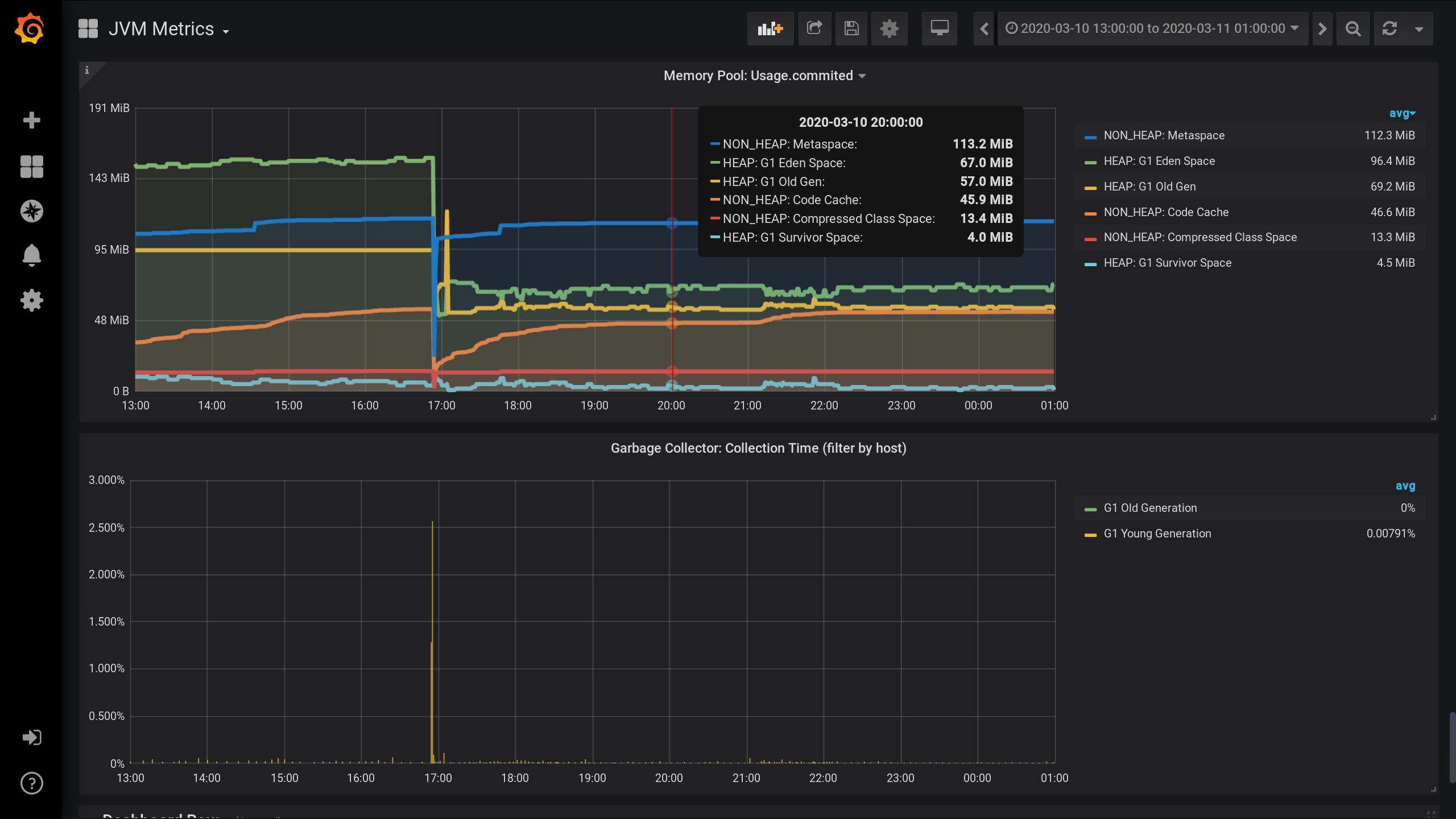
[outputs.influxdb]
urls = ["http://influxdb_server:8086"]
database = "telegraf"
username = "login-InfluxDb"
password = "*****"
retention_policy = "month"
influx_uint_support = false
[agent]
collection_jitter = "2s"
interval = "2s"
precision = "s"
[[inputs.jolokia2_agent]]
username = "login-Jolokia"
password = "*****"
urls = ["http://127.0.0.1:7777/jvm-service"]
[[inputs.jolokia2_agent.metric]]
paths = ["Usage","PeakUsage","CollectionUsage","Type"]
name = "java_memory_pool"
mbean = "java.lang:name=*,type=MemoryPool"
tag_keys = ["name"]
[[processors.converter]]
[processors.converter.fields]
integer = ["CollectionUsage.*", "PeakUsage.*", "Usage.*"]
tag = ["Type"]
Y en Grafana, construí una solicitud a InfluxDB para mostrar en gráficos el valor métrico máximo Usage.Committeddurante un período de tiempo con un paso $granularity(1m) y agrupado por dos etiquetas Type(HEAP o NON_HEAP) y name(Metaspace, G1 Old Gen, ...): la misma solicitud en forma de texto, teniendo en cuenta todas las variables de Grafana (preste atención al escape de valores de variables con - esto es importante para que la consulta funcione correctamente):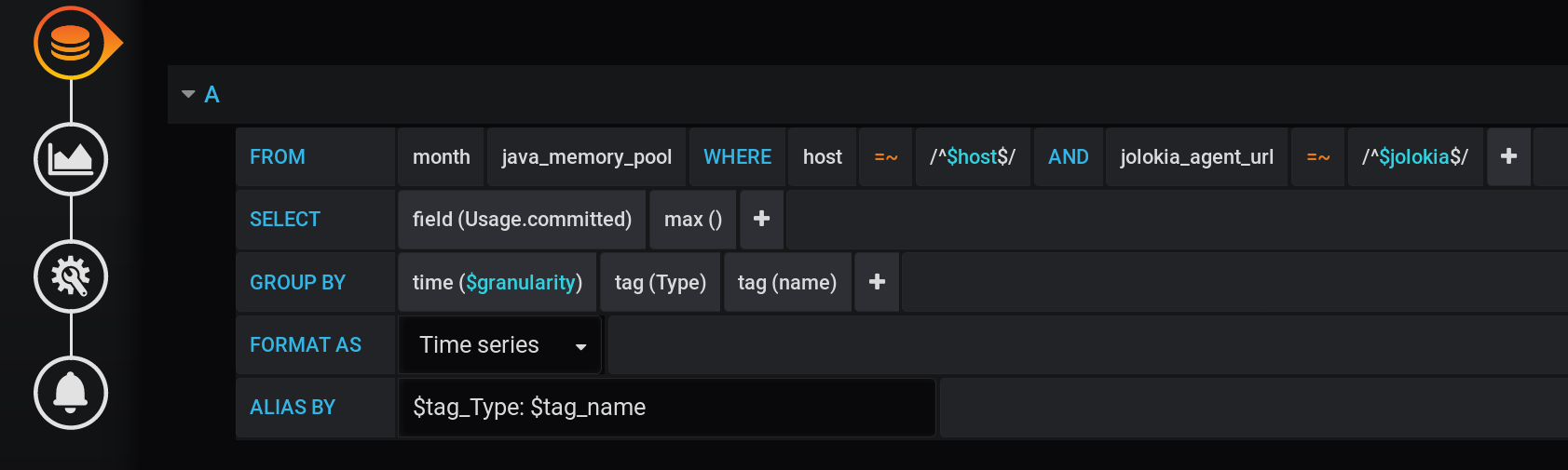
:regexSELECT max("Usage.committed")
FROM "telegraf"."month"."java_memory_pool"
WHERE
host =~ /^${host:regex}$/ AND
jolokia_agent_url =~ /^${jolokia:regex}$/ AND
$timeFilter
GROUP BY
"Type", "name", time($granularity)
La misma consulta en forma de texto, teniendo en cuenta los valores específicos de las variables de Grafana :SELECT max("Usage.committed")
FROM "telegraf"."month"."java_memory_pool"
WHERE
host =~ /^serverName$/ AND
jolokia_agent_url =~ /^http:\/\/127\.0\.0\.1:7777\/jvm-service$/ AND
time >= 1583834400000ms and time <= 1583877600000ms
GROUP BY
"Type", "name", time(1m)
Agrupación por tiempo GROUP BY time($granularity)o se GROUP BY time(1m)utiliza para reducir el número de puntos en el gráfico. Para un período de tiempo de 12 horas y un paso de agrupación de 1 minuto, obtenemos: 12 x 60 = 720 veces o 721 puntos (el último punto con un valor de nulo).Recuerde que 721 es el número esperado de puntos en respuesta a las solicitudes a InfluxDB con la configuración actual para el intervalo de tiempo (12 horas) y el paso de agrupación (1 minuto).
Agrupación de
memoria NON_HEAP: Metaspace (azul) está a la cabeza en el consumo de memoria a las 20:00. Y según HEAP: G1 Old Gen (amarillo) hubo un pequeño aumento local a las 17:03. Y a las 20:00, en total, todos los grupos NON_HEAP dejaron 172.5 MiB (113.2 + 45.9 + 13.4) y los grupos HEAP 128 MiB (67 + 57 + 4).
Recuerde los valores para las 20:00: NON_HEAP pools 172.5 MiB y HEAP pools 128 MiB . Nos centraremos en estos valores en el futuro.
En el contexto de Tipo : nombre , obtuvimos el valor de la métrica fácilmente.En el contexto de solo la etiqueta de nombre , el valor de la métrica también es fácil de obtener, ya que todos los nombres de las agrupaciones de memoria son únicos, y es suficiente para dejar la agrupación de resultados solo por nombre .La pregunta sigue siendo: ¿cómo obtener qué tamaño se asigna para todos los grupos HEAP y todos los grupos NON_HEAP en total?
1. Solo la cantidad agrupada por etiqueta de tipo
1.1. Suma agrupada por etiqueta
La primera solución que puede venir a la mente es agrupar los valores por la etiqueta Tipo y calcular la suma de los valores en cada grupo. Tal consulta se verá así: Una representación textual de una solicitud de cálculo de suma agrupada por etiqueta Tipo con todas las variables de Grafana :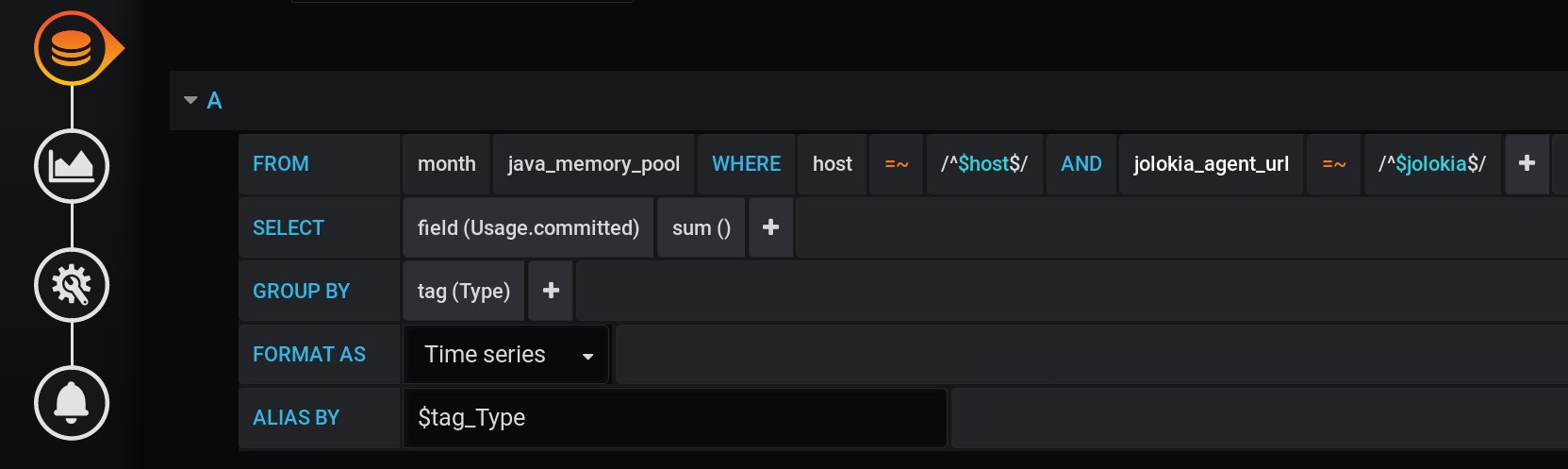
SELECT sum("Usage.committed")
FROM "telegraf"."month"."java_memory_pool"
WHERE
host =~ /^${host:regex}$/ AND
jolokia_agent_url =~ /^${jolokia:regex}$/ AND
$timeFilter
GROUP BY
"Type"
Esta es una consulta válida, pero devolverá solo dos puntos: la suma se calculará con la agrupación solo por la etiqueta Tipo con dos valores (HEAP y NON_HEAP). Ni siquiera veremos el horario. Habrá dos puntos independientes con una suma enorme en valores (más de 3 TiB): tal suma no es adecuada, se necesita un desglose en intervalos de tiempo.
1.2. Cantidad agrupada por etiqueta por minuto
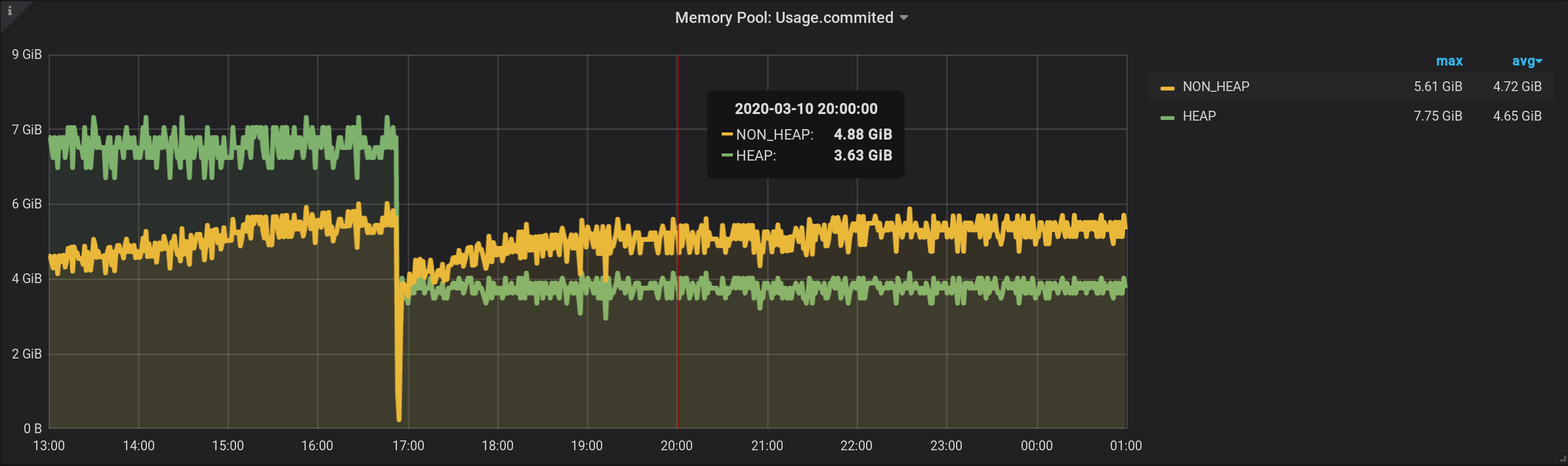
En la consulta original, agrupamos las métricas por un intervalo de granularidad $ personalizado . Hagamos la agrupación ahora por un intervalo personalizado.Esta consulta resultará, agregó GROUP BY time($granularity): Obtenemos valores inflados, en lugar de 172.5 MiB por NON_HEAP vemos 4.88 GiB: Dado que las métricas se envían a InfluxDB una vez cada 2 segundos (ver telegraf.conf arriba), la suma de lecturas en un minuto no dará la cantidad en el momento, y la suma de treinta de esas cantidades. Tampoco podemos dividir el resultado entre 30 constantes . Como $ granularity es un parámetro, se puede establecer en 1 minuto y 10 minutos. Y el valor de la cantidad cambiará.
1.3. Etiqueta agrupada por segundo
Para obtener correctamente el valor de la métrica para la intensidad de recopilación de la métrica actual (2 segundos), debe calcular la cantidad para un intervalo fijo que no exceda la intensidad de recopilación de la métrica.Intentemos mostrar estadísticas con una agrupación en segundos. Agregue a la GROUP BYagrupación time(1s): con una granularidad tan pequeña, obtenemos una gran cantidad de puntos para nuestro intervalo de tiempo de 12 horas (12 horas * 60 minutos * 60 segundos = 43.200 intervalos, 43.201 puntos por línea, la última de las cuales es nula): 43.201 puntos en cada línea de la gráfica. Hay tantos puntos que InfluxDB formará una respuesta durante mucho tiempo, Grafana tardará más en responder y luego el navegador extraerá una cantidad tan enorme de puntos durante mucho tiempo.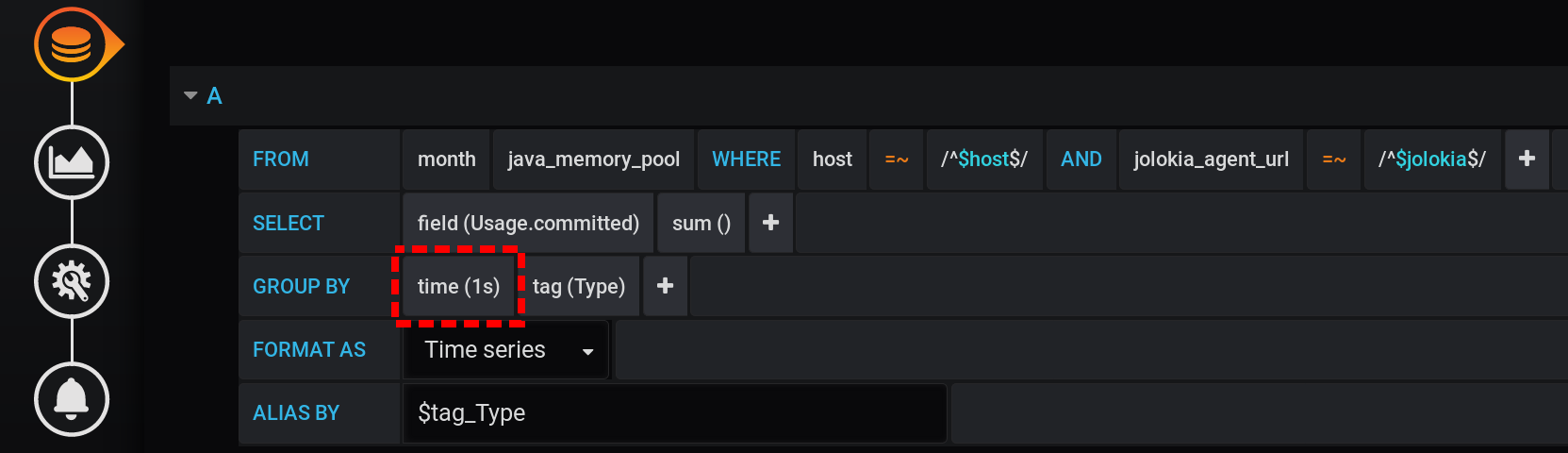
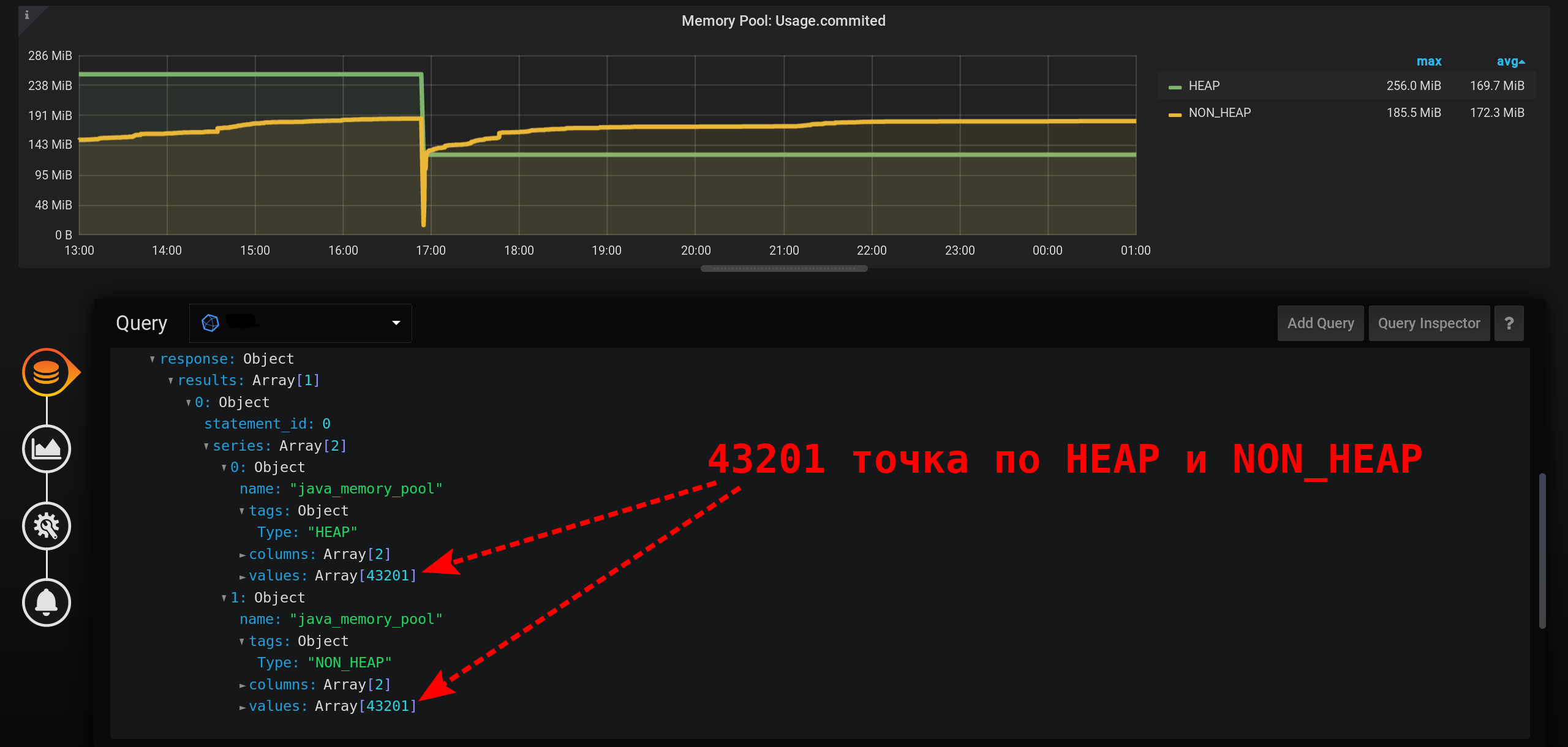 Y no en cada segundo hay puntos: las métricas se recopilaron cada 2 segundos y se agruparon por cada segundo, lo que significa que cada segundo punto será nulo. Para ver una línea suave, configure la conexión de valores no vacíos. De lo contrario, no veremos los gráficos: anteriormente, Grafana era tal que el navegador se bloqueaba durante el sorteo de una gran cantidad de puntos. Ahora la versión de Grafana tiene la capacidad de dibujar varias decenas de miles de puntos: el navegador simplemente omite algunos de ellos, dibuja un gráfico utilizando los datos reducidos. Pero el gráfico se suaviza. Los máximos se muestran como máximos promedio.
Y no en cada segundo hay puntos: las métricas se recopilaron cada 2 segundos y se agruparon por cada segundo, lo que significa que cada segundo punto será nulo. Para ver una línea suave, configure la conexión de valores no vacíos. De lo contrario, no veremos los gráficos: anteriormente, Grafana era tal que el navegador se bloqueaba durante el sorteo de una gran cantidad de puntos. Ahora la versión de Grafana tiene la capacidad de dibujar varias decenas de miles de puntos: el navegador simplemente omite algunos de ellos, dibuja un gráfico utilizando los datos reducidos. Pero el gráfico se suaviza. Los máximos se muestran como máximos promedio.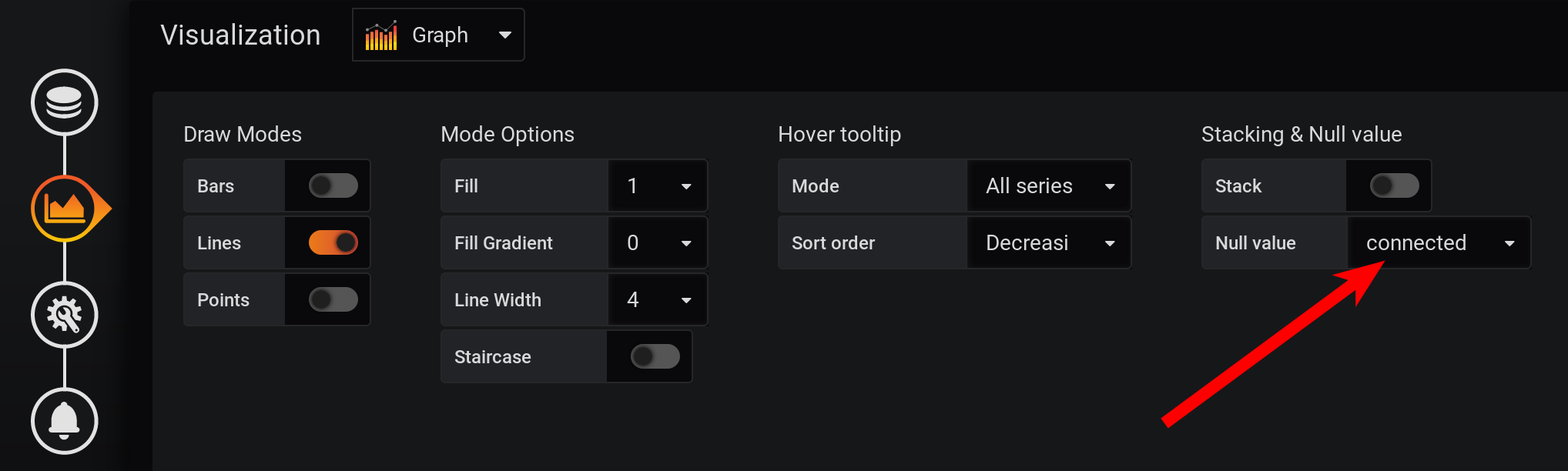 Como resultado, hay un gráfico, se muestra con precisión, las métricas a las 20:00 se calculan correctamente, las métricas en la leyenda del gráfico se calculan correctamente. Pero el gráfico está suavizado: las ráfagas no son visibles con una precisión de 1 segundo. En particular, el aumento de HEAP a las 17:03 desapareció del gráfico, el gráfico HEAP es muy suave: el menos en el rendimiento se manifestará claramente durante un intervalo de tiempo más largo. Si intenta construir un gráfico en un mes (720 horas), y no en 12 horas, entonces todo se congelará con una granularidad tan pequeña (1 segundo), habrá demasiados puntos. Y hay una desventaja en ausencia de picos, una paradoja: debido a la alta precisión de la obtención de métricas, obtenemos una baja precisión de su visualización .
Como resultado, hay un gráfico, se muestra con precisión, las métricas a las 20:00 se calculan correctamente, las métricas en la leyenda del gráfico se calculan correctamente. Pero el gráfico está suavizado: las ráfagas no son visibles con una precisión de 1 segundo. En particular, el aumento de HEAP a las 17:03 desapareció del gráfico, el gráfico HEAP es muy suave: el menos en el rendimiento se manifestará claramente durante un intervalo de tiempo más largo. Si intenta construir un gráfico en un mes (720 horas), y no en 12 horas, entonces todo se congelará con una granularidad tan pequeña (1 segundo), habrá demasiados puntos. Y hay una desventaja en ausencia de picos, una paradoja: debido a la alta precisión de la obtención de métricas, obtenemos una baja precisión de su visualización .
2. Grafana-way. Usamos una pila de valores
No fue posible crear una
solución simple y productiva con InfluxDB y el diseñador de consultas Grafana . Solo intentaremos usar las herramientas de Grafana para resumir las métricas que se muestran en el gráfico original. Y sí, esto es posible!2.1. Simplemente haga que la información sobre herramientas de desplazamiento / valor apilado: acumulativo
Dejaremos la solicitud para elegir métricas sin cambios, igual que en la sección "Cómo comenzó todo": las métricas se agruparán por Tipo y nombre . Pero solo mostraremos la etiqueta Tipo en los nombres de los gráficos : y en la configuración de visualización, agruparemos las métricas por pilas de Grafana : Primero, agregue la separación de dos etiquetas en dos pilas diferentes A y B, para que sus valores no se crucen: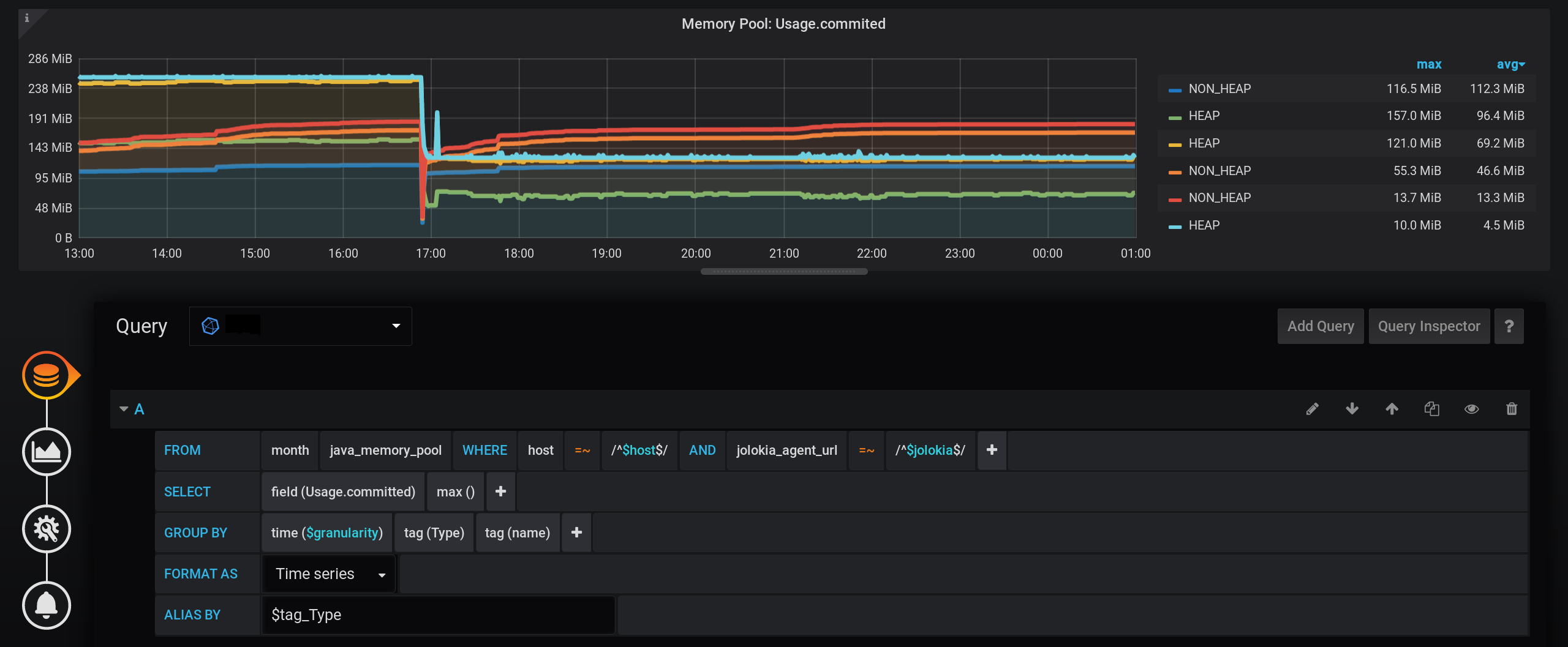
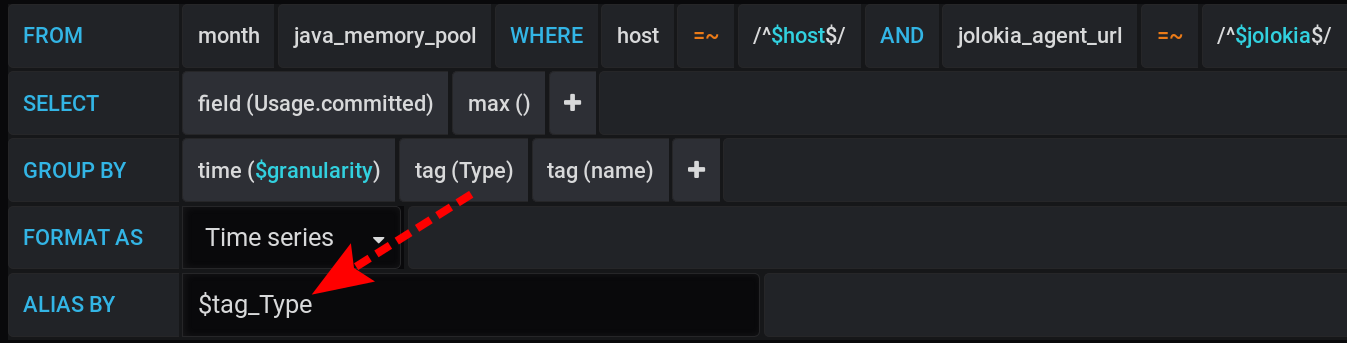
- Agregar anulación de serie / HEAP / Stack : A
- Agregar anulación de serie / NON_HEAP / Stack : B
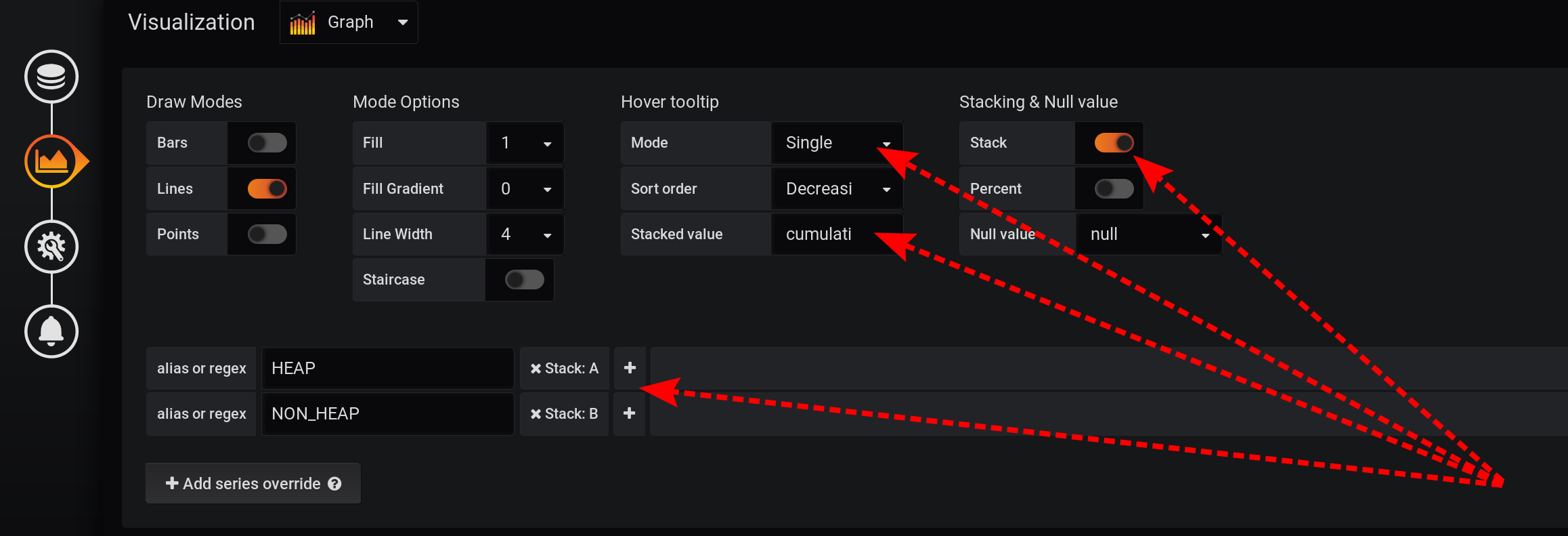
Luego, configure la visualización de métricas para mostrar los valores totales en una información sobre herramientas con gráficos:- Apilamiento y nulo valor / Pila : En
- Despliegue de información sobre herramientas / valor apilado : acumulativo
- Despliegue de información sobre herramientas / modo : solo
Debido a las diferentes características de Grafana, debe realizar acciones en ese orden. Si cambia el orden de las acciones o deja algunos campos con la configuración predeterminada, algo no funcionará:- Stack A B Stacking & Null value / Stack: On, ;
- Hover tooltip / Mode , Single, Hover tooltip .
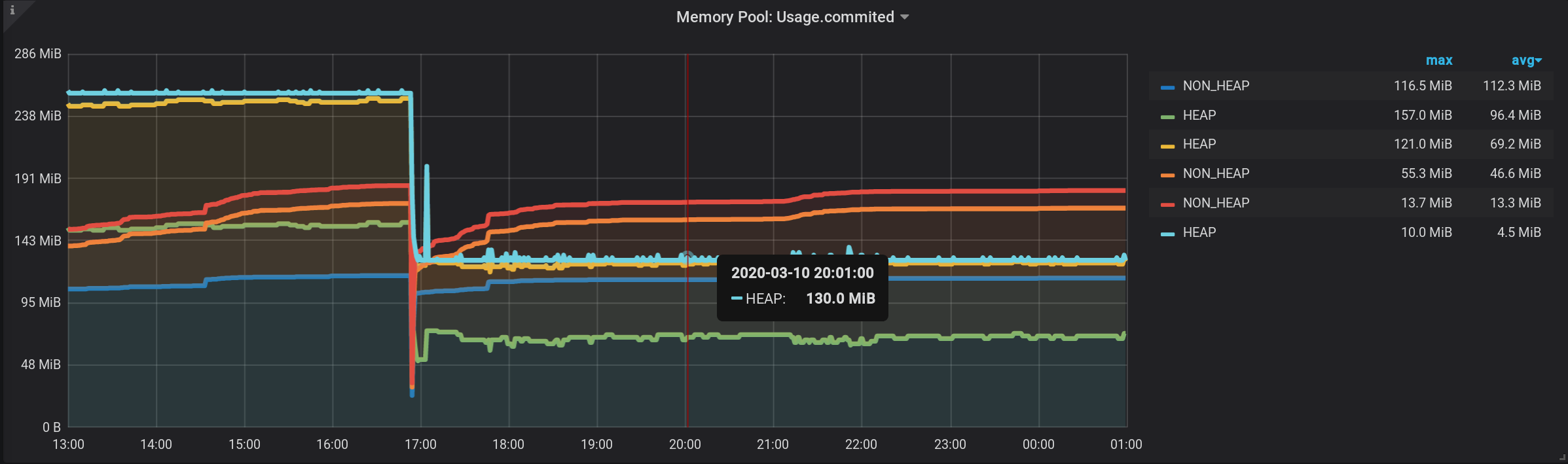
Y ahora, vemos muchas líneas, como para nosotros mismos. ¡Pero! Si pasa el cursor sobre el NON_HEAP superior , la información sobre herramientas mostrará la suma de los valores de todos los NON_HEAP . El monto se considera verdadero, ya que Grafana significa : Y si pasa el cursor sobre el cuadro superior con el nombre HEAP , veremos el monto por HEAP . El gráfico se muestra correctamente. Incluso el aumento de HEAP a las 17:03 es visible: formalmente, la tarea se ha completado. Pero hay inconvenientes: se muestran muchos gráficos adicionales. Debes colocar el cursor en la parte superior de ellos. Y en la leyenda del gráfico, no se acumulan, pero se muestran valores individuales, por lo que la leyenda se ha vuelto inútil.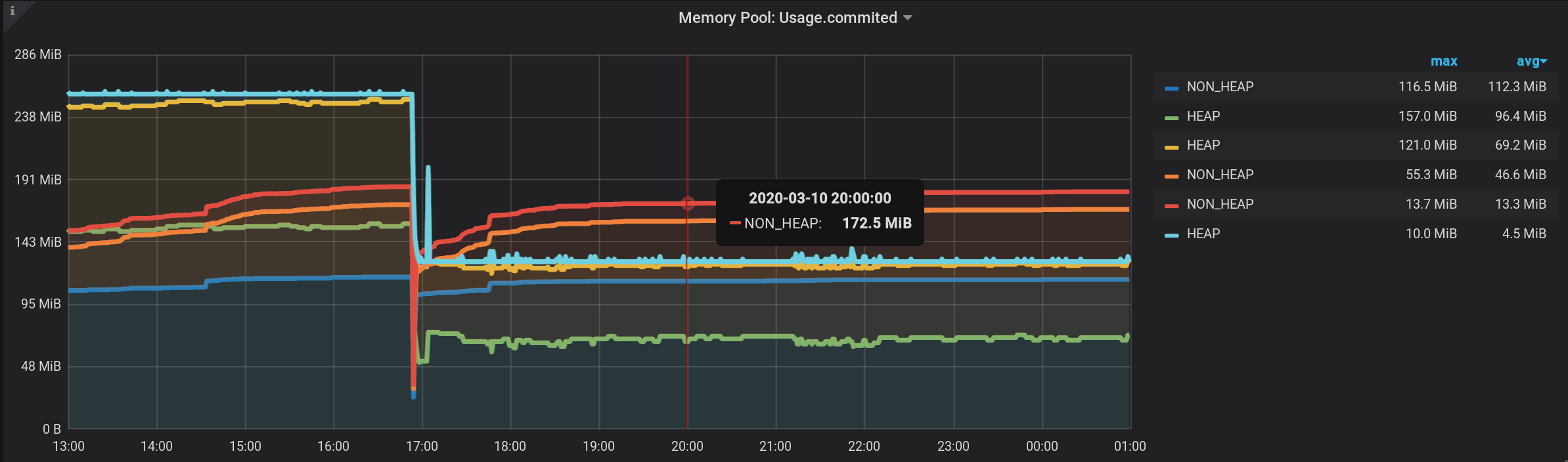
2.2. Valor apilado: acumulativo con líneas intermedias ocultas
Arreglemos el primer signo negativo de la solución anterior: asegúrese de que no se muestren gráficos adicionales.Para esto:- Agregue nuevas métricas con un nombre diferente y un valor 0 a los resultados.
- Agregue nuevas métricas a la Pila A y la Pila B , en la parte superior de la pila.
- Ocultar de la pantalla: las líneas originales de HEAP y NON_HEAP .
Agregamos dos nuevos después de la solicitud principal: solicitud B para recibir una serie con valores 0 y nombre [NON_HEAP] y solicitud C para recibir una serie con valores 0 y nombre [HEAP] . Para obtener 0, tomamos el primer valor del campo "Usage.committed" en cada grupo de tiempo y lo restamos: primero ("Usage.committed") - primero ("Usage.committed") - obtenemos un 0. estable Los nombres de los gráficos se cambian sin perder significado debido a los corchetes: [NON_HEAP] y [HEAP] : [HEAP] y HEAP se combinan en la Pila A , y también ocultan todo HEAP . [NON_HEAP]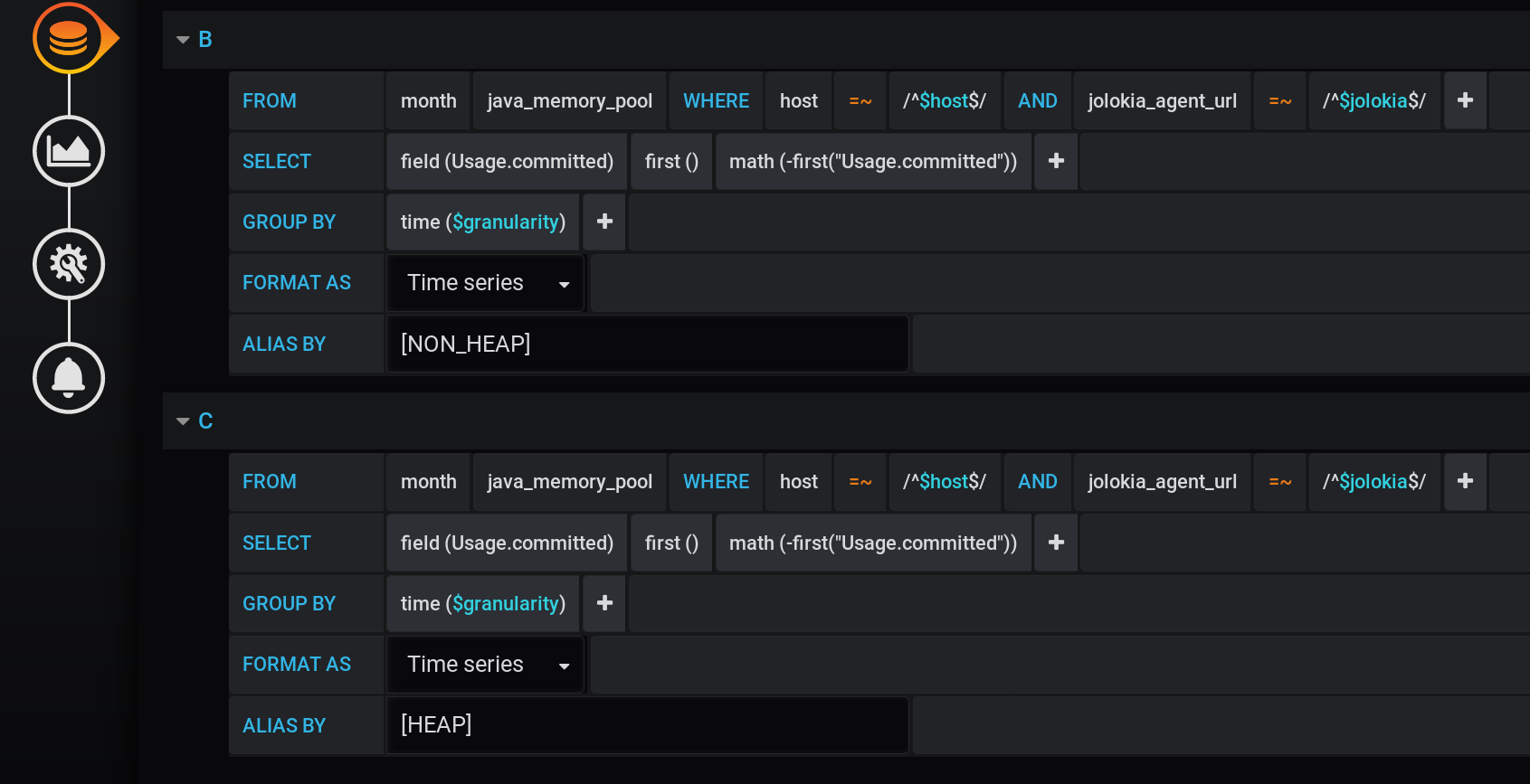 y combine NON_HEAP en la pila B y oculte NON_HEAP : obtenga la
cantidad correcta en [NON_HEAP] en la información sobre herramientas al pasar el cursor sobre el gráfico: obtenga
la cantidad correcta en [HEAP] en la información sobre herramientas al pasar sobre el gráfico. E incluso todas las explosiones son visibles: y el cronograma se forma rápidamente. Pero la leyenda siempre muestra 0, la leyenda se ha vuelto inútil. ¡Todo salió bien! La verdadera derivación es a través de las pilas de Grafana . Es por esto que el artículo se agregó a la categoría de Programación anormal .
y combine NON_HEAP en la pila B y oculte NON_HEAP : obtenga la
cantidad correcta en [NON_HEAP] en la información sobre herramientas al pasar el cursor sobre el gráfico: obtenga
la cantidad correcta en [HEAP] en la información sobre herramientas al pasar sobre el gráfico. E incluso todas las explosiones son visibles: y el cronograma se forma rápidamente. Pero la leyenda siempre muestra 0, la leyenda se ha vuelto inútil. ¡Todo salió bien! La verdadera derivación es a través de las pilas de Grafana . Es por esto que el artículo se agregó a la categoría de Programación anormal .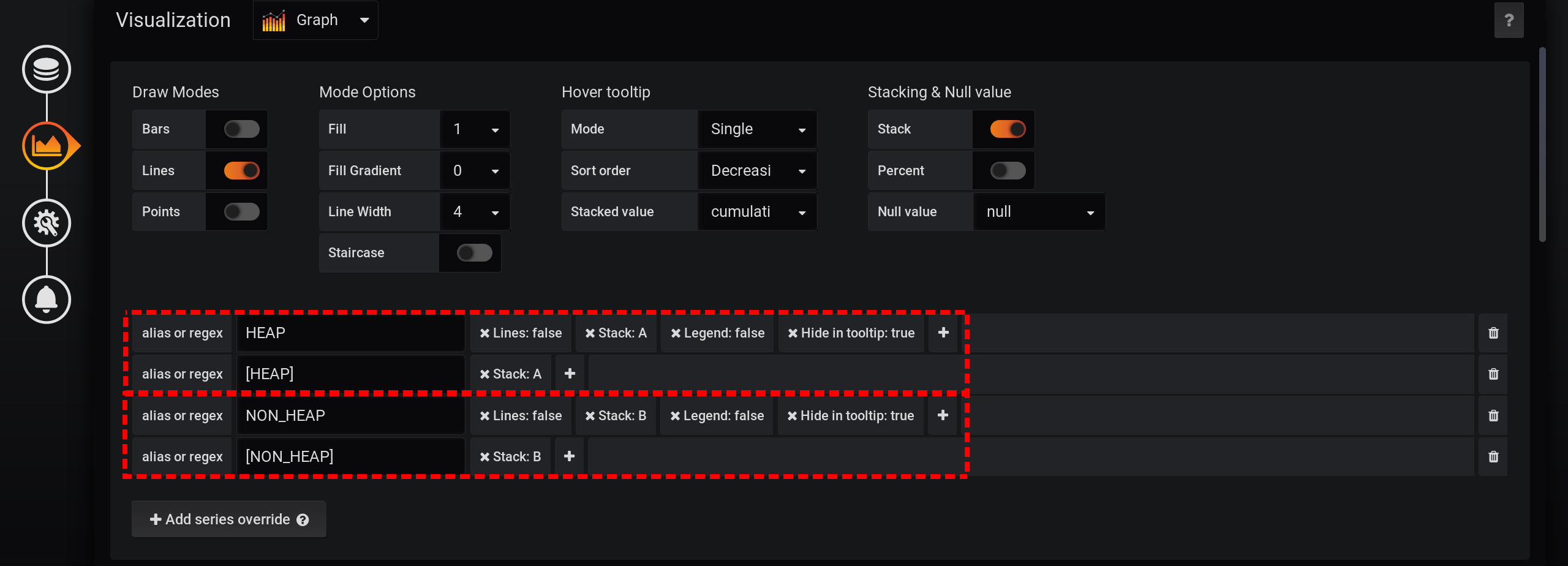


3. La suma de los máximos con la subconsulta
Como ya nos hemos embarcado en el camino de la programación anormal con un montón de Grafana e InfluxDB , continuemos. Hagamos que InfluxDB devuelva un pequeño número de puntos y haga que aparezca la leyenda.3.1 Suma de incrementos de la suma acumulada de máximos
Profundicemos
en las posibilidades de InfluxDB . Anteriormente, a menudo ayudaba tomando la derivada de la cantidad acumulada, así que intentaremos aplicar este enfoque ahora. Cambiemos al modo de edición manual de solicitudes: hagamos tal solicitud:
SELECT sum("U") FROM (
SELECT non_negative_difference(cumulative_sum(max("Usage.committed"))) AS "U"
FROM "month"."java_memory_pool"
WHERE
(
"host" =~ /^${host:regex}$/ AND
"jolokia_agent_url" =~ /^${jolokia:regex}$/
) AND
$timeFilter
GROUP BY time($granularity), "Type", "name"
)
GROUP BY "Type", time($granularity)
Aquí se toma el valor máximo de la métrica en el grupo por tiempo y la suma de dichos valores desde el momento en que comienza la referencia, agrupados por las etiquetas Tipo y nombre . Como resultado, en cada momento habrá una suma de todas las indicaciones por tipo ( HEAP o NON_HEAP ) con separación por nombre de grupo, pero no se suman 30 valores, como fue el caso en la versión 1.2, pero solo uno es el máximo.Y si tomamos el incremento de diferencia no negativa de dicha suma acumulativa para el último paso, obtendremos el valor de la suma de todos los grupos de datos agrupados por Tipo y etiquetas de nombre al comienzo del intervalo de tiempo.Ahora, para obtener la cantidad solo por etiquetaEscriba , sin agrupar por etiqueta de nombre , debe realizar una solicitud de nivel superior con parámetros de agrupación similares, pero sin agrupar por nombre .Como resultado de una consulta tan compleja, obtenemos la suma de todos los tipos.Horario perfecto La suma de los máximos se calcula correctamente. Hay una leyenda con los valores correctos, distintos de cero. En la información sobre herramientas puede mostrar todas las métricas, no solo Single. Incluso se muestran ráfagas HEAP : una cosa, pero la solicitud resultó ser difícil: la suma del incremento de la suma acumulada de máximos con un cambio en el nivel de agrupación.
3.2 Suma de máximos con un cambio en el nivel de agrupación
¿Se puede hacer algo más simple que en la versión 3.1? El cuadro de Pandora ya está abierto, cambiamos al modo de edición de consulta manual.Existe la sospecha de que recibir un incremento de la cantidad acumulada conduce a un efecto cero: uno extingue al otro. Deshágase de la diferencia no_negativa (suma acumulativa (...)) .Simplifica la solicitud.Simplemente dejamos la suma de los máximos, con una disminución en el nivel de agrupación:SELECT sum("A")
FROM (
SELECT max("Usage.committed") as "A"
FROM "month"."java_memory_pool"
WHERE
(
"host" =~ /^${host:regex}$/ AND
"jolokia_agent_url" =~ /^${jolokia:regex}$/
) AND
$timeFilter
GROUP BY time($granularity), "Type", "name"
)
WHERE $timeFilter
GROUP BY time($granularity), "Type"
Esta es una consulta simple y rápida que devuelve solo 721 puntos por serie en 12 horas, cuando se agrupa por minutos: 12 (horas) * 60 (minutos) = 720 intervalos, 721 puntos (último vacío). Tenga en cuenta que el filtro de tiempo está duplicado. Está en la subconsulta y en la solicitud de agrupación: sin $ timeFilter, en la solicitud de agrupación externa, el número de puntos devueltos no será 721 en 12 horas, sino más. Dado que la subconsulta se agrupa para el intervalo de ... a , y la agrupación de una solicitud externa sin filtro será para el intervalo de ... ahora . Y si en Grafana se selecciona un intervalo de tiempo que no dura las X horas (no es tal que to = now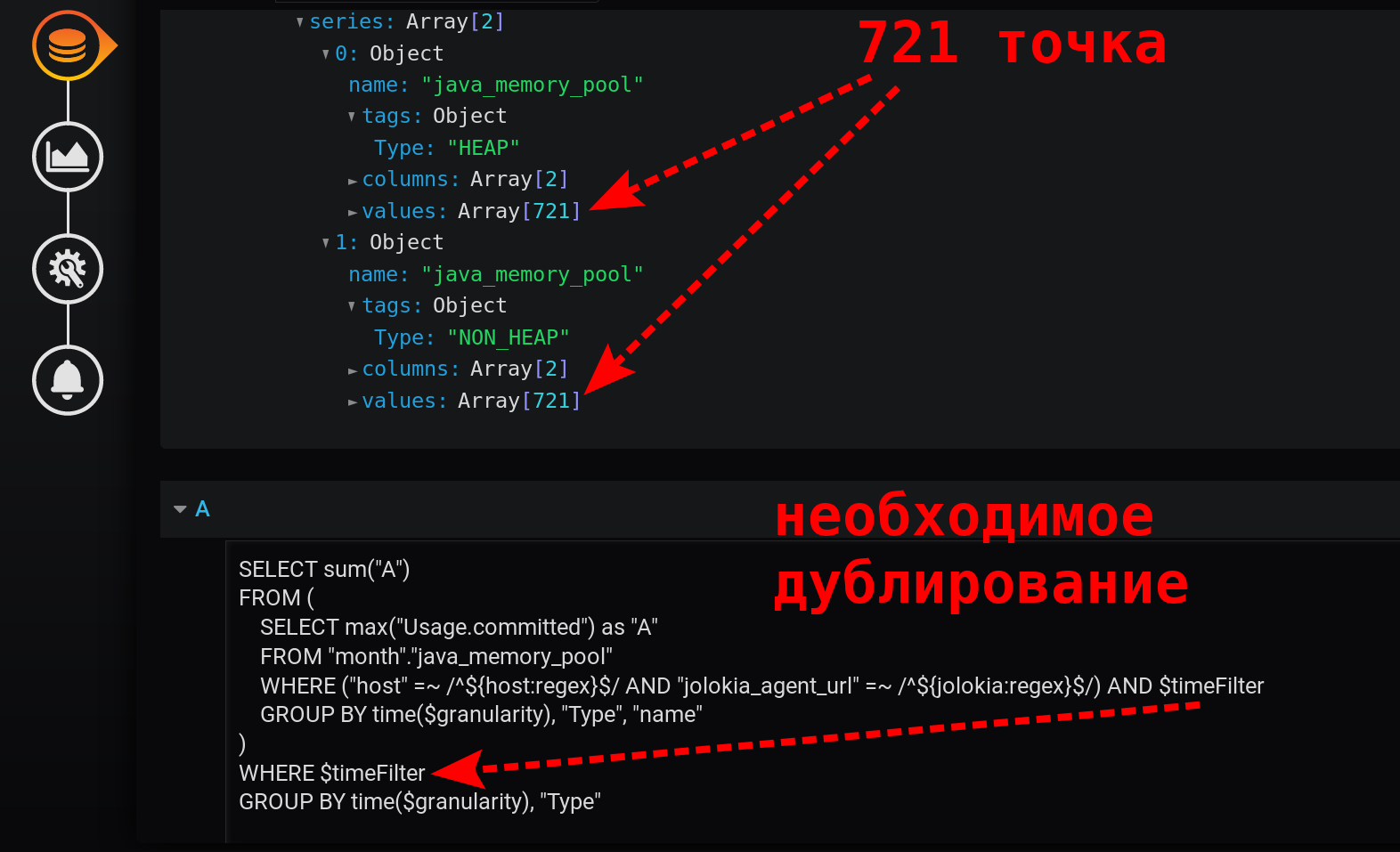 ), pero para el intervalo del pasado ( hasta < ahora ), aparecerán puntos vacíos con un valor nulo al final de la selección.El gráfico resultante resultó ser simple, rápido, correcto. Con una leyenda que muestra métricas de resumen. Con información sobre herramientas para varias líneas a la vez. Y también con la visualización de todas las ráfagas de valores: ¡ se logra el resultado!
), pero para el intervalo del pasado ( hasta < ahora ), aparecerán puntos vacíos con un valor nulo al final de la selección.El gráfico resultante resultó ser simple, rápido, correcto. Con una leyenda que muestra métricas de resumen. Con información sobre herramientas para varias líneas a la vez. Y también con la visualización de todas las ráfagas de valores: ¡ se logra el resultado!Referencias (en lugar de referencias)
Distribuciones de las herramientas utilizadas en el artículo:Documentación sobre las capacidades de las herramientas utilizadas en el artículo:Los ingenieros de pruebas de rendimiento deben conocer bien la combinación de Grafana e InfluxDB . Y en este paquete, muchas tareas simples son muy interesantes y no siempre se pueden resolver con métodos de programación normales.A veces conocimientos de programación anormales pueden ser necesarios con los Grafana características y sutilezas de la InfluxDB consulta lenguaje .En el artículo, se tomaron en cuenta cuatro pasos de la implementación de resumir una métrica con una agrupación por una etiqueta, pero que tiene varias etiquetas. La tarea fue interesante. Y hay muchas de esas tareas. Estoypreparando un informe sobre las sutilezas de la programación con Grafana e InfluxDB.. Periódicamente publicaré materiales sobre este tema. Mientras tanto, estaré contento con sus preguntas sobre el artículo actual.