 Ilustración creada para A Journey With Go de un original Gopher creado por Rene French.En términos de rendimiento, el uso sistemático de punteros en lugar de copiar la estructura misma para compartir estructuras con muchos desarrolladores de Go parece ser la mejor opción. Para comprender el efecto de usar un puntero en lugar de una copia de la estructura, consideraremos dos casos de uso.
Ilustración creada para A Journey With Go de un original Gopher creado por Rene French.En términos de rendimiento, el uso sistemático de punteros en lugar de copiar la estructura misma para compartir estructuras con muchos desarrolladores de Go parece ser la mejor opción. Para comprender el efecto de usar un puntero en lugar de una copia de la estructura, consideraremos dos casos de uso.Distribución intensiva de datos
Veamos un ejemplo simple cuando desee compartir una estructura para acceder a sus valores:type S struct {
a, b, c int64
d, e, f string
g, h, i float64
}
Aquí está la estructura básica, cuyo acceso se puede compartir mediante copia o puntero:func byCopy() S {
return S{
a: 1, b: 1, c: 1,
e: "foo", f: "foo",
g: 1.0, h: 1.0, i: 1.0,
}
}
func byPointer() *S {
return &S{
a: 1, b: 1, c: 1,
e: "foo", f: "foo",
g: 1.0, h: 1.0, i: 1.0,
}
}
En base a estos dos métodos, podemos escribir 2 puntos de referencia. El primero es donde se pasa la estructura con una copia:func BenchmarkMemoryStack(b *testing.B) {
var s S
f, err := os.Create("stack.out")
if err != nil {
panic(err)
}
defer f.Close()
err = trace.Start(f)
if err != nil {
panic(err)
}
for i := 0; i < b.N; i++ {
s = byCopy()
}
trace.Stop()
b.StopTimer()
_ = fmt.Sprintf("%v", s.a)
}
El segundo, muy similar al primero, donde la estructura se pasa por puntero:func BenchmarkMemoryHeap(b *testing.B) {
var s *S
f, err := os.Create("heap.out")
if err != nil {
panic(err)
}
defer f.Close()
err = trace.Start(f)
if err != nil {
panic(err)
}
for i := 0; i < b.N; i++ {
s = byPointer()
}
trace.Stop()
b.StopTimer()
_ = fmt.Sprintf("%v", s.a)
}
Ejecutemos los puntos de referencia:go test ./... -bench=BenchmarkMemoryHeap -benchmem -run=^$ -count=10 > head.txt && benchstat head.txt
go test ./... -bench=BenchmarkMemoryStack -benchmem -run=^$ -count=10 > stack.txt && benchstat stack.txt
Obtenemos las siguientes estadísticas:name time/op
MemoryHeap-4 75.0ns ± 5%
name alloc/op
MemoryHeap-4 96.0B ± 0%
name allocs/op
MemoryHeap-4 1.00 ± 0%
------------------
name time/op
MemoryStack-4 8.93ns ± 4%
name alloc/op
MemoryStack-4 0.00B
name allocs/op
MemoryStack-4 0.00
¡Usar una copia de la estructura fue 8 veces más rápido que usar un puntero!Para entender por qué, veamos los gráficos generados por la traza: el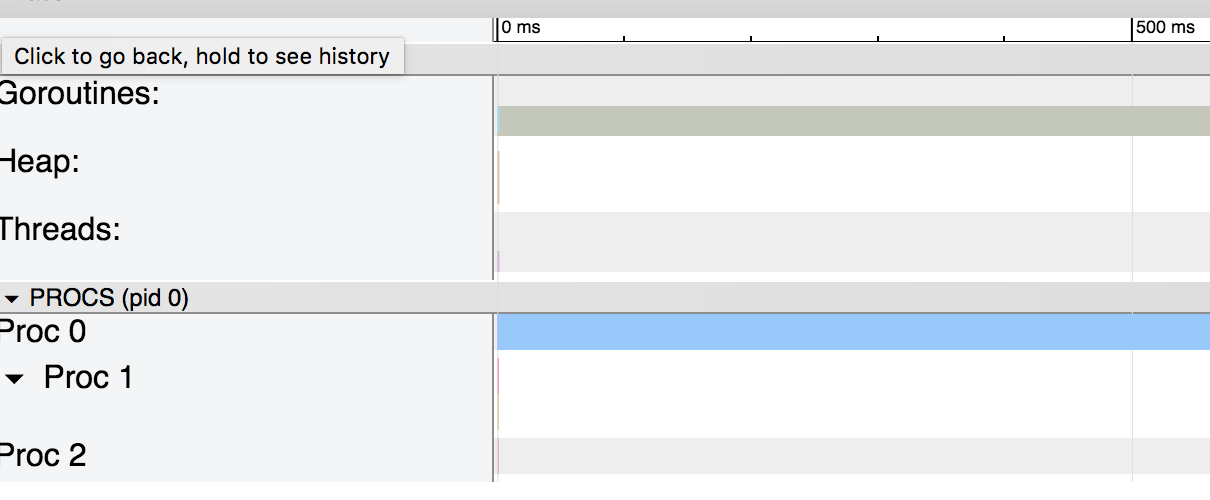 gráfico de la estructura pasada por la copia, el
gráfico de la estructura pasada por la copia, el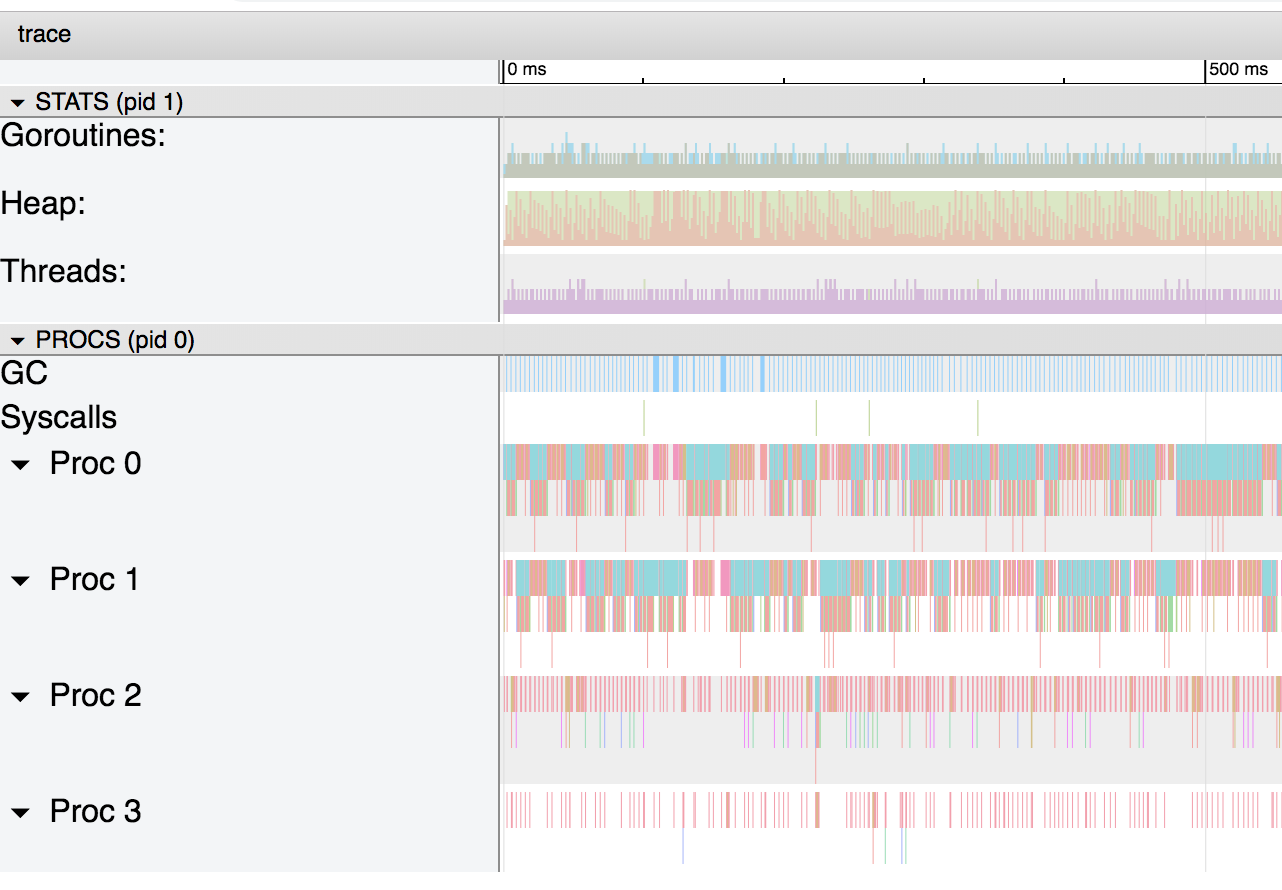 gráfico de la estructura pasada por el puntero.El primer gráfico es bastante simple. Como no se usa el montón, no hay recolector de basura y exceso de gorutina.En el segundo caso, el uso de punteros hace que el compilador Go mueva la variable al montón y trabaje como recolector de basura. Si aumentamos la escala del gráfico, veremos que el recolector de basura ocupa una parte importante del proceso:
gráfico de la estructura pasada por el puntero.El primer gráfico es bastante simple. Como no se usa el montón, no hay recolector de basura y exceso de gorutina.En el segundo caso, el uso de punteros hace que el compilador Go mueva la variable al montón y trabaje como recolector de basura. Si aumentamos la escala del gráfico, veremos que el recolector de basura ocupa una parte importante del proceso: este gráfico muestra que el recolector de basura comienza cada 4 ms.Si volvemos a acercarnos, podemos obtener información detallada sobre lo que está sucediendo exactamente:
este gráfico muestra que el recolector de basura comienza cada 4 ms.Si volvemos a acercarnos, podemos obtener información detallada sobre lo que está sucediendo exactamente: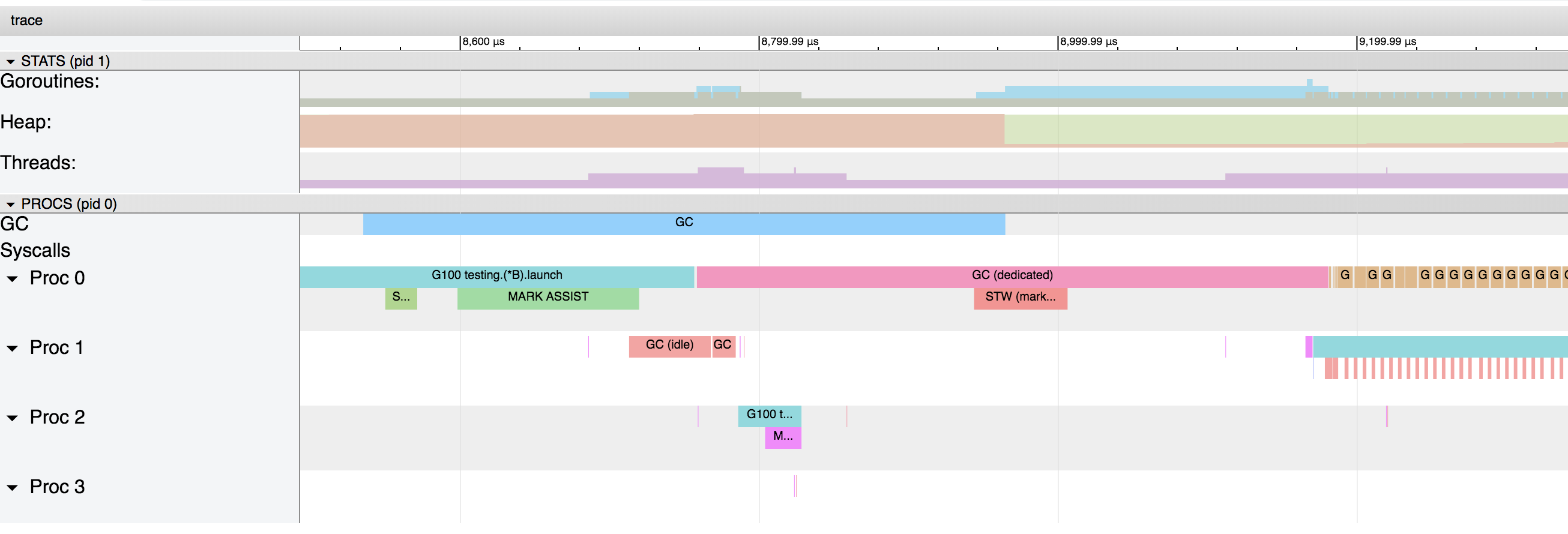 las franjas azul, rosa y roja son las fases del recolector de basura, y las marrones están asociadas con la asignación en el montón (marcado "runtime.bgsweep" en el gráfico):
las franjas azul, rosa y roja son las fases del recolector de basura, y las marrones están asociadas con la asignación en el montón (marcado "runtime.bgsweep" en el gráfico):Barrido es la liberación del montón de secciones de memoria relacionadas con datos que no están marcadas como utilizadas. Esta acción ocurre cuando las gorutinas intentan aislar nuevos valores en la memoria del montón. El retraso de barrido se agrega al costo de realizar la asignación en la memoria de almacenamiento dinámico y no se aplica a ningún retraso asociado con la recolección de basura.
www.ardanlabs.com/blog/2018/12/garbage-collection-in-go-part1-semantics.html
Incluso si este ejemplo es un poco extremo, vemos cómo puede ser costoso asignar una variable en el montón en lugar de en la pila. En nuestro ejemplo, la estructura se asigna mucho más rápido en la pila y se copia que se crea en el montón y se comparte su dirección.Si no está familiarizado con la pila / montón, y si desea saber más sobre sus detalles internos, puede encontrar mucha información en Internet, por ejemplo, este artículo de Paul Gribble.
Las cosas pueden ser aún peores si limitamos el procesador a 1 usando GOMAXPROCS = 1:name time/op
MemoryHeap 114ns ± 4%
name alloc/op
MemoryHeap 96.0B ± 0%
name allocs/op
MemoryHeap 1.00 ± 0%
------------------
name time/op
MemoryStack 8.77ns ± 5%
name alloc/op
MemoryStack 0.00B
name allocs/op
MemoryStack 0.00
Si el punto de referencia para colocar en la pila no cambió, entonces el indicador en el montón disminuyó de 75ns / op a 114ns / op.Llamadas a funciones intensivas
Agregaremos dos métodos vacíos a nuestra estructura y adaptaremos un poco nuestros puntos de referencia:func (s S) stack(s1 S) {}
func (s *S) heap(s1 *S) {}
El punto de referencia con la colocación en la pila creará la estructura y le pasará una copia:func BenchmarkMemoryStack(b *testing.B) {
var s S
var s1 S
s = byCopy()
s1 = byCopy()
for i := 0; i < b.N; i++ {
for i := 0; i < 1000000; i++ {
s.stack(s1)
}
}
}
Y el punto de referencia para el montón pasará la estructura por puntero:func BenchmarkMemoryHeap(b *testing.B) {
var s *S
var s1 *S
s = byPointer()
s1 = byPointer()
for i := 0; i < b.N; i++ {
for i := 0; i < 1000000; i++ {
s.heap(s1)
}
}
}
Como se esperaba, los resultados son completamente diferentes ahora:name time/op
MemoryHeap-4 301µs ± 4%
name alloc/op
MemoryHeap-4 0.00B
name allocs/op
MemoryHeap-4 0.00
------------------
name time/op
MemoryStack-4 595µs ± 2%
name alloc/op
MemoryStack-4 0.00B
name allocs/op
MemoryStack-4 0.00
Conclusión
Usar un puntero en lugar de una copia de la estructura en go no siempre es bueno. Para elegir una buena semántica para sus datos, le recomiendo leer una publicación sobre semántica de valor / puntero escrita por Bill Kennedy . Esto le dará una mejor idea de las estrategias que puede usar con sus estructuras y tipos incorporados. Además, el uso de perfiles de memoria definitivamente lo ayudará a comprender lo que está sucediendo con sus asignaciones y el montón.