Hola a todos.Nosotros, Victor Antipov e Ilya Aleshin, hoy hablaremos sobre nuestra experiencia con dispositivos USB a través de Python PyUSB y un poco sobre ingeniería inversa.
Antecedentes
En 2019, entró en vigencia el Decreto del Gobierno de la Federación de Rusia No. 224 “Sobre la aprobación de las reglas para etiquetar productos de tabaco mediante identificación y los detalles de la introducción de un sistema de información estatal para monitorear la circulación de productos sujetos a etiquetado obligatorio mediante identificación en relación con productos de tabaco”.El documento explica que a partir del 1 de julio de 2019, los fabricantes deben etiquetar cada paquete de tabaco. Y los distribuidores directos deben recibir estos productos con el diseño de un documento de transferencia universal (UPD). Las tiendas, a su vez, deben registrar la venta de productos etiquetados a través de la caja registradora.Además, desde el 1 de julio de 2020, los productos de tabaco sin marcar están prohibidos. Esto significa que todos los paquetes de cigarrillos deben estar etiquetados con un código de barras especial Datamatrix. Y, un punto importante, resultó que Datamatrix no será ordinario, sino inverso. Es decir, no un código negro sobre blanco, sino viceversa.Probamos nuestros escáneres, y resultó que la mayoría de ellos necesitan ser renovados / reentrenados, de lo contrario, simplemente no pueden funcionar normalmente con este código de barras. Este giro de los acontecimientos nos garantizó un fuerte dolor de cabeza, porque nuestra compañía tiene muchas tiendas dispersas en un vasto territorio. Varias decenas de miles de cajas, y muy poco tiempo.Cual era la tarea asignada? Hay dos opciones Primero: los ingenieros de la instalación actualizan y ajustan manualmente los escáneres. Segundo: trabajamos de forma remota y, preferiblemente, cubrimos muchos escáneres a la vez en una sola iteración.La primera opción, obviamente, no nos convenía: tendríamos que gastar dinero en viajes de campo de ingenieros, y en este caso es difícil controlar y coordinar el proceso. Pero lo más importante es que las personas trabajarían, es decir, potencialmente obtendríamos muchos errores y, lo más probable, no se ajustaría a la fecha límite.La segunda opción es buena para todos, si no para uno pero. Algunos proveedores no tenían las herramientas de flasheo remoto que necesitábamos para todos los sistemas operativos requeridos. Y como se acababan los plazos, tuve que pensar con la cabeza.A continuación, describiremos cómo desarrollamos herramientas para escáneres portátiles para el sistema operativo Debian 9.x (tenemos toda la taquilla de Debian).:
Dice Victor Antipov.La utilidad oficial proporcionada por el proveedor funciona en Windows, y solo con IE. La utilidad puede flashear y configurar el escáner.Como el sistema de destino es Debian, instalamos el servidor usb-redirector en el servidor Debian y el cliente usb-redirector en Windows. Usando las utilidades del redireccionador usb, el escáner fue reenviado desde la máquina Linux a la máquina Windows.La utilidad del proveedor de Windows vio el escáner e incluso lo flasheó normalmente. Por lo tanto, se hizo la primera conclusión: nada depende del sistema operativo, el asunto está en el protocolo de actualización.OKAY. Se inició un flasheo en una máquina con Windows y se eliminó un volcado en una máquina con Linux.Metieron el basurero en WireShark y ... estaban tristes (omitiré parte de los detalles del basurero, no son de interés).Qué volcado nos mostró: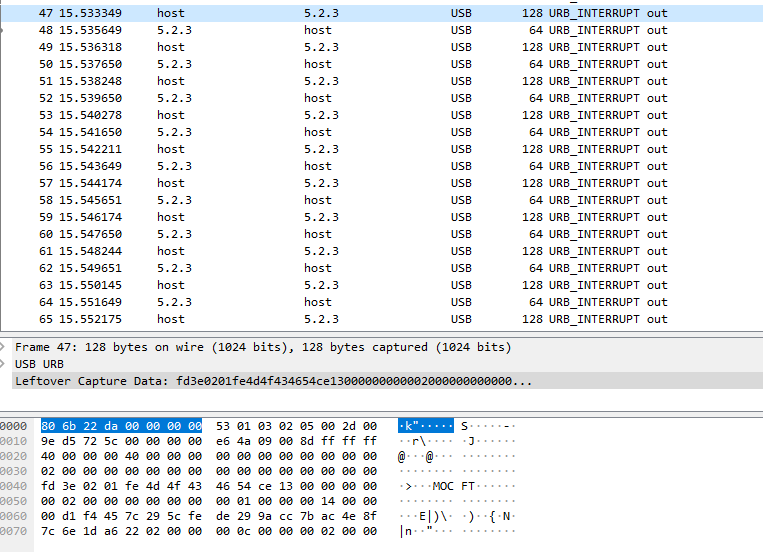
 Las direcciones 0000-0030, a juzgar por Wireshark, son información de servicio USB.Estábamos interesados en la parte 0040-0070.Nada estaba claro en una trama de transmisión, excepto los caracteres MOCFT. Estos símbolos resultaron ser símbolos del archivo de firmware, así como el resto de los símbolos hasta el final del marco (el archivo de firmware está resaltado):
Las direcciones 0000-0030, a juzgar por Wireshark, son información de servicio USB.Estábamos interesados en la parte 0040-0070.Nada estaba claro en una trama de transmisión, excepto los caracteres MOCFT. Estos símbolos resultaron ser símbolos del archivo de firmware, así como el resto de los símbolos hasta el final del marco (el archivo de firmware está resaltado): ¿Qué significaban los símbolos fd 3e 02 01 fe? Personalmente, como Ilya, no tenía idea.Miré el siguiente cuadro (la información de servicio se elimina aquí, el archivo de firmware se resalta):
¿Qué significaban los símbolos fd 3e 02 01 fe? Personalmente, como Ilya, no tenía idea.Miré el siguiente cuadro (la información de servicio se elimina aquí, el archivo de firmware se resalta): ¿Qué quedó claro? Que los dos primeros bytes son algún tipo de constante. Todos los bloques posteriores confirmaron esto, pero antes del final del bloque de transmisión:
¿Qué quedó claro? Que los dos primeros bytes son algún tipo de constante. Todos los bloques posteriores confirmaron esto, pero antes del final del bloque de transmisión: Este marco también entró en un estupor, ya que la constante cambió (resaltada) y, curiosamente, había una parte del archivo. El tamaño de los bytes transmitidos del archivo indicó que se transfirieron 1024 bytes. Qué significaban los bytes restantes: no lo sabía de nuevo.En primer lugar, como un antiguo apodo de BBS, revisé los protocolos de transferencia estándar. 1024 bytes, no se aprobó ningún protocolo. Comenzó a estudiar el material y se topó con el protocolo 1K Xmodem. Permitió transmitir 1024, pero con un matiz: al principio solo 128, y solo en ausencia de errores, el protocolo aumentó el número de bytes transmitidos. Inmediatamente tuve una transmisión de 1024 bytes. Decidí estudiar los protocolos de transmisión, y específicamente el módem X.Hubo dos variaciones del módem.Primero, el formato del paquete XMODEM con soporte CRC8 (XMODEM original):
Este marco también entró en un estupor, ya que la constante cambió (resaltada) y, curiosamente, había una parte del archivo. El tamaño de los bytes transmitidos del archivo indicó que se transfirieron 1024 bytes. Qué significaban los bytes restantes: no lo sabía de nuevo.En primer lugar, como un antiguo apodo de BBS, revisé los protocolos de transferencia estándar. 1024 bytes, no se aprobó ningún protocolo. Comenzó a estudiar el material y se topó con el protocolo 1K Xmodem. Permitió transmitir 1024, pero con un matiz: al principio solo 128, y solo en ausencia de errores, el protocolo aumentó el número de bytes transmitidos. Inmediatamente tuve una transmisión de 1024 bytes. Decidí estudiar los protocolos de transmisión, y específicamente el módem X.Hubo dos variaciones del módem.Primero, el formato del paquete XMODEM con soporte CRC8 (XMODEM original):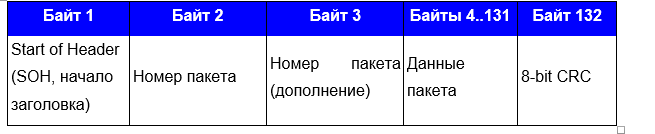 En segundo lugar, el formato de paquete XMODEM con soporte CRC16 (XmodemCRC): se
En segundo lugar, el formato de paquete XMODEM con soporte CRC16 (XmodemCRC): se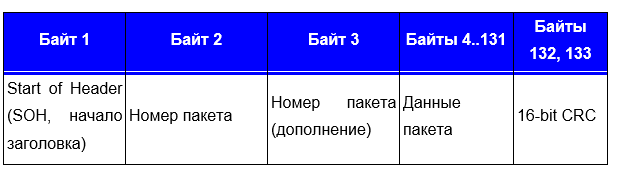 ve similar, con la excepción de SOH, número de paquete y CRC y la longitud del paquete.Miré el comienzo del segundo bloque de transmisión (y nuevamente vi el archivo de firmware, pero con una sangría de 1024 bytes):
ve similar, con la excepción de SOH, número de paquete y CRC y la longitud del paquete.Miré el comienzo del segundo bloque de transmisión (y nuevamente vi el archivo de firmware, pero con una sangría de 1024 bytes): Vi el encabezado familiar fd 3e 02, pero los siguientes dos bytes ya han cambiado: era 01 fe y se convirtió en 02 fd. Entonces noté que el segundo bloque ahora está numerado 02 y así entendí: frente a mí está la numeración del bloque de transmisión. La primera transmisión 1024 es 01, la segunda 02, la tercera 03 y así sucesivamente (pero en hexadecimal, por supuesto). Pero, ¿qué significa el cambio de fe a fd? Los ojos vieron una disminución de 1, el cerebro recordó que los programadores cuentan desde 0, no desde 1. Pero entonces, ¿por qué el primer bloque es 1, no 0? No encontré la respuesta a esta pregunta. Pero entendí cómo se considera el segundo bloque. El segundo bloque no es más que FF - (menos) el número del primer bloque. Por lo tanto, el segundo bloque se designó como = 02 (FF-02) = 02 FD. La lectura posterior del basurero confirmó mi presentimiento.Entonces, la siguiente imagen del programa comenzó a surgir:El comienzo del programa.fd 3e 02 - Inicio01 FE - contador de transmisiónTransmisión (se transmiten 34 bloques, 1024 bytes)fd 3e 1024 bytes de datos (divididos en bloques de 30 bytes).Fin de la transmisiónfd 25Restos de datos para alinear a 1024 bytes.¿Cómo se ve la trama final de la transferencia de bloque?:
Vi el encabezado familiar fd 3e 02, pero los siguientes dos bytes ya han cambiado: era 01 fe y se convirtió en 02 fd. Entonces noté que el segundo bloque ahora está numerado 02 y así entendí: frente a mí está la numeración del bloque de transmisión. La primera transmisión 1024 es 01, la segunda 02, la tercera 03 y así sucesivamente (pero en hexadecimal, por supuesto). Pero, ¿qué significa el cambio de fe a fd? Los ojos vieron una disminución de 1, el cerebro recordó que los programadores cuentan desde 0, no desde 1. Pero entonces, ¿por qué el primer bloque es 1, no 0? No encontré la respuesta a esta pregunta. Pero entendí cómo se considera el segundo bloque. El segundo bloque no es más que FF - (menos) el número del primer bloque. Por lo tanto, el segundo bloque se designó como = 02 (FF-02) = 02 FD. La lectura posterior del basurero confirmó mi presentimiento.Entonces, la siguiente imagen del programa comenzó a surgir:El comienzo del programa.fd 3e 02 - Inicio01 FE - contador de transmisiónTransmisión (se transmiten 34 bloques, 1024 bytes)fd 3e 1024 bytes de datos (divididos en bloques de 30 bytes).Fin de la transmisiónfd 25Restos de datos para alinear a 1024 bytes.¿Cómo se ve la trama final de la transferencia de bloque?: Fd 25 - señal al final de la transferencia de bloque. Siguiente 2f 52: los restos del archivo de hasta 1024 bytes. 2f 52, a juzgar por el protocolo, es una suma de verificación CRC de 16 bits.Basado en la memoria anterior, hice un programa en C que extraía 1024 bytes de un archivo y leía CRC de 16 bits. El lanzamiento del programa mostró que este no es un CRC de 16 bits. De nuevo estupor, durante unos tres días. Todo este tiempo intenté entender qué podría ser si no fuera una suma de verificación. Al estudiar sitios en inglés, descubrí que el módem X utiliza su propio cálculo de suma de comprobación: CRC-CCITT (XModem). No encontré ninguna implementación en C para este cálculo, pero encontré un sitio que lee esta suma de verificación en línea. Al subir 1024 bytes de mi archivo a la página web, el sitio me mostró una suma de verificación que coincidía completamente con la suma de verificación del archivo.¡Hurra! El último enigma está resuelto, ahora tenía que hacer su propio firmware. Luego transfirí mi conocimiento (y se quedaron solo en mi cabeza) a Ilya, quien está familiarizado con herramientas poderosas: Python.
Fd 25 - señal al final de la transferencia de bloque. Siguiente 2f 52: los restos del archivo de hasta 1024 bytes. 2f 52, a juzgar por el protocolo, es una suma de verificación CRC de 16 bits.Basado en la memoria anterior, hice un programa en C que extraía 1024 bytes de un archivo y leía CRC de 16 bits. El lanzamiento del programa mostró que este no es un CRC de 16 bits. De nuevo estupor, durante unos tres días. Todo este tiempo intenté entender qué podría ser si no fuera una suma de verificación. Al estudiar sitios en inglés, descubrí que el módem X utiliza su propio cálculo de suma de comprobación: CRC-CCITT (XModem). No encontré ninguna implementación en C para este cálculo, pero encontré un sitio que lee esta suma de verificación en línea. Al subir 1024 bytes de mi archivo a la página web, el sitio me mostró una suma de verificación que coincidía completamente con la suma de verificación del archivo.¡Hurra! El último enigma está resuelto, ahora tenía que hacer su propio firmware. Luego transfirí mi conocimiento (y se quedaron solo en mi cabeza) a Ilya, quien está familiarizado con herramientas poderosas: Python.Creación de programa
Narrado por Ilya Aleshin.Habiendo recibido las instrucciones apropiadas, estaba muy "feliz".¿Dónde empezar? Desde el principio. Por volcar desde un puerto USB.Ejecute USB-pcap https://desowin.org/usbpcap/tour.htmlElija el puerto al que está conectado el dispositivo y el archivo donde guardaremos el volcado.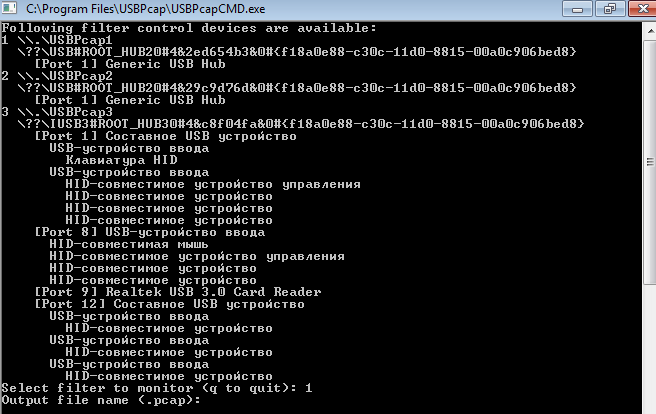 Conectamos el escáner a la máquina donde está instalado el software nativo EZConfigScanning para Windows.
Conectamos el escáner a la máquina donde está instalado el software nativo EZConfigScanning para Windows.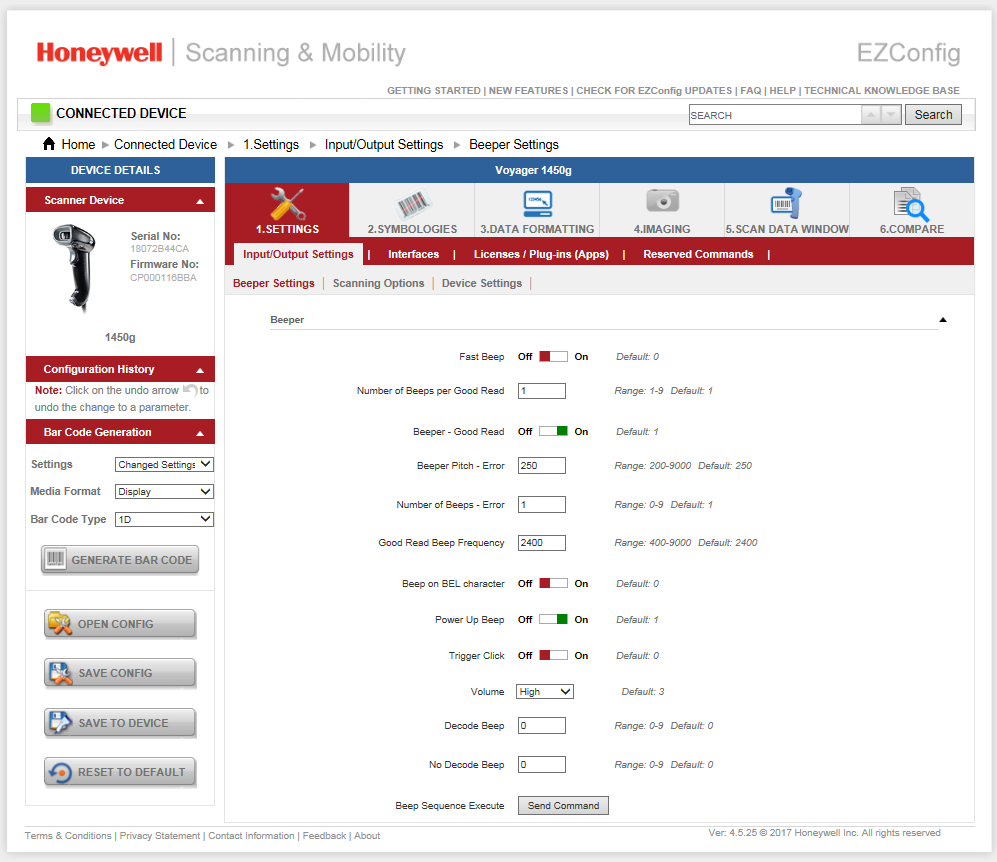 En él encontramos el punto de enviar comandos al dispositivo. ¿Pero qué hay de los equipos? ¿Dónde conseguirlos?Cuando se inicia el programa, el equipo se interroga automáticamente (lo veremos un poco más adelante). Y había códigos de barras de capacitación de los documentos oficiales del equipo. DEFALT. Este es nuestro equipo.
En él encontramos el punto de enviar comandos al dispositivo. ¿Pero qué hay de los equipos? ¿Dónde conseguirlos?Cuando se inicia el programa, el equipo se interroga automáticamente (lo veremos un poco más adelante). Y había códigos de barras de capacitación de los documentos oficiales del equipo. DEFALT. Este es nuestro equipo. Se reciben los datos necesarios. Abra dump.pcap a través de wireshark.Bloquear al iniciar EZConfigScanning. Los puntos rojos son lugares a los que prestar atención.
Se reciben los datos necesarios. Abra dump.pcap a través de wireshark.Bloquear al iniciar EZConfigScanning. Los puntos rojos son lugares a los que prestar atención.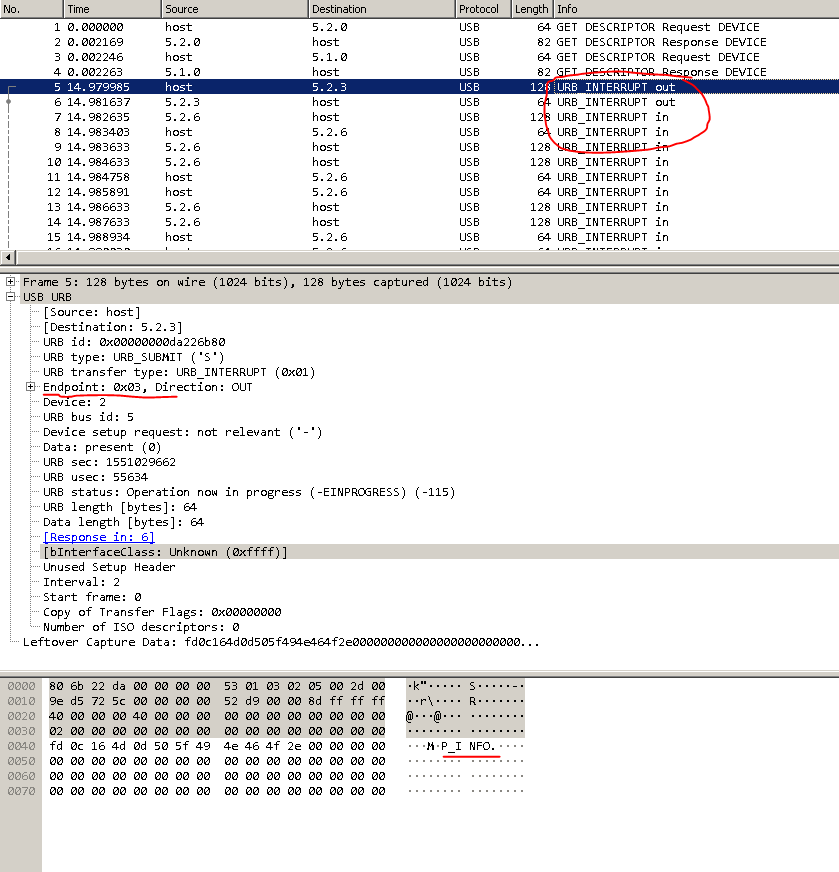
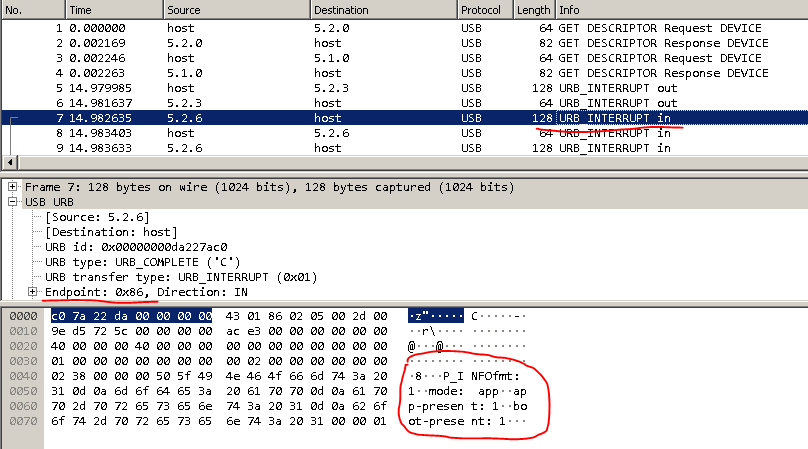 Al ver todo esto por primera vez, me desanimé. Dónde cavar más lejos no está claro.Un poco de lluvia de ideas y-y-y ... ¡Ajá! En un basurero, afuera está adentro , y adentro está afuera .Busqué en Google qué es URB_INTERRUPT. Descubrí que este es un método de transferencia de datos. Y hay 4 de estos métodos: control, interrupción, isócrono, a granel. Puedes leer sobre ellos por separado.Y las direcciones de punto final en la interfaz del dispositivo USB se pueden obtener a través del comando “lsusb –v” o mediante pyusb.Ahora necesita encontrar todos los dispositivos con este VID. Puede buscar específicamente por VID: PID.
Al ver todo esto por primera vez, me desanimé. Dónde cavar más lejos no está claro.Un poco de lluvia de ideas y-y-y ... ¡Ajá! En un basurero, afuera está adentro , y adentro está afuera .Busqué en Google qué es URB_INTERRUPT. Descubrí que este es un método de transferencia de datos. Y hay 4 de estos métodos: control, interrupción, isócrono, a granel. Puedes leer sobre ellos por separado.Y las direcciones de punto final en la interfaz del dispositivo USB se pueden obtener a través del comando “lsusb –v” o mediante pyusb.Ahora necesita encontrar todos los dispositivos con este VID. Puede buscar específicamente por VID: PID. Se parece a esto:
Se parece a esto: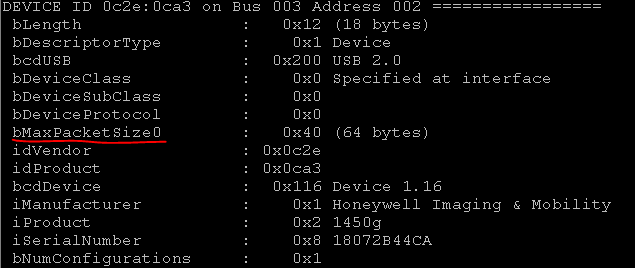
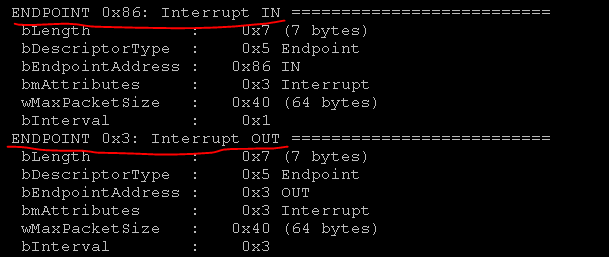 Entonces, tenemos la información necesaria: comandos P_INFO. o DEFALT, direcciones donde escribir los comandos endpoint = 03 y dónde obtener el endpoint de respuesta = 86. Solo queda traducir los comandos en hexadecimal.
Entonces, tenemos la información necesaria: comandos P_INFO. o DEFALT, direcciones donde escribir los comandos endpoint = 03 y dónde obtener el endpoint de respuesta = 86. Solo queda traducir los comandos en hexadecimal.
 Como ya encontramos el dispositivo, desconéctelo del núcleo ...
Como ya encontramos el dispositivo, desconéctelo del núcleo ...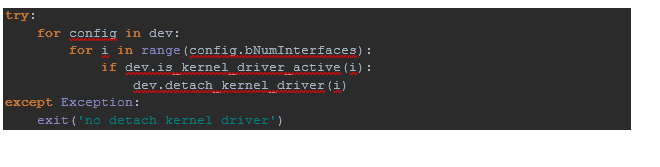 ... y escriba en el punto final con la dirección 0x03,
... y escriba en el punto final con la dirección 0x03, ... y luego lea la respuesta del punto final con la dirección 0x86.
... y luego lea la respuesta del punto final con la dirección 0x86. Respuesta estructurada:
Respuesta estructurada:P_INFOfmt: 1
mode: app
app-present: 1
boot-present: 1
hw-sn: 18072B44CA
hw-rev: 0x20
cbl: 4
app-sw-rev: CP000116BBA
boot-sw-rev: CP000014BAD
flash: 3
app-m_name: Voyager 1450g
boot-m_name: Voyager 1450g
app-p_name: 1450g
boot-p_name: 1450g
boot-time: 16:56:02
boot-date: Oct 16 2014
app-time: 08:49:30
app-date: Mar 25 2019
app-compat: 289
boot-compat: 288
csum: 0x6986
Vemos estos datos en dump.pcap.

 ¡Multa! Traducimos los códigos de barras del sistema a hexadecimal. Todo, la funcionalidad de entrenamiento está lista.¿Qué hacer con el firmware? Parece que todo es igual, pero hay un matiz.Habiendo eliminado un volcado completo del proceso de flasheo, entendimos aproximadamente a qué nos enfrentamos. Aquí hay un artículo sobre XMODEM que realmente ayudó a entender cómo ocurre esta comunicación, aunque en términos generales: http://microsin.net/adminstuff/others/xmodem-protocol-overview.html Recomiendo leerlo.Si observa el volcado, puede ver que el tamaño de trama es 1024 y el tamaño de los datos URB es 64.
¡Multa! Traducimos los códigos de barras del sistema a hexadecimal. Todo, la funcionalidad de entrenamiento está lista.¿Qué hacer con el firmware? Parece que todo es igual, pero hay un matiz.Habiendo eliminado un volcado completo del proceso de flasheo, entendimos aproximadamente a qué nos enfrentamos. Aquí hay un artículo sobre XMODEM que realmente ayudó a entender cómo ocurre esta comunicación, aunque en términos generales: http://microsin.net/adminstuff/others/xmodem-protocol-overview.html Recomiendo leerlo.Si observa el volcado, puede ver que el tamaño de trama es 1024 y el tamaño de los datos URB es 64.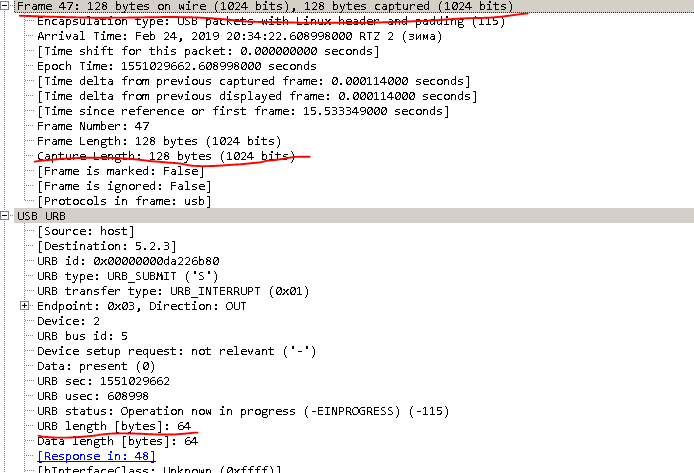 Por lo tanto, 1024/64, obtenemos 16 líneas en un bloque, leemos el archivo de firmware por 1 carácter y formamos un bloque. Complementando 1 línea en un bloque con caracteres especiales fd3e02 + número de bloque.Las siguientes 14 líneas se complementan con fd25 +, usando XMODEM.calc_crc () calculamos la suma de verificación de todo el bloque (tomó mucho tiempo entender que "FF - 1" es CSUM) y la última línea 16 se complementa con fd3e.Parece que todo, lea el archivo de firmware, golpee los bloques, desconecte el escáner del núcleo y envíelo al dispositivo. Pero no tan simple. El escáner debe ponerse en modo firmwareenviándolo NEWAPP = '\\ xfd \\ x0a \\ x16 \\ x4e \\ x2c \\ x4e \\ x45 \\ x57 \\ x41 \\ x50 \\ x50 \\ x0d'.¿De dónde viene este comando? Del basurero.
Por lo tanto, 1024/64, obtenemos 16 líneas en un bloque, leemos el archivo de firmware por 1 carácter y formamos un bloque. Complementando 1 línea en un bloque con caracteres especiales fd3e02 + número de bloque.Las siguientes 14 líneas se complementan con fd25 +, usando XMODEM.calc_crc () calculamos la suma de verificación de todo el bloque (tomó mucho tiempo entender que "FF - 1" es CSUM) y la última línea 16 se complementa con fd3e.Parece que todo, lea el archivo de firmware, golpee los bloques, desconecte el escáner del núcleo y envíelo al dispositivo. Pero no tan simple. El escáner debe ponerse en modo firmwareenviándolo NEWAPP = '\\ xfd \\ x0a \\ x16 \\ x4e \\ x2c \\ x4e \\ x45 \\ x57 \\ x41 \\ x50 \\ x50 \\ x0d'.¿De dónde viene este comando? Del basurero. Pero no podemos enviar todo el bloque al escáner debido a la restricción de 64:
Pero no podemos enviar todo el bloque al escáner debido a la restricción de 64: Bueno, el escáner en el modo de parpadeo NEWAPP tampoco acepta hexadecimal. Por lo tanto, es necesario traducir cada línea bytes_array
Bueno, el escáner en el modo de parpadeo NEWAPP tampoco acepta hexadecimal. Por lo tanto, es necesario traducir cada línea bytes_array[253, 10, 22, 78, 44, 78, 69, 87, 65, 80, 80, 13, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0]
Y ya envía estos datos al escáner.Obtenemos la respuesta:[2, 1, 0, 0, 0, 6, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0]
Si revisa el artículo sobre XMODEM, queda claro: los datos han sido aceptados. Después de que se hayan transferido todos los bloques, completamos la transferencia END_TRANSFER = '\ xfd \ x01 \ x04'.Bueno, dado que estos bloques no contienen ninguna información para la gente común, haremos el firmware en modo oculto de forma predeterminada. Y por si acaso, a través de tqdm organizaremos una barra de progreso.
Después de que se hayan transferido todos los bloques, completamos la transferencia END_TRANSFER = '\ xfd \ x01 \ x04'.Bueno, dado que estos bloques no contienen ninguna información para la gente común, haremos el firmware en modo oculto de forma predeterminada. Y por si acaso, a través de tqdm organizaremos una barra de progreso. En realidad, el resto es pequeño. Solo queda envolver la solución en scripts para la replicación masiva en un momento claramente definido, a fin de no ralentizar el proceso de trabajo en la taquilla y agregar el registro.
En realidad, el resto es pequeño. Solo queda envolver la solución en scripts para la replicación masiva en un momento claramente definido, a fin de no ralentizar el proceso de trabajo en la taquilla y agregar el registro.Total
Después de pasar mucho tiempo, energía y cabello en la cabeza , pudimos desarrollar las soluciones que necesitábamos, además, cumplimos con la fecha límite. Al mismo tiempo, los escáneres se actualizan y se vuelven a entrenar ahora de forma centralizada, controlamos claramente todo el proceso. La compañía ahorró tiempo y dinero, y obtuvimos una experiencia invaluable en ingeniería inversa de este tipo de equipos.